统计学第四版问题详解(贾俊平)
统计学第四版贾俊平人大-假设检验stata

假设检验作业8.1 小样本、方差已知的均值校验已知:总体服从N(4.55,0.1082);n=9;x =4.484;α=0.05假设:H 0:μ=4.55;H 1:μ≠4.55。
利用stata 求Z 统计量:display z=(4.484-4.55)/(0.108/sqrt(9)) 又83.1=Z <96.12/±=αZ 故原假设能接受,即现在生产的铁水平均含碳量为4.55。
8.2 大样本的均值校验已知:总体服从N(700,602);n=36;x =680;α=0.05假设:H 0:μ≥700;H 1:μ<700。
利用stata 求Z 统计量:display (680-700)/(60/sqrt(36)) 又2=Z >αZ =1.64,故原假设不能接受,即这批元件不合格。
8.3 小样本、方差已知的均值校验已知:总体服从N(250,302);n=25;x =270;α=0.05假设:H 0:μ≥250;H 1:μ<250。
利用stata 求Z 统计量:display (270-250)/(30/sqrt(25)) 又Z =3.33>αZ =1.64,故原假设不能接受,即这种化肥使小麦增产不明显。
8.4 小样本、方差未知的均值校验已知:总体服从N(100,σ2);n=9;Xi(i=1,2,3,4,5,6,7,8,9);α=0.05假设:H 0:μ=100;H 1:μ≠100。
利用stata 新建weight.dta 输入数据:编写程序求t 统计量:clearuse weightlist weightegen wgt1=mean(weight)egen sd=sd(weight)display (wgt1-100)/(sqrt(sd)/sqrt(9))又Z=0.06<2/αZ=1.96,故原假设能接受,即该打包机工作正常。
8.5 大样本的比例校验假设:H0:π≤5%;H1:π>5%。
统计学贾俊平_第四版课后习题答案第八章

姓名:潘方 学号:1106026 班级:金融一班8.2 解:根据题目的分析,本题采用左单侧检验:已知:μ0=700,x =680,σ=60, n=36,α=0.05则z α=1.645 其过程为: H 0:μ≥700 H 1:μ<700 x z ==-2 因为|z|>|z α|,Z 值位于拒绝域,故拒绝原假设,说明这批产品不合格。
因为2=Z ,且为左单侧检验,则()05.0022750132.0977249868.01=<=-=αP8.4 解:由excel 计算得:x =99.9778 S =1.21221H 0:μ=100 H 1:μ≠100 x t =-0.055 这是一个双侧检验,当α=0.05,自由度n -1=9时,得()29t α=2.262。
因为t <|2t α|,t 值位于接受区域,故接受原假设,说明打包机工作正常。
因为|Z|=0.055,且为双侧检验,由excel 得: P=0.95734>(α=0.05)8.9解:该题样本为,大样本,方差2σ已知、且不等,因此采用z 统计量 已知, 05.0=α、即96.12/=αZ ,811=n , 642=n ,σA=63*63 2σB=57*57 0:211≠-μμH 0:210=-μμH , ()()96.15.0645781630102010702222<≈+--=+---=BB A AB A B A n n x x Z σσμμ 因为|z|<|z α|,Z 值位于接受区域,故接受原假设,两厂生产材料抗压强度相同。
因为5.0=Z ,则()=-⨯=691462461.012P 0.617075078()05.0=>α8.13 解:此题为两个总体比例之差的假设H 0:π1≥π2;H 1:π1<π 2 α=0.05,即z α=1.6451100021==n n ,00945.0110001041==p ,01718.0110001892==pp p d z --=0.009450.017180--=-5 因为|z|>|z α|,Z 值位于拒绝域,故拒绝原假设,说明用阿司匹林可以降低心脏病发生率。
统计学_贾俊平_第4版_课后答案
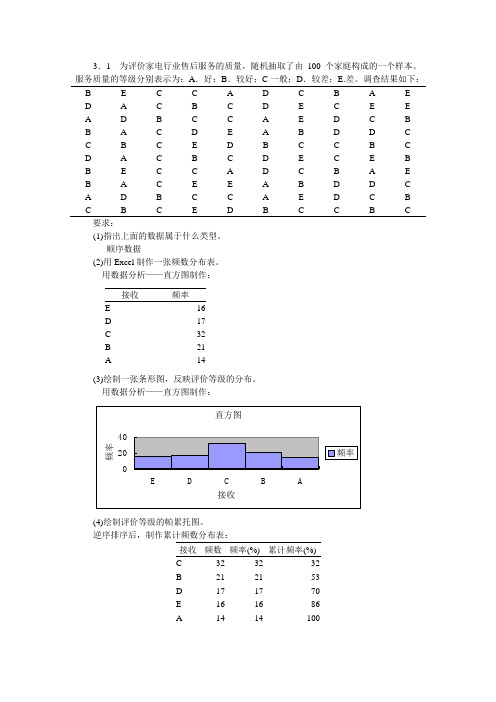
3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB AC E E A BD D CA DBC C A ED C BC B C ED B C C B C要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:接收频率E16D17C32B21A14(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收频数频率(%)累计频率(%)C 32 32 32B 21 21 53D 17 17 70E 16 16 86A 14 14 1005101520253035CDBAE204060801001203.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 9788123115119138112146113126要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取10 3(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
统计学 第四版 (贾俊平 著) 中国人民大学出版社 第四章课后答案
62.75
2 33.9375
82 64
(2) 可能的样本个数:
(3)由题可得所有样本的样本均值如下表:
第(3)小题图表
(4)利用SPSS软件得到Q-Q图:
(5)
x i 1
xi 64
m
62.75
33.9375 x 4.1193 2 n
0 4
(2) P(X≤2 )=
4.3 求标准正态分布的概率: (1)P ( 0 ≤ Z ≤ 1.2) ; (2)P ( -0.48 ≤ Z ≤ 0); (3)P (Z > 1.33)。
解: (1)P ( 0 ≤ Z ≤ 1.2) = P ( 1.2) -P ( 0 )= 0.3849 (2)P ( -0.48 ≤ Z ≤ 0 ) = P ( 0) -P (-0.48)= 0.1844 (3)P (Z > 1.33) = P ( -1.33) = 0.0918
(1 )
500 0.4 0.6 0.0219089 500
(2)
(3)由中心极限定理可知 p的分布近似正态分布
4.7 假设一个总体共有8个数值: 54,55,59,63,64,68,69,70.从该总体 中按重复抽样方式抽取n=2的随机样本。
(1)计算总体的均值和方差。 (2)一共有多少个可能的样本? (3)抽出所有可能的样本,并计算出每个样本的均值。 (4)画出样本均值的正态概率图,判断样本均值是否服从正态分布。 (5)计算所有样本均值的平均数和标准差,并与总体的均值和标准差进行对比得 到的结论是什么?
E ( x ) 200
n 50 5 100
(2 ) x
(3) 由中心极限定理可知 X 的概率分布近似服从正态分布
贾俊平第四版统计学-第八章假设检验练习答案教学教材

贾俊平第四版统计学- 第八章假设检验练习答案第八章假设检验练习答案•选择题1. 第一类错误,第二类错误,一,2. 第一类,第二类,原假设,不拒绝3.(1)H。
:220,H i:220(2)第一类错误是指新方法不能降低成本但被采用,导致成本上升;第二类错误是指新方法能够降低成本,但没有采用。
4.失学儿童中女孩所占的比例(或男孩所占的比例*);H。
:3,H1:43(或H 0:4* 1, Hz P(1).n三•计算题1.解:H°: 4.55, H1 4.55总体服从正态分布,总体含碳量的标准差b =0.108,n=9,检验统计量为z X 0 4.484 4.55 d------ 0 1.833 /、n 0.108/ .9不拒绝原假设结论:在显著性水平a =0.05下,样本提供的证据不足以推翻“现在生产的铁水平均含碳量为4.55”的说法。
2. H0: 6.7,H1: 6.7n=200>30大样本,总体标准差未知,X 7.25, s 2.5a=0.05,双侧检验,临界值为Z o.o25 1.96,因为z>-1.96,未落入拒绝域检验统计量为z 需需 3-11=0.01,右侧检验,临界值为Z o.oi 2.33。
因为z=3.11>Z o.oi ,落入拒绝域,所以拒绝原假设。
结论:在显著性水平a =0.01下,认为“如今每个家庭每天看电视的平均时间比十年前增加了3. 解:H 0: 60, H 1: 60n=7<30小样本,总体标准差未知,经计算 x 65, s 11.34域,所以不拒绝原假设。
结论:在显著性水平a =0.01下,样本提供的证据还不足以推翻“促销活动无效” 的说法。
4. H 0: 30%,H 1: 30%n 0 400* 0.3 120 5,且 n (10) 400* 0.7 280 5,大样本,经计算样本比例为 P=100/400=0.25 p0 0.25 0.30 检验统计量为z r 1 0 1 2.1820*(1 0) 0.30*0.70x n \ 400 =0.05,双侧检验,临界值为Z 0.025 1.96。
贾俊平第四版统计学-第三章 答案

一、选择题
1.B 2.C 3.A 4.B 5.D 6.C 7.B 8.D 9.B 10.C 11.C 12.A 二、填空题
1. 该表研究的变量是 收入 ,变量为 连续 型,采用的是 等距 分组,表中的职工数称 频数 ,收入6000元的职工应归为 6000-7000 组,表中第一组和第六组称为 开口组,第一组的组 中值是 3500 ,第二组中的4000称为 下限 ,5000称为 上限 。 2. 34岁以下(含34岁)人口占总人口的百分比是 48.9,34岁以 上人口占总人口的 51.1 %,25-54岁人口占总人口的 43.4 %。
5 13.9
36
100
(3)直图
分布特点:销售额呈左偏。
2. (1) 频数分布表
上班
频
时间
数
7:
3
00
4
7:
4
30
7
8:
2
00
8:
30
9:
00
合计
20
频 率%
15 20 20 35 10
100
(2)条形图或饼图均可,图略
三、绘图题
1. (1)茎叶图 树茎 15 468 16 0556777 17 045666678899 18 023456789 19 03457
(2) 频数分布表
分组
频数
频率 (%)
150160
3
8.3
160170
7 19.4
170180
12 33.3
180190
9 25.0
190-
200 合计
个人学习-贾俊平《统计学》(第四版)第12章 主成分分析和因子分析
12 - 6
统计学
STATISTICS (第四版)
因子分析得到的是什么?
医学:一位研究者对山东某县2000~2002年3年 的全死因调查资料中不同地区各恶性肿瘤标化死 亡率进行因子分析后发现,该县居民恶性肿瘤的 发病和死亡具有明显的地区分布。在地区分布中, 各种恶性肿瘤的死亡具有一定程度的聚集性。经 因子分析得到的 4 个主因子可以解释 10 种恶性肿 瘤死亡率的 74.54 %; 10 种恶性肿瘤中,被解释 的比例最小也在62%以上;而胃癌、白血病、膀 胱癌、乳腺癌、结肠癌死亡率被解释的比例均在 77%以上,表明这10种恶性肿瘤之间存在中等偏 强的内在联系和地区分布特点
12 - 20
2016-11-10
统计学
STATISTICS (第四版)
主成分分析
(实例分析)
【例 12-1】根据我国 31 个省市自治区 2006 年的 6 项主要经济指标数据,进行主成分分析,找出 主成分并进行适当的解释
31个地区的6项经济指标
12 - 21 2016-11-10
统计学
STATISTICS (第四版)
12 - 18 2016-11-10
12.1 主成分分析 12.1.3 主成分分析的步骤
统计学
STATISTICS (第四版)
主成分分析的步骤
对原来的p个指标进行标准化,以消除变量 在水平和量纲上的影响 根据标准化后的数据矩阵求出相关系数矩 阵 求出协方差矩阵的特征根和特征向量 确定主成分,并对各主成分所包含的信息 给予适当的解释
(principal component analysis)
主成分的概念由Karl Pearson在1901年提出 考察多个变量间相关性一种多元统计方法 研 究 如 何 通 过 少 数 几 个 主 成 分 (principal component)来解释多个变量间的内部结构。即从 原始变量中导出少数几个主分量,使它们尽可能 多地保留原始变量的信息,且彼此间互不相关 主成分分析的目的:数据的压缩;数据的解释
统计学课件(贾俊平)第四版 ppt
(二)现实经济生活中,依同样资料计算的拉氏指数一般大于帕氏 指数。 P 1 ri i Vi Vi 因为,可证明 p q q p L
ri
i pq
q p
质量指标个体指数与数量指标个体指数的相关系数 两种个体指数的标准差系数
Vi , Vi
由于在现实经济生活中,质量指标与数量指标(例如价格与 销售量)的变化之间通常存在着负相关关系,即下面三种情况之 一:1.质量指标的水平绝对上升,而数量指标的水平绝对下降, 或相反,数量指标的水平绝对上升,而质量指标的水平绝对下降; 2.质量指标和数量指标的水平都上升,但在其中一个的上升速率 加快的同时,另一个的上升速率则在减缓;3.质量指标和数量指 标的水平都下降,但在其中一个的下降速率加快的同时,另一个 的下降速率则在减缓。 商学院 2018/10/5 17
全部商品的价格指数
360 20 130 2000 p1 300 18 100 2500 p0 2600 95000 23000 612 q1 2400 84000 24000 510 q0
全部商品的销售量指数
复杂现象总体:不能直接加总或不能直接综合对比的现象。 总指数:反映复杂现象总体综合变动状况的指数。 商学院
拓广:用于空间上的比较(空间指数)和反映计划完成情况(计 划完成指数)。
2018/10/5
例:空间比价指数
商学院
4
商品 大米 猪肉 服装 冰箱
单位 百公斤 公斤 件 台
商品价格(元) 基期 报告期
销售量 基期 报告期
p0
300 18 100 2500
p1
360 20 130 2000
统计学(贾俊平四版)七练习题详细答案
第七章 练习题参考答案7.1 (1)已知σ=5,n=40,x =25,α=0.05,z205.0=1.96样本均值的抽样标准差σx=nσ=79.0405=(2)估计误差(也称为边际误差)E=z 2αnσ=1.96*0.79=1.557.2(1)已知σ=15,n=49,x =120,α=0.05,z205.0=1.96(2)样本均值的抽样标准差σx=nσ==4915 2.14估计误差E=z 2αnσ=1.96*=4915 4.2(3)由于总体标准差已知,所以总体均值μ的95%的置信区间为: nx z σα±=120±1.96*2.14=120±4.2,即(115.8,124.2)7.3(1)已知σ=85414,n=100,x =104560,α=0.05,z205.0=1.96由于总体标准差已知,所以总体均值μ的95%的置信区间为: nx z σα±=104560±1.96*=10085414104560±16741.144即(87818.856,121301.144)7.4(1)已知n=100,x =81,s=12,α=0.1,z 21.0=1.645由于n=100为大样本,所以总体均值μ的90%的置信区间为:ns x z 2α±=81±1.645*=1001281±1.974,即(79.026,82.974)(2)已知α=0.05,z205.0=1.96由于n=100为大样本,所以总体均值μ的95%的置信区间为:ns x z 2α±=81±1.96*=1001281±2.352,即(78.648,83.352)(3)已知α=0.01,z201.0=2.58由于n=100为大样本,所以总体均值μ的99%的置信区间为:ns x z 2α±=81±2.58*=1001281±3.096,即(77.94,84.096)7.5(1)已知σ=3.5,n=60,x =25,α=0.05,z205.0=1.96由于总体标准差已知,所以总体均值μ的95%的置信区间为: nx z σα±=25±1.96*=60.5325±0.89,即(24.11,25.89)(2)已知n=75,x =119.6,s=23.89,α=0.02,z 202.0=2.33由于n=75为大样本,所以总体均值μ的98%的置信区间为:ns x z 2α±=119.6±2.33*=759.823119.6±6.43,即(113.17,126.03)(3)已知x =3.419,s=0.974,n=32,α=0.1,z21.0=1.645由于n=32为大样本,所以总体均值μ的90%的置信区间为:ns x z 2α±=3.419±1.645*=3274.90 3.419±0.283,即(3.136,3.702)7.6(1)已知:总体服从正态分布,σ=500,n=15,x =8900,α=0.05,z205.0=1.96由于总体服从正态分布,所以总体均值μ的95%的置信区间为:nx z σα2±=8900±1.96*=155008900±253.03,即(8646.97,9153.03)(2)已知:总体不服从正态分布,σ=500,n=35,x =8900,α=0.05,z205.0=1.96虽然总体不服从正态分布,但由于n=35为大样本,所以总体均值μ的95%的置信区间为:nx z σα2±=8900±1.96*=355008900±165.65,即(8734.35,9065.65)(3)已知:总体不服从正态分布,σ未知, n=35,x =8900,s=500,α=0.1,z 21.0=1.645虽然总体不服从正态分布,但由于n=35为大样本,所以总体均值μ的90%的置信区间为:ns x z 2α±=8900±1.645*=355008900±139.03,即(8760.97,9039.03)(4)已知:总体不服从正态分布,σ未知, n=35,x =8900,s=500,α=0.01,z 01.0=2.58虽然总体不服从正态分布,但由于n=35为大样本,所以总体均值μ的99%的置信区间为:ns x z 2α±=8900±2.58*=355008900±218.05,即(8681.95,9118.05)7.7 已知:n=36,当α=0.1,0.05,0.01时,相应的z21.0=1.645,z205.0=1.96,z201.0=2.58根据样本数据计算得:x =3.32,s=1.61由于n=36为大样本,所以平均上网时间的90%置信区间为:ns x z 2α±=3.32±1.645*=361.61 3.32±0.44,即(2.88,3.76)平均上网时间的95%置信区间为:ns x z 2α±=3.32±1.96*=361.61 3.32±0.53,即(2.79,3.85)平均上网时间的99%置信区间为:ns x z 2α±=3.32±2.58*=361.61 3.32±0.69,即(2.63,4.01)7.8 已知:总体服从正态分布,但σ未知,n=8为小样本,α=0.05,)(18t05.0-=2.365根据样本数据计算得:x =10,s=3.46 总体均值μ的95%的置信区间为:ns x t α±=10±2.365*=83.4610±2.89,即(7.11,12.89)7.9 已知:总体服从正态分布,但σ未知,n=16为小样本,α=0.05,)(116t205.0-=2.131根据样本数据计算得:x =9.375,s=4.113从家里到单位平均距离的95%的置信区间为:ns x t α±=9.375±2.131*=144.1139.375±2.191,即(7.18,11.57)7.10 (1)已知:n=36,x =149.5,α=0.05,z205.0=1.96由于n=36为大样本,所以零件平均长度的95%的置信区间为:ns x z 2α±=149.5±1.96*=361.93149.5±0.63,即(148.87,150.13)(2)在上面的估计中,使用了统计中的中心极限定理。
统计学(第四版)贾俊平 第二章 部分练习题答案
统计学(第四版)贾俊平第二章部分练习题答案2.1 1表1 家电售后等级评价频数分布表评价等级频率百分比有效百分比累积百分比有效 A 14 14.0 14.0 14.0B 21 21.0 21.0 35.0C 32 32.0 32.0 67.0D 18 18.0 18.0 85.0E 15 15.0 15.0 100.0合计100 100.0 100.02.1.2图1 家电售后等级评价条形图等级分布较集中与C级,整体呈左偏正态分布。
2.1.3图2 家电售后等级评价帕累托图2.1.4图3 家电售后等级评价饼图评价等级中C级占大多数,BD级较少,AE级更少。
2.2.1表2 灯泡使用寿命频数分布表接收频率650 0660 2670 5680 6690 16700 26710 18720 12730 9740 3750 3其他02.2.2图4 灯泡使用寿命直方图灯泡使用寿命呈正态分布,大多集中于680—720。
2.2.3使用寿命 Stem-and-Leaf PlotFrequency Stem & Leaf1.00 Extremes (=<651)1.00 65 . 82.00 66 . 143.00 66 . 5683.00 67 . 1343.00 67 . 6797.00 68 . 11233347.00 68 . 555889913.00 69 . 001111222334413.00 69 . 55666778888998.00 70 . 0011223410.00 70 . 56667788896.00 71 . 0022337.00 71 . 56778894.00 72 . 01226.00 72 . 5678991.00 73 . 32.00 73 . 561.00 74 . 11.00 74 . 71.00 Extremes (>=749)Stem width: 10Each leaf: 1 case(s)图5 灯泡使用寿命茎叶图直方图和茎叶图都可以直观的看出灯泡使用寿命呈正态分布,大多集中于680—720.但是茎叶图保留了灯泡使用寿命的原始数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第1章统计和统计数据
1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:
(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?
(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据
););
=426.67;
,,
第五章1.
2
3.
4.
5.
6.
7.
5.8 (1)(3.02%,1
6.98%)。
(2)(1.68%,18.32%)。
5.9 详细答案:(4.06,24.35)。
5.10详细答案: 139。
5.11 详细答案: 57。
5.12 769。
第6章假设检验
平
看电
,绝
平
,,绝,,绝
在
,,
=100 =50
=14.8 =10.4
=0.8 =0.6
对
,,绝。
对
设,。
,
绝
在
,,绝。
在
设,。
,
绝
平
即
即
设,。
,绝
)绝
),。
,
,。
,绝。