快学scala第四章习题答案
第四章 作业和测验答案

• • • • • • •
第二步,对变换后的文法求predict集: Predict(A aC)={a} A aC Predict (B dB’)={d} B dB’ B’ bB’ Predict(B’ bB’)={b} B’ λ Predict(B’ λ)={e } C Abe C λ Predict(C ABe)={a} Predict(C λ)={d,#}
TP +TP | λ FQ *FQ | λ id | (E)
(3)已知文法G[A]如下: A aABe | a B Bb | d 请写出该文法的递归下降语法分析 程序(程序中给出必要的注释)
• 解答:第一步:该文法存在公共前缀和左递归不 满足递归下降语法分析的条件,需要对文法进行 变换,变换后文法如下: • A aC (1) • B dB’ (2) • B’ bB’ (3) • B’ λ (4) • C ABe (5) • C λ (6)
• • • • • • •
ET(){ switch(ch) of ‘-’ : match(-); E();break; ‘)’: ‘#’: break; default: error(); }
• • • • • •
V(){ switch(ch) of ‘id’ : match(id); VT();break; default: error(); }
为文法 G写一个 写一个 递归下降程序. 递归下降程序
ET → ε V → id VT VT → (E) VT → ε }
解答
• 第一步,给产生式加上编号,求predict集:
E → -E E → (E) E → V ET ET → -E ET → ε V → id VT VT → (E) VT → ε (1) (2) (3) (4) (5) (6) (7) (8) Predict(E → -E) = {-} Predict(E → (E) ) = {(} Predict(E → V ET) = {id} Predict(ET → -E) = {-} Predict(ET → ε ) = {),#} Predict(V → id VT) = {id} Predict(VT → (E)) = {(} Predict(VT → ε ) = {-,),#}
统计学课后习题答案_(第四版)4.5.7.8章

《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑nxx i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12 (3)2.494.1561)(2==-=∑-n i s x x (4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77(5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1(2)==∑nx x i63/9=7,714.0808.41)(2==-=∑-n i s x x (3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 2=0.714/7=0.102.由于v 1>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑nx x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5(2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5(3) 17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
第四章习题答案

第四章练习题参考答案1、(1)利用短期生产的总产量(TP)、平均产量(AP)和边际产量(MP)之间的关系,可以完成对该表的填空,其结果如下表:(2)所谓边际报酬递减是指短期生产中一种可变要素的边际产量在达到最高点以后开始逐步下降的这样一种普遍的生产现象。
本题的生产函数表现出边际报酬递减的现象,具体地说,由表可见,当可变要素的投入量由第4单位增加到第5单位时,该要素的边际产量由原来的24下降为12。
2、(1)过TPL曲线任何一点的切线的斜率就是相应的MPL的值。
(2)连接TPL曲线上任何一点和坐标原点的线段的斜率,就是相应的APL的值。
(3)当MPL>APL时,APL曲线是上升的。
当MPL<APL时,APL曲线是下降的。
当MPL=APL时,APL曲线达到极大值。
3、解答:(1)由生产数Q=2KL-0.5L2-0.5K2,且K=10,可得短期生产函数为:Q=20L-0.5L2-0.5*102=20L-0.5L2-50于是,根据总产量、平均产量和边际产量的定义,有以下函数:劳动的总产量函数TP L=20L-0.5L2-50劳动的平均产量函数AP L=20-0.5L-50/L劳动的边际产量函数MP L=20-L(2)关于总产量的最大值:20-L=0解得L=20所以,劳动投入量为20时,总产量达到极大值。
关于平均产量的最大值:-0.5+50L-2=0 L=10(负值舍去)所以,劳动投入量为10时,平均产量达到极大值。
关于边际产量的最大值:由劳动的边际产量函数MP L=20-L可知,边际产量曲线是一条斜率为负的直线。
考虑到劳动投入量总是非负的,所以,L=0时,劳动的边际产量达到极大值。
(3)当劳动的平均产量达到最大值时,一定有AP L=MP L。
AP L的最大值=10MP L=20-10=10很显然AP L=MP L=104、边际报酬变化是指在生产过程中一种可变要素投入量每增加一个单位时所引起的总产量的变化量,即边际产量的变化,而其他生产要素均为固定生产要素,固定要素的投入数量是保持不变的。
算法设计与分析第三版第四章课后习题答案

算法设计与分析第三版第四章课后习题答案4.1 线性时间选择问题习题4.1问题描述:给定一个长度为n的无序数组A和一个整数k,设计一个算法,找出数组A中第k小的元素。
算法思路:本题可以使用快速选择算法来解决。
快速选择算法是基于快速排序算法的思想,通过递归地划分数组来找到第k小的元素。
具体步骤如下: 1. 选择数组A的一个随机元素x作为枢纽元。
2. 使用x将数组划分为两个子数组A1和A2,其中A1中的元素小于等于x,A2中的元素大于x。
3. 如果k等于A1的长度,那么x就是第k小的元素,返回x。
4. 如果k小于A1的长度,那么第k小的元素在A1中,递归地在A1中寻找第k小的元素。
5. 如果k大于A1的长度,那么第k小的元素在A2中,递归地在A2中寻找第k-A1的长度小的元素。
6. 递归地重复上述步骤,直到找到第k小的元素。
算法实现:public class LinearTimeSelection {public static int select(int[] A, int k) { return selectHelper(A, 0, A.length - 1, k);}private static int selectHelper(int[] A, int left, int right, int k) {if (left == right) {return A[left];}int pivotIndex = partition(A, left, righ t);int length = pivotIndex - left + 1;if (k == length) {return A[pivotIndex];} else if (k < length) {return selectHelper(A, left, pivotInd ex - 1, k);} else {return selectHelper(A, pivotIndex + 1, right, k - length);}}private static int partition(int[] A, int lef t, int right) {int pivotIndex = left + (right - left) / 2;int pivotValue = A[pivotIndex];int i = left;int j = right;while (i <= j) {while (A[i] < pivotValue) {i++;}while (A[j] > pivotValue) {j--;}if (i <= j) {swap(A, i, j);i++;j--;}}return i - 1;}private static void swap(int[] A, int i, int j) {int temp = A[i];A[i] = A[j];A[j] = temp;}}算法分析:快速选择算法的平均复杂度为O(n),最坏情况下的复杂度为O(n^2)。
4.第四章习题及答案

4.第四章习题及答案.第四章习题及答案一、填空。
1.在制约孩子发展的因素当中,()是孩子发展的物质前提。
二、判断。
1.国外学者贝莱的研究表明,孩子的智能与父母的职业有着一定的关系,随着孩子年龄的增长,这种关系越来密切。
三、简答。
1.家长应如何注意情感特征对孩子的心理发展的影响?2.美国学者帕特丽夏等人关于家长的教养态度对孩子劳动品质影响的研究结果中,“仆人型家长”和“懒惰型家长”分别有哪些特征? 3.家长如何了解和认识孩子的能力? 4.家长应如何评价孩子的能力?四、论述。
1.案例分析。
《广州日报》1999年6月3日曾作过“高知家庭孩子易患孤独症”的报道:大广州医学院儿童训练基地的接待统计中,约80%孤独症孩子都来自知识分子家庭,孩子的父母都是高学历人士;这些孩子大都在3岁前就患上了孤独证,他们的智力发展很正常,有些孩子还非常聪明,但却不能与周围环境相融合。
请你就这此案例,以本章关于父母教育素质和教育能力的相关内容,做出分析。
2.学前儿童家长的道德素质如何影响着孩子道德品质的发展? 3.家长应如何调整自己的教养态度?参考答案:一、填空。
1.遗传。
二、判断。
1.错。
三、简答。
1.家长的情感特征会影响孩子的心理发展。
作为一种心理活动,情感也有区别于其他心理活动的特征,最重要的特征有两个,一是情感的两极性,一是情感的情境性,在功能上,情感具有动力功能,又分为增力功能和减力功能,动力功能是指积极乐观的情感,减力功能是指消极悲观的情感,如烦乱的心绪,极度的失落,以及冷漠的态度等,它能使人行动消极,降低学习和工作效率。
作为家长,要很好地了解自己的情感特征,发挥情感的动力功能,活跃家里的气氛,控制情感的负向功能,避免给孩子带来伤害和不好的榜样。
比如,家长不要把不良情绪带进家门,不迁怒于人,为孩子情感的健康发展营造良好的空间。
2.仆人型家长:这类家长承担了家庭中的全部家务劳动,觉得根本没必要训练孩子的做事技能,让孩子帮助大人做事。
编译原理第四章答案

编译原理第四章答案1. 介绍编译原理是计算机科学中一门重要的课程,它涵盖了编译器设计与实现的基本知识和技术。
本文将针对编译原理第四章的问题进行详细解答。
第四章主要讨论了词法分析的相关内容,包括正则表达式和有限自动机。
2. 正则表达式正则表达式是一种表示字符串模式的方法。
它由一些字符和操作符组成,用于描述一类字符序列的模式。
正则表达式通常用于文本搜索、匹配和替换操作中。
2.1 正则表达式的基本操作符正则表达式的基本操作符包括字符、连接、选择和重复。
•字符:可以是单个字符,例如a、b、c。
•连接:用于连接两个正则表达式,例如ab表示在字符串中同时出现a和b。
•选择:用于在多个正则表达式中选择一个,例如a|b表示字符串中可以是a或者b。
•重复:用于指定某个正则表达式的重复次数,例如a*表示a可以出现任意次数(包括 0 次)。
2.2 正则表达式的语法正则表达式的语法规则如下:•字符:表示一个字符。
•.:表示任意字符。
•[]:表示字符集合,匹配括号内的任意一个字符。
•[^]:表示字符集合的补集,匹配除了括号内的字符之外的任意字符。
•-:表示范围,例如[a-z]匹配任意小写字母。
•*:表示重复零次或多次。
•+:表示重复一次或多次。
•?:表示重复零次或一次。
•():表示分组。
2.3 正则表达式的应用正则表达式在编译原理中的应用非常广泛。
在词法分析中,正则表达式可以用来描述编程语言中的单词(token)和它们的模式。
编译器可以使用正则表达式作为词法分析器的输入,用于将源代码分解为不同的单词。
3. 有限自动机有限自动机(Finite Automaton,FA)是一种用于描述正则语言的理论模型。
它是一种数学模型,包括有限个状态和状态之间的转移。
根据输入的字符,自动机会从一个状态转移到另一个状态。
3.1 有限自动机的组成有限自动机由以下几个部分组成:•有限个状态:每个状态表示自动机在某个时刻的状态。
•输入符号集合:表示自动机接受的输入字符集合。
统计学第四章习题答案
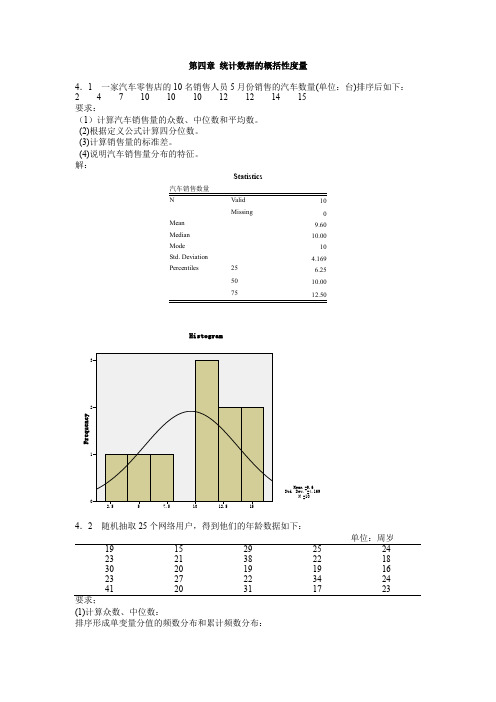
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing0Mean9.60Median10.00Mode10Std. Deviation 4.169Percentiles25 6.255010.0075单位:周岁19152925242321382218302019191623272234244120311723要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
为比较哪种排队方式使顾客等待的时间更短.两种排队方式各随机抽取9名顾客。
数据库第4章习题答案

.4.2 对于教学数据库的三个基本表S(SNO,SNAME,AGE,SEX,SDEPT)SC(SNO,CNO,GRADE)C(CNO,CNAME,CDEPT,TNAME)试用SQL的查询语句表达下列查询:①检索LIU老师所授课程的课程号和课程名。
②检索年龄大于23岁的男学生的学号和姓名。
③检索至少选修LIU老师所授课程中一门课程的女学生姓名。
④检索WANG同学不学的课程的课程号。
⑤检索至少选修两门课程的学生学号。
⑥检索全部学生都选修的课程的课程号与课程名。
⑦检索选修课程包含LIU老师所授(全部)课程的学生学号。
参考答案:①SELECT CNO,CNAMEFROM CWHERE TNAME=‘LIU';②SELECT SNO,SNAMEFROM SWHERE AGE>23AND SEX=‘M';③SELECT SNAME(联接查询方式)FROM S,SC,CWHERE S.SNO=SC.SNO AND O=OAND SEX='F' AND TNAME='LIU';或:SELECT SNAME (嵌套查询方式)FROM SWHERE SEX=‘F'AND SNO IN(SELECT SNOFROM SCWHERE CNO IN (SELECT CNOFROM CWHERE TNAME='LIU'));或:SELECT SNAME (存在量词方式)FROM SWHERE SEX=‘F'AND EXISTS(SELECT*FROM SCWHERE SC.SNO=S.SNOAND EXISTS(SELECT *FROM CWHERE O=OAND TNAME='LIU'));④SELECT CNOFROM CWHERE NOT EXISTS8/ 1.(SELECT *FROM S,SCWHERE S.SNO=SC.SNO AND O=OAND SNAME='WANG');或:SELECT CNOFROM CWHERE CNO NOT IN(SELECT OFROM S,SCWHERE S.SNO=SC.SNO AND SNAME='WANG'); 或:SELECT CNOFROM CWHERE CNO NOT IN(SELECT CNOFROM SCWHERE SNO IN(SELECT SNOFROM SWHERE SNAME='WANG'));⑤SELECT DISTINCT X..SNOFROM SC AS X,SC AS Y WHERE X.SNO=Y.SNO AND O<>O;或:SELECT SNOFROM SCGROUP BY SNO HA VING COUNT(CNO)>=2;⑥SELECT CNO,CNAMEFROM CWHERE NOT EXISTS(SELECT *FROM SWHERE NOT EXISTS(SELECT *FORM SCWHERE SC.SNO=S.SNO AND O=O));⑦SELECT DISTINCT SNOFROM SC AS XWHERE NOT EXISTS(SELECT *FORM CWHERE TNAME='LIU'AND NOT EXISTS(SELECT *FROM SC AS YWHERE Y.SNO=X.SNO AND O=O));8/ 2.4.3 设有两个基本表R(A,B,C)和S(D,E,F),试用SQL查询语句表达下列关系代数表达式:①SELECT A FROM R;②SELECT * FROM R WHERE B=17;③SELECT * FROM R,S;④SELECT A,F FROM R,S WHERE C=D;4.4 设有两个基本表R(A,B,C)和S(A,B,C),试用SQL查询语句表达下列关系代数表达式:1.(SELECT * FROM R)UNION(SELECT * FROM S);2.(SELECT * FROM R)INTERSECT(SELECT * FROM S);3.(SELECT * FROM R)EXCEPT(SELECT * FROM S);4.(SELECT A,B FROM R)NATURAL INNER JOIN(SELECT B,C FROM S);或:SELECT R.A, R.B, S.CFROM R,SWHERE R.B=S.B4.6 试用SQL查询语句表达下列对教学数据库中三个基本表S、SC、C的查询:1、统计有学生选修的课程门数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
abstract def zip[B](that: GenIterable[B]): StringOps[(A, B)]
GenIterable是可遍历对象需要包含的trait,对于String来说,它是可遍历的。但是它的遍历是遍历单个字母。所以拉链就针对每个字母来进行。
(values.count(_ < v),values.count(_ == v),values.count(_ > v))
}
5.10当你将两个字符串拉链在一起,比如"Hello".zip("World"),会是什么结果?想出一个讲得通的用例
scala> "Hello".zip("World")
res0: scala.collection.immutable.IndexedSeq[(Char, Char)] = Vector((H,W), (e,o), (l,r), (l,l), (o,d))
当然使用Scala的方法啦。参考第9章
首先,创建一个文件myfile.txt。输入如下内容
test test ttt test ttt t test sss s
Scala代码如下
importscala.io.Source
importscala.collection.mutable.HashMap
//val source = Source.fromFile("myfile.txt")
5.5重复前一个练习,这次使用java.util.TreeMap并使之适用于Scala API
主要涉及java与scala的转换类的使用
importscala.io.Source
importscala.collection.mutable.Map
importscala.collection.JavaConversions.mapAsScalaMap
importscala.collection.mutable.LinkedHashMap
importjava.util.Calendar
valmap=newLinkedHashMap[String,Int]
map += ("Monday"->Calendar.MONDAY)
map += ("Tuesday"->Calendar.TUESDAY)
valsource= Source.fromFile("myfile.txt").mkString
valtokens= source.split("\\s+")
varmap= Map[String,Int]()
for(key <- tokens){
map += (key -> (map.getOrElse(key,0) + 1))
5映射和元组
5.1设置一个映射,其中包含你想要的一些装备,以及它们的价格。然后构建另一个映射,采用同一组键,但是价格上打9折
映射的简单操作
scala> val map = Map("book"->10,"gun"->18,"ipad"->1000)
map: scala.collection.immutable.Map[ng.String,Int] = Map(book -> 10, gun -> 18, ipad -> 1000)
(values.max,values.min)
}
5.9编写一个函数Iteqgt(values:Array[int],v:Int),返回数组Байду номын сангаас小于v,等于v和大于v的数量,要求三个值一起返回
defiteqgt(values:Array[Int],v:Int)={
valbuf= values.toBuffer
//val tokens = source.mkString.split("\\s+") //此写法tokens为空,不知为何
valsource= Source.fromFile("myfile.txt").mkString
valtokens= source.split("\\s+")
valmap=newHashMap[String,Int]
scala> for((k,v) <- map) yield (k,v * 0.9)
res3: scala.collection.immutable.Map[ng.String,Double] = Map(book -> 9.0, gun -> 16.2, ipad -> 900.0)
map(key) = map.getOrElse(key,0) + 1
}
println(map.mkString(","))
5.6定义一个链式哈希映射,将"Monday"映射到java.util.Calendar.MONDAY,依次类推加入其他日期。展示元素是以插入的顺序被访问的
LinkedHashMap的使用
valtokens= source.split("\\s+")
varmap= SortedMap[String,Int]()
for(key <- tokens){
map += (key -> (map.getOrElse(key,0) + 1))
}
println(map.mkString(","))
importjava.util.TreeMap
valsource= Source.fromFile("myfile.txt").mkString
valtokens= source.split("\\s+")
valmap:Map[String,Int]=newTreeMap[String,Int]
for(key <- tokens){
for(key <- keys) {
print(key)
print(" "* (maxKeyLength - key.length))
print(" | ")
println(props(key))
}
5.8编写一个函数minmax(values:Array[Int]),返回数组中最小值和最大值的对偶
defminmax(values:Array[Int])={
valprops:scala.collection.Map[String,String]= System.getProperties()
valkeys= props.keySet
valkeyLengths=for( key <- keys )yieldkey.length
valmaxKeyLength= keyLengths.max
for(key <- tokens){
map(key) = map.getOrElse(key,0) + 1
}
println(map.mkString(","))
5.3重复前一个练习,这次用不可变的映射
不可变映射与可变映射的区别就是,每次添加元素,都会返回一个新的映射
importscala.io.Source
map += ("Sunday"->Calendar.SUNDAY)
println(map.mkString(","))
5.7打印出所有Java系统属性的表格,
属性转scala map的使用
importscala.collection.JavaConversions.propertiesAsScalaMap
5.2编写一段程序,从文件中读取单词。用一个可变映射来清点每个单词出现的频率。读取这些单词的操作可以使用java.util.Scanner:
val in = new java.util.Scanner(new java.io.File("myfile.txt")) while(in.hasNext())处理in.next()或者翻到第9章看看更Scala的做法。最后,打印出所有单词和它们出现的次数。
}
println(map.mkString(","))
5.4重复前一个练习,这次使用已排序的映射,以便单词可以按顺序打印出来
和上面的代码没有什么区别,只是将映射修改为SortedMap
importscala.io.Source
importscala.collection.SortedMap
valsource= Source.fromFile("myfile.txt").mkString
map += ("Wednesday"->Calendar.WEDNESDAY)
map += ("Thursday"->Calendar.THURSDAY)
map += ("Friday"->Calendar.FRIDAY)
map += ("Saturday"->Calendar.SATURDAY)