实验四 异方差问题及其修正
实验四异方差性的检验与处理

实验四异方差性的检验与处理集团标准化工作小组 [Q8QX9QT-X8QQB8Q8-NQ8QJ8-M8QMN]实验四 异方差性的检验及处理(2学时)一、实验目的(1)、掌握异方差检验的基本方法; (2)、掌握异方差的处理方法。
二、实验学时:2学时 三、实验要求(1)掌握用MATLAB 软件实现异方差的检验和处理; (2)掌握异方差的检验和处理的基本步骤。
四、实验原理1、异方差检验的常用方法(1) 用X-Y 的散点图进行判断(2). 22ˆ(,)(,)e x e y 或的图形 ,),x )i i y i i ((e 或(e 的图形)(3) 等级相关系数法(又称Spearman 检验)是一种应用较广的方法,既可以用于大样本,也可与小样本。
检验的三个步骤 ① ˆt t y y=-i e②|i x i i 将e 取绝对值,并把|e 和按递增或递减次序排序,计算Spearman 系数rs ,其中:21ni i d =∑s 26r =1-n(n -1)③ 做等级相关系数的显着性检验。
n>8时,/2(2),t t n α>-反之,若||i i e x 说明与之间存在系统关系,异方差问题存在。
(4) 帕克(Park)检验帕克检验常用的函数形式:若在统计上是显着的,表明存在异方差性。
2、异方差性的处理方法: 加权最小二乘法 如果在检验过程中已经知道:222()()()i i i ji u Var u E u f x σσ===则将原模型变形为:121(i i p pi iy x x uf xβββ=+⋅++⋅+在该模型中:即满足同方差性。
于是可以用OLS估计其参数,得到关于参数12,,,pβββ的无偏、有效估计量。
五、实验举例例101i i iy x u=++若用线性模型,研究不同收入家庭的消费情况,试问原数据有无异方差性如果存在异方差性,应如何处理解:(一)编写程序如下:(1)等级相关系数法(详见文件)%%%%%%%%%%%%%%% 用等级相关系数法来检验异方差性 %%%%%%%%[data,head]=xlsread('');x=data(:,1); %提取第一列数据,即可支配收入xy=data(:,2); %提取第二列数据,即居民消费支出yplot(x,y,'k.'); % 画x和y的散点图xlabel('可支配收入x(千元)') % 对x轴加标签ylabel('居民消费支出y(千元)') % 对y轴加标签%%%%%%%% 调用regres函数进行一元线性回归 %%%%%%%%%%%%xdata=[ones(size(x,1),1),x]; %在x矩阵最左边加一列1,为线性回归做准备[b,bint,r,rint,s]=regress(y,xdata);yhat=xdata*b; %计算估计值y% 定义元胞数组,以元胞数组形式显示系数的估计值和估计值的95%置信区间head1={'系数的估计值','估计值的95%置信下限','估计值的95%置信上限'};[head1;num2cell([b,bint])]% 定义元胞数组,以元胞数组形式显示y的真实值,y的估计值,残差和残差的95%置信区间head2={'y的真实值','y的估计值','残差','残差的95%置信下限','残差的95%置信上限'};[head2;num2cell([y,yhat,r,rint])]% 定义元胞数组,以元胞数组形式显示判定系数,F统计量的观测值,检验的P值和误差方差的估计值head3={'判定系数','F统计量的观测值','检验的P值','误差方差的估计值'};[head3;num2cell(s)]%%%%%%%%%%%%% 残差分析 %%%%%%%%%%%%%%%%%%figure;rcoplot(r,rint) % 按顺序画出各组观测值对应的残差和残差的置信区间%%% 画估计值yhat与残差r的散点图figure;plot(yhat,r,'k.') % 画散点图xlabel('估计值yhat') % 对x轴加标签ylabel('残差r') % 对y轴加标签%%%%%%%%%%%% 调用corr函数计算皮尔曼等级相关系数res=abs(r); % 对残差r取绝对值[rs,p]=corr(x,res,'type','spearman')disp('其中rs为皮尔曼等级相关系数,p为p值');(2)帕克(park)检验法(详见文件)%%%%%%%%%%%%%%% 用帕克(park)检验法来检验异方差性 %%%%%%%[data,head]=xlsread(''); %导入数据x=data(:,1);y=data(:,2);%%%%%% 调用regstats函数进行一元线性回归,linear表带有常数项的线性模型,r表残差ST=regstats(y,x,'linear',{'yhat','r','standres'});scatter(x,.^2) % 画x与残差平方的散点图xlabel('可支配收入(x)') % 对x轴加标签ylabel('残差的平方') %对y轴加标签%%%%%%% 对原数据x和残差平方r^2取对数,并对log(x)和log(r^2)进行一元线性回归ST1=regstats(log(.^2),log(x),'linear',{'r','beta','tstat','fstat'})% 输出参数的估计值% 输出回归系数t检验的P值% 输出回归模型显着性检验的P值(3)加权最小二乘法(详见文件)%%%%%%%%%%% 调用robustfit函数作稳健回归 %%%%%%%%%%%%[data,head]=xlsread(''); % 导入数据x=data(:,1);y=data(:,2);% 调用robustfit函数作稳健回归,返回系数的估计值b和相关统计量stats[b,stats]=robustfit(x,y) %调用函数作稳健回归% 输出模型检验的P值%%% 绘制残差和权重的散点图 %%%%%%%plot,,'o') %绘制残差和权重的散点图xlabel('残差')ylabel('权重'(二)实验结果与分析:第一步::用OLS方法估计参数,并保留残差(1)散点图图可支配收入(x)居民消费支出(y)散点图因每个可支配收入x的值,都有5个居民消费收入y与之对应,所以上述散点图呈现此形状。
异方差实验报告

《计量经济学》实训报告实训项目名称异方差的检验及修正实训时间 2011年12月13日实训地点班级学号姓名实训(实践) 报告实训名称异方差的检验及修正一、实训目的深刻理解异方差性的实质、异方差出现的原因、异方差的出现对模型的不良影响(即异方差的后果),掌握估计和检验异方差性的基本思想和修正异方差的若干方法;能够运用所学的知识处理模型中的出现的异方差问题,并要求初步掌握用EViews处理异方差的基本操作方法。
二、实训要求使用教材第五章的数据做异方差的图形法检验、Goldfeld-Quanadt检验与White检验,使用WLS法对异方差进行修正。
三、实训内容1、用图示法、戈德菲尔德、white验证法,验证该模型是否存在异方差。
2、用加权最小二乘法消除异方差。
四、实训步骤练习题5.8数据1998年我国重要制造业销售收入和销售利润的数据Y—销售利润,x—销售收入1. 用OLS方法估计参数,建立回归模型:ls y c x回归结果如下:Y=12.036+0.1044x;S = (19.5178) (0.00844)T= (0.6167) (12.3667)R^2=0.8547 S.E.=56.90372.检验是否存在异方差(1) 图形检验:残差图形scat x e2结果表明:残差平方e2对解释变量的x的散点图主要分布在图形的下方,大致看出残差平方随X 的变动呈增大的趋势,因此,模型很可能出现异方差。
(2)戈德菲尔德-夸特检验首先,对变量进行排序,在这个题目中,我选择递增型排序,这是y与x将以x按递增型排序。
然后构造子样本区间,建立回归模型。
在本题目中,n=28,删除中间的1/4,的观测值,即大约8个观测值,剩余部分平分得两个样本区间:1—10和19-28,他们的样本个数均为10。
用OLS方法得到前10个数的样本结果(ls y c x):用OLS方法得到后10个数的样本结果(ls y c x):接着,根据戈德菲尔德检验得到F统计量:(两个残差平方和相除,大的除以小的)F=63769.67/2577.969=24.736。
异方差性的检验及处理方法
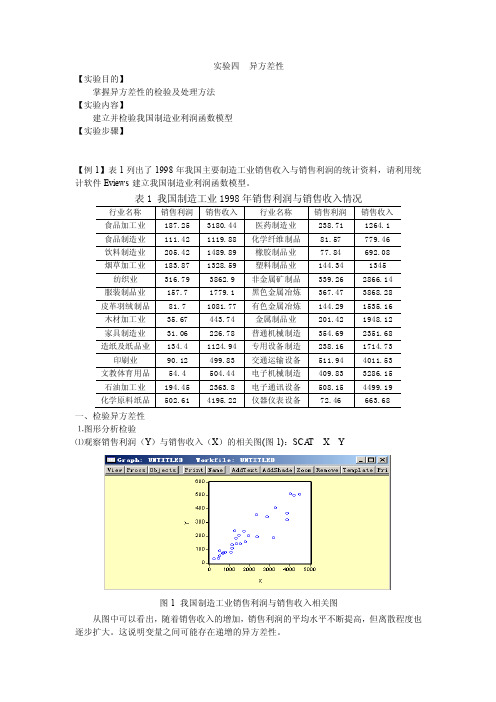
实验四异方差性【实验目的】掌握异方差性的检验及处理方法【实验内容】建立并检验我国制造业利润函数模型【实验步骤】【例1】表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。
一、检验异方差性⒈图形分析检验⑴观察销售利润(Y)与销售收入(X)的相关图(图1):SCA T X Y图1 我国制造工业销售利润与销售收入相关图从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
⑵残差分析首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。
在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。
图2 我国制造业销售利润回归模型残差分布图2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。
⒉Goldfeld-Quant检验⑴将样本按解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本)⑵利用样本1建立回归模型1(回归结果如图3),其残差平方和为2579.587。
SMPL 1 10LS Y C X图3 样本1回归结果⑶利用样本2建立回归模型2(回归结果如图4),其残差平方和为63769.67。
SMPL 19 28LS Y C X图4 样本2回归结果⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。
取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而44.372.2405.0=>=F F ,所以存在异方差性⒊White 检验⑴建立回归模型:LS Y C X ,回归结果如图5。
图5 我国制造业销售利润回归模型⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图6。
异方差的检验与修正

西安财经学院本科实验报告学院(部)统计学院实验室 313 课程名称计量经济学学生姓名学号 1204100213 专业统计学教务处制2014年12 月 15 日《异方差》实验报告开课实验室:313 2014年12月22第六部分异方差与自相关4. 在本例中,参数估计的结果为:2709030.01402097.01402.728X X Y ++=Λ(2.218) (2.438) (16.999)922173.02=R D.W.=1.4289 F=165.8853 SE=395.2538三.检查模型是否存在异方差 1.图形分析检验 (1)散点相关图分析分别做出X1和Y 、X2和Y 的散点相关图,观察相关图可以看出,随着X1、X2的增加,Y 也增加,但离散程度逐步扩大,尤其表现在X1和Y.这说明变量之间可能存在递增的异方差性。
在Graph/scatter 输入log(x2) e^2,结果如下:(2)残差相关图分析建立残差关于X1、X2的散点图,可以发现随着X 的增加,残差呈现明显的扩大趋势,表明模型很可能存在递增的异方差性。
但是否确实存在异方差还应通过更进一步的检验。
2.GQ 检验首先在主窗口Procs菜单里选Sort current page命令,输入排序变量x2,以递增型排序对解释变量X2进行排序,然后构造子样本区间,分别为1-12和20-31,再分别建立回归模型。
(1)在Sample菜单里,将区间定义为1—12,然后用OLS方法求得如下结果(2)在Sample菜单里,将区间定义为20—31,然后用OLS方法求得如下结果则F的统计量值为:6699.834542929948192122===∑∑iieeF在05.0=α下,式中分子、分母的自由度均为9,查F分布表得临界值为:18.3)9,9(05.0=F,因为F=8.6699>18.3)9,9(05.0=F,所以拒绝原假设,表明模型确实存在异方差。
异方差实验报告

异方差实验报告异方差实验报告引言在统计学中,方差是一种衡量数据分布离散程度的重要指标。
然而,在实际应用中,我们常常会遇到方差不稳定的情况,即异方差。
异方差的存在会对统计分析结果产生显著影响,因此,我们需要探索异方差的原因和解决方法。
本实验旨在通过模拟数据和实际案例来探讨异方差的现象、原因和处理方法。
一、异方差现象的模拟实验为了更好地理解异方差的现象,我们首先进行了一系列的模拟实验。
我们生成了两组数据,一组是服从正态分布的数据,另一组是服从泊松分布的数据。
然后,我们分别对两组数据进行方差分析,并比较其结果。
实验结果显示,当数据服从正态分布时,方差分析的结果较为稳定,各组之间的方差差异不大。
然而,当数据服从泊松分布时,方差分析的结果却出现了明显的差异。
这说明泊松分布的数据具有异方差性质。
二、异方差的原因分析为了深入理解异方差的原因,我们进一步探究了几个可能导致异方差的因素。
1. 数据的变换我们对泊松分布的数据进行了对数变换,然后再进行方差分析。
实验结果显示,经过对数变换后,数据的异方差性质得到了明显改善。
这说明,数据的变换可以在一定程度上解决异方差问题。
2. 数据的离散程度我们生成了两组服从正态分布的数据,一组具有较小的离散程度,另一组具有较大的离散程度。
实验结果显示,离散程度较大的数据组具有更明显的异方差性质。
这表明,数据的离散程度与异方差之间存在一定的关联。
3. 样本容量我们通过不断调整样本容量,观察方差分析结果的变化。
实验结果显示,随着样本容量的增加,方差分析结果的稳定性得到了明显改善。
这说明,样本容量的大小对异方差的影响是显著的。
三、处理异方差的方法针对异方差问题,统计学家们提出了多种处理方法。
以下是一些常见的方法:1. 方差齐性检验在进行统计分析之前,我们可以先对数据进行方差齐性检验。
常用的方差齐性检验方法包括Levene检验和Bartlett检验。
如果检验结果表明数据存在异方差,我们可以采取相应的处理方法。
EViews计量经济学实验报告异方差的诊断及修正
姓名 学号实验题目 异方差的诊断与修正一、实验目的与要求:要求目的:1、用图示法初步判断是否存在异方差,再用White 检验异方差;2、用加权最小二乘法修正异方差。
二、实验内容根据1998年我国重要制造业的销售利润与销售收入数据,运用EV 软件,做回归分析,用图示法,White 检验模型是否存在异方差,如果存在异方差,运用加权最小二乘法修正异方差。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等) (一) 模型设定为了研究我国重要制造业的销售利润与销售收入是否有关,假定销售利润与销售收入之间满足线性约束,则理论模型设定为:i Y =1β+2βi X +i μ其中,i Y 表示销售利润,i X 表示销售收入。
由1998年我国重要制造业的销售收入与销售利润的数据,如图1:1988年我国重要制造业销售收入与销售利润的数据 (单位:亿元)Dependent Variable: YMethod: Least Squares Date: 10/19/05 Time: 15:27 Sample: 1 28Included observations: 28Variable Coefficient Std. Error t-Statistic Prob.??C 12.03564 19.517790.6166500.5428 X0.1043930.00844112.366700.0000R-squared0.854696 ????Mean dependent var 213.4650Adjusted R-squared 0.849107 ????S.D. dependent var 146.4895 S.E. of regression 56.90368 ????Akaike info criterion 10.98935 Sum squared resid 84188.74 ????Schwarz criterion 11.08450 Log likelihood -151.8508 ????F-statistic 152.9353 Durbin-Watson stat1.212795 ????Prob(F-statistic)0.000000估计结果为: iY ˆ = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670)2R =0.854696 2R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。
异方差性的检验和修正
甘肃
4916.25
4126.47
上 海 11718.01
8868.19
青海
5169.96
4185.73
江 苏 6800.23
5323.18
新疆
5644.86
4422.93
1、做 Y 关于 X 的散点图以及回归分析 将数据通过 excel 录入到 eviews 中,对解释变量与被解释变量做散点图,选择解 释变量作为 group 打开,在数据表“ group”中点击 view/graph/scatter/simple scatter,出现以上数据的散点图,如下图所示:
图的结果显示,X 前的参数在 5%的显著性水平下不为零,同时,F 检验也表明方程的线性 关系在 5%的显著性水平下成立。 其次,采用异方差稳健标准误法修正原 OLS 的标准差,得到下图所示的估计结果:
任然可以看出,变量 x 对应参数修正后的标准差比 ols 估计的结果有所增大,这表明原模型 OLS 估计结果低估了 X 的标准差。
上海
11718.01
8868.19
青海
5169.96
4185.73
北京
10349.69
8493.49
内蒙古
5129.05
3927.75
广东
9761.57
8016.91
陕西
5124.24
4276.67
浙江
9279.16
7020.22
甘肃
4916.25
4126.47
天津
8140.5
6121.04
黑龙江
4912.88
计量经济学实验四——异方差的检验和修正
实验目的:学习建立回归模型,并进行异方差检验和对模型进行修正 实验内容:
异方差的检验与修正
【实验名称】实验四异方差的检验与修正【实验目的】1、理解异方差的概念,掌握异方差出现的原因与后果;2、掌握异方差常见的检验方法,包括图示法、GQ检验法与White检验法等;3、掌握加权最小二乘法等异方差的修正方法,能够利用EViews软件进行实现。
【实验内容】下表给出了2008年中国部分省市城镇居民人均可支配收入X与消费性支出Y的统计数据。
单位:元(1)试利用OLS法建立人均消费性支出与可支配收入的线性模型;(2)检验模型是否存在异方差性;(3)如果存在异方差性,试采用适当的方法估计模型参数。
解:1、建立工作文件并导入数据2、建立线性回归模型计算相关系数,画出散点图,将消费型支出cons设为Y变量,可支配收入设为inc变量。
得到散点图:然后进行回归分析:得出线性回归方程cons=725.3459+0.664746*ins并且由散点图可知,由ins与cons组成的模型很可能存在异方差,下面进行进一步检验:G-Q检验。
先对可支配收入inc进行排序:再将数据分为1-12、20-31两个子样本:得到1-12子样本线性回归方程cons=669.5344+0.677374*ins 得到20-31子样本线性回归方程cons=1179.053+0.644719*ins由命令得到:在5%的显著性水平下,自由度为(10,10)的F分布的临界值为4.263,于是拒绝同方差的原假设,表明模型存在异方差。
WHITE 检验从表中可知,检验的伴随概率是0.0172,拒绝原假设,即认为模型存在异方差。
修正异方差:即得到:cons=7.25.3459+0.664746*inc从结果上看,拟合优度提高了,t统计量也有了改进。
此时,模型不存在异方差。
【结果分析】【实验小结】。
异方差性的概念、类型、后果、检验及其修正方法(含案例).
~2
~2
异方差。
怀特(White)检验的EViews软件操作要点
• 在OLS的方程对象Equation中,选择View/Residual tests/White Heteroskedasticity。
– 在选项中,EViews提供了包含交叉项的怀特检验“White Heteroskedasticity(cross terms)”和没有交叉项的怀特 检验“White Heteroskedasticity(no cross terms)” 这样 两个选择。
nR2 ~ 2 ( )
显然,辅助回归仍是检验 ei 与解释变量可能的组合的相关性。如果存 在异方差性, 那么 ei 与解释变量的某种组合之间必定存在显著的相关 性,这时往往显示出有较大的可决系数 R 2 ,并且某一参数的 t 检验值 较大。
2 所以,检验准则是:如果 nR2 ≥ ( ) ,则存在异方差;反之,则不存在
如果存在某一种函数形式,使得方程显著成立,则说明原 模型存在异方差性。 由于f(Xj)的具体形式未知,因此需要选择各种形式进行试验。
4.戈德菲尔德-匡特(Goldfeld-Quandt)检验
G-Q检验以F检验为基础,仅适用于样本容量较大、 异方差为单调递增或单调递减的情况。 G-Q检验的思想:
先按某一被认为有可能引起异方差的解释变量对样
本排序,再将排序后的样本一分为二,对子样本①和 子样本②分别进行OLS回归,然后利用两个子样本的 残差平方和之比构造F统计量进行异方差检验。
G-Q检验的步骤:
①将n对样本观察值(Xi1, Xi2, …,Xik,Yi)按某一被认为有 可能引起异方差的解释变量观察值Xij的大小排队。 ②将序列中间的c=n/4个观察值除去,并将剩下的观 察值划分为较小与较大的容量相同的两个子样本, 每个子样本的样本容量均为(n-c)/2 。
计量经济学--异方差的检验及修正
经济计量分析实验报告一、实验项目异方差的检验及修正二、实验日期2015.12.06三、实验目的对于国内旅游总花费的有关影响因素建立多元线性回归模型,对变量进行多重共线性的检验及修正后,进行异方差的检验和补救。
四、实验内容建立模型,对模型进行参数估计,对样本回归函数进行统计检验,以判定估计的可靠程度,包括拟合优度检验、方程总体线性的显著性检验、变量的显著性检验,以及参数的置信区间估计。
检验变量是否具有多重共线性并修正。
检验是否存在异方差并补救。
五、实验步骤1、建立模型。
以国内旅游总花费Y 作为被解释变量,以年底总人口表示人口增长水平,以旅行社数量表示旅行社的发展情况,以城市公共交通运营数表示城市公共交通运行状况,以城乡居民储蓄存款年末增加值表示城乡居民储蓄存款增长水平。
2、模型设定为:t t t t t μβββββ+X +X +X +X +=Y 443322110t 其中:t Y — 国内旅游总花费(亿元) t 1X — 年底总人口(万人) t 2X — 旅行社数量(个) t 3X — 城市公共交通运营数(辆)t 4X — 城乡居民储蓄存款年末增加值(亿元)3、对模型进行多重共线性检验。
4、检验异方差是否存在。
六、实验结果(一)、消除多重共线性之后的模型多元线性回归模型估计结果如下:4321000779.0053329.0151924.0720076.0-99.81113ˆX +X +X +X =Y i SE=(26581.73) (0.230790) (0.108223) (0.013834) (0.020502) t =(3.051494) (-3.120046) (1.403805) ( 3.854988) (0.038020)R2=0.969693R2=0.957571F=79.98987(1)拟合优度检验:可决系数R 2=0.969693较高,修正的可决系数R 2=0.957571也较高,表明模型拟合较好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
异方差问题及其修正案例:中国农村居民人均消费函数 数据:建立模型: μβββ+++=22110ln ln ln X X Y一、模型的OLS 估计 (1)录入数据打开EViews6,点“File”→“New”→“Workfile”选择“Unstructured/Undated”,在Observations 后输入31,如下所示:点“ok”。
在命令行输入:DATA Y X1 X2,回车将数据复制粘贴到Group中的表格中:对变量取对数:在命令行输入命令:GENR lny=log(y) 回车GENR lnx1=log(x1) 回车GENR lnx2=log(x2) 回车(2)估计回归方程在命令行输入命令:LS lny C lnx1 lnx2, 回车 或者在主菜单中点“Quick ”→“Estimate Equation ”,在Specification 中输入 lny C lnx1 lnx2,点“确定”。
得到如下估计结果: 写出回归方程:214775.01502.0266.3ˆLnX LnX Y Ln ++= (3.14) (1.38) (9.25)2R =0.7798 7642.02=R F=49.60 D.W.=1.7810二、模型的异方差检验 1、 图示检验法(1) 作散点图:LnX2——LnY在命令行输入命令:scat lnx2 lny 回车(2)作散点图:LnX2——2~ie 首先生成残差的平方序列,在命令行输入命令:GENR E2=resid^2 回车作散点图: SCAT lnx2 E2 回车(3)作散点图:LnY ——2~ie 在命令行输入命令: SCAT LNY E2 回车2、模型的G-Q检验H:同方差原假设H:异方差备择假设1(1)首先将样本按LnX2由小到大的顺序排列,在命令行输入命令:SORT LnX2回车(2)去除掉中间的7个样本(n/4=7.75,为了使剩下的样本能被平均分成两份,去掉7个),将剩余的24样本平均分为两份,每一份12个样本。
(3)取前面的12个样本,在命令行输入命令:SMPL 1 12回车估计子样本1:LS lnY C lnX1 lnX2 回车得到子样本1的输出结果:写出回归结果:12ˆ 3.1410.3980.235LnY LnX LnX =++ RSS 1=0.0702(4)取最后面的12个样本,在命令行输入命令: SMPL 20 31 回车估计子样本2: LS lnY C lnX1 lnX2 回车得到子样本2的输出结果:写出回归结果:12ˆ 3.9940.1140.620LnY LnX LnX =-+ RSS 1=0.1912(5)计算G-Q 检验的F 统计量:已知子样本1的残差平方和为0.0702,子样本2的残差平方和为0.1912,相应的F 统计量为:220.19120.0702RSS F RSS ===2.73 F 统计量的自由度91227311221=---=---==k c n v v ,给定α=0.05,查F 统计量的临界值,18.3)9,9(05.0=F ,0.10(9,9) 2.44F =,由于F=2.73<3.18,因此,在5%的显著性水平下不拒绝原假设。
F=2.73>2.44,因此在10%的显著性水平下拒绝原假设。
3、 模型的Park 检验帕克检验常用22()()i vi i ji ji Var f X X e αμσσ=== 或者: 22i ij i Lne Ln LnX v σα=++因此,本题中用2i Lne 作为被解释变量,对2i LnX 做回归,然后检验方程的显著性。
首先将样本恢复成全部样本: SMPL 1 31 回车; 在命令行输入命令: LS LOG(E2) C LNX2 回车; 得到下面的输出结果:模型的F 统计量为0.055292,相伴概率P=0.81575>α=0.05,模型整体不显著。
在模型中加入LNX2的平方项,重新估计模型。
输入命令:LS LOG(E2) C LNX2 LNX2^2 回车;得到如下结果:模型的F 统计量为3.5502,P 值为0.0423,小于显著性水平α(0.05),因此模型整体显著,且变量LNX2和LNX2^2的t 统计量的P 值均小于α(0.05),变量均显著。
表明原来的模型中存在异方差,且异方差的形式为:()exp(2)i Var Lne μ≈222exp(93.19625.976 1.701)LnX LnX =-+4、 模型的戈里瑟检验戈里瑟检验通过检验如下方程2()i ji i e f X v =+ 或者 ||()i j i i e f X v =+ 是否显著成立来判断模型是否存在异方差。
首先,以2~ie 为被解释变量,LNX2为解释变量估计模型: 输入命令: LS E2 C LNX2 回车;得到如下结果:模型的F 统计量为2.1888,P 值为0.1498,大于显著性水平α(0.05),因此,模型不显著。
在模型中加入LNX2的平方项,重新估计模型。
输入命令: LS E2 C LNX2 LNX2^2 回车; 得到如下结果:模型的F 统计量为10.1629,P 值为0.00048,小于显著性水平α(0.05),因此模型整体显著,且变量LNX2和LNX2^2的t 统计量的P 值均小于α(0.05),变量均显著。
表明原来的模型中存在异方差,且异方差的形式为:()2i Var E μ≈2222.42860.64670.0432LnX LnX =-+ 5、 模型的White 检验首先采用OLS 估计模型,在弹出的Equation 窗口,点View →Residual Tests →Heteroskedasticity Tests …在弹出的窗口选择“White”,点“OK”。
得到如下输出结果:nR=20.55085,相伴概率P=0.0010,给定α=0.05,从表中可得到怀特检验的统计量:2P<α,因此拒绝同方差的原假设。
三、模型的修正1、加权最小二乘法(WLS)(1)以戈里瑟检验的结果获取权重首先,生成权重数据:genr w1=1/sqr(2.428590-0.646690*lnx2+0.043161*lnx2^2)或者,重新执行估计模型的命令:LS E2 C LNX2 LNX2^2 回车然后在Equation窗口,点击“Forecast”,将预测值保存为E2f1,这也是模型对E2的拟合值,然后生成权重:GENR W1=1/SQR(E2f1);采用加权最小二乘法估计模型:方法1:直接输入命令LS(W=W1) LNY C LNX1 LNX2方法2:在主菜单中点“Quick”→“Estimate Equation”,在Specification中输入LnY C LNX1 LNX2,然后点击“Options”,在弹出的对话框里选择“Weighted LS/TSLS”,然后在“Weight:”后输入权变量名称:w1,点“确定”。
得到如下输出:写出修正后的结果:12ˆ 2.41180.30740.4288LnY LnX LnX =++(3.047) (3.577) (8.374)2R =0.7274 20.7079R = F=37.36 D.W.=1.4786(2)以帕克检验的结果获取权重首先,生成权重数据:genr w2=1/sqr(exp(93.19586-25.97629*lnx2+1.701071*lnx2^2))或者,重新执行估计模型的命令:LS log(E2) C LNX2 LNX2^2 回车然后在Equation 窗口,点击“Forecast ”,将E2预测值保存为E2f2,这也是模型对E2的拟合值,然后生成权重:GENR W2=1/SQR(E2f2);采用加权最小二乘法估计模型:方法1:直接输入命令 LS(W=W2) LNY C LNX1 LNX2方法2:在主菜单中点“Quick ”→“Estimate Equation ”,在Specification 中输入 LnY C LNX1 LNX2,然后点击“Options ”,在弹出的对话框里选择“Weighted LS/TSLS ”,然后在“Weight:”后输入权变量名称:w2,点“确定”。
得到如下输出:写出修正后的结果:12ˆ 2.33820.31770.4287LnY LnX LnX =++ (3.231) (3.817) (9.607)2R =0.7827 20.7672R = F=50.43 D.W.=1.7161(2) 直接用最小二乘估计的残差得到权重生成权重数据: genr w3=1/sqr(e2)估计模型: LS(W=W3) LNY C LNX1 LNX2得到如下输出:写出修正后的结果:12ˆ 3.32660.15090.4679LnY LnX LnX =++ (19.165)(6.082) (47.831)2R =0.9896 20.9888R = F=1325.76 D.W.=1.52292、 异方差稳健标准误法在主菜单中点“Quick ”→“Estimate Equation ”,在Specification 中输入 LnY C LNX1 LNX2,然后点击“Options ”,在弹出的对话框里选择“Heteroskedasticity consistent coefficient ”,点“确定”。
得到如下输出:写出估计结果:12ˆ 3.32660.15020.4775LnY LnX LnX =++ (2.597)(0.9384) (8.3221)2R =0.7799 20.7642R = F=49.6012 D.W.=1.1547。