第二讲:STATA入门
Stata软件基本操作和数据分析入门(完整版讲义)

Stata软件基本操作和数据分析入门(完整版讲义)Stata软件基本操作和数据分析入门第一讲Stata操作入门张文彤赵耐青第一节概况Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。
它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。
Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS 系统也毫不逊色。
另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。
由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。
但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
更为令人叹服的是,Stata 语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。
Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。
用户可随时到Stata网站寻找并下载最新的升级文件。
事实上,Stata 的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata 程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。
Stata软件基本操作:统计描述入门

Stata软件基本操作和数据分析入门第二讲统计描述入门赵耐青一调查某市1998年110名19岁男性青年的身高(cm)资料如下,计算均数、标准差、中位数、百分位数和频数表。
Stata数据结构(读者可以把数据直接粘贴到Stata的Edit窗口)在介绍统计分析命令之前,先介绍打开一个保存统计分析结果的文件操作:计算样本的均数、标准差、最大值和最小值命令1:su 变量名 (可以多个变量:即:su 变量名1 变量名2 …变量名m)命令2:su 变量名,d (可以多个变量:即:su 变量名1 变量名2 …变量名m,d) 本例命令su x本例命令. su x,d计算百分位数还可以用专用命令centile。
centile 变量名(可以多个变量),centile(要计算的百分位数) 例如计算P2.5,P97.5等centile 变量名,centile(2.5 97.5)本例计算P2.5,P97.5,P50,P25,P75。
本例命令. centile x,centile(2.5 25 50 75 97.5)制作频数表,组距为2,从164开始,gen f=int((x-164)/2)*2+164 其中int( )表示取整数tab f 频数汇总和频率计算作频数图命令 graph 变量,bin(#) norm其中#表示频数图的组数;norm表示画一条相应的正态曲线(可以不要) 本例命令为graph x,bin(8) norm为了使坐标更清楚地在图上显示,可以输入下列命令graph x,bin(8) xlabel norm ylabel图形可以从Stata中复制到word中来,操作如下:计算几何均数可以用means 变量名(可以多个变量:即:means 变量1 …变量m) means x作Pie图描述构成比:每一类的频数用一个变量表示,命令:graph 各类频数变量名,pie第1地区血型构成比的Pie图的命令和图graph a b o ab if area==1,pie注意逻辑表达式中if area==1是两个等号。
STATA基本操作入门PPT课件
6.2查看变量的统计特征
• 如果要查看满足q≥10000的子样本的统计指标。方法:输入summarize q if q >=10000 • 或者su q if q >=10000
第9页/共23页
6.3 查看变量的统计特征
• 如果要查看更多的统计指标 • 方法:输入 su q,detail • 显示了百分位数, 方差,偏度与峰度
第21页/共23页
9.6 图像合并展示
• 将线性拟合和二次拟合这两个图像在一起展示 • 方法:输入graph combine scatter1.gph scatter2.gph
第22页/共23页
谢谢您的观看!
第23页/共23页
第10页/共23页
6.4 查看变量的统计特征
• 如果summarize 后面不输入具体变量,则展示所有变量的统计指标 • 方法:输入summarize 或 su
第11页/共23页
7.经验累积分布函数
• 如果要查看q的经验累积分布函数 • 方法:tabulate q 或则 ta q
第12页/共23页
• 展示满足q>=10000的q的数据 • 方法:list q if q >=10000 • 展示满足q>=10000的q和tc的数据 • 方法:list q tc if q >=10000
第7页/共23页
6.1查看变量的统计特征
• 查看变量q的统计特征: • 方法:输入summarize q 或 su q • 展示变量q的样本容量,平均值,标准差,最小值,最大值
8.相关系数
• 如果要显示PL,PF两个变量的相关系数 • 方法:pwcorr pl pf
第13页/共23页
stata入门中文讲义_经济学_高等教育_教育专区

Stata及数据处理目录第一章STATA基础 (3)1.1 命令格式 (4)1.2 缩写、关系式和错误信息 (6)1.3 do文件 (6)1.4 标量和矩阵 (7)1.5 使用Stata命令的结果 (8)1.6 宏 (10)1.7 循环语句 (11)1.8 用户写的程序 (15)1.9 参考文献 (15)1.10 练习 (15)第二章数据管理和画图 (18)2.1数据类型和格式 (18)2.2 数据输入 (19)2.3 画图 (21)第3章线性回归基础 (22)3.1 数据和数据描述 (22)3.1.1 变量描述 (23)3.1.2 简单统计 (23)3.1.3 二维表 (23)3.1.4 加统计信息的一维表 (26)3.1.5 统计检验 (26)3.1.6 数据画图 (27)3.2 回归分析 (28)3.2.1 相关分析 (28)3.2.2 线性回归 (29)3.2.3 假设检验 Wald test (30)3.2.4 估计结果呈现 (30)3.3 预测 (34)3.4 Stata 资源 (35)第4章数据处理的组织方法 (36)1、可执行程序的编写与执行 (36)方法1:do文件 (36)方法2:交互式-program-命令 (36)方法3:在do文件中使用program命令 (38)方法4:do文件合并 (39)方法5:ado 文件 (40)2、do文件的组织 (40)3、数据导入 (40)4、_n和_N的用法 (44)第一章STATA基础STATA的使用有两种方式,即菜单驱动和命令驱动。
菜单驱动比较适合于初学者,容易入学,而命令驱动更有效率,适合于高级用户。
我们主要着眼于经验分析,因而重点介绍命令驱动模式。
图1.1Stata12.1的基本界面关于STATA的使用,可以参考Stata手册,特别是[GS] Getting Started with Stata,尤其是第1章A sample session和第2章The Stata User Interface。
张文彤、赵耐青:Stata入门介绍

Stata入门介绍✧说明:(1)这里很可能有错误,如果产生不良影响,请见谅。
(2) 下面用红色注明的都是可执行的过程。
(3) Stata要在使用中熟练的,大家应该多加练习。
(4) Stata的很多细节,这里不可能涉及到,只是选取相对重要的部分加以解释,而且仅仅是入门性质。
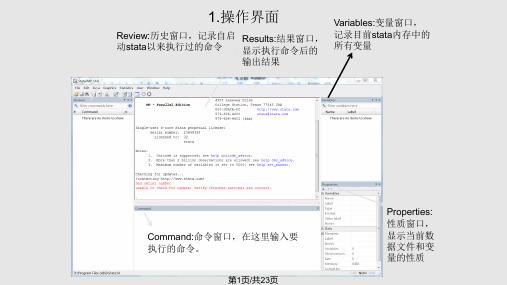
✧界面当我们把stata装好以后,首先需要了解的是它的界面。
打开Stata后我们便可以看到它常用的四个窗口:Stata Results; Review; Variables; Stata Command。
我们所有的运行结果都会在Stata Results界面中显示;而命令的输入则在Stata Command窗口;Review窗口记录我们使用过的命令;最后Variables窗口显示存在于当前数据库中的所有变量的名称。
可以直接点击Review窗口来重新输入已使用过的命令,我们所需变量可以通过点击Varaibles窗口来得到,这些都可以简便我们的操作。
✧Stata 命令Stata软件功能强大,体现在它提供了丰富的命令,可以实现许多功能。
每一个stata命令都相应的命令格式。
我们在这里介绍常用的一些命令的功能和相应的格式,大家在使用stata的过程中也会不断积累相关的知识。
命令格式可以用help命令查询。
也可以在Help选项下content中寻找相关命令。
使用help命令后,窗口中会有关于该命令的详尽说明。
更直接的办法是看Examples中的范例是如何使用该命令,阅读一些相关的说明并加以模仿。
✧重要习惯我们使用stata进行回归分析时,需要养成一些好的习惯。
在进行一些数据量很大,过程复杂的分析时尤其重要。
(1)使用日志(log)。
它可以帮助我们记录stata的运行结果。
格式:log using c:\stata\logfiles\10.21.5_30.log(注意:我们需要先建好文件夹c:\stata\logfiles)关闭log的命令为“log close”。
stata操作介绍之基础部分PPT幻灯片课件

数据编辑器
38
注意:
1.如果为某一变量输入的第一个值是一个数字,比如对人口、失业率和预 期寿命这些变量,那么stata便会认为这一列是一个“数值变量”,从此 以后只允许数字作为取值。 2.如果为某一变量第一次输入的是非数值字符,比如像地名的输入(或者 输入了带逗号的数字),那么stata会判断此列是字符串或文本变量。 3.在数据编辑器或数据浏览器中,字符串变量值显示为红色,这将其与数 值变量(黑色)或加标签的数值变量(蓝色)区分开来。
23
Stata 菜单栏简介
包含八项下拉菜单:文件、编辑、数据、绘图、统计分析、用户、窗口及帮助。
24
1.9 Stata命令输入
• Stata的命令输入方式: 1、点击菜单栏输入命令; 2、在命令窗口输入命令; 3、运行命令程序(利用.do文件);
25
1.10 Stata文件格式
• Stata常用的文件格式:
文件类型
扩展名
数据文件
.dta
命令程序文件
.do
运行程序文件
.ado
帮助文件
.hlp
说明
stata使用的数据
一系列命令的集合
用于完成用户提交的数据处理与统 计分析任务的程序文件
与相应的.ado文件有相同的文件名, 形成一堆文件,并提供在线帮助
26
1.11 Stata命令包安装
利用Stata做统计分析时,官方提供的命令包并不一定能满足需 求,因此许多研究者编写了大量的非官方命令包(包括.do文件、 .ado文件和帮助文件),使用此类非官方命令包之前需要对其进行 安装。
Stata中有两个命令对于用户寻找与安装命令包相当有用:search 和findit。
通过这两个命令可以找到相关搜索内容中有哪些额外的命令,点 击链接后安装即可。
stata初级入门2-数据篇
菜单操作:file>import
2014年4月17日星期四
《计量经济学软件应用》课程讲义
7
3.其它方式
(1)用StatTransfer 软件转换
可以用statTranser 9软件将各种格式的数据转换成 dta格式数据 前提是你安装了这个软件
(2)安装外挂命令程序包,如usespss.ado程 序包就是一个用于读取spss生成的格式数据的 程序包。
Precision for float is 3.795x10^-8. Precision for double is 1.414x10^-16.
字符型数据
String storage type str1 str2 ... ... ... str244
Maximum length 1 2 . . . 244
12
2014年4月17日星期四
《计量经济学软件应用》课程讲义
3.变量属性的修改
变量名更改:rename命令,常用语法格式:rename old_var new_var,如rename income inc. 变量标签(label)的定义:label命令,语法:label var varname “##”,如labeห้องสมุดไป่ตู้ var foreign “car type”。除用于定义变 量的标签外,其还可用于定义数据的标签,如label data “auto in American” 分类(或指示)变量的值标签定义:亦label命令,要完成分 类变量值的标签定义有两步,如把变量foreign取值为0,定义 为domestic,取值为1,定义为foreign,并用origin表示该变 量值标签定义结果:
stada中文教程
. drop _all
. input x y xy
1. 1 2 2. 3 4 3. 5 6 4. 7 8 5. 9 10 6. end
2)用 stata 的数据编辑工具
①进入数据编辑器 进入 stata 界面,在命令栏键入 edit 或在 stata 的 window 下
变量格式等均会被自动正确设置,见图 6 和图 7。
图 6 在 EXCEL 中的数据格式 图 7 粘贴入 Stata 后的数据格式 4)、打开已有的数据文件
Stata 能够直接打开的数据文件只能是自身专用格式或者以符号 分隔的纯文本格式,后者第一行可以是变量名,分述如下:
1.点击图标 ,然后选择路径和文件名,可以打开 Stata 专用 格式的数据文件,并且扩展名为.dta。
169.5 177.0 183.6 170.3 178.8 181.1 182.9 177.8 164.1 169.1
176.3 169.4 171.1 172.9 177.0 179.8 178.2 174.4 169.2 176.4
178.3 165.0 175.8 181.0 177.6 177.4 178.7 175.1 181.8 171.3
命令操作,如欲将上面建立的数据文件存入“C:\”中,文件名为 Data1.dta,则命令为:
. save c:\data1 file c:\data1.dta saved 该指令将在 C 盘根目录建立一个名为“data1.dta”的 Stata 数据 文件,后缀 dta 可以在命令中省略,会被自动添加。该文件只能在 Stata 中用 use 命令打开。如所指定的文件已经存在,则该命令将给 出如下信息:file c:\data1.dta already exists,告诉用户在该目标盘及 子目录中已有相同的文件名存在。如欲覆盖已有文件,则加选择项 replace。命令及结果如下: . save c:\data1.dta , replace file c:\data1.dta saved 2.存为文本格式:需要使用 outsheet 命令实现,该命令的基本格 式如下。 outsheet [变量名列表] using 文件名 [, nonames replace ]
(2021年整理)Stata教程(2)
Stata教程(2)编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(Stata教程(2))的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为Stata教程(2)的全部内容。
第一章 Stata 概貌§1.1 Stata的功能、特点和背景Stata是一个用于分析和管理数据的功能强大又小巧玲珑的实用统计分析软件,由美国计算机资源中心(Computer Resource Center)研制。
从1985至1998的十四年时间里,已连续推出1.1,1.2,1。
3,1。
4,1.5,……及2。
0,2。
1,3。
0,3.1,4.0,5。
0,6。
0等多个版本,通过不断更新和扩充,内容日趋完善。
它同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,又在许多方面别具一格。
Stata融汇了上述程序的优点,克服了各自的缺点,使其功能更加强大,操作更加灵活、简单,易学易用,越来越受到人们的重视和欢迎。
Stata的突出特点是只占用很少的磁盘空间,输出结果简洁,所选方法先进,内容较齐全,制作的图形十分精美,可直接被图形处理软件或字处理软件如WORD等直接调用.一、 Stata的数据管理能力1.Stata的数据管理空间受计算机的操作系统和计算机扩展内存的影响。
对640k内存的微机,3.1版本的Stata可以管理2400个记录×99个变量,并随计算机扩展内存的增加而增加;对4.0的WINDOWS版本,Stata可以管理4800个记录×99个变量;对WINDOWS 95下的5.0版本,可根据计算机的配置情况设置变量数和记录数,如32M扩展内存的计算机,可处理2千万个数据。
《stata基础》课件
假设检验与P值
假设检验的基本原理
理解假设检验的基本概念和 原理,了解如何提出原假设 和备择假设。
P值的意义
了解P值的意义和计算方法, 知道如何解读P值。
显著性检验
掌握在Stata中进行各种显著 性检验的方法,如t检验、Z 检验、卡方检验等。
变量筛选与模型优化
变量筛选方法
了解并掌握一些常见的变量筛选方法,如逐步回归、向前 /向后回归、岭回归等。
数据分析的方法
包括描述性分析、推断性分析等,可以使用Stata提 供的各种统计命令和程序来实现。
数据分析的步骤
包括确定分析目标、选择合适的分析方法、 执行分析操作等,需要按照一定的顺序逐步 进行。
04 Stata绘图功能
散点图与线性图
01
散点图
用于展示两个变量之间的关系, 通过散点的大小、颜色或形状表 示不同数据点。
数据清洗的方法
包括识别异常值、填充缺失值、删除重复值等,可以使用Stata提 供的各种命令和程序来实现。
数据清洗的步骤
包括数据预览、异常值识别、缺失值处理、重复值检测与处理等, 需要按照一定的顺序逐步进行。
数据转换
数据转换的必要性
数据转换是数据处理过程中经常需要进行的一步,可以将 数据转换为更易于分析和可视化的形式,或者将数据整合 到一起以便进行更深入的分析。
02 Stata基础操作
Stata界面介绍
Stata界面布局
介绍Stata的菜单栏、命令窗口、结 果窗口、变量列表等界面元素,帮助 用户熟悉操作环境。
工具栏功能
简要说明工具栏中各个按钮的作用, 方便用户快速执行常用操作。
数据导入与导
数据导入
介绍如何从不同格式(如CSV、Excel等)导入数据到Stata中,包括相关命令 和参数设置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
三、变量类型与简单描述统计方法
6.定比变量与描述统计 描述信息:最为完整的,除了前面变量层次包含 的信息之外,还可以做除法。但是,它的描述信 息基本与定距变量相同。 统计命令:summarize;summarize * ,detail; tabstat * , stat(mean sd median)
下周内容:
1. 单变量描述统计的简单回顾与课堂演示 2. 双变量的描述统计
3. 多变量的描述统计
第二讲:STATA入门
1.统计软件:STATA14.0
2.数据准备:① 2014年卫计委流动人口动态监测调
查数据之“社会融合与心理健康问卷”部分;②农
Hale Waihona Puke 民工随迁子女城市融入课题组的“外出务工调查数
据”。
1. 数据录入、打开与保存
2. 基本的STATA数据处理命令 3. 变量类型与简单描述统计方法 4. 练习与作业
4.删除变量或观察值命令
– drop命令
– drop in 1/10 or (-10/-1)
– keep命令
– keep var1 var2…
– keep if
二、基本的STATA数据处理命令
5.生成新变量的命令(egen)
–help egen –egen a=mean() –egen b=median() –egen c=sum()
一、数据录入、打开与保存
1.数据录入与读取
直接录入数据
input命令
读入ASCII格式原始数据——使用insheet、 infile、infix等命令 使用Stat/Transfer软件
一、数据录入、打开与保存
2. STATA数据打开
双击直接打开
Do文件中使用use命令
一、数据录入、打开与保存
二、基本的STATA数据处理命令
2. 数据排序命令
–sort –gsort (降序排序) –gsort (两个变量排序) –order
二、基本的STATA数据处理命令
3.修改变量名和变量值的命令
–rename (改变量名) –replace (替换变量值) –recode
二、基本的STATA数据处理命令
[STATA演示]
三、变量类型与简单描述统计方法
7. 离散与连续变量
通常,离散变量包括了定类变量和定序变量,统计 描述可参照之;而连续变量包括了定距变量和定比 变量,统计描述同样可参照之。 值得注意的是,在社会科学研究中,定距变量和定 比变量很少单独区分。
四、练习与作业
【1】请在2014年卫计委流动人口动态监测调查数据 之“社会融合与心理健康问卷”部分识别各变量 设置的层次。 【2】每类变量选出3-5个,按照以上统计描述进行 STATA演练。
二、基本的STATA数据处理命令
6.生成虚拟(哑)变量的命令
–tab region, generate(region) 7.帮助命令
–help command
三、变量类型与简单描述统计方法
1. 变量类型
区分标准之一:离散变量与连续变量 区分标准之二:定比变量、定距变量、 定序变量与定类变量
三、变量类型与简单描述统计方法
3.数据保存
save filename, replace
4.数据描述
describe命令
二、基本的STATA数据处理命令
练习数据:2014年卫计委流动人口动态监测调查 数据之“社会融合与心理健康问卷”。 1.查看数据命令 –browse(浏览数据) –edit(编辑数据) –describe(描述数据) –tab sex (频数表)
2.变量类型与描述统计的关系
简单来说,描述统计方法和策略是依据变量类型 而设定的,变量类型不同,相应地统计描述也不 同。
一般来说,高层次的变量可以转换为低层次变量, 因而也适用于低层次的统计方法和描述。但是, 这会降低高层次变量所包含的信息。
三、变量类型与简单描述统计方法
3.定类变量与描述统计
描述信息:频数、百分比、累积百分比及分布 统计命令:tabstat;tabulate;tab1
[STATA演示]
三、变量类型与简单描述统计方法
4.定序变量与描述统计
描述信息:排序、频数、百分比、及分布 统计命令:sort;gsort;tabulate;tabstat;tab1
[STATA演示]
三、变量类型与简单描述统计方法
5.定距变量与描述统计
描述信息:除了定类变量和定距变量的描述之外, 还可以描述均值、标准差及连续分布。 统计命令:summarize;summarize * ,detail; tabstat * , stat(mean sd median) [STATA演示]