模糊控制系统设计教程
模糊PID控制器的设计与仿真——设计步骤(修改)

模糊PID控制器的设计与仿真设计模糊PID控制器时,首先要将精确量转换为模糊量,并且要把转换后的模糊量映射到模糊控制论域当中,这个过程就是精确量模糊化的过程。
模糊化的主要功能就是将输入量精确值转换成为一个模糊变量的值,最终形成一个模糊集合。
本次设计系统的精确量包括以下变量:变化量e ,变化量的变化速率ec 还有参数整定过程中的输出量ΔKP ,ΔKD,ΔKI,在设计模糊PID 的过程中,需要将这些精确量转换成为模糊论域上的模糊值。
本系统的误差与误差变化率的模糊论域与基本论域为:E=[-6,-4,-2,0,2,4,6];Ec=[-6,-4,-2,0,2,4,6]。
模糊PID控制器的设计选用二维模糊控制器。
以给定值的偏差e和偏差变化ec为输入;ΔKP ,ΔKD,ΔKI为输出的自适应模糊PID控制器,见图1。
图1模糊PID控制器(1)模糊变量选取输入变量E和EC的模糊化将一定范围(基本论域)的输入变量映射到离散区间(论域)需要先验知识来确定输入变量的范围。
就本系统而言,设置语言变量取七个,分别为 NB,NM,NS,ZO,PS,PM,PB。
(2)语言变量及隶属函数根据控制要求,对各个输入,输出变量作如下划定:e,ec论域:{-6,-5,-4,-3,-2,-1,0,1,2,3,4,5,6}ΔKP ,ΔKD,ΔKI论域:{-6,-5,-4,-3,-2,-1,0,1,2,3,4,5,6}应用模糊合成推理PID参数的整定算法。
第k个采样时间的整定为).()(,)()(,)()(kKKkKkKKkKkKKkKDDDIIIPPP∆+=∆+=∆+=式中,,DIPKKK为经典PID控制器的初始参数。
设置输入变量隶属度函数如图2所示,输出变量隶属度函数如图3所示。
图2 输入变量隶属度函图3 输出变量隶属度函(3)编辑模糊规则库根据以上各输出参数的模糊规则表,可以归纳出49条控制逻辑规则,具体的控制规则如下所示:1.If (e is NB) and (ec is NB) then (kp is NB)(ki is PB)(kd is NS)(1)2.If (e is NB) and (ec is NM) then (kp is NB)(ki is PB)(kd is PS)(1)3.If (e is NB) and (ec is NS) then (kp is NM)(ki is PM)(kd is PB)(1)4.If (e is NB) and (ec is ZO) then (kp is NM)(ki is PM)(kd is PB)(1)5.If (e is NB) and (ec is PS) then (kp is NS)(ki is PS)(kd is PB)(1)6.If (e is NB) and (ec is PM) then (kp is ZO)(ki is ZO)(kd is PM)(1)7.If (e is NB) and (ec is PB) then (kp is ZO)(ki is ZO)(kd is NS)(1)8.If (e is NM) and (ec is NB) then (kp is NB)(ki is PB)(kd is NS)(1)9.If (e is NM) and (ec is NM) then (kp is NB)(ki is PB)(kd is PS)(1)10.If (e is NM) and (ec is NS) then (kp is NM)(ki is PM)(kd is PB)(1)11.If (e is NM) and (ec is ZO) then (kp is NS)(ki is PS)(kd is PM)(1)12.If (e is NM) and (ec is PS) then (kp is NS)(ki is PS)(kd is PM)(1)13.If (e is NM) and (ec is PM) then (kp is ZO)(ki is ZO)(kd is PS)(1)14.If (e is NM) and (ec is PB) then (kp is PS)(ki is ZO)(kd is ZO)(1)15.If (e is NS) and (ec is NB) then (kp is NM)(ki is PB)(kd is ZO)(1)16.If (e is NS) and (ec is NM) then (kp is NM)(ki is PM)(kd is PS)(1)17.If (e is NS) and (ec is NS) then (kp is NM)(ki is PS)(kd is PM)(1)18.If (e is NS) and (ec is ZO) then (kp is NS)(ki is PS)(kd is PM)(1)19.If (e is NS) and (ec is PS) then (kp is ZO)(ki is ZO)(kd is PS)(1)20.If (e is NS) and (ec is PM) then (kp is PS)(ki is NS)(kd is PS)(1)21.If (e is NS) and (ec is PB) then (kp is PS)(ki is NS)(kd is ZO)(1)22.If (e is ZO) and (ec is NB) then (kp is NM)(ki is PM)(kd is ZO)(1)23.If (e is ZO) and (ec is NM) then (kp is NM)(ki is PM)(kd is PS)(1)24.If (e is ZO) and (ec is NS) then (kp is NS)(ki is PS)(kd is PS)(1)25.If (e is ZO) and (ec is ZO) then (kp is ZO)(ki is ZO)(kd is PS)(1)26.If (e is ZO) and (ec is PS) then (kp is PS)(ki is NS)(kd is PS)(1)27.If (e is ZO) and (ec is PM) then (kp is PM)(ki is NM)(kd is PS)(1)28.If (e is ZO) and (ec is PB) then (kp is PM)(ki is NM)(kd is ZO)(1)29.If (e is PS) and (ec is NB) then (kp is NS)(ki is PM)(kd is ZO)(1)30.If (e is PS) and (ec is NM) then (kp is NS)(ki is PS)(kd is ZO)(1)31.If (e is PS) and (ec is NS) then (kp is ZO)(ki is ZO)(kd is ZO)(1)32.If (e is PS) and (ec is ZO) then (kp is PS)(ki is NS)(kd is ZO)(1)33.If (e is PS) and (ec is PS) then (kp is PS)(ki is NS)(kd is ZO)(1)34.If (e is PS) and (ec is PM) then (kp is PM)(ki is NM)(kd is ZO)(1)35.If (e is PS) and (ec is PB) then (kp is PM)(ki is NB)(kd is ZO)(1)36.If (e is PM) and (ec is NB) then (kp is NS)(ki is ZO)(kd is NB)(1)37.If (e is PM) and (ec is NM) then (kp is ZO)(ki is ZO)(kd is PS)(1)38.If (e is PM) and (ec is NS) then (kp is PS)(ki is NS)(kd is NS)(1)39.If (e is PM) and (ec is ZO) then (kp is PM)(ki is NS)(kd is NS)(1)40.If (e is PM) and (ec is PS) then (kp is PM)(ki is NM)(kd is NS)(1)41.If (e is PM) and (ec is PM) then (kp is PM)(ki is NB)(kd is NS)(1)42.If (e is PM) and (ec is PB) then (kp is PB)(ki is NB)(kd is NB)(1)43.If (e is PB) and (ec is NB) then (kp is ZO)(ki is ZO)(kd is NB)(1)44.If (e is PB) and (ec is NM) then (kp is ZO)(ki is ZO)(kd is NM)(1)45.If (e is PB) and (ec is NS) then (kp is PM)(ki is NS)(kd is NM)(1)46.If (e is PB) and (ec is ZO) then (kp is PM)(ki is NM)(kd is NM)(1)47.If (e is PB) and (ec is PS) then (kp is PM)(ki is NM)(kd is NS)(1)48.If (e is PB) and (ec is PM) then (kp is PB)(ki is NB)(kd is NS)(1)49.If (e is PB) and (ec is PB) then (kp is PB)(ki is NB)(kd is NB)(1) 把这49条控制逻辑规则,键入到模糊规则库中,如图4。
模糊控制系统课件
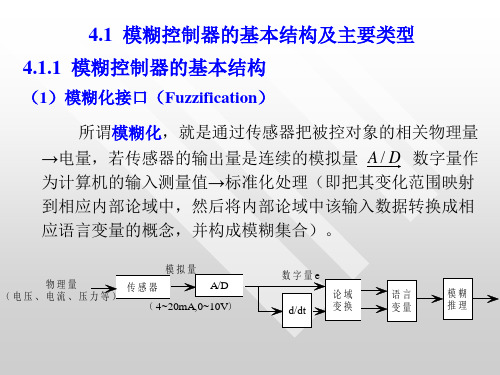
(1)模糊化接口(Fuzzification)
所谓模糊化,就是通过传感器把被控对象的相关物理量 →电量,若传感器的输出量是连续的模拟量 A / D 数字量作 为计算机的输入测量值→标准化处理(即把其变化范围映射 到相应内部论域中,然后将内部论域中该输入数据转换成相 应语言变量的概念,并构成模糊集合)。
量化因子:K e
2n1 eH eL
, Kec
2n2 eH eL
,
比例因子:
Ku
uH uL 2m
注:误差和误差变化这两个变量的连续值与其论域中的离散值
并不是一一对应的。
(2)模糊推理机(Inference engine) 模糊推理机由知识库(数据库和规则库)与模糊
推理决策逻辑构成。这是基本部分。 ①知识库(Knowledge base)=数据库(Date base) +语言控制规则库(Rule base)
缺点:不同被控对象,控制规则不变,控制效果不好。
图4.3 简单模糊控制器的结构
⑵模糊自调整控制器----二维模糊控制器中加入修正因子
(规则自调整模糊控制器)
u e 1 e
低阶控制系统: >0.5 高阶控制系统: <0.5
当误差较大时,控制系统的主要任务是消除误差,加快响 应速度,这时对误差的加权应该大些;
的概念? 3、常用的模糊控制器有哪些? 4、二维FC的工作原理?优缺点? 5、FC设计的两种实现方式及其特点? 6、设计模糊控制器的步骤?
4.2模糊控制器的结构设计
4.2.1模糊控制器的结构设计 实质:模糊控制器输入语言变量及输出语言变量的选取和模糊控制器的不同
3-3模糊控制器设计PPT课件

2021/3/10
5
3.3.2 模糊控制器的基本结构(续)
2.知识库 它通常由数据库和模糊控制规则库两部分组成。
(1)数据库主要包括各语言变量的隶属函数,尺 度变换因子及模糊空间的分级数等。
(2)规则库包括了用模糊语言变量表示的一系列 控制规则。它们反映了控制专家的经验和知识。
3.模糊推理
模糊推理是模糊控制器的核心,它具有模拟人 的基于模糊概念的推理能力程是基于模糊逻辑 中的蕴含关系及推理规则来进行的。
第3章 模糊控制 (续)
2021/3/10
1
3.3 模 糊 控 制 器 的 结 构 、 原理及设计方法
2021/3/10
2
3.3 模糊控制器的结构、原理及设计方法
要实现一个实际的模糊控制系统,需要解决三个问 题;知识的表示、推理策略和知识获取。
模糊控制是以模糊集合论、模糊语言变量及模糊 逻辑推理为基础的一种计算机控制。
3.3.3 模糊控制的基本原理(续-10)
上式中
2021/3/10
19
3.3.3 模糊控制的基本原理(续-11)
上式中
2021/3/10
20
3.3.3 模糊控制的基本原理(续-12)
模糊控制器的输出变量是触发电压u的变化,该电
压直接控制电热炉的供电电压的高低。
2021/3/10
12
3.3.3 模糊控制的基本原理(续-4)
(2)输入变量及输出变量的模糊语言描述
描述输入变量及输出变量的语言值的模糊子集为 {负大,负小,0,正小,正大}
通常采用如下简记形式
NB=负大,NS=负小,O=零,PS=正小,PB=正大。 其中,N=Negative,P=Positive,B=Big,S=Small, O=Zero。
模糊控制系统课件45(模糊控制系统的设计与仿真).

u为可控进水阀的控制量; q1为水箱进水量; q2为水箱 的流出水量; h为水位高度。水箱流出水量q2取决于出水管 道的半径(为定值)、出水阀的开度,同时与水箱水位h有关。 水箱水位高度h与进水阀控制量u之间的传递函数为惯性环节, 即
H (s) K G(s) U ( s) Ts 1
(5.1)
4.5 MATLAB辅助模糊系统设计
4.5.1 MATLAB仿真环境 4.5.2 模糊控制系统仿真
4.5.1 MATLAB仿真环境
4.5.2.1 MATLAB仿真环境的建立 在MATLAB命令窗口键入命令Simulink或直接点击工具 栏上的Simulink图标,可以打开Simulink模块库,如图所示。
图5.8 MATLAB主界面
图5.9 Simulink模块库
在Simulink模块库环境里通过选择菜单 File→New→Model,或直接点击工具栏上的相应图标可以 创建一个新的模型。 在图5.10所示的仿真模型编辑主窗口中,利用各种模块 库将系统“画”出来,即搭建起来。例如,在图5.9中的模 块查看区域内选中一个模块,拖到图5.10中,可以看到这个 模块出现在仿真环境仿真模型编辑主窗口中,如图5.10所示。
图5.20 模糊推理系统仿真系统编辑窗口
图5.21 设定模糊逻辑控制器的名称
将在模糊推理系统仿真界面中建立的模糊推理系统fzy1 打开。操作步骤如下:在MATLAB命令窗口中输入命令 fuzzy→Enter,出现FIS Edit编辑器画面,单击File→Import →From Disk,打开5.1节所建立的模糊推理系统fzy1.fis; 接 着单击File→Export→To Workspace,打开如图5.22所示的界 面。 在图5.22中,在Workspace variable栏内填入fzy1,单击
模糊PID控制原理与设计步骤

模糊PID控制原理与设计步骤1.模糊化输入:将输入量通过模糊化过程,将其转化为隶属度函数形式,用来描述输入数量的各个级别或水平。
2.模糊化输出:同样地,将输出量也通过模糊化过程,转化为隶属度函数形式。
3.模糊化规则库:根据经验和专家知识,建立一组模糊规则,用来描述输入与输出之间的关系。
4.基于规则库的推理:根据输入的隶属度函数和规则库,通过隶属度的逻辑运算进行推理,得到输出的隶属度函数。
5.解模糊化:将输出的隶属度函数转化为具体的输出量,可以采用常用的解模糊化方法,如最大隶属度法、面积法等。
1.系统建模:首先需要对被控对象进行建模,得到其输入-输出关系。
可以基于部分局部建模或物理建模进行分析和确定。
2.设计模糊控制器的输入和输出:根据系统的特性和要求,确定模糊控制器的输入和输出。
- 输入通常包括误差(error)和误差的变化率(change in error)等。
-输出通常为控制量,可为模糊量或一阶量。
3.确定输入和输出的隶属度函数:确定输入和输出的隶属度函数形式,并根据实际情况进行参数调整。
通常可以选择三角形、梯形或高斯型函数等。
4. 设计模糊规则库:根据经验和专家知识,建立模糊规则库。
规则库的设计需要包括合理的覆盖边界和均匀的分布。
可以使用专家系统、模糊C-Means聚类等方法进行规则库的构建。
5.制定模糊推理机制:确定模糊推理的方法,常用的有最小最大法、剪切平均法等。
根据输入的隶属度函数和规则库,进行隶属度的逻辑运算和推理,得到输出的隶属度函数。
6.解模糊化:根据规则库,将模糊输出转化为具体的控制量。
可以采用最大隶属度法、面积法等方法进行解模糊化。
7.验证和调整:将设计好的模糊PID控制器应用到实际系统中,进行运行和调整。
根据实际反馈信号,对模糊规则库进行优化和调整,以提高控制系统的性能和稳定性。
总结:模糊PID控制是一种基于模糊逻辑和PID控制相结合的控制方法,能够更好地应对非线性、时变和模糊的控制系统。
模糊控制系统课件4.5(模糊控制系统的设计与仿真)

面。
在图5.22中,在Workspace variable栏内填入fzy1,单击 OK按钮。这样就将模糊推理系统FIS所构建的参数传递给模 糊推理系统仿真编辑图形化窗口中名称为fzy1的Fuzzy Logic Controller。
图5.22 Fuzzy Logic Controller参数传递
4.5.3 模糊控制系统仿真
Simulink基本模块库包含的是最基本的仿真模块,是
MATLAB仿真建模的基础。每一个模块在使用时都需要设 定一些相关参数,一般可以在模型编辑窗口双击该模块,然 后在相应的弹出对话框里来设定这些参数。用右键单击模块 图标,还可以在弹出的菜单里选择相关操作。
2. Simulink Extras扩展模块库
图5.27 建立控制规则
图5.28 模糊推理系统输出面
5.3.2 建立Simulink仿真编辑环境
在MATLAB命令窗口中单击Simulink图标,激活仿真模 块库,根据5.2节所讲的步骤,建立仿真模型编辑环境窗口, 将仿真所需要的模块用鼠标拖入其中并连接好,如图5.29所 示。这里只讲解模糊控制系统的仿真方法,模块参数选择较 粗糙(调整参数的方法可参阅5.3节的内容)。仿真系统中,模 糊控制器的输出采用增量式输出,系统给定值h=2 m,水箱 数学模型为
图5.20 模糊推理系统仿真系统编辑窗口
图5.21 设定模糊逻辑控制器的名称
将在模糊推理系统仿真界面中建立的模糊推理系统fzy1
打开。操作步骤如下:在MATLAB命令窗口中输入命令 fuzzy→Enter,出现FIS Edit编辑器画面,单击File→Import →From Disk,打开5.1节所建立的模糊推理系统fzy1.fis; 接 着单击File→Export→To Workspace,打开如图5.22所示的界
模糊PID控制原理与设计步骤

3.1 模糊PID 控制原理与设计步骤模糊PID 控制器以误差e 和误差变化率e c 作为控制器的输入量,输入量经模糊化与模糊推理之后得出模糊控制器的输出值,PID 控制器根据模糊控制的输出值对自身参数进行调节。
本文所用模糊PID 控制器的原理图如图3.1所示图3.1 自适应模糊PID 控制结构图Fig.3.1 The structure of adaptive fuzzyPID control system3.1.1 PID 控制器性能分析在PID 控制环节,离散PID 控制算法为10()()kdp k i jk k j K u k K e K Te e e T(3.1)为便于控制模型的搭建,由式(3.1)进行z 变换得PID 控制环节的传递函数为(1)()1i d pK Tz K z G z K z Tz(3.2)其中,K p 、K i 、K d 分别为比例、积分与微分系数,T 为系统采样时间。
PID 控制器参数K p ,K i ,K d 共同作用于被控系统,它们各自对系统的响应速度、超调量、稳定性及稳态精度等性能的影响分别为:比例系数K p :使控制系统快速动作,减小系统误差。
K p 较大时,系统能快速响应,但K p 过大时会产生超调,甚至破坏系统的稳定性;K p 过小时,会减弱控制器动作幅度,调节时间增长,使系统响应变得不理想。
积分系数K i :系统进入稳态阶段时会消除系统误差。
K i 较大时,系统稳态误差会很快变小,但在系统初始响应阶段K i 较大时,会使控制器产生积分饱和,从而破坏系统的稳定性;K i 过小时,难以消除系统的稳态误差,不能确保较高的调节精度。
微分系数K d:提高系统的动态响应性能,会在系统响应过程中对偏差的变化进行提前预测,从而抑制偏差的变化。
K d过大时,会使系统响应作用减弱,从而使调节时间增长,而且会降低系统的抗干扰性能。
PID控制参数的调节必须考虑不同时刻它们各自对系统性能的影响及相互之间的互联关系。
自动控制系统中的模糊控制器设计技巧

自动控制系统中的模糊控制器设计技巧自动控制系统是现代工业生产的重要组成部分,而模糊控制器作为一种常用的控制策略,广泛应用于各种工业领域。
模糊控制器通过模糊逻辑和模糊推理来处理不确定性和非线性问题,具有灵活性和适应性高的特点。
在设计模糊控制器时,需要考虑多个因素,下面将介绍一些设计模糊控制器的技巧。
首先,选择适当的模糊逻辑和模糊推理方法是设计模糊控制器的基础。
模糊逻辑是将输入和输出之间的关系进行模糊化,以便用模糊推理方法进行推理和控制。
在选择模糊逻辑和模糊推理方法时,应考虑控制系统的具体需求和性能要求。
常见的模糊逻辑包括最小最大法、加法法和乘法法,而模糊推理方法包括模糊规则和模糊推理机制。
其次,建立合适的输入输出模糊化和去模糊化方法是设计模糊控制器的关键。
在输入模糊化阶段,需要将输入经过模糊化处理,将连续的输入值转换为模糊集合,以便后续的模糊推理。
常见的输入模糊化方法包括三角隶属函数、梯形隶属函数和高斯隶属函数。
在输出去模糊化阶段,需要将模糊控制器的输出转换为实际控制信号。
常见的输出去模糊化方法包括最大值法、平均值法和加权平均值法。
此外,对于模糊控制器中的模糊规则的设计,需要根据实际控制需求和系统特点进行合理的规则设置。
模糊规则是模糊控制器的核心部分,包含了控制输入和输出之间的模糊关系。
在设计模糊规则时,应对系统进行建模和分析,合理划分输入和输出的模糊集合,并利用专家经验和实验数据进行规则的设置。
常见的规则设置方法包括基于经验的设置和基于数据的设置。
此外,对于模糊控制器的参数调整,可以采用试探法、经验法和优化算法等不同的方法。
试探法是一种简单而直观的参数调整方法,通过不断试探和调整参数值来改善系统的控制性能。
经验法是基于专家经验和工程实践的参数调整方法,可以快速调整模糊控制器的参数以满足系统控制要求。
优化算法是一种系统化的参数调整方法,通过建立数学模型和优化目标函数,自动求解最优参数。
最后,模糊控制器的性能评价和系统的鲁棒性分析是设计模糊控制器的重要步骤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
u*
MIN MAX
u u du u du
17
MIN
当输出变量的隶属函数为单点集时
u*
u
i 1 i i
p
i 1
p
i
对于图中的上个单点集:
u1 a1 u 2 a2 u3 a4 u 4 a3 u* a1 a2 a3 a4
2.2.2 清晰量的模糊化
在模糊控制系统运行中,控制器的输入值、输出 值是有确定数值的清晰量,而在进行模糊控制时, 模糊推理过程是通过模糊语言变量进行的,在清 晰量和模糊量之间有一定的对应关系。
这种把物理量的清晰值转换成模糊语言变量值的 过程叫做清晰量的模糊化。
5
1. 语言变量隶属函数的设定
人们一般期望输出能快速、稳准地达到给定值。
在控制决策工程中,经验丰富的操作者并不是依据
数学模型进行控制,而是根据操作经验以及对系统
动态特征信息的识别进行直觉推理,在线确定或变
换控制策略,从而获得良好的控制效果。
25
图2.37为典型的二阶系统的单位阶跃 响应。
系统的响应是连 续的四个相位 (Ⅰ,Ⅱ,Ⅲ, Ⅳ)周期重复出 现,并且输出值 的变化量比上个 周期逐渐减小。
在图2.28中,温度500C既可属于“中”的范围,也可认为
属于“低”的范围。这就是隶属函数的重叠。
在一个模糊控制系统中,隶属函数之间的重叠程度直接影响
着系统的性能。
一般重叠率在0.2~0.6之间选取。
8
几个隶属函数重叠的例子
选择合适的重叠,正是一个模糊控制器相对于参 数变化时具有鲁棒性的原因所在。 而隶属函数之间不恰当的重叠,就可能最终导致 模糊控制系统产生随意的混乱行为。
u (k ) u(k ) u(k 1)
23
模糊控制规则的生成大致有以下四 种方法,即
根据专家经验或过程控制知识生成控制规 则 根据过程模糊模型生成控制规则
根据对手工控制操作的系统观察和测量生 成控制规则 根据学习算法生成控制规则
24
(1)根据专家经验或过程知识生成控 制规则
0.1 0.4 0.7 1.0 0.7 0.3 U 2 3 4 5 6 7 按最大隶属度的原则清晰化,应取控制量为
u 5
*
最大隶属度法就是取模糊集最大隶属度所对应的基础变量 值作为清晰值的方法。
16
(2)重心法
重心法是指取模糊集隶属函数曲线同基础变量轴 所围面积的重心对应的基础变量值作为清晰值的 方法,也是一种最常用的清晰化方法。 在输出量隶属函数为连续变量情况下
模糊控制规则的优化在本质上就是要解决控制规 则的数量与质量问题,就是要建立合适的规则数 目和正确的规则形式,并给每条控制规则赋予适 当的权系数,或称置信度。
控制规则的质量是指规则前件(前提条件)和后 件(结论)之间的推理关系是否处于最合理状态, 不同规则之间是否存在矛盾,这些都是需要鉴定 的问题。
偏差变化率CE和控制量U的模糊集均为 偏差E的论域为 偏差变化率 的论域为 控制量的论域 为
NB, NM , NS , ZE, PS, PM , PB 6,5,4,3,2,1,0,0,1,2,3,4,5,6
6,5,4,3,2,1,0,0,1,2,3,4,5,6
33
(1)CRI推理的查表法
查表法就是把所有可能的输入量都量化到语言
变量论域元素上,并以输入论域的元素作为输
入量进行组合,求出输入量论域元素和输出量
论域元素之间关系的表格。
34
二维模糊控制器的模糊控制表的建立
偏差的模糊集为
NB, NM , NS , NZ , PZ, PS, PM , PB
其中,i为规则序号, n为规则总数。
u*
k
i 1 n i
n
i
k
i 1
i
20
2.3.4 模糊控制规则及控制算法
1. 模糊控制规则的生成
设计模糊规则时,需遵守的原则是: 必须考虑控制规则的完备性、交叉性和一致性。 完备性是指对于任意的给定输入,均有相应的控 制规则起作用。 交叉性是指控制器的输出值总由数条控制规则来 决定 。 规则的一致性是指控制规则中不存在相互矛盾的 规则。
21
模糊控制器的两种类型。
(1)位置式 ri: IF e(k) is Ai and Δ e(k) is Bi THEN u(k) is Ci
(2)速度式
ri: IF e(k) is Ai and Δe(k) is Bi THEN Δ u(k) is Ci
22
速度型模糊控制器框图
图中
e(k ) r y(k ) e(k ) e(k ) e(k 1)
规则的质量对于控制品质的优劣起着关键性作用。
32
3. 模糊控制算法
模糊控制算法的目的,就是从输入的连续精确量
中,通过模糊推理的算法过程,求出相应的清晰
值的控制算法。
模糊控制算法有多种实现形式。为了便于在数字
计算机中实现,同时考虑算法的实时性,模糊控
制系统常目前采用的算法有:
CRI推理的查表法,CRI推理的解析公式法, Mamdani直接推理法,后件函数法等。
18
(3)左取大(LM)和右取大 (RM)法
左取大(LM)是指取输出隶属函数左边达到最大 值所对应的基础变量值作为清晰值的方法。 右取大(RM)是指取输出隶属函数右边达到最 大值所对应的基础变量值作为清晰值的方法 左取大和右取大的示意图如下图 :
19
(4)加权平均法
加权平均法是指以各条规则的前件和输入的模 糊集按一定法则确定的值ki为权值,并对后件代 表值μ i加权平均计算输出的清晰值的方法。其 计算公式为
语言变量是以自然或人工语言的词、词组或句子 作为值的变量。 例如,我们可以将“温度”划分成“较低”、 “低”、“中”、“高”、“较高”五个部分 (或称五档)。
“温度”称为语言变量,温度的“较低”、
“低”、“中”、“高”、“较高”称为这个语
言变量的语言值。
6
燃烧炉温度变量的隶属函数的描述
7
隶属函数的重叠
在每个相位中,有一些 特征点,如a1,b1,c1, d1等。
26
控制规则的建立
在响应的起始点a1处,偏差e很大且为正,偏差的一阶差分 几乎等于零。为了得到快速的系统响应,必须加大被控对 象的输入量,即操作量。此时的语言控制规则可写成: 如果e为PB和Δ e为ZE,则u为 PB 在b1处,为了减小系统的超调量,必须最大地减小操作量, 因此控制规则可写成 “如果e为ZE和Δ e为NB,则u为NB”
2.3 模糊控制器设计 2.3.1 模糊控制器设计要求
从系统硬件结构看,模糊控制系统与其他常规
数字控制系统一样,是由:
控制器、执行机构、被控对象、敏感元件和输
入输出接口等环节组成。
1
传统数字闭环控制系统的优化设 计过程示意图
设计过程包括: 系统分析 综合设计 控制器实现 模拟仿真 或试验等过 程。
14
表2.3 偏差变化率Δ e的语言变量值
对于偏差变化率Δ e,通过量化变换到整数论域{-6, -5,-4,-3,-2,-1,0,1,2,3,4,5,6},并 取正大、正中、正小、零、负小、负中、负大七个 语言变量值档次。
15
2.3.3 模糊量的清晰化 (1)最大隶属度法
最隶属度法是指选取推理结论的模糊集中隶属度最大的元 素作为控制量的方法。例如
12
3.清晰量转换为模糊量
模糊控制系统中含有偏差e、偏差变化率Δ e两个 输入量,和一个控制量u。它们都是清晰量。这 三个物理量都要从物理论域通过量化转换到整数 论域,再在整数论域给出若干语言变量值,从而 实现整个论域元素的模糊化过程。
13
表2.2 偏差e的语言变量值
对于偏差e,通过量化变换到整个论域{-6,-5,4,-3,-2,-1,0-,0+,1,2,3,4,5,6}, 并取正大、正中、正小、正零、负零、负小、负 小、负大八个语言变量值档次。
7,6,5,4,3,2,1,0,1,2,3,4,5,6,7
35
表2.9给出了一类根据系统输出的偏差及 偏差变化趋势来消除偏差的模糊控制规则。
这个控制规则表可以用21条模糊条件语句来描述。
36
模糊控制表如表2.10所示。
此控制表作为文件存储在计算机内存中。在实际 控制时,只要通过对输入量量化和查表这两个步 骤,就可得到控制值。
37
27
表2.5给出了这样一套控制规则, 共有13条规则。
如果只取这几条控制规则进行模糊推理的话,就会出 现“未定义的盲区”。 这样的控制效果是很差的,因此要对表2.5的控制规 则加以扩充,扩充后的控制规则库如表2.6所29
模糊状态变量隶属函数常用如图2.38 所示的三角形分布函数。
图中NB,NM,NS,ZE,PS,PM,PB表示负大、 负中、负小、零、正小、正中、正大。
30
图2.39 模糊控制输入输出关系
它反映了输入和 输出之间的非线 性关系。 当偏差较大时, 控制量的变化应 尽力使偏差迅速 减小; 当偏差较小时, 除了要消除偏差 外,还要考虑系 统的稳定性
31
2. 模糊控制规则的优化
10
2. 语言变量值的表示方法