视网膜建模的研究现状及进展
视网膜成像技术在眼科医学中的应用

视网膜成像技术在眼科医学中的应用近年来,随着科学技术的不断发展和创新,视网膜成像技术在眼科医学中的应用也越来越广泛。
视网膜成像技术是一种无创的眼科诊断技术,能够帮助医生快速、准确地诊断眼部疾病,提高治疗效果,降低不必要的医疗成本。
本文将介绍视网膜成像技术在眼科医学中的应用,包括其原理、类型、优点、普及程度以及未来的发展方向等方面。
一、视网膜成像技术的原理视网膜成像技术是基于眼底成像原理而发展起来的。
通过成像仪器将红外光、蓝光或绿光照射在患者眼部表面,经过反射、透射、散射等过程后,成像仪器能够捕捉到视网膜表面的图像信息。
而视网膜成像技术正是利用这些图像信息进行眼科临床诊断。
因此,不同类型的视网膜成像技术也有所不同,例如光学相干层析成像(OCT)、角膜地形图以及视网膜照相等。
二、视网膜成像技术的类型视网膜成像技术有许多种类,常见的有以下几种:1、光学相干层析成像(OCT):光学相干层析成像是一种基于光学原理的高分辨率眼底成像技术。
通过一个特殊的探测器即光学相干层析机,设置在患者的眼部,然后从设备中推送一束激光向眼内部照射。
从而获取到扫描图像,对扫描图像进行处理后,就可以得到一个高清晰度的视网膜图像。
2、视网膜照相:视网膜照相技术是将一束蓝光或绿光照射在患者眼部的功能区域,通过摄像机捕捉眼底反射的图像,并将图像传输到计算机中。
通过图像处理技术,可以得到一张高清晰度的视网膜照片,帮助医生进行诊断。
3、眼底荧光检查:眼底荧光检查是通过将一种荧光染料注射到静脉中,通过染料与眼底血管的反应,可以获取眼底的动态荧光图像并进行诊断。
4、角膜地形图:角膜地形图就是用传感器将蓝色的光照射在角膜上,然后记录下反射的光,并通过计算机处理形成角膜地形图像。
因此,各种不同类型的视网膜成像技术都有其特定的应用范围和用途。
三、视网膜成像技术的优点作为一种无创的眼科诊断技术,视网膜成像技术有许多优点。
1、无创、无痛:视网膜成像技术是一种无创、无痛的检查方式,不需要进行手术或注射麻醉剂,对患者的身体健康没有任何危害。
基于深度学习的视网膜病变辅助诊断研究

基于深度学习的视网膜病变辅助诊断研究视网膜是眼睛的一个重要部位,它能接收光线并将其转化为神经信号,然后传输到大脑中进行图像的形成。
但是,由于各种原因,视网膜可能会发生病变,导致视力下降和其他眼部症状。
在这种情况下,早期的诊断和治疗对于保持良好的视力和眼健康至关重要。
目前,深度学习技术已被广泛用于从医学图像中发现和诊断眼部疾病,包括视网膜病变。
深度学习是一种人工智能的分支,它使用人工神经网络来模拟人类大脑的结构和功能。
它能够从原始数据中提取复杂的特征,并进行分类和预测。
在视网膜病变的辅助诊断方面,深度学习可以通过学习大量的眼底图像,自动发现和识别各种视网膜病变的类型和程度。
在深度学习中,一个重要的任务是图像分类。
对于视网膜图像,分类任务通常涉及将它们分为健康和病态两类或更多类别。
最近的研究表明,深度学习算法在识别各种视网膜病变方面已经取得了相当好的结果。
例如,一项基于深度学习的研究使用了超过50000张眼底图像,包括2万多个病例和2万多个正常情况。
研究结果表明,训练有素的深度学习算法在对这些图像进行分类时,可以达到与医生相当的准确度。
此外,深度学习也可以用于检测和跟踪视网膜病变的进展。
传统的方法基于手动测量和观察不同时间点的眼底图像。
这种方法不仅费时费力,而且受到主观因素的影响。
使用深度学习技术,可以自动提取眼底图像中的各种特征,包括颜色、形状和纹理等。
这些特征可以用于判断病变的进展情况。
例如,一项研究使用了深度学习算法,对包括4000多个受试者的眼底图像进行检测。
结果表明,算法可以跟踪以前诊断的病变区域,并且能够检测到新的病变区域,这为疾病的早期发现和治疗提供了帮助。
当然,深度学习算法还有一些限制。
首先,需要大量的训练数据和强大的计算能力。
其次,算法可能出现过度拟合的情况,即在训练数据上取得了很好的效果,但在新的数据上却表现不佳。
此外,由于模型的复杂性,深度学习算法的解释性相对较差。
综上所述,基于深度学习的视网膜病变辅助诊断研究已经取得了显著的进展。
神经网络模型的研究现状及应用

神经网络模型的研究现状及应用随着近年来人工智能技术的进步,神经网络模型成为了热门研究领域之一。
神经网络模型是一种模仿生物神经网络结构与功能,并且进行信息处理的复杂数学模型。
神经网络模型已经被广泛应用于语音识别、图像处理、语言翻译、自动驾驶等领域,成为智能化时代的重要工具。
一、神经网络模型的研究现状神经网络模型的发展可以追溯到上世纪60年代,随着计算能力的提升和数学算法的不断发展,神经网络模型得以不断完善。
目前,神经网络模型经历了多个版本的迭代更新,其中比较重要的有感知器、多层感知器、全连接神经网络、卷积神经网络、循环神经网络等。
感知器是最早出现的神经网络模型,由于其简单、易于实现等优点被广泛应用于数值预测等领域。
但是感知器的局限性也很明显,比如只能处理线性可分的问题,所以在处理更加复杂的问题上显得不太够用。
多层感知器是感知器的升级版,通过增加隐藏层使得神经网络模型可以处理非线性问题。
全连接神经网络则进一步加强了神经元之间的连接,实现了更加高效的信息交流。
卷积神经网络则是基于孪生神经元的结构,可以更加有效地处理图像、语音等信息。
而循环神经网络则可以更好地处理时序性数据,如自然语言处理等系统。
除了上述几种比较经典的神经网络模型外,还有一些衍生出来的新型神经网络模型,如生成对抗网络、变分自编码器等,这些模型都有着新增加的特性,可以应用在更多的领域。
二、神经网络模型的应用随着神经网络模型的不断升级和完善,越来越多的领域都开始尝试引入神经网络模型,并且取得了一定的成效。
在语音识别领域,谷歌的语音识别系统就采用了卷积神经网络和递归网络的方法,大大提升了语音的识别精度。
在图像识别领域,卷积神经网络已经成为了不可或缺的技术,诸如谷歌、微软、Facebook等巨头公司都将其应用在了图像识别领域,并且在ImageNet大规模视觉识别竞赛中取得了不俗的成绩。
在自然语言处理领域,循环神经网络和长短时记忆网络已经成为了解决序列化任务的必备工具。
视网膜血管分割方法研究的开题报告

视网膜血管分割方法研究的开题报告一、课题背景与意义眼底视网膜疾病是目前全世界公认的导致失明的主要原因之一,其中包括糖尿病视网膜病变、年龄相关性黄斑变性、静脉阻塞等。
而对于这些疾病的早期发现和治疗,视网膜图像的分析和诊断是至关重要的。
而眼底图像中的视网膜血管分割就是其中一个重要的步骤。
视网膜血管分割是指将眼底图像中的血管区域与非血管区域进行分割,根据其分割结果可以定量地分析血管直径、长度、分支角度等。
传统的手工提取血管分割特征及边缘检测等方法因为要求对图像具有较高的专业知识和技能,操作复杂,且有制约因素等局限性,因此自动化的视网膜血管分割方法自然而然地成为了研究热点。
在目前的研究中,视网膜血管分割方法主要分为基于传统的机器学习、基于深度学习和基于传统机器学习和深度学习的结合方法。
但是,无论是基于传统的机器学习还是深度学习算法,均存在其本身的局限性。
因此,本课题旨在研究一种新的视网膜血管分割方法,充分发挥传统机器学习和深度学习的优点,通过深入探究其理论与方法,实现对眼底图像自动化分析的改进,并提高视网膜疾病的诊断准确度。
二、研究内容本研究计划采用图像处理、机器学习和深度学习等技术,开展视网膜血管分割方法的研究。
具体内容如下:1.对采集的眼底图像进行预处理,包括图像增强、去噪等。
2.采用传统机器学习算法,如支持向量机、决策树等,对眼底图像进行特征提取,建立视网膜血管分割模型,并对模型进行优化。
3.采用深度学习算法,如卷积神经网络、深度卷积神经网络等,对眼底图像进行处理,建立视网膜血管分割模型,并对模型进行优化。
4.将传统机器学习算法与深度学习算法相结合,提升视网膜血管分割的准确率和速度。
三、研究方法1.图像预处理方法:采用双边滤波、直方图均衡化、自适应直方图均衡化等方法对眼底图像进行预处理。
2.传统机器学习方法:采用多种特征提取方法,如纹理特征、形态特征等,建立视网膜血管分割模型,并采用交叉验证等方法对模型进行优化。
视网膜成像技术研究现状与未来展望

视网膜成像技术研究现状与未来展望视网膜成像技术是一种非侵入性的成像技术,借助于不同的成像设备和技术,可以提供人眼视网膜的高分辨率图像,从而帮助医生对眼部疾病进行有效的诊断和治疗。
视网膜成像技术的发展不仅为眼科医学带来了革命性的变化,也对全球眼科保健作出了重要贡献。
本文将对视网膜成像技术的研究现状进行综述,并展望其未来发展的前景。
视网膜成像技术的研究现状可以总结为以下几个方面:1. 光准直扫描成像技术:光准直扫描成像技术采用数字摄像机记录图像,并利用计算机图像处理技术分析。
这种技术在视网膜的病变检测和治疗过程中具有很大的帮助,成为临床眼科医学中的常用工具。
2. 红外图像技术:红外图像技术通过红外照射和检测红外光波来获取视网膜的图像。
由于红外光可以穿透眼球的虹膜和晶状体,因此这种技术可以提供更清晰的图像以便医生进行更精确的诊断。
3. 脉络膜成像技术:脉络膜是视网膜血管层的一部分,含有丰富的血管网。
脉络膜成像技术可以非侵入地检测脉络膜的血流动力学和纹理特征,以及其变化与眼部疾病的关系,为疾病的诊断和治疗提供重要的参考。
4. 谐波成像技术:谐波成像技术是一种通过谐波检测来生成图像的成像技术。
由于视网膜组织在弹性模量上有所不同,因此谐波成像技术可以用来检测视网膜组织中的细微变化,如纤维化和增生等。
未来,视网膜成像技术有望在以下几个方面取得进一步的发展:1. 高分辨率成像:随着成像技术的不断改进和计算机图像处理技术的发展,视网膜成像技术将能够提供更高分辨率的图像,从而更准确地检测眼部病变。
2. 无创检测:目前的视网膜成像技术需使用眼底镜或光束对眼球进行接触,这对患者来说可能不太舒适。
未来,随着技术的改进,我们可以期待无创的视网膜成像技术的出现,通过激光或其他无创手段检测眼球组织。
3. 自动化分析:强大的计算机算法对于快速、准确地分析和诊断视网膜图像至关重要。
未来,视网膜成像技术将更加注重自动化分析算法的发展,使得医生能够更轻松地进行诊断和治疗决策。
基于机器学习的视网膜图像识别模型设计
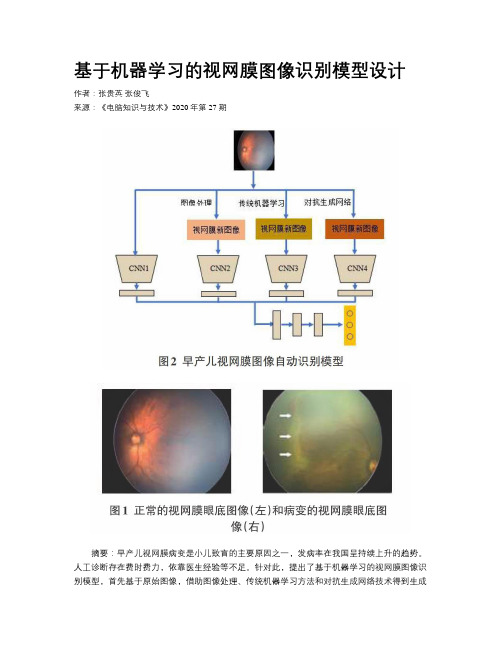
基于机器学习的视网膜图像识别模型设计作者:张贵英张俊飞来源:《电脑知识与技术》2020年第27期摘要:早产儿视网膜病变是小儿致盲的主要原因之一,发病率在我国呈持续上升的趋势。
人工诊断存在费时费力,依靠医生经验等不足。
针对此,提出了基于机器学习的视网膜图像识别模型,首先基于原始图像,借助图像处理、传统机器学习方法和对抗生成网络技术得到生成图像,然后基于这些图像和原始图像,提取其特征,最后对级联后的特征进行分类。
该模型有望为早产儿视网膜病变的自动筛查系统提供技术支持。
关键词:视网膜图像;自动识别;模型设计中图分类号:TP181 文献标识码:A文章编号:1009-3044(2020)28-0176-02开放科学(资源服务)标a码(OSID):1 引言早产儿视网膜病变( Retinopathy of Prematurity,ROP)曾称为Terry综合征或晶状体后纤维增生症,最早由Terry在1942年发现[1]。
孕期34周以下,出生体重小于1500、出生后吸氧史,发病率约为60%,孕期更短或更低出生体重者,发生率可达66%- 82%。
由于ROP可致盲,早在1984年到1987年,由国际组织ROP专家建立了详细的病变分类标准,以促进临床治疗。
指出了ROP发生的部位分为3个区域,并将病变的严重程度分为5期,图1为正常和ROP3期图像示例。
另外,需要注意的是Plus疾病:即后极部视网膜血管迁曲怒张,表明ROP 处于迅速进展期。
ROP最早出现在矫正胎龄32周,阈值病变大约出现在矫正胎龄37周,早期筛查和治疗可以阻止病变的发展。
目前,眼科医生通过数字视网膜照相机(如RetCam3)获取早产儿视网膜眼底图像,然后人工诊断有无病变及分级,这种方式面临几个问题。
首先,ROP需要通过开展大规模的眼底普查,对潜在眼底病患者进行定期的眼底视网膜检查。
然而,由于眼底病潜在患者数量较大,眼科专家人工检查工作开展较为困难,尤其在中国和印度这样人口众多的国家。
视网膜类器官治疗视网膜退行性疾病的研究进展
视网膜类器官治疗视网膜退行性疾病的研究进展奚惠雨;茅希颖;孙洁;袁松涛;刘庆淮【摘要】视网膜退行性疾病是导致视力受损与失明的重要原因.目前,对于感光细胞大量丧失的疾病晚期阶段尚无有效的治疗方案.近年来,大量研究提供了感光细胞的移植替代治疗的新思路,而视网膜3D培养技术产生的视网膜类器官能够在体外产生移植所需的感光细胞及组织,为视网膜退行性疾病的移植替代治疗奠定了基础.本文通过综述视网膜3D培养技术以及感光细胞移植的发展,着重阐述视网膜类器官在视网膜退行性疾病移植替代治疗中的现有运用策略以及局限性,以期为视网膜3D 培养技术在感光细胞替代治疗中的优化提供理论参考.【期刊名称】《国际眼科杂志》【年(卷),期】2019(019)005【总页数】4页(P771-774)【关键词】视网膜类器官;感光细胞;移植;视网膜退行性疾病【作者】奚惠雨;茅希颖;孙洁;袁松涛;刘庆淮【作者单位】210029 中国江苏省南京市,南京医科大学第一附属医院眼科;210029 中国江苏省南京市,南京医科大学第一附属医院眼科;210029 中国江苏省南京市,南京医科大学第一附属医院眼科;210029 中国江苏省南京市,南京医科大学第一附属医院眼科;210029 中国江苏省南京市,南京医科大学第一附属医院眼科【正文语种】中文0引言眼睛,作为连接人类与外在世界的窗户,给予人类分辨外界事物以及颜色的能力。
其中视网膜作为整合视觉信息的复杂神经组织结构,它的损伤往往会导致视力不可逆的损害。
在大多数国家,视网膜退行性病变是导致视网膜细胞损伤的重要原因[1],如视网膜色素变性(retinitis pigmentosa,RP)、年龄相关性黄斑变性(age-related macular degeneration,ARMD)等[2],这些疾病会导致感光细胞功能损伤及数量减少,引起视力受损,最终导致失明。
目前此类疾病的治疗方法包括神经保护治疗、基因疗法、药物疗法、光遗传学治疗、人工视网膜以及细胞替代疗法等[3]。
糖尿病视网膜Muller细胞的研究进展
糖尿病视网膜Muller细胞的研究进展【摘要】 Muller细胞是脊椎动物视网膜内最要紧的神经胶质细胞。
它贯穿整个视网膜,与视网膜神经细胞及视网膜血管发生多种功能的交互作用。
糖尿病视网膜病变(diabetic retinopathy,DR)的发病机制至今尚未明,最近几年来的临床和基础研究发觉DR患者和动物模型中Muller细胞超微结构和生理功能发生了转变,这种转变早于视网膜血管损伤。
本文就近几年有关糖尿病视网膜Muller细胞形态结构及生理转变的研究进展作一综述。
【关键词】糖尿病视网膜病变; Muller细胞; 形态结构; 生理转变Abstract: Muller cells are the most principal neuroglial cells in vertabrate cross the entire thinckness of the retina and interact with neurocytes and retinal uncertainty remains about the exact nature of the insult that initiates diabetic retinal changes,but the overwhelming majority of evidence from studies of human diabetes and animal models pointed to the ultrastructural and physiological changes in advance of the dectectable retinal vascular changes. In this paper the current research of morphological structure and physiological changes of Muller cells in diabetic retinopathy were reviewed.Key words: diabetic retinopathy; Muller cell; morphological structure; physiological changesDR是糖尿病(diabetes mellitus,DM)最多见而严峻的并发症之一,致盲率占眼科双盲中的第1位,DR所致的失明者是非糖尿病性失明者的5倍。
基于深度学习的糖尿病视网膜病变检测研究
基于深度学习的糖尿病视网膜病变检测研究糖尿病是一种慢性代谢性疾病,而糖尿病视网膜病变是其最常见和最严重的并发症之一。
早期识别和及时治疗糖尿病视网膜病变对于预防视力丧失至关重要。
然而,传统的糖尿病视网膜病变诊断方法需要专业医生的参与和大量的人工判断,耗时且易受主观因素干扰。
近年来,基于深度学习的糖尿病视网膜病变检测研究应用广泛,并取得了令人鼓舞的成果。
深度学习是一种机器学习的分支,通过神经网络模拟人脑的工作方式来进行模式识别和学习。
随着计算能力和数据量的不断增加,深度学习在医学领域的应用日益普及。
在糖尿病视网膜病变检测中,深度学习技术可以自动从大量的眼底图像中提取特征,并辅助医生进行准确诊断。
深度学习算法主要分为卷积神经网络(CNN)和循环神经网络(RNN)两种常见架构。
CNN适用于图像处理任务,可以有效提取图像中的特征。
而RNN则适用于序列数据处理,可以捕捉时间上的依赖关系。
在糖尿病视网膜病变检测中,常用的架构是基于CNN的卷积神经网络。
研究人员通常使用大规模的眼底图像数据库作为训练集,通过深度学习算法对这些图像进行训练,使得算法能够自动识别不同类型的糖尿病视网膜病变。
在训练过程中,研究人员会标注图像中病变的位置和类型,以增加算法对病变的准确识别能力。
训练完成后,算法可以自动识别眼底图像中的糖尿病视网膜病变,并给出相应的诊断结果。
深度学习在糖尿病视网膜病变检测中具有许多优势。
首先,深度学习算法能够处理大量的眼底图像数据,从而获得更准确的诊断结果。
其次,深度学习算法可以实现快速自动化的病变检测,大大缩短了诊断时间。
第三,深度学习算法具有良好的泛化能力,即使在不同医学中心收集的图像上,算法的性能也能保持稳定。
然而,深度学习算法在糖尿病视网膜病变检测中仍面临一些挑战。
首先,图像标注过程中的标签准确性和一致性对算法的影响较大,误标注可能导致算法的错误识别。
其次,缺乏高质量的标注数据集也是一个问题,很多数据集中的图像并没有准确的标注,这使得算法的训练更具挑战性。
眼科医学的研究现状与未来方向
眼科医学的研究现状与未来方向眼科医学是一门研究眼部疾病的学科,它的研究范围涉及眼部解剖、眼病的发生、病因、诊断以及治疗等方面。
随着科技的不断发展,现代眼科医学研究正面临着前所未有的机遇和挑战。
本文就研究现状和未来发展方向进行探讨。
一、眼科疾病的研究现状目前,全球范围内,眼科疾病的种类较多,其中包括白内障、青光眼、近视等常见疾病,还有其他相对较为罕见的疾病。
除此之外,一些全身性疾病,如糖尿病、高血压、甲状腺疾病等,也可能导致眼部出现疾病表现,因此对于这些疾病,眼科医生也需要有深入的了解。
针对眼科疾病的研究,当前主要集中在以下领域:1.基础研究领域眼科基础研究领域主要关注眼球的解剖、生理、发育、变异和病理学等方面。
研究人员通过光学显微镜和投影显微镜等高精度仪器,开展眼科研究工作。
包括关注角膜、晶状体和玻璃体的结构、功能和变异,以及睫状体、睫毛体、视网膜、视神经等区域的损伤、塑性和恢复能力等。
2.疾病诊疗领域这一领域的研究主要关注眼科常见疾病的诊断和治疗方法。
常见的兴奋光刺激、角膜曲率测量、荧光素眼底血管造影等检查方法,都有助于眼科医生进行准确的诊断和治疗。
另外,随着越来越多的激光和微创手术技术的出现,眼科医学领域的疾病治疗手段也越来越丰富。
3.青光眼研究领域青光眼是一种常见的眼科疾病,目前的治疗方法主要是降低眼内压力。
青光眼研究领域的重点主要是如何防止眼内压力影响的神经元,从而保护神经元免遭损伤。
通过针对神经元保护,可以进一步延缓青光眼的进展以及防止患者的视力持续下降。
二、未来眼科医学的研究方向未来眼科医学的研究方向主要集中在两个方面:探索新的治疗手段和开展个体化治疗。
1.新的治疗手段随着科技的不断进步,越来越多的新技术涌现,这些技术可以成为眼科医学的新治疗手段。
其中包括基因治疗、光学减振技术、3D打印技术等。
除此之外,类似再生医学、干细胞治疗、光感知器的设计等技术也可以成为眼科治疗技术的新范式。
这些新技术的应用,将会进一步拓展眼科医学的研究领域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
视网膜建模的研究现状及进展探摘要视网膜模型的建立是视网膜视觉假体中一个重要组成部分。
视网膜模型是从已知的生理知识和实验数据出发模拟视网膜处理信息的功能,研究输入图像和输出神经冲动的关系。
我们可以根据视网膜模型的原理将其分为硬件实现模型和算法模型。
本文就对视网膜建模的国内外研究现状进行分析和讨论。
关键词人工视觉假体视神经视觉假体视网膜视觉假体人工神经网络神经生理模型1 引言视觉是人类获得信息的一个重要途径。
然而世界上有很多人存在不同程度的视觉障碍,不能通过视觉获得信息。
所以建立人工视觉假体来帮助盲人恢复视力有重要的意义。
视觉是一个非常复杂的神经生理活动过程。
光信息医学论文网从1·3亿个光感受细胞输入,通过复杂的处理由100多万个神经节细胞产生相应神经冲动,经视神经、视交叉、视束传到外侧膝状体,再经视中枢的复杂处理,最终形成视觉。
对于某些有视觉障碍的人(如老年黄斑变性、色素性视网膜炎)来说,他们的大部分视网膜细胞的轴突穿过眼球组成了视神经。
而光感受细胞还可被分为视杆细胞和视锥细胞。
视网膜上视觉最敏锐的区域叫黄斑区,其中央有一直径1·5 mm 的中央凹。
在中心凹处主要集中的是视锥细胞,在中央凹以外视杆细胞逐渐增多。
视网膜的刺激传递是从光感受细胞到双极视网膜模型细胞最后传到神经节细胞产生放电。
水平细胞和无长突细胞则构成视网膜传递的横向结构。
光感受细胞的主要功能是接受光刺激。
视锥细胞主要对强光敏感,而视杆细胞主要对弱光敏感。
光感受细胞的电反应强度与细胞膜色素分子吸收的光子个数有关。
水平细胞位于光感受细胞下方,通过化学传递来接受光感受细胞的信号以及和其相邻层的电信号。
水平细胞的作用相当于一个低通滤波器,为双极细胞提供一低频信号。
双极细胞可以接受或抑制水平细胞和光感受细胞传来的信号,双极细胞根据其感受野的中心极性可以分为on和off两类。
无长突细胞和水平细胞一样都是横向结构的细胞。
无长突细胞接受双极细胞及其他无长突细胞的信号,它是首先产生神经冲动的细胞。
它的反应与所给刺激的特性有关,并且各个细胞体都有所差异。
无长突细胞对运动较为敏感。
神经节细胞分为瞬时和持续两类,它主要接受双极细胞和无长突细胞的信号然后产生神经冲动,通过轴突传递到视神经。
3 视网膜模型3.1 基于算法的模型基于算法的模型是应用人工神经网络、实验数据及数学算法等通过调节模型中的参数达到最优效果来模拟视网视网膜模型膜功能。
3.1.1 人工神经网络模型应用人工神经网络来进行视网膜建模十分普遍,因为视网膜有很明确的分层结构。
同时,在视觉假体中实现人的视觉重建是一个不断学习的过程,所以应用人工神经网络的各个学习算法来进行模型优化是可行的。
①Cellular Neural Network (CNN)网络对视网膜建模提供了良好的基础,因为CNN网络和视网膜结构有着很多相似之处。
CNN网络是一个非线性计算仿真网络。
CNN计算网络框架的所有基本单元都是一阶的RC细胞。
所有细胞间的冲动传递都是空间不变的,并且只能在相邻的层间作用。
它的所有非线性的突触连接是突触前电压单调连续函数。
冲动传递的时间间隙是连续的。
用CNN网络对视网膜建模一般分成三步,即构造框架、选择参数、选择刺激。
CNN模型为视网膜结构提供了一个有效、灵活的模拟。
目前美国和奥地利的Werblin等[14,15]采用CNN网络对视网膜进行研究。
该视网膜模型运用了多层CNN网络来实现。
生理学上的每个视网膜层由一层CNN网络来模拟,通过CNN网络的结构和参数的调节来模拟从光感受器到神经节细胞各个部分的视网膜结构。
两种分别控制运动和边缘检测的神经节细胞有着相同的结构,可以通过双极细胞传播和无长突细胞抑制这两个参数在其间进行转换。
参数的值被分配到各个CNN模板上。
每个层的参数包括神经元时间常数、空间常数及神经元输出函数,神经元输出函数可以是线性或非线性的。
该视网膜模型的输入是光感受器层,输出是神经节细胞的放电;输出是输入图像的一个特殊的编码。
模型通过突触来进行层间的传递。
有三种接受模型,即普通模型(plain)、延迟模型(delayed)和减感模型(desensitizing)。
视网膜模型的计算过程分为4步。
首先,通过外视网膜模块(OPL)来计算外视网膜(光感受细胞)。
其次,通过内视网膜(双极细胞)激发模块(IRE)和特征检测器的时空模式来计算不同的刺激模式。
再次,通过内视网膜抑制模块(IRI)来产生抑制模式。
最后,通过内视网膜抑制模块和内视网膜激发模块的输出来计算单个神经节细胞模式以得到视网膜对视觉的时空表达。
CNN模型的输出和脊椎动物的视网膜输出尤为相似。
通过该模型及其算法我们可以了解视网膜是如何调节各个参数的,可以解决一些真实的图像处理问题,当然也可以作为视觉假体中的视网膜编码器来产生刺激信号。
②比利时的Archambeau等[8]基于Veraart 等[9~11]所进行的刺激视神经的实验用人工神经网络对其进行建模。
他们采用了两种模型来预测刺激参数。
第一种是完全黑箱模型,运用了线性回归算法、多层感受器人工神经网络(MLP)、径向基函数网(RBFN)。
第二种是灰箱模型,该模型把目前所知的神经生理学知识和人工神经网络黑箱模型相结合来预测视觉感受的特征。
模型还采用了交叉确认以得到更好的估计。
这些模型医学论文网的目的在于找出能够把输入图像转换成脉冲刺激的算法来建立视觉编码。
黑箱和灰箱模型为电刺激得到的光斑的位置提供了一定的预测。
这些预测值为今后的视神经模型的建立提供了参考。
结果显示用人工神经网络来预测要比线性方法预测更准确,从而证实了视神经是非线性结构。
今后,需要基于神经生理学来进一步优化预测,使黑箱白化。
③Eckmiller等[16-17]则提出了视网膜编码模型(RE)。
该模型假设视网膜的图像处理可以通过一系列的时空滤波器(ST filter)来实现。
该模型通过对各个编码参数的反复调整和对话学习来优化图像和视网膜放电的映射关系。
模型由视网膜模块(RM)和视觉模块(VM)两部分组成。
RM由16×16=256个可调的时空滤波器组成。
时空滤波器的输入模拟了不同类型的神经节细胞的输入,它的输出则是用来刺激电极的脉冲串。
RM把一个视觉图像(P1)映射成一组视网膜输出参数R1(t)。
而VM则把视网膜参数R1(t)通过反映射转换成视觉对象(P2)。
不可逆时空滤波器模拟了视网膜神经节细胞的一些性质来产生模糊的输出信号。
而只有当输入R1(t)准确并含有充足的信息的时候,VM才能较好地产生输出视觉图像。
模型的光传感器模块由光传感器芯片和输入图像组成。
这个模块模拟了视网膜的光感受细胞部分。
每个像素可以被分配给一个或多个时空滤波器。
时空滤波器模拟了视网膜的神经节细胞。
时空滤波器有四类:P-on型、P-off型、M-on型和M-off型,每类时空滤波器有11个参数控制。
这些参数的值域很广,可以产生实时的信号流。
我们可以通过调节这些参数来达到最优输出。
视网膜编码模型的参数调节运用了基于对话的学习算法。
拥有正常视力的实验者被要求对P2输出的6个图像和原始P1输入图像进行比较,从中选出3个和原始图像最接近的图像,然后通过各种学习算法包括进化算法修改RE的参数,基于选出的3个图像得出新的6个改进后的图像,重复进行直到P2输出和P1输入足够接近。
Eckmiller基于视网膜编码模型还提出了一个改进的视网膜编码模型(RE*)。
这个模型考虑了如何对移动物体及眼睛的转动进行编码。
改进的视网膜编码模型由编码模块(EM)和解码模块(DM)组成。
EM由64×64阵列的光感受器输入和34×34蜂窝状排列的时空滤波器组成。
DM的主要功能则是把EM的输出重塑成输入图像。
DM的输出和EM的输入相对应,由64×64蜂窝状排列的像素点组成。
这个模型的时空滤波器有3类,即P-on型、P-off型和M型,P型占三分之二,M 型占三分之一。
每类时空滤波器产生三类不同的由4个值组成的代码。
这些代码可以用来确定部分感受野刺激的像素值。
改进的视网膜编码模型运用了树型分析算法。
首先,所有DM的输出64×64像素点都为零。
根据P-on型、P-off型和M型三类时空滤波器对中心感受野的响应得到可确认的像素点的值。
然后,根据时空滤波器对中心及外围的整个感受野的响应来给相应的像素点赋值。
接下来,运用树型分析算法可以继续为像素点赋值。
然后把输入图像在时钟4点方向移动一个像素点重复上述步骤以确定所有像素点的值。
该模型为我们如何进行编码提供了很好的参考。
模型根据视网膜的结构采用了蜂窝状的像素点,这样被不同电极激活的神经纤维不会相互干扰。
蜂窝状的像素提供了更高的采样频率和更好的转动恒定性。
另外该模型的算法设计也比较合理,根据神经节细胞的特性采用了P-on型、P-off型和M型三类时空滤波器逐步对像素点赋值。
3.1.2 实验统计模型比利时的Veraart 等[8~11]在进行视神经刺激的研究和建模。
他们通过在人视神经上植入一个有4个正交的电极的圈套来刺激视神经,并且得到了不少收获。
这个模型就是根据所得到的实验数据通过公式来拟合电流强度、刺激时间、脉冲个数、脉冲频率对域值、光斑位置、光斑大小、光斑亮度的影响。
为了比较所给刺激参数和所能“看到”的光斑的关系,Delbeke使用了体积传导模型。
这个模型由两个部分组成。
首先,用三维有限元素几何来计算被刺激到的区域。
然后,通过一些描述视神经行为的公式来确定被激活的神经束。
这个模型是一个简化的模型,模型假设视神经束排列是对称的、均匀的,并且视神经中心对应于一个固定的点。
该模型基于实验数据运用一些数学公式进行拟合。
然而用4个电极比较粗糙,目前该小组正在加大电极数目进行进一步研究。
另外对于实验对象来说,他的部分视神经细胞可能坏死,这样对实验结果带来了偏差,从而不能很好地用数学公式来拟合。
3.1.3 视网膜结构分层计算模拟模型视网膜结构分层计算模拟模型就是基于已知的生理学知识,运用数学工具和相关算法来模拟视网膜的各层结构。
①瑞士的Beaudot等[18]使用了Michaelis-Menten法则而不是传统的对数函数来模拟光感受传递函数(photoreceptor transfer function)。
可以看出,视网膜的神经及功能结构支持对非稳态的视觉信息的优化编码。
模型通过适应性传递函数来控制视觉敏感性。
该传递函数的参数由视网膜回路来估计,并反馈到光感受器上。
该模型具有很多脊椎动物光感受器的重要特征。
它根据Michaelis-Menten 法则对输入信号进行压缩。
它运用了基于信噪比的适应性的时空低通滤波器。
它通过调整Michaelis-Menten法则的参数来适应光强。