对等级树代码的一个应用
判定树
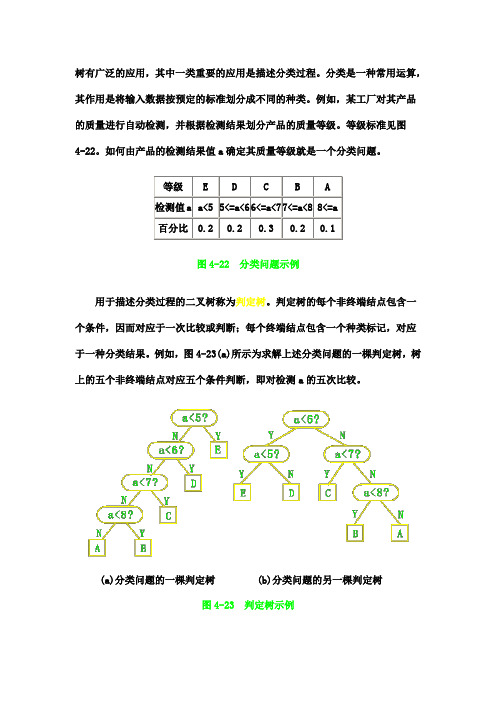
树有广泛的应用,其中一类重要的应用是描述分类过程。
分类是一种常用运算,其作用是将输入数据按预定的标准划分成不同的种类。
例如,某工厂对其产品的质量进行自动检测,并根据检测结果划分产品的质量等级。
等级标准见图4-22。
如何由产品的检测结果值a 确定其质量等级就是一个分类问题。
图4-22 分类问题示例用于描述分类过程的二叉树称为判定树。
判定树的每个非终端结点包含一个条件,因而对应于一次比较或判断;每个终端结点包含一个种类标记,对应于一种分类结果。
例如,图4-23(a)所示为求解上述分类问题的一棵判定树,树上的五个非终端结点对应五个条件判断,即对检测a 的五次比较。
(a)分类问题的一棵判定树(b)分类问题的另一棵判定树图4-23 判定树示例易知一棵判定树描述了一种分类方法。
图4-23(a)中判定树对应的分类算法如下:char classify1(float x)/ * 依给定标准将检测值x区分成相应的质量等级作为返回值 */{ if(x<5) return ('E');else if(x<6) return('D');else if(x<7)return('C');else if(x<8) return('B');else return('A');}利用这个算法,可由产品的检测结果值x确定其质量等级。
当一个分类算法需要反复使用时,其时间性能就值得进一步考虑。
假如进行上述产品质量自动分类(定等级)的工厂的产量很大,上述分类算法就将被频繁地重复使用,这时就需要考虑其时间性能。
假设需要分级的产品有N=100000件,并且这批产品的等级分布如图4-22中表格的第三行所示。
某等级产品总比较次数=某等级的“产品数”X单个检测的“比较次数”比如,D级产品数为N*20%个,为区分出一件产品是D级的,需进行2次比较。
那么,D级产品总比较次数=N*20%*2=100000*0.2*2=40000。
2024年9月GESP编程能力认证C++等级考试八级真题试卷(含答案)

2024年9月GESP 编程能力认证C++等级考试八级真题试卷(含答案)一、单选题(每题2分,共30分)。
1.下面关于C++类和对象的说法,错误的是()。
A. 类的析构函数可以为虚函数。
B. 类的构造函数不可以为虚函数。
C. class 中成员的默认访问权限为private 。
D. struct 中成员的默认访问权限为private 。
2.对于一个具有n 个顶点的无向图,若采用邻接矩阵表示,则该矩阵的大小为()。
A. 2n n B. n ×nC. (n-1)×(n-1)D. (n+1)×(n+1)3.设有编号为A 、B 、C 、D 、E 的5个球和编号为A 、B 、C 、D 、E 的5个盒子。
现将这5个球投入5个盒子,要求每个盒子放一个球,并且恰好有两个球的编号与盒子编号相同,问有多少种不同的方法()。
A. 5B. 120C. 20D. 604.从甲地到乙地,可以乘高铁,也可以乘汽车,还可以乘轮船。
一天中,高铁有10班,汽车有5班,轮船有2班。
那么一天中乘坐这些交通工具从甲地到乙地共有多少种不同的走法()。
A. 100B. 60C. 30D. 175.题n 个结点的二叉树,执行释放全部结点操作的时间复杂度是()。
A. O(n)B. O(n log n)C. O(log n)D. O(2n )6.在一个单位圆上,随机分布n 个点,求这n 个点能被一个单位半圆周全部覆盖的概率()。
nA.1-n21B.2n1C.n1D.n27.下面pailie函数是一个实现排列的程序,横线处可以填入的是()。
#include <iostream>using namespace std;int sum =0;void swap(int & a, int & b){int temp =a;a =b;b =temp;}void pailie(int begin, int end, int a[]){if(begin ==end){for(int i =0;i < end;i++)cout << a[i];cout << endl;}for(int i =begin;i < end;i++){__________ // 在此处填入选项。
最优二叉树

哈夫曼编码的另一种表示: 1.00
0 0.40 0 g 0.21 1
1
b 0.19
0
0.28 0 0.17 1
0.60 1 e 0.32
0.11 0 1
0
1 d 0.07 0.06
h 0.10
哈夫曼编码树
a
0.05
0 f 0.03 1 c 0.02
练习题:设计哈夫曼编码,通信中可能有8种字符,其频率 分别为:0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11
0 d
1
0
i 0 a
1
1 n
Huffman编码结果:d=0, i=10, a=110, n=111 WPL=1bit×7+2bit×5+3bit(2+4)=35(小于等长码的WPL=36) 特征:每一码不会是另一码的前缀,译码时唯一,不会错! Huffman编码也称为前缀码
Huffman编码
哈夫曼编码的基本思想是——— 出现概率大的信息用短码,概率小的用长码
最佳判定方法
Y Y E Y D Y a<60 N a<70 N C Y B Y D 70a<80 N 80a<90 N 60a<70 N
a<80
N a<90 N A
Y
E
C
Y B
a<60
N A
(b)WPL=40x1+30x2+15x3+5x4+10x4=205
(a)WPL=10x4+30x4+40x3+15x2+5x1=315
void Select (HuffmanTree HT,int t,int&s1,int&s2) {//在HT[1...t]中选择parent为0且权值最小的两个结点,其 序号分别为s1和s2 int i, m, n; m=n=100000; for(i=1;i<=t;i++) {if(HT[i].parent==0&&(HT[i].weight<m||HT[i].weight<n)) if(m<n) { n=HT[i].weight ; s2=i ; } else { m=HT[i].weight ; s1=i ; } } if(s1>s2) //s1放较小的序号 {i=s1;s1=s2;s2=i;} }
环氧树脂防火等级

环氧树脂防火等级环氧树脂是一种高分子材料,具有优异的物理性能和化学性能,因此被广泛应用于各个领域。
在建筑领域中,环氧树脂被用作防火材料,其防火等级也是非常重要的指标。
本文将详细介绍环氧树脂防火等级的相关知识。
一、环氧树脂的防火等级环氧树脂的防火等级是指其在火灾中的燃烧性能,通常用欧洲标准EN13501-1来评估。
该标准将建筑材料的防火等级分为七个等级,分别是A1、A2、B、C、D、E和F。
其中,A1级别最高,F级别最低。
环氧树脂的防火等级通常是通过添加阻燃剂来实现的。
阻燃剂是一种能够减缓或阻止材料燃烧的化学物质。
添加阻燃剂可以提高环氧树脂的防火等级,使其在火灾中不易燃烧或燃烧速度较慢。
二、环氧树脂的防火性能环氧树脂的防火性能主要取决于其化学结构和添加的阻燃剂种类、含量等因素。
一般来说,环氧树脂的防火性能越好,添加的阻燃剂含量就越高。
但是,过高的阻燃剂含量会影响环氧树脂的物理性能和加工性能,因此需要在防火性能和其他性能之间进行平衡。
环氧树脂的防火性能可以通过以下几个方面来评估:1. 燃烧性能燃烧性能是评估环氧树脂防火性能的重要指标。
在欧洲标准EN13501-1中,燃烧性能被分为四个等级,分别是A1、A2、B、C。
其中,A1级别最高,表示材料不燃烧,不产生烟雾和有毒气体;A2级别次之,表示材料不燃烧,但可能产生烟雾和有毒气体;B级别表示材料燃烧速度较慢,不易燃烧;C级别表示材料燃烧速度较快,易燃烧。
2. 烟雾生成性能烟雾生成性能是指环氧树脂在燃烧时产生的烟雾量。
烟雾是火灾中最危险的因素之一,会影响人员的逃生和救援工作。
因此,环氧树脂的防火性能还需要考虑其烟雾生成性能。
在欧洲标准EN13501-1中,烟雾生成性能被分为三个等级,分别是s1、s2、s3。
其中,s1级别最高,表示烟雾生成量最少;s3级别最低,表示烟雾生成量最多。
3. 有毒气体生成性能有毒气体生成性能是指环氧树脂在燃烧时产生的有毒气体量。
有毒气体是火灾中另一个危险因素,会对人员的健康造成威胁。
哈夫曼树及其应用

A
B
C
DE
FG
40% 30% 10%
HI
5% 15%
n
WPL= wi*li i=1
n为叶子结 点的数目
wi和li分别表示叶结点ki的权 值和根到ki的路径长6度
哈夫曼树概念
哈夫曼树(最优二叉树) 在权为w1,w2,……,wn的n个叶结点的所有二叉
树中,WPL最小的二叉树称为最优二叉树或哈夫曼树。 例:给定4个叶结点a,b,c,d,分别带权7,5,2,4,我们来构造3棵二叉树:
17
哈夫曼树构造
哈夫曼树的构造算法实现
Void CreateHT (hufmtree Tree)
{
int i,p1,p2;
InitHT(Tree);
// 初始化
InputW(Tree);
// 输入权值
for (i = n;i<2n-1;i++){ // n-1次合并 SelectMin(Tree,i-1,&p1,&p2);
Tree[p1].parent=Tree[p2].parent=i; Tree[i].lchild = p1; Tree[i].rchild = p2; Tree[i].weight = Tree[p1].weight +Tree[p2].weight; } }
18
哈夫曼编码
哈夫曼树的应用—哈夫曼编码
N
中等
A<90
Y
N
良好
优秀
70-79 中等 40%
80-89 良好 30%
90-100 优秀 10%
A<80
Y
N
A<70
Y A<60
day-7sklearn库实现ID3决策树算法

day-7sklearn库实现ID3决策树算法 本⽂介绍如何利⽤决策树/判定树(decision tree)中决策树归纳算法(ID3)解决机器学习中的回归问题。
⽂中介绍基于有监督的学习⽅式,如何利⽤年龄、收⼊、⾝份、收⼊、信⽤等级等特征值来判定⽤户是否购买电脑的⾏为,最后利⽤python和sklearn库实现了该应⽤。
1、决策树归纳算法(ID3)实例介绍 2、如何利⽤python实现决策树归纳算法(ID3)1、决策树归纳算法(ID3)实例介绍 ⾸先介绍下算法基本概念,判定树是⼀个类似于流程图的树结构:其中,每个内部结点表⽰在⼀个属性上的测试,每个分⽀代表⼀个属性输出,⽽每个树叶结点代表类或类分布。
树的最顶层是根结点。
决策树的优点:直观,便于理解,⼩规模数据集有效 决策树的缺点:处理连续变量不好,类别较多时,错误增加的⽐较快,可规模性⼀般 以如下测试数据为例: 我们有⼀组已知训练集数据,显⽰⽤户购买电脑⾏为与各个特征值的关系,我们可以绘制出如下决策树图像(绘制⽅法后⾯介绍) 此时,输⼊⼀个新的测试数据,就能根据该决策树很容易判定出⽤户是否购买电脑的⾏为。
有两个关键点需要考虑:1、如何决定分⽀终⽌;2如何决定各个节点的位置,例如根节点如何确定。
1、如何决定分⽀终⽌如果某个节点所有标签均为同⼀类,我们将不再继续绘制分⽀,直接标记结果。
或者分⽀过深,可以基于少数服从多数的算法,终⽌该分⽀直接绘制结果。
例如,通过年龄划分,所有middle_aged对象,对应的标签都为yes,尽管还有其它特征值,例如收⼊、⾝份、信⽤等级等,但由于标签所有都为⼀类,所以该分⽀直接标注结果为yes,不再往下细分。
2、如何决定各个节点的位置,例如根节点如何确定。
在说明这个问题之前,我们先讨论⼀个熵的概,信息和抽象,如何度量?1948年,⾹农提出了 “信息熵(entropy)”的概念,⼀条信息的信息量⼤⼩和它的不确定性有直接的关系,要搞清楚⼀件⾮常⾮常不确定的事情,或者是我们⼀⽆所知的事情,需要了解⼤量信息==>信息量的度量就等于不确定性的多少 例⼦:猜世界杯冠军,假如⼀⽆所知,猜多少次?每个队夺冠的⼏率不是相等的,也就说明该信息熵较⼤。
计算机等级考试(国家)-(a)二级java笔试模拟441

(A)二级JAVA笔试模拟441一、选择题1、下列叙述中正确的是______。
A.栈是“先进先出”的线性表B.队列是“先进后出”的线性表C.循环队列是非线性结构D.有序线性表既可以采用顺序存储结构,也可以采用链式存储结构2、支持子程序调用的数据结构是______。
A.栈 B.树C.队列 D.二叉树3、某二叉树有5个度为2的结点,则该二叉树中的叶子结点数是______。
A.10 B.8C.6 D.44、下列排序方法中,最坏情况下比较次数最少的是______。
A.冒泡排序B.简单选择排序C.直接插入排序D.堆排序5、软件按功能可以分为应用软件、系统软件和支撑软件(或工具软件)。
下面属于应用软件的是______。
A.编辑程序B.操作系统C.教务管理系统D.汇编程序6、下面叙述中错误的是______。
A.软件测试的目的是发现错误并改正错误B.对被调试的程序进行“错误定位”是程序调试的必要步骤C.程序调试通常也被称为的DebugD.软件测试应严格执行测试计划,排除测试的随意性7、耦合性和内聚性是对模块独立性度量的两个标准,下列叙述中正确的是______。
A.提高耦合性降低内聚性有利于提高模块的独立性B.降低耦合性提高内聚性有利于提高模块的独立性C.耦合性是指一个模块内部各个元素间彼此结合的紧密程度D.内聚性是指模块间互相连接的紧密程度8、数据库应用系统中的核心问题是______。
A.数据库设计B.数据库系统设计C.数据库维护D.数据库管理员培训9、有两个关系R、S如下:由关系R通过运算得到关系S,则所使用的运算为______。
A.选择 B.投影C.插入 D.连接10、将E-R图转换为关系模式时,实体和联系都可以表示为______。
A.属性 B.键C.关系 D.域11、Java虚拟机(JVM)运行Java代码时,不会进行的操作是______。
A.加载代码 B.校验代码C.编译代码 D.执行代码12、Java程序的并发机制是______。
C#编程题

1、从键盘输入一个正整数,按数字的相反顺序输出。
2、从键盘上输入两个整数,由用户回答它们的和,差,积,商和取余运算结果,并统计出正确答案的个数。
3、写一条for语句,计数条件为n从100~200,步长为2;然后再用while语句实现同样的循环。
4、编写一段程序,运行时向用户提问“你考了多少分?(0~100)”,接受输入后判断其等级并显示出来。
判断依据如下:等级={优(90~100分);良(80~89分);中(60~69分);差(0~59分);}5、输入一个整数,将各位数字反转输出。
6、使用穷举法并分别用for、while、do…while循环语句求出1~100之间的质数。
7、求出1~1000之间的所有能被7整除的树,并计算和输出每5个的和。
8、编写一个控制台程序,分别输出1~100之间的平方、平方根、自然对数、e指数的数学用表。
9、设计一个包含多个构造函数的类,并分别用这些构造函数实例化对象。
10、编写一个矩形类,私有数据成员为举行的长(len)和宽(wid),无参构造函数将len和wid设置为0,有参构造函数设置和的值,另外,类还包括矩形的周长、求面积、取举行的长度、取矩形的长度、取矩形的宽度、修改矩形的长度和宽度为对应的形参值等公用方法。
11、编写一个类,要求带有一个索引器可以存储100个整型变量。
12、编写一个类Cal1,实现加、减两种运算,然后,编写另一个派生类Cal2,实现乘、除两种运算。
13、建立三个类:具名、成人、官员。
居民包含身份证号、姓名、出生日期,而成人继承自居民,多包含学历、职业两项数据;官员则继承自成人,多包含党派、职务两项数据。
要求每个类中都提供数据输入输出的功能。
14、编写一个类,其中包含一个排序的方法Sort(),当传入的是一串整数,就按照从小到大的顺序输出,如果传入的是一个字符串,就将字符串反序输出。
15、设计一个类,要求用事件每10秒报告机器的当前时间。
16、编写一个窗体程序,用菜单命令实现简单的加、减、乘、除四则运算,并将结果输出到对话框。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
187
case just 1M® stars where used, whereas for the first two cases a Salpeter mass function ( f ( m ) d m = m-2"35dm) with upper cutoff at 1 M® and lower cutoff at 0.1 M® was used. The lightcurves along the marked tracks are displayed in figures 3a,b and c. T h e results of raising a up to 0.95 can be summarized as follows: - total n u m b e r of (micro-.) caustics increases rapidly, overlapping of caustics gets more and more i m p o r t a n t "clustering tendency" of caustics (already known from lower values of a, see e.g. SW) increases dramatically - time scale of fixed variations (e.g. A m > 0.5mag) grows - lightcurves get smoother and flatter (for fixed source size); they do not show the U-shaped double peaks, that are well known for low surface mass densities - average and peak amplitudes of variations decrease (for fixed source size) - the typical slopes for our smallest sources decrease from about 2 mag within 3 normalized units (cr = 0.8) to about 1 mag within 8 time units (a = 0.95) individual caustics can not be resolved any more in the lightcurve for our source sat Macrocaustics We modelled a realistic macrocaustic of an isothermal sphere with a finite core and put part of the m a t t e r into stars. Without stars one gets a smooth decrease in magnification inversely proportional to the square root of the distance d between source and (macro-) caustic: A oc d -°'~ (see figs. 2a,3d). Figs. 2b,c show the "grainy" situation (corresponding lightcurves in figs. 3e,f) for different values of the scaling p a r a m e t e r s0/rio, the ratio of the deflection angles of the isothermal sphere and a single star:
Microlensing
calculations with a hierarchical New Results
tree
code:
Joachim Wambsganss Max-Planck-Institut ffir Astrophysik 8046 Garching, West-Germany (bitnet: J K W at DGAIPP1S) 1. Introduction Microlensing deals with the effects of individual compact objects inside the lensing galaxy on the (macro-) image of a lensed background quasar (for reviews see, e.g., Schneider 1990 or Watson 1989). Due to the enormous amount of computing time, microlensing calculations have been performed only for a comparatively small number of lensing stars and for moderate values of the (normalized) surface mass density a = E/Ecr, (see e.g. Schneider and Weiss 1987 (SW); Kayser, Refsdal and Stabell 1986 (KRS); Paczynski 1986; Young 1981) where the critical density is given by ~or = (c2/4~rG)(Ds/DLDLs) (here c is the velocity of light, G is the gravitational constant and DL,Ds, DLs are the angular diameter distances observer-lens, observer-source, lenssource, resp.). For QSO 2237+0305 this value is ~cr -~ 2.5g cm -2 _~ 1.2 * 104M®pc -2. With a new code based on the hierarchical tree method (Barnes and Hut 1986) the time consuming part of the computations, the calculation of the deflection angles of each star, can be reduced in an efficient and elegant way (Wambsganss et ai.1989, 1990), so that a much larger number of stars can be included, allowing, e.g., for a mass spectrum of the lensing stars or surface mass densities closer to the critical one. Here we present new results of microlensing calculations obtained with this hierarchical tree code in four different regimes: - surface mass densities a --~ 1 - microlensing at macrocaustics - effects of a mass spectrum with different lower cutoff masses (for constant a) - macroimages for a --* 1. We used the inverse ray shooting method (described, e.g., in SW, KRS) and obtained two-dimensional distributions of the magnification factors for extended sources. The side lengths of these maps are 20~0, where ~0 = X/(4GM®/c2)(DLsDL/Ds) is the Einstein radius of a 1M® star. The resolution is 10242 pixels for figs. la,b and 5002 pixels for figs. lc-f and 2a-c, so that one pixel length corresponds to about 0.02 ~0 or 0.04 ~0. The lightcurves are calculated along the three marked tracks for sources with Gaussian profiles of halfwidths 1 (thin line), 4 (medium) and 16 (thick) pixellengths. In the case of QSO 2237+0305 the smMlest effective source size is of order 10 -4 pc. The time unit is t = ~o(Ds/DLs)(1 + ZL)/V6oo, where ZL is the lens redshift and v600 is the lens velocity (relative to observer/source) in units of 600 km/sec. For QSO 2237+0305 one time unit is about 9 years. 2. Microlensing for surface mass densities a --* 1.0 In figs. la,b,c we show the magnification patterns for cr = 0.8, 0.9 and 0.95. The numbers of individual lenses used are 41820, 184723, 172616, respectively. For the latter