数学建模数据之简单处理技巧(Mathematica)总结

数学建模数据之简单处理技巧
人们在生产实践与科学研究中经常会得到一系列的数据,然后通过这些数据得到某种内在规律,这就叫数据处理(Adjustment of Data )。科学家开发了许多方法来处理这个问题,最初由Gauss 发展起来,用于彗星轨道(Orbits of Comets )的计算以及三角测量术中。主要方法有:最小二乘平方法、平均误差及误差延伸法则、直接测量的处理、以及一个函数用较简单函数表示的问题。数据拟合(Fit )就是其中的一种。
假设已经得到数据列data1 = { y1, y2, y3,…,yn}, 现在需要寻找此数据列所满足的规律。Mathematica 系统提供了拟合命令Fit ,使用的格式如下,例如:
f[x] = Fit[ data1, { 1, x, x 2, x 3 }, x ] 表示用最小误差平方法去拟合数据data1,而且指明用32,,,1x x x 构成的函数基,线性表出拟合函数f[x]。此处,得到的拟合函数f[x] 按x = j, f[ j ] = yj (data1中第j 个数据)处理数据;
一般地,假设有2维数据 data2 = { { x 1, y 1 }, { x 2, y 2 }, … }, 则命令
Fit[ data2, { 1, f 1[x], f 2[x], … }, x ]
表示用最小误差平方法去拟合数据data2,而且指明用一元函数列{ 1, f 1[x], f 2[x], …}去线性表出拟合函数F[x]。
假设有3维数据 data3 = { { x 1, y 1, z 1 }, { x 2, y 2, z 2 }, … } }, 则命令
f[x, y] = Fit[ data3, {1,f 1[x,y],f 2[x,y],…},{x,y} ]
表示用最小误差平方法去拟合数据data3,而且指明用2元函数列{ 1, f 1[x, y], f 2[x, y], …}去线性表出拟合函数f[x, y]。
数据拟合典型例子
d = { { 1, 1}, { 2, -2 }, { 3, 3 }, { 4, -4 }, { 5, 5 }, { 6, 6 }}; g1 = ListPlot[ d, PlotStyl
e -> { Hue[ 0 ], PointSize[ .03 ] } ] f1 = Fit[ d, { 1, x, x^2, x^3, x^4 }, x ]; Print[“f1 = ”, f1]
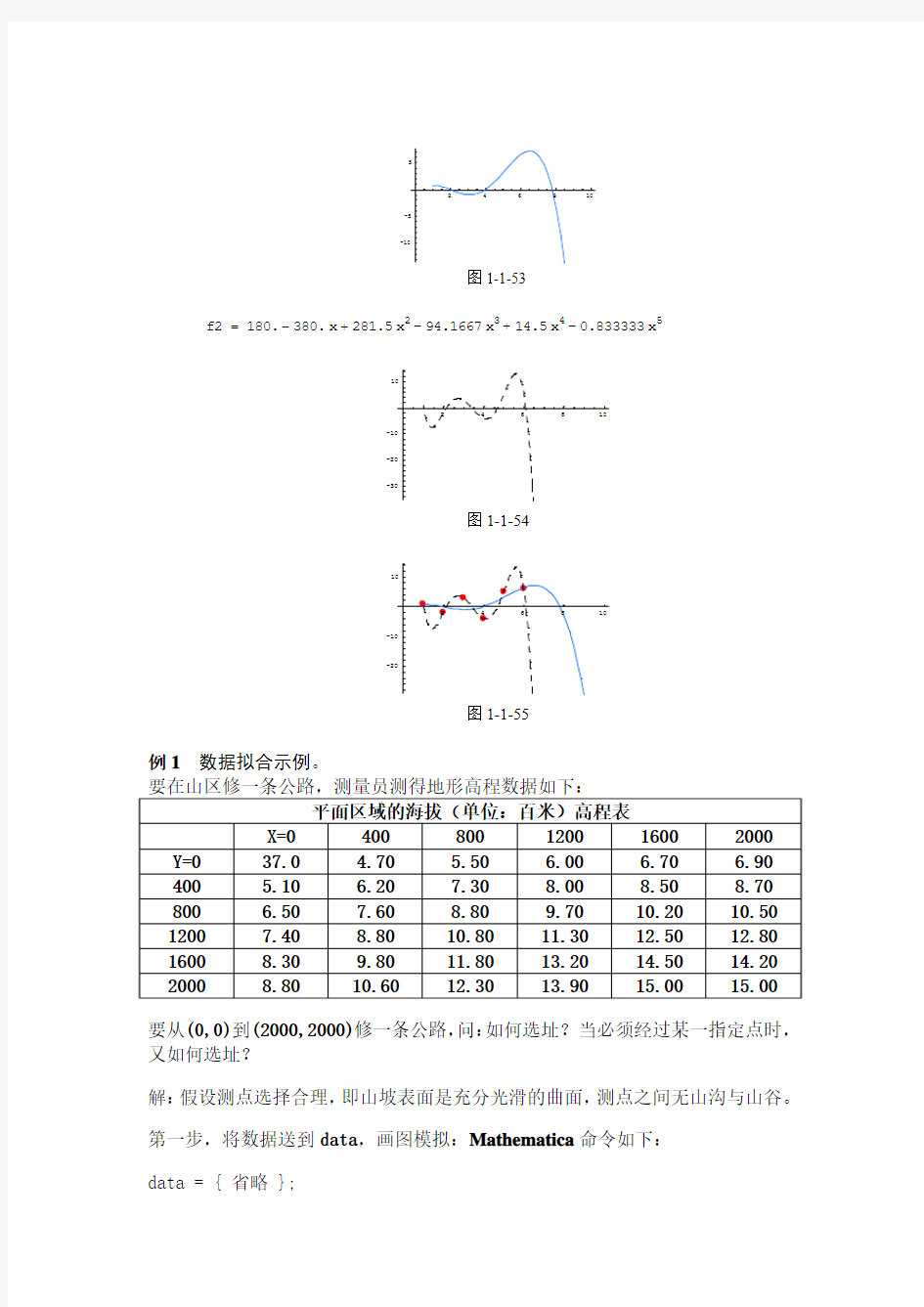
g2 = Plot[ f1, { x, 1, 10 }, PlotStyle -> Hue[ .6 ] ] f2 = Fit[ d, { 1, x, x^2, x^3, x^4, x^5}, x ]; Print[“f2 = ”, f2]
g3 = Plot[ f2, { x, 1, 10 }, PlotStyle ->{ GrayLevel[ 0 ], Dashing[ { .03 } ] } ] Show[ g1, g2, g3 ] 得到结果:
图1-1-52
f1=-3.33333+8.12169x -5.30556x 2+1.2037x 3-0.0833333x 4
图1-1-53
f2=180.-380.x+281.5x2-94.1667x3+14.5x4-0.833333x5
图1-1-54
图1-1-55
例1数据拟合示例。
要从(0,0)到(2000,2000)修一条公路,问:如何选址?当必须经过某一指定点时,又如何选址?
解:假设测点选择合理,即山坡表面是充分光滑的曲面,测点之间无山沟与山谷。
第一步,将数据送到data,画图模拟:Mathematica命令如下:
data = { 省略 };
ListPlot3D[data,ViewPoint->{*,*,*},AxesLabel->{x,y,z}]。
例如,可以选视点ViewPoint->{-1,-1,2}或{-1,1,2}画图做参考。
第二步,画三角剖分面构成的拟合曲面。打开子程序包
< TriangularSurfacePlot[data] 表示为data画一个由三角剖分面构成的拟合曲面(图像略)。 第三步,拟合。 ff = Fit[ data, { 1, x, x^2, x^3, x^4, y,y^2, y^3, y^4, x*y, x*y^2, x*y^3, x*y^4, x^2*y, x^2*y^2,x^2*y^3, x^2*y^4, x^3*y, x^3*y^2, x^3*y^3, x^3*y^4, x^4*y, x^4*y^2, x^4*y^3, x^4*y^4},{ x, y }] 程序执行后,得到一个拟合函数ff。再画ff 的图,效果更好。 Plot3D[ff,{x,0,2000},{y,0,2000}] (图像略)。 例2估计水箱流量(美国大学生MCM1991-A题) 某些州的用水管理机构需估计公众用水速度(单位:加仑/小时)和每日总用水量的数据。许多地方没有测量流入或流出市政水箱流量的设备,而只能测量水箱中的水位(误差不超过0.5%)。当水箱水位某最低水位L时,水泵抽水灌入水箱,直到水位达到最高水位H为止。但是,也无法测量水泵的流量。因此,在水泵开动时,无法立即将水箱中的水位和用水量联系起来。这种情形一天发生一次或两次,每次约为2小时。 估计所有时刻,包括水泵抽水期间流出水箱的流量f(t),并估计一天总用水量。下表给出某天某小镇的真实数据: 表中给出距开始测量的时间及即时水位。水箱是高40英尺、直径57英尺的正圆柱。通常水位低于L=27英尺时,水泵开始抽水,高于H=35.5英尺时,水泵停止工作。 参考解答: (1)由于水泵开动时,没有水位数据,所以,分段画图观察: Clear [ data ] data = { {0,31.35},{3316,31.10},{6635,30.54},{10619,29.94},{13937,29.47}, {17921,28.92},{21240,28.50},{25223,27.95},{28543,27.52},{32284,26.97}, {39435,35.50},{43118,34.45},{46636,33.50},{49953,32.60},{53936,31.67}, {57754,30.87},{60574,30.12},{64554,29.27},{68535,28.42},{71854,27.67}, {75020,26.97},{85948,34.75},{89953,33.97},{93270,33.40} }; ListPlot [ data ] 得到结果: 图1-1-56 从图上看出,水位函数h(t)是分段线性函数。分段拟合如下: d10,3135,3316,3110,6635,3054,10619,2994,13937,2947, 17921,2892,21240,2850,25223,2795,28543,2752,32284,2697; d239435,3550,43118,3445,46636,3350,49953,3260, 53936,31.67,57754,30.87,60574,30.12,64554,29.27, 68535,28.42,71854,27.67,75020,26.97; d385948,3475,89953,3397,93270,3340; h1Fit d1,1,t,t;Print"h1",h1 h2Fit d2,1,t,t;Print"h2",h2 h3Fit d3,1,t,t; Print"h3",h3 拟合后,得到结果:h1=31.4322-0.000138134t 图1-1-57 h2=44.5679-0.000236322t 图1-1-58 h3=50.6147-0.00018473t 图1-1-59 再画h(t) 的图与数据点图比较,将所画4张图放在一起,可见,拟合的非常好。 图1-1-60 (2) 水箱中的水量 )(4 57)(2t h t v π = 英尺3,流量 dt t dv t f )()(-= 英尺3/秒 于是: ] ,3[,"3int["Pr ;3*4573],2[,"2int["Pr ;2*4572] ,1[,"1int["Pr ;1*4571] 3,2,1[222t vv D f hh Pi N vv t vv D f hh Pi N vv t vv D f hh Pi N vv vv vv vv Clear -=?? ? ???=-=? ?? ???=-=?? ? ???= 得到: f1 = 36.7628 英尺3/秒; f2 = 60.2972 英尺3/秒; f3 = 47.1388 英尺3/秒; 一天的总用水量大约是: V = 36.7658*32284 + 60.2972*( 85948 – 39435 ) + 47.1388*( 93270 – 82649 ) = 6100962.4 英尺3。 (3) 再进一步就f1、f2、f3的数值,讨论管理机构应该如何操作(略)。 数据处理建模实验例题演示 例1.台湾灾难性地震的数学模型及预测 台湾处于地震多发地带,其大大小小的地震每年都要发生十几次,但由于大多数地震发生在台湾的外海地区,给台湾造成的损失不大,媒体报道,台湾地震专家认为“台湾中部、南部及北部在未来10年或数十年可能会相对平静,但花莲、台东地区发生大地震的可能性越来越高,已经进入地震警戒期”。资料显示,1900 预测,所有计算都用Mathematica 软件包计算。 1. 震级的预测 将震级看作是一个时间序列:z = { 6.5, 7.1, 7.1, 7.1, 6.5, 6.8, 7.6, 6.7, 7.5 }。用Mathematica 软件包画图观察,程序如下: z = { 6.5, 7.1, 7.1, 7.1, 6.5, 6.8, 7.6, 6.7, 7.5 }; g1=ListPlot[z,PlotJoined->True] 得到图形: 可以看出图形有震荡,规律性不强。对数据做累加处理再画图: z = { 6.5, 7.1, 7.1, 7.1, 6.5, 6.8, 7.6, 6.7, 7.5 }; zz = { 6.5, 6.5+7.1, 6.5+7.1+7.1, 6.5+7.1+7.1+7.1, 6.5+7.1+7.1+7.1+6.5, 6.5+ 7.1+7.1+7.1+6.5+6.8,6.5+7.1+7.1+7.1+6.5+6.8+7.6, 6.5+ 7.1+7.1+7.1+6.5+6.8+7.6+6.7, 6.5+7.1+7.1+7.1+6.5+6.8+7.6+6.7+7.5 }; g2=ListPlot[zz,PlotJoined->True] 图形具有很强的直线性。于是,用线性函数模拟并画图如下: z = { 6.5, 7.1, 7.1, 7.1, 6.5, 6.8, 7.6, 6.7, 7.5 }; zz = { 6.5, 6.5+7.1, 6.5+7.1+7.1, 6.5+7.1+7.1+7.1, 6.5+7.1+7.1+7.1+6.5, 6.5+ 7.1+7.1+7.1+6.5+6.8, 6.5+7.1+7.1+7.1+6.5+6.8+7.6, 6.5+ 7.1+7.1+7.1+6.5+6.8+7.6+6.7, 6.5+ 7.1+7.1+7.1+6.5+6.8+7.6+6.7+7.5 }; g2=ListPlot[zz,PlotJoined->True] fz = Fit[zz, {1, x}, x]; Print[“fz = ”,fz] g3=Plot[fz,{x,0,9},PlotStyle->RGBColor[1,0,0]] Show[g2,g3] 得到zz的图像: 得到拟合函数fz:fz = - 0.469444 + 7.005x 。拟合函数fz的图像: 把这两个图放在一起: 可见拟合得非常好。求出预测震级如下: u = fz/.x->10; u – ( 6.5+7.1+7.1+7.1+6.5+6.8+7.6+6.7+7.5 ) 得到结果:6.68056 即,台湾下一次灾难性地震的震级大约为 6.7级。 2. 地震日期的预测 首先,求出地震日期之间的间隔天数作为时间序列。打开Mathematica的日历子程序软件包: < 然后计算: a = { DaysBetween[{1904,11,6},{1906,3,17}], DaysBetween[{1906,3,17},{1935,4,11}], DaysBetween[{1935,4,11},{1941,12,17}], DaysBetween[{1941,12,17},{1964,1,18}], DaysBetween[{1964,1,18},{1986,11,15}], DaysBetween[{1986,11,15},{1999,9,21}], DaysBetween[{1999,9,21},{2001,12,18}], DaysBetween[{2001,12,18},{2002,3,30}]}; Print[“a = ”,a] ListPlot[a,PlotJoined->True] 得到结果: a = {496,10617,2442,8067,8337,4693,819,102} 图形显示数据的规律性也不强。因为数据都是正的,对数据做累加处理: a = {496,10617,2442,8067,8337,4693,819,102}; b = {496,496+10617, 496+10617+2442, 496+10617+2442+8067, 496+10617+2442+8067+8337, 496+10617+2442+8067+8337+4693, 496+10617+2442+8067+8337+4693+819, 496+10617+2442+8067+8337+4693+819+102}; g1=ListPlot[b,PlotJoined->True] 得到结果: 图形较平缓的地方说明地震间隔较短,对应灾害地震频发期,图形较陡峭的地方说明地震间隔较长,对应灾害地震休眠期。 [模型1] 数据一次累加模型 假设:台湾已经进入灾害地震休眠期 在这种假设下,图形应该向陡峭发展。于是做以下拟合: a496,10617,2442,8067,8337,4693,819,102; b496,49610617,496106172442,4961061724428067, 49610617244280678337,496106172442806783374693, 496106172442806783374693819, 496106172442806783374693819102; g1ListPlot b,PlotJoined True ff Fit b,1,x,x^2,x^3,x^4,x ^5,x; Print "ff",ff g2Plot ff,x,0,10,PlotStyle RGBColor 0,0,1 Show g1,g2 ff.x9 得到如下结果: 58779.7 这说明拟合函数ff[x]在x=9的值等于58779.7。再做计算 58779.7 – (496+10617+2442+8067+8337+4693+819+102 ) = 23207 (天) 即:在台湾已经进入灾害地震休眠期的假设下,2002年3月30日之后23207天,台湾有可能发生6.7级地震。 打开Mathematica软件包的日历功能: < DaysPlus[{2002,3,30},23207] 得到结果:{ 2065,10,12 } 结论1:在台湾已经进入灾害地震休眠期的假设下, 2002年3月30日之后23207天,也就是2065年10月12日左右,台湾有可能发生6.7级地震。 [模型2[ 数据3次累加模型 假设:台湾已经进入灾害地震休眠期 在这种假设下,图形应该向陡峭发展。将数据做3次累加,然后用3次多项式做以下拟合。 程序如下: a =8496,10617,2442,8067,8337,4693,819,102<; b1=Table A aj =1k a @j D ,8k ,1,8 b2=Table A aj =1k b1@j D ,8k ,1,8 b3=Table A aj =1 k b2@j D ,8k ,1,8 graph1=ListPlot @b3,PlotJoined ?True D f3=Fit @b3,81,x,x^2,x^3<,x D graph2=Plot @f 3,8x ,0,10<,PlotStyle ?RGBColor @1,0,0 D Show @g raph1,graph2 D 得到结果如下: (1)3次累加数据b3的图像: (2)通过拟合得到的3次多项式及其图像: 7536.36-11220.4x +4693.x 2+751.361x 3 (3)把两个图像合并起来: 可见,拟合的比较好。 (4)数据还原计算: z3=Table @f 3 .x ?j,8j ,1,12 @j D -z1@j -1D ,8j ,2,10 Print @"aa =",aa D 得到aa 如下: aa = 8 4508.17,4508.17,4508.17,4508.17,4508.17,4508.17,4508.17,4508.17,4508.17 < 于是,打开Mathematica 软件包的日历功能: < 结论2:在台湾已经进入灾害地震休眠期的假设下, 2002年3月30日之后 4508天,也就是2014年8月2日左右,台湾有可能发生6.7级地震。 [模型3] 假设台湾任然是灾害地震频发期 在这种假设下,图形应该走向平缓。于是做以下拟合: < 得到如下结果: 35692.5 119.532 可以看出图形拟合得较好。另外,求出拟合函数yy[x]在x = 9的值等于35692.5。而且,在台湾任然是灾害地震频发期的假设下,2002年3月30日之后大约120( 35692.5 – 35573 = 119.5)天,台湾有可能发生6.7级地震。 打开Mathematica软件包的日历功能: < DaysPlus[{2002,3,30},120] 得到结果:{ 2002,7,28 } 结论3:在台湾任然是灾害地震频发期的假设下,2002年3月30日之后120天,也就是2002年7月28日左右,台湾有可能发生6.7级地震。 总结如下: 结论1:在台湾已经进入灾害地震休眠期的假设下,2002年3月30日之后23207天,也就是2065年10月12日左右,台湾有可能发生6.7级地震。 结论2:在台湾已经进入灾害地震休眠期的假设下,2002年3月30日之后4508天,也就是2014年8月2日左右,台湾有可能发生6.7级地震。 结论3:在台湾任然是灾害地震频发期的假设下,2002年3月30日之后120天,也就是2002年7月28日左右,台湾有可能发生6.7级地震。 例2 艾滋病患者人数及时间预测。 问题:某城市新闻媒体报道:医疗机构发现本城市有9人发作艾滋病,过了3个月,又报道发现11人发作艾滋病,再过3个月又报道有7人发作艾滋病。请预测一下此城市一共有多少人将发作艾滋病,大约需要多长时间? 我们将尝试用不同的方法为这个问题建立模型。 [模型1]用微积分的方法建立模型。假设 (1)以上每批病人都在同一天发病,且每月按30天计算; (2)第t天发病人数为y(t),且y(t)是连续函数; 由上面假设,y(0) = 9, y(90) = 11, y(180) = 7。在Mathematica软件包中画图观察: data = { { 0, 9 }, { 90, 11 }, { 180, 7 } }; ListPlot[ data, PlotJoined -> True ] 执行后得到图像如下: 通过观察图像,我们进一步假设 (3)函数y(t)是一个2次多项式函数。于是,我们通过数据拟合求函数y(t)。 data = { { 0, 9 }, { 90, 11 }, { 180, 7 } }; y = Fit[ data, { 1, t, t2 }, t ]; Print[ “y =”, y ] 执行后得到:y = 9 + 0.0555556t – 0.00037037t2 画一下y的图像: Plot[ y, { t, -200, 300 } ] 得到图像如下: 求函数y(t)与坐标轴的两个交点,这两个交点分别代表有病人发作的最初时间和最后结束的时间。 Solve[ y == 0, t ] 执行后得到:{ { t -> - 97.9884 }, { t -> 247.988 } }。负的时间说明最初报道有9人发病之前就有人发病。这两个时间相减就得到所有病人发病总的持续时间。 247.988 – ( - 97.9884 ) = 345.976 (天),即,大约346天。 总的发病病人数 = ? -988 .2479884 .97ydt = 2556.38 (人) 结论1:此城市大约有2557人将发病,发病持续时间大约346天,换句话说,最后一个病人发病距离最初报道9人发病大约248天。 评注:这个模型简单易懂,但假设不一定合理,需要改进。改进后的模型如下: [模型2] 仍然用微积分的方法建立模型。 (1)假设第t 天发病人数为y(t),且y(t)是连续函数。因为3个数据只能确定3个未知数,所以令函数y(t)是一个2次多项式函数:y(t) = a x 2 +b x + c ; (2)假设报道的病人数都是在一段时间内发现的。即,从第一个病人发作到第一次报道时间3个月,共有9人发作,后3个月共有11人发作,再3个月共有7人发作。即 7 119; 270 180 180 9090 02===+?+?=? ??ydt ydt dt y c t b t a y 于是在Mathematica 软件包中编程如下: y =a t 2+b t +c;x1= à0 90 y at;x2= à90180 y at;x3= à180 270 y at; Solve @8x 1 9,x2 11,x3 7<,8a ,b,c :> 求y 与x 轴的交点,再编程序如下: a = - 1/243000; b = 2/2025; c = 1/15; y = a t 2 + b t + c ; Solve[ y == 0, t ] 运行后得到结果: 二者相减就是发病总时间:()() 857.3493443034430≈--+(天)。 求发病的病人总数,编程如下: a = - 1/243000; b = 2/2025; c = 1/15; y = a t 2 + b t + c ; N dt y //) 344(30) 344(30? +- 运行后得到结果:29.3707(人)。 结论2:此城市大约有30人将发病,发病持续时间大约350天,换句话说,最后一个病人发病距离最初报道9人发病大约295)344(30≈+天。 评注:这个模型简单易懂,但假设与结果都不一定合理,需要改进。进一步的模型如下: [模型3] 应用微分方程方法建立模型。 (1)假设t 时刻发病人数为y(t),且y(t)是连续函数; (2)假设此城市共有K 个人感染艾滋病毒,则在t 时刻已经感染病毒但没有发作的人数是K – y(t)。 (3)发病速度与y(t)和K – y(t)成正比,假设比例系数为a ; (4)以上每批病人都在同一天发病,且每月按30天计算;由上面假设,y(0) = 9, y(90) = 11, y(180) = 7。 依据假设建立模型如下: ()?????===-??=27 )180(,20)90(,9)0()()()(y y y t y K t y a dt t dy 应用分离变量法求解此微分方程。 () dt a y K y dy ?=-? dt K a dy y K y ??=??? ? ??-+?11 t K a t K a e c e K c y ?????+??=?1 919)0(=+?? =c K c y 20120)90(9090=?+???=??K a K a e c e K c y 27127)180(180180=?+???=??K a K a e c e K c y 令K a e x ?=90,得到方程组如下: ???????? ? =?+?+=?+?+=+?271)1(9201)1(9912 2 x c x c x c x c c K c 从后两个方程解出x : ?? ?? ? -= -=?c x c x 213 119202 于是,我们得到: c c 213119202 -= ?? ? ??- 解得:c = -1, c = 363157。将c = -1代入c x 11920 -=得到x = 1,190=??K a e ,推出a K = 0,不合题意,舍去。所以,c = 363 157 。 将c = 363157代入91=+?c K c 得到≈=157 4680 K 29.8089(人),即,此城市大约共 有30人已经感染艾滋病毒。 将c = 363157代入c x 11920-=得到x =7 33。即,1574680 ,73390==?K e K a ,推出a = 0.000577977。于是,a = 0.000577977,c = 363157,4680157=K ,t K a t K a e c e K c t y ?????+??=1)(。在区间400200≤≤-t 中画函数的图像: 由于≈= 157 4680 K 29.8089是函数y 的渐进线,所以,求使得y = 29.5的t 值: FindRoot[ y = 29.5, { t, 200 } ] 执行后得到:t = 313.267(天)。 结论3:此城市大约有30人将发病,发病持续时间大约314天。 评注:这个模型使用微分方程方法建立模型,但假设与结果都不一定合理,还需要进一步改进。 Mathematica函数及使用方法 (来源:北峰数模) --------------------------------------------------------------------- 注:为了对Mathematica有一定了解的同学系统掌握Mathematica的强大功能,我们把它的一些资料性的东西整理了一下,希望能对大家有所帮助。 --------------------------------------------------------------------- 一、运算符及特殊符号 Line1; 执行Line,不显示结果 Line1,line2 顺次执行Line1,2,并显示结果 ?name 关于系统变量name的信息 ??name 关于系统变量name的全部信息 !command 执行Dos命令 n! N的阶乘 !!filename 显示文件内容 < Expr>> filename 打开文件写 Expr>>>filename 打开文件从文件末写 () 结合率 [] 函数 {} 一个表 <*Math Fun*> 在c语言中使用math的函数 (*Note*) 程序的注释 #n 第n个参数 ## 所有参数 rule& 把rule作用于后面的式子 % 前一次的输出 %% 倒数第二次的输出 %n 第n个输出 var::note 变量var的注释"Astring " 字符串 Context ` 上下文 a+b 加 a-b 减 a*b或a b 乘 a/b 除 a^b 乘方 base^^num 以base为进位的数 lhs&&rhs 且 lhs||rhs 或 !lha 非 ++,-- 自加1,自减1 +=,-=,*=,/= 同C语言 >,<,>=,<=,==,!= 逻辑判断(同c) Mathematica函数大全--运算符及特殊符号一、运算符及特殊符号 Line1;执行Line,不显示结果 Line1,line2顺次执行Line1,2,并显示结果 ?name关于系统变量name的信息 ??name关于系统变量name的全部信息 !command执行Dos命令 n! N的阶乘 !!filename显示文件内容 a-b减 a*b或a b 乘 a/b除 a^b 乘方 base^^num以base为进位的数 lhs&&rhs且 lhs||rhs或 !lha非 ++,-- 自加1,自减1 +=,-=,*=,/= 同C语言 >,<,>=,<=,==,!=逻辑判断(同c) lhs=rhs立即赋值 lhs:=rhs建立动态赋值 lhs:>rhs建立替换规则 expr//funname相当于filename[expr] expr/.rule将规则rule应用于expr expr//.rule 将规则rule不断应用于expr知道不变为止param_ 名为param的一个任意表达式(形式变量)param__名为param的任意多个任意表达式(形式变量) 二、系统常数 Pi 3.1415....的无限精度数值 E 2.17828...的无限精度数值 Catalan 0.915966..卡塔兰常数 EulerGamma 0.5772....高斯常数 GoldenRatio 1.61803...黄金分割数 Degree Pi/180角度弧度换算 I复数单位 Infinity无穷大 Mathematica的内部常数 Pi , 或π(从基本输入工具栏输入, 或“Esc”+“p”+“Esc”)圆周率π E (从基本输入工具栏输入, 或“Esc”+“ee”+“Esc”)自然对数的底数e I (从基本输入工具栏输入, 或“Esc”+“ii”+“Esc”)虚数单位i Infinity, 或∞(从基本输入工具栏输入, 或“Esc”+“inf”+“Esc”)无穷大∞ Degree 或°(从基本输入工具栏输入,或“Esc”+“deg”+“Esc”)度 Mathematica的常用内部数学函数 指数函数Exp[x]以e为底数 对数函数Log[x]自然对数,即以e为底数的对数 Log[a,x]以a为底数的x的对数 开方函数Sqrt[x]表示x的算术平方根 绝对值函数Abs[x]表示x的绝对值 三角函数 (自变量的单位为弧度)Sin[x]正弦函数 Cos[x]余弦函数 Tan[x]正切函数 Cot[x]余切函数 Sec[x]正割函数 Csc[x]余割函数 反三角函数ArcSin[x]反正弦函数 ArcCos[x]反余弦函数 ArcTan[x]反正切函数 ArcCot[x]反余切函数 ArcSec[x]反正割函数 ArcCsc[x]反余割函数 双曲函数Sinh[x]双曲正弦函数 Cosh[x]双曲余弦函数 Tanh[x]双曲正切函数 Coth[x]双曲余切函数 Sech[x]双曲正割函数 Csch[x]双曲余割函数 反双曲函数ArcSinh[x]反双曲正弦函数 ArcCosh[x]反双曲余弦函数 ArcTanh[x]反双曲正切函数 ArcCoth[x]反双曲余切函数 ArcSech[x]反双曲正割函数 ArcCsch[x]反双曲余割函数 求角度函数ArcTan[x,y]以坐标原点为顶点,x轴正半轴为始边,从原点到点(x,y)的射线为终边的角,其单位为弧度 数论函数GCD[a,b,c,...]最大公约数函数 LCM[a,b,c,...]最小公倍数函数 数学建模的基本步骤 一、数学建模题目 1)以社会,经济,管理,环境,自然现象等现代科学中出现的新问题为背景,一般都有一个比较确切的现实问题。 2)给出若干假设条件: 1. 只有过程、规则等定性假设; 2. 给出若干实测或统计数据; 3. 给出若干参数或图形等。 根据问题要求给出问题的优化解决方案或预测结果等。根据问题要求题目一般可分为优化问题、统计问题或者二者结合的统计优化问题,优化问题一般需要对问题进行优化求解找出最优或近似最优方案,统计问题一般具有大量的数据需要处理,寻找一个好的处理方法非常重要。 二、建模思路方法 1、机理分析根据问题的要求、限制条件、规则假设建立规划模型,寻找合适的寻优算法进行求解或利用比例分析、代数方法、微分方程等分析方法从基本物理规律以及给出的资料数据来推导出变量之间函数关系。 2、数据分析法对大量的观测数据进行统计分析,寻求规律建立数学模型,采用的分析方法一般有: 1). 回归分析法(数理统计方法)-用于对函数f(x)的一组观测值(xi,fi)i=1,2,…,n,确定函数的表达式。 2). 时序分析法--处理的是动态的时间序列相关数据,又称为过程统计方法。 3)、多元统计分析(聚类分析、判别分析、因子分析、主成分分析、生存数据分析)。 3、计算机仿真(又称统计估计方法):根据实际问题的要求由计算机产生随机变量对动态行为进行比较逼真的模仿,观察在某种规则限制下的仿真结果(如蒙特卡罗模拟)。 三、模型求解: 模型建好了,模型的求解也是一个重要的方面,一个好的求解算法与一个合 适的求解软件的选择至关重要,常用求解软件有matlab,mathematica,lingo,lindo,spss,sas等数学软件以及c/c++等编程工具。 Lingo、lindo一般用于优化问题的求解,spss,sas一般用于统计问题的求解,matlab,mathematica功能较为综合,分别擅长数值运算与符号运算。 常用算法有:数据拟合、参数估计、插值等数据处理算法,通常使用spss、sas、Matlab作为工具. 线性规划、整数规划、多元规划、二次规划、动态规划等通常使用Lindo、Lingo,Matlab软件。 图论算法,、回溯搜索、分治算法、分支定界等计算机算法, 模拟退火法、神经网络、遗传算法。 四、自学能力和查找资料文献的能力: 建模过程中资料的查找也具有相当重要的作用,在现行方案不令人满意或难以进展时,一个合适的资料往往会令人豁然开朗。常用文献资料查找中文网站:CNKI、VIP、万方。 五、论文结构: 0、摘要 1、问题的重述,背景分析 2、问题的分析 3、模型的假设,符号说明 4、模型的建立(局部问题分析,公式推导,基本模型,最终模型等) 5、模型的求解 6、模型检验:模型的结果分析与检验,误差分析 7、模型评价:优缺点,模型的推广与改进 8、参考文献 9、附录 六、需要重视的问题 数学建模的所有工作最终都要通过论文来体现,因此论文的写法至关重要: 2012年北京师范大学珠海分校数学建模竞赛 题目:对中国大学生数学建模竞赛历年成绩的分析与预测 摘要 本文研究的是对自数学建模竞赛开展以来各高校建模水平的评价比较和预测问题。我们将针对题目要求,建立适当的评价模型和预测模型,主要解决对中国大学生数学建模竞赛历年成绩的评价、排序和预测问题。 首先我们用层次分析法来评价广东赛区各校2008年至2011年及全国各大高校1994至2011年数学建模成绩,从而给出广东赛区各校及全国各大高校建模成绩的科学、合理的评价及排序;其次运用灰色预测模型解决广东赛区各院校2012年建模成绩的预测。 针对问题一,首先我们对比了2008到2011年参加建模比赛的学校,通过分析我们选择了四年都参加了比赛的学校进行合理的排序(具体分析过程见表13),同时对本科甲组和专科乙组我们分别进行排序比较。在具体解决问题的过程中,我们先分析得出影响评价结果的主要因素:获奖情况和获奖比例,其中获奖情况主要考虑国家一等奖、国家二等奖、省一等奖、省二等奖、省三等奖,我们采用层次分析法,并依据判断尺度构造出各个层次的判断矩阵,对它们逐个做出一致性检验,在一致性符合要求的情况下,通过公式与matlab求得各大学的权重,总结得分并进行排序(结果见表11);在对广东赛区各高校2012建模成绩预测问题中,我们采用灰色预测模型,我们以华南农业大学为例,得到该校2012年建模比赛获奖情况为:省一等奖、省二等奖、省三等奖及成功参赛奖分别为5、9、8、8(其它各高校预测结果见表10)。 针对问题二,我们对全国各院校的自建模竞赛活动开展以来建模成绩排序采用与问题一相同的数学模型,在获奖情况考虑的是全国一等奖、全国二等奖。运用matlab求解,结果见表12。 针对问题三,我们通过对一、二问排序的解答及数据的分析,得出在对院校进评价和预测时还应考虑到各院的师资力量、学校受重视程度、学生情况、参赛经验等因素,考虑到这些因素,为以后评价高校建模水平提供更可靠的依据。 关键词:层次分析法权向量灰色预测模型模型检验 matlab Mathematica函数大全一、运算符及特殊符号 Line1; 执行Line,不显示结果 Line1,line2 顺次执行Line1,2,并显示结果 ?name 关于系统变量name的信息 ??name 关于系统变量name的全部信息 !command 执行Dos命令 n! N的阶乘 !!filename 显示文件内容 < >,<,>=,<=,==,!= 逻辑判断(同c) lhs=rhs 立即赋值 lhs:=rhs 建立动态赋值 lhs:>rhs 建立替换规则 lhs->rhs 建立替换规则 expr//funname 相当于filename[expr] expr/.rule 将规则rule应用于expr expr//.rule 将规则rule不断应用于expr知道不变为止 param_ 名为param的一个任意表达式(形式变量) param__ 名为param的任意多个任意表达式(形式变量) 二、系统常数 Pi 3.1415....的无限精度数值 E 2.17828...的无限精度数值 Catalan 0.915966..卡塔兰常数 EulerGamma 0.5772....高斯常数 GoldenRatio 1.61803...黄金分割数 Degree Pi/180角度弧度换算 I 复数单位 Infinity 无穷大 -Infinity 负无穷大 ComplexInfinity 复无穷大 Indeterminate 不定式 三、代数计算 Expand[expr] 展开表达式 Factor[expr] 展开表达式 Simplify[expr] 化简表达式 FullSimplify[expr] 将特殊函数等也进行化简 PowerExpand[expr] 展开所有的幂次形式 ComplexExpand[expr,{x1,x2...}] 按复数实部虚部展开 FunctionExpand[expr] 化简expr中的特殊函数 Collect[expr, x] 合并同次项 Collect[expr, {x1,x2,...}] 合并x1,x2,...的同次项 Together[expr] 通分 Apart[expr] 部分分式展开 Apart[expr, var] 对var的部分分式展开 Cancel[expr] 约分 ExpandAll[expr] 展开表达式 ExpandAll[expr, patt] 展开表达式 FactorTerms[poly] 提出共有的数字因子 FactorTerms[poly, x] 提出与x无关的数字因子 FactorTerms[poly, {x1,x2...}] 提出与xi无关的数字因子 Coefficient[expr, form] 多项式expr中form的系数 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MA TLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的插值计算,还有吵的沸沸扬扬可能会考的“非典”问题也要用到数据拟合算法,观察数据的 数学建模中常见的十大 模型 Document serial number【KKGB-LBS98YT-BS8CB-BSUT-BST108】 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MATLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 数学建模方法模型 一、统计学方法 1 多元回归 1、方法概述: 在研究变量之间的相互影响关系模型时候用到。具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 2、分类 分为两类:多元线性回归和非线性线性回归;其中非线性回归可以通过一定的变化转化为线性回归,比如:y=lnx 可以转化为 y=u u=lnx 来解决;所以这里主要说明多元线性回归应该注意的问题。 3、注意事项 在做回归的时候,一定要注意两件事: (1) 回归方程的显著性检验(可以通过 sas 和 spss 来解决) (2) 回归系数的显著性检验(可以通过 sas 和 spss 来解决) 检验是很多学生在建模中不注意的地方,好的检验结果可以体现出你模型的优劣,是完整论文的体现,所以这点大家一定要注意。 4、使用步骤: (1)根据已知条件的数据,通过预处理得出图像的大致趋势或者数据之间的大致关系; (2)选取适当的回归方程; (3)拟合回归参数; (4)回归方程显著性检验及回归系数显著性检验 (5)进行后继研究(如:预测等) 2 聚类分析 1、方法概述 该方法说的通俗一点就是,将 n个样本,通过适当的方法(选取方法很多,大家可以自行查找,可以在数据挖掘类的书籍中查找到,这里不再阐述)选取 m 聚类中心,通过研究各样本和各个聚类中心的距离 Xij,选择适当的聚类标准,通常利用最小距离法(一个样本归于一个类也就意味着,该样本距离该类对应的中心距离最近)来聚类,从而可以得到聚类结果,如果利用sas 软件或者 spss 软件来做聚类分析,就可以得到相应的动态聚类图。这种模型的的特点是直观,容易理解。 2、分类 聚类有两种类型: (1) Q型聚类:即对样本聚类; (2) R型聚类:即对变量聚类; 通常聚类中衡量标准的选取有两种: (1) 相似系数法 (2) 距离法 聚类方法: (1) 最短距离法 (2) 最长距离法 (3) 中间距离法 (4) 重心法 (5) 类平均法 (6) 可变类平均法 (7) 可变法 第五章 数值分析和数值计算 1. 如何求插值多项式 给定n 个点( x i ,y i ),(i=1,2,…,n),构造一个次数不超过n-1的多项式函数f(x),使得f(x i )=y i ,则称f(x)为拉格朗日插值多项式。 可以证明该多项式函数由公式 ))...()(())...()((...) )...()(())...()(())...()(())...()((1211212321231113121321--------++------+------=n n n n n n n n n n x x x x x x x x x x x x y x x x x x x x x x x x x y x x x x x x x x x x x x y y 唯一给定。 Mathematica 提供了根据插值点数据计算拉格朗日插值多项式的函数InterpolatingPolynomial ,下面是其调用格式: InterpolatingPolynomial[data,var] 作出以data 为插值点数据,以var 为变量名的插值多项式。 例: 在多数情况下,我们构造插值函数的目的在于计算函数f(x)的值,而并不在意插值多项式的具体表示形式。对于拉格朗日插值多项式,当n 较大时,得到的高次插值多项式由于截断误差和舍入误差的影响,往往误差较大。此时在实际应用中,一般采用分段插值。 Mathematica 提供了分段插值函数Interpolation ,其使用格式为: Interpolation[data,InterpolationOrder->n] 这里InterpolationOrder->n 指定插值多项式的次数,默认值为3。此外数据data 中还可以包括插值点处的导数,格式为:{{x1,{y1,dy1}},{x2,{y2,dy2}},…} 例:已知f(0)=0,f(1)=2,f’(0)=1,f’(1)=1,求3次插值多项式f(x),并计算f(0.72)和画出函数f(x)在[0,1]区间上的图形。 题目:数据的预处理问题 摘要 关键词:多元线性回归,t检验法,分段线性插值,最近方法插值,三次样条插值,三次多项式插值 一、问题重述 1.1背景 在数学建模过程中总会遇到大数据问题。一般而言,在提供的数据中,不可避免会出现较多的检测异常值,怎样判断和处理这些异常值,对于提高检测结果的准确性意义重大。 1.2需要解决的问题 (1)给出缺失数据的补充算法; (2)给出异常数据的鉴别算法; (3)给出异常数据的修正算法。 二、模型分析 2.1问题(1)的分析 属性值数据缺失经常发生甚至不可避免。 (一)较为简单的数据缺失 (1)平均值填充 如果空值为数值型的,就根据该属性在其他所有对象取值的平均 值来填充缺失的属性值;如果空值为非数值型的,则根据众数原 理,用该属性在其他所有对象的取值次数最多的值(出现频率最 高的值)来补齐缺失的属性值。 (2) 热卡填充(就近补齐) 对于包含空值的数据集,热卡填充法在完整数据中找到一个与其 最相似的数据,用此相似对象的值进行填充。 (3) 删除元组 将存在遗漏信息属性值的元组删除。 (二)较为复杂的数据缺失 (1)多元线性回归 当有缺失的一组数据存在多个自变量时,可以考虑使用多元线性回归模型。将所有变量包括因变量都先转化为标准分,再进行线性回归,此时得到的回归系数就能反映对应自变量的重要程度。 2.2问题(2)的分析 属性值异常数据鉴别很重要。 我们可以采用异常值t检验的方法比较前后两组数据的平均值,与临界值相 2.3问题(3)的分析 对于数据修正,我们采用各种插值算法进行修正,这是一种行之有效的方法。 (1)分段线性插值 将每两个相邻的节点用直线连起来,如此形成的一条折线就是分段线性插值函数,记作()x I n ,它满足()i i n y x I =,且()x I n 在每个小区间[]1,+i i x x 上是线性函数()x I n ()n i ,,1,0???=。 ()x I n 可以表示为 ()x I n 有良好的收敛性,即对于[]b a x ,∈有, 用 ()x I n 计算x 点的插值时,只用到x 左右的两个节点,计算量与节点个数n 无关。但n 越大,分段越多,插值误差越小。实际上用函数表作插值计算时,分段线性插值就足够了,如数学、物理中用的特殊函数表,数理统计中用的概率分布表等。 (2) 三次多项式算法插值 当用已知的n+1个数据点求出插值多项式后,又获得了新的数据点,要用它连同原有的n+1个数据点一起求出插值多项式,从原已计算出的n 次插值多项式计算出新的n+1次插值多项式很困难,而此算法可以克服这一缺点。 (3)三次样条函数插值[4] 数学上将具有一定光滑性的分段多项式称为样条函数。三次样条函数为:对于[]b a ,上的分划?:n x x x a 表达式: Plot[4 x - 9, {x, 0, 9}] f[x_] = x^3 Plot[f[x], {x, 0, 9}] a = Plot[4 x - 9, {x, 0, 9}] b = Plot[x^3, {x, 0, 3}] 两图画在一个坐标系 Show[a, b] a = Plot[4 x - 9, {x, 0, 9}] b = Plot[x^3, {x, 0, 3}] 两图画在一起(一排) c = GraphicsArray[{a, b}] Show[c] a = Plot[4 x - 9, {x, 0, 9}] b = Plot[x^3, {x, 0, 3}] c = GraphicsArray[{a}, {b}] 两图画在一起(两排) Show[c] 二维画图: Automatic 默认值 DisplayFunction -> Identity 不出现图 DisplayFunction -> $DisplayFunction 出现图 PlotRange -> All 画出所有点,指定区域点 PlotStyle -> {RGBColor[1, 0, 0]} 图像颜色 PlotStyle -> {Dashing[{0.01}]} 图像成虚线 PlotStyle -> {Thickness[0.01]} 图像粗细 AxesLabel -> {"x/t", "y/cm"} 坐标标签 PlotLabel -> {"s-t"} 图像标签 Frame -> True 图像边框 Axes -> {True, True} 坐标轴的显示 AxesOrigin -> {0, -5} 设置坐标原点 GridLines -> {{-π, -π/2, 0, π/2, π}, {-1,-0.5,0, 0.5, 1}} 给坐标轴分网格 TextStyle -> {FontSize -> 30} 坐标字体大小AspectRatio -> Automatic 坐标比例一致 Ticks -> {{0, 1, 2, 3}, {0,10,20}} 在坐标轴上显示特定点ParametricPlot[x(t),y(t)},{t,0,6,}] 画参数方程 现代统计学 1.因子分析(Factor Analysis) 因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量),以较少的几个因子反映原资料的大部分信息。 运用这种研究技术,我们可以方便地找出影响消费者购买、消费以及满意度的主要因素是哪些,以及它们的影响力(权重)运用这种研究技术,我们还可以为市场细分做前期分析。 2.主成分分析 主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。主成分分析一般很少单独使用:a,了解数据。(screening the data),b,和cluster analysis一起使用,c,和判别分析一起使用,比如当变量很多,个案数不多,直接使用判别分析可能无解,这时候可以使用主成份发对变量简化。(reduce dimensionality)d,在多元回归中,主成分分析可以帮助判断是否存在共线性(条件指数),还可以用来处理共线性。 主成分分析和因子分析的区别 1、因子分析中是把变量表示成各因子的线性组合,而主成分分析中则是把主成分表示成个变量的线性组合。 2、主成分分析的重点在于解释个变量的总方差,而因子分析则把重点放在解释各变量之间的协方差。 3、主成分分析中不需要有假设(assumptions),因子分析则需要一些假设。因子分析的假设包括:各个共同因子之间不相关,特殊因子(specific factor)之间也不相关,共同因子和特殊因子之间也不相关。 4、主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的时候,的主成分一般是独特的;而因子分析中因子不是独特的,可以旋转得到不同的因子。 5、在因子分析中,因子个数需要分析者指定(spss根据一定的条件自动设定,只要是特征值大于1的因子进入分析),而指定的因子数量不同而结果不同。在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分。 和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势。大致说来,当需要寻找潜在的因子,并对这些因子进行解释的时候,更加倾向于使用因子分析,并且借助旋转技术帮助更好解释。而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这中情况也可以使用因子得分做到。所以这中区分不是绝对的。 总得来说,主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。主成分分析一般很少单独使用:a,了解数据。(screening the data),b, 一.关于参赛时间分配,竞赛共72个小时完成。 下题:今年是9月11日早上8:00在https://www.360docs.net/doc/b5651967.html,下载,9月14日早8:00交试题。 选题:这三天的时间按排基本如下:11日8:00-15:00左右选题,选题分为粗选,细选。粗选就是直观的看这两道题是否平时练习相关问题或方法的,选题要对每试题的每一问都要认真分析,大至看看基本能用哪些方法,做到心中有数,对两道题都分析后在选择自已能够容易完成的一题去做。选题的过程中要去查资料、找数据、看论文,通过这些工作,你可以发现找到的东西能否够解决你选的题。 做题:11日15点-13日22点左右。从第一天下午开始去做题,做题的过程分为问题分析,数据处理,模型建立,模型求解等,一会在下边要专门讨论。 换题:如果选题后做一些后其它问题不好处理,或者没有办法处理,有人就会想到换题,当然尽可能的不要换题,要是换题一定不能晚于11日20:00,否则就有做不完题的可能。当然也因人而宜。 写论文:最迟要在13日22:00开始,到14日凌晨5:00写完,尽可能让指导教师帮着修改。7:00打印,打印好后要仔细看一遍,有问题在修改。8:00交论文。写论文的过程贯穿于选题做题过程之中,我们在选题做题时就把做的一些东西分别处理好,只是这说的写论文就是把所做的题目的不同问题,不同部分都贯穿在一起,形成一篇有血有肉的论文。论文写作应该专门有一人在做题的过程中进行。 二、关于写论文 1.正确的论文格式: 论文属于科学性的文章,它有严格的书写格式规范,因此一篇好的论文一定要有正确的格式,就拿摘要来说吧,它要包括6 要素(问题,方法,模型,算法,结论,特色),它是一篇论文的概括,摘要的好坏将决定你的论文是否吸引评委的目光,但听阅卷老师说,有些论文的摘要里出现了大量的图表和程序,这都是不符合论文格式的,这种论文也不会取得好成绩,因此我们写论文时要端正态度,注意书写格式。 2、论文的写作: 论文的写作是至关重要的,其实大家最后的模型和结果都差不多,为什么有些队可以送全国,有些队可以拿省奖,而有些队却什么都拿不到,这关键在于论文的写作上面。一篇好的论文首先读上去便使人感到逻辑清晰,有条例性,能打动评委;其次,论文在语言上的表述也很重要,要注意用词的准确性;另外,一篇好的论文应有闪光点,有自己的特色,有自己的想法和思考在里面,总之,论文写作的好坏将直接影响到成绩的优劣。 实验九数据的曲线拟合 一、实验目的与要求 学会利用Mathematica软件对已知数据进行拟合处理,并针对拟合结果的图形显示分析拟合函数的优劣 二、实验的基本知识 熟知一些曲线及其方程 三、实验的具体内容 例1现有一组实测数据 解输入数据表 L={{0,0.3},{0.2,0.45},{0.3,0.47},{0.52,0.50},{0.64,0.38},{0.7,0.33},{1.0,0.24}} 由于假设用一元二次函数拟合,因而经验函数表为{1 , x , x^2} 键入f=Fit[L,{1, x , x^2},x] 为观察拟合情况,我们在一个图上画出数据点和拟合函数,键入 ListPlot[L,PlotStyle→{RGBColor[0,1,0],PointSize[0.04]}] Plot[f,{x , -0.2 , 1.2}] Show[%,%%] 或键入fp= ListPlot[L,PlotStyle→{RGBColor[0,1,0],PointSize[0.04]}] gp= Plot[f,{x , -0.2 , 1.2}] Show[fp,gp] 运行可得拟合函数为0.33129+0.596026x-0.71812x2,并且从图形中可以观察拟合的结果,若散点图与曲线拟合不够理想,可以考虑用更高次的多项式或其它函数进行拟合。 例 2 在某化学反应里,由实验得到生物的浓度与时间的关系如下,求浓度与时间关系的拟合曲线 t(分) 1 2 3 4 5 6 7 8 y 4 6.4 8.0 8.4 9.28 9.5 9.7 9.86 t(分)9 10 11 12 13 14 15 16 y 10.0 10.2 10.32 10.42 10.5 10.55 10.58 10.6 解为确定拟合函数的类型,可先在直角坐标系中作出散点图,键入 t1={{1,4},{2,6.4,{3,8.0}},{4.8.4},{5,9.28},{6,9.5},{7,9.7},{8,9.86},{9,10.0},{10,10.2}, {11,10.32},{12,10.42},{13,10.5},{14,10.55},{15,10.58},{16,10.6}} t2=ListPlot[t1,PlotStyle→{RGBColor[0,1,0],PointSize[0.04]}] 若用四次多项式进行拟合,则键入 t3=Fit[t1,Table[x^I,{I,0,4}],x] t4=Plot[t3,{x,0,17},PlotStyle→{RGBColor[1,0,0]}] Show[t2,t4] 运行后,可得拟合函数的表达式以及散点图与拟合函数图,从图中可见二者的吻合情况是否满意。此例中,亦可用对数函数进行拟合,为此键入 t5=Fit[t1,{log[x],1},x] 第8章Mathematica中的常用函数8.1 运算符及特殊符号 Linel 执行Line,不显示结果 Linel,line2 顺次执行Line1,Line2,并显示结果 ?name 关于系统变量name的信息 ??name 关于系统变量name的全部信息 !command 执行Dos命令 N! N的阶乘 !!filename 显示文件内容 < -Infinity 负无穷大 Complexlnfinity 复无穷大 Indeterminate 不定式 8.3 代数计算 Expand[expr] 展开表达式 Factor[expr] 展开表达式 Simplify[expr] 化简表达式 FullSimplify[expr] 将特殊函数也进行化简PowerExpand[expr] 展开所有的幂次形式ComplexExpand[expr,{x1,x2…}] 按复数实部虚部展开FunctionExpand[expr] 化简表达式中的特殊函数 Collect[expr,x] 合并同次项 Collect[expr,{x1,x2,…}] 合并x1,x2,...的同次项 Together[expr] 通分 Apart[expr] 部分分式展开 Apart[expr,var] 对var的部分分式展开 Cancel[expr] 约分 ExpandAll[expr] 展开表达式 ExpandAll[expr,patt] 展开表达式 FactorTermsrpoly] 提出共有的数字因子 FactorTerms[poly,x] 提出与x无关的数字因子 FactorTerms[poly,(x1,x2…)] 提出与xi无关的数字因子 Coefficient[expr,form] 多项式expr中form的系数 Coefficient[expr,form,n] 多项式expr中form^n的系数 Exponent[expr,form] 表达式expr中form的最高指数 Numerator[expr] 表达式expr的分子 Denominator[expr] 表达式expr的分母 ExpandNumerator[expr] 展开expr的分子部分 8.4 解方程 Solve[eqns,vats] 从方程组eqns中解出Vats Solve[eqns,vats,elims] 从方程组eqns中削去变量elims,解出vats DSolve[eqn,y,x] 解微分方程,其中、y是x的函数 DSolve[{eqnl,eqn2,…},{y1,y2…},] 解微分方程组,其中yi是x的函数DSolve[eqn,y,{x1,x2…}]解偏微分方程 Eliminate[eqns,Vats] 把方程组eqns中变量vars约去SolveAlways[eqns,vars] 给出等式成立的所有参数满足的条件Reduce[eqns,Vats] 化简并给出所有可能解的条件LogicalExpand[expr] 用&&和,,将逻辑表达式展开InverseFunction[f] 求函数f的反函数 Root[f,k] 求多项式函数的第k个根 数学建模与数学实验 课程设计 学院数理学院专业数学与应用数学班级学号 学生姓名指导教师 2015年6月 数据的统计分析 摘要 问题:某校60名学生的一次考试成绩如下: 93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55 (1)计算均值、标准差、极差、偏度、峰度,画出直方图;(2)检验分布的正态性; (3)若检验符合正态分布,估计正态分布的参数并检验参数; 模型:正态分布。 方法:运用数据统计知识结合MATLAB软件 结果:符合正态分布 一. 问题重述 某校60名学生的一次考试成绩如下: 93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55 (1)计算均值、标准差、偏差、峰度,画出直方图; (2)检验分布的正态性; (3)若检验符合正态分布,估计正态分布的参数并检验参数。 二.模型假设 假设一:此组成绩没受外来因素影响。 假设二:每个学生都是独自完成考试的。 假设三:每个学生的先天条件相同。 三.分析与建立模型 像类似数据的信息量比较大,可以用MATLAB 软件决绝相关问题,将n 名学生分为x 组,每组各n\x 个学生,分别将其命为1x ,2X ……j x 由MATLAB 对随机统计量x 进行命令。此时对于直方图的命令应为 Hist(x,j) 源程序为: x1=[93 75 83 93 91 85 84 82 77 76 ] x2=[77 95 94 89 91 88 86 83 96 81 ] x3=[79 97 78 75 67 69 68 84 83 81 ]Mathematica函数及使用方法
Mathematica函数大全(内置)
Mathematica的常用函数
数学建模的基本步骤
对中国大学生数学建模竞赛历年成绩的分析与预测
Mathematica函数大全
数学建模中常见的十大模型
数学建模中常见的十大模型
数学建模方法模型
(完整版)Mathematica数值分析和数值计算
数学建模缺失大数据补充及异常大数据修正
Mathematica常用指令
数学建模各种分析报告方法
数学建模应该注意问题
Mathematica软件进行拟合
Mathematica中的常用函数命令
数学建模-数据的统计分析