实验十时间序列模型
《时间序列模型 》课件

目录
Contents
• 时间序列模型概述 • 时间序列模型的基础 • 时间序列模型的建立 • 时间序列模型的预测 • 时间序列模型的应用 • 时间序列模型的未来发展
01 时间序列模型概述
时间序列的定义
01 时间序列是指按照时间顺序排列的一系列观测值 。
02 时间序列数据可以是数值型、分类型或混合型。 03 时间序列数据可以用于描述和预测时间变化的现
详细描述
通过分析历史经济数据的时间序列特性,时间序列模型能够预 测未来经济走势,为政策制定者和企业决策者提供重要参考。
举例说明
例如,利用ARIMA模型分析国内生产总值(GDP)的时间 序列数据,可以预测未来一段时间的GDP增长趋势。
股票预测
01
总结词
时间序列模型在股票市场中具有实际应用价值。
02 03
SARIMA、VAR等。
识别模型阶数
02
确定模型的参数,如自回归阶数、差分阶数和移动平均阶数。
考虑季节性和趋势性
03
如果时间序列数据存在季节性和趋势性,需要在模型中加以考
虑。
参数估计
01
使用最小二乘法或最大似然法等统计方法估计模型 的参数。
02
考虑使用软件包或编程语言进行计算,如Python的 statsmodels库或R语言的forecast包。
象。
时间序列的特点
时序性
时间序列数据是按照时间顺序排列的,具有 时间上的连续性。
趋势性
时间序列数据通常具有一定的趋势,如递增 、递减或周期性变化。
季节性
一些时间序列数据呈现季节性变化,如年度 、季度或月度的变化规律。
不确定性
时间序列数据受到多种因素的影响,具有不 确定性,难以精确预测。
时间序列模型建模步骤

时间序列模型建模步骤时间序列模型是一种用来预测未来数据走势的统计模型,它基于时间序列数据的历史信息来进行预测。
建立时间序列模型的步骤主要包括数据收集、数据预处理、模型选择、模型拟合和模型评估等。
数据收集是建立时间序列模型的第一步。
我们需要收集与研究对象相关的时间序列数据,这些数据可以是经济指标、股票价格、气温等不同领域的数据。
收集到的数据需要包含一定的时间跨度,以便后续建模和预测。
接下来是数据预处理阶段,这一步是非常重要的。
我们需要对收集到的数据进行缺失值处理、异常值检测和处理,以及平稳性检验等。
确保数据的质量和完整性是建立准确模型的基础。
在选择模型的阶段,我们需要根据时间序列数据的特点来选择合适的模型。
常用的时间序列模型包括移动平均模型(MA)、自回归模型(AR)、自回归移动平均模型(ARMA)和自回归积分移动平均模型(ARIMA)等。
根据数据的自相关性和平稳性来选择最适合的模型。
模型拟合是建立时间序列模型的核心步骤。
在这一步中,我们需要对选定的模型进行参数估计,即利用历史数据来拟合模型的参数。
通过最大似然估计等方法来求解模型的参数,使模型能够较好地拟合历史数据。
最后是模型评估阶段,我们需要对建立的时间序列模型进行评估。
评估模型的好坏可以通过残差分析、模型拟合优度检验、预测准确度等指标来进行。
根据评估结果来判断模型的有效性和稳定性,进而决定是否需要进行调整和改进。
总的来说,建立时间序列模型是一个复杂而严谨的过程,需要充分理解数据的特点和模型的原理,结合实际情况来选择合适的建模方法和技术。
通过不断地优化和改进模型,可以提高时间序列预测的准确性和可靠性,为决策提供有力的支持。
时间序列模型讲义

时间序列模型讲义时间序列模型讲义一、概念介绍时间序列模型是一种用于分析和预测时间上变化的数据模型。
它是一种建立在时间序列数据上的数学模型,旨在揭示时间序列中的隐藏规律和趋势,并利用这些规律和趋势进行预测和决策。
二、时间序列的特征时间序列数据具有以下几个主要特征:1. 时间相关性:时间序列数据中的观测值在时间上是相关的,前一个时刻的观测值往往会影响后续时刻的观测值。
2. 趋势性:时间序列数据往往具有明显的趋势性,即观测值随时间呈现出递增或递减的趋势。
3. 季节性:时间序列数据中可以存在固定的周期性变化,比如月份、季节、一周等周期性变化。
4. 周期性:时间序列数据中可能存在非固定的周期性变化,比如经济周期、股票市场周期等。
三、时间序列模型的构建过程时间序列模型的构建过程主要包括以下几个步骤:1. 数据探索和预处理:对时间序列数据进行可视化和探索,查看数据的分布、趋势和周期性等特征,并进行缺失值处理、异常值处理等预处理操作。
2. 模型选择:选择适合数据特征的时间序列模型,常用的模型包括移动平均模型(MA模型)、自回归模型(AR模型)和自回归移动平均模型(ARMA模型)等。
3. 参数估计:利用已选定的时间序列模型,对模型中的参数进行估计,通常采用极大似然估计或最小二乘估计等方法。
4. 模型诊断:对估计得到的时间序列模型进行诊断,检验模型是否满足统计假设,例如模型的残差序列是否具有零均值和白噪声等特征。
5. 模型评价和预测:通过对模型在历史数据上的拟合程度进行评价,选择最优的模型,并利用该模型对未来的数据进行预测和决策。
四、常见的时间序列模型1. 移动平均模型(MA模型):该模型假设当前观测值是过去几个时刻的观测值的加权平均,其中权重是模型的参数。
该模型适用于没有明显趋势和季节性的时间序列。
2. 自回归模型(AR模型):该模型假设当前观测值是过去几个时刻的观测值的线性组合,其中系数是模型的参数。
该模型适用于具有明显的趋势性的时间序列。
时间序列模型及其应用分析

时间序列模型及其应用分析时间序列是一系列时间上连续的数据点所组成的序列,其中每个数据点都表示了某一特定时刻的某个特征。
这些数据点可以是均匀间隔的,也可以是不均匀间隔的。
时间序列模型是对时间序列数据进行分析和预测的一种方法,它可以用来预测未来的趋势、季节性以及周期性变化等。
时间序列模型应用广泛,包括经济学、金融学、气象学、生态学、医学等领域。
时间序列分析的三个方面时间序列模型的分析过程可以分为三个方面:描述性分析、模型建立和模型预测。
描述性分析是对时间序列数据进行探索性的分析,以了解数据的整体特征。
常用的描述性统计学方法有均值、方差、标准差、自相关和偏自相关函数等。
作为对比,我们还可以对比不同时间序列数据之间的相关性、差异性等指标。
模型建立则是对时间序列进行拟合,以找出可以描述时间序列数据模式的数学模型。
时间序列数据的核心特征是时间的序列性质,因此模型的选择需要充分考虑到时间因素。
常用的时间序列模型包括AR、MA、ARMA、ARIMA和季节性模型等。
这些模型可以用自回归、移动平均、季节性变量等手段描述时间序列中可能出现的趋势和周期性变化。
预测也是时间序列模型分析的重要一环,它可以帮助我们预测未来的趋势和变化。
预测分析通常需要对历史数据进行处理、建立模型、进行模型检验和预测。
预测结果应当与实际值进行比较,以评估预测模型的准确性和可靠性。
常规时间序列分析方法:ARMA模型ARMA模型是一个经典时间序列预测模型。
ARMA模型的基本思想是把时间序列变成可以预测的序列,根据历史数据样本建立恰当的模型,预测未来数据的值。
ARMA模型由自回归过程(AR)和移动平均过程(MA)组成,AR过程考虑的是某一时刻的过去的信息对当前时刻的影响,MA过程关注的是随机变量的移动平均值对当前随机变量的影响。
ARMA模型的具体表现形式是:$$ Y_t = \alpha_1 Y_{t-1} + \alpha_2 Y_{t-2} + ... +\alpha_p Y_{t-p} + \epsilon_t + \beta_1 \epsilon_{t-1} + \beta_2 \epsilon_{t-2}+ ... +\beta_q \epsilon_{t-q} $$其中,Yt表示时间序列的实际值,α1到αp表示历史数据对当前时刻的影响,εt到εt-q表示误差项,β1到βq表示误差项对当前时刻的影响。
时间序列模型

时间序列模型时间序列模型是一种用于预测时间序列数据的统计模型。
这种模型可以帮助我们了解数据中的趋势、季节性和周期性,并基于这些信息做出未来的预测。
时间序列模型的核心思想是将过去的观察结果作为未来预测的基础。
通过对已有数据的分析和建模,我们可以确定模型的参数和时间序列的性质,从而进行准确的预测。
有许多不同的时间序列模型可以使用,其中最常用的是自回归移动平均模型(ARMA)和自回归集成移动平均模型(ARIMA)。
这些模型假设未来的数值是过去的线性组合,并通过对数据进行差分来观察数据的趋势。
另一个流行的时间序列模型是季节性自回归集成移动平均模型(SARIMA),它在ARIMA模型的基础上增加了季节性组分。
这种模型特别适用于季节性数据,可以更好地捕捉季节性的规律。
除了上述模型之外,还有各种其他的时间序列模型,例如指数平滑模型、灰度预测模型和波动性模型等。
这些模型在数据的不同方面和性质上有不同的适用性。
时间序列模型的应用非常广泛,可以用于经济预测、股票价格预测、天气预测等领域。
它可以帮助我们研究和理解时间序列数据中的规律,并根据过去的观测结果做出未来的预测。
然而,时间序列模型也存在一些不足之处。
首先,它假设未来的数值是过去的线性组合,而无法捕捉非线性的规律。
其次,时间序列模型在数据中存在异常值或离群值时表现不佳。
此外,时间序列模型无法处理缺失值,而且对于长期预测的准确性可能会受到影响。
综上所述,时间序列模型是一种重要的统计模型,可以用于预测时间序列数据。
它能够帮助我们了解数据中的趋势、季节性和周期性,并根据这些信息做出未来的预测。
然而,我们在使用时间序列模型时需要注意其假设和限制,并结合实际情况进行分析和解释。
时间序列模型是一种用于分析和预测时间序列数据的统计模型。
它可以帮助我们识别和理解数据中隐含的模式和趋势,并以此为基础进行未来的预测。
时间序列模型广泛应用于各个领域,如经济学、金融学、交通规划、气象预测等。
时间序列模型概述

时间序列模型概述时间序列模型是一种用于预测时间序列数据的统计模型。
时间序列数据是一系列按照时间顺序排列的数据点。
例如,股票价格、气温、销售额都是时间序列数据。
时间序列模型能够分析数据中的趋势、周期性和季节性,提供对未来的预测。
时间序列模型的建立是基于以下几个假设:1. 时序依赖:时间序列数据中的每个数据点都依赖于之前的数据点。
这意味着前一时刻的数据对当前时刻的数据有影响。
2. 稳定性:时间序列数据的统计特性在时间上保持不变。
这意味着数据的平均值和方差不会随时间而变化。
3. 随机性:时间序列数据中的噪声是随机的,即不受任何规律的干扰。
为了建立时间序列模型,我们需要对数据进行预处理和分析。
首先,我们需要对数据进行平稳性检验,确保数据的均值和方差在时间上保持不变。
如果数据不稳定,我们可以采用一些技术,如差分操作,将其转化为稳定的形式。
接下来,我们需要对时间序列数据进行分解,找出其中的趋势、周期性和季节性。
常用的分解方法有加法分解和乘法分解。
加法分解将时间序列数据分解为趋势、季节性和误差项的和,乘法分解将时间序列数据分解为趋势、季节性和误差项的乘积。
在分解的基础上,我们可以选择适合的时间序列模型进行建模和预测。
常见的时间序列模型有:1. 自回归移动平均模型(ARMA):基于时间序列数据的自回归和移动平均过程。
ARMA模型适用于没有趋势和季节性的时间序列数据。
2. 自回归积分移动平均模型(ARIMA):在ARMA模型的基础上,增加了对时间序列数据的差分操作。
ARIMA模型适用于具有趋势但没有季节性的时间序列数据。
3. 季节性自回归积分移动平均模型(SARIMA):在ARIMA 模型的基础上,增加了对时间序列数据的季节性差分操作。
SARIMA模型适用于具有趋势和季节性的时间序列数据。
4. 季节性分解模型(STL):将时间序列数据进行分解,然后对趋势、季节性和残差进行建模。
STL模型适用于具有明显季节性的时间序列数据。
计量经济学实验十时间序列模型
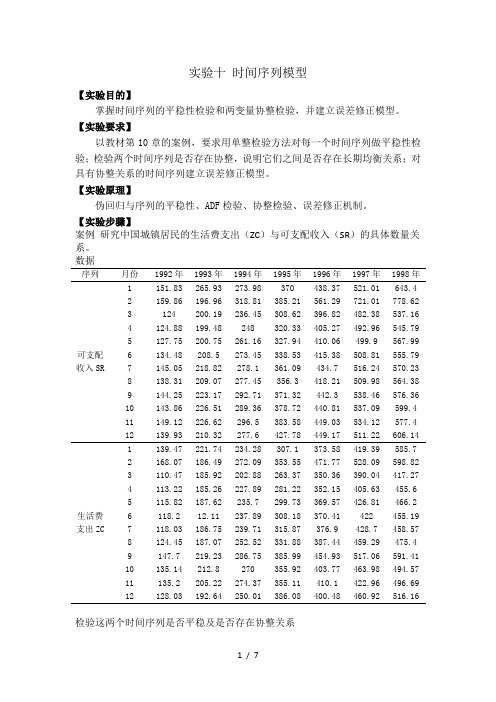
实验十时间序列模型【实验目的】掌握时间序列的平稳性检验和两变量协整检验,并建立误差修正模型。
【实验要求】以教材第10章的案例,要求用单整检验方法对每一个时间序列做平稳性检验;检验两个时间序列是否存在协整,说明它们之间是否存在长期均衡关系;对具有协整关系的时间序列建立误差修正模型。
【实验原理】伪回归与序列的平稳性、ADF检验、协整检验、误差修正机制。
【实验步骤】案例研究中国城镇居民的生活费支出(ZC)与可支配收入(SR)的具体数量关系。
数据序列月份1992年1993年1994年1995年1996年1997年1998年可支配收入SR1 151.83 265.93 273.98 370 438.37 521.01 643.42 159.86 196.96 318.81 385.21 561.29 721.01 778.623 124 200.19 236.45 308.62 396.82 482.38 537.164 124.88 199.48 248 320.33 405.27 492.96 545.795 127.75 200.75 261.16 327.94 410.06 499.9 567.996 134.48 208.5 273.45 338.53 415.38 508.81 555.797 145.05 218.82 278.1 361.09 434.7 516.24 570.238 138.31 209.07 277.45 356.3 418.21 509.98 564.389 144.25 223.17 292.71 371.32 442.3 538.46 576.3610 143.86 226.51 289.36 378.72 440.81 537.09 599.411 149.12 226.62 296.5 383.58 449.03 534.12 577.412 139.93 210.32 277.6 427.78 449.17 511.22 606.14生活费支出ZC1 139.47 221.74 234.28 307.1 373.58 419.39 585.72 168.07 186.49 272.09 353.55 471.77 528.09 598.823 110.47 185.92 202.88 263.37 350.36 390.04 417.274 113.22 185.26 227.89 281.22 352.15 405.63 455.65 115.82 187.62 235.7 299.73 369.57 426.81 466.26 118.2 12.11 237.89 308.18 370.41 422 455.197 118.03 186.75 239.71 315.87 376.9 428.7 458.578 124.45 187.07 252.52 331.88 387.44 459.29 475.49 147.7 219.23 286.75 385.99 454.93 517.06 591.4110 135.14 212.8 270 355.92 403.77 463.98 494.5711 135.2 205.22 274.37 355.11 410.1 422.96 496.6912 128.03 192.64 250.01 386.08 400.48 460.92 516.16检验这两个时间序列是否平稳及是否存在协整关系因为是月度数据,数据的工作文件如下建立:可支配收入(SR)序列平稳性检验打开SR序列,选择View/Unit Root Test,选择带截距项(intercept),滞后差分选2阶。
时间序列模型原理

时间序列模型原理时间序列模型是一种用于预测未来事件或变量发展趋势的统计模型。
它基于过去的观测数据,通过分析数据中的时间依赖关系,来推测未来的发展情况。
时间序列模型在许多领域都得到广泛应用,例如经济学、金融学、气象学等。
时间序列模型的原理可以简单概括为以下几个步骤:1. 数据收集与清洗:首先,我们需要收集相关的时间序列数据,这些数据可以是按照一定时间间隔采集的观测值,例如每日、每小时或每分钟的数据。
在收集到数据后,我们需要对数据进行清洗,即去除异常值或缺失值,使得数据具有一定的可靠性和连续性。
2. 数据探索与可视化:在进行时间序列建模之前,我们需要对数据进行探索与可视化分析,以了解数据的特点和规律。
通过绘制时间序列图、自相关图和偏自相关图等,可以帮助我们观察数据的趋势、季节性以及是否存在周期性等特征。
3. 模型选择与参数估计:选择合适的时间序列模型是构建准确预测的关键。
常用的时间序列模型包括ARIMA模型、季节性ARIMA模型(SARIMA)、指数平滑法、GARCH模型等。
在选择模型后,我们需要对模型的参数进行估计,通常使用最大似然估计或最小二乘估计等方法来确定模型参数的取值。
4. 模型诊断与验证:在参数估计后,我们需要对模型进行诊断和验证,以评估模型的拟合效果和预测能力。
常用的诊断方法包括检验残差序列的平稳性、白噪声性和自相关性等。
通过这些诊断方法,我们可以发现模型是否存在问题,进而对模型进行修正或调整。
5. 模型预测与评估:最后,我们可以使用已建立的时间序列模型进行未来事件或变量的预测。
通过模型预测,我们可以得到未来一段时间内的预测值,并使用一些评估指标(如均方根误差、平均绝对百分比误差等)来评估模型的预测准确性。
需要注意的是,时间序列模型的预测能力受到多种因素的影响,例如数据的质量、模型的选择和参数的确定等。
因此,在应用时间序列模型进行预测时,我们需要综合考虑各种因素,并不断优化和改进模型,以提高预测的准确性和稳定性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验十时间序列模型
实验目的
掌握时间序列的基本理论,时间序列模型种类的识别、估计、诊断和预测方法,以及相应的EViews软件操作方法。
实验原理
时间序列分析方法由Box-Jenkins (1976) 年提出。
它适用于各种领域的时间序列分析。
时间序列模型不同于经济计量模型的两个特点是:
(1)这种建模方法不以经济理论为依据,而是依据变量自身的变化规律,利用外推机制描述时间序列的变化。
(2)明确考虑时间序列的非平稳性。
如果时间序列非平稳,建立模型之前应先通过差分把它变换成平稳的时间序列,再考虑建模问题。
时间序列模型的应用:
(1)研究时间序列本身的变化规律(建立何种结构模型,有无确定性趋势,有无单位根,有无季节性成分,估计参数)。
(2)在回归模型中的应用(预测回归模型中解释变量的值)。
(3)时间序列模型是非经典计量经济学的基础之一(不懂时间序列模型学不好非经典计量经济学)。
实验内容
建立中国人口时间序列模型。
表给出了中国人口数据y t(1952-2004,单位万人),试建立y t的时间序列模型,并预测2005年中国人口总数。
表
建模步骤
10.4.1 识别模型
利用表数据建立y t序列图,如图。
图中国人口序列(1952-2004)
从人口序列图可以看出我国人口总水平除在1960和1961两年出现回落外,其余年份基本上保持线性增长趋势。
察看序列的相关图,在序列窗口选择View/Correlogram,便会弹出如下窗口,见图,选择滞后阶数(本例输入滞后期10),点击ok,得到如图所示的序列y t的相关图和偏相关图。
图
图y t的相关图,偏相关图
由y t的相关图,偏相关图判断y t为非平稳性序列。
进一步考察其差分序列Dy t,序列图见图,其相关图,偏相关图见图。
图
图Dy t的相关图,偏相关图
人口差分序列Dy t是平稳序列。
应该用Dy t建立模型。
因为Dy t均值非零,结合图拟建立带有漂移项的AR(1)模型。
10.4.2 估计模型
采用AR(1)模型对Dy t进行估计,从EViews主菜单中点击Quick键,选择Estimate Equation功能。
随即会弹出Equation specification对话框。
输入漂移项非零的AR(1)模型估计命令(C表示漂移项)如下:
D(Y) C AR(1)
结果如图所示,整理如下:
Dy t = + (Dy t-1–+ v t
R2 = , Q(10) = , Q? (k-p-q) = (10-1-0-1) =
图
10.4.3 对模型的检验
图
由估计结果,可以看到模型参数都通过了显着性t检验。
模型残差的相关图和偏相关图如图。
Q(10) = < ?(10-1-0) = ,可以认为模型误差序列为非自相关序列。
10.4.4 预测
EViews操作方法:把样本容量调整到1952-2005。
打开估计式窗口,在Equation Specification(方程设定)选择框输入命令,D(Y) C AR(1),保持Method(方法)选择框的缺省状态(LS方法),在Sample(样本)选择框中把样本范围调整至1949-2004。
点击OK键,得到估计结果后,点击功能条中的预测(Forecast)键。
得对话框及各种选择状态见图。
图
点击OK键,得到静态预测序列YF及置信区间图,如图。
同时,YF和YFse序列出现在工作文件中。
打开YF序列窗口,得2005年预测值为万人,见图。
已知2005年中国人口实际数是130756万人。
预测误差为:
? =130952.5130756
130756
-
=
若在图中输入预测样本范围为2005,则可以得到2005年的动态或静态预测结果。
如图所示。
本例得到的静态预测值的置信区间为[,]。
图
图
图。