16位超前加法器实验报告
labreport1

集成电路设计实习报告——16bit全加器姓名:翟羽佳 学号:00348186 一、实验目的:1.采用定制的设计方法,完成16bit的加法器的设计2.面向给定的工艺库,完成电路设计,版图设计3.掌握CMOS集成电路的设计方法,熟悉从电路分析,电路设计到流片和测试的设计过程二、实验内容:设计一个16位加法器,满足以下要求:功能:16位的加法器可以正确完成带进位的2个16位二进制数的加法,并输出16位和信号以及最高位的进位输出信号速度:没有要求面积:对于core部分没有要求,对整个芯片IO不超过28个功耗:没有要求可靠性:没有要求完成以下步骤:1.电路设计2.版图设计3.版图验证三、实验过程、数据分析及结果:1.使用半定制设计方法,对电路结构进行设计。
一个16位的加法器,至少要有Ain,Bin两组16bit输入以及Cin进位输入,一组16bit输出sum和Cout进位输出。
这样至少需要16x2+1+16+1=50个IO,但芯片只能提供28个IO,故必须将部分并行的信号改为以时序控制的串行进行处理,并需要相应的存储器用以暂存数据,该设计不是一个简单的组合逻辑而是时序逻辑。
重新考虑以时序方式设计芯片:以串行方式输入Ain与Bin,在此过程中Cin保持不变,Ain与Bin在时钟信号clock的控制下逐个输入16位,暂存入两个寄存器RegA和RegB,由寄存器并行输出两组16位加数及被加数到一个通用的16位全加器,由全加器的组合逻辑产生16位sum和1位进位输出Cout,故需要IO数目1+1+1+16+1=20,再加上时钟控制信号clock,寄存器复位信号reset,置位信号set,故一共需要IO数目20+3=23个,完全满足要求。
结构示意图如下:用Verilog对硬件进行描述,首先描述全加器模块。
采用半定制的设计方法,在bd05core_verilog_library.v的单元库调用16个1‐bit全加器单元module BD_FA_B, 以串行进位的方式搭建成16‐bit全加器:相应的Verilog代码如下:module Adder_16bit(A, B, CI, CO, S);output [15:0] S;output CO;input [15:0] A;input [15:0] B;input CI;wire c0,c1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15;BD_FA_B adder_0 (.A(A[0]), .B(B[0]), .CI(CI), .CO(c0),.S(S[0]) );BD_FA_B adder_1 (.A(A[1]), .B(B[1]), .CI(c0), .CO(c1),.S(S[1]) );BD_FA_B adder_2 (.A(A[2]), .B(B[2]), .CI(c1), .CO(c2),.S(S[2]) );BD_FA_B adder_3 (.A(A[3]), .B(B[3]), .CI(c2), .CO(c3),.S(S[3]) );BD_FA_B adder_4 (.A(A[4]), .B(B[4]), .CI(c3), .CO(c4),.S(S[4]) );BD_FA_B adder_5 (.A(A[5]), .B(B[5]), .CI(c4), .CO(c5),.S(S[5]) );BD_FA_B adder_6 (.A(A[6]), .B(B[6]), .CI(c5), .CO(c6),.S(S[6]) );BD_FA_B adder_7 (.A(A[7]), .B(B[7]), .CI(c6), .CO(c7),.S(S[7]) );BD_FA_B adder_8 (.A(A[8]), .B(B[8]), .CI(c7), .CO(c8),.S(S[8]) );BD_FA_B adder_9 (.A(A[9]), .B(B[9]), .CI(c8), .CO(c9),.S(S[9]) );BD_FA_B adder_10 (.A(A[10]), .B(B[10]), .CI(c9), .CO(c10),.S(S[10]) );BD_FA_B adder_11 (.A(A[11]), .B(B[11]), .CI(c10), .CO(c11),.S(S[11]) );BD_FA_B adder_12 (.A(A[12]), .B(B[12]), .CI(c11), .CO(c12),.S(S[12]) );BD_FA_B adder_13 (.A(A[13]), .B(B[13]), .CI(c12), .CO(c13),.S(S[13]) );BD_FA_B adder_14 (.A(A[14]), .B(B[14]), .CI(c13), .CO(c14),.S(S[14]) );BD_FA_B adder_15 (.A(A[15]), .B(B[15]), .CI(c14), .CO(CO),.S(S[15]) );endmodule对外部寄存器部分的电路设计采用Verilog中的行为级描述,然后综合出结果。
试验二16位算术逻辑运算试验

实验三16位算术逻辑运算实验一、实验目的1、掌握16位运算器的数据传送通路组成原理。
2、进一步验证算术逻辑运算功能发生器74LS181的组合功能。
3、按要求和给出的数据完成几种指定的算术逻辑运算。
二、实验内容1、实验原理16位运算器数据通路如图2-1所示,其中运算器由四片74LS181以并/串形成16位字长的ALU构成。
低8位运算器的输出经过一个三态门74LS245(U33)到ALUO1插座,实验时用8芯排线和内部数据总线BUSD0~D7插座BUS1~6中的任一个相连,低8位数据总线通过LZD0~LZD7显示灯显示;高8位运算器的输出经过一个三态门74LS245(U33`)到ALUO1`插座,实验时用8芯排线和高8位数据总线BUSD8~D15插座KBUS1或KBUS2相连,高8位数据总线通过LZD8~LZD15显示灯显示;参与运算的四个数据输入端分别由四个锁存器74LS273(U29、U30、U29`、U30、)锁存,实验时四个锁存器的输入并联后用8芯排线连至外部数据总线EXD0~D7插座EXJ1~EXJ3中的任一个;参与运算的数据源来自于8位数据开并KD0~KD7,并经过一三态门74LS245(U51)直接连至外部数据总线EXD0~EXD7,输入的数据通过LD0~LD7显示。
2、实验接线本实验需用到6个主要模块:①低8位运算器模块;②数据输入并显示模块;③数据总线显示模块;④功能开关模块(借用微地址输入模块);⑤高8位运算器模;,⑥高8位(扩展)数据总线显示模块。
根据实验原理详细接线如下(接线①~⑤同实验一):①ALUBUS连EXJ3;②ALUO1连BUS1;③SJ2连UJ2;④跳线器J23上T4连SD;⑤LDDR1、LDDR2、ALUB、SWB四个跳线器拨至左侧(手动方式);⑥AR跳线器拨至左侧,同时开关AR拨至“1”电平;⑦ALUBUS`连EXJ2;⑧ALUO1`连KBUS1;⑨跳线器J19、J25拨至左侧(16位ALU状态);⑩高8位运算器区跳线器ZI2、CN0、CN4连上短路套。
基本算数运算(DSP实验报告)

基本算数运算一、实验目的和要求加、减、乘、除是数字信号处理中最基本的算术运算。
DSP 中提供了大量的指令来实现这些功能。
本实验学习使用定点DSP 实现16 位定点加、减、乘、除运算的基本方法和编程技巧。
本实验的演示文件为exer1.out。
二、实验原理1) 定点DSP 中的数据表示方法2) 实现16 位定点加法ld temp1,a ;将变量temp1 装入寄存器Aadd temp2,a ;将变量temp2 与寄存器A相加,结果放入A中stl a,add_result ;将结果(低16 位)存入变量add_result 中3)实现16 位定点减法stm #temp1,ar3 ;将变量temp1 的地址装入ar3 寄存器stm #temp3,ar2 ;将变量temp3 的地址装入ar2 寄存器sub *ar2+, *ar3,b ;将变量temp3 左移16 位同时变量temp1 也左移16 位,然后相减,结果放入寄存器B(高16位)中,同时ar2 加1。
sth b,sub_result ;将相减的结果(高16位)存入变量sub_result 4)实现16 位定点整数乘法rsbx FRCT ;清FRCT标志,准备整数乘ld temp1,T ;将变量temp1 装入T 寄存器mpy temp2,a ;完成temp2*temp1,结果放入A寄存器(32 位)5)实现16 位定点小数乘法我们使用下列ssbx FRCT ;FRCT=1,准备小数乘法ld temp1,16,a ;将变量temp1 装入寄存器A的高16位mpya temp2 ;完成temp2 乘寄存器A的高16 位,结果在B中,同时将temp2 装入T 寄存器sth b,mpy_f ;将乘积结果的高16 位存入变量mpy_f6)实现16 位定点整数除法代码如下:ld temp1,T ;将被除数装入T 寄存器mpy temp2,A ;除数与被除数相乘,结果放入A寄存器ld temp2,B ;将除数temp2 装入B 寄存器的低16位abs B ;求绝对值stl B,temp2 ;将B 寄存器的低16 位存回temp2ld temp1,B ;将被除数temp1 装入B寄存器的低16 位abs B ;求绝对值rpt #15 ;重复SUBC 指令16 次subc temp2,b ;使用SUBC 指令完成除法运算bcd div_end,agt ;延时跳转,先执行下面两条指令,然后判断A,若A>0,则跳转到标号div_end,结束除法运算stl B,quot_i ;将商(B寄存器的低16 位)存入变量quot_i sth B,remain_i ;将余数(B 寄存器的高16 位)存入变量remain_ixor B ;若两数相乘的结果为负,则商也应为负。
超前进位加法器设计实验实验
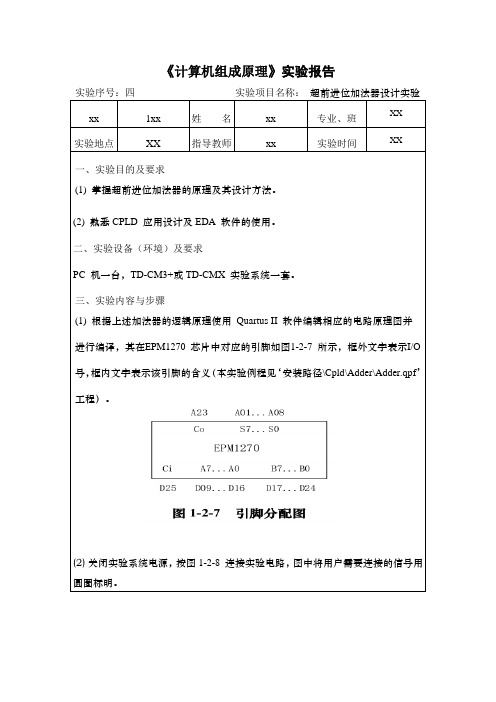
《计算机组成原理》实验报告实验序号:四实验项目名称:超前进位加法器设计实验xx 1xx 姓名xx 专业、班XX实验地点XX 指导教师xx 实验时间XX一、实验目的及要求(1) 掌握超前进位加法器的原理及其设计方法。
(2) 熟悉CPLD 应用设计及EDA 软件的使用。
二、实验设备(环境)及要求PC 机一台,TD-CM3+或TD-CMX 实验系统一套。
三、实验内容与步骤(1) 根据上述加法器的逻辑原理使用Quartus II 软件编辑相应的电路原理图并进行编译,其在EPM1270 芯片中对应的引脚如图1-2-7 所示,框外文字表示I/O 号,框内文字表示该引脚的含义(本实验例程见‘安装路径\Cpld\Adder\Adder.qpf’工程)。
(2)关闭实验系统电源,按图1-2-8 连接实验电路,图中将用户需要连接的信号用圆圈标明。
(3) 打开实验系统电源,将生成的POF 文件下载到EPM1270 中去。
(4) 以CON 单元中的SD17…SD10 八个二进制开关为被加数A,SD07…SD00 八个二进制开关为加数B,K7 用来模拟来自低位的进位信号,相加的结果在CPLD 单元的L7…L0 八个LED灯显示,相加后向高位的进位用CPLD 单元的L8 灯显示。
给A 和B 置不同的数,观察相加的结果。
四、实验结果与数据处理如在SD17...SD10中输入1111 1001,在SD07...SD00中输入1001 1111,在实验箱中可看到用来模拟低位与高位的进位信号K7、L8灯变亮,同时可看到A01...A08与L7...L0上的显示分别为1001与1000。
五、分析与讨论(心得)这个实验是上个实验的扩展,进一步加深了我对运算器的认识。
现实生活中我们也要学会对已有的知识的一种扩展补充,进一步加深对已有知识的巩固,并探索其更深层次的东西,设计出与众不同的东西来。
这个算法的核心是把8 位加法器分成两个 4 位加法器,先求出低 4 位加法器的各个进位,特别是向高4 位加法器的进位 C 4 。
16位全加器

四川理工大学课程设计任务书设计题目:采用门电路设计一个16位的全加器电路院系:计算机学院专业:计算机科学与技术班级:2008级6班指导教师:朱文忠学生姓名:赵******************目录:一引言 (1)1.1 设计背景 (1)1.2 设计分工 (1)二设计目的 (2)2.1 设计目的 (2)2.2 设计内容 (2)三设计过程 (2)3.1 硬件方案 (2)3.1.1 一位全加器的原理及设计 (2)3.1.2 四位全加器的原理及设计 (4)3.1.3 十六位全加器的原理及设计 (7)3.2 软件方案 (9)3.3 可行性论证 (13)3.4 结论 (15)四参考文献 (16)引言1. 设计背景随着计算机科学技术的发展,人们获得信息的途径更加多样,获取信息的速度更加快捷。
硬件的发展允许程序员编出很多精彩的使用软件,也使得计算机更加普及。
中央处理器CP U的好坏是影响和制约计算机速度和性能的关键因素。
而加法器是组成C PU的的重要部件,一般运算速度的快慢就取决与每秒执行加法的次数,加法器是算术逻辑单元中的基本逻辑器件。
例如:为了节省资源,减法器和硬件乘法器都可由加法器来构成。
但宽位加法器的设计是很耗费资源的,因此在实际的设计和相关系统的开发中需要注意资源的利用率和进位速度等两方面的问题。
多位加法器的构成有两种方式:并行进位和串行进位方式。
并行进位加法器设有并行进位产生逻辑,运算速度快;串行进位方式是将全加器级联构成多位加法器。
并行进位的并行加法器又可以分为组内并行、组间串行的进位链和组内并行、组间并行的进位链。
通常,并行加法器比串行级联加法器占用更多的资源,并且随着位数的增加,相同位数的并行加法器比串行加法器的资源占用差距也会越来越大。
它们的目的就是要进位信号的产生尽可能的快,因此产生了二重进位链或更高重进位链,显然进位速度的提高是以硬件设计的复杂化为代价来实现的。
2. 设计分工赵**(081010*****):硬件方案、排版吴**(081010*****):可行性论证、结论王**(081010*****):软件方案、找资料设计目的1.设计目的(1)掌握1位全加器的形成;(2)掌握4位片SN74LS181的原理;(3)用4片SN74LS181以并/串形成16位字长的ALU;(4)形成16位运算器数据通路结构;(5)将设计结果下载到实验板上,进行验证。
用单片机语言设计16位加法计算器实验报告

湖北第二师范学院计算机学院09计应单片机课程设计实验报告课程设计名称:电子计算器课程设计单位:10计应(1)班课设小组成员:徐凡(1060310039)凡平(1060310058)彭浩(1060310045)桂银(1060310010)潘光卉(1060300033)完成时间:2012年04月02日至2012年04月 24 日单片机课程设计实验报告课程设计题目:简易计算器作品功能描述:当通过输入键盘数字时,能够在显示器上显示输出的数值,并且通过想实现的简单运算功能,实现计算器的加、减、乘、除和清零,并将结果显示出来。
小组成员工作分工:徐凡:程序主框架的构造和主要功能函数的设计。
凡平:原理图的设计和硬件的焊接。
彭浩:基本功能函数的设计(“+,-,*,/”)。
桂银:程序流程图的设计和键盘扫描程序的实现。
潘光卉:编写文档和功能测试。
硬件电路设计:本设计中我们用的是AT89C52芯片,LCD1602 (PROTEUS中为LM016L)就是那个液晶屏,因为可以显示2行16个字符,故叫做LCD1602.11.0592M或12M晶振(CRYSTAL),两者均可,但要涉及到串口需选用12MKEYPAD-SMALLCALC就是那个4X4键盘电容20~30PF(CAP),接最小电路电容10PF主要接复位电路RESPACK-8排阻,为20K的,一个引脚接正极,另8个引脚接I/O口接RES电阻10K,接复位电路实物照片:硬件原理图原理说明:1,上电后,屏幕初始化;2,计算。
按下数字键,屏幕显示要运行的第一个数字,再按下符号键,然后再按下数字键,屏幕显示要运算的第二个数字,最后按下“=”号键,屏幕上显示出计算结果。
3,如果要再次计算,可以按下“ON/C”键清零,或者继续按下数字键,即可重新计算。
键盘使用说明如下:按键功能说明:Array“+”实现两个数的相加“-”实现两个数的相减“×”实现两个数的乘积“÷”实现两个数商的运算“ON/C”计算器显示的清零和接通电源程序控制流程图:软件设计:在程序设计方法上,模块化程序设计是单片机应用中最常用的程序设计方法。
十六位运算器ALU实验报告
⼗六位运算器ALU实验报告学⽣实验报告实验名称⽤Verilog HDL语句实现16位运算器的功能实验⽇期2013年10⽉19学号2012551212姓名李超班级12计算机科学与技术⼀班⼀、实验⽬的与要求1、了解运算器的组成结构;2、掌握算术逻辑运算器的⼯作原理;3、掌握简单运算器的数据传送通道4、掌握⽤Verilog HDL实现16位简单运算器的设计⼆、实验原理74LS181的逻辑功能表图中,S0到S3是四个控制端,⽤于选择进⾏何种运算。
M ⽤于控制ALU进⾏算术运算还是逻辑运算。
当M=0时,M对进位信号没有任何影响,Fi值与操作数Ai,Bi以及地位向本位进位Cn+1有关,所以M=0时进⾏算术运算。
操作数⽤补码表⽰,“加”只算术加,运算时考虑进位;“+”指逻辑加,不考虑进位;减法运算时,减法取反码运算后⽤加法器实现,结果输出为A减B减1在最末位产⽣⼀个强迫进位(加1),以得到A减B的结果。
当M=1时,封锁了各位的进位输出Cn+i=0,因此各位的运算结果Fi仅与操作数Ai,Bi有关,此时进⾏逻辑运算。
三、实验内容与步骤1.根据书85⾯的逻辑功能表编写Verilog HDL语句,编译,仿真等步骤。
实验代码SN74181:module sn74181(A,B,S,Cn,M,F,C);parameter bit_width=4;output [bit_width-1:0]F;output C;input [bit_width-1:0]A,B,S;input Cn,M;reg C;reg Y=0;reg [bit_width-1:0]F;reg t;initial C=0;always@(S)begincase(S)4'b0000:beginif(M) {t,F}=~{1'b0,A};elsebeginif(Cn) {t,F}={1'b0,A};else {t,F}={1'b0,A}|1;endend4'b0001:beginif(M) {t,F}=~({1'b0,A}|{1'b0,B});endend4'b0010:beginif(M) {t,F}=~{1'b0,A}&{1'b0,B};elsebeginif(Cn) {t,F}={1'b0,A}|({1'b0,~B});else {t,F}=({1'b0,A}|({1'b0,~B}))+1;endend4'b0011:beginif(M) {t,F}=0;elsebeginif(Cn) {t,F}={t,F}-1;else {t,F}=0;endend4'b0100 :beginif(M) {t,F}=~({1'b0,A}&{1'b0,B});elsebeginif(Cn) {t,F}={1'b0,A}+({1'b0,A}&({1'b0,~B}));else {t,F}={1'b0,A}+({1'b0,A}&({1'b0,~B}))+1;endend4'b0101 :beginif(M) {t,F}={1'b0,~B};elsebeginif (Cn) {t,F}=({1'b0,A}&({1'b0,~B}))+({1'b0,A}|{1'b0,B}); else{t,F}=({1'b0,A}&({1'b0,~B}))+({1'b0,A}|{1'b0,B})+1; endend4'b0110 :beginif(M) {t,F}={1'b0,A}^{1'b0,B};elsebeginif(Cn) {t,F}={1'b0,A}-{1'b0,B}-1;else {t,F}={1'b0,A}-{1'b0,B};endend4'b0111 :beginelse {t,F}={1'b0,A}&({1'b0,~B});endend4'b1000 :beginif(M) {t,F}={1'b0,~A}|{1'b0,B};elsebeginif(Cn) {t,F}={1'b0,A}+({1'b0,A}&{1'b0,B});else {t,F}={1'b0,A}+({1'b0,A}&{1'b0,B})+1;end4'b1001 :beginif(M) {t,F}={1'b0,~(A^B)};elsebeginif(Cn) {t,F}={1'b0,A}+{1'b0,B}+1;else {t,F}={1'b0,A}+{1'b0,B};endend4'b1010 :beginif(M) {t,F}={1'b0,B};elsebeginif(Cn){t,F}=({1'b0,A}&{1'b0,B})+({1'b0,A}|({1'b0,~B})); else{t,F}=({1'b0,A}&{1'b0,B})+({1'b0,A}|({1'b0,~B}))+1; end4'b1011 :beginif(M) {t,F}={1'b0,A}&{1'b0,B};elsebeginif(Cn) {t,F}={1'b0,A}&{1'b0,B}-1;else {t,F}={1'b0,A}&{1'b0,B};endend4'b1100 :beginif(M) {t,F}=1;elsebeginif(Cn) {t,F}={1'b0,A}+{1'b0,A};else {t,F}={1'b0,A}+{1'b0,A}+1;endend4'b1101:beginelse {t,F}={1'b0,A}+({1'b0,A}|{1'b0,B})+1; endend4'b1110 :beginif(M) {t,F}={1'b0,A}|{1'b0,B};elsebeginif(Cn) {t,F}={1'b0,A}+({1'b0,A}|({1'b0,~B})); else {t,F}={1'b0,A}+({1'b0,A}|({1'b0,~B}))+1; endend4'b1111 :beginif(M) {t,F}={1'b0,A};elsebeginif(Cn) {t,F}={1'b0,A}-1;else {t,F}={1'b0,A};endendendcaseC=t;endEndmoduleSHIFT:module shift(A,choose,result); parameter bit_width=16;input [bit_width-1:0]A;input[1:0] choose;output [bit_width-1:0] result;reg [bit_width-1:0]result;always@(A or choose)begincase(choose)2'b01:beginresult=A<<1;end2'b10:beginresult={A[0],A[15:1]};end2'b11:beginresult=$signed(A)>>>1;endendcaseendEndmoduleinput [width-1:0] r;input [1:0]x;output [width-1:0] result; output overflow,z,c,p,n;reg [width-1:0] a,b;reg [3:0]s;reg [1:0]sh;reg cn,m,ov;wire co1,co2,co3;wire [width-1:0]co,re1,re2; always@ (x or r)begincase(x)2'b11: begina=r;end2'b10: beginb=r;end2'b00: begins=r[3:0];sh=r[5:4];m=r[8];cn=r[12]; endendcaseendsn74181 u_sn74181_1(.A(a[3:0]),.B(b[3:0]),.S(s),.M(m),.Cn(cn),.C(co1),.F(re1[3:0]));sn74181 u_sn74181_2 (.A(a[7:4]),.B(b[7:4]),.S(s),.M(m),.Cn(co1),.C(co2),.F(re1[7:4]));sn74181 u_sn74181_3 (.A(a[11:8]),.B(b[11:8]),.S(s),.M(m),.Cn(co2),.C(co3),.F(re1[11:8]).B(b[15:12]),.S(s),.M(m),.Cn(co3),.C(overflow),.F(re1[15:12]));shift u_shift(.A(a),.choose(sh),.result(re2[15:0]));assign result=(sh?re2:re1);assign z=~|result;assign n=result[15];Endmodule仿真波形图按照模式⼀电路图结构图设置对应的引脚参数。
16位加法器设计
计算机组成原理课程设计报告题目 16位加法器设计B院系信息科学技术学院专业计算机科学与技术班级 11计本(2)教师学生学号内容提要本设计在其他基本加法器的基础上改进为超前进位加法器,它避免了串行进位加法器的进位延迟,提高了速度。
其主要分为四章,第一章为设计概述,主要介绍设计的任务、目标,以及设计环境,第二章为总体设计方案,其主要介绍本设计中系统设计的框架。
第三章为仿真测试,给出了系统在仿真环境下波形测试结果,看是否满足题目要求。
第四章为设计心得总结,主要是介绍在经过本次设计后,自己的一些心得体会。
最后还给出了本设计的一些参考文献。
前言计算机组成原理是一门实践性很强的课程;其课程设计目的在于综合运用所学知识,全面掌握微型计算机及其接口的工作原理、编程和使用方法;在设计中,通过小组协作提出设计方案,进行软件设计、调试,最后获得正确的结果,可以加深和巩固对理论知识的更好掌握,进一步建立计算机应用系统体概念,初步掌握单片机软、硬件开发方法,为以后进行实际的单片机软、硬件应用开发奠定良好的基础。
本设计是利用74181、74182芯片组成了16位加法器的组间组内并行。
目录1设计概述 (5)1.1设计任务 (5)1.2 设计要求 (5)1.3设计环境 (5)2总体设计方案 (6)3仿真测试 (9)4设计个人总结 (10)参考文献: (10)1设计概述1.1设计任务1、掌握MaxPlus2软件的使用方法。
2、熟悉74系列芯片的组成和工作过程。
3、掌握半加器,一位全加器的设计原理,掌握超前进位产生电路的设计方法。
4、正确将电路原理图下载到试验箱中。
5、正确通过实验箱连线实现一位二进制数的相加并得到正确结果。
6、完成设计实验报告。
7、完成课程设计答辩。
1.2 设计要求1、巩固和运用所学课程,理论联系实际,提高分析、解决计算机技术实际问题的独立工作能力。
2、学会使用MAX-PLUSⅡ软件设计电路原理图及功能模拟3、熟悉常用的门电路1.3设计环境MaxPlus22总体设计方案1、半加器的设计原理 半加器逻辑电路半加器逻辑表达式 S=B A ⊕ AB C =半加器真值表A B C S 0 0 0 0 0 1 0 1 1 0 0 1 11 1 02、一位全加器的设计原理 一位全加器逻辑电路CA B S=1&74182一位全加器逻辑表达式进位输出()i i i i i i B A C B A C +⊕=-1相加之和 1-⊕⊕=i i i i C B A F 一位加法器真值表A B 1-i C F i C 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 1 1 0 0 1 0 0 1 1 0 0 1 1 0 1 1 0 1 0 1 111113、十六位并行加法器的设计思路1. 先设计一个半加器然后两个半加器合并成一个一位的全加器,最后用16个一位的全加器组合成一个16位的全加器;2. 先设计一个一位全加器,然后16个并联组成一个16位全加器3. 使用4片74181和1片74182芯片采用双重分组跳跃进位组成16位并行加法器这里我们组采用的是第三个方法来实现16位并行加法器的。
74181 ALU的设计及16位加法功能验证
74181 ALU的设计及16位加法功能验证This is a controlled document.Printed copies must have the revision number verified prior to each use.修改记录分工情况目录修改记录................................................................................................... 错误!未定义书签。
分工情况................................................................................................... 错误!未定义书签。
目录................................................................................................... 错误!未定义书签。
1.0B关于本文 ......................................................................................... 错误!未定义书签。
1.1 4B目的............................................................................................ 错误!未定义书签。
1.2 5B术语列表........................................................................................ 错误!未定义书签。
1.3 6B相关文档........................................................................................ 错误!未定义书签。
十六进制加减计数器实验报告
本科生实验报告十六进制加减计数器电路实验专业名称:课程名称:数据逻辑与EDA指导教师:学生学号:学生姓名:二○一九年十一月1、实验目的1.1了解时序逻辑电路的基本功能1.2掌握时序逻辑电路的设计方法1.3熟悉时序逻辑电路的工作过程2、实验原理2.1定义:在逻辑电路中,任何时刻的稳定输出不仅取决于该时刻的输入,且与过去的输入相关。
2.2类型:边沿触发器、电平触发器、加法计数器、减法计数器、可逆计数器、序列检测器、采样控制器等。
3、实验设备:3.1 PC机3.2 教学实验箱3.3 通信线4、实验内容:4.1任务:设计一个两位16进制加减可逆的计数器,具有内部脉冲和手动计数功能,结果在7段数码管上显示。
4.2接线:(1)用插线连接插孔24,32,25到实验台的1HZ,10HZ和100HZ上,作为CLK1HZ,CLK10HZ,CLK100kHZ,三个频率的输入端;(2)用插线将实验台上的6个数码管的七段码a-h连接到插孔40,41,42,43,44,45,47,48上,作为七段码输出端;(3)七段数码管的位码S(0)-S(5)接到实验台的插孔51,52,53,55,57,58上,作为七段码位码输出端;(4)实验台上的开关K0接到插孔26上,作为en的输入开关。
en=1时手动,en=0时为自动;(5)手动脉冲按键din接单脉冲,然后接在28脚上输入;(6)复位键rst接K1开关连接在27脚输入;(7)加减控制键rev接K2开关连接在31脚输入4.3硬件描述语言源代码:module cnt(clk100khz,clk1hz,clk10hz,rst,en,din,scan,dout,rev);input rst;//复位键input rev;//加减控制器input en;//手动或自动计数开关input din;//手动计数脉冲input clk100khz,clk1hz,clk10hz;//分别为数码管刷新,自动计数,手动计数频率output[7:0]dout;//数码管七段码output[5:0]scan;//数码管位码reg[7:0]dout;reg[5:0]scan;reg f1,f2,c;//数码管个位和十位敏感信号;c为手动计数参数reg[2:0]cnt;//数码管扫描参数reg[3:0]dat;//数码管位码扫描参数reg[3:0]data1,data2;//个位和十位计数参数always@(posedge clk10hz) //设置自动计数和手动计数begin if(!din) c<=1; //din为1时,c=0;din为0时,c=1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
16位超前加法器设计实验
一、实验分析:
四位超前进位加法器HDL程序:
module add4_head ( a, b, ci, s, pp, gg);
input[3:0] a;
input[3:0] b;
input ci;
output[3:0] s;
output pp;
output gg;
wire[3:0] p;
wire[3:0] g;
wire[2:0] c;
assign p[0] = a[0] ^ b[0];
assign p[1] = a[1] ^ b[1];
assign p[2] = a[2] ^ b[2];
assign p[3] = a[3] ^ b[3];
assign g[0] = a[0] & b[0];
assign g[1] = a[1] & b[1];
assign g[2] = a[2] & b[2];
assign g[3] = a[3] & b[3];
assign c[0] = (p[0] & ci) | g[0];
assign c[1] = (p[1] & c[0]) | g[1];
assign c[2] = (p[2] & c[1]) | g[2];
assign pp = p[3] & p[2] & p[1] & p[0];
assign gg = g[3] | (p[3] & (g[2] | p[2] & (g[1] | p[1] & g[0])));
assign s[0] = p[0] ^ ci;
assign s[1] = p[1] ^ c[0];
assign s[2] = p[2] ^ c[1];
assign s[3] = p[3] ^ c[2];
endmodule
p表示进位否决信号(pass),如果p为0就否决调前一级的进位输入。
否决的意思就是即使前一级有进位,本级也不会向后一级产生进位输出。
g表示进位产生信号(generate),如果g为1就表示一定会向后一级产生进位输出。
p[n] = a[n] ^ b[n]这句话的意思是说,当a=1,b=0或a=0,b=1时前一级的进位输入信号不能否决。
这样就有个问题了,即当a=1,b=1时前一级的进位输入信号也不能否决啊,怎么没有体现出来?其实当a=1,b=1时产生了进位产生信号g,它的优先级高于p信号,就忽略了p信号,直接产生了向后一级产生进位输出,是没有逻辑错误的。
g[n] = a[n] & b[n]
这句话的意思是说,如果a=1,b=1时就直接向后一级产生进位输出信号,而不用考虑其它的任何因素。
pp表示本级模块的进位否决信号,如果pp为0就否决调前一级模块的进位输入。
gg表示本级模块进位产生信号,如果gg为1就表示一定会向后一级模块产生进位输出。
这两个信号pp和gg都是用于超前进位模块之间的连接,如4个4位超前进位加法器模块再使用超前进位逻辑进行连接构成16位超前进位加法器。
pp = p[3] & p[2] & p[1] & p[0]
这句话的意思是说,当a+b=1111时,此时前一级模块的进位输入不能被否决。
gg = g[3] | (p[3] & (g[2] | p[2] & (g[1] | p[1] & g[0])))
这一句可以这样理解,它是嵌套了几层的:
1. 如果g[3]=1,即最高位要产生进位位,则表示本模块一定会向后一级模块产生进位输出,于是gg=1。
2. 如果g[3]=0,但是p[3]=1(表示不能否决掉前一级的进位),而且前一级又有进位输入时,gg=1。
3. 以下层次的关系依此类推。
总之,可以看出几个规律:
1. 用于模块内部的p和g信号,它们的产生都不依赖于模块内部各位之间的进位信号,而是由输入信号a和b直接得到的。
2. 用于模块外部的pp和gg信号,它们的产生也不依赖于该模块的进位输入信号,pp和gg信号用于超前进位链的再次级联。
3. 当进位产生信号(g或gg)为1时,一定向后一级产生进位输出,此时不需要等待前一级进位信号的输入,速度得以加快。
4. 当进位产生信号(g或gg)为0时,向不向后一级产生进位输出就不好说了。
我们能肯定的是如果此时进位否决信号(p或pp)为0,则一定不会向后一级产生进位输出,这种情况也不需要等待前一级进位信号的输入,速度还是得以加快。
5. 如果进位产生信号(g或gg)为0,并且进位否决信号(p或pp)为1,向不向后一级产生进位输出就完全取决于前一级进位信号的输入了,这时花的时间最长。
二、实验所需程序:
module cla16(a,b,s); //top module 含有四个4 位超前进位加法器子模块
input [15:0] a,b;//定义输入信号
output [16:0] s;
wire pp4,pp3,pp2,pp1;
wire gg4,gg3,gg2,gg1;
wire [14:0] Cp;
wire [15:0] p,g;
pg i0 (a[15:0],b[15:0],p[15:0],g[15:0]);
add i1 (p[3],p[2],p[1],p[0],g[3],g[2],g[1],g[0],pp1,gg1);
add i2 (p[7],p[6],p[5],p[4],g[7],g[6],g[5],g[4],pp2,gg2);
add i3 (p[11],p[10],p[9],p[8],g[11],g[10],g[9],g[8],pp3,gg3);
add i4 (p[15],p[14],p[13],p[12],g[15],g[14],g[13],g[12],pp4,gg4);
add i5 (pp4,pp3,pp2,pp1,gg4,gg3,gg2,gg1,pp5,gg5);
add4 l0 (p[3],p[2],p[1],p[0],g[3],g[2],g[1],g[0],1'b0,Cp[2],Cp[1],Cp[0]);
add4 l1 (p[7],p[6],p[5],p[4],g[7],g[6],g[5],g[4],Cp[3],Cp[6],Cp[5],Cp[4]);
add4 l2 (p[11],p[10],p[9],p[8],g[11],g[10],g[9],g[8],Cp[7],Cp[10],Cp[9],Cp[8]);
add4 l3 (p[15],p[14],p[13],p[12],g[15],g[14],g[13],g[12],Cp[11],Cp[14],Cp[13]); assign s[0]=p[0]^1'b0;
assign s[1]=p[1]^Cp[0];
assign s[2]=p[2]^Cp[1];
assign s[3]=p[3]^Cp[2];
assign s[4]=p[4]^Cp[3];
assign s[5]=p[5]^Cp[4];
assign s[6]=p[6]^Cp[5];
assign s[7]=p[7]^Cp[6];
assign s[8]=p[8]^Cp[7];
assign s[9]=p[9]^Cp[8];
assign s[10]=p[10]^Cp[9];
assign s[11]=p[11]^Cp[10];
assign s[12]=p[12]^Cp[11];
assign s[13]=p[13]^Cp[12];
assign s[14]=p[14]^Cp[13];
assign s[15]=p[15]^Cp[14];
assign s[16]=pp5|gg5;
endmodule
module add4(p[3],p[2],p[1],p[0],g[3],g[2],g[1],g[0],Co,Cp[2],Cp[1],Cp[0]); //4位超前进位加法器模块
input [3:0]p,g;
input Co;
output [2:0] Cp;
assign Cp[0]=g[0]|p[0]&Co;
assign Cp[1]=g[1]|p[1]&Cp[0];
assign Cp[2]=g[2]|p[2]&Cp[1];
endmodule
module add(p[3],p[2],p[1],p[0],g[3],g[2],g[1],g[0],pp,gg);
//模块间进位信号产生
input [3:0]p,g;
output pp,gg;
assign pp=p[3]&p[2]&p[1]&p[0];
assign gg=g[3]|(p[3]&(g[2]|p[2]&(g[1]|p[1]&g[0])));
endmodule
module pg(a,b,p,g); //进位产生信号、进位传递信号产生模块
input [15:0] a,b;
output [15:0] p,g;
assign p=a^b;
assign g=a&b;
endmodule
三、结果分析
资源占用情况:
延时分析:仅对a,b第16位设值,在10ns内置1,进而得到计算的时延情况。