java长连接的实现
淘宝消息服务使用介绍

消息服务使用介绍更新时间:2016/03/24 访问次数:229642∙From淘宝消息服务使用∙To淘宝消息服务使用∙常用消息类型说明∙沙箱消息服务开通∙消息服务常见问题消息服务是开放平台为提高应用API调用效率而推出的一种主动推送服务(From淘宝),推送内容包括(淘宝交易、商品、退款等信息),基于该推送服务,应用获取淘宝数据不需再不停轮询API,仅需在接收到淘宝推送的消息时调用API获取即可,大大提高API调用效率和降低API使用费用。
同时还提供消息回流服务(To淘宝),应用可将信息回流到淘宝,做商品数源服务等。
From淘宝:即淘宝向外推送淘宝(包括天猫)的交易、商品、退款等官方消息。
To淘宝:即向淘宝回流消息。
那么如何使用消息服务呢?请看以下是消息服务From淘宝和To淘宝两种方式的详细使用说明。
From淘宝消息服务使用应用订阅消息进入ISV控制台,在“应用管理->消息服务->订阅消息”页面,选择需要的消息进行订阅,点击相应消息后面的“订阅”即可订阅消息成功,可以在“我的订阅”中查看已经成功订阅的消息。
如果需要取消消息的订阅,直接点击“取消订阅”。
点击消息名称可以查看每个消息返回的详细字段信息。
注意:如果该消息没有权限,则说明应用未开通相关API调用权限,通过点击“申请权限”,进入申请相应的权限包。
另如果需要在沙箱开通消息服务使用,可参照本文的[沙箱消息服务开通]章节给用户开通消息调用er.permit接口给用户(即淘宝或天猫商家)开通,可以选择只给用户开通部分消息类型,也可全部开通。
具体可看该API 入参说明。
备注:∙给用户开通消息前提是用户已经给应用授权,如未授权,请参考获取用户授权说明。
∙取消用户的消息服务调用er.cancel接口。
∙可以通过接口er.get获取用户已开通消息,入参必须输入is_valid,topics,modified来判断用户授权消息是否成功∙消息服务API文档:点击这里查看代码实现接收消息正式环境服务地址:ws:///沙箱环境服务地址:ws:///接收消息,实现方式有两种:通过SDK接收消息、通过API接收消息,推荐采用SDK接收消息。
java通过发送json,post请求,返回json数据的方法

java通过发送json,post请求,返回json数据的⽅法实例如下所⽰:import java.io.BufferedReader;import java.io.DataOutputStream;import java.io.InputStream;import java.io.InputStreamReader;import java.io.OutputStream;import .HttpURLConnection;import .URL;import org.json.JSONArray;import org.json.JSONObject;public class GetJsonData {public static String getJsonData(JSONObject jsonParam,String urls) {StringBuffer sb=new StringBuffer();try {;// 创建url资源URL url = new URL(urls);// 建⽴http连接HttpURLConnection conn = (HttpURLConnection) url.openConnection();// 设置允许输出conn.setDoOutput(true);// 设置允许输⼊conn.setDoInput(true);// 设置不⽤缓存conn.setUseCaches(false);// 设置传递⽅式conn.setRequestMethod("POST");// 设置维持长连接conn.setRequestProperty("Connection", "Keep-Alive");// 设置⽂件字符集:conn.setRequestProperty("Charset", "UTF-8");// 转换为字节数组byte[] data = (jsonParam.toString()).getBytes();// 设置⽂件长度conn.setRequestProperty("Content-Length", String.valueOf(data.length));// 设置⽂件类型:conn.setRequestProperty("contentType", "application/json");// 开始连接请求conn.connect();OutputStream out = new DataOutputStream(conn.getOutputStream()) ;// 写⼊请求的字符串out.write((jsonParam.toString()).getBytes());out.flush();out.close();System.out.println(conn.getResponseCode());// 请求返回的状态if (HttpURLConnection.HTTP_OK == conn.getResponseCode(){System.out.println("连接成功");// 请求返回的数据InputStream in1 = conn.getInputStream();try {String readLine=new String();BufferedReader responseReader=new BufferedReader(new InputStreamReader(in1,"UTF-8"));while((readLine=responseReader.readLine())!=null){sb.append(readLine).append("\n");}responseReader.close();System.out.println(sb.toString());} catch (Exception e1) {e1.printStackTrace();}} else {System.out.println("error++");}} catch (Exception e) {}return sb.toString();}public static void main(String[] args) {JSONObject jsonParam = new JSONObject();jsonParam.put("id", "1401_1406");jsonParam.put("device_size", "480x720");String url="";String data=GetJsonData.getJsonData(jsonParam,url);//返回的是⼀个[{}]格式的字符串时:JSONArray jsonArray = new JSONArray(data);//返回的是⼀个{}格式的字符串时:/*JSONObject obj= new JSONObject(data);*/}}以上这篇java 通过发送json,post请求,返回json数据的⽅法就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
dubbo中的各种协议

Dubbo各种协议协议参考手册dubbo://1.<dubbo:protocol name="dubbo" port="20880"/> Set default protocol:1.<dubbo:provider protocol="dubbo"/>Set service protocol:1.<dubbo:service protocol="dubbo"/>Multi port:1.<dubbo:protocol id="dubbo1" name="dubbo" port="20880"/>2.<dubbo:protocol id="dubbo2" name="dubbo" port="20881"/>Dubbo protocol options:1.<dubbo:protocol name=“dubbo”port=“9090”server=“netty”client=“netty” codec=“dubbo”serialization=“hessian2”charset=“UTF-8”threadpool=“fixed” threads =“100”queues=“0”iothreads=“9”buffer=“8192”accepts=“1000”payload=“838860 8” />∙Transportero mina, netty, grizzy∙Serializationo dubbo, hessian2, java, json∙Dispatchero all, direct, message, execution, connection∙ThreadPoolo fixed, cached∙<dubbo:protocol name="dubbo"connections="2"/><dubbo:service connections=”0”>或<dubbo:reference connections=”0”>表示该服务使用JVM共享长连接。
Android端i-jetty服务器开发

一、i-jetty简介介绍:A port of the popular Jetty open-source web container to run on the Android mobile device platform.Having a "personal" webserver on your phone opens up a world of possibilities, letting you run your favourite existing webapps in your mobile environment.Moreover, as webapps developed for i-jetty have access to the Android API, this means that you can bring the contents of your mobile phone to your normal desktop browser.To demonstrate the possibilities, we've created a "Console" webapp that interfaces to the data on your mobile device. You don't need any special software to synchronize the mobile data to your desktop computer - the i-jetty console webapp makes your on-phone info like contacts lists, call logs and media instantly available and manageable via your browser. We've packaged the Console webapp as an Android application so it can be conveniently downloaded and updated via the Android Marketplace.i-jetty can also dynamically download webapps from anywhere on the net. To help get you started, we've also created a "Hello World" webapp that is simpler than the Console webapp. You can either build it from src and install it locally, or you can point i-jetty to the pre-built hello.war on the download page.The apks for i-jetty and the i-jetty Console webapp are both available from the Android Marketplace, and also from the download page.翻译:Jetty是一款运行在Android平台的并且流行的web服务器,为在手机上实现个人web服务的世界提供了可能,可以让您在手机环境中运行存在的web应用程序。
【狂神说Java】JavaWeb入门到实战1---笔记

【狂神说Java】JavaWeb⼊门到实战1---笔记转⾃:⽂章⽬录1、基本概念1.1、前⾔1.2、web应⽤程序web应⽤程序:1.3、静态web1.4、动态web2、web服务器2.1、技术讲解2.2、web服务器3、Tomcat3.1安装tomcat tomcat3.2、Tomcat启动和配置3.3、配置3.4、发布⼀个web⽹站4、Http4.1、什么是HTTPHTTP4.2、两个时代4.3、Http请求1、请求⾏2、消息头4.4、Http响应1、响应体2、响应状态码5、Maven5.1 Maven项⽬架构管理⼯具5.2下载安装Maven5.3配置环境变量5.4阿⾥云镜像5.5本地仓库5.6 ~ 5.13笔记-下载地址6、Servlet6.1、Servlet简介6.2、HelloServlet6.2、HelloServlet6.3、Servlet原理6.4、Mapping问题6.5、ServletContext1、共享数据2、获取初始化参数3、请求转发6.6、HttpServletResponse1、简单分类2、下载⽂件3、验证码功能6.7、HttpServletRequest获取参数,请求转发7、Cookie、Session7.1、会话7.2、保存会话的两种技术7.3、Cookie7.4、Session(重点)8、JSP8.1、什么是JSP8.2、JSP原理8.3、JSP基础语法JSP表达式jsp脚本⽚段JSP声明8.4、JSP指令8.5、9⼤内置对象8.6、JSP标签、JSTL标签、EL表达式9、JavaBean10、MVC三层架构10.1、以前的架构10.2、MVC三层架构11、Filter (重点)12、监听器13、过滤器、监听器常见应⽤14、JDBC15、SMBMS(超市管理项⽬)1、基本概念1.1、前⾔web开发:web,⽹页的意思,·静态webhtml,sss提供给所有⼈看的数据始终不会发⽣变化!动态web淘宝,⼏乎是所有的⽹站;提供给所有⼈看的数据始终会发⽣变化,每个⼈在不同的时间,不同的地点看到的信息各不相同!技术栈:Servlet/ISP,ASP,PHP1.2、web应⽤程序web应⽤程序:可以提供浏览器访问的程序;a.html、b.html.….多个web资源,这些web资源可以被外界访问,对外界提供服务;你们能访问到的任何⼀个页⾯或者资源,都存在于这个世界的某⼀个⾓落的计算机上。
Apollo配置中心
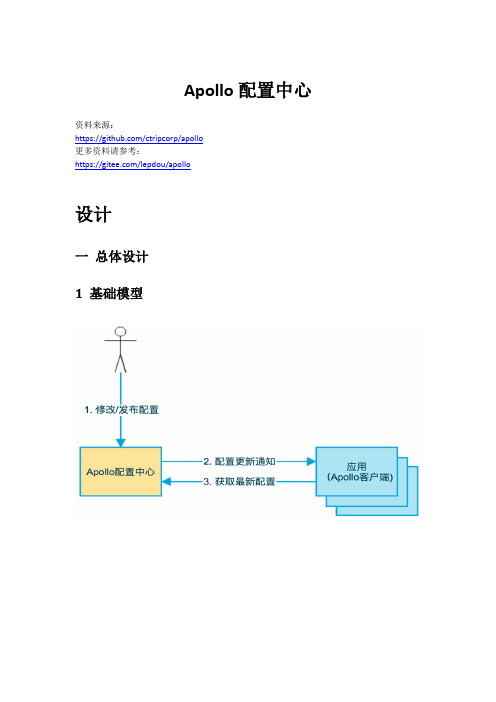
Apollo配置中心资料来源:https:///ctripcorp/apollo更多资料请参考:https:///lepdou/apollo设计一总体设计1 基础模型2 架构模块3 各模块概要介绍1 Config Service•提供配置获取接口•提供配置更新推送接口(基于Http long polling)o服务端使用Spring DeferredResult实现异步化,从而大大增加长连接数量o目前使用的tomcat embed默认配置是最多10000个连接(可以调整),使用了4C8G的虚拟机实测可以支撑10000个连接,所以满足需求(一个应用实例只会发起一个长连接)。
•接口服务对象为Apollo客户端2 Admin Service•提供配置管理接口•提供配置修改、发布等接口•接口服务对象为Portal3 Meta Server•Portal通过域名访问Meta Server获取Admin Service服务列表(IP+Port)•Client通过域名访问Meta Server获取Config Service服务列表(IP+Port)•Meta Server从Eureka获取Config Service和Admin Service的服务信息,相当于是一个Eureka Client•增设一个Meta Server的角色主要是为了封装服务发现的细节,对Portal和Client而言,永远通过一个Http接口获取Admin Service和Config Service的服务信息,而不需要关心背后实际的服务注册和发现组件•Meta Server只是一个逻辑角色,在部署时和Config Service是在一个JVM进程中的4 Eureka•基于Eureka和Spring Cloud Netflix提供服务注册和发现•Config Service和Admin Service会向Eureka注册服务,并保持心跳•为了简单起见,目前Eureka在部署时和Config Service是在一个JVM进程中的(通过Spring Cloud Netflix)5 Portal•提供Web界面供用户管理配置•通过Meta Server获取Admin Service服务列表(IP+Port),通过IP+Port访问服务•在Portal侧做load balance、错误重试6 Client•Apollo提供的客户端程序,为应用提供配置获取、实时更新等功能•通过Meta Server获取Config Service服务列表(IP+Port),通过IP+Port访问服务•在Client侧做load balance、错误重试二、服务端设计1 配置发布后的实时推送设计在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。
Java ResultSet导出大数据
众所周知,java在处理数据量比较大的时候,加载到内存必然会导致内存溢出,而在一些数据处理中我们不得不去处理海量数据,在做数据处理中,我们常见的手段是分解,压缩,并行,临时文件等方法;例如,我们要将数据库(不论是什么数据库)的数据导出到一个文件,一般是Excel或文本格式的CSV;对于Excel来讲,对于POI和JXL的接口,你很多时候没有办法去控制内存什么时候向磁盘写入,很恶心,而且这些API在内存构造的对象大小将比数据原有的大小要大很多倍数,所以你不得不去拆分Excel,还好,POI 开始意识到这个问题,在 3.8.4的版本后,开始提供cache的行数,提供了SXSSFWorkbook的接口,可以设置在内存中的行数,不过可惜的是,他当你超过这个行数,每添加一行,它就将相对行数前面的一行写入磁盘(如你设置2000行的话,当你写第20001行的时候,他会将第一行写入磁盘),其实这个时候他些的临时文件,以至于不消耗内存,不过这样你会发现,刷磁盘的频率会非常高,我们的确不想这样,因为我们想让他达到一个范围一次性将数据刷如磁盘,比如一次刷1M 之类的做法,可惜现在还没有这种API,很痛苦,我自己做过测试,通过写小的Excel比使用目前提供刷磁盘的API来写大文件,效率要高一些,而且这样如果访问的人稍微多一些磁盘IO可能会扛不住,因为IO资源是非常有限的,所以还是拆文件才是上策;而当我们写CSV,也就是文本类型的文件,我们很多时候是可以自己控制的,不过你不要用CSV自己提供的API,也是不太可控的,CSV本身就是文本文件,你按照文本格式写入即可被CSV识别出来;如何写入呢?下面来说说。
在处理数据层面,如从数据库中读取数据,生成本地文件,写代码为了方便,我们未必要1M怎么来处理,这个交给底层的驱动程序去拆分,对于我们的程序来讲我们认为它是连续写即可;我们比如想将一个1000W数据的数据库表,导出到文件;此时,你要么进行分页,oracle当然用三层包装即可,mysql用limit,不过分页每次都会新的查询,而且随着翻页,会越来越慢,其实我们想拿到一个句柄,然后向下游动,编译一部分数据(如10000行)将写文件一次(写文件细节不多说了,这个是最基本的),需要注意的时候每次buffer的数据,在用outputstream写入的时候,最好flush一下,将缓冲区清空下;接下来,执行一个没有where条件的SQL,会不会将内存撑爆?是的,这个问题我们值得去思考下,通过API发现可以对SQL进行一些操作,例如,通过:PreparedStatement statement =connection.prepareStatement(sql),这是默认得到的预编译,还可以通过设置:PreparedStatement statement = connection.prepareStatement(sql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);来设置游标的方式,以至于游标不是将数据直接cache到本地内存,然后通过设置statement.setFetchSize(200);设置游标每次遍历的大小;OK,这个其实我用过,oracle用了和没用没区别,因为oracle的jdbc API默认就是不会将数据cache到java 的内存中的,而mysql里头设置根本无效,我上面说了一堆废话,呵呵,我只是想说,java提供的标准API也未必有效,很多时候要看厂商的实现机制,还有这个设置是很多网上说有效的,但是这纯属抄袭;对于oracle上面说了不用关心,他本身就不是cache到内存,所以java内存不会导致什么问题,如果是mysql,首先必须使用5以上的版本,然后在连接参数上加上useCursorFetch=true这个参数,至于游标大小可以通过连接参数上加上:defaultFetchSize=1000来设置,例如:jdbc:mysql://xxx.xxx.xxx.xxx:3306 /abc?zeroDateTimeconvertToNull&useCursorFetch=true& defaultFetchSize=1000< /span>上次被这个问题纠结了很久(mysql的数据老导致程序内存膨胀,并行2个直接系统就宕了),还去看了很多源码才发现奇迹竟然在这里,最后经过mysql文档的确认,然后进行测试,并行多个,而且数据量都是500W以上的,都不会导致内存膨胀,GC一切正常,这个问题终于完结了。
Websocket协议(一)Websocket协议简述
Websocket协议(⼀)Websocket协议简述⽬的:即时通讯,替代轮询应⽤场景:⽹站上的即时通讯是很常见的,⽐如⽹页的QQ,聊天系统等。
按照以往的技术能⼒通常是采⽤轮询、Comet技术解决。
HTTP协议是⾮持久化的,单向的⽹络协议,在建⽴连接后只允许浏览器向服务器发出请求后,服务器才能返回相应的数据。
当需要即时通讯时,通过轮询在特定的时间间隔(如1秒),由浏览器向服务器发送Request请求,然后将最新的数据返回给浏览器。
这样的⽅法最明显的缺点就是需要不断的发送请求,⽽且通常HTTP request的Header是⾮常长的,为了传输⼀个很⼩的数据需要付出巨⼤的代价,是很不合算的,占⽤了很多的宽带。
缺点:会导致过多不必要的请求,浪费流量和服务器资源,每⼀次请求、应答,都浪费了⼀定流量在相同的头部信息上然⽽WebSocket的出现可以弥补这⼀缺点。
在WebSocket中,只需要服务器和浏览器通过HTTP协议进⾏⼀个握⼿的动作,然后单独建⽴⼀条TCP的通信通道进⾏数据的传送。
原理:WebSocket同HTTP⼀样也是应⽤层的协议,但是它是⼀种双向通信协议,是建⽴在TCP之上的。
连接过程 —— 握⼿过程1. 浏览器、服务器建⽴TCP连接,三次握⼿。
这是通信的基础,传输控制层,若失败后续都不执⾏。
2. TCP连接成功后,浏览器通过HTTP协议向服务器传送WebSocket⽀持的版本号等信息。
(开始前的HTTP握⼿)3. 服务器收到客户端的握⼿请求后,同样采⽤HTTP协议回馈数据。
4. 当收到了连接成功的消息后,通过TCP通道进⾏传输通信。
WebSocket与HTTP的关系相同点都是⼀样基于TCP的,都是可靠性传输协议。
都是应⽤层协议。
不同点WebSocket是双向通信协议,模拟Socket协议,可以双向发送或接受信息。
HTTP是单向的。
WebSocket是需要握⼿进⾏建⽴连接的。
联系WebSocket在建⽴握⼿时,数据是通过HTTP传输的。
Java面试——RPC
Java⾯试——RPC⼀、RPC 服务的原理●第1步:客户端调⽤本地的客户端存根⽅法(client stub)。
客户端存根的⽅法会将参数打包并封装成⼀个或多个⽹络消息体并发送到服务端。
将参数封装到⽹络消息中的过程被称为编程(encode),它会将所有数据序列化为字节数组格式。
●第2步:客户端存根(client stub)通过系统调⽤,使⽤操作系统内核提供的 Socket 套接字接⼝来向远程服务发送我们编码的⽹络消息。
●第3步:⽹络消息由内核通过某种协议(⽆连接协议:UDP,⾯向连接协议:TCP)传输到远程服务端。
●第4步:服务端存根(server stub)接受客户端发送的消息,并对参数消息进⾏解码(decode),通常它会将参数从标准的⽹络格式转化成特定的语⾔格式。
●第5步:服务端存根调⽤服务端,并将从客户端接收的参数传递给该⽅法,它来运⾏具体的功能并返回,对客户端来说这部分代码的执⾏就是远程过程调⽤。
●第6步:将返回值返回到服务端存根代码中。
●第7步:服务端存根在将该返回值进⾏编码并序列化后,通过⼀个或多个⽹络消息发送给客户端。
●第8步:消息通过⽹络发送到客户端存根中。
●第9步:客户端存根从本地 Socket 接⼝中读取结果消息。
●第10步:客户端存根再将结果返回给客户端函数,并且消息从⽹络⼆进制形式转化成本低语⾔格式,这样就完成了远程服务调⽤。
⼆、gRPC 你了解多少gRPC 是⾕歌旗下的⼀款 RPC 框架,基于 HTTP/2 协议标准,使⽤ ProtoBuf 作为序列化⼯具和接⼝定义语⾔(IDL),⽀持多语⾔开发。
使⽤ gRPC后,客户端应⽤就像调⽤本地对象⼀样直接调⽤另⼀台机器上服务端的⽅法,使我们能够更容易地创建分布式应⽤和服务。
gRPC 和其它 RPC框架类似,也通过定义⼀个服务接⼝并指定其能够被远程调⽤的⽅法,然后在服务端实现这个接⼝,并运⾏ gRPC服务器来处理客户端调⽤。
在客户端拥有⼀个存根,该存根提供了和服务端相同的⽅法。
Socket心跳包机制总结【转】
Socket⼼跳包机制总结【转】转⾃:跳包之所以叫⼼跳包是因为:它像⼼跳⼀样每隔固定时间发⼀次,以此来告诉服务器,这个客户端还活着。
事实上这是为了保持长连接,⾄于这个包的内容,是没有什么特别规定的,不过⼀般都是很⼩的包,或者只包含包头的⼀个空包。
在TCP的机制⾥⾯,本⾝是存在有⼼跳包的机制的,也就是TCP的选项:SO_KEEPALIVE。
系统默认是设置的2⼩时的⼼跳频率。
但是它检查不到机器断电、⽹线拔出、防⽕墙这些断线。
⽽且逻辑层处理断线可能也不是那么好处理。
⼀般,如果只是⽤于保活还是可以的。
⼼跳包⼀般来说都是在逻辑层发送空的echo包来实现的。
下⼀个定时器,在⼀定时间间隔下发送⼀个空包给客户端,然后客户端反馈⼀个同样的空包回来,服务器如果在⼀定时间内收不到客户端发送过来的反馈包,那就只有认定说掉线了。
其实,要判定掉线,只需要send或者recv⼀下,如果结果为零,则为掉线。
但是,在长连接下,有可能很长⼀段时间都没有数据往来。
理论上说,这个连接是⼀直保持连接的,但是实际情况中,如果中间节点出现什么故障是难以知道的。
更要命的是,有的节点(防⽕墙)会⾃动把⼀定时间之内没有数据交互的连接给断掉。
在这个时候,就需要我们的⼼跳包了,⽤于维持长连接,保活。
在获知了断线之后,服务器逻辑可能需要做⼀些事情,⽐如断线后的数据清理呀,重新连接呀……当然,这个⾃然是要由逻辑层根据需求去做了。
总的来说,⼼跳包主要也就是⽤于长连接的保活和断线处理。
⼀般的应⽤下,判定时间在30-40秒⽐较不错。
如果实在要求⾼,那就在6-9秒。
⼼跳检测步骤:1 客户端每隔⼀个时间间隔发⽣⼀个探测包给服务器2 客户端发包时启动⼀个超时定时器3 服务器端接收到检测包,应该回应⼀个包4 如果客户机收到服务器的应答包,则说明服务器正常,删除超时定时器5 如果客户端的超时定时器超时,依然没有收到应答包,则说明服务器挂了很多⼈会⽤boolean socketFlag = socket.isConnected() && socket.isClosed()来判断就⾏了,但事实上这些⽅法都是访问socket在内存驻留的状态,当socket 和服务器端建⽴链接后,即使socket链接断掉了,调⽤上⾯的⽅法返回的仍然是链接时的状态,⽽不是socket的实时链接状态,所以这样⼼跳⽤这个不靠谱,下⾯给出例⼦证明这⼀点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
梁应宏 引言 TCP长连接服务在传统的智能网应用中扮演着重要的角色。由于其传输的高效率,在智能网SCP和IP的各个模块之间,大量使用了这种服务。例如,SS7gateway与SCF、SCF与INES、INES与外部节点、CN与VN,等等。
相反,在各种WEB应用中,广泛使用TCP短连接服务。基于HTTP承载的各种应用协议,如HTML,XML,SOAP等,多数使用TCP短连接服务。原因有二:一是这些HTTP协议的数据包较大,传输所占的开销较大,连接建立的开销相对较小。此时使用长连接对性能的提升并不明显。二是相对于长连接而言,无论是对于客户端还是服务端,短连接的实现难度要低很多。
以网通水平业务平台SPGW为例,多数对外接口采用HTTP/XML/SOAP协议和短连接。然而,出于性能的考虑,还有两个接口采用TCP长连接:
l 东向接口(SPGW-DSMP):SCCP协议使用二进制消息。 l 南向接口(SPGW-SMSC):SPGW与短消息网关SMSC之间的SM7协议使用二进制消息。
从Java开发语言的角度,短连接的使用比较简单。因为Java的IO库已经提供了一个httpConnection类,成熟可靠,使用方便。但是,对于TCP长连接的使用,Java的IO库并没有直接的支持。本文将探讨对TCP长连接服务的一般需求和我们的实现考虑。
以下也简称TCP长连接服务为TCP服务。 需求 具有网络编程经验的人都知道,TCP程序的编写是“易学难精”。很容易编写一个TCP程序,具有一定的功能并且在少数正常情况下可以运行。但是,要想让它在各种网络条件、各种负荷情况下都能稳定运行,却不是一件简单的工作。具体说来,TCP长连接服务需要满足以下条件:
高性能 实现这一点的关键是,消息的接收操作必须是异步的。以SPGW与短信网关之间的消息流程为例,如下:
如上图所示,SPGW可以不等待上一消息的应答消息,就发送下一个短消息。因此在同一个TCP connection上,SM7消息的接收必须是异步的,否则就会阻塞后续消息的发送。
健壮性 健壮性要求,TCP长连接服务不仅要能适应良好的网络情况和低负荷,而且要能适应差的网络情况和高负荷。实现这一点需要做到: l 应用级心跳:自动检测网络故障。 l 应用级重连:自动排除网络故障。 l 请求分发:需要将请求消息分发到消息队列或者独立的线程中,以免阻塞接收线程的工作。
l 统计与管理:可以查询统计TCP服务模块的工作情况。也可以通过某种标准的网络管理协议(如SNMP)来控制TCP连接的状态,如打开或者关闭。
应用友好性 l 同步的响应消息接收API:尽管TCP服务内部对消息的接收是异步的,但是,它需要向应用模块提供同步的响应消息接收API,以简化应用模块的开发。
l 明确的双向接口:一般的服务包只需要提供单向的API接口,由应用模块调用。但是,TCP服务包不同,除了被应用模块调用外,它还要对应用模块进行回调。例如,当接收到消息时,需要回调应用模块的方法,对消息进行定界和分发;在进行心跳检测时,需要回调应用模块的编解码方法。因此需要明确地定义TCP模块和应用模块之间的双向接口。
传统的实现方式 在我们以往的程序实现中,一般都是采用单connection,异步消息收发的方式。
Extra Node
Application
Main Thread
Transceive Thread
Message Queue
整个系统的逻辑结构大致如上。Application一般分为Main和Transceive两个线程。前者用于完成应用的逻辑,后者完成消息的收发。它们之间通过一个共享的Message Queue来通信。二者的流程使用伪码表示如下:
Main Thread: while(true) 从Message Queue取输入消息 处理该消息(中间可能产生输出消息送到Message Queue)
Transceive Thread: while(true) if(connection 可写) 从Message Queue取输出消息 将该消息写到connection if(connection 可读) 从connection读输入消息 将该消息送到Message Queue 对于Transceive Thread,判断connection是否可读写,是为了避免阻塞。这是通过socket API的select函数来完成的。
在实际的实现中,由于C语言的多线程存在移植性问题,以上两个线程一般合为一个: Single Thread: while(true) 执行Main Thread的操作 执行Transceive Thread的操作
优点 以上方式的优点是非常高效,这已经为我们以前的系统的性能表现所证明。
缺点 以上方式的缺点是Main Thread的编写比较麻烦。因为没有同步的消息接收API,我们需要使用FSM之类的机制将多条消息关联起来。当一条消息发出后,需要设置FSM实例的状态和定时器。当回应消息收到时,将回应消息投递到对应的FSM实例进行处理。使用FSM机制进行开发,对于一般的应用还是太复杂了。
另外,传统的实现方式不好解决TCP服务回调应用协议功能的问题,往往将应用协议的部分功能(如定界、编解码)集成到TCP模块中。结果随着应用协议类型的增加,TCP模块变得越来越臃肿和复杂。出现这一问题的部分原因是,与Java不同,C/C++语言不存在Interface(接口)这种语言结构,用于明确地定义两个模块之间的调用接口。
Java实现 功能与结构 TCP服务模块的功能是:
1. 消息收发功能:提供了两个发送API: l sendRecv:发送请求消息,并且同步等待响应消息。 l send:发送消息并立即返回。用于无需等待响应消息的场合。 2. 心跳功能:通过设置心跳属性,如心跳模式、心跳间隔、是否发送心跳、是否显示心跳等,TCP模块自动执行心跳检查。
3. 重连功能:对于Tcp客户端,通过设置重连属性,如是否重连,重连间隔等,TCP模块在连接断开后,自动执行重连操作。
4. 请求分发:将请求消息分发到独立的线程中,并自动调用应用模块的方法进行处理。
5. 统计与管理:可以查询统计TCP服务模块的工作情况。也可以通过SNMP和JMX来控制TCP连接的状态,如打开或者关闭。
线程分配 为了同时满足高性能和易用性的要求,TCP模块充分利用了Java语言对多线程的良好支持。它包括如下线程:
HeartBeat thread S
Tcp服务模块
S
Recv thread
S
App 模块
S
Send thread1
S
Send thread2
S
Process request thread3
S
sendRecv
S
send
S
processRequest
S
Reconnect thread
S
Send thread:发送线程就是应用线程。也就是说,TCP模块在应用线程中完成发送操作。 Recv thread:每个TCP连接都启动一个接收线程,用于接收来自对端的消息。 HeartBeat thread:每个TCP连接都启动心跳线程,用于定期向对端发送心跳消息,并检查是否及时收到响应。
Reconnect thread:TCP模块启动一个重连线程,用于定期检查连接的状态,并试图重连关闭的连接。
Process request thread:请求处理线程是应用线程。当接收线程收到一个请求消息,它会启动一个请求处理线程,将请求消息投递给该线程进行处理。
接口 下面简要列出TCP模块提供给应用模块的ITcpService接口:
l 打开连接:open(String ip, int port) l 关闭连接:void close() l 发送数据包:void send(byte[] data) l 发送数据包并等待响应:byte[] sendRecv(byte[] data, int timeout) l 设置应用协议接口:void setTcpMessage(ITcpMessage tcpMessage); 下面简要列出应用模块提供给TCP模块的ITcpMessage接口: l 判断给定的消息是否为请求消息:boolean isRequest(byte[] data) l 判断给定的消息是否为心跳消息:boolean isHeartBeat(byte[] data) l 判断给定的消息是否有效:boolean isValid(byte[] data) l 取消息的长度:int getLength(byte[] data) l 获取给定的消息的Key(消息的Key用于关联一对请求和响应):String getKey(byte[] data)
l 编码心跳请求消息:byte[] EncodeHeartBeatRequest() l 编码心跳响应消息:byte[] EncodeHeartBeatResponse(byte[] request);