编译原理词法分析和语法分析报告+代码(C语言版)
编译原理_词法分析器_C语言版_简单易懂

#include<stdio.h>#include<string.h>char ch,token[8],prog[80];char *a[6]={"标示符","整常数","if","else","while","for"}; int p,i,sum,m,n;panduan();main(){p=0;printf("please input string :\n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{panduan();switch(i){case 1:printf("(%s,%d,指向%s在符号表的入口)\n",token,i,token); break;case 2:printf("(%d,%d,指向%d在符号表的入口)\n",sum,i,sum); break;case -1:printf("error!");default: printf("(%s,%d,-)\n",token,i);break;}}while(i!=0);printf("词法分析成功!\n");}panduan(){sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&( ch<='9' ))){token[m++]=ch;ch=prog[p++];}p--;i=1;//如果是字母,输出的标示类别为for(n=0;n<6;n++)if(strcmp(token,a[n])==0){i=n+1;break;}}else if((ch>='0')&&(ch<='9')) {while((ch>='0')&&(ch<='9')) {sum=sum*10+ch-'0';ch=prog[p++];}p--;i=2;}else switch(ch)// 以下为自己定义符号类的标示类别号{case'<': i=39;token[m++]=ch;break;case'<=': i=40;token[m++]=ch;break;case'>':i=41;token[m++]=ch;break;case'+': i=35;token[m++]=ch;break;case'-':i=36;token[m++]=ch; break;case'=':i=37; token[m++]=ch; break;case'==':i=38; token[m++]=ch; break;case'*': i=15; token[m++]=ch; break;case'(': i=55; token[m++]=ch; break;case')': i=56; token[m++]=ch; break;case';': i=57; token[m++]=ch; break;case'#': i=0; token[m++]=ch; break;default: i=-1; break;}token[m++]='\0'; }。
编译原理的词法分析代码

Pl0.h 和S1.c编译原理词法分析程序(C语言)/*头文件pl0.h*/#define al 10/*符号的最大长度*/#define nmax 14/*number的最大位数*/#define norw 8/*关键字个数*/char ch;/*获取字符的缓冲区,getch使用*/int cc,ll;/*cc表示当前字符(ch)的位置*/char line[81];/*读取行缓冲区*/char a[al+1];/*临时符号,多处的字节用于存放0*/ char anum[nmax+1];/*临时符号,存放number*/ char inum[nmax+1];/*存放常数*/char word[norw][al];/*保留字*/char fname[al];/*文件名*/char id[al+1];/*存放标识符或保留字*/int num;/*常数*/int err;//错误计数器FILE * fin;FILE * fout;FILE * fas;/*词法分析结果文件*//*函数执行出错,退出程序*/#define getchdo if(-1==getch()) return -1#define getsymdo if(-1==getsym()) return -1 int getch();/*读取一行字符*/int getsym();/*读取一个分词*//*主程序*//**运行环境:Microsoft visual c++ 6.0*//**程序功能要求:*编制一个读单词过程,源程序为一个文件,读取该文件,识别出各个具有独立意义的单词,*即基本保留字、标识符、常数、运算符、界符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
*单词的内部编码如下:*1.保留字:if、int、for、while、do、return、break、continue;单词种别码为1;*2.标识符:除保留字外的以字母开头,后跟字母、数字的字符序列;单词种别码为2;*3.常数为无符号整形数;单词种别码为3;*4.运算符包括:+、-、*、/、=;单词种别码为4;*5.分隔符包括:,、;、{、}、(、);单词种别码为5。
C语言 编译原理实现词法分析程序

case '>':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=24;
token[m++]=ch;
}
{ syn=17;
token[m++]=ch;
}
else
{ syn=13;
p--;
}
break;
{ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
{ sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else switch(ch)
{ case '<':token[m++]=ch;
ch=prog[p++];
break;
default: syn=-1;
break;
}
token[m++]='\0';
}
编译原理----词法分析程序----C语言版

编译原理----词法分析程序----C语⾔版#include<stdio.h>#include<string.h>#include<stdlib.h>char KeyWord[20][100]={"begin","end","if","while","var","procedure","else","for","do","int","read","write"};char yunsuanfu[]="+-*/<>%=";char fenjiefu[]=",;(){}:";int main(){char test[]="var a=10;\nvar b,c;\nprocedure p; \n\tbegin\n\t\tc=a+b\n\tend\n";int len_yunsuanfu=strlen(yunsuanfu);int len_fenjiefu=strlen(fenjiefu);puts(test);int length=strlen(test),i,j,k;for(i=0;i<length;i++){if(test[i]==' '||test[i]=='\n'||test[i]=='\t')continue;int tag=0;for(j=0;j<len_fenjiefu;j++){if(fenjiefu [j]==test[i]){printf("分界符\t%c\n",test[i]);tag=1;break;}}if(tag==1)continue;tag=0;for(j=0;j<len_yunsuanfu;j++){if(yunsuanfu[j]==test[i]){printf("运算符\t%c\n",test[i]);tag=1;break;}}if(tag==1)continue;if(test[i]>='0'&&test[i]<='9'){printf("数字\t");while(test[i]>='0'&&test[i]<='9'){printf("%c",test[i]);i++;}printf("\n");continue;}char temp[100];j=0;while(test[i]>='0'&&test[i]<='9'||test[i]>='a'&&test[i]<='z'||test[i]>='A'&&test[i]<='Z'||test[i]=='_') {temp[j++]=test[i];i++;}i--;temp[j++]='\0';tag=0;for(j=0;j<20;j++){if(strcmp(temp,KeyWord[j])==0){tag=1;printf("关键字\t%s\n",temp);break;}}if(tag==0)printf("标识符\t%s\n",temp);}}。
编译原理词法分析和语法分析报告 代码(C语言版)
admit=0;
for(in=0;in<cal-1;in++){str[in]=str[in+1];}
str[in]='\0';
cal--;
r_find=r_find->next;
}//:入栈~
if(r_find->line_States==s_find->num&&r_find->rank_Letter==str[0]&&r_find->name=='r'){//:规约
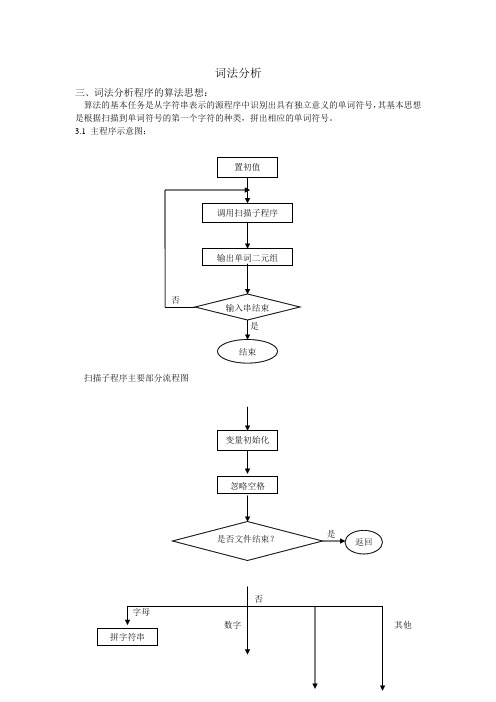
词法分析
三、词法分析程序的算法思想:
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1主程序示意图:
否
是
扫描子程序主要部分流程图
是是
否
字母
数字其他
运算符、符号
界符等符号
否
是
词法分析程序的C语言程序源代码:
//词法分析函数: void scan()
//数据传递:形参fp接收指向文本文件头的文件指针;
//全局变量buffer与line对应保存源文件字符及其行号,char_num保存字符总数。
void scan()
{
char ch;
int flag,j=0,i=-1;
while(!feof(fp1))
{
ch=fgetc(fp1);
flag=judge(ch);
struct Sign *next;
(完整word版)编译原理语法分析报告+代码
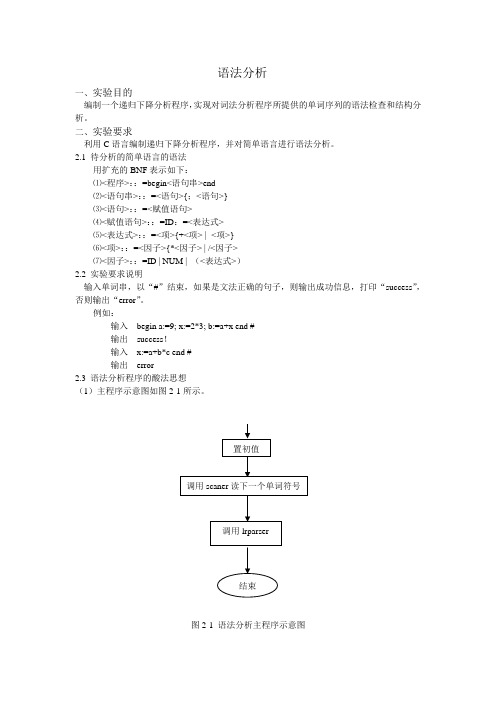
语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的酸法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的C语言程序源代码:#include "stdio.h"#include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"};int syn,p,m,n,sum;int kk;factor();expression();yucu();term();statement();lrparser();scaner();main(){p=kk=0;printf("\nplease input a string (end with '#'): \n");do{ scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。
【2017年整理】编译原理词法分析报告代码(C语言版)[1]
![【2017年整理】编译原理词法分析报告代码(C语言版)[1]](https://img.taocdn.com/s3/m/fc3dea18f02d2af90242a8956bec0975f465a48b.png)
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:表2.1 各种单词符号对应的种别码输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
编译原理课程设计报告C语言词法与语法分析器的实现

编写原理课程设计报告题目:编译原理课程设计C语言词法和语法分析器的实现C-词法和语法分析器的实现1.课程设计目标(1)题目的实用性C语言具有完整语言的基本属性,写C语言的词法分析和语法分析对理解编译原理的相关理论和知识会起到很大的作用。
通过编写C语言词法和语法分析程序,可以对编译原理的相关知识:正则表达式、有限自动机、语法分析等有一个清晰的认识和掌握。
(2)C语言的词法描述①语言的关键词:else if int返回void while的所有关键字都是保留字,必须小写。
②特殊符号:+ - * / < <= > >= == != = ;, ( ) [ ] { } /* */③其他标记是ID和NUM,它们由以下正则表达式定义:ID =字母字母*NUM =数字数字*字母= a|..|z|A|..|Zdigit = 0|..|9注:ID表示标识符,NUM表示数字,letter表示字母,digit表示数字。
小写字母和大写字母是有区别的。
④它由空格、换行符和制表符组成。
空格通常会被忽略。
⑤用常用的C语言符号/*将注释括起来...*/.注释可以放在任何空白位置(也就是注释不能放在标记上),可以多行。
注释不能嵌套。
(3)规划目标能够正确分析程序的词法和语法。
2.分析和设计(1)设计理念a.词汇分析词法分析的实现主要使用有限自动机理论。
有限自动机可以用来描述识别输入字符串中模式的过程,因此也可以用来构造扫描程序。
词法分析器可以很容易地用有限自动机理论来设计。
b.语法分析语法分析采用递归下降分析法。
递归下降法是语法分析中最容易理解的方法。
其主要原理是根据每个非终结符的产生式结构为其构造相应的解析子程序,其中终结符生成匹配命令,非终结符生成过程调用命令。
这种方法被称为递归子例程下降法或递归下降法,因为语法递归的相应子例程也是递归的。
子程序的结构与产生式的结构几乎相同。
(2)程序流程图主程序流程图:词法分析:语法分析:词汇分析子流程图:语法分析子流程图:3.程序代码实现整个词法与语法程序设计在同一个项目中,包含八个文件,分别是main.cpp、parse.cpp、scan.cpp、util.cpp、scan.h、util.h、globals.h和parse.h,其中scan.cpp和scan.h是词法分析程序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。
扫描子程序主要部分流程如图3-2所示。
图3-2 四、词法分析程序的C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"}; scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=22;token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch;ch=prog[p++];if(ch=='+'){ syn=17;token[m++]=ch;}else{ syn=13;p--;}break;case '-':token[m++]=ch;ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++];if(ch=='='){ syn=21;token[m++]=ch;}else{ syn=31;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch;break;case '/': syn=16;token[m++]=ch;break;case '(': syn=27;token[m++]=ch;break;case ')': syn=28;token[m++]=ch;break;case '{': syn=5;token[m++]=ch;break;case '}': syn=6;token[m++]=ch;break;case ';': syn=26;token[m++]=ch;break;case '\"': syn=30;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;default: syn=-1;break;}token[m++]='\0';}五、结果分析:输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:图5-1六、总结:词法分析的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
通过本试验的完成,更加加深了对词法分析原理的理解。
语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的酸法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的C语言程序源代码:#include "stdio.h"#include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"};int syn,p,m,n,sum;int kk;factor();expression();yucu();term();statement();lrparser();scaner();main(){p=kk=0;printf("\nplease input a string (end with '#'): \n");do{ scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。