计量资料的统计课后习题
统计学各章节练习题

计量资料的统计描述练习题选择题:1、描述一组偏态分布资料的变异度,以()指标较好。
A、全距B、标准差C、变异系数D、四分位数间距E、方差2、用均数和标准差可以全面描述()资料的特征。
A、正偏态分布B、负偏态分布C、正态分布D、对称分布E、对数正态分布3、各观察值均加(或减)同一数后()。
A、均数不变B、几何均数不变C、中位数不变D、标准差不变E、变异系数不变4、比较某地1~2岁和5~6岁儿童身高的变异程度,宜用()。
A、极差B、四分位数间距C、方差D、变异系数E、标准差5、偏态分布宜用()描述其分布的集中趋势。
A、均数B、标准差C、中位数D、四分位数间距E、方差6、各观察值同乘以一个不等于0的常数后,()不变。
A、算术均数B、标准差C、几何均数D、中位数E、变异系数7、()分布的资料,均数等于中位数。
A、对数正态B、正偏态C、负偏态D、偏态E、正态9、横轴上,标准正态曲线下从0到2.58的面积为()。
A、99%B、45%C、99.5%D、47.5%E、49.5%10、当各观察值呈倍数变化(等比关系)时,平均数宜用()。
A、均数B、几何均数C、中位数D、相对数E、四分位数1、算术均数和中位数相比,算数均数()A、抽样误差更大B、不易受极端值的影响C、更充分利用数据信息D、更适用于偏态分布资料E、更适用于分布不明确资料2、计算几何均数时,采用以e为底的自然对数ln(X)和采用以10为底的常用对数lg(X),所得的计算结果()A、相同B、不相同C、有时相同,有时不同D、只能采用ln(X)E、只能采用lg(X)3、在服从正态分布条件下,样本标准差S的值()A、与算术均数无关B、与个体的变异程度有关C、与样本量无关D、与集中趋势有关E、与量纲无关4、比较身高和体重两组数据的变异大小,宜采用()A、方差B、标准差C、全距D、四分位数间距E、变异系数5、变异系数CV的数值()A、一定大于等于1B、一定小于等于1C、一定比标准差小D、一定等于1E、可以大于1,也可以小于1概率分布1、正态分布曲线下方横轴上方,从μ到μ+2.58σ的面积占曲线下总面积的()A、99%B、95%C、47.5%D、49.5%E、90%2、在X轴上方,标准正态曲线下中间95%的面积所对应X的取值范围是()A、-∞~+1.96B、-1.96~+1.96C、-∞~+2.58D、-2.58~+2.58E、-1.64~+1.643、正态曲线上的拐点的横坐标为()A 、μ±2σB 、μ±σC 、μ±3σD 、μ±1.96σE 、μ±2.58σ 4、计算医学参考值范围最好是()A 、百分位数法B 、正态分布法C 、对数正态分布法D 、标准化法E 、结合原始数据分布选择计算公式5、根据200个人的发铅值(分布为偏态分布),计算正常人发铅值95%参考值范围应选择()A 、双侧正态分布法B 、双侧百分位数法C 、单上侧正态分布法D 、单下侧百分位数法E 、单上侧百分位数法 6、正态分布中,当μ恒定时,σ越大A 、曲线沿横轴向左移动B 、曲线沿横轴向右移动C 、观察值变异程度越大,曲线越扁平D 、观察值变异程度越小,曲线越细高E 、曲线位置和形状不变7、均数的标准误反映了()A 、个体变异程度的大小B 、个体集中趋势的位置C 、指标的分布特征D 、频数的分布特征E 、样本均数与总体均数的差异参数估计1、当样本含量增大时,以下说法正确的是()A 、标准差会变小B 、标准差会变大C 、样本均数标准误会变大D 、样本均数标准误会变小E 、以上都不对 2、区间x S x 58.2±的含义是()A 、99%总体观察值在此范围内B 、99%样本观察值在此范围内C 、总体均数99%置信区间D 、样本均数99%置信区间E 、以上都不对 3、通常可采用以下哪种方法来减小抽样误差()A 、减小样本标准差B 、增大样本标准差C 、减小样本量D 、增大样本量E 、以上都不对4、均数的标准误反映了()A 、个体变异程度的大小B 、个体集中趋势的位置C 、指标的分布特征D 、频数的分布特征E 、样本均数的与总体均数的差异假设检验1、两样本均数比较的t 检验,差别有统计学意义时,P 值越小,说明() A 、两样本均数差别越大B 、两总体均数差别越大C 、越有理由认为两总体均数不同D 、越有理由认为两样本均数不同E 、越有理由认为两总体均数不相同2、在参数未知的正态总体中随机抽样,≥-||μx ()的概率为5%。
计量经济学(第四版)习题及参考答案解析详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
医学统计学课后习题答案解析

医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± 68.27% 95% 99%5. 47.5%6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显著性水准、0.05、 0.01 (0.1)11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同?答:相同点,均表示计量资料集中趋势的指标。
医学统计学课后习题答案

医学统计学课后习题答案 Revised by Jack on December 14,2020医学统计学第一章 绪论答案名词解释:(1) 同质与变异:同质指被研究指标的影响因素相同,变异指在同质的基础上各观察单位(或个体)之间的差异。
(2) 总体和样本:总体是根据研究目的确定的同质观察单位的全体。
样本是从总体中随机抽取的部分观察单位。
(3) 参数和统计量:根据总体个体值统计算出来的描述总体的特征量,称为总体参数,根据样本个体值统计计算出来的描述样本的特征量称为样本统计量。
(4) 抽样误差:由抽样造成的样本统计量和总体参数的差别称为抽样误差。
(5) 概率:是描述随机事件发生的可能性大小的数值,用p 表示(6) 计量资料:由一群个体的变量值构成的资料称为计量资料。
(7) 计数资料:由一群个体按定性因数或类别清点每类有多少个个体,称为计数资料。
(8) 等级资料:由一群个体按等级因数的级别清点每类有多少个体,称为等级资料。
是非题:1. ×2. ×3. ×4. ×5. √6. √7. ×单选题:1. C2. E3. D4. C5. D6. B第二章 计量资料统计描述及正态分布答案名词解释:1. 平均数 是描述数据分布集中趋势(中心位置)和平均水平的指标2. 标准差 是描述数据分布离散程度(或变量变化的变异程度)的指标3. 标准正态分布 以μ服从均数为0、标准差为1的正态分布,这种正态分布称为标准状态分布。
4. 参考值范围 参考值范围也称正常值范围,医学上常把把绝大多数的某指标范围称为指标的正常值范围。
填空题:1. 计量,计数,等级2. 设计,收集资料,分析资料,整理资料。
3. σμχ-=u (变量变换)标准正态分布、0、1 4. σ± σ96.1± σ58.2± % 95% 99%5. %6.均数、标准差7. 全距、方差、标准差、变异系数8. σμ96.1± σμ58.2±9. 全距 R10. 检验水准、显着性水准、、 ()11. 80% 90% 95% 99% 95%12. 95% 99%13. 集中趋势、离散趋势14. 中位数15. 同质基础,合理分组16. 均数,均数,μ,σ,规律性17. 标准差18. 单位不同,均数相差较大是非题:1. ×2. √3. ×4. ×5. ×6. √7. √8. √9. √ 10. √11. √ 12. √ 13. × 14. √ 15. √ 16. × 17. × 18. × 19. √ 20. √21. √单选题:1. B2. D3. C4. A5. C6. D7. E8. A9. C 10. D11. B 12. C 13. C 14. C 15. A 16. C 17. E 18. C 19. D 20. C21. B 22. B 23. E 24. C 25. A 26. C 27. B 28. D 29. D 30. D31. A 32. E 33. D 34. A 35. D 36. D 37. C 38. E 39. D 40. B41. C 42. B 43. D 44. C 45. B问答题:1.均数﹑几何均数和中位数的适用范围有何异同答:相同点,均表示计量资料集中趋势的指标。
计量经济学课后题答案
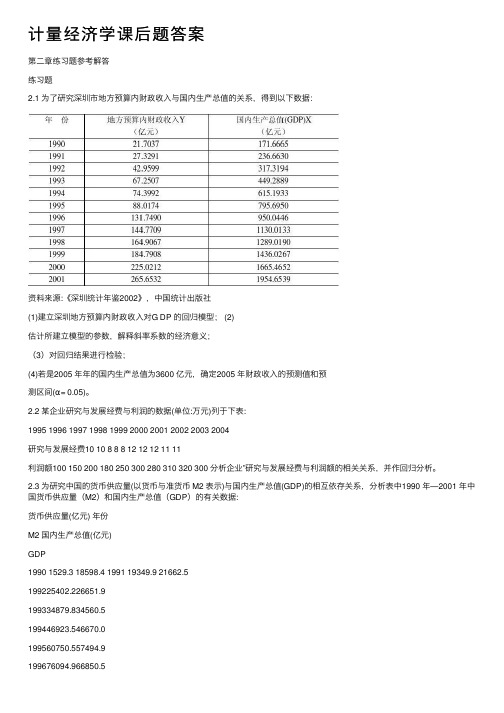
计量经济学课后题答案第⼆章练习题参考解答练习题2.1 为了研究深圳市地⽅预算内财政收⼊与国内⽣产总值的关系,得到以下数据:资料来源:《深圳统计年鉴2002》,中国统计出版社(1)建⽴深圳地⽅预算内财政收⼊对G DP 的回归模型; (2)估计所建⽴模型的参数,解释斜率系数的经济意义;(3)对回归结果进⾏检验;(4)若是2005 年年的国内⽣产总值为3600 亿元,确定2005 年财政收⼊的预测值和预测区间(α= 0.05)。
2.2 某企业研究与发展经费与利润的数据(单位:万元)列于下表:1995 1996 1997 1998 1999 2000 2001 2002 2003 2004研究与发展经费10 10 8 8 8 12 12 12 11 11利润额100 150 200 180 250 300 280 310 320 300 分析企业”研究与发展经费与利润额的相关关系,并作回归分析。
2.3 为研究中国的货币供应量(以货币与准货币 M2 表⽰)与国内⽣产总值(GDP)的相互依存关系,分析表中1990 年—2001 年中国货币供应量(M2)和国内⽣产总值(GDP)的有关数据:货币供应量(亿元) 年份M2 国内⽣产总值(亿元)GDP1990 1529.3 18598.4 1991 19349.9 21662.5199225402.226651.9199334879.834560.5199446923.546670.0199560750.557494.9199676094.966850.5199790995.373142.71998104498.576967.21999119897.980579.42000134610.388228.12001158301.994346.4资料来源:《中国统计年鉴2002》,第51 页、第662 页,中国统计出版社对货币供应量与国内⽣产总值作相关分析,并说明分析结果的经济意义。
计量资料的统计推断

2018/6/22
Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106
均数
8
6.
19
2、均数的标准误
均数的标准误 (standard error of mean):样本均数的标准差,它反映了 样本均数间的离散程度。 意 义:反映抽样误差的大小。标准误越 小,抽样误差越小,用样本均数估计总体 均数的可靠性越大。
5
样本均数分布示意图:
样本 1 x1 样本 2 样本 3
x2
x3
总体 X
μσ
样本 4 样本 5
x4
x5 x.....
样本均数 X
若 总 体 服 从 正 态 分 布 或 抽 样 例 数 足 够 大
样本 6
x6
N ,
2018/6/22 Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106
某地成年男子红细胞数的抽样调查, n=144人,均数为5.38×1012/L, s=0.44×1012/L,求其标准误。
s 0.44 12 sx n 144 0.037(10 / L)
2008执考:若不知总体标准差,反映均数 抽样误差大小的指标,用: A. S B. sx C.SP D.σp E. x
2018/6/22 Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106 11
3、标准误与标准差的区别与联系 标准差 标准误
意义 衡量均数的标准差,衡 量样本均数的离散程度, 反映了抽样误差的大小。
s
( x x ) n 1
2018/6/22 Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106 4
计量课后习题第二章
2.1题:(1)Dependent Variable: YMethod: Least SquaresDate: 05/24/15 Time: 14:13Sample: 2001 2022Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134Y=56.64794+0.128360x1Dependent Variable: YMethod: Least SquaresDate: 05/24/15 Time: 15:30Sample: 2001 2022Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001Y=38.79424+0.331971x2Dependent Variable: YMethod: Least SquaresDate: 05/24/15 Time: 15:30Sample: 2001 2022Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103Y=31.79956+0.387276X3Dependent Variable: YMethod: Least SquaresDate: 05/24/15 Time: 15:27Sample: 2001 2022Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 32.99309 3.138595 10.51206 0.0000X1 0.071619 0.014755 4.853871 0.0001X2 0.168727 0.039956 4.222811 0.0005X3 0.179042 0.048869 3.663731 0.0018R-squared 0.906549 Mean dependent var 62.50000Adjusted R-squared 0.890974 S.D. dependent var 10.08889S.E. of regression 3.331262 Akaike info criterion 5.407545Sum squared resid 199.7515 Schwarz criterion 5.605916Log likelihood -55.48299 Hannan-Quinn criter. 5.454275F-statistic 58.20479 Durbin-Watson stat 1.616536Prob(F-statistic) 0.000000Y=32.99309+0.071619x1+0.168727x2+0.179042x3(2)拟合优度的度量:人均寿命与人均GDP的R^2=0.526082,说明所建模型整体上对样本数据拟合还行,即解释变量“人均GDP”对被解释变量“人均寿命”的小部分差异作出了解释。
第二章 计量资料的统计描述
意义:越大说明离散程度越大 优点:计算简单 缺点:不能全面反映资料的离散程度;不稳定,易受 极端值影响
(二)四分位数间距(Quartile interval)
四分位数间距( Q ):将一组资料分为四等份,上四分位数QU(P75) 与下四分位数QL(P25)之差。
(四)众数(mode)
• 众数是指一组观察值中出现次数最多的那个数值。一组观察 值可以有多个众数,也可以没有众数。众数只有在数据量较 大时才有意义。众数不受极端值大小的影响,但它掩盖的信 息经常比它揭示的要多。
• 例2-1资料中有频数最大为4的6个众数,分别为131、133、135、13 8、142、145(g/L);当列成表2-1的频数分布时,由于“138~” 组的频数为21最大,因此众数为该组的组中值141.5(g/L)。
不但反映研究指标数值的稳定性和均匀性,而且反映集中 性指标的代表性。
三组同性别同年龄儿童的体重如下:
x 甲组:26 28 30 32 34 甲 = 30Kg x 乙组:24 27 30 33 36 乙 = 30Kg x 丙组:26 29 30 31 34 丙 = 30Kg
(一)全距(Range)
集中趋势和离散趋势是揭示数据分布的类型和正
确进行统计描述与统计推断的前提。
(三)异常值的识别
频数表有助于发现极小或极大的异常值。 在频数表的两端连续出现几个组段的频数为0后,又
出现一些极小值或极大值,应怀疑这些资料的准确 性,需对这些数据进一步核对和复查,若发现错误, 及时改正。
(四)有利于进一步对资料进行 统计描述与分析
2 (xi )2
N
s2
xi
x2
计量课后习题
矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。
计量经济学的课后习题答案
计量经济学的课后习题答案计量经济学的课后习题答案计量经济学是经济学中的一个重要分支,它运用数理统计学和经济理论的方法来研究经济现象。
在学习计量经济学的过程中,课后习题是巩固知识和提高能力的重要途径。
下面将为大家提供一些计量经济学的课后习题答案,希望对大家的学习有所帮助。
第一题:回归分析假设我们有一个简单的线性回归模型:Y = β0 + β1X + ε,其中Y表示因变量,X表示自变量,β0和β1是回归系数,ε是误差项。
我们通过最小二乘法估计得到的回归方程为Y = 2 + 3X。
根据这个回归方程,当X等于5时,预测Y的值是多少?答案:根据回归方程,当X等于5时,预测Y的值为2 + 3*5 = 17。
第二题:假设检验在计量经济学中,假设检验是一种常用的统计方法,用于检验某个经济理论或假设是否成立。
假设我们有一个假设H0:β1 = 0,即自变量X对因变量Y没有显著影响。
我们通过回归分析得到的t统计量为2.5,自由度为50。
在显著性水平为0.05的条件下,我们应该接受还是拒绝这个假设?答案:在显著性水平为0.05的条件下,自由度为50的t分布的临界值为1.96。
由于t统计量的值(2.5)大于临界值(1.96),我们可以拒绝假设H0,即自变量X对因变量Y有显著影响。
第三题:多元回归分析多元回归分析是计量经济学中常用的分析方法之一,它考虑了多个自变量对因变量的影响。
假设我们有一个多元回归模型:Y = β0 + β1X1 + β2X2 + ε,其中Y表示因变量,X1和X2表示两个自变量,β0、β1和β2是回归系数,ε是误差项。
我们通过最小二乘法估计得到的回归方程为Y = 1 + 2X1 + 3X2。
根据这个回归方程,当X1等于3,X2等于4时,预测Y的值是多少?答案:根据回归方程,当X1等于3,X2等于4时,预测Y的值为1 + 2*3 +3*4 = 19。
第四题:异方差问题在计量经济学中,异方差是指误差项的方差不恒定,而是与自变量的取值相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章 课后习题
一、选择题
1.描述一组偏态分布资料的变异度,以( )指标较好。
A. 全距 B. 标准差 C. 变异系数
D. 四分位数间距 E. 方差
2.各观察值均加(或减)同一数后( )。
A. 均数不变,标准差改变 B. 均数改变,标准差不变
C. 两者均不变 D. 两者均改变 E. 以上都不对
3.偏态分布宜用( )描述其分布的集中趋势。
A. 算术均数 B. 标准差 C. 中位数
D. 四分位数间距 E. 方差
4.为了直观地比较化疗后相同时点上一组乳腺癌患者血清肌酐和血液尿素氮两
项指标观测值的变异程度的大小,可选用的最佳指标是( )。
A.标准差 B.标准误 C.全距 D.四分位数间距 E.变异系数
5.测量了某地152人接种某疫苗后的抗体滴度,宜用( )反映其平均滴度。
A. 算术均数 B. 中位数 C.几何均数 D.众数 E.调和均数
6.测量了某地237人晨尿中氟含量(mg/L),结果如下:
尿氟值:0.2~ 0.6~ 1.0~ 1.4~ 1.8~ 2.2~ 2.6~ 3.0~ 3.4~ 3.8~
频 数: 75 67 30 20 16 19 6 2 1 1
宜用( )描述该资料。
A. 算术均数与标准差 B.中位数与四分位数间距 C.几何均数与标准差
D. 算术均数与四分位数间距 E. 中位数与标准差
7.用均数和标准差可以全面描述( )资料的特征。
A. 正偏态资料 B. 负偏态分布 C. 正态分布
D. 对称分布 E. 对数正态分布
8.比较身高和体重两组数据变异度大小宜采用( )。
A. 变异系数 B. 方差 C. 极差 D. 标准差 E. 四分位数间距
9.血清学滴度资料最常用来表示其平均水平的指标是( )。
A. 算术平均数 B. 中位数 C. 几何均数 D. 变异系数 E. 标准差
10.最小组段无下限或最大组段无上限的频数分布资料,可用( )描述其集
中趋势。
A. 均数 B. 标准差 C. 中位数 D. 四分位数间距 E. 几何均数
11.现有沙门菌食物中毒患者164例的潜伏期资料,宜用( )描述该资料。
A. 算术均数与标准差 B.中位数与四分位数间距 C.几何均数与标准差
D. 算术均数与四分位数间距 E. 中位数与标准差
12.测量了某地68人接种某疫苗后的抗体滴度,宜用( )反映其平均滴度。
A. 算术均数 B. 中位数 C.几何均数 D.众数 E.调和均数
二、计算题
1. 某市1973年120名12岁男孩身高频数分布如下
身高(cm) 频数
125~ 1
129~ 4
133~ 9
137~ 28
141~ 35
145~ 27
149~ 11
153~ 4
157~ 1
合计 120
试回答此频数分布类型,应该用何指标描述其特征。试计算均数、标准差、中位数、
四分位数、p2.5及p97.5。
2. 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白含量,结果见表
(1)说明女性的红细胞数与血红蛋白含量的变异程度何者为大;
(2)分别计算男、女两项指标的抽样误差;
(3)试估计该地健康成年男、女红细胞数的均数;
(4)试估计该地健康成年男、女红细胞数的95%医学参考值范围。
指标 性别 例数 均数 标准差 标准值
红细胞数/(1012/L)
男
360 4.66 0.58 4.84
女
255 4.18 0.29 4.33
血红蛋白/(g/L)
男
360 134.5 7.1 140.2
女
255 117.6 10.2 124.7