Apache Nutch 1.3 学习笔记三(Inject)
nutch分布式详解

nutch分布式详解1( Injector)初始抓取时,没有任何文件,只有几个待抓取的url站点信息。
假设所有url站点存在rootUrlDir文件目录下(可以是一个或多个文件,每个文件一行一个url)。
需要将这些url导入到crawldb中去,以方便在下次generate时能够抓取这些网页。
这里详细介绍导入函数injector的分布式过程。
导入函数调用方式为:injector.inject(crawlDb, rootUrlDir)。
整体过程包含两个MapReduce过程:(1)sortJob:把输入的url转换为crawlDatum格式;Input: urlDirMapper:InjectMapper: <lineCounter, url> ---> <url,crawlDatum>Output:tempDirOutputFormat:SequenceFileOutputFormat分析:Map过程中,一行读取一个url,并将url站点封装成crawlDatum对象。
每个url都经过urlNormalizers, filters,scfilters三个过程标记状态:urlNormailizes在这里为URLNormalizers.SCOPE_INJECT状态,将url正规化处理,如规范大小写等;filters由nutch-site.xml的“urlfilter.order”属性控制,默认值为空时加载所有的urlfilter,把一些不符合的url 过滤掉(这里也可以自定义urlfilter,比如过滤某些不需要抓取的站点);Scfilters由“scoring.filter.order”属性控制,默认值是空也是加载所有的score filter的injectedScore 函数;新构造的crawlDatum的status = STATUS_INJECTED,fetchInterval=30天,fetchTime=currentTime,score =1.0f。
java inject用法

java inject用法Java中的@Inject用法在Java中,@Inject是一个注解,用于标识依赖注入(Dependency Injection)的目标。
依赖注入是一种设计模式,通过将一个或多个依赖对象注入到目标对象中,实现对象之间的解耦和灵活性。
1. @Inject注解的使用@Inject注解可以用于构造函数、方法、字段和任何自定义注解中。
下面分别介绍在这些场景中的使用方法。
2. 在构造函数中使用@Inject@Inject注解可以用于构造函数,用于标识需要进行依赖注入的构造函数。
在依赖注入的过程中,被注入的依赖对象会自动通过构造函数来创建并传入目标对象。
javapublic class Example {private Dependency dependency;@Injectpublic Example(Dependency dependency) {this.dependency = dependency;}}上述代码中的Example类有一个Dependency类型的依赖对象,通过@Inject注解标识了构造函数,表示需要对该构造函数进行依赖注入。
3. 在方法中使用@Inject@Inject注解还可以用于方法,用于标识需要进行依赖注入的方法。
在依赖注入的过程中,被注入的依赖对象会自动通过方法调用来获取。
javapublic class Example {private Dependency dependency;@Injectpublic void setDependency(Dependency dependency) { this.dependency = dependency;}}上述代码中的Example类有一个Dependency类型的依赖对象,通过@Inject注解标识了setDependency方法,表示需要对该方法进行依赖注入。
4. 在字段中使用@Inject@Inject注解还可以用于字段,用于标识需要进行依赖注入的字段。
apache工具类常用方法

apache工具类常用方法
Apache Commons是一组开源工具库,提供了一些实用的方法和工具类,用于简化常见的编程任务。
以下是Apache Commons工具类中一些常用
的方法:
1. Apache Commons Lang:提供了一些用于处理Java基本类型的实用方法,例如字符串操作、数字格式化、数组操作等。
2. Apache Commons IO:提供了一些用于处理文件和IO操作的实用方法,例如文件操作、文件过滤、文件复制等。
3. Apache Commons Collections:提供了一些用于处理集合的实用方法,例如集合转换、集合过滤、集合映射等。
4. Apache Commons Math:提供了一些用于数学计算的实用方法,例如
数学函数、线性代数、统计计算等。
5. Apache Commons Validator:提供了一些用于数据验证的实用方法,
例如字符串验证、电子邮件验证、IP地址验证等。
这些工具类中的方法都是静态的,可以直接通过类名调用,无需创建对象实例。
使用这些工具类可以大大简化代码,提高开发效率。
Nutch 的配置文件

Nutch 的配置Nutch的配置文件主要有三类:1.Hadoop的配置文件,Hadoop-default.xml和Hadoop-site.xml。
2.Nutch的配置文件,Nutch-default.xml和Nutch-site.xml。
3.Nutch的插件的配置文件,这些插件的配置文件在加载插件的时候由插件自行加载,如filter的配置文件。
配置文件的加载顺序决定了配置文件的优先级,先加载的配置文件优先级低,后加载的配置文件优先级高,优先级低的配置会被优先级高的配置覆盖。
因此,了解Nutch配置文件加载的顺序对学习使用Nutch是非常必要的。
下面我们通过对Nutch源代码的分析来看看Nutch加载配置文件的过程。
Nutch1.0使用入门(一)介绍了Nutch主要命令--crawl的使用,下面我们就从crawl的main类(org.apache.nutch.crawl.Crawl)的main方法开始分析:Crawl类main方法中加载配置文件的源码如下:Configuration conf = NutchConfiguration.create();conf.addResource("crawl-tool.xml");JobConf job = new NutchJob(conf);上面代码中,生成了一个NutchConfiguration类的对象,NutchConfiguration 是Nutch管理自己配置文件的类,Configuration是Hadoop管理自己配置文件的类。
下面我们进入NutchConfiguration类的create()方法。
/** Create a {@link Configuration} for Nutch. */public static Configuration create() {Configuration conf = new Configuration();addNutchResources(conf);return conf;}create()方法中,先生成了一个Configuration类的对象。
inject用法

inject用法inject是一个常用的编程术语,通常用于向变量、函数或方法中注入数据。
在许多编程语言中,都有类似的用法。
本文将介绍inject 的基本用法,包括定义变量、函数或方法,以及如何向其中注入数据。
一、定义变量在许多编程语言中,我们可以使用inject来定义变量,向其中注入数据。
例如,在Python中,我们可以使用inject来定义一个变量并注入数据:```pythonmy_variable = inject("Hello, world!")```这将创建一个名为my_variable的变量,并将其设置为字符串"Hello, world!"。
二、函数或方法注入除了定义变量之外,我们还可以使用inject来向函数或方法中注入数据。
在Java中,我们可以使用Spring框架中的@Autowired注解来自动注入依赖项,例如:```java@Autowiredprivate MyService myService;```这将自动将MyService实例注入到myService变量中。
在Python 中,我们可以使用inject来向函数或方法中注入参数:```pythondef my_function(param1, param2):inject("Hello, " + param1 + "!")```这将创建一个名为my_function的函数,并将参数param1和param2传递给它。
然后,函数内部使用inject将字符串"Hello, "加上param1拼接起来。
三、注入示例下面是一个使用inject的示例代码,展示如何向Python函数中注入数据:```pythondef my_function(name):inject("Hello, " + name + "!")print("Injection successful!")```这将创建一个名为my_function的函数,它接受一个参数name,并在函数内部使用inject向其添加字符串"Hello, "。
nutch介绍

搜索过程 Nutch提供了一个Fascade的NutchBean类供我 们使用,一段典型的代码如下
nutch的目标 nutch致力于让每个人能很容易, 同时花费很少 就可以配置世界一流的Web搜索引擎. 为了完成这 一宏伟的目标, nutch必须能够做到: • 每个月取几十亿网页 • 为这些网页维护一个索引 • 对索引文件进行每秒上千次的搜索 • 提供高质量的搜索结果 • 以最小的成本运作 这将是一个巨大的挑战。
Crawler工作流程 1. 创建一个新的WebDb (admin db -create). 2. 将抓取起始URLs写入WebDB中 (inject). 3. 根据WebDB生成fetchlist并写入相应的 segment(generate). 4. 根据fetchlist中的URL抓取网页 (fetch). 5. 根据抓取网页更新WebDb (updatedb).
爬虫,Crawler Index是Crawler抓取的所有网页的索引,它 是通过对所有单个segment中的索引进行合并处 理所得的。Nutch利用Lucene技术进行索引,所 以Lucene中对索引进行操作的接口对Nutch中的 index同样有效。但是需要注意的是,Lucene中 的segment和Nutch中的不同,Lucene中的 segment是索引index的一部分,但是Nutch中的 segment只是WebDB中各个部分网页的内容和索 引,最后通过其生成的index跟这些segment已经 毫无关系了。
爬虫,Crawler Crawler的重点在两个方面,Crawler的工作流 程和涉及的数据文件的格式和含义。数据文件主要 包括三类,分别是web database,一系列的 segment加上index,三者的物理文件分别存储在 爬行结果目录下的db目录下webdb子文件夹内, segments文件夹和index文件夹。那么三者分别 存储的信息是什么目录: 1.crawdb,linkdb 是web link目录,存放url 及url的互联关 系,作为爬行与重新爬行的依据,页面默认30天过期。 2.segments 是主目录,存放抓回来的网页。页面内容有 bytes[]的raw content 和 parsed text的形式。nutch 以广度优先的原则来爬行,因此每爬完一轮会生成一个 segment目录。 3.index 是lucene的索引目录,是indexs里所有index合并 后的完整索引,注意索引文件只对页面内容进行索引,没 有进行存储,因此查询时要去访问segments目录才能获 得页面内容。
Eclipse配置Nutch源码-适用于nutch任何版本-在网上找了很久,这是自己总结出来的
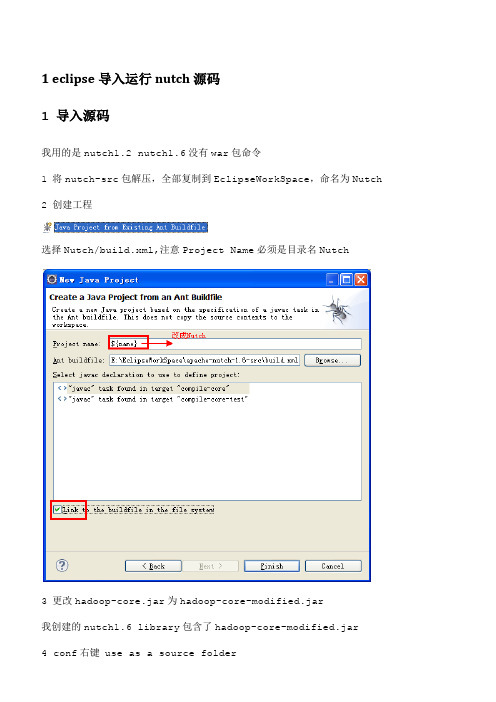
1 eclipse导入运行nutch源码1 导入源码我用的是nutch1.2 nutch1.6没有war包命令1 将nutch-src包解压,全部复制到EclipseWorkSpace,命名为Nutch2 创建工程选择Nutch/build.xml,注意Project Name必须是目录名Nutch3 更改hadoop-core.jar为hadoop-core-modified.jar我创建的nutch1.6 library包含了hadoop-core-modified.jar4 conf右键 use as a source folder项目编码改为utf-85 修改conf下的nutch-site.xml,在configuration标签对中添加如下代码:<property><name></name><value>My Agent</value></property>6 在conf下的nutch-default.xml中找到plugin.folders,原来的值是plugins,这个是build.xml编译之后,生成的目录,所以不用改7 ant编译build.xml,勾选jar job war有的src源码中的java文件扩展名改为了jav,不多,都要改过来8 将生成的build/ jar job plugins复制到根目录下面注意,每次修改了conf目录中的配置文件,必须重新编译,重新把jar job plugins复制一份,修改才能生效9在工程的根目录下建立urls文件夹,其中新建一个url.txt文件注意,最后由一个/,否则,会出错10 修改crawl-urlfilter.txt,只过滤我们想要的网站11在Crawl.java上配置java项目的运行参数: urls -dir mycrawls -depth 5 -threads4urls表示去爬那个网站,就是创建的urls目录名,不是命令参数名,就是一个参数值-dir参数,表示爬的数据放在mycrawls目录中,-depth 5表示深度为5 可以理解成/ 后面跟了几个/就是目录的深度,-threads 4就是几个线程11 运行中碰到的问题可以查看根目录中的hadoop.log详细信息2 问题1 fail to set permissions of path\ staging 0700nutch1.4往上的版本会有这个问题,hadoop设置的文件权限问题,linux下没有问题,方法,将nutch library中的hadoop-core-1.3.jar中的一个FileUtil文件修改一下,重新打包,我下载了一个,在libs_plugins/libs/hadoop-core-modified.1.0.2.jar2 OutofMem-Xms512m -Xmx1024m -XX:MaxPermSize=256m3 Error in configuring object应该是没有ant编译,plugins不是程序需要的。
inject 用法

inject 用法inject是一个常用的Python库,用于在代码中注入依赖项,以便在其他模块中使用。
它可以帮助您轻松地管理代码中的依赖项,并确保它们在运行时正确加载和初始化。
本文将介绍inject的基本用法和示例。
一、安装和导入库首先,您需要安装inject库。
您可以使用pip命令在终端中安装它:```shellpipinstallinject```安装完成后,您可以使用以下代码导入inject库:```pythonfrominjectimportInjector```二、使用Injector创建依赖项注入容器Injector类是inject库的核心,它用于创建依赖项注入容器。
您可以使用它来注册依赖项、注入对象和获取对象实例。
以下是一个简单的示例,演示如何使用Injector创建容器:```python#注册依赖项my_service=MyService()my_dependency=MyDependency()injector=Injector()injector.instance(my_service)injector.instance(my_dependency)#注入对象user_service=injector.get(UserService)user_service.set_dependencies(my_service,my_dependency) ```在上面的示例中,我们首先创建了两个依赖项:MyService和MyDependency。
然后,我们使用Injector创建了一个容器,并使用instance方法将它们注册到容器中。
最后,我们使用get方法从容器中获取UserService对象,并设置其依赖项。
三、使用依赖项注入对象的方法和属性一旦您已经创建了依赖项注入容器,您就可以使用它来注入对象的方法和属性。
以下是一个示例:```pythonclassUserService(object):def__init__(self,my_service,my_dependency):self.my_service=my_serviceself.my_dependency=my_dependencydefget_user(self):returnself.my_service.get_user(self.my_dependency)```在上面的示例中,UserService对象依赖于MyService和MyDependency。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Nutch 1.3 学习笔记三1. Inject是干嘛的?在Nutch中Inject是用来把文本格式的url列表注入到抓取数据库中,一般是用来引导系统的初始化。
这里的文本格式如下:1./ \t nutch.score=10 \t nutch.fetchInterval=2592000 \t userType=open_source这里的url与其元数据之间用Tab隔开,这里有两个保留的元数据,如下nutch.score : 表示特定url的分数nutch.fetchInterval : 表示特定url的抓取间隔,单位为毫秒Inject注入后生成的数据库为二进制结构,是Hadoop的MapSequenceFileOutputFormat 格式2. Inject运行命令1.bin/nutch inject <url_dir><crawl_db>在本地运行后的输出结果如下:1.Injector: starting at 2011-08-23 10:14:102.Injector: crawlDb: db/crawldb3.Injector: urlDir: urls4.Injector: Converting injected urls to crawl db entries.5.Injector: Merging injected urls into crawl db.6.Injector: finished at 2011-08-23 10:14:12, elapsed: 00:00:02你可以用如下命令来查看其数据库内容1.bin/nutch readdb <crawl_db> -stats -sort在本机的输出如下:1.rawlDb statistics start: db/crawldb2.Statistics for CrawlDb: db/crawldb3.TOTAL urls: 14.retry 0: 15.min score: 1.06.avg score: 1.07.max score: 1.08.status 1 (db_unfetched): 19. : 110.CrawlDb statistics: done3. Inject源代码分析我们知道Injector.java在Nutch源代码中的位置为org.apache.nutch.crawl.Injector.java 其中有一个main入口函数,使用Hadoop的工具类T oolRunner来运行其实例但其是终入口函数还是void inject(Path crawlDb, Path urlDir)其中有两个MP任务,第一个主要是把文件格式的输入转换成<url,CrawlDatum>格式的输出,这里的CrawlDatum是Nutch对于单个抓取url对象的一个抽象,其中有很多url的相关信息第二个MP主要是把上面新生成的输出与旧的CrawlDb数据进行合并,生成一个新的CrawlDb3.1 对于Inject中第一个MP任务的分析第一个MP任务主要代码如下:1.JobConf sortJob = new NutchJob(getConf()); // 生成一个Nutch的配置抽象2. sortJob.setJobName("inject " + urlDir);3. FileInputFormat.addInputPath(sortJob, urlDir); // 设置InputFormat,这里为FileInputFormat,这里要注意的是可以调用多次addInputPath这个方法,效果是会有多个输入源4. sortJob.setMapperClass(InjectMapper.class); // 这里设置了Mapper方法,主要是用于解析、过滤和规格化url文本,把其转换成<url,CrawlDatum>格式5.6.7. FileOutputFormat.setOutputPath(sortJob, tempDir); // 这里定义了一个输出路径,这里的tempDir=mapred.temp.dir/inject-temp-Random()8. sortJob.setOutputFormat(SequenceFileOutputFormat.class); // 这里配置了输出格式,这里为SequenceFileOutputFormat,这是MP的一种二进制输出结构9. sortJob.setOutputKeyClass(Text.class); // 这里配置了MP的输出<key,value>的类型,这里为<Text,CrawlDatum>10. sortJob.setOutputValueClass(CrawlDatum.class);11. sortJob.setLong("injector.current.time", System.currentTimeMillis());12. JobClient.runJob(sortJob); // 这里用于提交任务到JobTracker,让其运行任务这里对InjectMapper中的主要代码进行分析:这个类主要用于对url进行解析、过滤和规格化1.public void map(WritableComparable key, Text value,2. OutputCollector<Text, CrawlDatum> output, Reporter reporter)3. throws IOException {4. String url = value.toString(); // value is line of text5.6.7. if (url != null && url.trim().startsWith("#")) { // 这里以#号开头的文本就过滤8. /* Ignore line that start with # */9. return;10. }11.12.13. // if tabs : metadata that could be stored14. // must be name=value and separated by \t15. float customScore = -1f;16. int customInterval = interval;17. Map<String,String>metadata = new TreeMap<String,String>(); // 设置属性的一个容器18. if (url.indexOf("\t")!=-1){19. String[] splits = url.split("\t"); // 对一行文本进行切分20.url = splits[0];21. for (int s=1;s<splits.length;s++){22. // find separation between name and value23. int indexEquals = splits[s].indexOf("=");24. if (indexEquals==-1) {25. // skip anything without a =26.continue;27. }28. String metaname = splits[s].substring(0, indexEquals); // 得到元数据的名字29. String metavalue = splits[s].substring(indexEquals+1); // 得到元数据的值30. if (metaname.equals(nutchScoreMDName)) { // 看是不是保留的元数据31. try {32.customScore = Float.parseFloat(metavalue);}33. catch (NumberFormatException nfe){}34. }35. else if (metaname.equals(nutchFetchIntervalMDName)) {36. try {37.customInterval = Integer.parseInt(metavalue);}38. catch (NumberFormatException nfe){}39. }40. else metadata.put(metaname,metavalue); // 如果这个元数据不是保留的元数据,就放到容器中41. }42. }43. try {44.url = urlNormalizers.normalize(url, URLNormalizers.SCOPE_INJECT); // 对url进行规格化,这里调用的是plugins中的插件45.url = filters.filter(url); // filter the url // 以url进行过滤46. } catch (Exception e) {47. if (LOG.isWarnEnabled()) { LOG.warn("Skipping " +url+":"+e); }48.url = null;49. }50. if (url != null) { // if it passes51. value.set(url); // collect it52. // 这里生成一个CrawlDatum对象,设置一些url的初始化数据53. CrawlDatum datum = new CrawlDatum(CrawlDatum.STATUS_INJECTED, customInterval);54. datum.setFetchTime(curTime); // 设置当前url的抓取时间55. // now add the metadata56. Iterator<String>keysIter = metadata.keySet().iterator();57. while (keysIter.hasNext()){ // 配置其元数据58. String keymd = keysIter.next();59. String valuemd = metadata.get(keymd);60. datum.getMetaData().put(new Text(keymd), new Text(valuemd));61. }62. // 设置初始化分数63. if (customScore != -1) datum.setScore(customScore);64. else datum.setScore(scoreInjected);65. try {66. // 这里对url的分数进行初始化67. scfilters.injectedScore(value, datum);68. } catch (ScoringFilterException e) {69. if (LOG.isWarnEnabled()) {70. LOG.warn("Cannot filter injected score for url " + url71. + ", using default (" + e.getMessage() + ")");72. }73. }74. // Map 收集相应的数据,类型为<Text,CrawlDatum>75. output.collect(value, datum);76. }77. }78. }3.2 第二个MP任务的分析第二个MP任务主要是对crawlDb进行合并,源代码如下:1.// merge with existing crawl db2. JobConf mergeJob = CrawlDb.createJob(getConf(), crawlDb); // 这里对Job进行相应的配置3. FileInputFormat.addInputPath(mergeJob, tempDir); // 这里配置了输入的文本数据,就是上面第一个MP任务的输出4. mergeJob.setReducerClass(InjectReducer.class); // 这里配置了Reduce的抽象类,这里会覆盖上面createJob设置的Reduce类5. JobClient.runJob(mergeJob); // 提交运行任务6. CrawlDb.install(mergeJob, crawlDb); // 把上面新生成的目录重命名为crawlDb的标准文件夹名,然后再删除老的目录7.8.9. // clean up10. FileSystem fs = FileSystem.get(getConf());11. fs.delete(tempDir, true); // 把第一个MP任务的输出目录删除下面是createJob的源代码说明:1.public static JobConf createJob(Configuration config, Path crawlDb) throws IOException {2. // 生成新的CrawlDb文件名3. Path new newCrawlDb = new Path(crawlDb,Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));4.5.6. JobConf job = new NutchJob(config); // 生成相应的Job配置抽象7. job.setJobName("crawldb " + crawlDb);8.9.10. Path current = new Path(crawlDb, CURRENT_NAME);11. if (FileSystem.get(job).exists(current)) { // 如果存在老的CrawlDb目录,将其加入InputPath路径中,和上面的tempDir一起进行合并12. FileInputFormat.addInputPath(job, current);13. }14. // NOTE:有没有注意到这里如果有老的CrawlDb目录的话,那它的文件格式是MapFileOutputFormat,而下面对其读取用了SequenceFileInputFormat来读,因为这两个类底层都是调用了SequenceFile的Reader与Writer来读写的,所以可以通用。