图的优先遍历算法(C语言版)
图的深度优先遍历(DFS)c++非递归实现

图的深度优先遍历(DFS)c++⾮递归实现深搜算法对于程序员来讲是必会的基础,不仅要会,更要熟练。
ACM竞赛中,深搜也牢牢占据着很重要的⼀部分。
本⽂⽤显式栈(⾮递归)实现了图的深度优先遍历,希望⼤家可以相互学习。
栈实现的基本思路是将⼀个节点所有未被访问的“邻居”(即“⼀层邻居节点”)踹⼊栈中“待⽤”,然后围绕顶部节点猛攻,每个节点被访问后被踹出。
读者可以⾃⼰画图分析⼀下,难度并不⼤。
代码写的⽐较随意,仅供参考。
~#include <iostream>#include <stack>using namespace std;#define MaxNode 20#define MAX 2000#define StartNode 1int map[MaxNode+1][MaxNode+1];void dfs_stack(int start, int n){int visited[MaxNode],s_top;for(int i = 0;i <= MaxNode; i++){visited[i] = 0;}visited[start] = 1;stack <int> s;cout<<start<<"";for(int i = 1; i <= n; i++){if(map[i][start] == 1 && !visited[i] ){visited[i] = 1;s.push(i);}}while(!s.empty()){s_top = s.top();visited[s_top] = 1;cout<<s_top<<"";s.pop();for(int i = 1; i <= n; i++){if(map[i][s_top] == 1 && !visited[i] ){visited[i] = 1;s.push(i);}}}}int main(int argc, const char * argv[]) {int num_edge,num_node;int x,y;cout<<"Input number of nodes and edges >"<<endl;cin>>num_node>>num_edge;for(int i =0;i<num_node;i++){for(int j=0;j<num_node;j++){map[i][j] = 0;}}for(int i = 1; i <= num_edge; i++){cin>>x>>y;map[x][y] = map[y][x] = 1;}dfs_stack(StartNode, num_node);return0;}。
C语言常用算法概述

C语言常用算法概述C语言作为一种通用的高级编程语言,广泛应用于计算机科学领域,特别是在算法和数据结构方面。
C语言提供了许多常用算法,这些算法能够解决各种计算问题,并提供了高效的解决方案。
本文将概述C语言中常用的算法,包括排序算法、查找算法和图算法。
一、排序算法排序算法是将一组元素按照特定的顺序排列的算法。
C语言提供多种排序算法,下面将介绍几种常用的排序算法。
1. 冒泡排序冒泡排序是一种简单的排序算法,它通过多次遍历数组,每次比较相邻的两个元素,将较大的元素向后移动。
通过多次遍历,最大的元素会逐渐“冒泡”到数组的末尾。
2. 插入排序插入排序是一种稳定的排序算法,它通过将数组分为已排序和未排序两部分,将未排序的元素逐个插入已排序的部分,使得整个数组逐渐有序。
3. 快速排序快速排序是一种高效的排序算法,它通过选择一个基准元素,将数组分成两个子数组,其中一个子数组中的元素都小于基准,另一个子数组中的元素都大于基准。
然后递归地对两个子数组进行排序。
4. 归并排序归并排序是一种稳定的排序算法,它通过将数组划分为多个子数组,然后将这些子数组逐个合并,最终得到有序的数组。
归并排序使用了分治的思想,对子数组进行递归排序。
二、查找算法查找算法用于在一个集合中寻找特定元素的算法。
C语言提供了多种查找算法,下面将介绍两种常用的查找算法。
1. 顺序查找顺序查找是一种简单的查找算法,它通过逐个比较集合中的元素,直到找到需要查找的元素或者遍历完整个集合。
2. 二分查找二分查找是一种高效的查找算法,它要求集合必须有序。
它通过将集合分成两半,然后比较需要查找的元素与中间元素的大小关系,从而确定下一步查找的范围。
三、图算法图算法用于解决图结构相关的计算问题。
C语言提供了多种图算法,下面将介绍两种常用的图算法。
1. 深度优先搜索深度优先搜索是一种用于遍历或搜索图的算法,它通过从一个顶点出发,依次访问与该顶点相邻的未访问过的顶点。
当无法再继续访问时,回退到上一个顶点继续搜索。
先序遍历的递归算法c语言

先序遍历的递归算法c语言先序遍历是二叉树遍历的一种方法,它的遍历顺序是先访问根结点,然后递归地先序遍历左子树,最后递归地先序遍历右子树。
在C语言中,我们可以通过递归算法来实现二叉树的先序遍历。
首先,我们需要定义二叉树的结构体,包括树的节点结构以及创建树的函数。
树的节点结构体定义如下:```ctypedef struct TreeNode {int data;struct TreeNode* left;struct TreeNode* right;} TreeNode;```接下来,我们可以编写递归函数来实现先序遍历。
先序遍历的递归算法如下:```cvoid preorderTraversal(TreeNode* root) {if (root == NULL) {return;}printf("%d ", root->data); // 访问根结点preorderTraversal(root->left); // 递归遍历左子树preorderTraversal(root->right); // 递归遍历右子树}```在这段代码中,我们首先判断根结点是否为空,如果为空则直接返回。
然后,我们先访问根结点的数据,然后递归地对左子树和右子树进行先序遍历。
接下来,我们可以编写一个测试函数来创建二叉树并进行先序遍历:```cint main() {// 创建二叉树TreeNode* root = (TreeNode*)malloc(sizeof(TreeNode));root->data = 1;root->left = (TreeNode*)malloc(sizeof(TreeNode));root->left->data = 2;root->left->left = NULL;root->left->right = NULL;root->right = (TreeNode*)malloc(sizeof(TreeNode));root->right->data = 3;root->right->left = NULL;root->right->right = NULL;// 先序遍历二叉树printf("Preorder traversal: ");preorderTraversal(root);return 0;}```在这个测试函数中,我们首先创建了一个简单的二叉树,然后调用先序遍历函数对这棵树进行遍历,并输出遍历结果。
c语言 优先级算法

c语言优先级算法在C语言中,优先级算法是一种常用的算法,用于确定多个任务之间的执行顺序。
优先级算法可以根据任务的重要性或紧急程度决定任务的优先级,进而影响任务的执行顺序。
本文将介绍C语言中常用的几种优先级算法,并给出相应的代码示例。
一、静态优先级算法静态优先级算法是指在编写程序时,为每个任务分配一个预先确定的优先级,而不会在运行时改变。
静态优先级算法可以通过宏定义或全局变量来定义任务的优先级。
在实际应用中,可以根据任务的重要性和紧急程度来合理分配任务的优先级。
下面是一个使用静态优先级算法的示例代码:```c#include <stdio.h>#define PRIORITY_A 1#define PRIORITY_B 2#define PRIORITY_C 3void taskA() {printf("This is task A\n");}void taskB() {printf("This is task B\n");}void taskC() {printf("This is task C\n");}int main() {// 任务执行顺序:taskC -> taskB -> taskAtaskC();taskB();taskA();return 0;}```在上述代码中,我们为任务A、任务B和任务C定义了不同的优先级,并在`main`函数中按照优先级顺序调用这些任务。
根据定义的优先级,最终的任务执行顺序为taskC -> taskB -> taskA。
二、动态优先级算法动态优先级算法是指在运行时根据任务的状态和其他因素来动态地调整任务的优先级。
常用的动态优先级算法有抢占式优先级算法和时间片轮转算法。
1. 抢占式优先级算法抢占式优先级算法是指在任务执行过程中,如果有更高优先级的任务需要执行,则会抢占当前正在执行的任务,并立即执行更高优先级的任务。
深度优先遍历算法实现及复杂度分析

深度优先遍历算法实现及复杂度分析深度优先遍历算法(Depth First Search, DFS)是一种常用的图遍历算法,用于查找或遍历图的节点。
本文将介绍深度优先遍历算法的实现方法,并进行对应的复杂度分析。
一、算法实现深度优先遍历算法的基本思想是从图的某个节点出发,沿着深度方向依次访问其相邻节点,直到无法继续下去,然后返回上一层节点继续遍历。
下面是深度优先遍历算法的伪代码:```1. 初始化访问标记数组visited[],将所有节点的访问标记置为false。
2. 从某个节点v开始遍历:- 标记节点v为已访问(visited[v] = true)。
- 访问节点v的相邻节点:- 若相邻节点w未被访问,则递归调用深度优先遍历算法(DFS(w))。
3. 遍历结束,所有节点都已访问。
```二、复杂度分析1. 时间复杂度深度优先遍历算法的时间复杂度取决于图的存储方式和规模。
假设图的节点数为V,边数为E。
- 邻接表存储方式:对于每个节点,需要访问其相邻节点。
因此,算法的时间复杂度为O(V+E)。
- 邻接矩阵存储方式:需要检查每个节点与其他节点的连通关系,即需要遍历整个邻接矩阵。
因此,算法的时间复杂度为O(V^2)。
2. 空间复杂度深度优先遍历算法使用了一个辅助的访问标记数组visited[]来记录每个节点的访问状态。
假设图的节点数为V。
- 邻接表存储方式:访问标记数组visited[]的空间复杂度为O(V)。
- 邻接矩阵存储方式:访问标记数组visited[]的空间复杂度同样为O(V)。
综上所述,深度优先遍历算法的时间复杂度为O(V+E),空间复杂度为O(V)。
三、应用场景深度优先遍历算法在图的遍历和搜索问题中广泛应用。
以下是一些典型的应用场景:1. 连通性问题:判断图中两个节点之间是否存在路径。
2. 非连通图遍历:对于非连通图,深度优先遍历算法可以用于遍历所有连通分量。
3. 寻找路径:在图中寻找从起始节点到目标节点的路径。
C语言算法全总结

C语言算法全总结C语言是一种广泛应用于计算机科学领域的编程语言,具有高效、可移植和灵活的特点。
在程序设计中,算法是解决问题的一系列有序步骤,可以通过C语言来实现。
本文将为您总结C语言中常用的算法,包括排序算法、查找算法和图算法。
一、排序算法排序算法是将一组元素按照特定的顺序重新排列的算法。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序和归并排序。
这些算法的核心思想是通过比较和交换元素的位置来进行排序。
1.冒泡排序冒泡排序通过多次比较和交换相邻元素的位置来实现排序。
它的基本思想是将最大的元素不断地往后移动,直到整个序列有序。
2.选择排序选择排序通过每次选择最小的元素来实现排序。
它的基本思想是通过比较找到最小元素的位置,然后将其与第一个元素交换,接着在剩下的元素中继续找到最小元素并进行交换,如此重复直到整个序列有序。
3.插入排序插入排序通过构建有序序列,对未排序序列逐个元素进行插入,从而实现排序。
它的基本思想是将当前元素插入到前面已经排好序的序列中的适当位置。
4.快速排序快速排序是一种分治算法,通过选择一个基准元素,将其他元素划分为小于基准元素和大于基准元素的两部分,然后递归地对这两部分进行排序,最终实现整个序列有序。
5.归并排序归并排序也是一种分治算法,将序列分成两个子序列,分别对这两个子序列进行排序,然后将排序后的子序列合并成一个有序序列,从而达到整个序列有序的目的。
二、查找算法查找算法是在一个数据集合中寻找特定元素的算法。
常见的查找算法包括线性查找、二分查找和散列查找。
这些算法的核心思想是通过比较元素的值来确定待查找元素的位置。
1.线性查找线性查找是从数据集合的开头开始,依次比较每个元素的值,直到找到目标元素为止。
它的时间复杂度为O(n),其中n为数据集合的大小。
2.二分查找二分查找是针对有序序列进行查找的算法,它的基本思想是通过不断缩小查找范围,将目标元素与中间元素进行比较,从而确定待查找元素的位置。
c语言二叉树的先序,中序,后序遍历
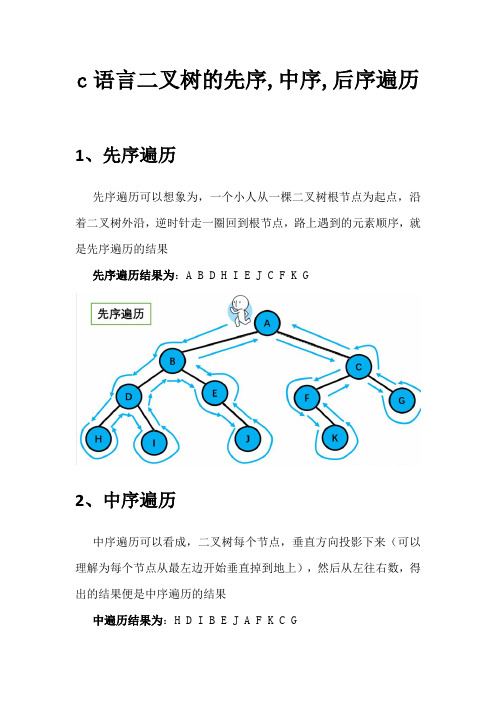
c语言二叉树的先序,中序,后序遍历1、先序遍历先序遍历可以想象为,一个小人从一棵二叉树根节点为起点,沿着二叉树外沿,逆时针走一圈回到根节点,路上遇到的元素顺序,就是先序遍历的结果先序遍历结果为:A B D H I E J C F K G2、中序遍历中序遍历可以看成,二叉树每个节点,垂直方向投影下来(可以理解为每个节点从最左边开始垂直掉到地上),然后从左往右数,得出的结果便是中序遍历的结果中遍历结果为:H D I B E J A F K C G3、后序遍历后序遍历就像是剪葡萄,我们要把一串葡萄剪成一颗一颗的。
还记得我上面提到先序遍历绕圈的路线么?(不记得翻上面理解)就是围着树的外围绕一圈,如果发现一剪刀就能剪下的葡萄(必须是一颗葡萄)(也就是葡萄要一个一个掉下来,不能一口气掉超过1个这样),就把它剪下来,组成的就是后序遍历了。
后序遍历中,根节点默认最后面后序遍历结果:H I D J E B K F G C A4、口诀先序遍历:先根再左再右中序遍历:先左再根再右后序遍历:先左再右再根这里的根,指的是每个分叉子树(左右子树的根节点)根节点,并不只是最开始头顶的根节点,需要灵活思考理解5、代码展示#include<stdio.h>#include<stdlib.h>typedef struct Tree{int data; // 存放数据域struct Tree *lchild; // 遍历左子树指针struct Tree *rchild; // 遍历右子树指针}Tree,*BitTree;BitTree CreateLink(){int data;int temp;BitTree T;scanf("%d",&data); // 输入数据temp=getchar(); // 吸收空格if(data == -1){ // 输入-1 代表此节点下子树不存数据,也就是不继续递归创建return NULL;}else{T = (BitTree)malloc(sizeof(Tree)); // 分配内存空间T->data = data; // 把当前输入的数据存入当前节点指针的数据域中printf("请输入%d的左子树: ",data);T->lchild = CreateLink(); // 开始递归创建左子树printf("请输入%d的右子树: ",data);T->rchild = CreateLink(); // 开始到上一级节点的右边递归创建左右子树return T; // 返回根节点}}// 先序遍历void ShowXianXu(BitTree T) // 先序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}printf("%d ",T->data);ShowXianXu(T->lchild); // 递归遍历左子树ShowXianXu(T->rchild); // 递归遍历右子树}// 中序遍历void ShowZhongXu(BitTree T) // 先序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}ShowZhongXu(T->lchild); // 递归遍历左子树printf("%d ",T->data);ShowZhongXu(T->rchild); // 递归遍历右子树}// 后序遍历void ShowHouXu(BitTree T) // 后序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}ShowHouXu(T->lchild); // 递归遍历左子树ShowHouXu(T->rchild); // 递归遍历右子树printf("%d ",T->data);}int main(){BitTree S;printf("请输入第一个节点的数据:\n");S = CreateLink(); // 接受创建二叉树完成的根节点printf("先序遍历结果: \n");ShowXianXu(S); // 先序遍历二叉树printf("\n中序遍历结果: \n");ShowZhongXu(S); // 中序遍历二叉树printf("\n后序遍历结果: \n");ShowHouXu(S); // 后序遍历二叉树return 0;}。
图的深度优先遍历的C语言实现

图的深度优先遍历的C语言实现
杜恒;龚茜茹
【期刊名称】《九江职业技术学院学报》
【年(卷),期】2004(000)002
【摘要】图的深度优先遍历,是对图中的每个顶点进行访问且不能重复访同,而我们要遍历图,不是在它的逻辑结构上来实现,而是要在内存中来实现,在这里我们可以先把图采用邻接表方式将图存储起来,然后进行深度优先遍历.
【总页数】3页(P26-28)
【作者】杜恒;龚茜茹
【作者单位】河南工业职业技术学院,河南,南阳,473009;河南工业职业技术学院,河南,南阳,473009
【正文语种】中文
【中图分类】TP312C
【相关文献】
1.图的深度优先遍历算法及运用 [J], 周泰
2.深度优先遍历图的非递归算法的改进 [J], 王荣
3.基于有向图深度优先遍历的组合反馈环路检测算法 [J], 倪韬雍;金乃咏
4.图的深度优先遍历智能化分析与实现 [J], 林尚垣
5.数据结构中图的深度优先遍历算法与实现 [J], 贾学斌
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include<stdio.h>
#define MAX_VERTEX_NUM 20
#define ERROR -1
#define TRUE 1
#define FALSE 0
typedef struct ArcNode{
int adjvex;
struct ArcNode *nextarc;
}ArcNode;
typedef struct VNode{
char data;
ArcNode *firstarc;
}VNode,AdjList[MAX_VERTEX_NUM];
typedef struct {
AdjList vertices;
int vexnum,arcnum;
}ALGraph;
void CreateAL(ALGraph *G);
int LocateVex(ALGraph G,char u);
void DFSTraverse(ALGraph G,void (*Visit)(ALGraph G,int v)); void PrintElem(ALGraph G,int v);
void DFS(ALGraph G,int v);
int FirstAdjVex(ALGraph G,int v);
int NextAdjVex(ALGraph G,int v,int w);
int visited[MAX_VERTEX_NUM];
void (*VisitFunc)(ALGraph G,int v);
int main(){
ALGraph G;
CreateAL(&G);
printf("The Graph is:\n");
DFSTraverse(G,PrintElem);
getch();
}
void CreateAL(ALGraph *T){
int i,j,m;
ArcNode *p,*s;
char ch[100];
printf("Please input the vexnum and arcnumm:\n");
scanf("%d%d",&(T->vexnum),&(T->arcnum));
printf("Please input the vertexs:\n");
for(i=0;i<(T->vexnum);++i){
scanf(" %c",&(T->vertices[i].data));
T->vertices[i].firstarc=NULL;
}
for(i=0;i<(T->vexnum);++i){
m=0;
printf("Please input the adjacents of %c\n",T->vertices[i].data);
scanf(" %s",&ch);
j=LocateVex(*T,ch[0]);
p=(ArcNode *)malloc(sizeof(ArcNode));
p->adjvex=j;
p->nextarc=NULL;
T->vertices[i].firstarc=p;
while(ch[++m]!='\0'){
j=LocateVex(*T,ch[m]);
s=(ArcNode *)malloc(sizeof(ArcNode));
s->adjvex=j;
s->nextarc=NULL;
p->nextarc=s;
p=s;
}
}
}
int LocateVex(ALGraph G,char u){
int j;
int i=sizeof(G.vertices)/sizeof(VNode);
for(j=0;j<i;j++){
if(u==G.vertices[j].data)
return j;
}
printf("Can not find the vertex! Please press any key to exit\n");
getchar();
getchar();
exit(ERROR);
}
void DFSTraverse(ALGraph G,void (*Visit)(ALGraph G,int v)){ int v;
VisitFunc=Visit;
for(v=0;v<G.vexnum;++v)
visited[v]=FALSE;
for(v=0;v<G.vexnum;++v)
if(!visited[v]) DFS(G,v);
}
void DFS(ALGraph G,int v){
int w;
visited[v]=TRUE;
VisitFunc(G,v);
for(w=FirstAdjVex(G,v);w>=0;w=NextAdjVex(G,v,w))
if(!visited[w]) DFS(G,w);
}
void PrintElem(ALGraph G,int v){
printf(" %3c",G.vertices[v].data);
}
int FirstAdjVex(ALGraph G,int v){
ArcNode *p=G.vertices[v].firstarc;
return p->adjvex;
}
int NextAdjVex(ALGraph G,int v,int w){
ArcNode *p,*s;
for(p=G.vertices[v].firstarc;p!=NULL;p=p->nextarc){ if(((p->adjvex)==w)&&(p->nextarc)){
s=p->nextarc;
return s->adjvex;
}
}
return ERROR;
}。