10.第十章计量经济学
第十章定性选择模型(计量经济学,潘省初)

1 F[(0 j Xij )] j 1
其中F是u的累积散布函数。 假设u的散布是对称的,那么1 F (z) F (z) ,我 们可以将上式写成
k
Pi F (0 j X ij ) j 1
(10.9)
我们可写出似然函数:
L Pi (1 Pi ) Yi 1 Yi 0
(10.10)
假设只要两个选择,我们可用0和1 区分表示它们, 如乘公交为0,自驾车为1,这样的模型称为二元选择 模型〔binary choice Models〕,多于两个选择〔如下 班方式加上一种骑自行车〕的定性选择模型称为多项 选择模型〔Multinomial choice models〕。
第一节 线性概率模型
概率=F(Z)
1
Probit模型
线性概率模型
0
Z
图10-1 线性概率模型和Probit模型
虽然Probit模型实践是非线性的,但它可以以一 种相似于其他经济模型的方式写出。首先,我们需求 将等式〔10.12〕稍微改写一下,它代表由累积正态 概率函数执行的变换:
第二节 Probit模型和Logit模型
一.Probit和Logit方法概要
估量二元选择模型的另一类方法假定回归模
Yi* 0 k j X ij 型 u为i
(10.7)
j 1
Yi*
这里 不可观测,通常称为潜变量〔latent variYaible〕10 。若我其Y们i*它能0观测到(的10是.8)虚拟变量:
AGE的斜率估量值也在1%的水平上清楚。在支出和 性别不变的状况下,年龄添加1岁,选择候选人甲的概 率添加0.016。MALE的斜率系数统计上不清楚,因此 没有证听说明样本中男人和女人的选票不同。
我们可以得出如下结论:年轻一些、富有一些的选
第10章 向量自回归模型 《计量经济学》PPT课件

VAR的发展
发生于20世纪70年代,以卢卡斯(E.Lucas)、萨金特 (J.Sargent)、西姆斯(A.Sims)等为代表的对经典计 量经济学的批判,其后果之一是导致计量经济学模型 由经济理论导向转向数据关系导向。
阶差分项的滞后,即VEC模型是两阶滞后约束的VAR模
型 。为了估计没有一阶差分项的VEC模型,指定滞后的
形式为:“0 0”。
144
③ 对VEC模型常数和趋势的说明在Cointegration栏 (下图)。必须从5个趋势假设说明中选择一个,也必 须在适当的编辑框中填入协整关系的个数,应该是一个 小于VEC模型中内生变量个数的正数。
脉冲响应函数描述的是VAR模型中的一个内生变量 的冲击给其他内生变量所带来的影响。而方差分解(variance decomposition)是通过分析每一个结构冲击对内生变量变化 (通常用方差来度量)的贡献度,进一步评价不同结构冲击的 重要性。因此,方差分解给出对VAR模型中的变量产生影响的 每个随机扰动的相对重要性的信息。
前r个变量作为剩余k r个变量的函数,其中r表示协整关
系数,k是VEC模型中内生变量的个数。 第二部分输出是在第一步之后以误差修正项作为回归
量 的 一 阶 差 分 的 VAR 模 型 。 误 差 修 正 项 以 CointEq1, CointEq2,……表示形式输出。输出形式与无约束的VAR 输出形式相同,将不再赘述。
12 22
(1) (1)
yt zt
+n-1
+n-1
...
11 21
(n (n
1) 1)
12 22
(n (n
计量经济学课程第10章(离散选择模型)

Yi 0 1X i 2Di i
(10.1.1)
如果我们假定模型(10.1.1)中随机误差项εi的条件 期望为0,则男、女收入的总体回归函数可表示 为:
E
E (Yi
(Yi Di
Di 0, Xi )
1, Xi ) (0
0 1X i 2 ) 1Xi
1、误差项ε不服从正态分布 在 取 εi服线 值从0性或贝概1努,率ε里i服模分从型布正中态。,分误布差的项假εi和定Y就i一不样成,立只。 在小样本下,不能使用通常的t统计量和F
统计量对(10.2.1)的OLS估计量进行统计推 断,但在大样本下,仍可沿用正态性假定 下的方法。
2、线性概率模型的误差项εi也不满足同方 差的假定
三. 使用虚拟变量检验模型的稳定性
以城乡居民储蓄存款余额代表居民储蓄(S),以 GDP代表居民收入。
我们以1990年为分割点设定虚拟变量: Dt=1(1990年以前),Dt=0(1990年以后)
设定储蓄函数回归模型:
St 0 1Dt 2GDPt 3Dt GDP t (10.1.5
若将模型中的截距项去掉,如果定性虚拟 变量含有m个分类,则在模型中应引入m个 虚拟变量。
例10-1下面以我国2000-2007年季度GDP数 据为例来说明虚拟变量如何度量截距的变 化,图10.1是关于GDP的序列图 。
图10.1.1 GDP序列图
结合数据特征,我们首先定义季度虚拟变量。
1 (第二季度)
蓄函数的斜率系数发生结构变化;如果估计的β1,
β3联合不为零,则表明储蓄函数的截距和斜率都
发生结构变化。
可以使用通常的t统计量检验单个回归系数 β1或β3的显著性,而对于β1,β3的联合显著 性,则使用通常受约束的F统计量。模型 (10.1.5)的估计结果如下:
高级计量经济学 第十章 消费行为模型[精]
![高级计量经济学 第十章 消费行为模型[精]](https://img.taocdn.com/s3/m/22d3ef2ab7360b4c2e3f645e.png)
边际消费倾向满足0<<1 Ct=+Yt+ut
相对收入假说
消费水平不仅受消费者当前收入水平的影响,还受其 过去最高收入水平的影响。
Ct=+1Yt+ 2Ytmax+ut 当收入呈现稳定增长趋势时,可能会有Ytmax=Yt-1。
3
宏观消费函数:理论基础
?支出弹性??????bpj??ap2lnlnnijijjkkijkmmp????????????????????????????????????????????????i????????10ijij?????????????bp??ap12?1lniiiimw????????????????分层消费模型弹性计算?前面给出的计算公式针对不分层的模型可以看作是有条件弹性取决于类支出计算基于总消费支出的无条件弹性需要做必要的假定
CPt=YPt+ut
YP可以用现期和过去收入的加权平均值来表示,过去收入的效应 随时间推移而逐步减小到零。
Ct=+tYt+ut
4
宏观消费函数:理论基础
相对收入假说和持久收入假说均可以用几何分布滞后模型 来反映:
Ct=+1Yt+ 2Ct-1+ut
对该模型也可以直接解释为,消费行为的变化非常缓慢,前期消 费行为和现期可支配收入共同影响现期消费行为。
局部均衡分析框架(假定该商品市场上发生的变化不 会影响到其他市场)
应用模型常常根据研究需要扩展进其他解释变量
持久收入(家庭资产) 政策干预(定量供给、补贴…) 人口学特征(年龄、教育、家庭人口构成…) 市场环境
15
单一商品需求模型:理论基础
第十章 计量经济学-模型设定.

对多元回归,非线性函数可能是关于若干个 或全部解释变量的非线性,这时可按遗漏变量的 程序进行检验。 例如,估计 Y=0+1X1+2X2+
但却怀疑真实的函数形式是非线性的。 这时,只需以估计出的Ŷ的若干次幂为“替代” 变量,进行类似于如下模型的估计
ˆ2 Y ˆ3 Y 0 1 X1 2 X 2 1Y 2
2.39 9.52
• 由所得系数可以看出,两种情况下均造成高估所保留变量的参数, 据此做分析可能导致得出错误的结论。 • 两个参数所处的区间应该分别为0 1 0.454 和 0 2 0.051
关于遗漏必要的解释变量的总结
• 遗漏必要的解释变量是一种严重的错误,必须 注意避免。 • 对别人的研究成果做评价时,是否存在遗漏必 要解释变量的错误是需要考察的最重要的一个 方面。
例如,先估计 Y=0+ 1X1+v 得 ˆ ˆ0 ˆ1 X 1 Y
ˆ2 Y ˆ3 Y 0 1 X 1 1Y 2
再根据增加解释变量的F检验来判断是否增加这 些“替代”变量。 若仅增加一个“替代”变量,也可通过t检验来 判断。
RESET检验也可用来检验函数形式设定偏误的 问题。
ˆ ) 2 Var( 1
ˆ1 ) Var(
2 x 1i
2
x
2 1i
x ( x1i x2i )
2 2i
x
2 2i
2
2 2 x ( 1 r 1i x1x2 )
2
如果X2与X1相关,显然有 如果X2与X1不相关,也有
ˆ) ˆ1 ) Var( Var( 1 ˆ) ˆ1 ) Var( Var( 1
计量经济学 詹姆斯斯托克 第10章 受约束回归

例1. 建立中国城镇居民食品消费需求函数模型。
根据需求理论,居民对食品的消费需求函数大致为
Q f ( X , P1 , P0 )
(*) Q:居民对食品的需求量,X:消费者的消费支出总额
P1:食品价格指数,P0:居民消费价格总指数。
零阶齐次性,当所有商品和消费者货币支出总额按同 一比例变动时,需求量保持不变
Y1 X1 Y 0 2 0 β μ 1 X 2 α μ 2
如果=,表示没有发生结构变化,因此可针对 如下假设进行检验:H0: =
施加上述约束后变换为受约束回归模型:
Y1 X 1 μ 1 β Y X μ 2 2 2
X:人均消费 X1:人均食 品消费 GP:居民消 费价格指数 FP:居民食品 消费价格指数 XC:人均消 费(90年价) Q:人均食品 消费(90年价) P0:居民消费 价格缩减指数 (1990=100) P:居民食品 消费价格缩减 指数 (1990=100
(当年价 ) (当年价 ) (上年 =100) (上年 =100)
Q f ( X / P0 , P1 / P0 )
(**)
为了进行比较,将同时估计(*)式与(**)式。
首先,确定具体的函数形式
根据恩格尔定律,居民对食品的消费支出与居 民的总支出间呈幂函数的变化关系:
Q AX
1
P1 2 P0 3
对数变换:
ln(Q ) 0 1 ln X 2 ln P1 3 ln P0
• 该检验也被称为邹氏参数稳定性检验(Chow test for parameter stability)。
2、邹氏预测检验
• 如果出现n2<k ,则往往进行如下的邹氏预测检
计量经济学第十章 时间序列计量经济模型

H0
第三步:对一阶差分序列作单位根检验得到序列的单整阶数 为了得到人均可支配收入(SR)序列的单整阶数,在单位根检 验(Unit Root Test)对话框(图10.3)中,指定对一阶差分序 列作单位根检验,选择带截距项(intercept),滞后差分项 (Lagged differences)选2阶,点击OK,得到估计结果,见表 10.5。
t(t T )
举例:
1、连续性随机过程:心电图,用 Y t 表示。
2、离散型随机过程:GDP,DPI等,用 Y1 , Y2 ,...,Yt 表示。记住,这 些Y中的每一个都是一个随机变量,而这些随机变量按时间编排形 成的集合就是一个随机过程。
讨论:如何理解GNP是一个随机过程呢?
理论上讲,某一年的GNP数字可能是任何一个数字,取决 于当时的政治与经济环境。某个数字只是所有这些可能性 中的一个特定的实现,也可以看成是某年GNP所有可能值 得均值。因此,我们可以说,GNP是一个随机过程,而我 们在某个时期期间所观测到的实际值只是这个过程的一个 特定实现(即样本)。与我们利用截面数据中的样本数据 对总体进行推断一样,在时间序列中,我们利用这些实现 对其背后的随机过程加以推断。
-0.7791体现了对偏离的修正,上一期偏离越远,本 期修正的量就越大,即系统存在误差修正机制。
第十章 时间序列计量经济模型
本章主要讨论:
时间序列的基本概念
时间序列平稳性的单位根检验 协整
第一节 时间序列基本概念
本节基本内容:
●伪回归问题 ●随机过程的概念 ●时间序列的平稳性
一、伪回归问题
传统计量经济学模型的假定条件:序列的平稳性、正态性。
所谓“伪回归”,是指变量间本来不存在相依关系,但回归 结果却得出存在相依关系的错误结论。即表现在:两个本来没 有任何因果关系的变量,却有很高的相关性(有较高的R2)。 例如:用美国人口数和中国GDP回归,也可能会得到很高的 可决系数。 20世纪70年代,Grange、Newbold 研究发现,造成“伪回归” 的根本原因在于时序序列变量的.,Ytn
习题答案计量经济学
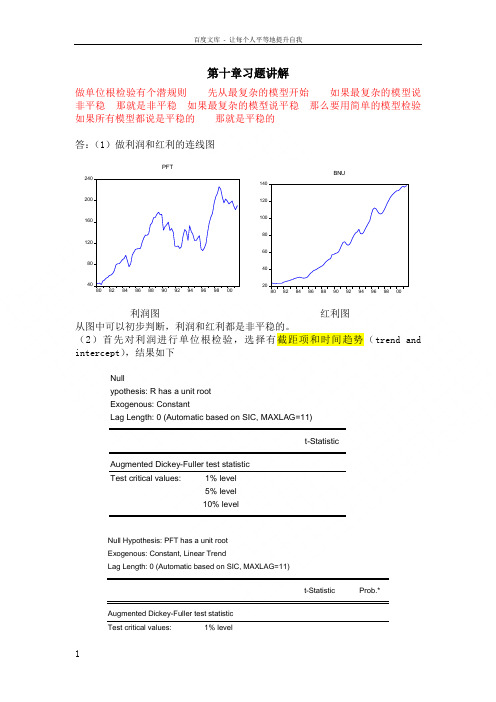
第十章习题讲解做单位根检验有个潜规则 先从最复杂的模型开始 如果最复杂的模型说非平稳 那就是非平稳 如果最复杂的模型说平稳 那么要用简单的模型检验 如果所有模型都说是平稳的 那就是平稳的 答:(1)做利润和红利的连线图40801201602002408082848688909294969800PFT204060801001201408082848688909294969800BNU利润图 红利图 从图中可以初步判断,利润和红利都是非平稳的。
(2)首先对利润进行单位根检验,选择有截距项和时间趋势(trend and intercept ),结果如下Nullypothesis: R has a unit root Exogenous: ConstantLag Length: 0 (Automatic based on SIC, MAXLAG=11)t-StatisticAugmented Dickey-Fuller test statistic Test critical values:1% level 5% level10% levelNull Hypothesis: PFT has a unit root Exogenous: Constant, Linear TrendLag Length: 0 (Automatic based on SIC, MAXLAG=11)t-StatisticProb.*Augmented Dickey-Fuller test statistic Test critical values:1% level5% level10% level*MacKinnon (1996) one-sided p-values.可以看到ADF值大于所有临界值且P值很大,所以不能拒绝原假设,即利润是非平稳的。
然后对红利进行单位根检验,选择有截距项和时间趋势,结果如下Null Hypothesis: I has a unit rootExogenous: ConstantLag Length: 3 (Automatic based on SIC, MAXLAG=11)t-Statistic Prob.*Augmented Dickey-Fuller test statisticTest critical values: 1% level5% level10% levelNull Hypothesis: BNU has a unit rootExogenous: Constant, Linear TrendLag Length: 1 (Automatic based on SIC, MAXLAG=11)t-Statistic Prob.*Augmented Dickey-Fuller test statisticTest critical values: 1% level5% level10% level*MacKinnon (1996) one-sided p-values.可以看到ADF值大于所有临界值且P值很大,所以不能拒绝原假设,即红利也是非平稳的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Economics 20 - Prof. Anderson
13
除趋势(续 除趋势 续)
与向模型引入时间趋势因子相比, 与向模型引入时间趋势因子相比,采用 除趋势数据的好处是便于计算拟合优度 由于趋势的高解释度, 由于趋势的高解释度,时间序列回归往 往具有很高的R 往具有很高的 2 而使用除趋势数据作回归,所得到的R 而使用除趋势数据作回归,所得到的 2 能够更真实地地反映x 能够更真实地地反映 t对 yt的解释程度
Economics 20 - Prof. Anderson
2
时间序列数据的例子
描述同期变量关系的静态模型: 描述同期变量关系的静态模型 yt = β0 + β1zt + ut 具有滞后效应的有限分 允许自变量对 y 具有滞后效应的有限分 布滞后 (FDL)模型 模型 yt = α0 + δ0zt + δ1zt-1 + δ2zt-2 + ut 更一般地, 一个q阶 更一般地 一个 阶的有限分布滞后模型 将包含z的 个滞后变量 将包含 的q个滞后变量
时间序列数据
yt = β0 + β1xt1 + . . .+ βkxtk + ut 1. 基本分析
Economics 20 - Prof. Anderson
1
时间序列数据与横截面数据的比较
不像横截面数据, 不像横截面数据,时间序列数据有一个 时间的排序 考虑到时间序列数据 时间序列数据不再拥有一个对个 考虑到时间序列数据不再拥有一个对个 体的随机样本,因此需要改变某些假定 因此需要改变某些 体的随机样本 因此需要改变某些假定 取而代之的是, 取而代之的是,可以将时间序列数据看 作是一个随机过程的实现 作是一个随机过程的实现
Economics 20 - Prof. Anderson
5
无偏性假定 (续) 续
零条件均值假定表明,诸 x都是严格外生的 条件均值假定表明, 都是严格外生的 另外, 另外,一种更加类似于横截面情形的假定 是 E(ut|xt) = 0 该假定意指, 该假定意指,诸x是同期外生的 是同期外生的 同期外生性只能满足大样本的要求 同期外生性只能满足大样本的要求
Economics 20 - Prof. Anderson
3
有限分布滞后模型
通常将 它反映了y的 通常将δ0称为冲击倾向 –它反映了 的即期 它反映了 变化 对于自变量暂时的单期变化, 将在第 将在第q+1 对于自变量暂时的单期变化, y将在第 个时期之后回到它最初的水平 通常将 通常将δ0 + δ1 +…+ δq称为长期倾向 (LRP) – 它反映了自变量的永久改变所导致的 y的 它反映了自变量的永久改变所导致的 的 长期变化
Economics 20 - Prof. Anderson
11
时间序列的趋势(续 时间序列的趋势 续)
一种可能性是线性趋势,可以采用模型: 一种可能性是线性趋势,可以采用模型 模型 yt = α0 + α1t + et, t = 1, 2, … 另一种可能性是指数趋势,可采用模型 模型: 另一种可能性是指数趋势,可采用模型 log(yt) = α0 + α1t + et, t = 1, 2, … 另外,还有二次函数趋势,可采用模型 二次函数趋势 模型: 另外,还有二次函数趋势,可采用模型 yt = α0 + α1t + α2t2 + et, t = 1, 2, …
Economics 20 - Prof. Anderson
12
除趋势
在回归中增加一个线性趋势项, 在回归中增加一个线性趋势项,与在回 归中使用已经除去趋势的时间序列, 归中使用已经除去趋势的时间序列,所 得结果是一样的 对时间序列除趋势, 对时间序列除趋势,就是对模型中的每 一个变量,都对时间t作回归 一个变量,都对时间 作回归 由此得到除趋势序列的残差形式 这样, 这样,序列中原有的时间趋势就被偏掉 了
Economics 20 - Prof. Anderson
9
普通最小二乘估计量的方差(续 普通最小二乘估计量的方差 续)
在上述五个假定下,时间序列的普通最 上述五个假定下, 五个假定下 小二乘估计量的方差将与横截面情形相 同,即 σ2的估计量是相同的 普通最小二乘估计量仍然是最优线性无 偏估计量 加上误差项的正态假定, 加上误差项的正态假定,推断也是相同 的
Economics 20 - Prof. Anderson
7
普通最小二乘估计量的无偏性
基于上述三条假定,对于时间序列数据, 基于上述三条假定,对于时间序列数据, 普通最小二乘估计量是无偏的 这正如横截面数据的情形一样, 这正如横截面数据的情形一样,在适当 的条件下普通最小二乘估计量是无偏的 可以采用横截面情形下的相同方法, 可以采用横截面情形下的相同方法,来 分析遗漏变量的偏误问题
Economics 20 - Prof. Anderson
14
季节性
通常, 通常,时间序列数据会表现出某种周期 性,这种周期性统称为季节性 例子: 例子:零售额季度数据往往会在第四个 季度出现跳跃 对于季节性, 对于季节性,可以通过增加一组季节虚 拟变量来处理 同时间趋势一样, 同时间趋势一样,也可以在回归之前对 序列进行去季节性处理
Economics 20 - Prof. Anderson
6
无偏性假定 (续) 续
仍需假定x是变量,并且诸 之间 之间没有完全 仍需假定 是变量,并且诸 x之间没有完全 是变量 共线性 注意我们已经跳过了随机样本假定 注意我们已经跳过了随机样本假定 随机样本假定的关键效应是每一个u 效应是每一个 随机样本假定的关键效应是每一个 i都是 独立的 而前面的严格外生性假定, 而前面的严格外生性假定,已经包含了这 一点
Economics 20 - Prof. Anderson
8
普通最小二乘估计量的方差
正如在横截面情形下一样, 正如在横截面情形下一样,为了推导出 估计方差 方差, 估计方差,需要增加同方差性假定 即假定 Var(ut|X) = Var(ut) = σ2 因此,误差项的方差是独立于所有的x 因此,误差项的方差是独立于所有的 , 并且是不随时间而变的常数 此外,还需要作无序列相关假定: 此外,还需要作无序列相关假定 Corr(ut ,us| X)=0 ,对于 t ≠ s
Economics 20 - Prof. Anderson
15
Economics 20 - Prof. Anderson
10
带趋势的时间序列 带趋势的时间序列
经济时间序列通常具有时间趋势 仅仅因为两个时间序列在时间趋势上走 到了一起, 到了一起,是不能认为它们之间存在因 果关系的 经常地,是其他未观测到的因素, 经常地,是其他未观测到的因素,导致 了两个时间序列出现趋势 尽管这些因素是无法观测到的 因素是无法观测到的, 尽管这些因素是无法观测到的,但我们 可以通过直接控制趋势来控制它们 可rof. Anderson
4
无偏性假定
仍然假定模型对参数是线性的 仍然假定模型对参数是线性的: yt = β0 + 模型对参数是线性的 β1xt1 + . . .+ βkxtk + ut 仍然需要作零条件均值假定 零条件均值假定: 仍然需要作零条件均值假定 E(ut|X) = 0, t = 1, 2, …, n 注意到这个假定的含义是, 注意到这个假定的含义是,任一时期的误 含义是 差项与所有时期的解释变量都无关