模式识别大作业
模式识别大作业

Iris 数据聚类分析-----c 均值和模糊c 均值一.问题描述Iris 数据集包含150个数据,共有3类,每一类有50个数据,其每个数据有四个维度,每个维度代表鸢尾花特征(萼片,花瓣的长度)中的一个,其三类数据名称分别setosa,versicolor,virginica ,这些就是 Iris 数据集的基本特征。
现在使用c 均值和模糊c 均值的方法解决其聚类分析,并且计算比较两种方法得到的分类结果的正确率。
二.算法介绍1.c-均值算法C 均值算法属于聚类技术中一种基本的划分方法,具有简单、快速的优点。
其基本思想是选取c 个数据对象作为初始聚类中心,通过迭代把数据对象划分到不同的簇中,使簇内部对象之间的相似度很大,而簇之间对象的相似度很小。
其主要思想:(1) 计算数据对象两两之间的距离;(2) 找出距离最近的两个数据对象,形成一个数据对象集合A1 ,并将它们从总的数据集合U 中删除;(3) 计算A1 中每一个数据对象与数据对象集合U 中每一个样本的距离,找出在U 中与A1 中最近的数据对象,将它并入集合A1 并从U 中删除, 直到A1 中的数据对象个数到达一定阈值;(4) 再从U 中找到样本两两间距离最近的两个数据对象构成A2 ,重复上面的过程,直到形成k 个对象集合;(5) 最后对k 个对象集合分别进行算术平均,形成k 个初始聚类中心。
算法步骤:1.初始化:随机选择k 个样本点,并将其视为各聚类的初始中心12,,,k m m m ;2.按照最小距离法则逐个将样本x 划分到以聚类中心12,,,k m m m 为代表的k 个类1,k C C 中;3.计算聚类准则函数J,重新计算k 个类的聚类中心12,,,k m m m ; 4.重复step2和3知道聚类中心12,,,k m m m 无改变或目标函数J 不减小。
2.模糊c-均值模糊C 均值算法就是,在C 均值算法中,把硬分类变为模糊分类。
设()j i μx 是第i 个样本i x 属于第j 类j G 的隶属度,利用隶属度定义的准则函数为211[()]C N b f j i i jj i J μ===-∑∑x x m其中,b>1是一个可以控制聚类结果的模糊程度的常数。
模式识别作业三道习题

K7 ( X ) K6 ( X ) 1 第八步:取 X 4 w2 , K 7 ( X 4 ) 32 0 ,故 0 K8 ( X ) K 7 ( X ) 0 第九步:取 X 1 w1 , K8 ( X 1 ) 32 0 ,故 1 K 9 ( X ) K8 ( X ) 0 第十步:取 X 2 w1 , K9 ( X 2 ) 32 0 ,故 1 K10 ( X ) K9 ( X )
2
K ( X , X k ) exp{ || X X k || 2} exp{[( x 1 xk 1) 2 ( x 2 xk 2 ) 2]} x1 X = x2 ,训练样本为 X k 。 其中
模式识别大作业

模式识别大作业模糊聚类算法模糊聚类算法概述模糊聚类算法是一种基于函数最优方法的聚类算法,使用微积分计算技术求最优代价函数。
在基于概率算法的聚类方法中将使用概率密度函数,为此要假定合适的模型,模糊聚类算法的向量可以同时属于多个聚类,从而摆脱上述问题。
在模糊聚类算法中,定义了向量与聚类之间的近邻函数,并且聚类中向量的隶属度由隶属函数集合提供。
对模糊方法而言,在不同聚类中的向量隶属函数值是相互关联的。
硬聚类可以看成是模糊聚类方法的一个特例。
模糊聚类算法的分类模糊聚类分析算法大致可分为三类[4]:1)分类数不定,根据不同要求对事物进行动态聚类,此类方法是基于模糊等价矩阵聚类的,称为模糊等价矩阵动态聚类分析法。
2)分类数给定,寻找出对事物的最佳分析方案,此类方法是基于目标函数聚类的,称为模c均值聚类。
3)在摄动有意义的情况下,根据模糊相似矩阵聚类,此类方法称为基于摄动的模糊聚类分析法。
模糊c均值(FCM)聚类算法算法描述模糊c均值聚类算法的步骤还是比较简单的,模糊c均值聚类(FCM),即众所周知的模糊ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。
1973年,Bezdek提出了该算法,作为早期硬c均值聚类(HCM)方法的一种改进。
FCM把n个向量x i(i=1,2,…,n)分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。
FCM与HCM的主要区别在于FCM用模糊划分,使得每个给定数据点用值在0,1间的隶属度来确定其属于各个组的程度。
与引入模糊划分相适应,隶属矩阵U允许有取值在0,1间的元素。
不过,加上归一化规定,一个数据集的隶属度的和总等于1:∑==∀=ciijnju1,...,1,1(3.1)那么,FCM的价值函数(或目标函数)就是:∑∑∑====c i njijm ij c i i c d u J c c U J 1211),...,,(, (3.2)这里u ij 介于0,1间;c i 为模糊组I 的聚类中心,d ij =||c i -x j ||为第I 个聚类中心与第j 个数据点间的欧几里德距离;且[)∞∈,1m 是一个加权指数。
中科院模式识别大作业——人脸识别

中科院模式识别大作业——人脸识别人脸识别是一种广泛应用于安全领域的技术,它通过对图像或视频中的人脸进行特征提取和比对,实现对个体身份的自动识别。
中科院模式识别大作业中的人脸识别任务主要包括了人脸检测、人脸对齐、特征提取和人脸比对等步骤。
下面将详细介绍这些步骤。
首先,人脸检测是人脸识别的第一步。
它的目的是在图像或视频中准确地定位人脸区域,去除背景和其他干扰信息。
传统的人脸检测算法主要基于特征匹配、分类器或神经网络等方法,而近年来深度学习技术的兴起也为人脸检测带来了重大突破。
深度学习方法通过构建卷积神经网络,在大规模数据上进行训练,可以准确地检测出各种姿态、光照和遮挡条件下的人脸区域。
接下来是人脸对齐,它的目的是将检测到的人脸区域进行准确的对齐,使得不同人脸之间的几何特征保持一致。
人脸对齐算法通常包括了关键点检测和对齐变换操作。
关键点检测通过在人脸中标注一些特定点(如眼睛、鼻子和嘴巴)来标定人脸的几何结构。
对齐变换操作则根据标定的关键点信息,对人脸进行旋转、尺度调整和平移等变换操作,使得不同人脸之间具有一致的几何结构。
人脸对齐可以提高后续特征提取的准确性,从而提高整个人脸识别系统的性能。
特征提取是人脸识别的核心步骤之一,它将对齐后的人脸图像转化为能够表示个体身份信息的特征向量。
传统的特征提取方法主要基于手工设计的特征描述子,如LBP、HOG等。
这些方法需要针对不同任务进行特征设计,且往往存在一定的局限性。
相比之下,深度学习方法可以通过网络自动地学习出适用于不同任务的特征表示。
常用的深度学习模型有卷积神经网络和人工神经网络等,它们通过在大规模数据上进行监督学习,可以提取出能够表达人脸细节和结构的高层次特征。
最后是人脸比对,它根据提取的特征向量进行个体身份的匹配。
人脸比对算法通常需要计算两个特征向量之间的相似度,常用的计算方法有欧氏距离、余弦相似度等。
在实际应用中,为了提高匹配的准确性,通常会结合分数归一化、阈值设定等技术来进行优化。
模式识别大作业1

模式识别大作业--fisher线性判别和近邻法学号:021151**姓名:**任课教师:张**I. Fisher线性判别A. fisher线性判别简述在应用统计方法解决模式识别的问题时,一再碰到的问题之一是维数问题.在低维空间里解析上或计算上行得通的方法,在高维里往往行不通.因此,降低维数就成为处理实际问题的关键.我们考虑把维空间的样本投影到一条直线上,形成一维空间,即把维数压缩到一维.这样,必须找一个最好的,易于区分的投影线.这个投影变换就是我们求解的解向量.B.fisher线性判别的降维和判别1.线性投影与Fisher准则函数各类在维特征空间里的样本均值向量:,(1)通过变换映射到一维特征空间后,各类的平均值为:,(2)映射后,各类样本“类内离散度”定义为:,(3)显然,我们希望在映射之后,两类的平均值之间的距离越大越好,而各类的样本类内离散度越小越好。
因此,定义Fisher准则函数:(4)使最大的解就是最佳解向量,也就是Fisher的线性判别式。
2.求解从的表达式可知,它并非的显函数,必须进一步变换。
已知:,, 依次代入上两式,有:,(5)所以:(6)其中:(7)是原维特征空间里的样本类内离散度矩阵,表示两类均值向量之间的离散度大小,因此,越大越容易区分。
将(4.5-6)和(4.5-2)代入(4.5-4)式中:(8)其中:,(9)因此:(10)显然:(11)称为原维特征空间里,样本“类内离散度”矩阵。
是样本“类内总离散度”矩阵。
为了便于分类,显然越小越好,也就是越小越好。
将上述的所有推导结果代入表达式:可以得到:其中,是一个比例因子,不影响的方向,可以删除,从而得到最后解:(12)就使取得最大值,可使样本由维空间向一维空间映射,其投影方向最好。
是一个Fisher线性判断式.这个向量指出了相对于Fisher准则函数最好的投影线方向。
C.算法流程图左图为算法的流程设计图。
II.近邻法A. 近邻法线简述K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
模式识别大作业
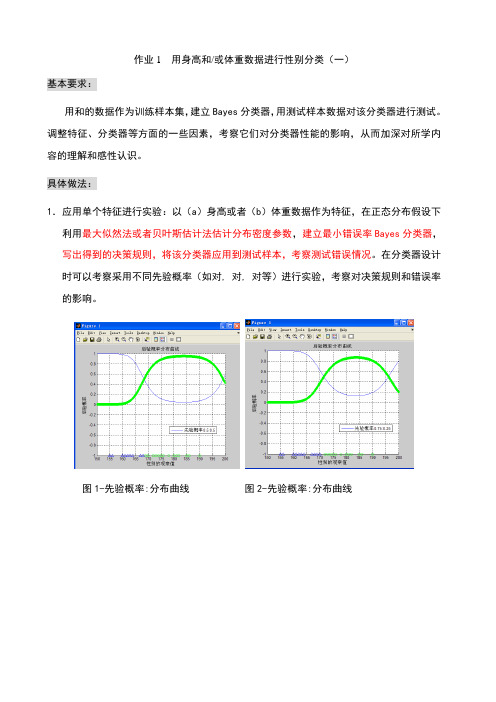
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如 vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率 vs. 图2先验概率 vs.图3先验概率 vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
设以ceshi1单个特征身高进行试验:决策表W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2); error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
模式识别大作业-许萌-1306020
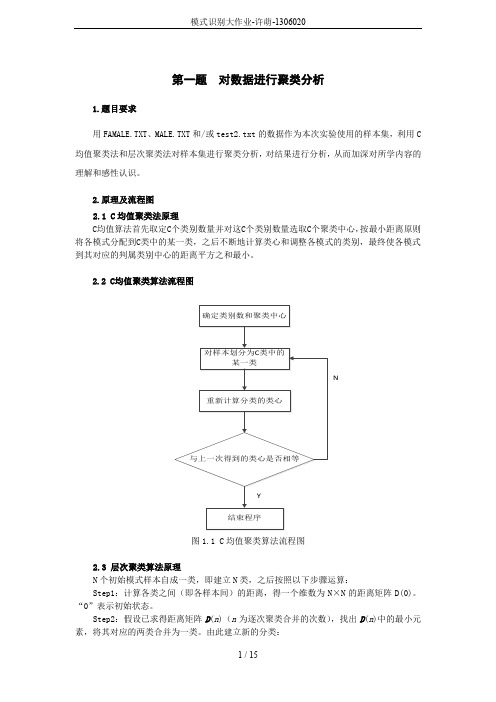
第一题对数据进行聚类分析1.题目要求用FAMALE.TXT、MALE.TXT和/或test2.txt的数据作为本次实验使用的样本集,利用C 均值聚类法和层次聚类法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。
2.原理及流程图2.1 C均值聚类法原理C均值算法首先取定C个类别数量并对这C个类别数量选取C个聚类中心,按最小距离原则将各模式分配到C类中的某一类,之后不断地计算类心和调整各模式的类别,最终使各模式到其对应的判属类别中心的距离平方之和最小。
2.2 C均值聚类算法流程图N图1.1 C均值聚类算法流程图2.3 层次聚类算法原理N个初始模式样本自成一类,即建立N类,之后按照以下步骤运算:Step1:计算各类之间(即各样本间)的距离,得一个维数为N×N的距离矩阵D(0)。
“0”表示初始状态。
Step2:假设已求得距离矩阵D(n)(n为逐次聚类合并的次数),找出D(n)中的最小元素,将其对应的两类合并为一类。
由此建立新的分类:Step3:计算合并后所得到的新类别之间的距离,得D (n +1)。
Step4:跳至第2步,重复计算及合并。
直到满足下列条件时即可停止计算:①取距离阈值T ,当D (n )的最小分量超过给定值 T 时,算法停止。
所得即为聚类结果。
②或不设阈值T ,一直到将全部样本聚成一类为止,输出聚类的分级树。
2.4层次聚类算法流程图N图1.2层次聚类算法流程图3 验结果分析对数据文件FAMALE.TXT 、MALE.TXT 进行C 均值聚类的聚类结果如下图所示:图1.3 C 均值聚类结果的二维平面显示将两种样本即进行聚类后的样本中心进行比较,如下表:从下表可以纵向比较可以看出,C 越大,即聚类数目越多,聚类之间差别越小,他们的聚类中心也越接近。
横向比较用FEMALE,MALE 中数据作为样本和用FEMALE,MALE ,test2中),1(),1(21++n G n G数据作为样本时,由于引入了新的样本,可以发现后者的聚类中心比前者都稍大。
模式识别大作业
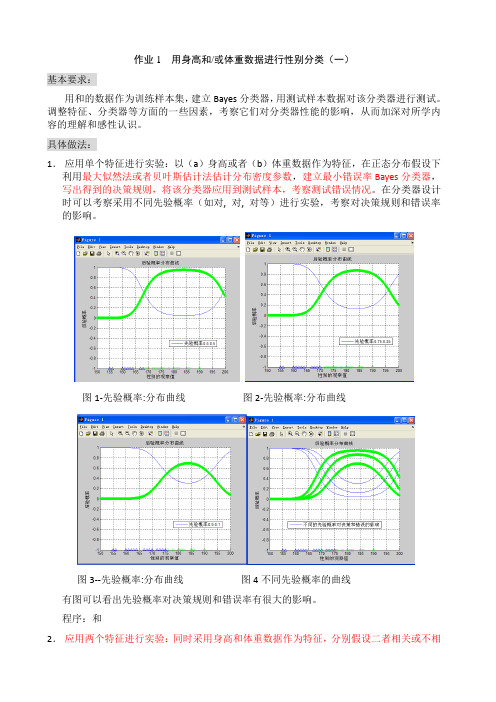
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率vs. 图2先验概率vs.图3先验概率vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2);error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、问题描述
现有sonar 和wdbc 这两个样本数据集,取一半数据作为训练样本集,其余数据作为测试样本集,通过编程实现分别用C 均值算法对测试样本集中的数据进行分类,进行10次分类求正确率的平均值。
二、算法描述
1.初始化:选择c 个代表点,...,,321c p p p p
2.建立c 个空间聚类表:C K K K ...,21
3.按照最小距离法则逐个对样本X 进行分类:
),(),,(min arg J i i
K x add p x j ∂=
4.计算J 及用各聚类列表计算聚类均值,并用来作为各聚类新的代表点(更新代表点)
5.若J 不变或代表点未发生变化,则停止。
否则转2.
),(1∑∑=∈=c
i K x i i p x J δ
6.计算正确率:将dtat(i,1)与trueflag(i,1)(i=1~n )进行比较,统计正确分类的样本数,并计算正确率将上述过程循环10次,得到10次的正确率,并计算平均正确率ave
算法流程图
三、实验数据
表1 实验数据
四、实验结果
表2 实验结果准确率(%)
注:表中准确率是十次实验结果的平均值
五、程序源码
用C均值算法对sonar分类(对wdbc分类的代码与之类似)clc;clear;
accuracy = 0;
for i = 1:10
data = xlsread('sonar.xls');
data = data';
%初始划分2个聚类
rand(:,1:size(data,2)) = data(:,randperm(size(data,2))'); %使矩阵元素按列重排
A(:,1) = rand(:,1);
B(:,1) = rand(:,2); %选取代表点
m = 1;
n = 1;
for i = 3:size(rand,2)
temp1 = rand(:,i) - A(:,1);
temp2 = rand(:,i) - B(:,1);
temp1(61,:) = [];
temp2(61,:) = []; %去掉标号后再计算距离
if norm(temp1) < norm(temp2)
m = m + 1; %A类中样本个数
A(:,m) = rand(:,i);
else
n = n + 1; %B类中样本个数
B(:,n) = rand(:,i);
end
end
%划分完成
m1 = mean(A,2);
m2 = mean(B,2);
%计算Je
J = 0;
for i = 1:m
temp = A(:,i) - m1;
temp(61,:) = []; %去掉标号的均值
J = J + norm(temp)^2;
end
for i = 1:n
temp = B(:,i) - m2;
temp(61,:) = [];
J = J + norm(temp)^2;
end
test = [A,B];
N = 0; %Je不变的次数
while N < m + n
rarr = randperm(m + n); %产生1-208即所有样本序号的随机不重复序列向量
y = test(:,rarr(1,1));
if rarr(1,1) <= m %y属于A类时
if m == 1
continue
else
temp1 = y - m1;
temp1(61,:) = [];
temp2 = y - m2;
temp2(61,:) = [];
p1 = m / (m - 1) * norm(temp1);
p2 = n / (n + 1) * norm(temp2);
if p2 < p1
test = [test,y];
test(:,rarr(1,1)) = [];
m = m - 1;
n = n + 1;
end
end
else %y属于B类时
if n == 1
continue
else
temp1 = y - m1;
temp1(61,:) = [];
temp2 = y - m2;
temp2(61,:) = [];
p1 = m / (m + 1) * norm(temp1);
p2 = n / (n - 1) * norm(temp2);
if p1 < p2
test = [y,test];
test(:,rarr(1,1)) = [];
m = m + 1;
n = n - 1;
end
end
end
A(:,1:m) = test(:,1:m);
B(:,1:n) = test(:,m + 1:m + n);
m1 = mean(A,2);
m2 = mean(B,2);
%计算Je
tempJ = 0;
for i = 1:m
temp = A(:,i) - m1;
temp(61,:) = []; %去掉标号的均值
tempJ = tempJ + norm(temp)^2;
end
for i = 1:n
temp = B(:,i) - m2;
temp(61,:) = [];
tempJ = tempJ + norm(temp)^2;
end
if tempJ == J
N = N + 1;
else
J = tempJ;
end
end %while循环结束
%判断正确率
correct = 0;
false = 0;
A(:,1:m) = test(:,1:m);
B(:,1:n) = test(:,m + 1:m + n);
c = mean(A,2);
if abs(c(61,1) - 1) < abs(c(61,1) - 2) %聚类A中大多为1类元素
for i = 1:m
if A(61,i) == 1
correct = correct + 1;
else
false = false + 1;
end
end
for i = 1:n
if B(61,i) == 2
correct = correct + 1;
else
false = false + 1;
end
end
else %聚类A中大多为2类元素
for i = 1:m
if A(61,i) == 2
correct = correct + 1;
else
false = false + 1;
end
end
for i = 1:n
if B(61,i) == 1
correct = correct + 1;
else
false = false + 1;
end
end
end
accuracy = accuracy + correct / (correct + false);
end
aver_accuracy = accuracy / 10
fprintf('用C均值算法对sonar进行十次分类的结果的平均正确率为%.2d %%.\n',aver_accuracy*100)
六.实验心得
本算法确定的K 个划分到达平方误差最小。
当聚类是密集的,且类与类之间区别明显时,效果较好。
对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为O(NKt),其中N是数据对象的数目,t是迭代的次数。
但
它需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。
这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果。