编译原理与技术讲义-第4章
编译原理_chapter4

Fa | (E)
描述IF语句的二义文法
<stmt>→ if <expr> then <stmt>
| if <expr> then <stmt> else <stmt>
| other
(4.7)
根据if语句中else与then配对情况将其分为配对 的语句和不配对的语句两类。
上述if语句的文法没有对这两个不同的概念加 以区分,只是简单地将它们都定义为<stmt>, 从而导致该文法是二义性的。
if e1 then if e2 then s1 else s2的语法树
二义性(ambiquity)的定义
对于文法G,如果L(G)中存在一个具有两 棵或两棵以上分析树的句子,则称G是二 义性的。也可以等价地说:如果L(G)中
存在一个具有两个或两个以上最左(或最
右)推导的句子,则G是二义性文法。 如果一个文法G是二义性的,假设
2021/4/25
计算机学院 辛明影
E E→a a
E
E→a a
一棵树!
9
关于语法树的几点结论
短语:一棵子树的 所有叶子自左至右 排列起来形成一个 相对于子树根的短 语。教材p50
短语:
a, a,a,
a+a, a+a*a
2021/4/25
E E* E E +E
a
aa
10
关于语法树的几点结论
直接短语:仅有父子两 代的一棵子树,它的 所有叶子自左至右排列 起来所形成的符号串。
对于一般情况而言,若某一文法G的产生 式具有如下形式:
A→A α1| A α2 |…| A αm| β1| β2|…| βn
编译原理课件第四章
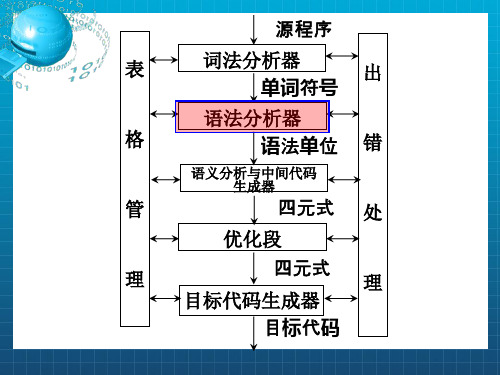
单词符号
语法分
源程序 词法分
语法分 析树 编译程序
析器 取下一单词 析器
后续部分
... 符号表
• 语法分析的方法: • 自下而上分析法(Bottom-up)
• 基本思想:从输入串开始,逐步进行“归约”,
直到文法的开始符号。即从树末端开始,构造语法 树。所谓归约,是指根据文法的产生式规则,把产 生式的右部替换成左部符号。
FIRST( i)∩FOLLOW(A)= i=1,2,...,n
如果一个文法G满足以上条件,则称该文法G为L L(1)文法。
• 对于一个满足上述条件的文法,可以对其输入串进行有效的无回溯的自上而下分析。假 设要用非终结符A进行匹配,面临的输入符号为a,A的所有产生式为 A→ 1 | 2 | … | n 1. 若aFIRST( i),则指派 i执行匹配任务;
Q→Sab | ab | b • 现在的Q不含直接左递归,把它代入到S的有关候选后,S变成
S→Sabc | abc | bc | c
• 例 考虑文法G(S)
S→Qc|c Q→Rb|b R→Sa|a
• S变成
S→Sabc | abc | bc | c
• 消除S的直接左递归后: S→abcS | bcS | cS S→abcS | Q→Sab |ab | b R→Sa|a
P P
含有左递归的文法将使自上而下的分 析陷入无限循环。
4.3 LL(1)分析法
• 构造不带回溯的自上而下分析算法 • 要消除文法的左递归性 • 克服回溯
4.3.1 左递归的消除
• 直接消除见诸于产生式中的左递归:假定关于非终结符P的规则为 P→P |
其中不以P开头。 我们可以把P的规则等价地改写为如下的非直接左递归形式:
编译原理第4章.doc
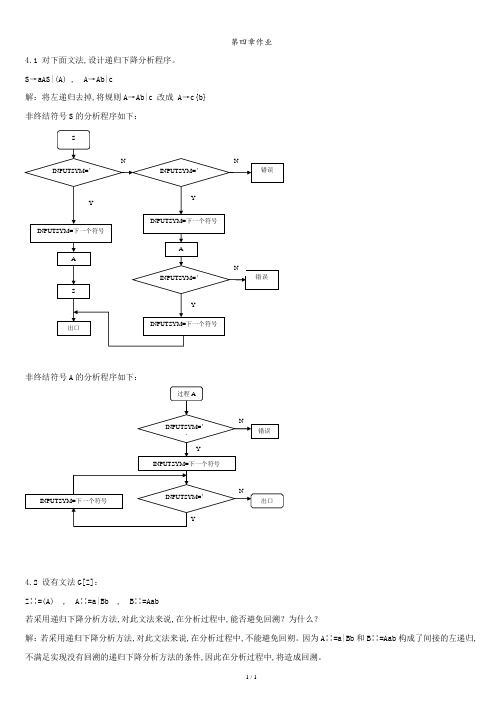
第四章作业4.1 对下面文法,设计递归下降分析程序。
S→aAS|(A) , A→Ab|c解:将左递归去掉,将规则A→Ab|c 改成 A→c{b}非终结符号S的分析程序如下:非终结符号A的分析程序如下:4.2 设有文法G[Z]:Z∷=(A) , A∷=a|Bb , B∷=Aab若采用递归下降分析方法,对此文法来说,在分析过程中,能否避免回溯?为什么?解:若采用递归下降分析方法,对此文法来说,在分析过程中,不能避免回朔。
因为A∷=a|Bb和B∷=Aab构成了间接的左递归,不满足实现没有回溯的递归下降分析方法的条件,因此在分析过程中,将造成回溯。
4.3 若有文法如下,设计递归下降分析程序。
<语句>→<语句><赋值语句>|ε<赋值语句>→ID=<表达式><表达式>→<项>|<表达式>+<项>|<表达式>-<项><项>→<因子>|<项>*<因子>|<项>/<因子><因子>→ID|NUM|(<表达式>)解:首先,去掉左递归(1)<语句>→<语句><赋值语句>|ε改为: <语句>→{<赋值语句>}(3)<表达式>→<项> | <表达式> + <项> | <表达式> - <项> 改为:<表达式>→<项>{(+ | -)<项>}(4)<项>→<因子> | <项> * <因子> | <项> / <因子>改为:<项>→<因子>{(* | /)<因子>}则文法变为:<语句>→{<赋值语句>}<赋值语句>→ID=<表达式><表达式>→<项>{(+ | -)<项>}<项>→<因子>{(* | /)<因子>}<因子>→ID|NUM|(<表达式>)非终结符号 <语句>→{<赋值语句>} 的分析程序如下:非终结符号 <赋值语句>→ID=<表达式> 的分析程序如下:非终结符号<表达式>→<项>{(+ | -)<项>} 的分析程序如下:非终结符号 <项>→<因子>{(* | /)<因子>} 的分析程序如下:非终结符号 <因子>→ID|NUM|(<表达式>) 的分析程序如下:4.4 有文法G[A]:A::=aABe|ε,B::=Bb|b(1)求每个非终结符号的FOLLOW集。
编译原理 第4章1

4.2.2 文法的左递归性和回 溯的消除
第二种情况: 文法中相同左部的规 则,其中某一右部能推出ε串,例如, 文法G: A→ Bx B→ x |ε 其非终结符B有两个右部,第二个右 部能推导出ε串且两个右部左端第一 个符号不相同,但在分析符号串 W=x 时出现回溯。
4.2.2 文法的左递归性和回 溯的消除
FIRST(α) SELECT(A→ α) = FIRST(α)/{ε}∪FOLLOW (A) * 若αε
* 若α / ε
LL(1)文法的判断条件
例 设有文法G[A]: A→aB | d B→bBA | ε
SELECT(A→aB ) = FIRST(aB) = { a } SELECT(A→d ) = FIRST(d) = { d }
LL(1)文法的判断条件
为了建立LL(1)文法的判断条件,需引 进三个相关集: FIRST集
FOLLOW集
SELECT集
LL(1)文法的判断条件
(1) 设α是文法G的任一符号串,定义文 法符号串α的首符号集合。 * FIRST(α) = { a | α a…且 a∈V }
T
* ε ,则规定 ε∈ FIRST(α) 若α
4.2.2 文法的左递归性和回 溯的消除
2. 回溯的消除 在自上而下分析过程中,由于回 溯,需要推翻前面的分析,包括已做 的一大堆语义工作,重新去进行试探, 这样大大降低了语法分析器的工作效 率,因此,需要消除回溯。
4.2.2 文法的左递归性和回 溯的消除
我们分析发现引起回溯的原因是: 在 文法中,当某个非终结符A有多个候选式时: A → α1 | α2 | α3 |∙∙∙∙∙∙| αn
LL(1)文法的判断条件
S → aAb A → de | d ∵ SELECT(A→de)= FIRST(de)={d} SELECT(A→d)= FIRST(d)={d} ∴ SELECT(A→de)∩SELECT(A→d) ≠Φ
编译原理第四章

FIRST( F ) = { (, id
}
FIRST( T ) = FIRST( F ) = { (, id } FIRST( E ) = FIRST( T ) = { (, id } FIRST( E' ) = { +,ε }
FIRST( T' ) = { *, ε }
定义
教学进度
FOLLOW( A ) 的计算法(P67)
计算机科学与工程系
表达式文法直接左递归的消除
E → E + T|T T → T * F|F F → ( E )|id
E E' T T' F → → → → → T + F * ( E' T E'|ε T' F T'|ε E )|id
教学进度
计算机科学与工程系
把直接左递归改为直接右递归:
将规则A →A1|A2|...|Am|1|2|...|n 改写为: A → 1 A’ |2 A’ |...|n A’ A’ → 1A’|2 A’ |...|m A’ | ε
• top down parsing:推导
• bottom up parsing:归约
教学进度
4.2 自顶向下语法分析
• 基本思想:
计算机科学与工程系
• 从文法的开始符号出发,向下推导出句子; • 试图用一切可能的办法,从文法开始符号出发, 自上而下地为输入串建立一课语法树;(寻找一 个最左推导) • 此分析过程本质上是一种试探过程。 • 非确定的自上而下分析法实际上采用的是一种 穷尽一切可能的试探法。
• E → T E' • E'→ + T E'|ε • T → F T' • T'→ * F T'|ε • F → ( E )|id 按照最左推导过程,构造分析树
编译原理第四章

S→aAb A→c A′
A′ →d|
n
A→α A′ A′ →β 1|β 2|…|β
n
不确定的自顶向下
转化
确定的自顶向下
问题: 回溯 左递归
解决问题: 提取左因子 消除左递归算法
例教材4.2 : SaBC B bC|dB Cc|a 分析句子adbca
思考: BAf|Be 选哪个? 计算Af 和Be 首终结符是 什么?
S S(L) LSL ’ L’ε
)
a
Sa LSL ’
a
A
b
【例4.1】 分析acb 是否句子? G[S]: S→aAb A→cd|c
S · 3. 选第一个Acd推导 a b-d不匹配(失败) c d S · a A c b A b
思考: 为何有 回溯
4.回溯 即砍掉A的子树 改选A的第二右部 Ac 匹配
(1)推导过程是一个不断试探的过程,出现回溯(回退并使用其他候选式试探)
S S
b S
① ②
a
S
b
a
S
S a
③
a
S
S a
a
b
思考:为何 有死循环
(2)陷入死循环
分析时可能出现: (1) 回溯 原因:推导过程中有多个侯选式可供选择 ,并根据所面临 的输入符号不能准确的确定所要选择时,就可能出现回溯。 例4.1
(2) 死循环。例4.2:在没有对当前输入符号匹配就进入处理 S的过程,无法确定什么时候才用Sb替换, 造成死循环. 原因: 左递归
1 3
=>acS
4
=>acaA =>acaA =>aca
1 4 4
当用A ε , A用ε代替,可以通过A的后随终结符号来匹 配
编译原理第四章答案

First( A' ) Follow ( A' ) {d , } {), b}
4.4(2)
见课后答案 规则见课本P66
问题?
Select( E gAf ) Select( E c) First( gAf ) Frist(c) {g} {c}
4.2
对下面的文法G: E→TE’ E’→+TE’|ε T→FT’ T’→*FT’|ε F→(E)|id (1)计算这个文法的每个非终结符的FIRST和FOLLOW。 (2)证明这个文法是LL(1)的。 (3)构造它的预测分析表。 (4)构造它的递归下降分析程序。
第四章习题
4.1 4.2 4.3 4.4
4.1
1、考虑下面文法G[A]: A→BCc|gDB B→bCDE|ε C→DaB|ca D→dD|ε E→gAf|c (1)FIRST集和FOLLOW集 (2)是否是LL(1)文法。
4.1(1) First集
First( A) First( BCc) First( gDB) First( B) \ { } First(C ) {g} {b} First( D) \ { } {a} First(ca) {g} {b} {d } {a} {c} {g} {a, b, c, d , g}
E’→ε T→FT ’ T’→ε F→idFra bibliotekE’→ε
T’→ε
4.2(4)
规则见课本P66 见课后答案 E→TE’ T→FT’ F→(E)|id E’→+TE’|ε T’→*FT’|ε
4.3
文法G[S]: S→A A→B|AiB B→C|B+C C→)A*|( 1)改写为LL(1)文法 2)求改写后的文法的每个非终结符的First集和Follow集 3)构造相应的预测分析表
ppt编译原理4章444

4.3 确定的自顶向下分析思想
一、算法思想: 文法特点: (1)每个产生式的 对于任一输入符号串,从文法的识别符号出发,根据 右部都由终结符号开始;(2) 当前的输入符号,唯一的确定一个产生式,用产生式的右 两个产生式若左部相同,则 部的符号串替代相应的非终结符往下推导,或构造一棵语 其右部以不同的终结符号开 始;(3)无空产生式U 法树。若能推导出输入串或构造语法树成功则输入串是句 子,否则不是。 S 二、举例: (1)文法G[S]: SpA |qB AcAd|a 输入串 w=pccadd 对应最左推导:
4.5 非LL(1)文法转换为LL(1)文法
对某个语言来说其文法不一定是LL(1)文法,而非LL(1) 文法将无法采用确定的自顶向下分析方法进行分析,但我 们可以通过对文法进行等价变换,在有些情况下使其成为 LL(1)文法。 一、提取左公共因子: 设文法中有Uxy|xw( UVN, x,y,wV*)形式的产生式,从 而导致了: First(xy)First(xw)=First(x)Ф 因而使: Select(Uxy) Select(Uxw) Ф 1.方法:若有产生式Uxy|xw|…|xz , 则提取左公共因 若在y,w,…,z中仍然有左公 子并用EBNF表示为: Ux(y|w|…|z) 共因子,可以再次提取。 注意,若有:Uxy|x 再引入另一个非终结符号V,将产生式变为: 则提取后:Ux(y|) UxV V y|w|…|z
2.举例: 设有产生式:S→if B then S1 else S2 | if B then S1 其中,S表示两种类型的条件语句。 提取公因子,改成: S→if B then S1 ( else S2 | ) 引入非终结符号R: S→if B then S1 R R→else S2 |ε 文法中,if , then, elseVT
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
S c A d c a (a) (a)
5
S A b (b) (b) d c
S A a (c) (c) d
编译原理与技术
4.1 自顶向下语法分析的一般方法
这种一般方法存在一些问题: 这种一般方法存在一些问题:
(1) 左递归问题
自顶向下分析采取最左推导, 自顶向下分析采取最左推导,文法中含有左递归会使 自上而下的分析过程陷入无限循环。因此, 自上而下的分析过程陷入无限循环。因此,必须消除文 法的左递归。 法的左递归。
S c A d c a (a) (a)
S A b (b) (b) d c
S A a (c) (c) d
图4.1 输入串cad的语法分析树
编译原理与技术
4
4.1 自顶向下语法分析的一般方法
此时A的最左子结点a匹配输入串第二个符号。而A的第二个子结点b和输入串 第三个符号不一致,说明A的这个产生式不能用来产生该输入串。这就需要 回到子结点A,选用另一个产生式A→a来构造语法树,如图4.1(c)所示。 这种回头选用其他产生式的过程称为回溯。回溯时,要把由前面产生式 A→ab得到的子树删除,并重新读入在子结点A处的当时符号a。 用新的产生式构造语法树后,A的子结点为a,与当前符号一致,读入最后一 个输入符号d。此时结点A完成匹配,它的右边是结点d,与当前符号一致。 这样就完成了输入串的匹配,说明输入串cad是该文法的一个句子。 上面的分析同时也给出了输入串cad的最左推导过程:S ⇒ cAd ⇒ cad。
S a A A a
11
编译原理与技术
4.2 LL(1)文法 文法
文法G 文法 2[S]: S→Aa | Bb A→a | cA B→b | dB
这个文法的特点: 这个文法的特点: • 每个产生式的右部不全是由 终结符号开始。 终结符号开始。 • 如果两个产生式有相同的左 部,那么它们的右部由不同 的终结符或非终结符开始。 的终结符或非终结符开始。 • 文法中无空产生式。 文法中无空产生式。
可能跟开始符号S,而S推导的符号串只能以a, d开头, 即FIRST(S)= {a, d},因此FOLLOW(A)= {a, d, $}。
18
编译原理与技术
4.2 LL(1)文法 文法
10
对于这样的文法,分析输入串 时,可以跟据输入串的当前符号 确定选取产生式。 比如w1 = pccadd,第一个 符号是p,而从开始符号S出发, 只有选择产生式S→pA推导,才 能出现符号p。同样,要出现第 二个符号c,必须选择产生式 A→cAd。 这样,虽然具有相同左部的 产生式不只一个,但文法的特点 决定了每一步推导只能选择惟一 的产生式,从而可以避免回溯。
13
编译原理与技术
4.2 LL(1)文法 文法
由此我们可以看出,如果文法中不含空符产生式, 由此我们可以看出,如果文法中不含空符产生式,并 且每个非终结符的所有候选式右部的首符集两两不相交, 且每个非终结符的所有候选式右部的首符集两两不相交, 则推导中就不会产生回溯。 则推导中就不会产生回溯。而提取左因子正是为了达到 这个目的,即反复提取左因子后, 这个目的,即反复提取左因子后,就能够把每个非终结 符(包括新引进的非终结符)的所有候选首符集变成两 包括新引进的非终结符) 两不相交。因此, 两不相交。因此,提取左因子可以使得不含空符产生式 的文法消除回溯。 的文法消除回溯。
编译原理与技术
第4章 章 自顶向下的语法分析
主要内容
自顶向下语法分析概述 LL(1)文法 文法 递归下降分析技术 预测分析技术 LL(1)分析中的错误处理 分析中的错顶向下语法分析的一般方法
基本思想: 基本思想:
–
对任何输入串,试图用一切可能的办法, 对任何输入串,试图用一切可能的办法,从 文法开始符号出发,自上而下, 文法开始符号出发,自上而下,从左到右地 为输入串建立分析树。或者说, 为输入串建立分析树。或者说,为输入串寻 找最左推导。 找最左推导。 本质上是一种试探过程, 本质上是一种试探过程,反复使用不同的产 生式谋求匹配输入串。 生式谋求匹配输入串。
17 编译原理与技术
4.2 LL(1)文法 文法
例 4.5: : 文法G 文法 4[S]: S→aA | d A→bAS |ε
输入串w4 = abd的推导过程为: S ⇒ aA ⇒ abAS ⇒ abS ⇒ abd 可以看出,开始符号S后面不会跟任何符号,但 是有S
…S,因此FOLLOW(S)={$}。 …A,也 非终结符A后面可能不跟任何符号,即S
S A c A d p
S A c A d c A d p
S A c A d c A d a
9
编译原理与技术
4.2 LL(1)文法 文法
文法G 文法 1[S]: S→pA | qB A→cAd | a B→dB | b
这个文法的特点: 这个文法的特点: • 每个产生式的右部都由终结 符号开始。 符号开始。 • 如果两个产生式有相同的左 部,那么它们的右部由不同 的终结符开始。 的终结符开始。
16
编译原理与技术
4.2 LL(1)文法 文法
–
因此,一个文法能否进行确定的自顶向下语法分析, 因此,一个文法能否进行确定的自顶向下语法分析,不 仅仅与文法中具有相同左部的产生式右部的FIRST集有 仅仅与文法中具有相同左部的产生式右部的 集有 关系,若有产生式右部可能推出ε, 关系,若有产生式右部可能推出 ,则还与其左部非终 结符的后继符号集合有关。 结符的后继符号集合有关。 定义4.2: 设G = (VN,VT , P, S)是上下文无关文法,对于 是上下文无关文法, 定义 是上下文无关文法 P∈VN,定义后继符集 定义后继符集FOLLOW(P)为 ∈ 为 FOLLOW(P) = {a | S µPβ且a∈FRIST(β), µ∈VT*, β ∈ β β∈V+ } 即 FOLLOW(P)={a | S …Pa… , a∈VT }。 ∈ 。 特别地, 特别地,若S …P,则规定 ∈FOLLOW(P)。即 ,则规定$∈ 。 FOLLOW(P)是推导过程中所有可能紧跟在 之后的终结 是推导过程中所有可能紧跟在P之后的终结 是推导过程中所有可能紧跟在 符或边界符号$ 用来界定输入串 表示为: 输入串 用来界定输入串, 输入串$) 符或边界符号 ($用来界定输入串,表示为:$输入串 )。
(2) 回溯问题
反复寻找可正确匹配的产生式时可能需要不断回溯, 反复寻找可正确匹配的产生式时可能需要不断回溯, 虚假匹配现象需要使用更复杂的回溯技术。 虚假匹配现象需要使用更复杂的回溯技术。这样将会产 生许多额外工作,因此应设法消除回溯。 生许多额外工作,因此应设法消除回溯。
6
编译原理与技术
4.1 自顶向下语法分析的一般方法
12
对于这样的文法,分析输入串时, 也可以跟据输入串的当前符号确定 地选取产生式。 比如推导w2=ccaa时,首先考虑开 始符号S,它可以推出以A或B开头 的符号串。而由以A和B为左部的产 生式可知,A只能推出以a, c开头的 符号串,B只能推出以b, d开头的符 号串。因此,要得到w2的第一个符 号c,只有选择产生式S→Aa, A→cA。同样,要出现第二个符号c, 仍需选择产生式A→cA,没有别的 选择。这样,文法的特点决定了每 一步推导只能选择确定的产生式, 从而可以避免回溯。
14
编译原理与技术
4.2 LL(1)文法 文法
后继符集FOLLOW 后继符集
输入串w3 = cca自顶向下的推导过程为: 例4.4: S ⇒ Aa ⇒ cAa ⇒ ccAa ⇒ cca : 文法 G3与例4.3中文法G2惟一不同之处在于,G3中非终 结符A的候选式中含有空符产生式。分析时,对于 G3[S]: 输入串w3的前两个符号cc,可以确定使用产生式 A→cA,而要得到第三个符号a,按照a所在的首符 S→Aa | Bb 集我们应该选择产生式A→a,但是显然这种选择是 错误的,因为这样得到的是符号串ccaa而不是cca。 A→a | cA |ε 实际上,这时正确的选择是产生式A→ε,也就是让 A自动匹配到空符,就可以得到与输入串匹配的符 B→b | dB 号串cca。
特点: 特点:
–
3
编译原理与技术
4.1 自顶向下语法分析的一般方法
例4.1:设文法 :设文法G[S]:S→cAd,A→ab|a,输入串为 : , ,输入串为cad,自 , 顶向下进行语法分析,并构造相应语法树。 顶向下进行语法分析,并构造相应语法树。
先按文法的开始符号产生根结点S,选择S惟一的产生式构造语法树,如图 4.1(a)所示。 把S的子结点从左到右与输入串中的字符相比较,第一个子结点c匹配输入串 第一个符号。第二个子结点是非终结符A,要选择A的产生式进一步构造。 而A有两个候选式,先选择A→ab构造语法树,如图4.1(b)所示。
8 编译原理与技术
–
–
4.2 LL(1)文法 文法
首符集FIRST 首符集
例4.2: : 文法G 文法 1[S]: S→pA | qB A→cAd | a B→dB | b p
w1 = pccadd自顶向下的推导过程: S ⇒ pA ⇒ pcAd ⇒ pccAdd ⇒ pccadd 语法树:
S A p
7
编译原理与技术
4.2 LL(1)文法 文法
–
要实现无回溯的自顶向下语法分析, 要实现无回溯的自顶向下语法分析,对相应文法 必须要有一定的限制。首先, 必须要有一定的限制。首先,文法应该不含左递 若文法中含有左递归, 归,若文法中含有左递归,则需使用文法的等价 变换消除左递归。其次,还要消除回溯。 变换消除左递归。其次,还要消除回溯。 通过提取左因子消除某些文法的回溯,为什么? 通过提取左因子消除某些文法的回溯,为什么? 没有左递归和左因子的文法是否一定可以进行确 定的自顶向下分析? 定的自顶向下分析?
编译原理与技术