国家自然科学基金项目大数据分析课件

2016年国家自然科学基金项目大数据分析
2016年的国家自然科学基金项目评审结果已经出炉。科学网在已有结果的基础上,结合历史数据,对基金在不同空间尺度的分布情况进行全面考察,多角度探索科学基金分布特征。
(一)按项目类别统计2015-2016年项目数量变化趋势
根据国家自然科学基金委8月17日通告显示,共接收项目申请172843项,经初步审查受理169832项,决定资助其中的37409项,约占总数的22%。和2015年相比,增加202项。
由表可见,一方面,国家正加大力度提升较不发达地区科研机构完成项目的能力和动力,因此增加了地区科学基金项目的数量;另一方面,国家对青年科学项目的水平和要求已经提高。结合历史数据,基金总项数和基金总金额依然呈正相关。地区科研基金项目多分布在甘肃、广西、贵州、广西、云南等地区,其原因来自制度保护;其他种类基金都分布在高等院校和科研单位比较多的地区,比如北京、上海、广东等经济较发达的城市。
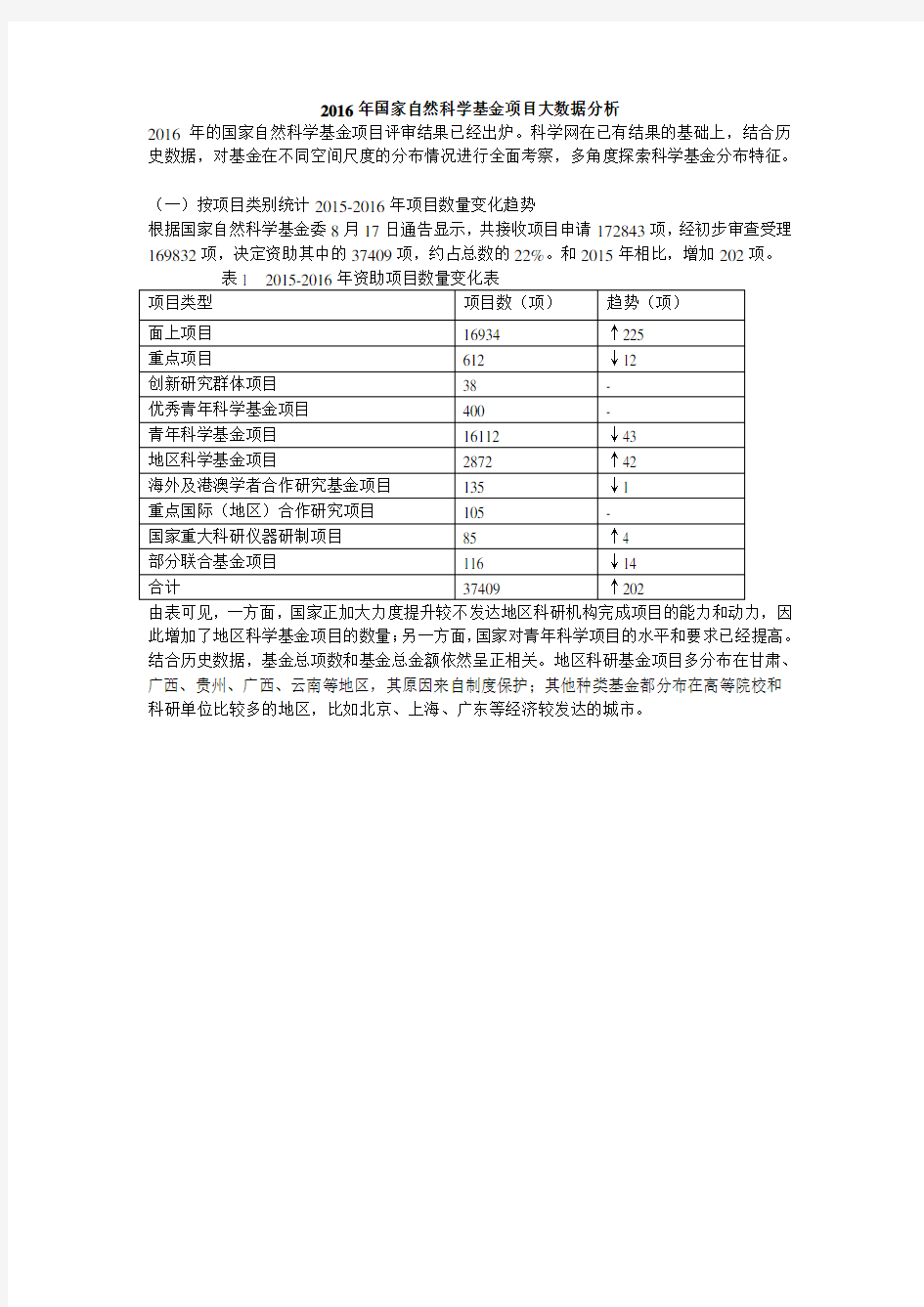
图1 省市项目金额分配(单位:万元)
如图1所示,北京市科研机构所获项目资金近38亿元,约占项目金额总数的20.8%,超过末尾18个省市区之和。分得项目资金10亿元以上的有北京、上海、江苏和广东,总数为86亿余元,约占总额的47.25%。
(二)大数据分类统计
1.单项之最
本年度自然科学基金项目单项资助最多的数额是3500万元,该项目研究方向为地球科学,被国家海洋局第一海洋研究所揽。另外,单项资助1000万元以上的项目37项,总金额42593万元,详情见表2。
表2 单项资助金额1000万以上项目统计表
序号机构名称学部金额(万元)
1 国家海洋局第一海洋研究所地球科学3500
2 中德科学基金研究交流中心管理科学2393
3 北京大学医学科学1050
4 北京大学生命科学1050
5 北京工业大学工程与材料科学1050
大数据处理技术ppt讲课稿
大数据处理技术ppt讲课稿 科信办刘伟 第一节Mapreduce编程模型: 1.技术背景: 分布式并行计算是大数据(pb)处理的有效方法,编写正确高效的大规模并行分布式程序是计算机工程领域的难题:分布式并行计算是大数据(pb)处理的有效方法,编写正确高效的大规模并行分布式程序是计算机工程领域的难题。并行计算的模型、计算任务分发、计算机结果合并、计算节点的通讯、计算节点的负载均衡、计算机节点容错处理、节点文件的管理等方面都要考虑。 谷歌的关于mapreduce论文里这么形容他们遇到的难题:由于输入的数据量巨大,因此要想在可接受的时间内完成运算,只有将这些计算分布在成百上千的主机上。如何处理并行计算、如何分发数据、如何处理错误?所有这些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处理,普通程序员无法进行大数据处理。 为了解决上述复杂的问题,谷歌设计一个新的抽象模型,使用这个抽象模型,普通程序员只要表述他们想要执行的简单运算即可,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,这些问题都被封装了,交个了后台程序来处理。这个模型就是mapreduce。 谷歌2004年公布的mapreduce编程模型,在工业、学术界产生巨大影响,以至于谈大数据必谈mapreduce。 学术界和工业界就此开始了漫漫的追赶之路。这期间,工业界试图做的事情就是要实现一个能够媲美或者比Google mapreduce更好的系统,多年的努力下来,Hadoop(开源)脱颖而出,成为外界实现MapReduce计算模型事实上的标准,围绕着Hadoop,已经形成了一个庞大的生态系统 2. mapreduce的概念: MapReduce是一个编程模型,一个处理和生成超大数据集的算法模型的相关实现。简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。 mapreduce成功的最大因素是它简单的编程模型。程序员只要按照这个框架的要求,设计map和reduce函数,剩下的工作,如分布式存储、节点调度、负载均衡、节点通讯、容错处理和故障恢复都由mapreduce框架(比如hadoop)自动完成,设计的程序有很高的扩展性。所以,站在计算的两端来看,与我们通常熟悉的串行计算没有任何差别,所有的复杂性都在中间隐藏了。它让那些没有多少并行计算和分布式处理经验的开发人员也可以开发并行应用,开发人员只需要实现map 和reduce 两个接口函数,即可完成TB级数据的计算,这也就是MapReduce的价值所在,通过简化编程模型,降低了开发并行应用的入门门槛,并行计算就可以得到更广泛的应用。 3.mapreduce的编程模型原理 开发人员用两个函数表达这个计算:Map和Reduce,首先创建一个Map函数处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合,然后再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值,就完成了大数据的处理,剩下的工作由计算机集群自动完成。 即:(input)