第3章:SPSS 数据文件的建立和管理
SPSS数据文件的建立和管理实验报告
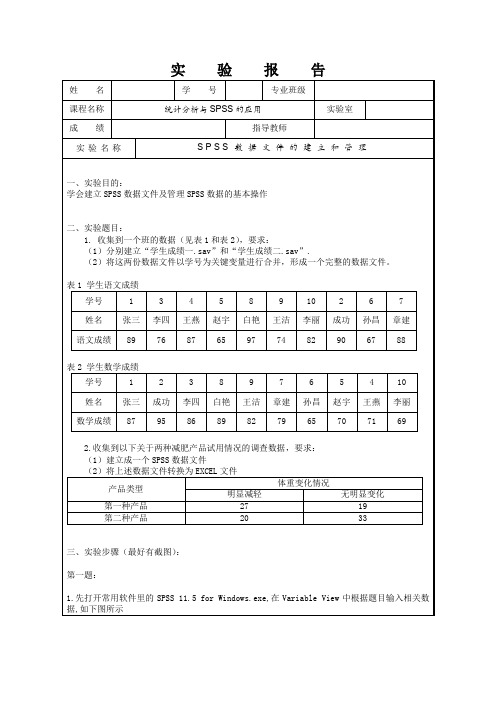
第二题:
1.先打开常用软件里的SPSS 11.5 for Windows.exe,在Variable View中根据题目输入相关数据,如下图所示
2.在Data View中根据题目输入相关数据,结果如下图所示
3.对这个表格进行保存,并且命名为“减肥产品.sav”
3.选中“Match cases on key variables in sorted files”,将“学号”放入“Key Variables”中,结果如下所示
第二题:
因为题中要求将数据文件转换为EXCEL文件,所以通过【File】→【Save As】可实现
输入文件名“减肥产品”,再修改保存类型,选择EXCEL保存类型,即可得到升序排列,结果如下图所示
3.对第一个表格进行保存,并且命名为“学生成绩一.sav”
4.重新打开一个表格,在Variable View中根据题中要求输入数据,如下图所示
5.在Data View中先输入数据,再选中“学号”一列,选择升序排列,结果如下图所示
表1学生语文成绩
学号
1
3
4
5
8
9
10
2
6
7
姓名
张三
李四
王燕
赵宇
白艳
王洁
李丽
成功
孙昌
章建
语文成绩
89
76
87
65
97
74
82
90
67
88
表2学生数学成绩
学号
1
2
3
8
9
7
6
5
4
10
姓名
张三
成功
SPSS上机实验报告一
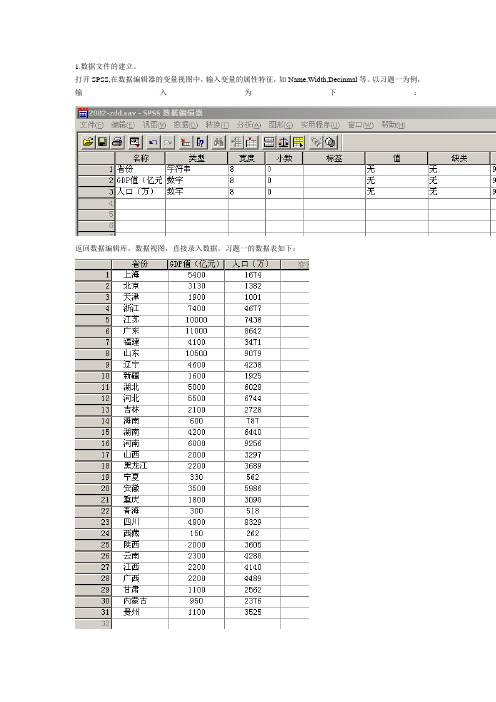
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。
第章:SPSS数据文件的建立和管理PPT课件

b) 数据的排序,方便的得到变量的最大值、最小值,计 算出数据的全距,了解数据的离散程度。
1/11/2020 10:14 AM
浙江树人大学管理学院
1
c) 数据的排序,可以快速发现异常值,以便及时对其进 行处理。
数据,即相同取值的个案 只录入一次,另加一个频数变量用于记录该数值共出现了
多少次,这样就需要在 分析时使用“加权个案” 对话框将数据指定为频 数格式(加下页)。
1/11/2020 10:14 AM
浙江树人大学管理学院
9
点击【数据】→【加权个案】
观察其描述性统计:
1/11/2020 10:14 AM
96.60 90.11 81.94
合计
481
51 532
90.41
1/11/2020 10:14 AM
浙江树人大学管理学院
12
SPSS操作过程(行×列表卡方检验)
①建立数据文件 数据格式:包括6行3列的频数格式,3个变量分别为
行变量、列变量和频数变量。 ②说明频数变量:数据 加权个案
浙江树人大学管理学院
11
加权个案用在卡方检验上的案例
例 某医师研究物理疗法、药物治疗和外用膏药三
种疗法治疗周围性面神经麻痹的疗效,资料见表。 问三种疗法的有效率有无差别?
疗法
三种疗法有效率的比较
有效 无效 合计 有效率(%)
物理疗法组 199 药物治疗组 164 外用膏药组 118
7 206 18 182 26 144
“过滤掉未选定的个案”:未选定的个案不包括在分析中, 但保留在数据集中,使用该选项会在数据文件中生成名为 filter_$的变量,对于选定个案该变量的值为1,对于未选定
第01节如何建立SPSS数据文件

第01节如何建立SPSS数据文件SPSS(Statistical Package for the Social Sciences)是一种专业的统计分析软件,被广泛应用于社会科学、市场调研以及其他领域的数据分析中。
建立SPSS数据文件是使用SPSS进行数据分析的第一步,本文将介绍如何建立SPSS数据文件的步骤。
1. 确定数据变量在建立SPSS数据文件之前,首先需要确定好需要收集和记录的各个数据变量。
数据变量包括各种观测指标或测量项目,可以是数值型、顺序型或名义型的变量。
2. 打开SPSS软件双击打开SPSS软件,进入SPSS统计分析界面。
3. 创建新数据文件在SPSS界面的主菜单栏选择"File" -> "New" -> "Data",或者直接点击工具栏上的新建数据文件图标。
弹出新建数据文件对话框。
4. 设定数据文件属性在新建数据文件对话框中,可以设置数据文件的属性,包括数据文件名、存储位置、数据文件类型等。
根据需要填写相应信息,并确定保存位置和数据文件类型。
5. 定义数据变量在数据视图窗口中,可以依次定义各个数据变量。
点击数据视图窗口中的第一个空白格,输入第一个数据变量的名称,并按下"Tab"键移动到下一个格子中。
在下一个格子中选择适当的数据类型(如数值型、字符型等)并输入数据,然后按下"Tab"键继续定义下一个数据变量。
依此类推,逐个定义好所有的数据变量。
6. 设定数据值标签在数据视图窗口中,还可以对特定的数据变量设定数据值标签。
选中某个数据变量所在的格子,点击菜单栏中的"Variable View",在弹出的对话框中输入该变量的数据值标签。
7. 保存数据文件在完成所有数据变量的定义后,点击菜单栏中的"File" -> "Save",选择保存数据文件。
spss 第3章

主要内容
3.1 频数分析 3.2 描述分析 3.3 求分组平均数 3.4 求交叉分组平均数(列联表分析) 3.5 统计分析图的制作
3.1 频数分析
• 频数分布表 知识回顾 • 统计量 – 分位数(四分位数、百分位数) – 离散趋势指标(标准差、方差、全距、 最小值、最大值) – 集中趋势指标(算术平均数、中位数、 众数、总和) – 分布参数 • 统计图:条形图、饼图、直方图
3.2 描述分析
• Descriptives:计算变量的描述性统 计量(均值、总和、标准差等)
3.2.2 例题
结果分析
3.3 求分组平均数
3.3.1 主要参数
3.3.2 例题
结果分析
3.4 交叉分组描述(卡方检验)
• 检验两个变量是否有关联 • 列联表分析 • 知识回顾
某集团公司打算进行一项改革,但此项改革涉及
Graphs
3.5.1 条形图(Bar)
1、条形图的类型 – 3种形状 – 3种统计量综述方式 – 9种组合方式构成9种 类型的条形图
例题1 简单条形图-个案分组
• 问题:对不同顾客类型(X1)的满意 度(X19)平均数进行统计作图。
例题2 简性的平均 数统计图,按照不同地区分列。
描述分析
求分组平均数
• 按照某个变量分组统计某个或多个变 量值对应的统计量。
求交叉分组平均数
• 检验两个变量是否有关联 • 列联表分析 2 • 检验
H0:两个变量独立
H1:两个变量不独立
统计分析图的制作
• • • • • • • • • • • 条形图 三维条形图 线图 面积图 饼图 高低图 盒式图 误差图 总体锥图 散点图 直方图
实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构

实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。
SPSS统计分析第章数据文件建立和管理

SPSS统计分析第章数据文件建立和管理引言SPSS(Statistical Product and Service Solutions)是一个被广泛使用的统计分析软件,它的分析功能十分强大,因此在社会科学、教育研究、医学研究等领域得到了广泛的应用。
而SPSS的数据文件建立和管理是使用SPSS时必须掌握的基本操作,它能够让我们更加高效地管理数据,减少误操作,提高分析效率。
本文将介绍SPSS的数据文件建立和管理。
SPSS数据文件建立SPSS数据文件包含两个主要部分:数据字典和数据录入。
数据字典是说明数据文件包含哪些变量,每个变量的名称、类型、取值范围等信息。
数据录入是将实际数据输入到数据文件中。
在建立SPSS数据文件时,需要先建立数据字典,然后再进行数据录入。
数据字典的建立数据字典是SPSS数据文件的重要组成部分,它包含了数据文件中的变量定义和取值范围。
在SPSS中建立数据字典的过程如下:1.打开SPSS软件并新建数据文件:打开SPSS软件,点击“文件”菜单,选择“新建数据文件”选项,弹出新建数据文件对话框。
选择“默认”选项设置数据文件名称和存储位置,并点击“确定”按钮,即可新建一个空的SPSS数据文件。
2.添加变量定义:在新建数据文件中,点击“变量视图”选项卡,然后在空白区域右键单击,选择“插入变量”选项,弹出“建立变量”对话框。
在该对话框中输入变量名称、类型(数值型、文字型、日期型等)、长度、标签等信息,然后点击“添加”按钮。
3.设置变量取值范围:在“建立变量”对话框中,设置变量的取值范围,例如最小值、最大值、有效值等。
点击“确定”按钮,变量将被添加到数据字典中。
4.重复以上步骤,创建所有需要的变量。
数据录入数据录入是向SPSS数据文件中输入实际数据的过程,通常可以使用多种方式进行,如手动输入、导入外部数据等。
手动输入是最常见的方式,它需要打开数据文件并逐行录入数据,并注意每个字段的格式要与数据字典一致。
spss基本操作

11
变量的定义信息
在图所示的窗口中每一行表示一个变量的定义信息,包括Name(变量 名)、Type(变量类型)、Width(变量格式宽度)、Decimal(变量小数位)、 Label(变量名标签)、Values(变量值标签)、Missing(变量缺失值)、 Columns(变量列宽)、Align(变量对齐方式)、Measure(变量测度水平)等。
启动SPSS后看到的第一个窗口便是数据编辑窗口,如图所示。在数据编辑 窗口中可以进行数据的录入、编辑以及变量属性的定义和编辑,是SPSS的 基本界面。主要由以下几部分构成:标题栏、菜单栏、工具栏、编辑栏、 变量名栏、观测序号、窗口切换标签、状态栏。
5
标题栏:显示数据编辑的数据文件名。 菜单栏:通过对这些菜单的选择,用户可以进行几乎所有的SPSS
31
Step02:选择合并文件
点选【An external SPSS Statistics data file(外部SPSS Sta tistics数据文件)】 单选钮,同时单击【Browse】按 钮,选中需要合并的文件,并指定文件路径, 然后 单击【Continue】按钮。
17
缺失值的定义方式:Missing
SPSS有两类缺失值:系统缺失值和用户缺失值。 单击Missing相应单元中的按钮,在弹出的如图2-5所示 的对话框中可改变缺失值的定义方式,在SPSS中有两种定义 缺失值的方式。 可以定义3个单独的缺失值。 可以定义一个缺失值范围和一个单独的缺失值。
18
变量的显示宽度:Columns
16
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
点击【数据】→【加权个案】
观察其描述性统计:
(2) 案例数据抽样权重的确定
例如:希望掌握菜市场某天蔬菜销售的平均价格。如果 仅使用各种蔬菜销售单价的平均数作为平均价格就很不合理, 还应考虑到销售量对平均价格的影响。因此,以蔬菜的销售 量为权数计算各种蔬菜销售单价的加权平均数,就能够较准
确地反映平均价格的水平。
收入情况、未来收入情况,取值分别为:1,增加;2,
基本不变;3,减少。 如果想了解在每一个个案中,选3(减少)的变量有几个,
如何用SPSS快速的给出答案?
例子特点:多个变量中 ,取同一个值的变量有多少个?
例2:高考成绩.sav :要统计出每一考生语文、英语、数
学、物理和化学5科成绩,落在某一区间(如[70,79])的有几科? 例子特点:多个变量,取值在同一个区间的有多少个?
(2) 计数取某一值变量的个数
计数涉及的变量一般都取多个值,我们只关心多个变量
同时取某一个值或在某一个区间取值变量的个数。
例子:收入情况未来收入情况这两个变量取3的有几个? 点击【 定义值 】按钮,确定变量取值的对话框,见图
A) 值 在Value下边的文本框中填入几个变量都取的值,对于我
们的例子填入3,完成设置。
3. 加权个案(通常在做卡方检验的时候用的比较多
一般而言,下面两种情形需要进行该操作:
(1) 以频数录入的格式
在默认情况下,数据集中的每一行就是一条原始记录, 这在多数情况下没有什么问题,但有时却很麻烦。如果所示 的数据:如果每一行就是一条原始记录,需要输入121行! 这时候一般使用频数格式录入数据,即相同取值的个案 只录入一次,另加一个频数变量用于记录该数值共出现了 多少次,这样就需要在 分析时使用“加权个案” 对话框将数据指定为频 数格式(加下页)。
高级工程师对应工资上浮5%,高级职称的值等于1,在 编辑框输入条件表达式:zc=1。
5) 条件语句编辑例
这时高级工程师的个案的sfgz变量都有了数据,其它职 称个案的sfgz的值为缺失值。 重复同样的方法,分别设置: 表达式 (sr-bx)*1.03 (sr-bx)*1.02 条件 zc=2 zc=3 工程师 助理工程师
B) S系统缺失、 系统或用户缺失。
统计几个变量同时取系统缺失值、用户缺失值的个数,
很少用,略。 C) 范围:
m 到
。n
统计多个变量中,在闭区间[m,n]中取值的变量个数。 例如,在高考成绩.sav数据集中,成绩的5个变量都在区
间[70,79]中取值的变量个数。
这时m=70,n=79,完成设置后观察生成变量的数据并进 行分析。
案的值将替换旧变量对应的值,其它值不变。
c) 新变量的数据类型默认为数值型,点击类型与标签按 钮,在弹出的对话框中可以定义新变量的数据类型和标签。 对于我们的例子,新变定义量名 实发工资为:sfgz,选 择默认数据类型。
(sr-bx)*系数,系数因职称不同而不同,下图是上浮 5%的情况,其它情形相似。
以上问题,如何通过SPSS软件实现?
1) 计数的功能
计数是统计出在一个个案中,多个变量取同一个值或在
同一个区间取值的变量个数的方法。
因此,处理这样的问题需要关注两个问题: A) 考察哪几个变量?
B) 同时取什么值,在哪一个区间取值?
2) 计数的步骤
选择菜单 转换 计算个案内值的出现次数,进入计数
B) 选择分类变量
从左边的变量列表框选择分类变量到分组变量框中。操
作:职业。
C) 选择汇总变量 汇总变量汇总变量模块。
操作:存款金额 D) 确定计算什么统计量。
点击【 函数 】按钮,弹出选择对话框,可供选择的统 计量包括: 均值、求和、最大值、最小值等20个选项,默认选项是 均值,每次只能计算一个统计量。默认是均值。 【 变量名与标签 】按钮为计算的统计量定制标签。 操作:均值(注意观察汇总变量的取值随着选择的改变而改变) E) 输出每一类中包含的个案数。 选择框 个案数,若选择将生成一个每一类中所含个案数 的变量,变量名为N_BREAK。
4) 条件语句编辑
单击 if 按钮,进入条件语句编辑框,有两个单选按钮。
a) 包括所有个案 :对所有个案进行计算,默认选项。
b) 如果个案满足条件则包括:仅对满足条件的个案进行 计算。选择这一单选按钮后,编辑框激活。 c) 在这里可以输入筛选条件。需要说明的是,每次只能
编辑一个筛选条件,不能同时编辑多个筛选条件。
SPSS统计分析方法及应用第三章
SPSS 数据的预处理
数据文件建立完成之后,为了方便统计分析,需要对数
据进行初步的处理,如对数据进行排序,将一列数据扩大一 个倍数,多列数据的求和等等。
1 数据的排序 1) 数据排序的目的
数据集中的数据是按照录入的先后排列的,并没有规律 可言,不便于数据的分析。数据排序有什么好处呢? a) 数据的排序,有助于了解数据的取值状况、变化规律、 缺失值的个数等等。 b) 数据的排序,方便的得到变量的最大值、最小值,计 算出数据的全距,了解数据的离散程度。
1) 分类汇总关注的问题
A) 按照哪个变量进行分类(如:区域、性别)。 B) 对哪个变量进行汇总(如:职工工资、高考总分)。 C) 计算哪些指标(如:平均值、最大值和最小值)。
例:利用居民储蓄调查数据.sav数据集,分析职业与存
款数额之间的关系。
2) 分类汇总的基本操作
A) 打开汇总菜单 点击:数据 分类汇总,弹出分类汇总对话框。
4. 数据的拆分(Split)
(1) 数据拆分的意义
在进行统计分析时,经常要对文件中的观测进行分组, 然后按组分别进行分析。例如要求按性别不同分组。又比如, 省统计局每次的数据处理都是针对各个地级市的;学校对于 学生数据的处理都是针对各个系的。 以数据加工(职工数据).sav为例,我们需要看统计比较不
下面我们看各种设置的结果 不设置
比较组
按组织输出
5 变量的计算
在实际工作中,经常要对变量进行加工整理,产生新的
变量和计算结果。
比如计算一个变量的倍数,计算几个变量的和、差,计 算变量的绝对值、平方等等。
SPSS如何对变量进行计算呢?
变量计算的例(58页)
对职工的基本情况的数据(41页)表2-5进行处理,依据职 称级别计算实发工资,满足:职称1~4的工资分别上浮5%、
3) 数据排序的操作
a) 选择菜单数据 排序个案。这时,数据集所有变量
出现在排序对话框左侧的列表中。 b) 选择排序变量并移入 排序依据列表框中,指定该变量 的数据是升序(Ascending)还是降序(Descending)的单选按钮. c)量先排序;第一个变量相同,按下一个变 量排序;余类推。
确认后sfgz中zc只有1的个案出现了工作调整的数据, 其它做系统缺失值处理,再确认2、3、4时可将其补充。
3) 算术表达式及运算符的定义
a)算术表达式的元素。变量可以从左侧的变量列表中选
择;数字、运算符号可以在软键盘中选择;函数可以从右侧 选择,这些也都可以直接用键盘输入。 b)逻辑运算符及意义 逻辑与:& 逻辑或: | 逻辑非:~ 等价于 等价于 等价于 AND OR NOT
加权个案用在卡方检验上的案例
例 某医师研究物理疗法、药物治疗和外用膏药三
种疗法治疗周围性面神经麻痹的疗效,资料见表。 问三种疗法的有效率有无差别?
三种疗法有效率的比较
疗法 物理疗法组 药物治疗组 外用膏药组 合计 有效 199 164 118 481 无效 7 18 26 51 合计 206 182 144 532 有效率(%) 96.60 90.11 81.94 90.41
选择对话框。出现计数设置对话框见图3-6。
图3-6 计数操作设置窗口
(1) 确定计数变量
计数变量用于存储统计结果。步骤如下: a) 目标变量:在下面的文本框填入目标变量,用于存储 计数的值。 操作:在文本框中输入 X b) 目标标签 :在下面的文本框中输入变量的标签,作为 目标变量的说明,可选。操作:堪忧。 c) 数字变量 :将要计数的变量移入。 操作:收入情况、未来收入情况
E) 指定计算的统计量保存到何处。有3中选择。 a) 将统计量的计算结果存储到当前数据集。 b) 创建一个只含指定统计量作为变量的新数据集。
这时需在下面的文本框给出数据集的名字。 c) 将计算的统计量存储到一个默认名称为agg.sav,的新
文件中。文件类型可以不是SPSS的文件类型。
c) 数据的排序,可以快速发现异常值,以便及时对其进 行处理。
2) 数据排序的规则
a) 排序分为升序与降序,可以同时对数据集中的多个变 量进行排序。
b) 排序的规则是:按第一个变量排序,第一个变量相同
时按第二个变量排序,余此类推。 c) 排序将导致个案的位置改变,未排序的变量数据随排
序变量的位置同时改变。
(sr-bx)*1.01
zc=4
无职称
这时变量sfgz所在的列将不再有缺失值。
6) 计算方法的不足
对于满足一定条件时变量的计算,无法一次将不同条件 的表达式集中编写,只能一个条件的表达式运行一次。
6. 计数
在实际工作当中,需要对调查问卷的答案进行分析。 例1:居民储蓄调查(存款).sav中有如下两个指标:
同职称的失业保险情况(对之进行统计性描述)。
(2) 数据拆分的步骤
选择菜单【数据】→【拆分文件】,如下图所示 :
在对话框的右上端有3个单选按钮。
a) 分析所有个案,不创建组:默认选项,此选项也用于 将拆分设置删除。
b) 比较组:将各组的结果在一个表输出,以方便结论的
比较对照。 c) 按组分多个表输出结果。 数据排序状态 分组状态的2个单选按钮。 a) 按分组变量排序文件:系统先按分组变量排序,然后 进行拆分。 b) 文件已排序:已经按分组变量进行了排序,系统不需 要再进行排序,可直接进行拆分。