12 随机算法
生成随机数的方法

生成随机数的方法
生成随机数的方法有很多种,以下是其中几种常见的方法:
1. 使用随机数生成算法:常见的随机数生成算法有线性同余法、梅森旋转算法等。
这些算法可以基于一个种子值生成一个伪随机数序列。
2. 使用随机数生成器函数或类:许多编程语言都提供了内置的随机数生成函数或类,可以使用这些函数或类来生成随机数,通常需要指定生成随机数的范围。
3. 使用时间戳作为种子:可以使用当前时间戳作为随机数生成的种子,然后使用这个种子来生成随机数。
4. 使用外部硬件设备:某些情况下需要更高质量的随机数,可以利用外部硬件设备如热噪声发生器、麦克风或摄像头等生成真随机数。
5. 使用随机数表:事先准备好一张随机数表,需要时从中选取随机数。
不同的方法适用于不同的应用场景,选择适合的方法可以保证生成的随机数具有一定的随机性。
随机数字公式

随机数字公式随机数字公式是一个在数学和计算机领域中广泛应用的概念,它可以生成一个随机的数字序列。
在现代科技的发展过程中,随机数字公式已经成为了许多应用程序的基础,如随机数生成器、加密算法、模拟器等等。
本文将介绍随机数字公式的原理、应用和发展历程。
一、随机数字公式的原理随机数字公式是一种能够生成随机数字序列的算法。
它的核心思想是利用数学函数和计算机程序来产生随机性。
在实际应用中,随机数字公式通常使用伪随机数生成器(PRNG)来产生随机序列。
PRNG是一种计算机程序,它使用一个初始种子(seed)来生成一系列伪随机数。
由于计算机程序是确定性的,因此PRNG所产生的随机序列实际上并不是真正的随机数序列。
但是,它们的表现比较接近真正的随机数序列,因此在实际应用中被广泛使用。
随机数字公式的实现方法有很多种,其中最常用的是线性同余法和梅森旋转算法。
线性同余法是一种最简单的随机数字公式,它的表达式为:Xn+1 = (aXn + c) mod m其中,Xn是当前的随机数,Xn+1是下一个随机数,a、c、m是常数。
梅森旋转算法则是一种更加复杂的随机数字公式,它可以生成更加高质量的随机数序列。
梅森旋转算法的表达式为:Xn+1 = f(Xn, Xn-k) xor Y其中,f是一个非线性的函数,k是一个常数,Y是一个密钥。
梅森旋转算法的优点是能够生成更加高质量的随机数序列,但是相应的计算复杂度也更高。
二、随机数字公式的应用随机数字公式在现代科技领域中有着广泛的应用。
以下是一些常见的应用场景:1. 随机数生成器随机数生成器是一种能够产生随机数字序列的应用程序。
它通常使用PRNG算法来产生随机数序列。
随机数生成器在密码学、模拟器、游戏等领域中都有着广泛的应用。
2. 加密算法加密算法是一种能够保护信息安全的算法。
在加密算法中,随机数字公式被用来生成密钥。
密钥是一种用来加密和解密信息的随机数序列。
随机数字公式在加密算法中扮演着至关重要的角色。
Python中生成0到9之间的随机整数

输出量
12 18 12 10 10 19 18 12 19 15
2.兰 特
randrange(start, stop+1)别名randrange(start, stop+1)
#!/usr/bin/python import random
for _ in range(10): print(random.randint(0, 9)) # 0-9
输出量
7 2 0 9 8 6 1 3 5 8
3.机 密
生成密码强的随机数,请阅读此模块的秘密
#!/usr/bin/python from secrets import randbelow
for _ in range(10): print(randbelow(10))
#!/usr/bin/python import random
for i in range(10): print(random.randrange(10)) # 0-9
输出量:
7 4 1 1 5 1 4 3 0 9
1.2生成10(含)至19(含)之间的随机整数
#!/usr/bin/python import random
博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
Python中生成 0到 9之间的随机整数
很少有示例向您展示如何生成0(含)和9(含)之间的随机整数0
123456789
randrange
1.1生成0到9之间的随机整数
输出量
9 0 4 9 3 6 2 7
12的二进制算法

12的二进制算法
将12转换为二进制数的过程如下:
1.找到小于或等于12的最大的2的幂。
在这个例子中,最大的2的幂小于或等于12是2^3(等于8)。
2.从12中减去这个幂(12 - 8 = 4)。
3.接下来找到小于或等于剩余数(4)的最大的2的幂。
在这个例子中,这个数是2^2(等于4)。
4.重复上述步骤,直到剩余数为0。
在这个例子中,4减去4等于0,所以我们不再需要找下一个2的幂。
5.写下我们找到的每个2的幂的指数(从大到小)。
在这个例子中,我们找到了2^3和2^2。
6.对于我们找到的每个幂,如果它在原数中出现过(即原数减去它之后得到的差不是负数),则在二进制数中对应位置写1,否则写0。
因此,12的二进制表示中,2^3的位置是1(因为12中包含8),2^2的位置也是1(因为4被减去后剩余0),2^1和2^0的位置是0(因为12中没有包含2和1)。
所以,12的二进制表示是:1100。
即:
•12 - 8 = 4 (写1,因为包含了8)
• 4 - 4 = 0 (写1,因为包含了4)
•剩下的数为0,所以不再继续。
因此,二进制数从高位到低位为1100。
【国家自然科学基金】_随机优化方法_基金支持热词逐年推荐_【万方软件创新助手】_20140802
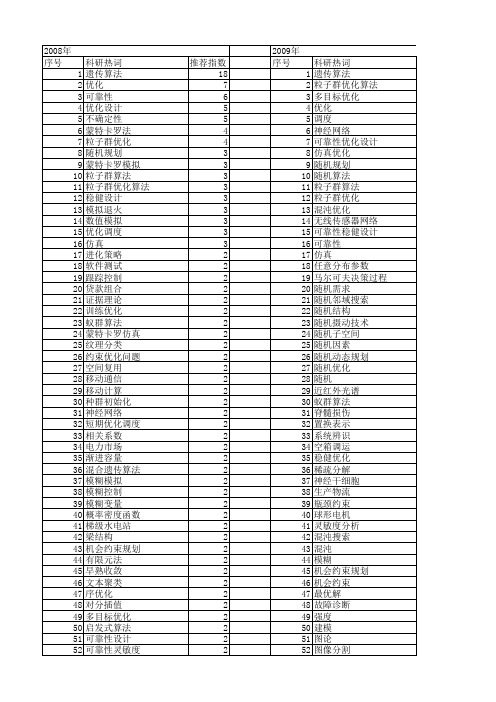
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
启发式算法 可靠性灵敏度设计 可见-近红外光谱 变尺度 匹配追踪(mp) 分布估计算法 优化调度 优化设计 人工随机模拟 主成分分析 丙戊酸 rapd 鲁棒优化模型 高度波动非线性功能函数 高层建筑 骨骼肌 验证 马尔可夫链使用模型 马尔可夫链 香蕉枯萎病 风险厌恶 风险代价 颜色检测 频谱接入 预防控制 预测方法 预测控制 顶点法 鞍点逼近 面向订单制造 非齐次马尔可夫链 非等时距 非正态随机参数 零阶方法 集装箱 集成技术 集成学习 集员估计 集中质量模型 隶属函数 隔震 随机过程 随机载波调制 随机试验 随机访问扫描 随机观测 随机肽库 随机网络 随机编码 随机用户平衡分配 随机爬山算法 随机潮流 随机测试生成 随机梯度下降法
可靠性分析 可靠性优化设计 可靠性优化 函数优化 信道估计 位置管理 任意分布参数 主动容错控制 不确定性环境 不完全概率信息 markov过程 doppler频谱 鲁棒控制 鲁棒优化 鲁棒主动控制 鲁棒h∞控制 鲁棒h∞优化控制 高耸结构 高斯混合模型 高效液相指纹图谱 高光谱图像 马尔可夫随机场 马尔可夫决策过程 饱和非线性约束 飞机流 风险计量 风险价值 颤振导数 频谱特性 预补偿器 预测模型 预条件 预应力识别 面向对象 非结构化 非线性规划 非线性加权响应面法 非线性优化设计 非线性 非稳态 非独立模式 集装箱码头 集装箱专用车辆调度问题 集中质量模型 隶属函数 随机风荷我 随机需求的车辆路径 随机需求 随机过程 随机资源分配 随机访问扫描 随机访问 随机聚焦粒子群算法 随机的
游戏中的随机算法

游戏中的随机算法1.从⼀个数组中随机取出⼀个元素1var element = myArray[Random.Range(0, myArray.Length)];2.PRD伪随机算法, 通常⽤来计算暴击率1using System;2using System.Collections;3using System.Collections.Generic;4using UnityEngine;5using UnityEditor;6using System.IO;7using System.Text;8using System.Threading;910public class PRDCalcC : EditorWindow11 {12private static readonly string obj = "lock";13private static Dictionary<int, int> prdDic = new Dictionary<int, int>();14private string infoStr = "";15private string dataStr = "数据运算中....";1617 [MenuItem("Tools/PRD_C")]18static void ShowWindow()19 {20 GetWindow<PRDCalcC>();21 }2223private void OnGUI()24 {25 EditorGUILayout.BeginVertical();26if (GUILayout.Button("运算数据"))27 {28// 计算 1% - 100% 暴击率范围所有的 PRD C值29for (int i = 0; i <= 100; ++i)30 {31int j = i;32// 创建线程负责具体计算 C 值33 Thread thread = new Thread(() =>34 {35double p = i * 1d / 100d; // 显⽰给玩家的暴击率36double c = CFromP(p); // PRD算法暴击增量37int ic = (int)Math.Round(c * 100, 0); // 将百分数⼩数转换为整数38lock (obj)39 {40 prdDic[j] = ic; // 计算结果存放在字典中41 }42 });43 thread.Start();44 }45 }46 bel(dataStr);47if (prdDic.Count == 101)48 {49 dataStr = "数据运算完毕";50if (GUILayout.Button("点击⽣成配置⽂件"))51 {52try53 {54 CreateXml();55 infoStr = "配置⽂件⽣成成功!";56 }57catch (Exception e)58 {59 infoStr = "配置⽂件⽣成失败!错误为:" + e;60 }61 }62 }6364 bel(infoStr);6566 EditorGUILayout.EndVertical();67 }6869// ⽣成 XML ⽂件70private void CreateXml()71 {72string path = EditorUtility.OpenFolderPanel("选择⽬标⽂件夹", "", "") + @"/prd.xml";73 StringBuilder sb = new StringBuilder();74 sb.Append(@"<?xml version=""1.0"" encoding=""UTF - 8"" standalone=""yes""?>");75 sb.Append('\n');76 sb.Append(@"<root xmlns:xsi=""/2001/XMLSchema-instance"">");77 sb.Append('\n');7879string xml = null;80lock (obj)81 {82// 在主线程中从字典中拿出多线程放⼊的数据,进⾏解析83foreach(var pair in prdDic)84 {85 sb.Append("<item>\n");86 sb.Append(" <p>" + pair.Key + "</p>\n");87 sb.Append(" <c>" + pair.Value + "</c>\n");88 sb.Append("</item>\n");89 }90 xml = sb.ToString();91 sb.Clear();92 xml.Remove(xml.Length - 1);93 }94using(FileStream fs = Directory.Exists(path) ? File.OpenWrite(path) : File.Create(path)) 95 {96byte[] bytes = Encoding.UTF8.GetBytes(xml);97 fs.Write(bytes, 0, bytes.Length);98 fs.Flush();99 fs.Close();100 }101lock (obj)102 {103 prdDic.Clear();104 }105 }106107// 根据传⼊ C 值,计算该C值下,最⼩暴击范围的平均暴击率108private static double PFromC(double c)109 {110double dCurP = 0d;111double dPreSuccessP = 0d;112double dPE = 0;113int nMaxFail = (int)Math.Ceiling(1d / c);114for (int i = 1; i <= nMaxFail; ++i)115 {116 dCurP = Math.Min(1d, i * c) * (1 - dPreSuccessP);117 dPreSuccessP += dCurP;118 dPE += i * dCurP;119 }120return 1d / dPE;121 }122123// 根据传⼊的暴击率,计算 PRD 算法中的系数 C124private static double CFromP(double p)125 {126double dUp = p;127double dLow = 0d;128double dMid = p;129double dPLast = 1d;130while (true)131 {132 dMid = (dUp + dLow) / 2d;133double dPtested = PFromC(dMid);134135if (Math.Abs(dPtested - dPLast) <= 0.00005d) break;136137if (dPtested > p) dUp = dMid;138else dLow = dMid;139140 dPLast = dPtested;141 }142143return dMid;144 }145 }3.洗牌算法1///<summary>2/// Knuth-Durstenfeld Shuffle算法,效率最⾼,会打乱原数组,时间复杂度O(n) 空间复杂度O(1) 3///</summary>4///<typeparam name="T">数组类型</typeparam>5///<param name="_array">⽬标数组</param>6public void KnuthDurstenfeldShuffle<T>(T[] _array)7 {8int rand;9 T tempValue;10for (int i = 0; i < _array.Length; i++)11 {12 rand = Random.Range(0, _array.Length - i);13 tempValue = _array[rand];14 _array[rand] = _array[_array.Length - 1 - i];15 _array[_array.Length - 1 - i] = tempValue;16 }17 }4.权重概率算法1//probs为权重数组, 且权重由⼤到⼩排序2float Choose (float[] probs) {3float total = 0;4foreach (float elem in probs) {5 total += elem;6 }7float randomPoint = Random.value * total;8for (int i= 0; i < probs.Length; i++) {9if (randomPoint < probs[i]) {10return i;11 }12else {13 randomPoint -= probs[i];14 }15 }16return probs.Length - 1;17 }5.在⼀个空⼼圆范围内随机⽣成物体1using UnityEngine;2using System.Collections;34public class RandomRadius : MonoBehaviour {5public GameObject prefabs;6// Use this for initialization7void Start () {8for (int i = 0; i < 1000; i++) {9 Vector2 p = Random.insideUnitCircle*3;10 Vector2 pos = p.normalized*(2+p.magnitude);11 Vector3 pos2 = new Vector3(pos.x,0,pos.y);12 Instantiate(prefabs,pos2,Quaternion.identity);13 }14 }15 }6.从⼀个数组中随机选择指定个数且不重复的元素1int[] spawnPoints = {1, 5, 6, 8, 9, 20, 15, 10, 13};23int[] ChooseSet (int numRequired) {4int[] result = new Transform[numRequired];5int numToChoose = numRequired;6for (int numLeft = spawnPoints.Length; numLeft > 0; numLeft--) { 7float prob = (float)numToChoose/(float)numLeft;8if (Random.value <= prob) {9 numToChoose--;10 result[numToChoose] = spawnPoints[numLeft - 1];11if (numToChoose == 0) {12break;13 }14 }15 }16return result;17 }7.在⼀个球体内⽣成随机点1var randWithinRadius = Random.insideUnitSphere * radius;8.遵循⾼斯分布的随机算法(lua实现)1function randomNormalDistribution()2local u, v, w, c = 0, 0, 0, 03while(w == 0or w >= 1)4do5--//获得两个(-1,1)的独⽴随机变量6 u = math.random() * 2 - 17 v = math.random() * 2 - 18 w = u * u + v * v9end10--//这⾥就是 Box-Muller转换11 c = math.sqrt((-2 * math.log(w)) / w)12--//返回2个标准正态分布的随机数,封装进⼀个数组返回13--//当然,因为这个函数运⾏较快,也可以扔掉⼀个14--//return [u*c,v*c];15return u * c16end1718function getNumberInNormalDistribution(mean, std_dev)19return mean + (randomNormalDistribution() * std_dev)20end21--//参数1表⽰期望值, 参数⼆表⽰差值范围22 getNumberInNormalDistribution(180, 10)。
概率论中的随机过程算法仿真

概率论中的随机过程算法仿真概率论中的随机过程算法仿真在概率论中,随机过程是一种描述随机演化的数学模型。
通过对随机过程进行算法仿真,我们可以获得一系列随机事件的演化轨迹,从而更好地理解和分析概率现象。
本文将介绍随机过程的基本概念以及常用的算法仿真方法,并通过具体案例展示其应用。
一、随机过程的基本概念随机过程是一组随机变量的集合,其中每个变量代表系统在不同时间点上的状态。
随机过程可以是离散的(如离散时间马尔可夫链)或连续的(如布朗运动)。
它可以用数学的方式进行建模和分析,帮助我们理解和预测随机现象。
二、随机过程的算法仿真方法1. 蒙特卡洛方法蒙特卡洛方法是一种基于随机抽样的统计分析方法。
在随机过程的算法仿真中,可以通过蒙特卡洛方法模拟系统的随机演化。
具体而言,我们可以生成大量的随机数作为系统状态的取值,并根据系统的特定规律更新状态,从而观察随机事件的演化轨迹。
2. 马尔可夫链蒙特卡洛方法马尔可夫链蒙特卡洛方法是一种利用马尔可夫链进行随机过程仿真的方法。
马尔可夫链是指具有马尔可夫性质的随机过程,即未来状态只与当前状态有关,与过去的状态无关。
通过定义状态空间和状态转移概率矩阵,我们可以使用马尔可夫链蒙特卡洛方法模拟系统的随机演化。
3. 扩散过程模拟方法扩散过程是一种连续的随机过程,常用于描述具有随机漂移和随机波动的现象。
在扩散过程的算法仿真中,可以使用随机微分方程或随机差分方程进行建模。
通过模拟扩散过程的数值解,我们可以观察系统状态的演化,并分析其概率分布特征。
三、随机过程算法仿真的应用案例案例:股票价格模拟假设我们想要模拟某只股票的价格,可以将其视为一个随机过程,并使用算法仿真方法进行分析。
首先,我们可以根据历史数据估计股票价格的平均涨跌幅和波动率,进而构建一个符合实际股票市场特征的随机过程模型。
然后,我们可以使用蒙特卡洛方法生成大量的随机数,并根据随机数和模型规则更新股票价格。
通过多次模拟,并统计价格的分布情况,我们可以得到股票价格的概率分布特征,进而进行风险评估和投资决策。
【软件学报】_随机算法_期刊发文热词逐年推荐_20140727

科研热词 随机算子 遗传算法 进化模式 转发连通 轨迹固定 访问模式 能耗利用率 网络流量监测 移动sink 渐近收敛性 流量数据采集 流量数据分析 最小覆盖集 时序 文件预取 数据采集 数据采样方法 数据竞争 数据包抽样 操作系统 异构无线传感器网络 度约束最小生成树 并发i/o 差分演化 嫁接 大象流 多线程 压缩映射 剪接 传感器网络 linux i/o性能 hidden markov模型 d-left哈希
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
科研热词 推荐指数 高维数据 1 集成学习 1 隐私保护数据发布 1 随机漫步 1 随机游走 1 随机投影 1 随机任务 1 邻域比较 1 计算机网络 1 蚁群算法 1 脆弱水印 1 能耗管理 1 聚类 1 网络聚类 1 网络编码 1 绿色云计算 1 簇结构 1 篡改检测 1 等价置换弧 1 理论分析 1 熵最大化准则 1 支持向量机分类器 1 搜索 1 排队论 1 拓扑 1 抗扰动 1 对等网流媒体 1 安全邻域 1 大规模多智能体系统 1 复杂网络特性 1 复杂网络 1 协同控制 1 位置敏感哈希 1 传输算法 1 传输模型 1 任务调度 1 不一致图像块 1 svm classifier 1 random projection 1 peer-to-peer 1 locality sensitive hashing 1 k邻域 1 jpeg图像 1 high-dimensional data 1 entropy maximizing criterion 1 c-近似最近邻查询 1 c-approximate nearest neighbor1 query
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 引言-随机算法举例
2. Min Cut (5)出错概率
重复k次出错概率为
2 n ( n 1) 1 e n( n 1) k 2k
(6)本算法是一个Monte Carlo型算法.
1 引言-基本知识
2.背景和历史 (1)重要方法 - Monte Carlo求定积分法 - 随机k-选择算法 - 随机快排序 -素性判定的随机算法 - 二阶段随机路由 算法 (2)重要人物和工作 - de Leeuw等人提出了概率图灵机(1955) - John Gill的随机算法复杂性理论(1977) - Rabin的数论和计算几何领域的工作(1976) - Karp的算法概率分析方法(1985) - Shor的素因子分解量子算法(1994)
2 低度法的正确性 定理18.7 算法18.2产生的X={v∈V| label(v)=1}就是一个低度顶点 集, 使得Pr{|X|≤αn}≤e-βn, 其中α和β为常数, n是顶点数. 证: 我们知道算法18.2产生的X满足低度顶点集的前两个条件, 现在 只要证明条件3高概率成立, 即Pr{|X|≤αn}≤e-βn, 其中α和β为常数, n 是顶点数. 考虑一个特殊的低度顶点子集V’⊆V6, 这里V’中的任意两顶点之 间的距离至少为3, 下面只要证明|V’∩X|以高概率满足条件3. V’这样构造: 先任取v1∈V6, 删去V6中与v1距离小于2的顶点, 可知至多删去36个顶点, 再从V6的剩余顶点中任取v2, 删去V6中与v2 距离小于2的顶点, 可知至多删去36个顶点, 直至V6为空. V’={v1,v2,…}. 因此, |V’|≥(1/37)|V6|≥(1/37)(n/7)=cn c=1/259 (∵|Vd|≥c0|V|, c0=(d5)/(d+1))
1 引言-随机算法举例
1. Quick Sort (1)传统的快排序算法 -总是取第一个元素作为划分元; -算法的最坏运行时间是O(n2) ,平均时间是O(nlogn) ; -因此存在一些输入实例,使得算法达到最坏运行时间, 如:降序的序列; (2)随机快排序算法 -随机选择一个元素作为划分元; -任何一个输入的期望时间是O(nlogn); -是一个Las Vegas算法;
3 多项式恒等的验证-基本技术
1.原理 - 定理18.13 设p(x1,x2,…,xn)是域F上的多项式, 且 p(x1,x2,…,xn)非恒等零, 若I是F的任意有限子集, 则In中有 p(x1,x2,…,xn)的零元素数目≤|I|n-1deg(p), 其中deg(p)是多 项式的阶. - 系18.3 令p(x1,x2,…,xn)≠0, 则随机元组(y1,y2,…,yn)∈In是 p(x1,x2,…,xn)的零元素的概率≤deg(p)/|I|. 2.测试多项式p(x1,x2,…,xn)是否恒为零的方法 ①先选择有限子集I⊆F, 使|I|≥2deg(p); ②随机选择v∈In, 计算p(x1,x2,…,xn)|v; ③如果p(x1,x2,…,xn)|v为零, 则p≡0;否则p不恒为零; 注: 该方法的错误概率≤1/2, 重复k次的错误概率≤(1/2)k
2 低度顶点部分独立集-并行算法
2.算法分析 定理18.7的证明(续):
cn 1 vi X 对每个vi V , 定义随机变量 Xi , i 1,2,...,cn; 且定义X X i i 1 0 vi X
应用Chernoff 不等式, 对0 1, 有 e
1 引言-随机算法举例
- 数学期望和方差 - Markov和Chebyshev不等式 - Chernoff不等式 设Xi是n个独立的Bernoulli随机变量, 对于1≤i≤n, E[Xi]=pi, 0<pi<1,
则对于 X X i , E[ X ] pi , 和0 1, 有
3 多项式恒等的验证-矩阵乘积的验证
(2)随机并行算法 - 算法描述 ①随机产生v∈{0,1}n ; ②并行计算A(Bv)和Cv; ③如果A(Bv)=Cv, 则AB=C, 否则AB≠C; - 时间分析 运行时间为O(logn), 使用了O(n2)乘法
4.研究意义 - 求解问题的一种重要让步策略 - 有效的随机算法 - 实际可行的随机算法 - 可转化为确定算法 - 易于并行化 - 促进智能计算的发展
1 引言-时间复杂性度量
1.运行时间的期望和方差 (1)实例的运行时间期望 A 对固定实例x, 设随机算法A的运行时间 x 是一个[0,+∞) 上的随机变量,定义随机算法A在实例x上的运行时间期望 为 E[ xA ] , 也称为随机算法A在实例x上的执行时间. (2)算法的运行时间期望 如果对一个规模为n问题的所有实例是均匀选取的, 则定 义各个实例上的平均执行时间为随机算法在该问题上的运行 时间期望, 记为T(n) 注: 类似地可以定义方差. 2.随机复杂度类(参见Motwani R. and Raghavan P., Randomized Algorithms.) RP(Randomized Polynomial time), ZPP, PP, BPP etc.
1 引言-时间复杂性度量
1.挫败对手(Foiling the Adversary) 将不同的算法组成算法群, 根据输入实例的不同随机地或 有选择地选取不同的算法, 以使性能达到最佳. 2.随机采样(Random Sampling) 用“小”样本群的信息, 指导整体的求解. 3.随机搜索(Random Search) 是一种简单易行的方法, 可以从统计角度分析算法的平均 性能, 如果将搜索限制在有解或有较多解的区域, 可以大大 提到搜索的成功概率. 4.指纹技术(Fingerprinting) 利用指纹信息可以大大减少对象识别的工作量. 通过随机 映射的取指方法, Karp和Rabin得到了一个快速的串匹配随 机算法. 5.输入随机重组(Input Randomization) 对输入实例进行随机重组之后, 可以改进算法的平均性能.
2 低度顶点部分独立集-并行算法
1.算法描述(算法18.2) 输入: 平面图G(V,E)的边表 输出: 低度顶点独立集X={v∈V| label(v)=1} begin (1)Par-do: 标出低度顶点Vd(deg(v)<=6); (2)Par-do: 随机等概率分配所有v∈Vd以标号0或1; //破 对称技术 (3)Par-do: 剔除不满足独立性的标号为1的顶点; (4)剩下的标号为1的低度顶点集就是所求的X; end
e
2 ( 1 ) 7 cn / 2 2 7 2 1 8 c(1 )( 1 2 ) , c ( 2 )
Pr[| X | n] Pr[| X | n] e n
至此证明了条件3高概率成立. (2)算法时间: O(1), 使用了O(n)次运算.
1 引言-时间复杂性度量
6.负载平衡(Load Balancing) 在并行与分布计算、网络通讯等问题中, 使用随机选择技 术可以达到任务的负载平衡和网络通讯的平衡. 7.快速混合Markov链(Rapidly Mixing Markov Chain) 使用该方法可以解决大空间中的均匀抽样问题. 8.孤立和破对称技术(Isolation and Symmetry Breaking) 使用该技术可以解决处理的并行性, 避免分布式系统的死 锁等问题. 如: 图着色算法, 部分独立集问题 9.概率存在性证明(Probabilistic Methods and Existence Proofs) 如果随机选取的物体具有某种特性的概率大于0, 则具有该 特性的物体一定存在. 10.消除随机性(Derandomization) 许多优秀的确定性算法是由随机算法转换而来的.
第十八章 随机算法
内容
1 引言 2 低度顶点部分独立集 3 多项式恒等的验证
1 引言-基本知识
1.随机算法的定义 - 定义: 是一个概率图灵机. 也就是在算法中引入随机因素, 即通过随机数选择算法的下一步操作. - 三要素: 输入实例、随机源和停止准则. - 特点: 简单、快速和易于并行化. - 一种平衡: 随机算法可以理解为在时间、空间和随机三大 计算资源中的平衡(Lu C.J. PhD Thesis 1999). - 重要文献 Motwani R. and Raghavan P., Randomized Algorithms. Cambridge University Press, New York, 1995
1 引言-基本知识
3.随机算法的分类 - Las Vegas算法和Monte Carlo算法是常见的两类随 机算法。 - Las Vegas算法运行结束时总能给出正确的解,但其 运行时间每次有所不同。 - Monte Carlo算法可能得到不正确的结果,但这种概 率是小的且有界的。
1 引言-基本知识
i 1 i 1
N
N
P r[X (1 ) ] e 和 P r[X (1 ) ] e
2
3
2
2
2 低度顶点部分独立集-串行算法
1.问题定义: 设G(V,E)是一个平面图. 顶点集合称为低度顶点 部分独立集, 满足以下三个条件: (1)对 v X , deg(v)≤d常数; (2)集合X独立,即X中的任何两顶点都不相邻; (3)X的大小满足|X|≥c|v|,c为某个正常数. 2.引理18.1: 设G(V,E)是一个至少有三个顶点的平面图, 则 |E|≤3|V|-6. 3.串行算法 - 定理18.6 对任何平面图G(V,E), 可以在线性时间内构造 出低度顶点部分独立集. - 算法: ①取 Vd {v | v V且 deg(v) d,常数d 6} , d=6; ②由Vd构造独立集: 反复取 v Vd 加入到X中, 每次 移去Vd中与v相连的顶点, 直至Vd空; X就是所求;