数据库的查询

河南工业大学实验报告
课程数据库技术基础实验名称数据库的查询
院系中英国际学院专业班级
一.目的和要求
1.掌握SELECT语句的基本用法;
2.掌握子查询的表示;
3.掌握连接查询的表示;
4.掌握SELEFCT语句的GROUP BY子句的作用和方法;
5.掌握SELECT语句的ORDER BY子句的作用和使用方法。
二.实验准备
1.了解SELECT语句的基本语法格式;
2.了解SELECT语句的执行方法;
3.了解子查询的表示的方法;
4.了解连接查询的表示;
5.了解SELECT语句的GROUP BY子句的作用和使用方法;
6.了解SELECT语句的ORDER BY子句的作用。
三.实验内容
实验4-1
数据库的查询
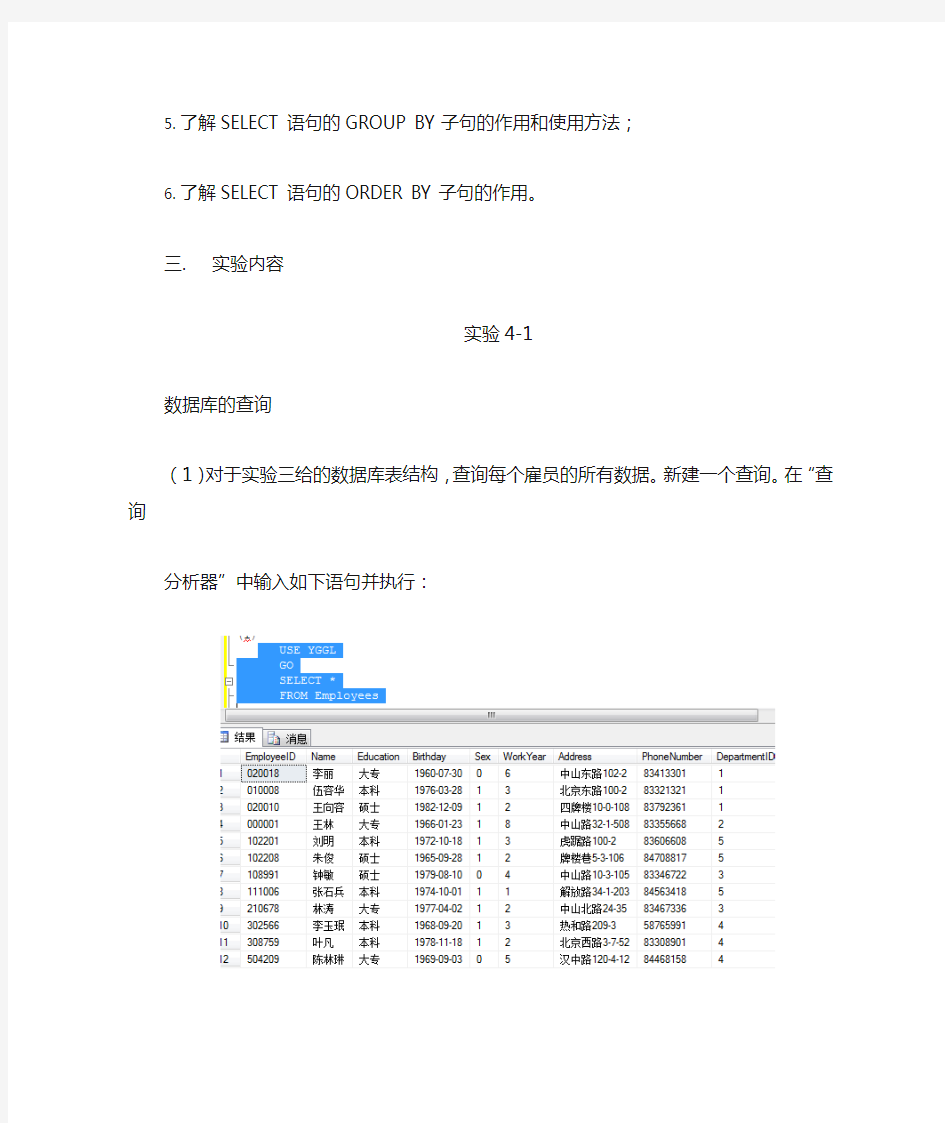
(1)对于实验三给的数据库表结构,查询每个雇员的所有数据。新建一个查询。在“查询分析器”中输入如下语句并执行:
图4.1.1新建一个查询的执行结果
思考与练习:用SELECT语句查询Department和Salary表中的所有信息。
图4.1.2用SELECT语句查询Department
图4.1.3用SELECT语句查询Salary
为了方便,后面的语句可能省略打开YGGL数据库命令:
图4.1.4省略打开YGGL数据库命令
(2)用SELECT语句查询Employees表中的每个雇员的地址和电话。新建一个查询,在“查询分析器”中输入以下语句并执行:
图4.1.5查询Employees表中的每个雇员的地址和电话
思考与练习:
用SELECT语句查询Dementments和Salary表的一列和若干个列.
图4.1.6用SELECT语句查询Department表的一列和若干个列.
图4.1.7用SELECT语句查询Department表的一列和若干个列. 查询Employees表中的部门编号和性别,要求使用DISTINCT消除重复行。
图4.1.8查询Employees表中的部门编号和性别
(3)查询EmployeesID为000001的雇员的地址和电话。代码如下:
图4.1.9查询EmployeesID为000001的雇员的地址和电话
思考与练习:
查询月收入高于2000的员工编号。
图4.1.10查询月收入高于2000的员工编号
查询1970年以后出生的员工姓名和地址。
图4.1.11查询1970年以后出生的员工姓名和地址
查询所有财务部员工编号和姓名。
图4.1.12查询所有财务部员工编号和姓名
(4)查询Employees表中的女员工的住址和电话,使用AS子句将结果中各列标题分别指定为住址和电话。代码如下:
图4.1.13查询Employees表中的女员工的住址和电话
思考与练习:查询Employees表中男员工的姓名和出生日期,要求降格标题用中文表示。
图4.1.14查询Employees表中男员工的姓名和出生日期
(5)查询Employees表中员工的姓名和性别,要求Sex的值为1时显示“男”,为0时显示“女”。代码如下:
图4.1.15查询Employees表中员工的姓名和性别
思考与练习:查询Employees员工的姓名,住址和收入水平,2000元以下显示低收入,2000-3000元显示为中等收入,3000元以上显示为高收入。
图4.1.16查询Employees员工的姓名(6)计算每个雇员的实际收入。代码如下:
图4.1.17计算每个雇员的实际收入
思考与练习:使用SELECT语句进行简单的计算。
图4.1.18使用SELECT语句进行简单的计算(7)获得员工总数。代码如下:
图4.1.19获得员工总数
思考与练习:
计算Salary表中的员工月收入的平均数。
图4.1.20计算Salary表中的员工月收入的平均数获得Employees表中年龄最大的员工编号。
图4.1.21获得Employees表中年龄最大的员工编号计算Salary表中所有员工的总支出。
图4.1.22计算Salary表中所有员工的总支出
查询财务部雇员的最高和最低实际收入。
图4.1.23查询财务部雇员的最高和最低实际收入(8)查找出所有姓王的雇员的部门编号。代码如下:
图4.1.24查找出所有姓王的雇员的部门编号
思考与练习:
找出所有住址中含有中山的雇员的员工编号及部门编号。
图4.1.25找出所有住址中含有中山的雇员的员工编号及部门编号查找员工编号中倒数第二个数为“0”的员工姓名住址及学历。
图4.1.26查找员工编号中倒数第二个数为“0”的员工姓名住址及学历(9)找出所有收入在2000-3000元之间的员工编号。代码如下:
图4.1.27找出所有收入在2000-3000元之间的员工编号
思考于练习:找出所有在部门“1”或“2”工作的雇员的员工编号。
图4.1.28找出所有在部门“1”或“2”工作的雇员的员工编号
(10)使用INTO子句,有Salary创建“收入在1500元以上的员工”表,包括员工编号及收入。代码如下:
图4.1.29Salary创建“收入在1500元以上的员工”表
思考与练习:使用INTO子句,有表Employees创建男员工表,包括员工姓名即编号。
图4.1.30表Employees创建男员工表,包括员工姓名即编号
2.子查询
(1)查找在财务部工作的雇员的情况。代码如下:
图4.1.31查找在财务部工作的雇员的情况
思考与练习:用子查询的方法查找所有收入在2500一下的雇员的情况。
图4.1.32用子查询的方法查找所有收入在2500一下的雇员的情况。(2)查找财务部年龄不低于研发部雇员年龄的雇员的姓名。代码如下:
图4.1.33查找财务部年龄不低于研发部雇员年龄的雇员的姓名
思考与练习:用子查询的方法查找研发部比所有财务部雇员收入都高的雇员的姓名。
图4.1.34用子查询的方法查找研发部比所有财务部雇员收入都高的雇员的姓名(3)查找比所有财务部的雇员收入都高的雇员的姓名。
图4.1.35查找比所有财务部的雇员收入都高的雇员的姓名
思考与练习:用子查询的方法查找所有年龄比研发部雇员年龄都大的雇员的姓名。
图4.1.36查找所有年龄比研发部雇员年龄都大的雇员的姓名
3.连接查询
(1)查询雇员的情况及其薪水情况。代码如下:
图4.1.37查询雇员的情况及其薪水情况
思考与练习:查询每个雇员的情况及其部门的情况。
数据库数据处理
实验三数据处理 【实验目的】 1.学会处理表数据、查看表记录 2.学会使用SQL语句处理表数据 【实验内容】 1.使用SQL语句给课程表、成绩添加数据--INSERT语句 2.使用SQL语句给学生表、成绩表更新数据--UPDATE语句 3.使用SQL语句为学生表删除记录--DELETE语句 【实验准备】 1.复习与本次实验内容相关知识 2.对本次实验中要求自己完成的部分做好准备 【实验步骤】 特别说明:本实验中使用的数据仅为实验而已,无任何其他作用。 1.给班级表添加记录 o用自己的帐号、密码,注册并连接到SQL Server服务器。 o展开连接的服务器-->展开"数据库"-->展开你的数据库(你的学号)-->单击"表"。 o在右边的窗格内,右击班级表(U_CLASSES),在弹出的快捷菜单中,将鼠标移到"打开表(O)"上,再移到"返回所有行(A)"上单击.参见下图。 o o接着按下图输入数据,注意,ID列不用输入(为什么?)。 o
o输入完成后,若要对数据行(如:删除行)进行操作,可在某行上右击鼠标,在弹出菜单中选择要执行的命令。关闭该查询窗口。 2.修改表记录数据 o若要修改数据,可用上述方法打开数据表,直接修改即可。 3.用界面方式给学生表(U_STUDENTS)添加数据 o参照前面方法给用界面方式给学生表输入如下记录。在输入过程中,注意观察如果输入相同学号有什么现象(什么原因?),如果班级编号不输入,又会怎 样(为什么?)。 o 4.用SQL命令给课程表(U_COURSES)、成绩表(U_SCORES)添加数据、修改数据 o先运用界面方式给课程表(U_COURSES)增加一列CREDIT,数据类型为tinyint o启动数据库引擎查询(如下图所示),进入到查询编辑窗口。 o o输入(为减少输入工作量,可将下面的语句复制)如下语句并执行之,为课程表(U_COURSES)插入插入5条记录。 o INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('计算机文化基础',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('C语言程序设 计',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('数据结构',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('数据库原理与 应用',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('SQL Server',3) o输入"SELECT * FROM U_COURSES"查看课程表记录。
数据库查询操作详解
一、数据查询-----单表查询 (1)查询语句格式 Select [all|distinct] <目标列表达式> [,<目标列表达式>]…… From <表名或视图> [,<表名或视图>]…… [where <条件表达式>] [group by <列名1> [having <条件表达式>]] [order by <列名2> [asc|desc]] ; 注:[all|distinct]中all为缺省值,取消结果中的重复列则用distinct; [asc|desc]中asc为缺省值,表示按照升序排列。对于空值,若按照升序排,则含空值的元组显示在最后面;若按降序排,则空值的元组最先显示。 (2)查询指定列 a)查询部门表dept中所有部门的详细信息,并且列名用汉字表示。 select DNO,DNAME,ADDR from dept; b)查询部门表dept中人力资源部的部门编号。 select DNO from dept where DNAME='人力资源部'; <目标列表达式>中各个列的先后顺序可以与表中的顺序不一致. (3)查询全部列 查询全体学生的详细记录 Select * From Student ; (4)将查询结果的列名用别名显示 查询部门表dept中所有部门的详细信息,并且列名用汉字表示。 select DNO部门编号,DNAME部门名称,ADDR部门地址 from dept; (5)在查询的结果中插入新的一列用来显示指定的内容 Select Sname NAME ,’Year of Birth:’BIRTH ,Sbirth BIRTHDAY ,Sdept DEPARTMENT From Stuent ; 则显示的结果中,每个元组的第二列均为”Year of Birth:”,此列在原数据库中是不存在的. (6)查询经过计算的值 Select 子句的<目标列表达式> 不仅可以是表中的属性列,也可以是表达式。 例:查询全体学生的姓名及其出生年月 Select Sname ,2004 – Sage /*当时年份减去年龄为出生年月
ACCESS数据库操作必须更新查询的解决办法
ACCESS数据库操作必须更新查询的解决办法 1、在通常情况下,Web应用程序只读属性并不影响Web系统运行。在需要写入、更新数据库时,Web程序操作数据库因权限不够会提示"操作必须使用一个可更新的查询。"这种情况可能会在NTFS分区环境下出现,FTA32一般分区不会出现。将Web应用程序放在FTA32分区下运行时,不会出现因权限等问题而导致系统不能正常运行的情况,但是其安全性不如NTFS好。因此,一般网站软件可在FTA32下测试运行,单位正式网站软件建议放置在NTFS 下运行。 2、现以XP环境下,NTFS格式为例。进入网站根目录,工具—>文件夹选项—>查看,将“使用简单文件共享”前的勾选去掉。 3、网站根目录赋予Everyone完全控制、读写权限。 下面以一个例子更详细的介绍解决此类问题的方法和过程 出错举例: Microsoft JET Database Engine (0x80004005)操作必须使用一个可更新的查询。/LeadBBS/inc/Board_Popfun.asp, 第569 行需要权限:服务器管理员,否则联系服务器管理员进行示例操作系统:Windows 2000 Server1.找到你存放网站的文件夹,比如你的网站存放在D:\WEB\https://www.360docs.net/doc/d78352618.html,右键点击文件夹,选择属性 2.出来新窗口,选择安全,点击按钮添加(D)
3.在出来的窗口中,找到IUSER_开头的名称,并双击,点击确定. 4.确定后的结果是这个窗口,在安全的名称列表中多了刚才选择的用户点击下面的按钮高级(V)...
5.在弹出的新小窗口中,继续点击查看/编辑(V)按钮 6.出来新窗口..
SQLServer数据查询的优化方法
SQLServer数据查询的优化方法聂文燕 摘要:SQLServer是一种功能强大的数据库管理系统,许多数据库应用系统都是以它作为后台数据库。本文在分析影响SQLSERVER数据查询效率的因素的基础上,提出了几种优化数据查询的方法。 关键词:SQLServer,数据,查询,优化 一、引言 SQLServer是是由微软公司开发的基于Windows操作系统的关系型数据库管理系统,它是一个全面的、集成的、端到端的数据解决方案,为企业中的用户提供了一个安全、可靠和高效的平台用于企业数据管理和商业智能应用。目前,许多中小型企业的数据库应用系统都是用SQLServer作为后台数据库管理系统设计开发的。设计一个应用系统并不难,但是要想使系统达到最优化的性能并不是一件容易的事。根据多年的实践,由于初期的数据库中表的记录数比较少,性能不会有太大问题,但数据积累到一定程度,达到数百万甚至上千万条,全面扫描一次往往需要数十分钟,甚至数小时。20%的代码用去了80%的时间,这是程序设计中的一个著名定律,在数据库应用程序中也同样如此。如果用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟。而且我们知道,目前数据库系统应用中,查询操作占了绝大多数,查询优化成为数据库性能优化最为重要的手段之一。 二、影响查询效率的因素 SQLServer处理查询计划的过程是这样的:在做完查询语句的词法、语法检查之后,将语句提交给SQLServer的查询优化器,查询优化器通过检查索引的存在性、有效性和基于列的统计数据来决定如何处理扫描、检索和连接,并生成若干执行计划,然后通过分析执行开销来评估每个执行计划,从中选出开销最小的执行计划,由预编译模块对语句进行处理并生成查询规划,然后在合适的时间提交给系统处理执行,最后将执行结果返回给用户。所以,SQLServer中影响查询效率的因素主要有以下几种:1.没有索引或者没有用到索引。索引是数据库中重要的数据结构,使用索引的目的是避免全表扫描,减少磁盘I/O,以加快查询速度。 2.没有创建计算列导致查询不优化。 3.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)。 4.返回了不必要的行和列。 5.查询语句不好,没有优化。其中包括:查询条件中操作符使用是否得当;查询条件中的数据类型是否兼容;对多个表查询时,数据表的次序是否合理;多个选择条件查询时,选择条件的次序是否合理;是否合理安排联接选择运算等。 三、SQLServer数据查询优化方法 3.1建立合适的索引索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。当根据索引码的值搜索数据时,索引提供了对数据的快速访问。事实上,没有索引,数据库也能根据SELECT语句成功地检索到结果,但随着表变得越来越大,使用“适当”的索引的效果就越来越明显。索引的使用要恰到好处,其使用原则有: (1)对于基本表,不宜建立过多的索引; (2)对于那些查询频度高,实时性要求高的数据一定要建立索引,而对于其他的数据不考虑建立索引; (3)在经常进行连接,但是没有指定为外键的列上建立索引; (4)在频繁进行排序或分组(即进行groupby或orderby操作)的列上建立索引;
空间数据库中查询处理的探讨
地理空间信息 104Vol.7,No.6Dec.,2009GEOSPATIAL INFORMATION 空间数据库中查询处理的探讨 张培斯,左小清 (昆明理工大学国土资源工程学院,云南昆明650093) 摘要:查询是数据库管理系统中一项基本的功能。简要介绍了三种不同的查询,重点对空间连接与非空间连接的区别进 行了说明,阐述了过滤-精炼策略来处理范围查询,最后描述了一个处理空间连接查询过滤阶段的算法。 关键词:GIS;空间数据库;空间连接;空间聚集;过滤-精炼 中图分类号:P208文献标志码:B文章编号:1672-4623(2009)06-0104-03 Research on Dealing with Query in Spatial Database ZHANG Peisi,ZUO Xiaoqing (FacultyofLandResourceEngineering,KunmingUniversityofScienceandTechnology,Kunming650093,China)Abstract:Queryisabasalfunctionofadatabasemanagementsystem.Inthispaper,threetypesofquery methodwereintroduced,thetacticofleach-refinewasdiscussedondealwithrange-query,intheend,a arithmeticofleachonspatial-joinquerywasdescribed. Key words:GIS;spatialdatabase;spatial-join;spatial-assemble;leach-refine
数据库SQL查询处理及其优化方法的研究 精品
数据库SQL查询处理及其优化方法的研究 1 绪论 到如今,几乎所有应用系统的开发都离不开数据库,通过查询数据库就可以有效的得到想要的数据。但是,现实中许多数据库开发人员在利用一些前端数据库开发工具开发数据库应用程序时只注重用户界面的华丽,并不注重查询效率,导致所开发出来的应用系统中查询时间长,响应速度慢,甚至查询结果不够准确等,系统工作效率低下,资源浪费严重。究其原因,一是硬件设备(如CPU、磁盘)的存取速度跟不上,内存容量不够大;另一方面是数据查询方法不适当,抑或是没有进行数据查询优化。 许多数据库开发人员认为查询优化是DBMS(数据库管理系统)的任务,与程序员所编写的SQL语句关系不大,这是不对的,一个好的查询方法往往可以使程序性能提高数十倍。在实际的数据库产品(如Oracle、Sybase、SQL Server 2000等)的高版本中都是采用基于代价的优化方法,这种优化能根据从系统字典表中所得到的信息来估计不同的查询方法代价,然后选择一个较优的规则。虽然现在的数据库产品在数据查询优化方面已经做得越来越好,但由于用户提交的SQL语句是查询优化的基础,因此用户所写语句的优劣至关重要。 2 关系数据库查询处理 要研究查询优化就必须知道数据库查询处理过程,本节阐述了关系数据库(RDBMS)的查询处理步骤,并介绍了查询处理的任务是把用户提交给RDBMS的查询语句转换为高效的执行计划。 2.1 查询处理步骤 RDBMS查询处理过程可以分为四个阶段:查询分析、查询检查、查询优化和查询执行,如图2-1所示。 (1) 查询分析 查询分析是查询处理的第一个阶段,主要任务是对查询语句进行扫描、词法分析和语法分析。从查询语句中识别出语言符号,SQL关键字、属性名和关系名等,并且进行语法检查和语法分析,即判断查询语句是否符合SQL语法规则。 (2) 查询检查
数据库中如何处理大型数据
数据库中如何处理大型数据
处理百万级以上的数据提高查询速度的方法: 1.应尽量避免在where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 2.对查询进行优化,应尽量避免全表扫描,首先应考虑在where 及order by 涉及的列上建立索引。 3.应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num 列没有null值,然后这样查询: select id from t where num=0 4.应尽量避免在where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 5.下面的查询也将导致全表扫描:(不能前置百
分号) select id from t where name like ‘%abc%’ 若要提高效率,可以考虑全文检索。 6.in 和not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用between 就不要用in 了: select id from t where num between 1 and 3 8.应尽量避免在where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id select id from t where
数据库查询和处理语句
目录 数据库查询和处理语句(八) (2) 1、批量复制分公司的一些门户 (2) 2、文档查询中的修改区间是否可以调整? (2) 3、把所有已经归档的流程,归档人未查看的批量置为已查看的SQL语句 (3) 4、批量修改流程的属性的语句 (3) 5、著者文档数量的脚本 (3) 6、个人文档脚本 (4) 7、流程超时人员检索SQL (4)
数据库查询和处理语句(八) 本期为您提供在维护ecology系统的过程中,一些常用的数据库查询和处理语句。 重点提醒:操作之前,请千万备份数据库!!!!! 1、批量复制分公司的一些门户 注:44是要被复制的子公司的名字。1是不需要复制的公司的名字。 Insert into extendHpWebCustom(templateid,subCompanyId,pagetemplateid,menuid,menustyleid,defaultshow,leftmenuid) select b.templateid,a.id,b.pagetemplateid,b.menuid,b.menustyleid,b.defaultshow,b.leftmenuid from HrmSubCompany a,extendHpWebCustom b where a.id not in(select x.subCompanyId from extendHpWebCustom x) and b.subCompanyId=44 ----根据情况修改 go Insert into SystemTemplate(templateName,companyId,topBgColor,toolbarBgColor,leftbarBgColor,leftbarFontColor,menubarBgColor,menubtnB gColor,menubtnBgColorActive,menubtnBgColorHover,menubtnFontColor,menubtnBorderColorActive,menubtnBorderColorHover,te mplateTitle,isOpen,extendtempletid,extendtempletvalueid) select templateName,a.id,topBgColor,toolbarBgColor,leftbarBgColor,leftMenuFontColor,menubarBgColor,menubtnBgColor,menubtnBgCol orActive,menubtnBgColorHover,menubtnFontColor,menubtnBorderColorActive,menubtnBorderColorHover,templateTitle,isOpen,ext endtempletid,extendtempletvalueid from HrmSubCompany a,SystemTemplate b where a.id<>1 and a.id not in(select https://www.360docs.net/doc/d78352618.html,panyId from SystemTemplate x) and https://www.360docs.net/doc/d78352618.html,panyId=44 ----根据情况修改 go update extendHpWebCustom set templateid=SystemTemplate.id from SystemTemplate where extendHpWebCustom.subCompanyId=https://www.360docs.net/doc/d78352618.html,panyId and extendHpWebCustom.subCompanyId<>1 ----根据情况修改 go update SystemTemplate set extendtempletvalueid=id where id<>1----根据情况修改 2、文档查询中的修改区间是否可以调整? 查询ecology目录下有一个叫:docdateduring的文档。 如果你想默认显示近三年的,只要将date2during=36便可以了。 设置完成后要重启下Resin服务