SPSS实验报告册
【精品】spss实验报告

【精品】spss实验报告
本报告主要研究了SPSS实验的结果。
通过对原始数据的收集、预处理、描述性统计信息和统计图分析,讨论了实验结果。
首先,本文进行了实验数据的收集,共收集了100个实验样本。
收集的数据包括以下几个变量:性别(男士/女士),年龄,收入和教育水平。
收集的数据将交给SPSS模型进行处理。
其次,进行了数据的预处理,包括数据的清洗、缺失值的处理和异常值的处理等。
根据数据的性质,进行了适当的数据转换。
第三,计算了一些描述性统计信息,如数据中变量的平均数、标准差、最小值和最大值等。
然后,使用绘图功能绘制出直方图,用于描述数据中变量的分布情况。
箱线图用于刻画变量的离散程度,并可以汇总和识别变量的一些特征。
最后,进行多元统计分析,如相关性分析、回归分析等,以深入研究不同变量之间的关系。
总之,通过对SPSS实验的有效处理,可以得出数据属性、分布特征、变量关系等有效结果,有助于对实践事件做出正确判断,并且在改进实验步骤时也可以添加核心变量,从而得到更准确的结果。
SPSS实验报告完整版
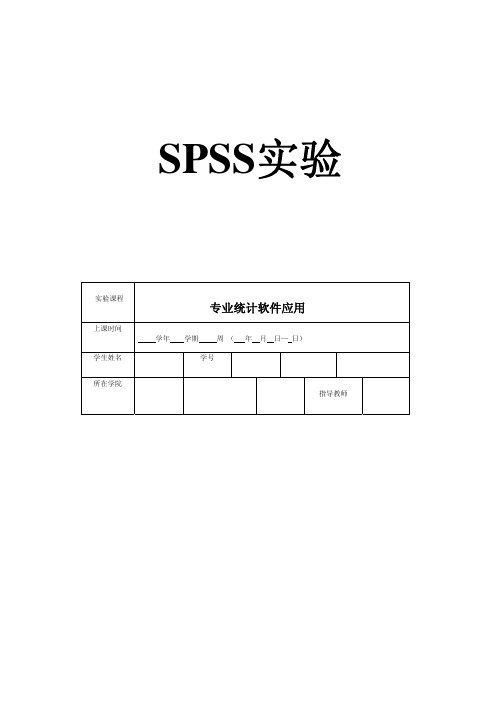
SPSS实验实验课程专业统计软件应用上课时间学年学期周(年月日—日)学生姓名学号所在学院指导教师第五章第一题通过样本分析,结果如下图One-Sample StatisticsN Mean Std. Deviation Std. Error Mean 成绩27 77.9312.111 2.331One-Sample TestTest Value = 70t df Sig. (2-tailed)Mean Difference 95% Confidence Interval of theDifferenceLower Upper成绩 3.400 26.0027.926 3.13 12.72从图看出,sig=0.002,小于0.05,因此本班平均成绩与全国平均成绩70分有显著性差异。
第五章第二题通过独立样本分析,结果如下图Group Statistics成绩N Mean Std. Deviation Std. Error Mean成绩1=男10 84.0011.528 3.6450=女10 62.9018.454 5.836Independent Samples TestLevene's Test forEquality of Variances t-test for Equality of MeansF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifference95% Confidence Interval of theDifferenceLower Upper成绩Equalvariancesassumed1.607.221 3.06718.007 21.100 6.881 6.64435.556Independent Samples TestLevene's Test forEquality of Variances t-test for Equality of MeansF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifference95% Confidence Interval of theDifferenceLower Upper成绩Equalvariancesassumed1.607.221 3.06718.007 21.100 6.881 6.64435.556Equalvariancesnotassumed3.06715.096.008 21.100 6.881 6.44235.758在显著性水平为0.05的情况下,t统计量的概率p为0.007,故拒绝零假设,既两样本的均值不相等,既男女生成绩有显著性差异。
SPSS实验报告册

《SPSS统计软件应用》实验报告册20 13 ——20 14 学年第一学期班级:学号:姓名:实验教师:实验学时:实验组号:目录实验一SPSS的数据管理 (1)实验二描述性统计分析 (13)实验三均值检验 (21)实验四相关分析 (27)实验五方差分析 (34)实验六绘制统计图 (40)实验七因子分析 (44)实验八聚类分析 (48)实验九判别分析 (58)实验十回归分析 (67)实验十一非参数检验 (75)实验一 SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表实验步骤:(1)打开定义变量的界面启动SPSS,进入主界面,单击图6-2所示的屏幕左下角的“Variable View”选项卡,打开定义变量的表格。
(2)输入变量名,符合变量的命名规则在“Name”列的第一个单元格输入第一个变量名,如“xm”。
(3)确定变量类型,单击“Type”列的第一个单元格,如图6-3所示,SPSS的默认变量类型为数值型。
单击数值型变量后的“”,弹出如图6-4所示的对话框,用户可以从该对话框中选择其他的变量类型。
(4)设置字段值(5)依次按要求输入完毕即可。
结果如下:2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。
spss对数据进行相关性分析实验报告

spss对数据进行相关性分析实验报告一、实验目的与背景在统计学的研究中,相关性分析是一种常见的分析方法,用于研究两个或多个变量之间的关联程度。
本实验旨在使用SPSS软件对收集到的数据进行相关性分析,并探索变量之间的关系。
二、实验过程1. 数据收集:根据研究目的,我们收集了一份包含多个变量的数据集。
其中,变量包括A、B、C等。
2. 数据准备:在进行相关性分析之前,我们需要对数据进行准备。
首先,我们载入数据集到SPSS软件中。
然后,对于缺失数据,我们根据需要采取相应的填补或删除策略。
接着,我们进行数据的清洗和整理,以确保数据的准确性和一致性。
3. 相关性分析:使用SPSS软件,我们可以轻松地进行相关性分析。
在SPSS的分析菜单中,选择相关性分析功能,并设置相应的参数。
我们将选择Pearson相关系数,该系数用于衡量两个变量之间的线性相关关系。
此外,还可以选择其他类型的相关系数,如Spearman相关系数,用于非线性关系的探索。
设置参数后,我们点击“运行”按钮,即可得到相关性分析的结果。
4. 结果解读:SPSS将为我们提供一份详细的结果报告。
我们可以看到每对变量之间的相关系数及其显著性水平。
如果相关系数接近1或-1,并且P值低于显著性水平(通常为0.05),则可以得出两个变量之间存在显著的线性相关关系的结论。
此外,我们还可以通过散点图、线性回归等方法进一步分析相关性结果。
5. 结论与讨论:根据相关性分析的结果,我们可以得出结论并进行讨论。
如果发现两个变量之间存在显著的相关关系,我们可以进一步探究其原因和意义。
同时,我们还可以提出假设并设计更深入的实验,以验证和解释这些相关性。
三、结果与讨论根据我们的研究目的和数据集,通过SPSS软件进行的相关性分析显示了一些有意义的结果。
我们发现变量A与变量B之间存在显著的正相关关系(Pearson相关系数为0.7,P<0.05)。
这表明随着A的增加,B也会相应增加。
SPSS期末综合实验报告

SPSS期末综合实验报告姓名:学号:成绩:(附:本实验报告基于SPSS 20.0)一、用“SUMMARIZE CASES”作一个分组比较【1】点击【分析】——【报告】——【个案汇总】菜单项,弹出“摘要个案”对话框,设置如下:【2】点击【确定】,输出结果,整理后得三线表,如下:个案汇总N性别城市学历男北京188 上海221 广州228 Total 637女北京190 上海166 广州154 Total 510从上表可以看出,上海市和广州市的男性比例要高于女性,而在北京市方面,男女之间则差别不大,但同时也要考虑到抽样调查数据中男性和女性的绝对数的大小不同。
二、对某一个变量“选择个案(select)”进行频数分析【1】点击【分析】——【描述统计】——【频率】菜单项,弹出“频率”对话框,设置如下:【2】点击【确定】,输出结果,整理后得三线表,如下:城市频数百分比(%)北京上海广州Total 378 33.0 387 33.7 382 33.3 1147 100.0从上表可以看出,在抽样调查的数据当中,样本中北京市的被调查者有378人,占总数的33.0%,样本中上海市的被调查者有387人,占总数的33.7%,样本中广州市的被调查者有382人,占总数的33.3%,因此,在误差允许的范围内,可以认为抽样是相对均匀的。
三、对某一个变量进行重新分组(recode)【1】点击【转换】——【重新编码为不同变量】,弹出“重新编码为不同变量”对话框,设置如下:【2】点击【更改】后,如上图,点击【旧值和新值】,弹出如下对话框,依次设置如下:【3】点击【继续】——【确定】可得如下效果,变量视图:四、对某两个定类变量进行卡方检验【1】点击【分析】——【描述统计】——【交叉表】菜单项,弹出“交叉表”对话框,如图所示:【2】在“行”列表框中选入“家庭收入2级Ts9”;在“列”列表框中选入“是否拥有家用轿车O1”,如图所示:【3】单击【单元格】,弹出“单元显示”对话框,选中“行百分比”复选框;如图:【4】单击【继续】,再单击【统计量】,弹出“统计量”对话框,选中“卡方”复选框,如图:【5】单击【继续】——【确定】,得到输出结果,整理后得三线表,如下:Ⅰ交叉表:家庭收入2级 * 是否拥有家用轿车Crosstabulation是否拥有家用轿车有没有家庭收入2级Below 48,000Count% within 家庭收入2级32 3039.6% 90.4%Over 48,000Count 225 429% within 家庭收入2级34.4% 65.6% TotalCount 257 732% within 家庭收入2级26.0% 74.0%Ⅰ由交叉表可知低收入家庭中只有9.6%拥有轿车,而中高收入家庭中有34.4%拥有轿车,样本数据差异明显,但该差异是否具有统计学意义尚需检验,卡方检验结果如下表。
SPSS的相关分析实验报告
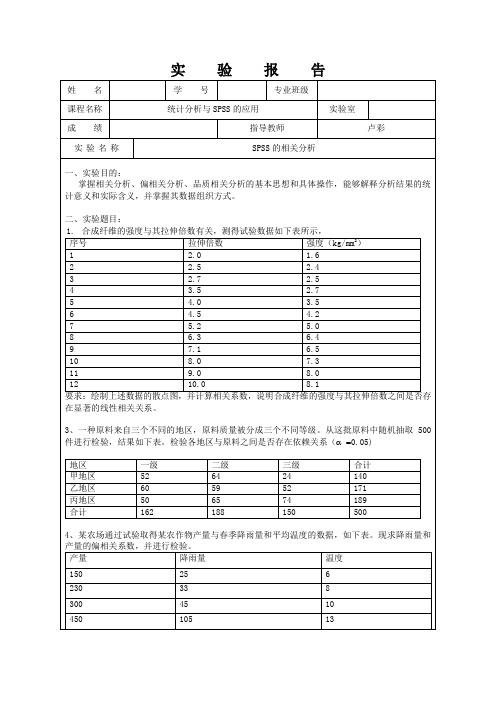
第三题:
1打开SPSS软件,建立不同地区不同质量原料数据的文件,并保存为“数据二.sav”,如图
2选择菜单:【Analyze】→【Descriptive Statistics】→【Crosstabs】,将“地区”选入行变量,将“原料质量”选入列变量,在Cells和Statistics中选择需要计算的检验方式。
实验报告
姓名
学号
专业班级
课程名称
统计分析与SPSS的应用
实验室
成绩
指导教师
卢彩
实验名称
SPSS的相关分析
一、实验目的:
掌握相关分析、偏相关分析、品质相关分析的基本思想和具体操作,能够解释分析结果的统计意义和实际含义,并掌握其数据组织方式。
二、实验题目:
1.合成纤维的强度与其拉伸倍数有关,测得试验数据如下表所示,
3、一种原料来自三个不同的地区,原料质量被分成三个不同等级。从这批原料中随机抽取500件进行检验,结果如下表。检验各地区与原料之间是否存在依赖关系(0.05)
地区
一级
二级
三级
合计
甲地区
52
64
24
140
乙地区
60
59
52
171
丙地区
50
65
74
189
合计
162
188
150
500
4、某农场通过试验取得某农作物产量与春季降雨量和平均温度的数据,如下表。现求降雨量和产量的偏相关系数,并进行检验。
产量
降雨量
温度
150
SPSS报告册

《SPSS统计软件应用》报告册20 15 - 20 16 学年第 1 学期班级:学号:姓名:实验教师:学时: 2周目录1.实验一 SPSS的数据管理2.实验二描述性统计分析3.实验三均值检验4.实验四相关分析5.实验五方差分析6.实验六统计图7.实验七因子分析8.实验八聚类分析9.实验九回归分析10.实验十判别分析11.实验十一非参数检验实验一SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表实验步骤:(1)首先ssps统计分析软件,(2)然后新建一个文件,点击左下角“变量视图”,(3)然后依据所给表格创建字段,如“姓名”、“性别”等。
在输入每个名称字段时,(4)对其类型和宽度等限制条件按要求分别限制指即可。
实验结果及分析:实验结果如下图最终建成了所要的表格。
2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。
少数民族考生加20分,西部考生加10分。
(4)对参加过省以上竞赛并取得三等奖以上名次的考生,每项加10分。
(5)文化课成绩和加分总和构成综合分,录取综合排名为前7名的学生。
练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验步骤:(1)计算文化课总成绩: 打开数据文件compute.sav.变量计算:点击“转换”——“计算变量”,定义变量总分,目标变量中的值设为“总分”,数字表达式设置“语文+数学+英语+综合”,单击“确定”按钮。
《SPSS统计软件应用》 报告册

《SPSS统计软件应用》报告册20 - 20 学年第学期班级:学号:姓名:实验教师:学时:目录:实验一、SPSS数据文件的建立和管理 (3)实验二、数据预处理 (5)实验三、基本统计分析 (8)实验四、参数检验 (11)实验五、方差分析 (15)实验六、非参数检验 (21)实验七、相关分析 (25)实验八、回归分析 (30)实验九、聚类分析 (36)实验十、因子分析 (43)实验一、SPSS数据文件的建立和管理一、实验目的了解SPSS的基本操作环境,理解SPSS进行数据分析的基本步骤,掌握SPSS数据录入与编辑的方法,掌握SPSS的数据管理的相关功能。
二、实验内容大学生基本情况调查问卷1、性别 A.男 B.女2、您现在是大学几年级?A.大一 B.大二 C.大三 D.大四3、您所在学院?4、您的出生日期?5、在大学里,您是否学习过双语课程? A.是 B.否6、您参加了学校哪些社团?(多选)A.文艺社团B.体育社团C.读书社団D.公益社团E.创业社团7、您本学期选修课的门数?A.0 B.1 C.2 D.3 E.4门以上8、您的月平均消费?A.300元以下B.300-400C.400-500D.500-600E.600以上9、您对自己在大学里的表现满意程度如何?A.非常满意B.比较满意C.满意D.不太满意E.不满意10、您认为最受欢迎的老师应该具有哪些特点?要求:根据问卷建立SPSS数据文件,文件名为:大学生基本情况调查问卷.sav。
至少录入2条数据。
三、实验关键步骤1、定义变量图1.1变量视图窗口2、录入数据图1.2 录入数据窗口3、保存数据保存路径及文件名如下:图1.3保存数据四、结果分析(手写)实验二、数据预处理一、实验目的掌握利用SPSS的“数据”菜单和“转换”菜单提供的相关功能实现数据的预处理,为后续的数据分析做准备。
二、实验内容某年级确定学生奖学金等级,制定了如下规则:1、学生如果有违纪,不能获得奖学金。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《SPSS统计软件应用》实验报告册20 - 20 学年第学期班级:学号:姓名:授课教师:实验教师:实验学时:实验组号:目录实验一SPSS的数据管理 (3)实验二描述性统计分析 (5)实验三均值检验 (6)实验四相关分析 (7)实验五因子分析 (8)实验六聚类分析 (11)实验七回归分析 (13)实验八判别分析 (14)实验一SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容及步骤:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
表1 大学教师基本情况调查表1.定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
实验步骤:(1)、打开定义变量的界面启动SPSS,进入主界面,单击图6-2所示的屏幕左下角的“Variable View”选项卡,打开定义变量的表格。
(2)、输入变量名,符合变量的命名规则在“Name”列的第一个单元格输入第一个变量名,如:“xm”。
(3)、确定变量类型,单击“Type”列的第一个单元格,如图6-3所示,SPSS的默认变量类型为数值型。
单击数值型变量后的“···”,弹出如图6-4所示的对话框,用户可以从该对话框中选择其他的变量类型。
(4)、设置字段值(5)、依次按要求输入完毕即可实验结果:实验分析:本实验,主要是按照要求一步一步来设置条件即可完满完成实验。
2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。
少数民族考生加20分,西部考生加10分。
(4)对参加过省以上竞赛并取得三等奖以上名次的考生,每项加10分。
(5)文化课成绩和加分总和构成综合分,录取综合排名为前7名的学生。
练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验内容:2.高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验步骤:(1)计算文化课总成绩: 打开数据文件compute.sav.变量计算transform->compute,在弹出的compute variable对话框中,定义变量zcj, type&label中的label值设为“文化课总成绩”,numberic expression 设置“语文+数学+英语+综合”,单击ok按钮。
(2)筛选出400分以上并且没有不良记录的学生:date-select case ,在弹出的对话框中选择if condition is satisfied 单选按钮并单击if 按钮,在弹出的select case :if 对话框中,设置不良记录=0 & zcj>=400的判断条件,单击continue,选择deleted单选按钮,最后单击ok 。
(3)计算西部考生和少数名族加分项:transform->compute,target variable 选择zcj。
if 条件中设置“名族=2 or 名族=3 or 民族=4”,numberic expression中zcj+20;If 条件中设置“名族=5”numberic expression中设置zcj+10(4)计算最综成绩,并排序:transform->compute,numberic expression ,zcj 奖项*10. 选择“Data→Sort Cases”命令,弹出“Sort Cases”对话框,把“zcj”变量选入“Sort by”中,并在Sort Order中选择“Ascending(降序)”选项,将学生成绩按升序排列,单击“OK”按钮。
实验结果:选取综合成绩升序排列后的前七名即可,如图所示:录取的分别是艾甫尔513分、孙悦婷495分、张囯欣471分、果冻样462分、杨乐451分、高超438分、易仲勃434分。
实验分析:本实验,主要是按照要求一步一步来设置条件,最后边计算有点难,就是算加分。
首先要解决不留空的,不然最后没法求和。
根据结果选出符合要求的即可。
三、实验小结:实验中遇到的问题及解决办法、心得体会等等...本实验,第一小题,主要考察我们创建数据文件的结构,即数据文件的变量和定义变量的属性。
老师上课时给我们演示很到位,在老师的详细讲解下,我熟悉了spss软件界面,以及一些主要组成部分,但是里面的一些具体参数还不太清楚,不过常用主要属性都掌握了,没有太大问题。
第二小问,问题就相当大了,先是选择不小于400分的,经常排除不了,后来在同学的帮助下克服了。
然后在加分部分比较难,最开始先符合一个加一个,但是后来发现不是,经过反复尝试,把需要加分的先列出来,最后汇总,但是没加粉的,我没计算,导致最后求和时,不能加,因为有的是空字符,而不是数字0,后来又经改进,把没有加分的同学,在相对加分位置是-表示,最后才完满完成实验。
实验二描述性统计分析一、实验目的利用SPSS进行描述性统计分析。
要求掌握频数分析(Frequencies过程)、描述性分析(Descriptives过程)、交叉列联表分析(Crosstabs过程)。
二、实验内容及步骤1、打开数据文件descriptives.sav,是从某校选取的3个班级共16名学生的体检列表,要求以班级为单位列表计算年龄,体重和身高的统计量,包括极差,最小最大值,均值,标准差和方差。
给出操作步骤和分析结果。
1)打开数据文件descriptives.sav,选“数据”菜单的“选择个案”命令项,弹出对话框。
选择“如果条件满足”单选按纽,点击“如果”钮,弹出对话框,输入条件:班级=1单击“继续”按纽。
在“输出”栏选择“过滤掉未选定的个案”项,单击“确定”按钮。
2)在主菜单栏单击“分析”,在出现的下拉菜单里移动鼠标至“描述性统计”项上,在出现的次菜单里单击“描述性”项,打开对话框。
从左则的源变量框里选择年龄、体重、身高三个变量进入“变量”框里。
单击“选项”钮,弹出“选项”对话框,选中均值Std.deviation 标准差最小值方差最大值范围复选框,单击“继续”按钮,单击“确定”按钮。
3)2、3班操作类似,只需将条件改为“班级=2”、“班级=3”即可一班二班。
三班:2、某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法治疗效果有无差别三、练习题:1、打开数据文件descriptives.sav,是从某校选取的3个班级共16名学生的体检列表,要求以班级为单位列表计算年龄,体重和身高的统计量,包括极差,最小最大值,均值,标准差和方差。
给出操作步骤和分析结果。
分析:1班年龄的最大值,最小值,平均数最小,方差和标准差最大;体重的极差,最大值,最小值,平均数,方差,标准差都最小;身高的极差,最大值,最小值,平均数,方差,标准差都最小。
2班年龄的最大值,最小值,平均数居中,方差和标准差最小;体重的极差,最大值,最小值,平均数,方差,标准差都居中;身高的极差,最大值,最小值,平均数,方差,标准差都居中3班年龄的最大值,最小值,平均数最大,方差和标准差居中;体重的极差,最大值,最小值,平均数,方差,标准差都最大;身高的极差,最大值,最小值,平均数,方差,标准差都最大。
2、某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法治疗效果有无差别三个变量――行变量、列变量和指示每个格子中频数的变量,然后用WeightCases对话框指定频数变量,最后调用Crosstabs过程进行X2检验。
假设三个变量分别名为R、C和W,则数据集结构和命令如下):R C W1.00 1.00 54.001.002.00 44.002.00 1.00 8.002.00 2.00 20.00分析:卡方检验统计量的p值=0.013<0.05,拒绝原假设,呋喃硝胺治疗十二指肠溃疡有显著性影响。
四、实验小结:实验中遇到的问题及解决办法、心得体会等等...1、通过本次实验,使我较好地掌握了利用SPSS进行描述性统计分析的方法,学会了频数分布(Frequencies过程)、描述性分析(Descriptives过程)、交叉列联表分析(Crosstabs过程)。
2、频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各种统计量来描述数据的分布特征。
3、Descriptives过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,其功能和频数分布过程类似,主要以计算数值型单变量的统计量为主。
实验三均值检验一、实验目的学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
二、实验内容及步骤1、一个生产高性能汽车的公司生产直径为322mm的圆盘制动闸。
公司的质量控制部门随机抽取不同机器生产的制动闸进行检验。
共4台机器,每台机器抽取16支产品。
见数据文件ttest1.sav,要求检验每个机器生产的产品均值和322在90%的置信水平下是否有显著差异。
步骤:(1)打开数据文件ttest1.sav,选择菜单“Analyze→Compare Means→One-Sample T Test”。
弹出“One-Sample T Test”对话框。
(2)在对话框左侧的变量列表中选择变量“制动闸直径”进入“Test Variable(s)”框;在“Test Value”编辑框中输入过去的平均生产直径值322 选择Options,置信水平90%,单击contiue-ok2、在体育课上记录14名学生乒乓球得分的数据,男女各7名。
数据如下:男:82.00 80.00 85.00 85.00 78.00 87.00 82.00女:75.00 76.00 80.00 77.00 80.00 77.00 73.00比较在置信度为95%的情况下男女生得分是否有显著差别。
步骤:(1)建立表结构并输入数据(2)选择菜单“Analyze→Compare Means→Independent-samples T Test”项,弹出“Independent- samples T Test”对话框。