数据库sql分组
sql group by分组后条件判断

SQL GROUP BY 分组后条件判断在SQL中,使用GROUP BY语句可以将查询结果按照指定的列进行分组,并对每个分组进行聚合操作。
但有时候我们需要在分组后对每个组进行条件判断,以便筛选出符合特定条件的数据。
本文将详细介绍如何使用SQL的GROUP BY分组后进行条件判断。
1. GROUP BY语法首先,我们来回顾一下GROUP BY语句的基本语法:SELECT列名1, 列名2, ...FROM表名GROUP BY列名1, 列名2, ...GROUP BY语句用于将查询结果按照指定的列进行分组,而SELECT子句中的列必须是GROUP BY子句中指定的列或者是聚合函数(如SUM、AVG、COUNT等)。
2. 分组后条件判断在使用GROUP BY分组后,我们可以通过HAVING子句对每个分组进行条件判断。
HAVING子句用于在分组后筛选满足特定条件的数据。
SELECT列名1, 列名2, ...FROM表名GROUP BY列名1, 列名2, ...HAVING条件HAVING子句和WHERE子句类似,但它用于筛选已经分组后的数据。
只有满足HAVING子句中指定的条件的分组才会被包含在结果集中。
3. 示例为了更好地理解GROUP BY分组后条件判断的使用,我们来看一个示例。
假设有一个名为”orders”的表,包含以下列:order_id, customer_id, order_date和order_total。
我们想要分别计算每个客户的总订单金额,并筛选出总订单金额大于1000的客户。
首先,我们需要使用GROUP BY语句按照customer_id进行分组,并使用SUM函数计算每个客户的总订单金额:SELECT customer_id, SUM(order_total) AS total_amountFROM ordersGROUP BY customer_id接下来,我们需要在分组后进行条件判断,筛选出总订单金额大于1000的客户。
SQL汇总和分组数据

SQL汇总和分组数据SQL是一种用于管理和操作关系型数据库的语言,它提供了各种功能和命令,用于对数据进行查询、插入、更新和删除等操作。
汇总和分组数据是SQL中常用的功能之一,可以用于对数据进行统计和分析。
在SQL中,可以使用如下几个关键字来实现汇总和分组数据的操作:1.SELECT:用于查询数据,可以通过SELECT命令选择相应的列或者使用通配符"*"选择所有列。
2.FROM:用于指定查询的数据源,即要查询的表或者视图的名称。
3.GROUPBY:用于对数据进行分组。
可以按照一个或多个列来进行分组,分组后的数据将会根据指定的列值进行分组。
4.HAVING:用于对分组后的数据进行过滤。
可以使用逻辑运算符和聚合函数对分组后的数据进行筛选。
5.ORDERBY:用于对查询结果进行排序,可以按照一个或多个列进行排序。
下面是一个示例,展示如何使用SQL对数据进行汇总和分组:假设有一个存储销售订单信息的订单表,其中包含以下字段:订单号、客户名、订单金额和订单日期。
现在需要查询每个客户的订单总金额,并按照总金额降序排列。
```sqlSELECT客户名,SUM(订单金额)AS总金额FROM订单表GROUPBY客户名ORDERBY总金额DESC;```上述SQL语句中,我们使用了SUM函数来计算每个客户的订单总金额,并使用GROUPBY将结果按照客户名进行分组。
最后,使用ORDERBY将结果按照总金额降序排序。
除了SUM函数外,还可以使用其他聚合函数(如COUNT、AVG、MIN和MAX)对数据进行汇总和分组。
同时,还可以在HAVING子句中使用逻辑运算符和聚合函数来对分组后的数据进行筛选。
除了单一列的分组,还可以按照多个列进行分组。
例如,我们希望按照客户名和订单日期对数据进行分组,可以使用如下SQL语句:```sqlSELECT客户名,订单日期,SUM(订单金额)AS总金额FROM订单表GROUPBY客户名,订单日期ORDERBY客户名,订单日期;```上述SQL语句中,我们按照客户名和订单日期进行了分组,并计算每个分组的订单总金额。
数据库的分区sql语句

数据库的分区sql语句数据库的分区是指将一个大的数据库表按照某种规则拆分成多个较小的子表,以提高查询性能和管理效率。
数据库的分区可以基于范围、列表或哈希等方式进行。
下面是数据库分区的SQL语句示例:1. 基于范围的分区:```sqlCREATE TABLE 表名(列1 数据类型,列2 数据类型,...) PARTITION BY RANGE(列名) (PARTITION 分区名1 VALUES LESS THAN (边界值1),PARTITION 分区名2 VALUES LESS THAN (边界值2),...);```2. 基于列表的分区:```sqlCREATE TABLE 表名(列1 数据类型,列2 数据类型,...) PARTITION BY LIST(列名) (PARTITION 分区名1 VALUES IN (值1, 值2),PARTITION 分区名2 VALUES IN (值3, 值4),...);```3. 基于哈希的分区:```sqlCREATE TABLE 表名(列1 数据类型,列2 数据类型,...) PARTITION BY HASH(列名) PARTITIONS 分区数量; ```这些示例中,`表名`为要进行分区的表的名称,`列名`为用于分区的列的名称,`分区名`为每个分区的名称,`边界值`为范围分区或列表分区的边界值,`值`为列表分区中的值,`分区数量`为哈希分区的数量。
需要注意的是,不同的数据库管理系统可能有不同的语法和规则来进行分区,上述示例是一般情况下的SQL语句,具体应根据所使用的数据库管理系统的文档进行调整和参考。
sql 分组统计 函数

sql 分组统计函数一、COUNT函数COUNT函数用于统计指定列的行数或非空值的数量。
COUNT函数可以用于任何数据类型。
例如,统计一个表中某一列的行数,可以使用如下语句:SELECT COUNT(column_name) FROM table_name;其中,column_name是要统计的列名,table_name是要统计的表名。
二、SUM函数SUM函数用于计算指定列的数值总和。
SUM函数只能用于数值型数据。
例如,统计一个表中某一列的数值总和,可以使用如下语句:SELECT SUM(column_name) FROM table_name;其中,column_name是要计算总和的列名,table_name是要计算总和的表名。
三、AVG函数AVG函数用于计算指定列的数值平均值。
AVG函数只能用于数值型数据。
例如,统计一个表中某一列的数值平均值,可以使用如下语句:SELECT AVG(column_name) FROM table_name;其中,column_name是要计算平均值的列名,table_name是要计算平均值的表名。
四、MAX函数MAX函数用于计算指定列的最大值。
MAX函数可以用于任何数据类型。
例如,统计一个表中某一列的最大值,可以使用如下语句:SELECT MAX(column_name) FROM table_name;其中,column_name是要计算最大值的列名,table_name是要计算最大值的表名。
五、MIN函数MIN函数用于计算指定列的最小值。
MIN函数可以用于任何数据类型。
例如,统计一个表中某一列的最小值,可以使用如下语句:SELECT MIN(column_name) FROM table_name;其中,column_name是要计算最小值的列名,table_name是要计算最小值的表名。
六、GROUP BY子句GROUP BY子句用于对查询结果进行分组。
sql多表中group by用法

SQL中的GROUP BY语句用于对查询结果进行分组,并对每个组进行汇总或统计操作。
在实际应用中,我们经常需要使用多个表进行数据查询,而使用GROUP BY语句进行多表查询需要注意一些注意事项和用法。
一、基本用法1.1 GROUP BY语句的基本语法是:SELECT column_name, aggregate_function(column_name) FROM table_nameWHERE conditionGROUP BY column_name;1.2 在多表查询中,我们可以根据需要选择多个表,并通过JOIN条件将它们连接起来,然后在GROUP BY语句中指定需要分组的列名。
1.3 我们有两个表t1和t2,分别存储了员工的基本信息和工资信息,现在需要统计每个部门的平均工资,可以这样写查询语句:SELECT dept_name, AVG(salary)FROM t1JOIN t2 ON t1.emp_id = t2.emp_idGROUP BY dept_name;二、使用聚合函数2.1 在GROUP BY语句中,我们通常需要结合聚合函数来对分组进行统计。
常用的聚合函数包括COUNT、SUM、AVG、MAX和MIN等。
2.2 我们需要统计每个部门的员工数和总工资,可以这样写查询语句:SELECT dept_name, COUNT(*), SUM(salary)FROM t1JOIN t2 ON t1.emp_id = t2.emp_idGROUP BY dept_name;2.3 在使用聚合函数时,需要注意聚合函数只能用于SELECT列表中的列,而GROUP BY子句中的列必须是SELECT列表中的列或者是通过表达式计算的结果。
三、使用HAVING子句3.1 在GROUP BY语句中,如果需要对分组进行筛选,可以使用HAVING子句来进行条件过滤。
与WHERE子句不同的是,HAVING子句是在分组后对结果进行过滤,而WHERE子句是在分组前对原始数据进行过滤。
SQL语句——08、聚集,分组,行转列
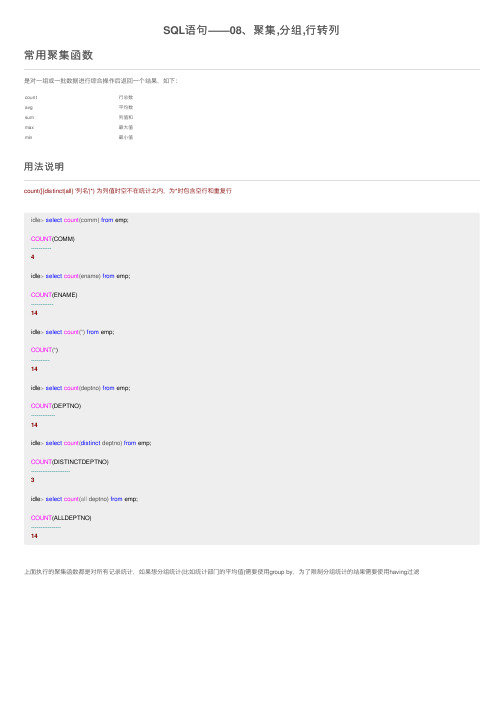
count⾏总数avg平均数sum列值和max最⼤值min最⼩值SQL语句——08、聚集,分组,⾏转列常⽤聚集函数是对⼀组或⼀批数据进⾏综合操作后返回⼀个结果,如下:⽤法说明count([{distinct|all} '列名'|*) 为列值时空不在统计之内,为*时包含空⾏和重复⾏idle>select count(comm) from emp;COUNT(COMM)-----------4idle>select count(ename) from emp;COUNT(ENAME)------------14idle>select count(*) from emp;COUNT(*)----------14idle>select count(deptno) from emp;COUNT(DEPTNO)-------------14idle>select count(distinct deptno) from emp;COUNT(DISTINCTDEPTNO)---------------------3idle>select count(all deptno) from emp;COUNT(ALLDEPTNO)----------------14上⾯执⾏的聚集函数都是对所有记录统计,如果想分组统计(⽐如统计部门的平均值)需要使⽤group by,为了限制分组统计的结果需要使⽤having过滤求出每个部门的平均⼯资idle>select deptno,avg(sal) from emp group by deptno;DEPTNO AVG(SAL)---------- ----------301566.66667202175102916.66667分组再排序idle>select deptno,avg(sal) from emp group by deptno order by deptno ;DEPTNO AVG(SAL)---------- ----------102916.66667202175301566.66667分组修饰列可以是未选择的列idle>select avg(sal) from emp group by deptno order by deptno;AVG(SAL)----------2916.6666721751566.66667如果在查询中使⽤了分组函数,任何不在分组函数中的列或表达式必须在group by⼦句中。
sql分组的规律 -回复
sql分组的规律-回复SQL分组是一种在数据库中对数据进行分类和汇总的操作。
通过将数据按照指定的属性进行分组,可以对每个组内的数据进行运算、统计和排序等操作。
本文将从什么是SQL分组、如何使用SQL进行分组、分组的规律和应用场景等方面进行详细介绍。
一、什么是SQL分组SQL分组是指根据指定的属性将数据分成不同的组,并进行相关操作的过程。
通常情况下,分组操作是在SELECT语句的后面添加GROUP BY子句来实现的。
GROUP BY子句后面可以跟一个或多个属性,用来指定按照哪些属性进行分组。
分组后,可以使用一些聚合函数,如SUM、AVG、COUNT等来对每个组内的数据进行计算。
二、如何使用SQL进行分组使用SQL进行分组可以通过以下步骤来实现:1. 编写SQL查询语句:首先需要写一条查询语句来选择需要分组的数据。
可以使用SELECT语句来选择需要的属性,可以使用WHERE子句来添加筛选条件。
2. 添加GROUP BY子句:在查询语句的末尾添加GROUP BY子句,并在子句中指定按照哪些属性进行分组。
可以使用一个或多个属性来进行分组,多个属性之间使用逗号分隔。
3. 运行查询语句:运行查询语句后,会得到按照分组属性进行分组的结果。
4. 使用聚合函数:可以在查询语句中使用一些聚合函数,如SUM、AVG、COUNT等来计算每个组内的数据。
三、分组的规律分组操作有一些规律需要注意:1. 分组属性在SELECT语句中出现:如果某个属性在GROUP BY子句中出现,那么在SELECT语句中必须出现,否则会出错。
这是因为分组后,每个组内的数据都会生成一个结果行,而SELECT语句中的属性用于选择需要显示的属性。
2. 分组属性和非分组属性的区别:分组属性是指在GROUP BY子句中指定的属性,非分组属性是指在SELECT语句中未出现在GROUP BY子句中的属性。
在SELECT语句中可以使用聚合函数来计算非分组属性的值,如SUM、AVG等。
数据库中如何分类、分组并总计SQL数据
数据库中如何分类、分组并总计SQL数据您需要了解如何使用某些SQL子句和运算符来安排SQL数据,从而对它进行高效分析。
下面这些建议告诉您如何建立语句,获得您希望的结果。
以有意义的方式安排数据可能是一种挑战。
有时您只需进行简单分类。
通常您必须进行更多处理——进行分组以利于分析与总计。
可喜的是,SQL提供了大量用于分类、分组和总计的子句及运算符。
下面的建议将有助于您了解何时进行分类、何时分组、何时及如何进行总计。
1、分类排序通常,我们确实需要对所有数据进行排序。
SQL的ORDER BY子句将数据按字母或数字顺序进行排列。
因此,同类数据明显分类到各个组中。
然而,这些组只是分类的结果,它们并不是真正的组。
ORDER BY显示每一个记录,而一个组可能代表多个记录。
2、减少组中的相似数据分类与分组的不同在于:分类数据显示(任何限定标准内的)所有记录,而分组数据不显示这些记录。
GROUP BY子句减少一个记录中的相似数据。
例如,GROUP BY能够从重复那些值的源文件中返回一个的邮政编码列表:SELECT ZIPFROM CustomersGROUP BY ZIP仅包括那些在GROUP BY和SELECT列列表中字义组的列。
换句话说,SELECT列表必须与GROUP列表相匹配。
只有一种情况例外:SELECT列表能够包含聚合函数。
(而GROUP BY不支持聚合函数。
)记住,GROUP BY不会对作为结果产生的组分类。
要对组按字母或数字顺序排序,增加一个ORDER BY子句(#1)。
另外,在GROUP BY子句中您不能引用一个有别名的域。
组列必须在根本数据中,但它们不必出现在结果中。
3、分组前限定数据您可以增加一个WHERE子句限定由GROUP BY分组的数据。
例如,下面的语句仅返回肯塔基地区顾客的邮政编码列表。
SELECT ZIPFROM CustomersWHERE State = 'KY'GROUP BY ZIP在GROUP BY子句求数据的值之前,WHERE对数据进行过滤,记住这一点很重要。
SQL 分组、分类
在数据库中如何分类、分组并总计SQL数据您需要了解如何使用某些SQL子句和运算符来安排SQL数据,从而对它进行高效分析。
下面这些建议告诉您如何建立语句,获得您希望的结果。
以有意义的方式安排数据可能是一种挑战。
有时您只需进行简单分类。
通常您必须进行更多处理——进行分组以利于分析与总计。
可喜的是,SQL提供了大量用于分类、分组和总计的子句及运算符。
下面的建议将有助于您了解何时进行分类、何时分组、何时及如何进行总计。
欲了解每个子句和运算符的详细信息,请查看在线书籍。
#1:分类排序通常,我们确实需要对所有数据进行排序。
SQL的ORDER BY 子句将数据按字母或数字顺序进行排列。
因此,同类数据明显分类到各个组中。
然而,这些组只是分类的结果,它们并不是真正的组。
ORDER BY显示每一个记录,而一个组可能代表多个记录。
#2:减少组中的相似数据分类与分组的最大不同在于:分类数据显示(任何限定标准内的)所有记录,而分组数据不显示这些记录。
GROUP BY子句减少一个记录中的相似数据。
例如,GROUP BY能够从重复那些值的源文件中返回一个唯一的邮政编码列表:SELECT ZIPFROM CustomersGROUP BY ZIP仅包括那些在GROUP BY和SELECT列列表中字义组的列。
换句话说,SELECT列表必须与GROUP列表相匹配。
只有一种情况例外:SE LECT列表能够包含聚合函数。
(而GROUP BY不支持聚合函数。
)记住,G ROUP BY不会对作为结果产生的组分类。
要对组按字母或数字顺序排序,增加一个ORDER BY子句(#1)。
另外,在GROUP BY子句中您不能引用一个有别名的域。
组列必须在根本数据中,但它们不必出现在结果中。
#3:分组前限定数据您可以增加一个WHERE子句限定由GROUP BY分组的数据。
例如,下面的语句仅返回肯塔基地区顾客的邮政编码列表。
SELECT ZIPFROM CustomersWHERE State = 'KY'GROUP BY ZIP在GROUP BY子句求数据的值之前,WHERE对数据进行过滤,记住这一点很重要。
如何在MySQL中实现数据分组与汇总
如何在MySQL中实现数据分组与汇总在数据处理和数据分析过程中,数据的分组与汇总是非常重要的环节。
MySQL作为一种常用的关系型数据库管理系统,提供了丰富的聚合函数和分组操作,使得我们可以轻松地实现数据的分组与汇总。
本文将介绍如何在MySQL中实现数据分组与汇总,并探讨一些相关的技巧和注意事项。
1. GROUP BY子句的使用GROUP BY子句是实现数据分组的基础,在SELECT语句中通过GROUP BY 子句可以将结果集按照指定的列进行分组。
例如,我们有一个订单表(order),其中包括订单编号(order_id)、客户编号(customer_id)和订单金额(amount)等字段。
我们可以使用以下语句将订单按照客户编号进行分组,并计算每个客户的订单总金额:```sqlSELECT customer_id, SUM(amount) AS total_amountFROM ordersGROUP BY customer_id;```上述语句中,我们使用SUM函数将每个客户的订单金额进行求和,并通过GROUP BY子句将结果按照客户编号进行分组。
通过这个简单的例子,我们可以看到GROUP BY子句的基本使用方法。
在实际应用中,根据具体的需求可以使用多个字段进行分组,或者与其他函数(如COUNT、AVG等)进行组合使用,以满足更加复杂的业务需求。
2. 聚合函数的运用在数据分组的过程中,经常需要对分组后的数据进行汇总计算。
MySQL提供了一系列的聚合函数,如SUM、COUNT、AVG、MAX、MIN等,使得我们可以方便地对数据进行求和、计数、求平均值、找出最大值和最小值等操作。
继续以订单表(order)为例,假设我们需要计算每个客户的平均订单金额。
可以使用以下语句实现:```sqlSELECT customer_id, AVG(amount) AS avg_amountFROM ordersGROUP BY customer_id;```上述语句中,我们使用AVG函数计算每个客户的平均订单金额,并通过GROUP BY子句按照客户编号进行分组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、聚集数据
2、聚集函数
聚集函数是SQL中很重要的一部分。聚 集函数不是对某个记录进行操作,而是对表 中或查询到的所有记录进行操作。聚集函数 中的expression通常是一个列名或者别名, 但也可以是一个常量或者一个函数(SQL支持 函数的嵌套)。 在使用聚集函数时,需要注意: 在函数COUNT( )、SUM( )、AVG( )中可以使用DISTINCT关键字,以在计算中不 包含重复的行。而对于函数MAX( )、MIN( )与COUNT(*)由于不会改变其结果,因此 没有必要使用DISTINCT。 函数SUM( )、AVG( )只能对类型为数字数据类型的列使用,而函数COUNT( )、 MAX( )、MIN( )与COUNT(*)可以对所有数据类型使用。 不同的系统可能提供不同的函数,例如Oracle中提供了用于计算的STDDEV() 与VARIANCE()函数,ASA中提供了LIST()函数。使用时请注意查阅系统手册。
本章小结:
•掌握对数据进行排序的方法和注意点 •掌握聚集数据的方法 •掌握对数据分组的方法
SELECT pnumber, budget, gross, gross – budget AS profit FROM Project WHERE profit >= 30000.00 AND profit <= 70000.00 ORDER BY profit
(2)使用别名排序 如果没有为表达式创建别名也没有关系,SQL也支持按照在SELECT子句列 表中的位置来指定排序的列。
二、聚集数据
1、去除相同行:DISTINCT
SELECT子句中有两个可选的关键字ALL与DISTINCT,ALL为默认选项,表 示列出所有记录,而不管是否出现重复。如果要去掉重复的记录,可以使用 DISTINCT关键字。可以使用DISTINCT对一列或多列的组合进行重复的删除。 (1)在一列中使用 (2)在多列中使用 (3)空值的处理
三、分组数据
1、GROUP BY子句
GROUP BY子句根据列的内容对查询 结果进行分类。使用GROUP BY时, order_list中的每一列都必须出现在 select_list中,即不能选择 select_list之外的列用于分组。
GROUP BY与 DISTINCT GROUP BY与聚集函 数 与WHERE子句一起使 用
SELECT pnumber, budget, gross, gross – budget FROM Project WHERE profit >= 30000.00 AND profit <= 70000.00 ORDER BY 4 DESC
一、排序数据
4、多级排序
SQL中可以指定多列进行排序。初级排序对查询结果进行分类并排序,第 二级排序对初级排序分好的类中的数据在相同的数据中进行再次排序。 用户也可以在多级排序中使用DESC与ASC关键字,以指定排序的列是按 照降序还是升序进行排序。多级排序中的DESC与ASC关键字的使用是互不干扰 的。 在多级排序中还可以使用别名和位置指定排序的列。
二、聚集数据
3、避免使用DISTINCT时的错误
在列和表达式 中使用 DISTINCT 在聚集函数中 使用 DISTINCT DISTINCT对空 值的处理
在列和表达式中使用DISTINCT时,只能使用一次DISTINCT,因为 DISTINCT是对SELECT列表中的所有元素的组合起作用。这样在使用 DISTINCT时有了很大的限制,或者是对一个列或表达式去除重复值, 或者对列的组合去除重复值,而不能在列的组合中分别对每个列或 表达式指定是否包含DISTINCT。 聚集函数中可以包含DISTINCT关键字。函数之间使用DISTINCT是互 不干扰的,它是在函数计算时起作用,并不与规则——DISTINCT必 须在select_list之前使用——相违背。 DISTINCT对空值的处理与其它运算符对空值的处理有相同也有不同。 相同点:都将空值作为未知对待,不认为其大于或小于其它任何值; 不同点:对其它运算符而言,空值之间是互不相同的,而且要想查 找到空值需要使用IS NULL进行判断;而对于DISTINCT来说,将空 值看作是相同的,也不需要使用IS NULL。
一、排序数据
2、升序排序和降序排序
在排序中用户可以指定按照什么顺序来排序:升序或降序。SQL中,关键 字ASC表示按照升序排列,关键字DESC表示按照降序排列。而默认的排序方式 为升序,也就是说,如果用户不输入DESC或ASC,那么显示结果将按照从低到 高的顺序排列。当然,为了使用户能更好的明白显示结果的排列顺序,也可 Results 以指定ASC。
三、分组数据
5、空值的处理
GROUP BY子句将分组中所有的空值也都看成是相同的,如果成组的列包 含多个空值,那么它们将被放在同一组中。
6、避免分组时的错误
使用多次分组时,如果包含聚集函数,需要注意的是:多次分组后聚 集函数是对多次分组形成的小组进行计算,而不是对先形成的大组进行计算; 在使用GROUP BY子句时还应该注意以下一些事项: (1)GROUP BY子句、HAVING子句中使用的列名必须包含在SELECT列表 中,否则将会产生错误,不过HAVING子句中使用的列名不一定要包含在GROUP BY子句中。如果使用ORDER BY子句,则ORDER BY子句中使用的列名必须是 GROUP BY子句中包含的列名; (2)ORDER BY子句必须跟在GROUP BY子句之后,如果使用HAVING子句 它必须紧接在GROUP BY子句之后,而在ORDER BY子句之前; (3)HAVING子句是对组进行限制,而WHERE子句是对行进行限制,二 者虽然有相似之处,但是仍有很大的不同; (4)对空值成组时,要注意COUNT( )与COUNT(*)之间的不同。
三、分组数据
2、多次分组
可以使用ORDER BY子句对多个列进行排序一样,在GROUP BY子句中也可 以指定多个列对一组数据再次进行分组。多个列之间也是使用逗号分隔。执 行顺序也与多级排序类似:先对查询结果进行分组,再对分好的组中的数据 进行第二次分组。
3、多次分组
ORDER BY子句可以与GROUP BY子句一起使用以对结果进行排序,更清 晰的显示结果。SQL语句书写时,ORDER BY子句必须在GROUP BY子句之后书写。 这两个子句一起使用时,执行顺序为: 按照GROUP BY对查询到的数据进行分组; 使用ORDER BY对形成的组中的数据进行排序。
SELECT [ALL | DISTINCT] select_list FROM table_list/view_list [WHERE conditions] [GROUP BY group_list] [HAVING conditions] [ORDER BY order_list]
GROUP BY子句可以用来对数据进行分组,将数据分成组并为每一组返回一 行。在不使用聚集函数时,使用GROUP BY与D有聚集函数GROUP BY 子句也就没有多大的用处。GROUP BY子句可以将查询到的数据分成组,而 聚集函数则用来对每组的数据进行计算。二者的结合是非常有用的。 排序中可以使用WHERE子句以对特定的记录进行排序,在分组中也可以使 用WHERE子句以对特定的记录进行分组。执行顺序为:先执行WHERE子句 将符合条件的记录选出,再对选出的数据进行分组。当然,WHERE子句中 使用的列并不是一定要在SELECT列表中出现。
在ORDER BY子句中也可以包含多个元素,元素之间也是使用逗号隔开; 关键字ASC表示按照升序排列,这是默认的排列方式。而关键字DESC表 示按照降序排列; 在ORDER BY列表可以是SELECT子句中一个列的名称——columnname; 也可以是SELECT子句中为列或表达式创建的别名——alias;也可以是 SELECT子句中代表位置的编码——position,如1表示SELECT子句中第一个 列,2表示SELECT子句中第二个列。
SELECT name, sex, id, salary FROM Employee WHERE salary = 3000.00 OR salary = 6000.00 ORDER BY id DESC
一、排序数据
3、使用表达式排序
(1)使用别名排序 为列或表达式创建了别名之后,在排序中就可以使用别名来指定进行排 序的列。
name sex id salary ————— ——— —— ———— 王力刚 男 5003 3000.00 梁朝阳 男 5002 3000.00 王亚鹏 男 4004 6000.00 魏华翔 男 4003 6000.00 王静 女 3004 3000.00 吴忠彦 男 3002 3000.00 林志祥 男 2003 3000.00 刘燕 女 2002 3000.00 庞文凯 男 1005 3000.00 李大平 男 1003 3000.00 林志千 男 1001 6000.00 [11rows]
三、分组数据
4、HAVING子句
当同时包含WHERE子句、GROUP BY子句、HAVING子句及聚集函数时,执行 顺序如下: (1)执行WHERE子句查找符合条件的数据; (2)使用GROUP BY子句对数据进行分组; (3)对GROUP BY子句形成的组运行聚集函数计算每一组的值; (4)最后使用HAVING子句去掉不符合条件的组。
一、排序数据
5、空值的处理
当按照某一列进行排序,而该列包含有空值时,就涉及到空值的处理。 SQL中指出:当排序遇到空值时,空值大于或小于所有非空值。并没有明确规 定应该是大于还是小于。不同的数据库系统可能采取不同的处理。 如微软的SQL Server中,空值小于所有非空值。而Oracle中,空值大于 所有非空值。
第6章 数据的排序,聚集和分组
重点内容:
• 排序数据
• 聚集数据 • 分组数据
一、排序数据