张晓峒VAR模型与协整讲义
我国货币供应量M1与GDP关系的实证分析

我国货币供应量M1与GDP关系的实证分析摘要:我国国家宏观调控的政策包括财政政策和货币政策。
我国货币供应量M1与国内生产总值GDP具有显著的时间性和不平稳性,通过建立V AR(3)模型,分析得出我国货币供应量M1与国内生产总值GDP存在长期稳定的正相关关系。
脉冲响应分析和方差分解分析,得出货币供应量M1和国民生产总值GDP均具有显著的内生性,并且货币供应量M1对GDP的作用的发挥是一个长期过程,在短期内效果有限,而GDP对货币供应量M1在短期内有较强的影响力,而在长期影响力变弱。
最后,通过建立货币供应量M1与GDP的长期ECM协整方程以及短期误差修正模型,进一步用数理方程式证明我国货币政策的作用在短期内较弱,在长期内较显著。
关键词:货币供应量M1、国内生产总值GDP、V AR模型、ECM误差修正一、货币供应量与GDP关系的理论分析1,货币供应量是货币政策的一部分,货币供应量的增加对gdp的增长有一定的刺激作用。
由产出关系式m+++=可以发现,货币供应量(以狭义货cy-gxi币供应量m1表示)的增加,使利率降低,从而刺激投资i和消费c,带来产出的增加,企业收入增长,又会增加国家的税收,从而增加政府购买g,流通中的货币增加又会造成汇率下降,从而刺激出口,而短期内进口具有刚性,因而,总得来说,y增加,用价值表示就是gdp的增加。
2,货币供应量受经济发展水平的制约,流通中的货币供应量增加速度快于经济发展速度,则会造成通货膨胀,严重的通货膨胀对经济发展造成负面影响,因此,货币供应量不可能无限制增长,央行根据经济需要决定货币发行,货币发行量的政策指导性很强,具有显著的内生性。
3,国内生产总值GDP对货币供应量有正向影响,GDP的增加,使社会各个经济单位和部门的收入增加,从而使流通中的货币总量增加,同时,GDP的增长要求社会有充足的流动性以满足物质增长的需求,因此,要求央行新发行货币以满足经济发展需要,因而国内生产总值的增长刺激了货币供应量的增加。
金融时间序列分析

《金融时间序列分析》讲义主讲教师:徐占东登录:徐占东《金融时间序列模型》参考教材:1.《金融时间序列的经济计量学模型》经济科学出版社米尔斯著2.《经济计量学手册》章节3.《Introductory Econometrics for Finance》 Chris Brooks 剑桥大学出版社4.《金融计量学:资产定价实证分析》周国富著北京大学出版社5.《金融市场的经济计量学》 Andrew lo等上海财经大学出版社6.《动态经济计量学》 Hendry著上海人民出版社7.《商业和经济预测中的时间序列模型》中国人民大学出版社弗朗西斯著8.《No Linear Econometric Modeling in Time series Analysis》剑桥大学出版社9.《时间序列分析》汉密尔顿中国社会科学出版社10.《高等时间序列经济计量学》陆懋祖上海人民出版社11.《计量经济分析》张晓峒经济科学出版社12.《经济周期的波动与预测方法》董文泉高铁梅著吉林大学出版社13.《宏观计量的若干前言理论与应用》王少平著南开大学出版社14.《协整理论与波动模型——金融时间序列分析与应用》张世英、樊智著清华大学出版社15.《协整理论与应用》马薇著南开大学出版社16.(NBER working paper)17.(Journal of Finance)18.(中国金融学术研究网) 教学目的:1)能够掌握时间序列分析的基本方法;2)能够应用时间序列方法解决问题。
教学安排1单变量线性随机模型:ARMA ; ARIMA; 单位根检验。
2单变量非线性随机模型:ARCH,GARCH系列模型。
3谱分析方法。
4混沌模型。
5多变量经济计量分析:V AR模型,协整过程;误差修正模型。
第一章引论第一节金融学简介一.金融学概论1.金融学:研究人们在不确定环境中进行资源最优配置的学科。
金融学的三个核心问题:资产时间价值,资产定价理论(资源配置系统)和风险管理理论。
固定效应和随机效应

方差分析主要有三种模型:即固定效应模型(fixed effects model),随机效应模型(random effects model),混合效应模型(mixed effects model)。
所谓的固定、随机、混合,主要是针对分组变量而言的。
固定效应模型,表示你打算比较的就是你现在选中的这几组。
例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。
这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。
“固定”的含义正在于此,这三种药是固定的,不是随机选择的。
随机效应模型,表示你打算比较的不仅是你的设计中的这几组,而是想通过对这几组的比较,推广到他们所能代表的总体中去。
例如,你想知道是否名牌大学的就业率高于普通大学,你选择了北大、清华、北京工商大学、北京科技大学4所学校进行比较,你的目的不是为了比较这4所学校之间的就业率差异,而是为了说明他们所代表的名牌和普通大学之间的差异。
你的结论不会仅限于这4所大学,而是要推广到名牌和普通这样的一个更广泛的范围。
“随机”的含义就在于此,这4所学校是从名牌和普通大学中随机挑选出来的。
混合效应模型就比较好理解了,就是既有固定的因素,也有随机的因素。
一般来说,只有固定效应模型,才有必要进行两两比较,随机效应模型没有必要进行两两比较,因为研究的目的不是为了比较随机选中的这些组别。
固定效应和随机效应的选择是大家做面板数据常常要遇到的问题,一个常见的方法是做huasman检验,即先估计一个随机效应,然后做检验,如果拒绝零假设,则可以使用固定效应,反之如果接受零假设,则使用随机效应。
但这种方法往往得到事与愿违的结果。
另一个想法是在建立模型前根据数据性质确定使用那种模型,比如数据是从总体中抽样得到的,则可以使用随机效应,比如从N个家庭中抽出了M个样本,则由于存在随机抽样,则建议使用随机效应,反之如果数据是总体数据,比如31个省市的Gdp,则不存在随机抽样问题,可以使用固定效应。
进口贸易与经济增长的实证分析研究

进口贸易与经济增长的实证分析研究【摘要】本文运用单位根检验、误差修正模型、V AR模型、脉冲响应函数,利用1978-2012年的统计数据,对进口贸易对与经济增长的内在联系进行研究,结果表明GDP与进口贸易之间存在着长期稳定的动态均衡关系,进口贸易对GDP有很强促进作用,最后根据以上分析提出相关建议。
【关键词】协整检验;误差修正模型;V AR模型;脉冲响应函数0 引言当今世界是一个开放的世界,经济日益全球化,任何一个国家都不可能通过闭关锁国而取得经济上的长远发展,对外贸易于是就成为各国互通有无,调剂余缺的桥梁。
而长期以来,决策界和学术界总体上形成了高度重视出口贸易而低估甚至忽视进口贸易在经济增长中发挥作用的倾向。
在贸易政策方面,国家通过出口补贴和出口退税等措施鼓励出口,而对进口则实行不同程度的关税和非关税限制措施;在评价对外贸易对经济增长的贡献时,几乎都把关注的焦点放在出口或是贸易顺差上,似乎只有出口或贸易顺差才对经济增长起推动作用。
然而,进口贸易规模不断增长同样具有重大作用。
利用1978-2012年统计数据,对进口贸易对及国内生产总值的影响进行实证分析。
数据为1978-2012年我国进口贸易总额以及国内生产总值,来源于历年《中国统计年鉴》。
1 模型建立及分析1.1 单位根检验分别采用ADF单位根检验,由表1知,LNGDP、LNIM原序列在95%的显著性水平上不能拒绝存在单位根的原假设,而一阶差分后的序列在95%的显著性水平上拒绝存在单位根的原假设,即两序列均为I(1)序列。
表1 ADF单位根检验结果1.2 协整检验单位根检验结果表明所有序列都是I(1),即它们具备构造协整方程组的必要条件。
为了进一步确定变量之间是否存在协整关系,本文采用EG两步法对变量进行协整检验。
第一步,先用OLS法进行协整回归,得到非均衡误差。
估计的协整方程如下:利用上述建立的误差的修正模型静态预测GDP与实际GDP拟合图如图1,可知拟合比较理想。
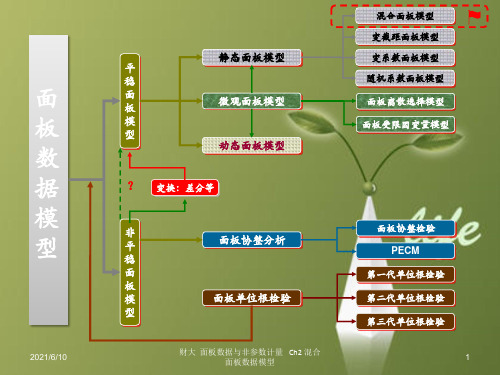
课件:混合面板数据模型
2021/6/10
财大 面板数据与非参数计量 Ch2 混合 面板数据模型
11
Ch2 混合面板数据模型
• Ch2.1 混合面板数据模型及估计 • Ch2.2 模型设定检验 • Ch2.3 案例分析
2021/6/10
财大 面板数据与非参数计量 Ch2 混合 面板数据模型
12
Ch2.3 案例分析
• 请参见 • 第三、四章中的案例分析
•
第八章 微观面板数据模型(离散选择模型、
Tobit模型)
• 下篇 非平稳面板数据模型
•
第五章 面板单位根检验(第一、二、三代单位检验)
•
2021/6/10
第六章 面财板大 面协板数整据与检非参验数计量与Ch误2 混合差修正模型 面板数据模型
2
Ch2 混合面板数据模型
张华节 统计学院 Email:hjzhang@
财大 面板数据与非参数计量 Ch2 混合 面板数据模型
9
Ch2 混合面板数据模型
• Ch2.1 混合面板数据模型及估计 • Ch2.2 模型设定检验 • Ch2.3 案例分析
2021/6/10
财大 面板数据与非参数计量 Ch2 混合 面板数据模型
10
Ch2.2 模型设定检验
• 与固定效应和随机效应检验结合判断。 • 具体内容,请参见 • 综合第三、四章关于模型检验中的部分内
8
• 对混合模型通常采用的是混合最小二乘 (Pooled OLS)估计法。
• 然而,在误差项服从独立同分布条件下由 OLS法得到的方差协方差矩阵,在这里通 常不会成立。
• 因为对于每个个体 i 及其误差项来说通常
是序列相关的。NT个相关观测值要比 NT
我国进出口贸易关系的时间检验

( 1.5)
并用 OLS 法估计上式中的短期参数 $ 和 &, 通过调整 %yt 和 %xt 的滞后项消除 ’t 的自相关。
三、数据的采集和说明
笔者所采集的数据为 1951 - 2003 年我国出口总额( Et) 、进口总额( It) 和物价指数( Pt, 固定 P1990=1) , 因为时间跨度较长, 特别是经济转型期物价变化较为激烈, 所以物价指数也作为经济变量加入模型中 ( 数据来自《中国统计年鉴》, 1992 版第 236 页, 第 627 页, 2004 版第 323 页, 第 714 页, 并计算) 。
下都是平稳序列, 符合 Engle- Granger 协整检验的要求。
2.协整关系检验
下面把 lnEt 作为因变量, lnIt, lnPt 作为自变量, 进行 OLS 回归, 得回归方程如下: lnEt=1.8360+0.0259t+0.6400lnIt+0.5741lnPt+!^ t
( 2.1)
( 7.55) ( 6.26) ( 14.59) ( 5.81)
( 2.4)
R2=0.56, DW=1.86, s.e.=0.144, T=52( 1952- 2003 年)
LM1=1.44( P1=0.24) , LM2=2.69( P2=0.07) ,
- 12 -
《国际贸易问题》2006 年第 1 期
经贸论坛
ARCH=1.85( P=0.18) ( 2.4) 式中的回归系数都通过了显著性检验, 误差修正系数为负, 符合反向修正机制。LM 的一阶和 二阶 P 值都大于 0.05, 模型不存在自相关, ARCH 的 P 值也大于 0.05, 所以也不存在异方差。
量之间的关系。非平稳变量变为平稳变量之后, 也可以建立动态滞后分布模型( ADL) , 其参数估计量具
面板数据分析简要步骤与注意事项面板单位根—面板协整—回归分析
面板数据分析简要步骤与注意事项面板单位根—面板协整—回归分析 SANY标准化小组 #QS8QHH-HHGX8Q8-GNHHJ8-HHMHGN#面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)步骤一:分析数据的平稳性(单位根检验)按照正规程序,面板数据模型在回归前需检验数据的平稳性。
李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。
这种情况称为称为虚假回归或伪回归(spurious regression)。
他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。
因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。
因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。
而检验数据平稳性最常用的办法就是单位根检验。
首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。
单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,LevinandLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。
后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。
Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。
Im et al. (1997) 还提出了检验面板单位根的IPS 法,但Breitung(2000) 发现IPS 法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung 法。
动态面板数据分析步骤详解..
动态⾯板数据分析步骤详解..动态⾯板数据分析算法1. ⾯板数据简介⾯板数据(Panel Data, Longitudinal Data ),也称为时间序列截⾯数据、混合数据,是指同⼀截⾯单元数据集上以不同时间段的重复观测值,是同时具有时间和截⾯空间两个维度的数据集合,它可以被看作是横截⾯数据按时间维度堆积⽽成。
⾃20世纪60年代以来,计量经济学家开始关注⾯板数据以来,特别是近20年,随着计量经济学理论,统计⽅法及计量分析软件的发展,⾯板数据计量经济分析已经成为计量经济学研究最重要的分⽀之⼀。
⾯板数据越来越多地被应⽤到计量模型的研究中,其在实证分析中的优点是明显的:相对于只具有⼀个时点的横截⾯数据模型,⾯板数据包含了更多时间维度的数据,从⽽可以利⽤更多的信息来分析所研究问题的动态关系;⽽时间序列模型,其数据往往是由个体数据加总产⽣的,在实际计量分析中,在研究其动态调整⾏为时,由于个体差异被忽略,其估计结果有可能是有偏的,⽽⾯板数据模型能够通过截距项,捕捉到数据的动态调整过程中的个体差异,有效地减少了由于数据加总所产⽣的偏误;同时,⾯板数据同时具有时间和截⾯空间的两个维度,从⽽分享了横截⾯数据和时间序列数据的优点,另外,由于具有更多的观察值,其推断的可靠性也有所增加。
2. ⾯板数据的建模与检验设3. 动态⾯板数据的建模与检验所谓动态⾯板数据模型,是指通过在静态⾯板数据模型中引⼊滞后被解释变量以反映动态滞后效应的模型。
这种模型的特殊性在于被解释变量的动态滞后项与随机误差组成部分中的个体效应相关,从⽽造成估计的内⽣性。
4、步骤详解步骤⼀:分析数据的平稳性(单位根检验)按照正规程序,⾯板数据模型在回归前需检验数据的平稳性。
李⼦奈曾指出,⼀些⾮平稳的经济时间序列往往表现出共同的变化趋势,⽽这些序列间本⾝不⼀定有直接的关联,此时,对这些数据进⾏回归,尽管有较⾼的R平⽅,但其结果是没有任何实际意义的。
这种情况称为称为虚假回归或伪回归(spurious regression)。
中国能源需求向量自回归模型的建立与分析
一、引言经济增长与能源需求关系密切,两者相互影响,相互促进。
随着我国国民经济的发展,对能源需求日益增加。
科学地预测我国中长期能源需求量,对于经济的可持续发展具有重要的意义。
能源需求预测的方法很多,如时间序列法,回归分析法,能源消耗弹性系数法,投入产出法等。
但这些方法都存在一定的局限性,只反映单一的因素或几个主要的因素对能源需求的影响,影响因素与能源需求的关系主要是线性的、静态的。
而向量自回归模型是用一种动态的非结构性的方法来建立变量之间关系模型,推动了经济系统动态性分析的广泛运用,这种模型常用于预测相互联系的时间序列系统,近年来受到越来越多经济工作者的重视。
向量自回归模型系统内每个方程有相同的右侧变量,而这些右侧变量包括所有内生变量的滞后值,当每个变量都对预测其他变量起作用时,这组变量适合用VAR 模型。
能源总消费量由煤炭、石油、天然等的消费量组成,其中每个因素的变化都会对另外因素产生影响,另外,VAR 模型在能源需求预测中较少应用,因此,本文应用VAR 模型对2020年以前能源总消费量、煤炭、石油、天然气的消费量进行了中长期预测。
二、向量自回归模型用联立方程的形式建立模型在20世纪五六十年代风行一时。
这种方法的理论优点是对方程内有随机误差项与某些解释变量的相关所造成的回归参数估计量的偏倚给予了充分的注意与考虑,从而提出工具变量法,两阶段最小二乘法,有限信息及大似然估计法等估计方法。
这种建模方法用来研究大型复杂的宏观经济问题,用来做政策分析和预测,在实际应用中,由于这些模型的预测效果并不令人十分满意,所以联立方程模型也招致一些批评。
疑问主要集中在零约束的假定条件以及对变量进行内生与外生的划分上。
为达到可识别的目的就要对变量实行零约束。
当模型不可识别时,通常是加入一些额外的不同变量于不同的方程从而满足识别条件。
这些新加入变量的解释能力有时是很弱的。
如果变量是非平稳的,则违反了假定条件。
这也是造成预测效果不佳的原因之一。
高级计量经济学-1
步骤之一,即探索性的关系识别。 • 一些人为了获得预想的结果,常常有目的地进行“数据淘洗
〞 (data-cleaning) ,即删除那些不支持预想结果的观察值, 甚至修改数据。 • 因而应该认识到,利用计量经济学方法得出的结论都是有条 件的。
和归纳开展为探讨多因素间的数量关系和进行假说检 验
第十九页,编辑于星期六:十八点 十八分。
计量经济学与经验研究
• 传统研究方法侧重于得到模型参数的“精确〞估计, 但对于“数据生成过程〞未给予高度关注。
• 研究人员依据感觉或经验提出模型,然后利用“试错 法〞、逐步回归等手段估计变量之间的统计关系,在 此基础上,“选择〞出自己满意的模型。
o 高雪梅主编(2005).《计量经济分析方法与建模:EVIEWS应 用及实例》.北京:清华大学出版社.
4
第四页,编辑于星期六:十八点 十八分。
△ 初、中、高级计量经济学
• 初级以计量经济学的数理统计学基础知识和经典 的线性单方程模型理论与方法为主要内容;
• 中级以用矩阵描述的经典的线性单方程模型理论 与方法、经典的线性联立方程模型理论与方法, 以及传统的应用模型为主要内容;
8
第八页,编辑于星期六:十八点 十八分。
• 非经典计量经济学一般指20世纪70年代以来开展的计 量经济学理论、方法及应用模型,也称为现代计量经济 学。
• 非经典计量经济学主要包括:微观计量经济学、非参数 计量经济学、时间序列计量经济学和动态计量经济学等。
• 非经典计量经济学的内容体系:模型类型非经典的计量 经济学问题、模型导向非经典的计量经济学问题、模型 结构非经典的计量经济学问题、数据类型非经典的计量 经济学问题和估计方法非经典的计量经济学问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
例8.7 N = 3 的V AR 模型的3个特征根分别是λ1 = 0.9, λ2 = 0.5, λ3 = 0.04。
样本容量T = 100,临界值相应给出。
见表8.1。
练习协整向量个数的检验过程。
首先检验r = 0。
LR = - T [∑+=N r i log 1(1- λi ) ] = - 100∑=-31)1log(i i λ= -100 [log(0.1)+ log(0.5)+ log(0.96)]= -100 (-2.302-0.693-0.04) = 303.6 > 34.91(临界值)接着检验r = 1。
LR = - 100∑=-32)1log(i i λ= -100 [log(0.5)+ log(0.96)]= -100 (-0.693-0.04) = 73.30 > 19.96(临界值)接着检验r = 2。
LR = - 100 log (1- λ3 ) = -100 log(0.96)= -100 (-0.04) = 4.082 < 9.24(临界值) 因为r ≤ 1已被拒绝,但r ≤ 2未被拒绝,所以结论是该V AR 模型存在2个协整向量。
如下表。
协整检验过程零假设 N - r 特征值 迹统计量5%水平临界值 r = rk(∏ ) = 0 3 0.90 303.6 > 34.91 r = rk(∏ ) ≤ 1 2 0.50 73.30 > 19.96 r = rk(∏ ) ≤ 210.044.082 <9.24注:临界值取自附表1的b 部分。
8.3.3 VEC 模型中确定项的处理 1.常数项的处理VEC 模型中常数项的位置可分3种情形讨论。
位置不同,相应的协整检验用表也不同。
(1)常数项μ完全属于协整空间。
那么可以把μ写成如下形式:μ = α μ1其中μ是N ⨯1阶的,α是N ⨯ r 阶的,μ1是r ⨯ 1阶的。
以V AR 模型Y t = μ + ∏1 Y t -1 + u t 为例,相应VEC 模型形式是∆Y t = α β ' Y t -1 +α μ1 + u t = α (β ', μ1 )⎥⎦⎤⎢⎣⎡-11t Y + u t (8.100) (2)常数项 μ 的一部分进入协整空间,一部分属于数据空间(V AR 的常数项)。
下面介绍怎样把μ 分离成两部分。
因为α 是N ⨯ r 阶的,构造一个N ⨯ (N – r ) 阶矩阵α⊥,使α 'α⊥ = 0。
α 与α⊥ 正交。
定义α⊥ 的目的是要把μ 分离成相互无关的两部分。
μ = α μ1 + α⊥ μ2 (8.101)显然α μ1能进入协整空间(见(8.100)式)。
μ1属于协整空间的常数项。
因为α 与α⊥ 是正交,α⊥ μ2不能进入协整空间。
μ2属于数据空间的常数项。
∆Y t = μ + α β ' Y t -1 + u t = α μ1 + α⊥ μ2 + α β ' Y t -1 + u t= α⊥ μ2 + α (β ', μ1 )⎥⎦⎤⎢⎣⎡-11t Y + u t (8.102) 下面介绍μ1,μ2的求法。
用 (α 'α)-1α ' 左乘(8.101) 式,得(α 'α)-1α 'μ = (α 'α)-1α 'α μ1 + (α 'α)-1α 'α⊥ μ2 = μ1 (8.103)上式是 μ1的计算公式。
用 (α⊥' α⊥)-1α⊥' 左乘(8.101) 式,得(α⊥' α⊥)-1α⊥ 'μ = (α⊥' α⊥) –1 α⊥' α μ1 + (α⊥'α⊥)-1α⊥' α⊥ μ2 = μ2 (8.104)上式是 μ2的计算公式。
例8.6 举例说明μ 的位置。
设N =2的VAR 模型如下, ⎥⎦⎤⎢⎣⎡t t y y ,2,1=⎥⎦⎤⎢⎣⎡-40/140/3+⎥⎦⎤⎢⎣⎡--16/12/116/12/1⎥⎦⎤⎢⎣⎡--1,21,1t t y y +⎥⎦⎤⎢⎣⎡t t u u 21 (8.105) 其中μ =⎥⎦⎤⎢⎣⎡-40/140/3。
先求α。
变化上式, ⎥⎦⎤⎢⎣⎡t t y y ,2,1=⎥⎦⎤⎢⎣⎡-40/140/3+⎥⎦⎤⎢⎣⎡-2/12/1[]8/11-⎥⎦⎤⎢⎣⎡--1,21,1t t y y +⎥⎦⎤⎢⎣⎡t t u u 21 (8.106) 因为 α =⎥⎦⎤⎢⎣⎡-2/12/1,所以α⊥ =⎥⎦⎤⎢⎣⎡--2/12/1,则 α 'α⊥ =[]2/12/1-⎥⎦⎤⎢⎣⎡--2/12/1= 0。
按(8.103)式,(α 'α)-1α 'μ = μ1计算μ1, μ1 = (α 'α)-1α 'μ =()12/12/12/12/1-⎥⎥⎦⎤⎢⎢⎣⎡⎪⎪⎭⎫ ⎝⎛--[]2/12/1-⎥⎦⎤⎢⎣⎡-40/140/3= 1/10 按(8.104)式,(α⊥' α⊥)-1α⊥ 'μ = μ2计算μ2, μ2 = (α⊥ 'α⊥)-1α⊥ 'μ =()12/12/12/12/1-⎥⎥⎦⎤⎢⎢⎣⎡⎪⎪⎭⎫ ⎝⎛----[]2/12/1--⎥⎦⎤⎢⎣⎡-40/140/3= 1/20 验证,μ = α μ1 + α⊥ μ2。
μ = α μ1 + α⊥ μ2 =⎥⎦⎤⎢⎣⎡-2/12/1(1/10) +⎥⎦⎤⎢⎣⎡--2/12/1(1/20) = ⎥⎦⎤⎢⎣⎡-20/120/1+⎥⎦⎤⎢⎣⎡--40/140/1=⎥⎦⎤⎢⎣⎡-40/140/3 按(8.102)式,VEC 模型表示为∆Y t = μ + α β ' Y t -1 + u t = α μ1 + α⊥ μ2 + α β ' Y t -1 + u t= α⊥ μ2 + α (β ' μ1 )⎥⎦⎤⎢⎣⎡-11t Y + u t (8.107) ⎥⎦⎤⎢⎣⎡∆∆t t y y ,2,1=⎥⎦⎤⎢⎣⎡--40/140/1+⎥⎦⎤⎢⎣⎡-2/12/1()10/18/11-⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--11,21,1t t y y +⎥⎦⎤⎢⎣⎡t t u u 21μ 的一部分进入协整空间,一部分进入数据空间。
(3)常数项只进入数据空间(V AR 的常数项),不进入协整空间。
对于(8.101) 式,当α μ1 = 0时,μ = α⊥ μ2。
常数项只进入数据空间∆Y t = μ + α β ' Y t -1 + u t = α⊥ μ2 + α β ' Y t -1 + u t (8.108)2.趋势项的处理同理,对时间趋势项t 的系数δ 也可以做上述分解。
δ = α δ1 + α⊥ δ2 (8.109)α δ1进入协整空间,表示变量协整关系中也存在线性趋势。
α⊥ δ2进入数据空间(V AR 的常数项)。
表示原变量中存在二次方的时间趋势项,或差分变量中存在一次方的时间趋势项,例如V AR 模型为,Y t = μ + δ t + ∏1 Y t -1 + u t相应的VEC 模型形式是∆Y t = μ + δ t + ∏Y t -1 + u t = α μ1 + α⊥ μ2 + α δ1 t + α⊥ δ2 t + α β 'Y t -1 + u t= α⊥ μ2 + α⊥ δ2 t + (α β 'Y t -1 + α μ1 + α δ1 t ) + u t (8.111) = α⊥ (μ2 + δ2 t )+ α ( β 'Y t -1 + μ1 + δ1 t ) + u t (8.112)= α⊥ (μ2, δ2) ⎥⎦⎤⎢⎣⎡t 1+ α (β ', μ1, δ1 )⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-t t 11Y + u t8.3.4 协整检验用表根据 μ 和 δ t 所在位置不同,检验协整关系的LR 统计量的分布也不同。
检验时应选择相应的临界值表。
附表1给出了5种模型条件下所对应的临界值。
附表1 VAR 模型协整检验临界值表(迹统计量)单位根个数 α模型类型N - r0.10 0.05 0.011 2.86 3.84 6.51 模型(1)2 10.47 12.53 16.31 μ = 0, δ = 03 21.63 24.31 29.75 协整空间中无常数项、无趋势项。
4 36.58 39.89 45.58 数据空间中无均值、无趋势项。
5 55.44 59.46 66.52 6 78.36 82.49 90.457 104.77 109.99 119.808 135.24 141.20 152.329 169.45 175.77 187.31 10 206.05 212.67 226.40 11 248.45 255.27 269.811 7.52 9.24 12.97 模型(2)2 17.85 19.96 24.60 μ1 ≠ 0, μ2 = 0, δ = 03 32.00 34.91 41.07 协整空间中有常数项、无趋势项。
4 49.65 53.12 60.16 数据空间中无均值、无趋势项。
5 71.86 76.07 84.45 6 97.18 102.14 111.01 7 126.58 131.70 143.09 8 159.48 165.58 177.20 9 196.37 202.92 215.74 10 236.54 244.15 257.6811282.45291.40307.641 2.69 3.76 6.65模型(3) 2 13.33 15.41 20.04 μ1≠ 0, μ2≠ 0, δ= 0 3 26.79 29.68 35.65协整空间中有常数项、无趋势项。
4 43.95 47.21 54.46数据空间中有线性趋势、无二次趋势项。
5 64.84 68.52 76.076 89.48 94.15 103.187 118.50 124.24 133.578 150.53 156.00 168.369 186.39 192.89 204.9510 225.85 233.13 247.1811 269.96 277.71 293.441 10.49 12.25 16.26模型(4) 2 22.76 25.32 30.45 μ1≠ 0, μ2≠ 0, δ1≠ 0, δ2= 0 3 39.06 42.44 48.45协整空间中有常数项、有线性趋势项。
4 59.14 62.99 70.05数据空间中有线性趋势、无二次趋势项。
5 83.20 87.31 96.586 110.42 114.90 124.757 141.01 146.76 158.498 176.67 182.82 196.089 215.17 222.21 234.4110 256.72 263.42 279.0711 303.13 310.81 327.451 2.57 3.74 6.40模型(5) 2 16.06 18.17 23.46 μ1≠ 0, μ2≠ 0, δ1≠ 0, δ2≠ 0 3 31.42 34.55 40.49协整空间中有常数项、有线性趋势项。