python爬虫的例子
Python网络爬虫入门实战(爬取最近7天的天气以及最高最低气温)
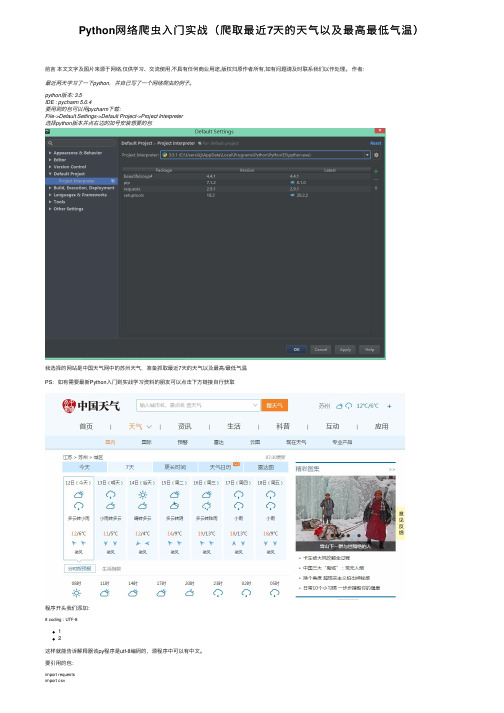
Python⽹络爬⾍⼊门实战(爬取最近7天的天⽓以及最⾼最低⽓温)前⾔本⽂⽂字及图⽚来源于⽹络,仅供学习、交流使⽤,不具有任何商业⽤途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:最近两天学习了⼀下python,并⾃⼰写了⼀个⽹络爬⾍的例⼦。
python版本: 3.5IDE : pycharm 5.0.4要⽤到的包可以⽤pycharm下载:File->Default Settings->Default Project->Project Interpreter选择python版本并点右边的加号安装想要的包我选择的⽹站是中国天⽓⽹中的苏州天⽓,准备抓取最近7天的天⽓以及最⾼/最低⽓温PS:如有需要最新Python⼊门到实战学习资料的朋友可以点击下⽅链接⾃⾏获取程序开头我们添加:# coding : UTF-812这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中⽂。
要引⽤的包:import requestsimport csvimport randomimport timeimport socketimport http.client# import urllib.requestfrom bs4 import BeautifulSoup12345678requests:⽤来抓取⽹页的html源代码csv:将数据写⼊到csv⽂件中random:取随机数time:时间相关操作socket和http.client 在这⾥只⽤于异常处理BeautifulSoup:⽤来代替正则式取源码中相应标签中的内容urllib.request:另⼀种抓取⽹页的html源代码的⽅法,但是没requests⽅便(我⼀开始⽤的是这⼀种)获取⽹页中的html代码:def get_content(url , data = None):header={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, sdch','Accept-Language': 'zh-CN,zh;q=0.8','Connection': 'keep-alive','User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'}timeout = random.choice(range(80, 180))while True:try:rep = requests.get(url,headers = header,timeout = timeout)rep.encoding = 'utf-8'# req = urllib.request.Request(url, data, header)# response = urllib.request.urlopen(req, timeout=timeout)# html1 = response.read().decode('UTF-8', errors='ignore')# response.close()break# except urllib.request.HTTPError as e:# print( '1:', e)# time.sleep(random.choice(range(5, 10)))## except urllib.request.URLError as e:# print( '2:', e)# time.sleep(random.choice(range(5, 10)))except socket.timeout as e:print( '3:', e)time.sleep(random.choice(range(8,15)))except socket.error as e:print( '4:', e)time.sleep(random.choice(range(20, 60)))except http.client.BadStatusLine as e:print( '5:', e)time.sleep(random.choice(range(30, 80)))except http.client.IncompleteRead as e:print( '6:', e)time.sleep(random.choice(range(5, 15)))return rep.text# return html_text12345678910111213141516171819202122232425262728293031323334353637383940414243header是requests.get的⼀个参数,⽬的是模拟浏览器访问header 可以使⽤chrome的开发者⼯具获得,具体⽅法如下:打开chrome,按F12,选择network重新访问该⽹站,找到第⼀个⽹络请求,查看它的headertimeout是设定的⼀个超时时间,取随机数是因为防⽌被⽹站认定为⽹络爬⾍。
Python网络爬虫在环境保护领域的应用案例

Python网络爬虫在环境保护领域的应用案例随着现代技术的快速发展,网络爬虫已成为信息获取和处理的重要工具之一。
在环境保护领域,Python网络爬虫的运用也逐渐得到了广泛应用。
本文将通过介绍几个具体的案例,展示Python网络爬虫在环境保护领域的重要作用。
一、大气污染监测大气污染对人类健康和环境造成了严重的影响。
为了及时准确地掌握大气污染状况,许多机构开始使用Python网络爬虫技术收集相关数据。
举个例子,某地的环境保护局想要研究该地区的大气污染情况,他们可以使用Python网络爬虫从相关网站上抓取大气监测站的数据。
通过分析这些数据,他们可以得出该地区的大气污染情况及其变化趋势,从而制定相应的环境保护策略。
二、水质监测水质是人类生活和生态系统的重要组成部分。
为了及时监测水质状况,许多水利和环境保护机构也开始利用Python网络爬虫技术获取水质数据。
例如,某地的水务局需要了解该地区各个水域的水质情况。
他们可以通过编写Python爬虫程序,从相关网站上抓取水文监测站的数据。
通过对这些数据的分析,他们可以了解水体的污染程度、水质变化趋势,并采取相应的措施来改善水环境。
三、环境事件监测除了大气和水质监测外,Python网络爬虫还可以用于监测环境事件。
例如,森林火灾、水灾、地质灾害等,都对环境和人类造成了巨大的威胁。
爬取相关新闻网站上发布的新闻和事件数据,可以及时了解并监测这些环境事件。
借助Python网络爬虫的高效性和自动化功能,环保部门可以更加准确地预测和响应这些事件,确保人民生命财产的安全,减少环境灾害对生态系统的破坏。
总结:通过以上案例的介绍,我们可以清楚地看到Python网络爬虫在环境保护领域中的重要作用。
它不仅能够高效地获取各种环境数据,还能对这些数据进行分析和处理。
这使得环境保护部门能够更好地了解环境状况,及时采取措施保护环境,减少环境污染。
然而,需要注意的是,在利用Python网络爬虫获取数据时,必须遵守相关法律法规和网站的使用规定,不得进行非法抓取和滥用数据。
python 爬虫常规代码

python 爬虫常规代码Python爬虫常规代码是指用Python编写的用于网页数据抓取和提取的代码。
爬虫是一种自动化程序,可以模拟人类在网页浏览器中的行为,从而获取所需的信息。
在这篇文章中,我们将一步一步地回答关于Python 爬虫常规代码的问题,帮助读者了解如何编写自己的爬虫程序。
第一步:安装Python和必要的库首先,我们需要安装Python和一些必要的库来编写爬虫代码。
Python 是一种流行的编程语言,可以用于开发各种应用程序,包括爬虫。
对于Python的版本,我们建议使用Python 3.x。
然后,我们需要安装一些常用的爬虫库,例如requests和beautifulsoup4。
可以使用pip命令来安装它们:pip install requestspip install beautifulsoup4第二步:发送HTTP请求在编写爬虫代码之前,我们首先需要发送HTTP请求以获取网页的内容。
这可以使用requests库来实现。
以下是一个简单的例子:pythonimport requestsurl = "response = requests.get(url)if response.status_code == 200:content = response.textprint(content)在这个例子中,我们首先指定了要访问的URL,然后使用requests库的get方法发送一个GET请求。
如果响应的状态码是200,表示请求成功,我们就可以从response对象中获取网页内容,并打印出来。
第三步:解析网页内容获取网页的原始内容后,我们通常需要解析网页,提取所需的信息。
这可以使用beautifulsoup4库来实现。
下面是一个示例:pythonfrom bs4 import BeautifulSoup# 假设content是之前获取的网页内容soup = BeautifulSoup(content, "html.parser")# 使用soup对象进行解析在这个例子中,我们首先导入了BeautifulSoup类并创建了一个soup对象,该对象将用于解析网页内容。
Python网络爬虫在物联网领域的应用案例

Python网络爬虫在物联网领域的应用案例物联网(Internet of Things,简称IoT)是指通过互联网将各种智能设备、传感器和物理对象连接在一起,实现信息的互通和资源的共享。
物联网的兴起为各行各业带来了无限的潜力和机会。
而Python作为一门强大的编程语言,其网络爬虫功能在物联网领域中也发挥着重要的作用。
本文将介绍几个Python网络爬虫在物联网领域的应用案例,以展示其在实际应用中的价值。
案例一:环境监测数据采集在物联网中,环境监测是一个重要的应用领域。
通过传感器采集环境数据,可以帮助我们监测和控制空气质量、水质、噪声等环境指标。
而Python网络爬虫可以帮助我们从各个数据源采集环境数据,并进行分析和处理。
比如,我们可以编写一个网络爬虫程序,定时从气象局网站获取实时的天气数据,并将数据存储到数据库中。
这样,我们就可以实时监测各个地区的天气情况,并做出相应的决策。
案例二:智能家居设备控制智能家居是物联网领域中的一个典型应用。
通过连接各种家居设备和家居电器,我们可以实现对家居环境的智能化控制。
而Python网络爬虫可以帮助我们从各种设备供应商的网站上爬取设备控制指令,并通过互联网将指令发送到对应的设备上。
例如,我们可以编写一个网络爬虫程序,从智能灯泡供应商的网站上获取灯泡的亮度控制指令,并将指令发送到家中的智能灯泡上,实现对灯光的远程控制。
案例三:物流数据分析物联网在物流领域中有着广泛的应用。
通过物联网技术,我们可以实时监控货物的位置、温度、湿度等指标,并通过数据分析对物流过程进行优化和改进。
而Python网络爬虫可以帮助我们从快递公司的网站上爬取货物运输信息,并将数据存储到数据库中。
这样,我们可以实时获取货物的运输状态,并通过数据分析找出潜在的问题和改进的方向。
通过以上几个案例的介绍,我们可以看到Python网络爬虫在物联网领域中的广泛应用。
它可以帮助我们从各个数据源获取实时的环境数据、设备控制指令和物流信息,并通过数据分析和处理,为我们提供更好的决策依据和优化方案。
python爬虫应用案例

python爬虫应用案例Python爬虫应用案例一、前言随着互联网的发展,网络上的信息越来越多,人们需要获取这些信息。
而Python爬虫技术的出现,为人们获取网络信息提供了更加便捷和高效的方法。
本文将介绍一个基于Python爬虫技术的应用案例。
二、案例背景某公司需要收集竞争对手在某电商平台上销售的商品信息,包括商品名称、价格、销量等数据,并进行分析和比较。
由于竞争对手数量较多,手动收集数据成本较高且效率低下,因此需要使用爬虫技术进行自动化数据采集。
三、实现步骤1. 分析目标网站结构首先需要分析目标网站结构,确定需要采集的数据内容以及其所在页面位置和HTML标签名称。
通过浏览器开发者工具可以查看页面源代码,并根据HTML标签名称和CSS选择器确定需要采集的数据内容。
2. 编写爬虫程序根据分析结果编写Python爬虫程序。
可以使用第三方库如Requests、BeautifulSoup等来实现HTTP请求和HTML解析功能。
具体步骤如下:(1)发送HTTP请求获取页面内容;(2)使用BeautifulSoup解析HTML页面并提取所需数据;(3)将数据存储到本地文件或数据库中。
3. 实现自动化采集为了实现自动化采集,可以使用Python的定时任务模块进行定时执行爬虫程序。
也可以使用多线程或多进程技术提高爬虫程序的效率。
四、技术难点及解决方案1. 网站反爬虫机制为了防止爬虫程序对网站造成过大的访问负载,一些网站会设置反爬虫机制,如IP封锁、验证码等。
为了应对这种情况,可以使用代理IP、用户代理等技术来隐藏访问来源,或者使用OCR识别技术来自动识别验证码。
2. 数据量过大导致程序崩溃在进行大规模数据采集时,可能会出现数据量过大导致程序崩溃的情况。
为了避免这种情况,可以使用分布式爬虫技术将任务分散到多个节点上执行,从而提高系统的稳定性和效率。
五、应用效果通过使用Python爬虫技术进行竞争对手商品信息采集,并结合数据分析和比较工具进行分析处理后,该公司成功地发现了一些市场机会和潜在风险,并及时调整了营销策略,提高了企业的竞争力和盈利能力。
Python网络爬虫的数据采集与分析案例分享

Python网络爬虫的数据采集与分析案例分享随着互联网的快速发展,数据成为了当今社会的一项重要资源。
而网络爬虫作为一种自动化工具,能够帮助我们从互联网上获取大量的数据,为我们的数据分析提供了很大的便利。
本文将分享几个实际案例,演示如何使用Python网络爬虫进行数据采集与分析。
案例一:天气数据采集与分析在实际生活中,我们经常需要了解天气情况以便做出相应的安排。
而许多网站提供了天气预报的信息,我们可以使用Python爬虫库来获取这些数据。
通过分析历史天气数据,我们可以揭示出一些有趣的趋势和规律,如某地区的季节性变化、气温变化趋势等。
这些数据可以帮助我们做出更准确的天气预测和决策。
案例二:股票数据采集与分析股票市场一直是人们关注的焦点,而股票数据的采集和分析对于投资者来说尤为重要。
我们可以使用Python爬虫从金融网站获取股票的实时价格、历史数据和相关新闻等信息。
通过分析这些数据,我们可以发现股票价格的波动规律,预测趋势,制定相应的投资策略,提高投资收益。
案例三:舆情数据采集与分析舆情分析是一种通过网络爬虫收集大众言论,并对其进行情感分析和主题分析的方法。
舆情分析可以用于政府决策、企业品牌建设、新闻报道等方面。
我们可以使用Python爬虫从社交媒体平台、论坛等网站上获取公众对某个事件、产品或者品牌的评论和评价。
通过情感分析和主题分析,我们可以了解到大众的看法和反应,为决策提供参考。
案例四:电影数据采集与分析电影作为一种重要的文化载体,一直受到人们的喜爱。
我们可以使用Python爬虫从电影评价网站获取电影的评分、评论、导演等信息。
通过分析这些数据,我们可以了解到观众对于不同类型电影的喜好、各个导演的特点等。
这些信息对于电影业的发展和电影推荐系统的建立都具有重要意义。
综上所述,Python网络爬虫是一种强大的工具,通过它我们能够方便地从互联网上获取各种数据资源。
在数据采集的基础上,我们可以对这些数据进行深入的分析,揭示出一些有价值的信息和规律,为决策和研究提供帮助。
Python网络爬虫技术在农业大数据分析中的应用案例

Python网络爬虫技术在农业大数据分析中的应用案例农业是国民经济的重要支柱产业,而大数据分析正逐渐成为农业科技进步的重要手段。
随着互联网的普及和发展,Python网络爬虫技术得以广泛应用于农业领域,为农业大数据分析提供了有效的数据获取途径。
本文将介绍几个Python网络爬虫技术在农业大数据分析中的应用案例。
一、天气数据采集农业生产对气象因素具有很高的依赖性,而天气数据是农业决策与生产管理的重要参考依据。
利用Python网络爬虫技术,可以从各大气象网站上自动获取实时天气数据,并进行数据清洗和分析。
例如,可以爬取全国各地的温度、降雨量、湿度等数据,对农作物的生长环境进行评估和预测。
二、市场行情数据获取农业产品的市场行情对农民的收入和农产品的供应链管理有着重要影响。
Python网络爬虫技术可以通过爬取各大农产品市场网站或电商平台的数据,实时获取农产品的价格和交易信息。
这些数据可以为农民提供决策参考,帮助他们灵活调整种植计划,以适应市场需求变化。
三、病虫害监测与预测病虫害是农作物生产中的常见问题,对减产甚至农作物死亡造成严重影响。
利用Python网络爬虫技术,可以收集各地病虫害监测站的数据,实时获取病虫害的发生情况。
通过对这些数据进行分析和建模,可以预测病虫害的发展趋势和帮助制定相应防治措施,提高农作物的产量和质量。
四、土壤质量评估土壤是农作物生长的基础,而土壤质量对农作物的产量和品质有着直接影响。
通过采集并分析土壤样本,可以评估土壤的有机质含量、养分含量、酸碱度等指标。
Python网络爬虫技术可以帮助快速获取各个农业研究机构或监测站点的土壤质量数据,提供农民合理施肥和土壤改良的依据。
五、农业政策与法规分析农业政策与法规对农业生产和经营管理具有重要影响。
Python网络爬虫技术可以用于抓取国家和地方政府网站上发布的农业政策和法规文件,提供给农民、农业企业和农业研究机构参考和分析。
这些数据可以帮助农业从业者了解最新的政策变化,及时调整经营策略,提高农业生产效率。
python3.5爬虫基础urllib实例

python3.5爬⾍基础urllib实例python3.5不同于python2.7,在python3.5中,编写爬⾍⼩程序,需要安装模块urllib下的request和parse类⼩程序1:编写脚本,⽤来实现抓取百度贴吧指定页⾯1import urllib.parse #主要⽤来解析url2import urllib.request #主要⽤于打开和阅读url3import os,re4import urllib.error #⽤于错误处理56print("模拟抓取百度贴吧python和java页⾯,并写⼊指定路径⽂件")78def tieba_baidu(url,l):9#伪装成浏览器10 header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'}11for i in range(len(l)):12 file_name="G:/test/"+l[i]+".html"13print("正在下载"+l[i]+"页⾯,并保存为"+file_name)14 m=urllib.request.urlopen(url+l[i],headers=header).read()15 with open(file_name,"wb") as file:16 file.write(m)1718if__name__=="__main__":19 url="/f?kw="20 l_tieba=["python","java","c#"]21 tieba_baidu(url,l_tieba)⼩程序⼆:爬取指定页⾯指定格式的⽂件(本例⼦爬取指定页⾯的jpg⽂件)1print("爬取指定页⾯的jp格式的⽂件")2def baidu_tieba(url,l):3"""4根据传⼊的地址和关键字列表进⾏图⽚抓取5"""6for i in range(len(l)):7 count=18 file_name="G:/test/"+l[i]+".html"9print("正在下载"+l[i]+"页⾯,并保存为"+file_name)10 m=urllib.request.urlopen(url+l[i]).read()11#创建⽬录保存每个⽹页上的图⽚12 dirpath="G:/test/"13 dirname=l[i]14 new_path=os.path.join(dirpath,dirname)15if not os.path.isdir(new_path):16 os.makedirs(new_path)1718 page_data=m.decode()19 page_image=pile('<img src=\"(.+?)\"') #匹配图⽚的pattern20for image in page_image.findall(page_data):#page_image.findall(page_data)⽤正则表达式匹配所有的图⽚21 pattern=pile(r'http://.*.jpg$') #匹配jpg格式的⽂件22if pattern.match(image): #如果匹配,则获取图⽚信息,若不匹配,进⾏下⼀个页⾯的匹配23try:24 image_data=urllib.request.urlopen(image).read() #获取图⽚信息25 image_path=dirpath+dirname+"/"+str(count)+".jpg"#给图⽚命名26 count+=127print(image_path) #打印图⽚路径28 with open(image_path,"wb") as image_file:29 image_file.write(image_data) #将图⽚写⼊⽂件30except urllib.error.URLError as e:31print("Download failed")32 with open(file_name,"wb") as file: #将页⾯写⼊⽂件33 file.write(m)3435if__name__=="__main__":36 url="/f?kw="37 l_tieba=["python","java","c#"]38 baidu_tieba(url,l_tieba)注:1、要爬取某个页⾯的⽂件,必须⽤urllib.request.urlopen打开页⾯的连接,并⽤read⽅法读取页⾯的html内容2、要爬取某些具体内容,必须分析该页⾯对应的html代码,找到需爬取内容所在位置的标签,利⽤正则表达式获取标签3、浏览器伪装:为了防⽌有些⽹站拒绝爬⾍,我们需要伪装成浏览器来实现页⾯的爬取,即需要添加头部⽂件来伪装成浏览器header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'}4、规范:爬取的内容尽量写⼊到某个⽂件,如果直接打印在控制台,影响阅读效果;5、致谢:上⽂⼩例⼦亲测通过,但具体思路借鉴某位⼤神,但是地址找不到了,⽆法分享给⼤家~。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python爬虫的例子
Python爬虫的例子
爬虫技术是在网络上自动获取数据的一种方法,可以用于获取各种类型的数据。
在本篇文章中,我们将介绍Python爬虫的例子,以及一步一步解释如何实现一个简单的爬虫程序。
第一步:导入所需的库
在Python中,有几个非常有用的库可以帮助我们实现爬虫功能。
我们将使用其中的两个库:requests和BeautifulSoup。
python
import requests
from bs4 import BeautifulSoup
第二步:发送网络请求
要获取网页上的数据,我们首先需要发送一个HTTP请求。
在这个例子中,我们将使用requests库发送get请求,并将响应对象存储在变量response中。
python
url = "
response = requests.get(url)
第三步:解析网页内容
获得响应后,我们需要解析网页内容以提取所需的数据。
为此,我们将使用BeautifulSoup库。
首先,我们创建一个BeautifulSoup对象,并将响应的文本传递给它。
python
soup = BeautifulSoup(response.text, 'html.parser')
第四步:提取数据
接下来,我们可以使用BeautifulSoup的各种方法和属性来提取所需的数据。
这些方法和属性可以根据不同的网页结构和需求而有所不同。
以下是一个简单的例子,假设我们想要提取网页中的所有标题:
python
titles = soup.find_all('h1')
for title in titles:
print(title.text)
在这个例子中,我们使用了BeautifulSoup的find_all方法来查找所有的'h1'标签,并使用text属性来提取标签内的文本。
第五步:保存数据
一旦我们提取到所需的数据,我们可以将其保存到本地或进行其他处理。
下面是一个简单的例子,我们将提取的标题保存到一个文本文件中。
python
with open('titles.txt', 'w') as file:
for title in titles:
file.write(title.text + '\n')
在这个例子中,我们使用open函数创建一个名为'titles.txt'的文本文件,并使用write方法将标题逐行写入文件。
第六步:异常处理
在进行网络请求和解析网页内容的过程中,可能会出现各种错误。
为了确保我们的程序可以正常运行,我们需要添加适当的异常处理机制。
以下是一个简单的例子,捕获并处理可能出现的异常。
python
try:
response = requests.get(url)
response.raise_for_status()
except requests.exceptions.HTTPError as errh:
print("HTTP error:", errh)
except requests.exceptions.ConnectionError as errc:
print("Error connecting:", errc)
except requests.exceptions.Timeout as errt:
print("Timeout error:", errt)
except requests.exceptions.RequestException as err:
print("Error:", err)
在这个例子中,我们使用try/except结构来捕获不同类型的异常,并打印
错误消息。
总结:
通过以上步骤,我们可以实现一个简单的Python爬虫程序。
当然,实际的爬虫程序可能更为复杂,需要考虑各种不同的情况和需求。
但是,掌握了这些基本概念和技巧后,你就可以根据具体的需求进行进一步的学习和应用。
注意:在实际的爬虫过程中,请遵守网站的规则和法律法规,以确保合法、道德和公正的使用爬虫技术。