Oracle_LogMiner_终结版
Oracle 审计功能

Oracle 审计功能(Oracle10g)•1、什么是审计审计(Audit)用于监视用户所执行的数据库操作,审计记录可存在数据字典表(称为审计记录:存储在system表空间中的SYS.AUD$表中,可通过视图dba_audit_trail查看)或操作系统审计记录中(默认位置为$ORACLE_BASE/admin/$ORACLE_SID/adump/).。
默认情况下审计是没有开启的。
当数据库的审计是使能的,在语句执行阶段产生审计记录。
审计记录包含有审计的操作、用户执行的操作、操作的日期和时间等信息。
不管你是否打开数据库的审计功能,以下这些操作系统会强制记录:用管理员权限连接Instance;启动数据库;关闭数据库。
Oracle审计功能审计是对选定的用户动作的监控和记录,通常用于:审查可疑的活动。
例如:数据被非授权用户所删除,此时安全管理员可决定对该数据库的所有连接进行审计,以及对数据库的所有表的成功地或不成功地删除进行审计。
监视和收集关于指定数据库活动的数据。
例如:DBA可收集哪些被修改、执行了多少次逻辑的I/O等统计数据。
ORACLE所允许的审计选择限于下列方面:审计语句的成功执行、不成功执行,或者其两者。
对每一用户会话审计语句执行一次或者对语句每次执行审计一次。
对全部用户或指定用户的活动的审计。
审计相关的表安装SQLPLUS> connect / AS SYSDBASQLPLUS> select * from sys.aud$; --没有记录返回SQLPLUS> select * from dba_audit_trail; - 没有记录返回如果做上述查询的时候发现表不存在,说明审计相关的表还没有安装,需要安装。
SQLPLUS> connect / as sysdbaSQLPLUS> @$ORACLE_HOME/rdbms/admin/cataudit.sql审计表安装在SYSTEM表空间。
oracle11g常用命令

第一章:日志管理1.forcing log switchessql> alter system switch logfile;2.forcing checkpointssql> alter system checkpoint;3.adding online redo log groupssql> alter database add logfile [group 4]sql> ('/disk3/log4a.rdo','/disk4/log4b.rdo') size 1m;4.adding online redo log memberssql> alter database add logfile membersql> '/disk3/log1b.rdo' to group 1,sql> '/disk4/log2b.rdo' to group 2;5.changes the name of the online redo logfilesql> alter database rename file 'c:/oracle/oradata/oradb/redo01.log' sql> to 'c:/oracle/oradata/redo01.log';6.drop online redo log groupssql> alter database drop logfile group 3;7.drop online redo log memberssql> alter database drop logfile member 'c:/oracle/oradata/redo01.log';8.clearing online redo log filessql> alter database clear [unarchived] logfile 'c:/oracle/log2a.rdo';ing logminer analyzing redo logfilesa. in the init.ora specify utl_file_dir = ' 'b. sql> executedbms_logmnr_d.build('oradb.ora','c:\oracle\oradb\log');c. sql> executedbms_logmnr_add_logfile('c:\oracle\oradata\oradb\redo01.log',sql> dbms_logmnr.new);d. sql> executedbms_logmnr.add_logfile('c:\oracle\oradata\oradb\redo02.log',sql> dbms_logmnr.addfile);e. sql> executedbms_logmnr.start_logmnr(dictfilename=>'c:\oracle\oradb\log\oradb.ora ');f. sql> select * fromv$logmnr_contents(v$logmnr_dictionary,v$logmnr_parameterssql> v$logmnr_logs);g. sql> execute dbms_logmnr.end_logmnr;第二章:表空间管理1.create tablespacessql> create tablespace tablespace_name datafile'c:\oracle\oradata\file1.dbf' size 100m,sql> 'c:\oracle\oradata\file2.dbf' size 100m minimum extent 550k [logging/nologging]sql> default storage (initial 500k next 500k maxextents 500 pctinccease 0)sql> [online/offline] [permanent/temporary] [extent_management_clause]2.locally managed tablespacesql> create tablespace user_data datafile'c:\oracle\oradata\user_data01.dbf'sql> size 500m extent management local uniform size 10m;3.temporary tablespacesql> create temporary tablespace temp tempfile'c:\oracle\oradata\temp01.dbf'sql> size 500m extent management local uniform size 10m;4.change the storage settingsql> alter tablespace app_data minimum extent 2m;sql> alter tablespace app_data default storage(initial 2m next 2m maxextents 999);5.taking tablespace offline or onlinesql> alter tablespace app_data offline;sql> alter tablespace app_data online;6.read_only tablespacesql> alter tablespace app_data read only|write;7.droping tablespacesql> drop tablespace app_data including contents;8.enableing automatic extension of data filessql> alter tablespace app_data add datafile'c:\oracle\oradata\app_data01.dbf'size 200msql> autoextend on next 10m maxsize 500m;9.change the size fo data files manuallysql> alter database datafile 'c:\oracle\oradata\app_data.dbf'resize 200m;10.Moving data files: alter tablespacesql> alter tablespace app_data rename datafile'c:\oracle\oradata\app_data.dbf'sql> to 'c:\oracle\app_data.dbf';11.moving data files:alter databasesql> alter database rename file 'c:\oracle\oradata\app_data.dbf'sql> to 'c:\oracle\app_data.dbf';第三章:表1.create a tablesql> create table table_name (column datatype,column datatype]....) sql> tablespace tablespace_name [pctfree integer] [pctused integer] sql> [initrans integer] [maxtrans integer]sql> storage(initial 200k next 200k pctincrease 0 maxextents 50)sql> [logging|nologging] [cache|nocache]2.copy an existing tablesql> create table table_name [logging|nologging] as subquery3.create temporary tablesql> create global temporary table xay_temp as select * from xay;on commit preserve rows/on commit delete rows4.pctfree = (average row size - initial row size) *100 /average row size pctused = 100-pctfree- (average row size*100/available data space)5.change storage and block utilization parametersql> alter table table_name pctfree=30 pctused=50 storage(next 500k sql> minextents 2 maxextents 100);6.manually allocating extentssql> alter table table_name allocate extent(size 500k datafile'c:/oracle/data.dbf');7.move tablespacesql> alter table employee move tablespace users;8.deallocate of unused spacesql> alter table table_name deallocate unused [keep integer]9.truncate a tablesql> truncate table table_name;10.drop a tablesql> drop table table_name [cascade constraints];11.drop a columnsql> alter table table_name drop column comments cascade constraints checkpoint 1000;alter table table_name drop columns continue;12.mark a column as unusedsql> alter table table_name set unused column comments cascade constraints;alter table table_name drop unused columns checkpoint 1000;alter table orders drop columns continue checkpoint 1000data_dictionary : dba_unused_col_tabs第四章:索引1.creating function-based indexessql> create index summit.item_quantity onsummit.item(quantity-quantity_shipped);2.create a B-tree indexsql> create [unique] index index_name on table_name(column,.. asc/desc) tablespacesql> tablespace_name [pctfree integer] [initrans integer] [maxtrans integer]sql> [logging | nologging] [nosort] storage(initial 200k next 200k pctincrease 0sql> maxextents 50);3.pctfree(index)=(maximum number of rows-initial number ofrows)*100/maximum number of rows4.creating reverse key indexessql> create unique index xay_id on xay(a) reverse pctfree 30storage(initial 200ksql> next 200k pctincrease 0 maxextents 50) tablespace indx;5.create bitmap indexsql> create bitmap index xay_id on xay(a) pctfree 30 storage( initial 200k next 200ksql> pctincrease 0 maxextents 50) tablespace indx;6.change storage parameter of indexsql> alter index xay_id storage (next 400k maxextents 100);7.allocating index spacesql> alter index xay_id allocate extent(size 200k datafile'c:/oracle/index.dbf');8.alter index xay_id deallocate unused;第五章:约束1.define constraints as immediate or deferredsql> alter session set constraint[s] = immediate/deferred/default;set constraint[s] constraint_name/all immediate/deferred;2. sql> drop table table_name cascade constraintssql> drop tablespace tablespace_name including contents cascade constraints3. define constraints while create a tablesql> create table xay(id number(7) constraint xay_id primary key deferrablesql> using index storage(initial 100k next 100k) tablespace indx);primary key/unique/references table(column)/check4.enable constraintssql> alter table xay enable novalidate constraint xay_id;5.enable constraintssql> alter table xay enable validate constraint xay_id;第六章:LOAD数据1.loading data using direct_load insertsql> insert /*+append */ into emp nologgingsql> select * from emp_old;2.parallel direct-load insertsql> alter session enable parallel dml;sql> insert /*+parallel(emp,2) */ into emp nologgingsql> select * from emp_old;ing sql*loadersql> sqlldr scott/tiger \sql> control = ulcase6.ctl \sql> log = ulcase6.log direct=true第七章:reorganizing dataing expoty$exp scott/tiger tables(dept,emp) file=c:\emp.dmp log=exp.log compress=n direct=ying import$imp scott/tiger tables(dept,emp) file=emp.dmp log=imp.log ignore=y3.transporting a tablespacesql>alter tablespace sales_ts read only;$exp sys/.. file=xay.dmp transport_tablespace=y tablespace=sales_tstriggers=n constraints=n$copy datafile$imp sys/.. file=xay.dmp transport_tablespace=ydatafiles=(/disk1/sles01.dbf,/disk2/sles02.dbf)sql> alter tablespace sales_ts read write;4.checking transport setsql> DBMS_tts.transport_set_check(ts_list=>'sales_ts' ..,incl_constraints=>true);在表transport_set_violations 中查看sql> dbms_tts.isselfcontained 为true 是,表示自包含第八章: managing password security and resources1.controlling account lock and passwordsql> alter user juncky identified by oracle account unlock;er_provided password functionsql> function_name(userid in varchar2(30),password in varchar2(30),old_password in varchar2(30)) return boolean3.create a profile : password settingsql> create profile grace_5 limit failed_login_attempts 3sql> password_lock_time unlimited password_life_time 30sql>password_reuse_time 30 password_verify_function verify_function sql> password_grace_time 5;4.altering a profilesql> alter profile default failed_login_attempts 3sql> password_life_time 60 password_grace_time 10;5.drop a profilesql> drop profile grace_5 [cascade];6.create a profile : resource limitsql> create profile developer_prof limit sessions_per_user 2sql> cpu_per_session 10000 idle_time 60 connect_time 480;7. view => resource_cost : alter resource costdba_Users,dba_profiles8. enable resource limitssql> alter system set resource_limit=true;第九章:Managing users1.create a user: database authenticationsql> create user juncky identified by oracle default tablespace users sql> temporary tablespace temp quota 10m on data password expire sql> [account lock|unlock] [profile profilename|default];2.change user quota on tablespacesql> alter user juncky quota 0 on users;3.drop a usersql> drop user juncky [cascade];4. monitor userview: dba_users , dba_ts_quotas第十章:managing privileges1.system privileges: view =>system_privilege_map ,dba_sys_privs,session_privs2.grant system privilegesql> grant create session,create table to managers;sql> grant create session to scott with admin option;with admin option can grant or revoke privilege from any user or role;3.sysdba and sysoper privileges:sysoper: startup,shutdown,alter database open|mount,alter database backup controlfile,alter tablespace begin/end backup,recover databasealter database archivelog,restricted sessionsysdba: sysoper privileges with admin option,create database,recover database until4.password file members: view:=> v$pwfile_users5.O7_dictionary_accessibility =true restriction access to view or tables in other schema6.revoke system privilegesql> revoke create table from karen;sql> revoke create session from scott;7.grant object privilegesql> grant execute on dbms_pipe to public;sql> grant update(first_name,salary) on employee to karen with grant option;8.display object privilege : view => dba_tab_privs, dba_col_privs9.revoke object privilegesql> revoke execute on dbms_pipe from scott [cascade constraints];10.audit record view :=> sys.aud$11. protecting the audit trailsql> audit delete on sys.aud$ by access;12.statement auditingsql> audit user;13.privilege auditingsql> audit select any table by summit by access;14.schema object auditingsql> audit lock on summit.employee by access whenever successful;15.view audit option : view=>all_def_audit_opts,dba_stmt_audit_opts,dba_priv_audit_opts,dba_obj_audit_opts16.view audit result: view=>dba_audit_trail,dba_audit_exists,dba_audit_object,dba_audit_session,dba_audit_statement第十一章: manager role1.create rolessql> create role sales_clerk;sql> create role hr_clerk identified by bonus;sql> create role hr_manager identified externally;2.modify rolesql> alter role sales_clerk identified by commission; sql> alter role hr_clerk identified externally;sql> alter role hr_manager not identified;3.assigning rolessql> grant sales_clerk to scott;sql> grant hr_clerk to hr_manager;sql> grant hr_manager to scott with admin option;4.establish default rolesql> alter user scott default role hr_clerk,sales_clerk; sql> alter user scott default role all;sql> alter user scott default role all except hr_clerk; sql> alter user scott default role none;5.enable and disable rolessql> set role hr_clerk;sql> set role sales_clerk identified by commission; sql> set role all except sales_clerk;sql> set role none;6.remove role from usersql> revoke sales_clerk from scott;sql> revoke hr_manager from public;7.remove rolesql> drop role hr_manager;8.display role informationview: =>dba_roles,dba_role_privs,role_role_privs,dba_sys_privs,role_sys_privs,role_tab_privs,session_roles第十二章: BACKUP and RECOVERY1.v$sga,v$instance,v$process,v$bgprocess,v$database,v$datafile,v$sgasta t2. Rman need set dbwr_IO_slaves or backup_tape_IO_slaves andlarge_pool_size3. Monitoring Parallel Rollback> v$fast_start_servers , v$fast_start_transactions4.perform a closed database backup (noarchivelog)> shutdown immediate> cp files /backup/> startup5.restore to a different location> connect system/manager as sysdba> startup mount> alter database rename file '/disk1/../user.dbf'to'/disk2/../user.dbf';> alter database open;6.recover syntax--recover a mounted database>recover database;>recover datafile '/disk1/data/df2.dbf';>alter database recover database;--recover an opened database>recover tablespace user_data;>recover datafile 2;>alter database recover datafile 2;7.how to apply redo log files automatically>set autorecovery on>recover automatic datafile 4;plete recovery:--method 1(mounted databae)>copy c:\backup\user.dbf c:\oradata\user.dbf>startup mount>recover datafile 'c:\oradata\user.dbf;>alter database open;--method 2(opened database,initially opened,not system or rollback datafile)>copy c:\backup\user.dbf c:\oradata\user.dbf (alter tablespace offline)>recover datafile 'c:\oradata\user.dbf' or>recover tablespace user_data;>alter database datafile 'c:\oradata\user.dbf' online or>alter tablespace user_data online;--method 3(opened database,initially closed not system or rollback datafile)>startup mount>alter database datafile 'c:\oradata\user.dbf' offline;>alter database open>copy c:\backup\user.dbf d:\oradata\user.dbf>alter database rename file 'c:\oradata\user.dbf'to'd:\oradata\user.dbf'>recover datafile 'e:\oradata\user.dbf' or recover tablespace user_data; >alter tablespace user_data online;--method 4(loss of data file with no backup and have all archive log) >alter tablespace user_data offline immediate;>alter database create datafile 'd:\oradata\user.dbf'as'c:\oradata\user.dbf''>recover tablespace user_data;>alter tablespace user_data online9.perform an open database backup> alter tablespace user_data begin backup;> copy files /backup/> alter database datafile '/c:/../data.dbf' end backup;> alter system switch logfile;10.backup a control file> alter database backup controlfile to 'control1.bkp';> alter database backup controlfile to trace;11.recovery (noarchivelog mode)> shutdown abort> cp files> startup12.recovery of file in backup mode>alter database datafile 2 end backup;13.clearing redo log file>alter database clear unarchived logfile group 1;>alter database clear unarchived logfile group 1 unrecoverable datafile;14.redo log recovery>alter database add logfile group 3 'c:\oradata\redo03.log'size 1000k; >alter database drop logfile group 1;>alter database open;or >cp c:\oradata\redo02.log' c:\oradata\redo01.log>alter database clear logfile 'c:\oradata\log01.log';。
OracleCDC简介及异步在线日志CDC部署示例
OracleCDC简介及异步在线⽇志CDC部署⽰例摘要最近由于⼯作需要,花时间研究了⼀下Oracle CDC功能和LogMiner⼯具,希望能找到⼀种稳定、⾼效的技术来实现Oracle增量数据抽取功能。
以下是个⼈的部分学习总结和部署实践。
1. Oracle CDC 简介很多⼈都认为,只要是涉及到数据库数据复制和增量数据抽取,都是需要购买收费软件的。
实际上,我们通过Oracle提供的CDC和LogMiner等免费⼯具也能实现数据库数据复制和增量数据抽取,各种数据复制软件只是使得获取增量数据更加便捷,或者是可以⽀持更多的扩展功能(例如:异构数据库之间的同步,ETL过程的数据清洗、装换),但实际Oracle本⾝是⽀持CDC机制,只是很少有⼈关注,操作起来也有些复杂,⽽且据传⾔并不稳定,常常见到论坛上爆出⼀些莫名其妙的问题。
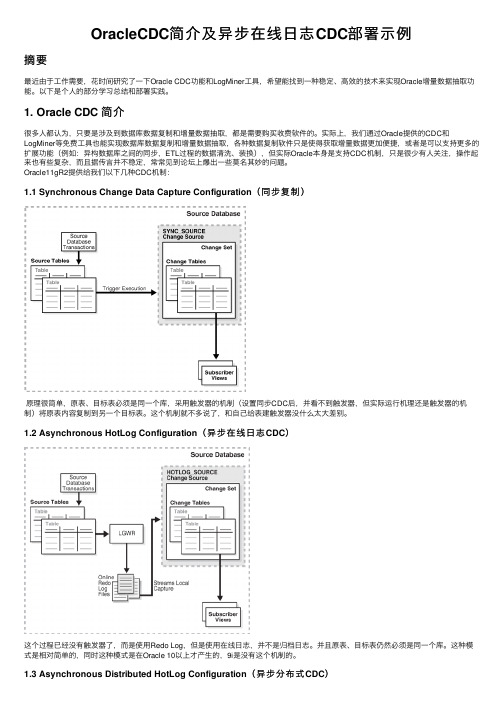
Oracle11gR2提供给我们以下⼏种CDC机制:1.1 Synchronous Change Data Capture Configuration(同步复制)原理很简单,原表、⽬标表必须是同⼀个库,采⽤触发器的机制(设置同步CDC后,并看不到触发器,但实际运⾏机理还是触发器的机制)将原表内容复制到另⼀个⽬标表。
这个机制就不多说了,和⾃⼰给表建触发器没什么太⼤差别。
1.2 Asynchronous HotLog Configuration(异步在线⽇志CDC)这个过程已经没有触发器了,⽽是使⽤Redo Log,但是使⽤在线⽇志,并不是归档⽇志。
并且原表、⽬标表仍然必须是同⼀个库。
这种模式是相对简单的,同时这种模式是在Oracle 10以上才产⽣的,9i是没有这个机制的。
1.3 Asynchronous Distributed HotLog Configuration(异步分布式CDC)实际这个模式是对异步在线⽇志CDC的⼀种优化,也⽐较容易理解,就是加⼊了DB-LINK机制,使原表、⽬标表不在同⼀个数据库。
Oracle数据库DBA面试题50道及答案_经典

Oracle数据库DBA面试题50道及答案_经典1. 解释冷备份和热备份的不同点以及各自的优点解答:热备份针对归档模式的数据库,在数据库仍旧处于工作状态时进行备份。
而冷备份指在数据库关闭后,进行备份,适用于所有模式的数据库。
热备份的优点在于当备份时,数据库仍旧可以被使用并且可以将数据库恢复到任意一个时间点。
冷备份的优点在于它的备份和恢复操作相当简单,并且由于冷备份的数据库可以工作在非归档模式下,数据库性能会比归档模式稍好。
(因为不必将archive log写入硬盘)2. 你必须利用备份恢复数据库,但是你没有控制文件,该如何解决问题呢?解答:重建控制文件,用带backup control file 子句的recover 命令恢复数据库。
3. 如何转换init.ora到spfile?解答:使用create spfile from pfile 命令.4. 解释data block , extent 和 segment的区别(这里建议用英文术语)解答:data block是数据库中最小的逻辑存储单元。
当数据库的对象需要更多的物理存储空间时,连续的data block就组成了extent . 一个数据库对象拥有的所有extents被称为该对象的segment.5. 给出两个检查表结构的方法解答:1、DESCRIBE命令2、DBMS_METADATA.GET_DDL 包6. 怎样查看数据库引擎的报错解答:alert log.7. 比较truncate和delete 命令解答:两者都可以用来删除表中所有的记录。
区别在于:truncate是DDL 操作,它移动HWK,不需要 rollback segment .而Delete是DML操作需要rollback segment 且花费较长时间。
8. 使用索引的理由解答:快速访问表中的data block9. 给出在STAR SCHEMA中的两种表及它们分别含有的数据解答:Fact tables 和dimension tables. fact table 包含大量的主要的信息而 dimension tables 存放对fact table 某些属性描述的信息10. FACT Table上需要建立何种索引?解答:位图索引(bitmap index)11. 给出两种相关约束?解答:主键和外键12. 如何在不影响子表的前提下,重建一个母表解答:子表的外键强制实效,重建母表,激活外键13. 解释归档和非归档模式之间的不同和它们各自的优缺点解答:归档模式是指你可以备份所有的数据库 transactions并恢复到任意一个时间点。
RMAN-08137:警告:因为仍需要归档日志,所以未删除问题解决

RMAN-08137:警告:因为仍需要归档⽇志,所以未删除问题解决环境:windowsXP oracle11g 开发数据库情景:⽤户登录失败,提⽰只有内部账号才能登陆,查看alert⽂件及trace⽂件得到下⾯⼀些信息ORA-16014: log 1 sequence# 401 not archived, no available destinationsORA-19815: WARNING: db_recovery_file_dest_size of 10737418240 bytes is 99.99% used, and has 685568 remaining bytes available. ************************************************************************You have following choices to free up space from flash recovery area:1. Consider changing RMAN RETENTION POLICY. If you are using Data Guard,then consider changing RMAN ARCHIVELOG DELETION POLICY.2. Back up files to tertiary device such as tape using RMANBACKUP RECOVERY AREA command.3. Add disk space and increase db_recovery_file_dest_size parameter toreflect the new space.4. Delete unnecessary files using RMAN DELETE command. If an operatingsystem command was used to delete files, then use RMAN CROSSCHECK andDELETE EXPIRED commands.************************************************************************过程:提⽰⽐较明显,归档空间不够了,⽆法归档,⽽且给出了解决办法,在sqlplus中 conn / as sysdba可以连接数据库,查看参数设置show parameter db_recovery_file_dest -->d:\oracle\flash_recovery_areadshow parameter db_recovery_file_dest_size -->10G查看实际⽬录下却是有很多归档⽇志沾满了空间,然后⼿⼯删除所有的归档⽇志(因为是开发库),仍然提⽰相同的错误,查看空间:select * from V$FLASH_RECOVERY_AREA_USAGE;使⽤率⼏乎是100%,还剩余200多个⽂件,靠,不对啊,我已经把⽂件夹都清空了啊!!不⾏就改参数吧,alter system set b_recovery_file_dest_size =20G scope=both;再查⼀下空间使⽤情况:使⽤率是百分之五⼗左右,⽂件数还是200多个,空间好像增⼤了,为了保险起见重启了数据库,理论上是不需要重启的因为 scope=both,终于可以正常启动,哈哈,再⼀想,没有解决根本问题啊,还有200多个⽂件删除不了啊,照这样下去多少空间也不够啊!google了⼀把才明⽩必须⽤rman删除才⾏,恍然明⽩了上⾯列出的trance⽂件中的解决⽅案,原来这个空间是rman来管理的,只是⼿⼯删除操作系统⽂件还不⾏,必须通过rman删除,好,那就⽤rman删除吧,命令如下:crosscheck archivelog all;返回:对归档⽇志的验证失败靠,怎么还失败了!再执⾏:delete noprompt expired archivelog all;返回:RMAN-08137: 警告: 因为仍需要归档⽇志, 所以未删除抓狂上了趟厕所,继续google,有⼈说oracle 11g有bug删除归档⽇志需要⽤force关键字,赶紧试⼀下delete noprompt force archivelog all;再次查看空间,变成了百分之零点⼏,⽂件数也为0,好使,终于搞定了,苍天呐!!。
数据库日志查看方式

SQL Server在SQL Server 7.0和SQL Server2000中,可以用下面的命令查看事务日志:DBCC log ( {dbid|dbname}, [, type={0|1|2|3|4}] )参数:Dbid or dbname - 任一数据库的ID或名字type - 输出结果的类型:0 - 最少信息(operation, context, transaction id)1 - 更多信息(plus flags, tags, row length)2 - 非常详细的信息(plus object name, index name,page id, slot id)3 - 每种操作的全部信息4 - 每种操作的全部信息加上该事务的16进制信息默认type = 0要查看MSATER数据库的事务日志可以用以下命令:DBCC log (master)错误日志找到SQL server,点属性,点开advance选项卡,里面有个dump directory后面那个目录就是你的日志文件存放的目录这时你复制那个目录下来,在资源管理器中打开那个目录,里面的ERORRLOG就是日志文件啦,用记事本打开OracleOracle日志查看一.Oracle日志的路径:登录:sqlplus "/as sysdba"查看路径:SQL> select * from v$logfile;SQL> select * from v$logfile;(#日志文件路径)二.Oracle日志文件包含哪些内容:(日志的数量可能略有不同)control01.ctl example01.dbf redo02.log sysaux01.dbf undotbs01.dbfcontrol02.ctl redo03.log system01.dbf users01.dbfcontrol03.ctl redo01.log SHTTEST.dbf temp01.dbf三.Oracle日志的查看方法:SQL>select * from v$sql (#查看最近所作的操作)SQL>select * fromv $sqlarea(#查看最近所作的操作)Oracle 数据库的所有更改都记录在日志中,从目前来看,分析Oracle日志的唯一方法就是使用Oracle公司提供的LogMiner来进行,因为原始的日志信息我们根本无法看懂,Oracle8i 后续版本中自带了LogMiner,而LogMiner就是让我们看懂日志信息的工具,通过这个工具可以:查明数据库的逻辑更改,侦察并更正用户的误操作,执行事后审计,执行变化分析。
Oracle错误代码大全
Oracle错误代码大全ORA-00001: 违反唯一约束条件ORA-00017: 请求会话以设置跟踪事件ORA-00018: 超出最大会话数ORA-00019: 超出最大会话许可数ORA-00020: 超出最大进程数ORA-00021: 会话附属于其它某些进程;无法转换会话ORA-00022: 无效的会话ID;访问被拒绝ORA-00023: 会话引用进程私用内存;无法分离会话ORA-00024: 单一进程模式下不允许从多个进程注册ORA-00025: 无法分配ORA-00026: 丢失或无效的会话IDORA-00027: 无法删去当前会话ORA-00028: 您的会话己被删去ORA-00029: 会话不是用户会话ORA-00030: 用户会话ID 不存在。
ORA-00031: 标记要删去的会话ORA-00032: 无效的会话移植口令ORA-00033: 当前的会话具有空的移植口令ORA-00034: 无法在当前PL/SQL 会话中ORA-00035: LICENSE_MAX_USERS 不能小于当前用户数ORA-00036: 超过递归SQL () 级的最大值ORA-00037: 无法转换到属于不同服务器组的会话ORA-00038: 无法创建会话: 服务器组属于其它用户ORA-00050: 获取入队时操作系统出错ORA-00051: 等待资源超时ORA-00052: 超出最大入队资源数()ORA-00053: 超出最大入队数ORA-00054: 资源正忙,要求指定NOWAITORA-00055: 超出DML 锁的最大数ORA-00056: 对象'.' 上的DDL 锁以不兼容模式挂起ORA-00057: 超出临时表锁的最大数ORA-00058: DB_BLOCK_SIZE 必须为才可安装此数据库(非) ORA-00059: 超出DB_FILES 的最大值ORA-00060: 等待资源时检测到死锁ORA-00061: 另一个例程设置了不同的DML_LOCKSORA-00062: 无法获得DML 全表锁定;DML_LOCKS 为0 ORA-00063: 超出LOG_FILES 的最大数ORA-00064: 对象过大以至无法分配在此O/S (,)ORA-00065: FIXED_DATE 的初始化失败ORA-00066: LOG_FILES 为但需要成为才可兼容ORA-00067: 值对参数无效;至少必须为ORA-00068: 值对参数无效,必须在和之间ORA-00069: 无法获得锁定-- 禁用了表锁定ORA-00070: 命令无效ORA-00071: 进程号必须介于 1 和之间ORA-00072: 进程""不活动ORA-00073: 命令介于和个参数之间时使用ORA-00074: 未指定进程ORA-00075: 在此例程未找到进程""ORA-00076: 未找到转储ORA-00077: 转储无效ORA-00078: 无法按名称转储变量ORA-00079: 未找到变量ORA-00080: 层次指定的全局区域无效ORA-00081: 地址范围[,) 不可读ORA-00082: 的内存大小不在有效集合[1], [2], [4] 之内ORA-00083: 警告: 可能损坏映射的SGAORA-00084: 全局区域必须为PGA, SGA 或UGAORA-00085: 当前调用不存在ORA-00086: 用户调用不存在ORA-00087: 命令无法在远程例程上执行ORA-00088: 共享服务器无法执行命令ORA-00089: ORADEBUG 命令中无效的例程号ORA-00090: 未能将内存分配给群集数据库ORADEBUG 命令ORA-00091: LARGE_POOL_SIZE 至少必须为ORA-00092: LARGE_POOL_SIZE 必须大于LARGE_POOL_MIN_ALLOC ORA-00093: 必须介于和之间ORA-00094: 要求整数值ORA-00096: 值对参数无效,它必须来自之间ORA-00097: 使用Oracle SQL 特性不在SQL92 级中ORA-00099: 等待资源时发生超时,可能是PDML 死锁所致ORA-00100: 未找到数据ORA-00101: 系统参数DISPATCHERS 的说明无效ORA-00102: 调度程序无法使用网络协议ORA-00103: 无效的网络协议;供调度程序备用ORA-00104: 检测到死锁;全部公用服务器已锁定等待资源ORA-00105: 未配置网络协议的调度机制ORA-00106: 无法在连接到调度程序时启动/关闭数据库ORA-00107: 无法连接到ORACLE 监听器进程ORA-00108: 无法设置调度程序以同步进行连接ORA-00111: 由于服务器数目限制在, 所以没有启动所有服务器ORA-00112: 仅能创建多达(最多指定) 个调度程序ORA-00113: 协议名过长ORA-00114: 缺少系统参数SERVICE_NAMES 的值ORA-00115: 连接被拒绝;调度程序连接表已满ORA-00116: SERVICE_NAMES 名过长ORA-00117: 系统参数SERVICE_NAMES 的值超出范围ORA-00118: 系统参数DISPATCHERS 的值超出范围ORA-00119: 系统参数的说明无效ORA-00120: 未启用或安装调度机制ORA-00121: 在缺少DISPATCHERS 的情况下指定了SHARED_SERVERS ORA-00122: 无法初始化网络配置ORA-00123: 空闲公用服务器终止ORA-00124: 在缺少MAX_SHARED_SERVERS 的情况下指定了DISPATCHERSORA-00125: 连接被拒绝;无效的演示文稿ORA-00126: 连接被拒绝;无效的重复ORA-00127: 调度进程不存在ORA-00128: 此命令需要调度进程名ORA-00129: 监听程序地址验证失败''ORA-00130: 监听程序地址'' 无效ORA-00131: 网络协议不支持注册''ORA-00132: 语法错误或无法解析的网络名称''ORA-00150: 重复的事务处理IDORA-00151: 无效的事务处理IDORA-00152: 当前会话与请求的会话不匹配ORA-00153: XA 库中的内部错误ORA-00154: 事务处理监视器中的协议错误ORA-00155: 无法在全局事务处理之外执行工作ORA-00160: 全局事务处理长度超出了最大值()ORA-00161: 事务处理的分支长度非法(允许的最大长度为) ORA-00162: 外部dbid 的长度超出了最大值()ORA-00163: 内部数据库名长度超出了最大值()ORA-00164: 在分布式事务处理中不允许独立的事务处理ORA-00165: 不允许对远程操作进行可移植分布式自治转换ORA-00200: 无法创建控制文件ORA-00201: 控制文件版本与ORACLE 版本不兼容ORA-00202: 控制文件: ''ORA-00203: 使用错误的控制文件ORA-00204: 读控制文件时出错(块,# 块)ORA-00205: 标识控制文件出错,有关详情,请检查警告日志ORA-00206: 写控制文件时出错(块,# 块)ORA-00207: 控制文件不能用于同一数据库ORA-00208: 控制文件的名称数超出限制ORA-00209: 控制文件块大小不匹配,有关详情,请检查警告日志ORA-00210: 无法打开指定的控制文件ORA-00211: 控制文件与先前的控制文件不匹配ORA-00212: 块大小低于要求的最小大小( 字节)ORA-00213: 不能重新使用控制文件;原文件大小为,还需ORA-00214: 控制文件'' 版本与文件'' 版本不一致ORA-00215: 必须至少存在一个控制文件ORA-00216: 无法重新调整从8.0.2 移植的控制文件大小ORA-00217: 从9.0.1 进行移植无法重新调整控制文件的大小ORA-00218: 控制文件的块大小与DB_BLOCK_SIZE () 不匹配ORA-00219: 要求的控制文件大小超出了允许的最大值ORA-00220: 第一个例程未安装控制文件,有关详情,请检查警告日志ORA-00221: 写入控制文件出错ORA-00222: 操作将重新使用当前已安装控制文件的名称ORA-00223: 转换文件无效或版本不正确ORA-00224: 控制文件重设大小尝试使用非法记录类型()ORA-00225: 控制文件的预期大小与实际大小不同ORA-00226: 备用控制文件打开时不允许进行操作ORA-00227: 控制文件中检测到损坏的块: (块,# 块)ORA-00228: 备用控制文件名长度超出了最大长度ORA-00229: 操作不允许: 已挂起快照控制文件入队ORA-00230: 操作不允许: 无法使用快照控制文件入队ORA-00231: 快照控制文件未命名ORA-00232: 快照控制文件不存在, 已损坏或无法读取ORA-00233: 控制文件副本已损坏或无法读取ORA-00234: 标识或打开快照或复制控制文件时出错ORA-00235: 控制文件固定表因并发更新而不一致ORA-00236: 快照操作不允许: 挂上的控制文件为备份文件ORA-00237: 快照操作不允许: 控制文件新近创建ORA-00238: 操作将重用属于数据库一部分的文件名ORA-00250: 未启动存档器ORA-00251: LOG_ARCHIVE_DUPLEX_DEST 不能是与字符串相同的目的地ORA-00252: 日志在线程上为空,无法存档ORA-00253: 字符限制在以内,归档目的字符串超出此限制ORA-00254: 存档控制字符串'' 时出错ORA-00255: 存档日志(线程, 序列# ) 时出错ORA-00256: 无法翻译归档目的字符串ORA-00257: 存档器错误。
查看SQL数据库操作日志方法
查看SQL数据库操作日志方法在SQL数据库中,可以通过各种方法查看操作日志。
下面将介绍几种常用的方法:1.使用数据库自带的日志功能大多数SQL数据库都会记录操作日志,用于跟踪和审计数据库的活动。
可以通过查询数据库的系统视图或系统表来查看操作日志。
不同数据库有不同的实现方法,下面以MySQL为例进行说明:-使用`SHOWBINARYLOGS`语句可以查看二进制日志文件的列表。
-使用`SHOWMASTERSTATUS`语句可以查看主日志文件和当前写入位置。
-使用`SHOWSLAVESTATUS`语句可以查看备用服务器的复制状态。
2.使用数据库监控工具许多数据库监控工具提供了查看操作日志的功能,这些工具通常能够以图表形式显示数据库的活动情况。
一些著名的数据库监控工具如Nagios、Datadog、Prometheus等都支持查看SQL数据库的操作日志。
3. 使用SQL Profiler工具SQL Profiler是微软提供的一个用于监视和分析SQL Server数据库活动的工具。
通过SQL Profiler,可以实时查看数据库的操作日志,并根据需要进行过滤和分析。
SQL Server Management Studio(SSMS)中集成了SQL Profiler,可以方便地使用。
4.使用第三方工具除了数据库厂商提供的工具外,还有一些第三方工具也提供了查看数据库操作日志的功能。
这些工具通常具有更加强大和灵活的功能,可以对数据库活动进行更深入的分析和监控。
比较常用的第三方工具有Percona Toolkit、Mytop、SQLSentry等。
5.使用日志解析工具SQL数据库的日志文件通常是二进制格式的,难以直接阅读。
为了方便查看和分析日志,可以使用一些日志解析工具。
这些工具能够将日志文件转换为易于阅读和分析的文本格式。
比较常用的日志解析工具有MySQL binlog reader、Oracle logminer等。
ORACLECMD命令(最全的)
ORACLECMD命令(最全的)启动Oracle,在cmd模式下依次启动:net start oracleservice服务名lsnrctl start 启动监听程序关闭服务为:lsnrctl stopnet stop oracleserviceData1. Oracle安装完成后的初始口令?internal/oraclesys/change_on_installsystem/managerscott/tigersysman/oem_temp2. ORACLE9IAS WEB CACHE的初始默认用户和密码?administrator/administrator3. oracle 8.0.5怎么创建数据库?用orainst。
如果有motif界面,可以用orainst /m4. oracle 8.1.7怎么创建数据库?dbassist5. oracle 9i 怎么创建数据库?dbca6. oracle中的裸设备指的是什么?裸设备就是绕过文件系统直接访问的储存空间7. oracle如何区分 64-bit/32bit 版本$ sqlplus '/ AS SYSDBA'SQL*Plus: Release 9.0.1.0.0 - Production on Mon Jul 14 17:01:09 2003(c) Copyright 2001 Oracle Corporation. All rights reserved.Connected to:Oracle9i Enterprise Edition Release 9.0.1.0.0 - ProductionWith the Partitioning optionJServer Release 9.0.1.0.0 - ProductionSQL> select * from v$version;BANNER---------------------------------------------------------------- Oracle9i Enterprise Edition Release 9.0.1.0.0 - ProductionPL/SQL Release 9.0.1.0.0 - ProductionCORE 9.0.1.0.0 ProductionTNS for Solaris: Version 9.0.1.0.0 - ProductionNLSRTL Version 9.0.1.0.0 - ProductionSQL>8. SVRMGR什么意思?svrmgrl,Server Manager.9i下没有,已经改为用SQLPLUS了sqlplus /nolog变为归档日志型的9. 请问如何分辨某个用户是从哪台机器登陆ORACLE的?SELECT machine , terminal FROM V$SESSION;10. 用什么语句查询字段呢?desc table_name 可以查询表的结构select field_name,... from ... 可以查询字段的值select * from all_tables where table_name like '%'select * from all_tab_columns where table_name='??'11. 怎样得到触发器、过程、函数的创建脚本?desc user_sourceuser_triggers12. 怎样计算一个表占用的空间的大小?select owner,table_name,NUM_ROWS,BLOCKS*AAA/1024/1024 "Size M",EMPTY_BLOCKS,LAST_ANALYZEDfrom dba_tableswhere table_name='XXX';Here: AAA is the value of db_block_size ;XXX is the table name you want to check13. 如何查看最大会话数?SELECT * FROM V$PARAMETER WHERE NAME LIKE 'proc%';SQL>SQL> show parameter processesNAME TYPE VALUE------------------------------------ ------- ------------------------------aq_tm_processes integer 1db_writer_processes integer 1job_queue_processes integer 4log_archive_max_processes integer 1processes integer 200这里为200个用户。
Oracle 11g自带的系统Job介绍
Oracle 11g Default JobsOracle 11g的自带的Job,使用select * from Dba_Scheduler_Jobs;可查询到。
介绍如下:1. ORA$AUTOTASK_CLEANThe job is created by the 11g script catmwin.sql which mentions that this job is an autotask repository data ageing job. It runs the procedure ora$age_autotask_data.2. HM_CREATE_OFFLINE_DICTIONARYThe job is created by the 11g script catmwin.sql which mentions that this is a job for creation of offline dictionary for Database Repair Advisor.The system job SYS.HM_CREATE_OFFLINE_DICTIONARY executes thedbms_hm.create_offline_dictionary package which creates a LogMiner offline dictionary in the ADR for DRA name translation service. The job for generating the logminer dictionary is scheduled during the maintenance window. This job can be disabled. ‘3. DRA_REEVALUATE_OPEN_FAILURESThe job is created by the 11g script catmwin.sql which mentions that this is a job for reevaluate open failures for Database Repair Advisor. The job executes the procedure dbms_ir.reevaluateopenfailures.4. MGMT_CONFIG_JOB - comes with the OCM(Oracle Configuration Manager) installation - This is a configuration collection job.The job is created by the script ocmjb10.sql by running procedure‘ORACLE_OCM.MGMT_CONFIG.collect_config’.5. MGMT_STATS_CONFIG_JOBThis is an OCM Statistics collection job created in ocmjb10.sql by running ‘ORACLE_OCM.MGMT_CONFIG.collect_stats’.6. BSLN_MAINTAIN_STATS_JOB (替换了10G的GATHER_STATS job)This job replaces the old GATHER_STATS job. It is a compute statistics job. This job runs the BSLN_MAINTAIN_STATS_PROG program on theBSLN_MAINTAIN_STATS_SCHED schedule. The programBSLN_MAINTAIN_STATS_PROG will keep the default baseline’s statistics up-to-date.7. XMLDB_NFS_CLEANUP_JOBThe job is created in xdbu102.sql and runs the proceduredbms_xdbutil_int.cleanup_expired_nfsclients.8.下面的视图显示有关自动数据库维护任务的信息:select * from DBA_AUTOTASK_CLIENT_JOB;select * from DBA_AUTOTASK_CLIENT;select * from DBA_AUTOTASK_JOB_HISTORY; select * from DBA_AUTOTASK_WINDOW_CLIENTS; select * from DBA_AUTOTASK_CLIENT_HISTORY;。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LogMiner_终结版 Oracle LogMiner 是Oracle公司从产品8i以后提供的一个实际非常有用的分析工具,使用该工具可以轻松获得Oracle 重作日志文件(归档日志文件)中的具体内容,特别是,该工具可以分析出所有对于数据库操作的DML(insert、update、delete等)语句,另外还可分析得到一些必要的回滚SQL语句。该工具特别适用于调试、审计或者回退某个特定的事务。 LogMiner分析工具实际上是由一组PL/SQL包和一些动态视图(Oracle8i内置包的一部
分)组成,它作为Oracle数据库的一部分来发布,是8i产品提供的一个完全免费的工具。但该工具和其他Oracle内建工具相比使用起来显得有些复杂,主要原因是该工具没有提供任何的图形用户界面(GUI)。本文将详细介绍如何安装以及使用该工具。 一、 LogMiner的用途 日志文件中存放着所有进行数据库恢复的数据,记录了针对数据库结构的每一个变化,也就是对数据库操作的所有DML语句。 在Oracle 8i之前,Oracle没有提供任何协助数据库管理员来读取和解释重作日志文件内容的工具。系统出现问题,对于一个普通的数据管理员来讲,唯一可以作的工作就是将所有的log文件打包,然后发给Oracle公司的技术支持,然后静静地等待Oracle 公司技术支持给我们最后的答案。然而从8i以后,Oracle提供了这样一个强有力的工具-LogMiner。 LogMiner 工具即可以用来分析在线,也可以用来分析离线日志文件,即可以分析本身自
己数据库的重作日志文件,也可以用来分析其他数据库的重作日志文件。 总的说来,LogMiner工具的主要用途有: 1. 跟踪数据库的变化:可以离线的跟踪数据库的变化,而不会影响在线系统的性能。 2. 回退数据库的变化:回退特定的变化数据,减少point-in-time recovery的执行。 3. 优化和扩容计划:可通过分析日志文件中的数据以分析数据增长模式。 二、安装LogMiner 要安装LogMiner工具,必须首先要运行下面这样两个脚本, l $ORACLE_HOME/rdbms/admin/dbmslsm.sql 2 $ORACLE_HOME/rdbms/admin/dbmslsmd.sql. 这两个脚本必须均以SYS用户身份运行。其中第一个脚本用来创建DBMS_LOGMNR包,该包用来分析日志文件。第二个脚本用来创建DBMS_LOGMNR_D包,该包用来创建数据字典文件。 三、使用LogMiner工具 下面将详细介绍如何使用LogMiner工具。 1、 创建数据字典文件(data-dictionary)
前面已经谈到,LogMiner工具实际上是由两个新的PL/SQL内建包((DBMS_LOGMNR 和 DBMS_ LOGMNR_D)和四个V$动态性能视图(视图是在利用过程DBMS_LOGMNR.START_LOGMNR启动LogMiner时创建)组成。在使用LogMiner工具分
析redo log文件之前,可以使用DBMS_LOGMNR_D 包将数据字典导出为一个文本文件。该字典文件是可选的,但是如果没有它,LogMiner解释出来的语句中关于数据字典中的部分(如表名、列名等)和数值都将是16进制的形式,我们是无法直接理解的。例如,下面的sql语句: INSERT INTO dm_dj_swry (rydm, rymc) VALUES (00005, '张三'); LogMiner解释出来的结果将是下面这个样子, insert into Object#308(col#1, col#2) values (hextoraw('c30rte567e436'), hextoraw('4a6f686e20446f65')); 创建数据字典的目的就是让LogMiner引用涉及到内部数据字典中的部分时为他们实际的名字,而不是系统内部的16进制。数据字典文件是一个文本文件,使用包DBMS_LOGMNR_D来创建。如果我们要分析的数据库中的表有变化,影响到库的数据字典也发生变化,这时就需要重新创建该字典文件。另外一种情况是在分析另外一个数据库文件的重作日志时,也必须要重新生成一遍被分析数据库的数据字典文件。 首先在init.ora初始化参数文件中,指定数据字典文件的位置,也就是添加一个参数UTL_FILE_DIR,该参数值为服务器中放置数据字典文件的目录。如: UTL_FILE_DIR = (e:Oraclelogs) 重新启动数据库,使新加的参数生效,然后创建数据字典文件: SQL> CONNECT SYS SQL> EXECUTE dbms_logmnr_d.build( dictionary_filename => ' v816dict.ora', dictionary_location => 'e:oraclelogs'); 2、创建要分析的日志文件列表 Oracle的重作日志分为两种,在线(online)和离线(offline)归档日志文件,下面就分别来讨论这两种不同日志文件的列表创建。 (1)分析在线重作日志文件
A. 创建列表 SQL> EXECUTE dbms_logmnr.add_logfile( LogFileName=>' e:Oracleoradatasxfredo01.log', Options=>dbms_logmnr.new); B. 添加其他日志文件到列表 SQL> EXECUTE dbms_logmnr.add_logfile( LogFileName=>' e:Oracleoradatasxfredo02.log', Options=>dbms_logmnr.addfile);(2)分析离线日志文件 A.创建列表 SQL> EXECUTE dbms_logmnr.add_logfile( LogFileName=>' E:OracleoradatasxfarchiveARCARC09108.001', Options=>dbms_logmnr.new); B.添加另外的日志文件到列表 SQL> EXECUTE dbms_logmnr.add_logfile( LogFileName=>' E:OracleoradatasxfarchiveARCARC09109.001', Options=>dbms_logmnr.addfile);关于这个日志文件列表中需要分析日志文件的个数完全由你自己决定,但这里建议最好是每次只添加一个需要分析的日志文件,在对该文件分析完毕后,再添加另外的文件。
和添加日志分析列表相对应,使用过程 'dbms_logmnr.removefile' 也可以从列表中移去一个日志文件。下面的例子移去上面添加的日志文件e:Oracleoradatasxfredo02.log。
SQL> EXECUTE dbms_logmnr.add_logfile( LogFileName=>' e:Oracleoradatasxfredo02.log', Options=>dbms_logmnr. REMOVEFILE); 创建了要分析的日志文件列表,下面就可以对其进行分析了。 3、使用LogMiner进行日志分析 (1)无限制条件 SQL> EXECUTE dbms_logmnr.start_logmnr( DictFileName=>' e:oraclelogs v816dict.ora '); (2)有限制条件 通过对过程DBMS_ LOGMNR.START_LOGMNR中几个不同参数的设置(参数含义见表1),可以缩小要分析日志文件的范围。通过设置起始时间和终止时间参数我们可以限制只分析某一时间范围的日志。如下面的例子,我们仅仅分析2001年9月18日的日志,:
SQL> EXECUTE dbms_logmnr.start_logmnr( DictFileName => ' e:oraclelogs v816dict.ora ', StartTime => to_date('2001-9-18 00:00:00','YYYY-MM-DD HH24:MI:SS') EndTime => to_date(''2001-9-18 23:59:59','YYYY-MM-DD HH24:MI:SS ')); 也可以通过设置起始SCN和截至SCN来限制要分析日志的范围: SQL> EXECUTE dbms_logmnr.start_logmnr( DictFileName => ' e:oraclelogs v816dict.ora ', StartScn => 20, EndScn => 50); 表1 DBMS_LOGMNR.START__LOGMNR过程参数含义
4、观察分析结果(v$logmnr_contents) 到现在为止,我们已经分析得到了重作日志文件中的内容。动态性能视图v$logmnr_contents包含LogMiner分析得到的所有的信息。
SELECT sql_redo FROM v$logmnr_contents; 如果我们仅仅想知道某个用户对于某张表的操作,可以通过下面的SQL查询得到,该查询可以得到用户DB_ZGXT对表SB_DJJL所作的一切工作。
SQL> SELECT sql_redo FROM v$logmnr_contents WHERE username='DB_ZGXT' AND tablename='SB_DJJL';
需要强调一点的是,视图v$logmnr_contents中的分析结果仅在我们运行过程'dbms_logmrn.start_logmnr'这个会话的生命期中存在。这是因为所有的LogMiner存储都
在PGA内存中,所有其他的进程是看不到它的,同时随着进程的结束,分析结果也随之消失。
最后,使用过程DBMS_LOGMNR.END_LOGMNR终止日志分析事务,此时PGA内存区域被清除,分析结果也随之不再存在。
四、其他注意事项 我们可以利用LogMiner日志分析工具来分析其他数据库实例产生的重作日志文件,而不仅仅用来分析本身安装LogMiner的数据库实例的redo logs文件。使用LogMiner分析其他数据库实例时,有几点需要注意:
1. LogMiner必须使用被分析数据库实例产生的字典文件,而不是安装LogMiner的数据库产生的字典文件,另外必须保证安装LogMiner数据库的字符集和被分析数据库的字符集相同。
2. 被分析数据库平台必须和当前LogMiner所在数据库平台一样,也就是说如果我们要分析的文件是由运行在UNIX平台上的Oracle 8i产生的,那么也必须在一个运行在UNIX平台上的Oracle实例上运行LogMiner,而不能在其他如Microsoft NT上运行LogMiner。当然两者的