8位并行乘法器
EDA实验--8位二进制乘法电路

EDA数字系统设计实验——8位二进制乘法电路学院:电子工程学院学号:0210****姓名:***8位二进制乘法电路1.选题目的:通过八位二进制乘法器设计实验,进一步熟悉VHDL语言的电路设计,及数字电路的基本知识,为以后进一步在数字电路学习上奠定基础。
2.设计要求8位二进制乘法采用移位相加的方法。
即用乘数的各位数码,从低位开始依次与被乘数相乘,每相乘一次得到的积称为部分积,将第一次(由乘数最低位与被乘数相乘)得到的部分积右移一位并与第二次得到的部分积相加,将加得的和右移一位再与第三次得到的部分积相加,再将相加的结果右移一位与第四次得到的部分积相加。
直到所有的部分积都被加过一次。
例如:被乘数(M7M6M5M4M3M2M1M0)和乘数(N7N6N5N4N3N2N1N0)分别为11010101和10010011,其计算过程如下:1 1 0 1 0 1 0 1× 1 0 0 1 0 0 1 11 1 0 1 0 1 0 1 N0与被乘数相乘的部分积,部分积右移一位1 1 0 1 0 1 0 1 N1与被乘数相乘的部分积+ 1 1 0 1 0 1 0 11 0 0 1 1 1 1 1 1 11 0 0 1 1 1 1 1 1 1 两个部分积之和,部分积之和右移一位+ 0 0 0 0 0 0 0 0 N2与被乘数相乘的部分积0 1 0 0 1 1 1 1 1 1 10 1 0 0 1 1 1 1 1 1 1 与前面部分积之和相加,部分积之和右移一+ 0 0 0 0 0 0 0 0 N4与被乘数相乘的部分积· · ·· · · N7与被乘数相乘的部分积+ 1 1 0 1 0 1 0 11 1 1 1 0 1 0 0 1 0 0 1 1 1 1 与前面部分积之和相加0 1 1 1 1 0 1 0 0 1 0 0 1 1 1 右移一位得到最后的积为了实现硬件乘法器,根据上面的乘法的计算过程可以得出3点:一是只对两个二进制数进行相加操作,并用寄存器不断累加部分积;而是将累加的部分积左移(复制的被乘数不移动);三是乘数的对应位若为0时,对累加的部分积不产生影响(不操作)。
应用移位相加原理设计8位乘法器

应用移位相加原理设计8位乘法器1.顶层文件library ieee;use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity multi8x8 isport(clkk,start:in std_logic;a,b:in std_logic_vector(7 downto 0);dout:out std_logic_vector(15 downto 0));end entity;architecture struc of multi8x8 iscomponent arictlport(clk,start:in std_logic;clkout,rstall:out std_logic);end component;component andarithport(abin:in std_logic;din:in std_logic_vector(7 downto 0);dout:out std_logic_vector(7 downto 0));end component;component adder8bport(cin:in std_logic;a,b:in std_logic_vector(7 downto 0);s:out std_logic_vector(7 downto 0);cout:out std_logic);end component;component sreg8bport(clk,load:in std_logic;din:in std_logic_vector(7 downto 0);qb:out std_logic);end component;component reg16bport(clk,clr:in std_logic;d:in std_logic_vector(8 downto 0);q:out std_logic_vector(15 downto 0));end component;signal gndint,intclk,rstall,newstart,qb:std_logic;signal andsd:std_logic_vector(7 downto 0);signal dtbin:std_logic_vector(8 downto 0);signal dtbout:std_logic_vector(15 downto 0);begindout<=dtbout;gndint<='0';process(clkk,start)beginif(start='1')thennewstart<='1';else if(clkk='0')thennewstart<='0';end if;end if;end process;u1:arictl port map(clk=>clkk,start=>newstart,clkout=>intclk,rstall=>rstall);u2:sreg8b port map(clk=>intclk,load=>rstall,din=>b,qb=>qb);u3:andarith port map(abin=>qb,din=>a,dout=>andsd);u4:adder8b port map(cin=>gndint,a=>dtbout(15 downto 8),b=>andsd,s=>dtbin(7 downto 0),cout=>dtbin(8));u5:reg16b port map(clk=>intclk,clr=>rstall,d=>dtbin,q=>dtbout);end architecture;2.各部件1)arictl—控制元件library ieee;use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity arictl isport(clk,start:in std_logic;clkout,rstall:out std_logic);end entity;architecture bhv of arictl issignal cnt4b:std_logic_vector(3 downto 0);beginprocess(clk,start)beginrstall<=start;if(start='1')thencnt4b<="0000";else if(clk'event and clk='1')thenif(cnt4b<8)thencnt4b<=cnt4b+1;end if;end if;end if;end process;process(clk,cnt4b,start)beginif(start='0')thenif(cnt4b<8)thenclkout<=clk;elseclkout<='0';end if;elseclkout<=clk;end if;end process;end architecture;2)sreg8b—8位移位寄存器元件library ieee;use ieee.std_logic_1164.all;entity sreg8b isport(clk,load:in std_logic;din: in std_logic_vector(7 downto 0);qb:out std_logic );end sreg8b;architecture behav of sreg8b issignal reg8 : std_logic_vector(7 downto 0); beginprocess(clk,load)beginif clk'event and clk = '1' thenif load ='1' then reg8<=din;else reg8(6 downto 0)<=reg8(7 downto 1);end if;end if;end process;qb<=reg8(0);end behav;3)andarith—一位乘法元件library ieee;use ieee.std_logic_1164.all;entity andarith isport( abin: in std_logic;din: in std_logic_vector(7 downto 0);dout : out std_logic_vector(7 downto 0) );end andarith;architecture behav of andarith isbeginprocess(abin,din)beginfor i in 0 to 7 loopdout(i)<=din(i) and abin;end loop;end process;end behav;4)adder8b—8位加法元件library ieee;use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity adder8b isport (cin : in std_logic;a,b : in std_logic_vector(7 downto 0);s : out std_logic_vector(7 downto 0);cout : out std_logic );end adder8b;architecture behav of adder8b issignal sint,aa,bb : std_logic_vector(8 downto 0); beginaa<='0'& a;bb<='0'& b;sint<=aa+bb+cin;s<=sint(7 downto 0);cout<=sint(8);end behav;5)reg16b—16位移位寄存器元件library ieee;use ieee.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity reg16b is --16 bit shift register port(clk,clr:in std_logic;d:in std_logic_vector(8 downto 0);q:out std_logic_vector(15 downto 0));end entity;architecture bhv of reg16b issignal r16s:std_logic_vector(15 downto 0);beginprocess(clk,clr)beginif(clr='1') thenr16s<="0000000000000000" ;else if(clk'event and clk='1')thenr16s(6 downto 0)<=r16s(7 downto 1);r16s(15 downto 7)<=d;end if;end if;end process;q<=r16s;end architecture;。
基于fpga八位硬件乘法器课程设计

基于FPGA的八位硬件乘法器课程设计,可以分以下几个步骤进行:
1. 确定设计要求:根据要求,设计一个能对两个八位二进制数进行乘法运算的硬件电路。
需要考虑到输入、输出、各种控制信号等。
2. 确定设计方案:根据设计要求,确定具体的设计方案。
可以使用Verilog语言进行描述,包括输入输出端口的定义、状态转移的描述等。
3. 编写Verilog代码:根据设计方案,编写Verilog代码。
代码需要对各种信号进行定义,并实现相应的逻辑功能。
4. 进行仿真:在编写完代码后,进行功能仿真。
可以使用ModelSim等仿真工具进行验证。
对代码进行仿真测试,在设计出现问题时可以及时进行调试和修改。
5. 进行综合和布局布线:通过综合和布局布线操作,将Verilog代码映射到FPGA芯片上,并生成bit文件,用于烧录到FPGA芯片中。
6. 进行验证:将bit文件烧录到FPGA芯片中,进行验证。
可以通过开发板上的按键等方式,输入两个八位二进制数并进行乘法运算,同时显示结果。
设计八位硬件乘法器需要了解数字电路设计基础知识和Verilog语言的使用。
同时,需要熟练掌握FPGA开发板的使用,以及相关的开发工具(如Quartus II等)的使用。
基于FPGA的8位移位相加型硬件乘法器的设计

基于FPGA的8位移位相加型硬件乘法器的设计作者:张建妮来源:《智能计算机与应用》2014年第04期摘要:乘法器是数字信号处理中非常重要的模块。
本文首先介绍了硬件乘法器的原理,在此基础上提出了硬件乘法器的设计方法,最后再利用EDA技术,在FPGA开发平台上,通过VHDL编程和图形输入对其进行了实现,具有实用性强、性价比高、可操作性强等优点。
关键词:硬件乘法器;加法器; VHDL中图分类号:TP2 文献标识码:A文章编号:2095-2163(2014)04-0087-04Abstract:Multiplier is very important in digital signal processing module. In this paper, the principle of the hardware multiplier is introduced at first. Based on it, a design method is put forward.Finally , using EDA technology,the hardware -multiplier is implemented through VHDL programming combining with the input mode of schematic diagram on the FPGA development platform. The design has strong practicability ,high cost-effective, strong operability, etc.Key words:Hardware-Multiplier; Adder; VHDL0引言在数字信号处理中,经常会遇到卷积、数字滤波、FFT等运算,而在这些运算中则存在大量类似ΣA(k)B(n-k)的算法过程。
因此,乘法器是数字信号处理中必不可少的一个模块。
(VHDL)8位二进制乘法电路程序

8位二进制乘法电路该乘法器是有由8位加法器构成的以时序方式设计的8位乘法器,采用逐项移位相加的方法来实现相乘。
用乘数的各位数码,从低位开始依次与被乘数相乘,每相乘一次得到的积称为部分积,将第一次<由乘数最低位与被乘数相乘)得到的部分积右移一位并与第二次得到的部分积相加,将加得的和右移一位再与第三次得到的部分积相加,再将相加的结果右移一位与第四次得到的部分积相加。
直到所有的部分积都被加过一次。
例如:被乘数<M7M6M5M4M3M2M1M0)和乘数<N7N6N5N4N3N2N1N0)分别为11010101和10010011,其计算过程如下:下面分解8位乘法器的层次结构,分为以下4个模块:①右移寄存器模块:这是一个8位右移寄存器,可将乘法运算中的被乘数加载于其中,同时进行乘法运算的移位操作。
②加法器模块:这是一个8位加法器,进行操作数的加法运算。
③1位乘法器模块:完成8位与1位的乘法运算。
④锁存器模块:这是一个16位锁存器,同时也是一个右移寄存器,在时钟信号的控制下完成输入数值的锁存与移位。
按照上述算法,可以得到下图所示之框图和简单流程图。
图中8位移位寄存器reg_8存放乘数a ,从a的最低位开始,每次从reg_8中移出一位,送至1×8位乘法器multi_1中,同时将被乘数加至multi_1中,进行乘法运算,运算的结果再送至8位加法器adder_8中,同时取出16位移位寄存器reg_16的高8位与之进行相加,相加后结果即部分积存入reg_16中,进行移位后并保存。
这样经过8次对乘数a的移位操作,所以的部分积已全加至reg_16中,此时锁存器reg_16存放的值即所要求的积。
<A)电路框图<B)简单流程图8位移位寄存器是在时钟<r8_clk'event and r8_clk='1')信号作用下,当r8_load='1'时,将8位乘数加载进入;而当r8_load='0'时,对数据进行移位操作,同时定义一个信号reg8用来装载新数据及移位后的操作数,完成这些操作后,寄存器的最低位reg8(0>传送给r8_out输出。
八位二进制乘法器booth

八位二进制乘法器booth八位二进制乘法器Booth是一种快速计算二进制乘法的方法,其原理是将被乘数与乘数一起转化为二进制补码形式,然后进行位移和相加运算,最终得出乘积。
下面我们就来详细了解Booth乘法器的实现流程。
1. 将被乘数和乘数转化为二进制补码形式Booth乘法器的第一步是将被乘数和乘数转化为8位二进制补码形式。
具体来说,要将它们分别转化为8位带符号的二进制数,如果是正数则其二进制与原数相同,如果是负数则其二进制为其绝对值的原码取反加1。
2. 初始化Booth乘法器Booth乘法器的第二步是对其进行初始化。
具体来说,要先在最左侧添加一个0,然后添加8个辅助位,辅助位一般初始化为0。
3. 进行循环,执行移位和加减运算Booth乘法器的第三步是进行循环,每次循环都要进行移位和加减运算。
具体来说,在每一次循环中,都将乘数向右移动一位,并将最后一位的值赋给辅助位。
然后,根据当前乘数的最后一位和辅助位的值,选择加上或者减去被乘数。
4. 得出结果Booth乘法器的最后一步是得出结果。
具体来说,将得到的答案转化为二进制补码形式,然后去掉最左侧辅助位即可得到最终的八位乘积。
除了上述四个步骤外,还有一些细节需要注意。
例如,在进行加减运算时,要先将乘数和被乘数进行符号扩展,将它们分别扩展为一个9位数,扩展时要将第8位的符号复制到第9位。
此外,在进行移位时,要注意移位后最左侧位的值是否为1,如果是1,要进行2次减法。
综上所述,Booth乘法器可以大大加快二进制乘法的运算速度,是一种十分实用的计算方法。
vivado 定点数乘法

在Vivado设计套件中实现定点数乘法通常涉及到几个步骤,包括定点数的表示、乘法器的选择以及乘法操作的实现。
以下是详细的步骤:1. 定点数表示:首先确定定点数的位宽和小数点位。
例如,一个8位的定点数可能有4位整数部分和4位小数部分。
定点数的表示形式将直接影响乘法操作和结果的处理。
2. 选择乘法器:在Vivado的IP Catalog中,选择合适的乘法器。
对于定点数乘法,可以使用通用的并行乘法器(Parallel Multiplier)。
配置乘法器的参数时,需要指定数据位宽和小数点位。
3. 乘法器配置:在IP配置界面中,设置乘法器的类型(如无符号或有符号)、位宽、小数点位等参数。
如果是有符号定点数乘法,确保IP支持符号位的扩展(如使用二进制补码表示法)。
4. 生成IP核:配置完成后,生成IP核,并将其添加到项目中。
5. 编写测试平台:使用VHDL或Verilog编写测试平台(testbench),以验证定点数乘法器的功能。
在测试平台中生成输入信号,运行乘法器,并检查输出结果是否正确。
6. 仿真和验证:在Vivado Simulator中运行测试平台,进行仿真验证。
检查乘法结果是否符合预期,并确保在所有可能的输入组合下都能正常工作。
7. 综合和实现:一旦仿真验证通过,可以对设计进行综合(Synthesis)和实现(Implementation)。
在这一步中,Vivado会将硬件描述语言代码转换成可以在FPGA上实现的门级逻辑。
8. 硬件测试:最后,将设计下载到FPGA板上,进行实际的硬件测试,确保在真实硬件环境中定点数乘法器也能正常工作。
在整个设计流程中,需要特别注意定点数溢出和舍入问题。
设计时可能需要引入饱和机制或舍入逻辑,以确保乘法结果的准确性和可靠性。
此外,为了优化性能和资源利用率,可能还需要对乘法器的实现进行时序分析和优化。
8位硬件乘法器设计
end
endmodule
4.基于时序电路的移位相加乘法器-8位加法器
module adder8(cin,A,B,S,cout);
input cin;
input[7:0] A,B;
output[7:0] S;
output cout;
assign {cout,S}=cin+A+B;
2016年10月31日
学号
指导教师
王红航
成绩
批改时间
2016年月日
报告内容
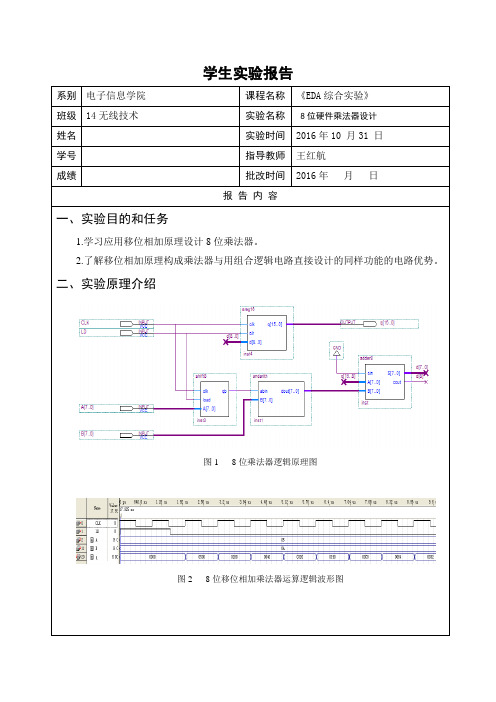
一、实验目的和任务
1.学习应用移位相加原理设计8位乘法器。
2.了解移位相加原理构成乘法器与用组合逻辑电路直接设计的同样功能的电路优势。
二、实验原理介绍
图1 8位乘法器逻辑原理图
图2 8位移位相加乘法器运算逻辑波形图
三、设计代码(或原理图)、仿真波形及分析
input [7:0] A;
output qb;
reg[7:0] reg8;
always@(posedge clk or posedge load)
begin
if(load) reg8<=A;
else reg8[6:0]<=reg8[7:1];//移位相加_8位二进制加法器
end
assign qb=reg8[0];
1.基于时序电路的移位相加乘法器-16位移位寄存器
module sreg(clk,clr,d,q);
input clk,clr;
input [8:0] d;
output[15:0] q;
reg[15:0] reg16;
always@(posedge clk or posedge clr)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
8位并行乘法器
在数字信号处理中,乘法器的速度对整个芯片以
及系统性能有着重要影响。随着超大规模集成电路的
发展,高速、低功耗、版图设计规则、占用芯片面积
小等是乘法器研究的重点。
串行乘法器,通常是两个N位二进制数x、y的
乘积用简单的方法计算就是利用移位操作来实现。但
计算一次乘法需要8个周期,这种乘法器的优点是所
占用的资源是所有类型乘法器中最少的,在低速的信
号处理中有着广泛的应用,但是串行乘法器速度比较
慢、时延大。
为了加快运算速度,一般的快速乘法器通常采用
逐位并行的迭代阵列结构,将每个操作数的N位都并
行地提交给乘法器。但是一般对于FPGA来讲,进位
的速度快于加法的速度,这种阵列结构并不是最优的。
所以可以采用多级流水线的形式,将相邻的两个部分
乘积结果再加到最终的输出乘积上,即排成一个二叉
树形式的结构,这样对于N位乘法器需要lb(N)级
来实现。
一、VHDL代码
library IEEE;
use IEEE.STD_LOGIC_1164.all;
use IEEE.STD_LOGIC_ARITH.all;
use IEEE.STD_LOGIC_UNSIGNED.all;
entity chengfa is
port( clk :in std_logic;
a :in std_logic_VECTOR(7 downto 0);
b :in std_logic_VECTOR(7 downto 0);
cout:out std_logic_VECTOR(15 downto 0) );
end chengfa;
architecture one of chengfa is
signal a1,b1:std_logic_vector(3 downto 0);
signal a2,b2:std_logic_vector(7 downto 4);
signal cout1:std_logic_vector(15 downto 0);
signal cout2:std_logic_vector(15 downto 0);
signal a1b1,a2b1,a1b2,a2b2:std_logic_vector(15 downto 0);
begin
process(a,b,clk)
begin
if clk'event and clk='1' then
a1b1<="0000"&(a(5 downto 0) *b(5 downto 0));
a2b1<="00"&(a(7 downto 6)*b(5 downto 0))&"000000";
a1b2<="00"&(a(5 downto 0)*b(7 downto 6))&"000000";
a2b2<=(a(7 downto 6)*b(7 downto 6))&"000000000000";
end if;
end process;
process(clk)
begin
if clk'event and clk='1' then
cout1<=a1b1+a2b1;
cout2<=a1b2+a2b2;
end if;
end process;
process(clk)
begin
if clk'event and clk='1' then
cout<=cout1+cout2;
end if;
end process;
end one;