elasticsearch index_patterns格式 -回复
基于Elasticsearch检索型智能问答机器人实现方案(详细)
一、设计方案最近项目需要在做一个客服问答系统,里面涉及到了大量的问题搜索。
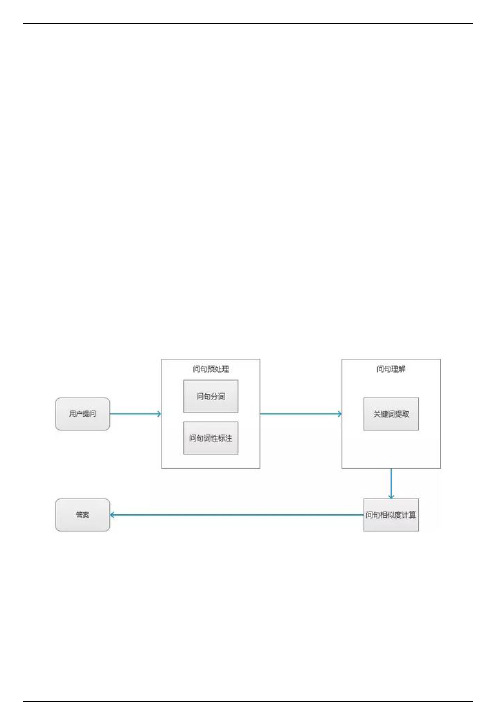
1.1 系统功能在特定的垂直业务领域下,问答系统可以回答用户所提出的一系列问题,其主要功能包括问句预处理、问句理解、问句相识度匹配和标签分类。
1)问句预处理:将用户问句进行分词和词性标注2)问句理解:提取问句中的关键词3)问句相似度匹配:将问句与每个标签分类下的问题进行相似度计算后召回4)标签分类:为问句添加标签,在标签分类下的问题匹配相似问题,以此来提升机器理解能力和匹配精度,同时也可以对问答对进行分类化管理,可以按业务分类、问题所属分类等自己需要的维度来管理问答对,提高问答对的管理效率。
标签分类根据实际业务场景需求进行分类,切记标注标签分类的时候需要保持数据的一致性1.2 问答型机器人处理流程:1.3 整体产品结构图以下是问答系统整体产品结构图,主要围绕核心模块有问答管理、关键词管理、未知问题管理。
则其余模块不会做详细讲解。
按照传统的mysql去完成,虽然可以很容易地实现,但是性能方面却很力不从心,要知道mysql对like查询支持不好,如果数据量一大,很容易造成全表扫描,十分影响用户体验。
采用redis远程字典式缓存服务,将部分热点数据进行缓存,能够快速响应用户对热点内容读取的需求,另外点赞收藏等易变化的部分数据不立即存入数据库,而是通过缓存操作加定时任务,实现弱一致性的数据存取也可实现。
但是作为主业务通过最短的对话轮次(一问一答),获得精准、直接的答案以及更好地完成任务,来满足用户的需求。
我们参考百度,京东,谷歌最终选择,elasticsearch 搜索引擎解决这个问题。
1.4 技术选型最终技术选型问答系统使用Python elasticsearch PythonIA(统一管理API)实现题库检索。
前后端分离,题库分类,标签,权限管理等我们使用JAVAMySql实现业务的统一管理。
页面展示使用VUE uni-app实现!二、Elasticsearch介绍Elasticsearch是一个基于Lucene的搜索服务器。
elasticsearch index_patterns格式

elasticsearch index_patterns格式在使用elasticsearch进行数据索引和搜索时,index_patterns是一个非常重要的概念。
它指定了索引的命名模式和匹配规则,可以帮助我们更有效地组织和管理数据。
本文将介绍elasticsearch index_patterns格式,探讨其用法和一些相关注意事项。
1. 什么是index_patterns在elasticsearch中,数据是以索引为单位进行组织的。
而index_patterns可以看作是索引的名称模式,它决定了一个或多个索引名称的命名规则。
通过利用通配符和正则表达式,我们可以根据需求来定义这些模式。
2. index_patterns的语法index_patterns通常以字符串的形式表示。
当需要定义多个模式时,可以使用逗号进行分隔。
以下是一些常见的用法示例:- "pattern-*":匹配以"pattern-"开头的索引名称。
- "*-pattern":匹配以"-pattern"结尾的索引名称。
- "pattern-?,pattern-*":匹配以"pattern-"开头的单字符或多字符索引名称。
- "pattern-{2015,2016}":匹配以"pattern-"开头,并后跟2015或2016的索引名称。
3. 使用正则表达式除了通常的通配符外,我们还可以使用正则表达式来定义更复杂的匹配规则。
例如,"[0-9]{4}-[0-9]{2}-[0-9]{2}"可以匹配以日期格式(如"2022-05-30")命名的索引。
需要注意的是,正则表达式需要用斜杠(/)进行包裹,并保证其格式正确性和有效性。
同时,正则表达式的性能相对较差,因此在实际使用中应避免过于复杂的模式。
ESQueryDSL以及Java中使用matchQuery和termQuery的区别

ESQueryDSL以及Java中使⽤matchQuery和termQuery的区别1. DSL简单介绍官⽅介绍如下: Elasticsearch provides a full Query DSL (Domain Specific Language) based on JSON to define queries. Think of the Query DSL as an AST (Abstract Syntax Tree) of queries, consisting of two types of clauses:Leaf query clauses Leaf query clauses look for a particular value in a particular field, such as the match, term or range queries. These queries can be used by themselves.Compound query clauses Compound query clauses wrap other leaf or compound queries and are used to combine multiple queries in a logical fashion (such as the bool or dis_max query), or to alter their behaviour (such as the constant_score query). Query clauses behave differently depending on whether they are used in query context or filter context.2.数据构造1. 创建索引类型1. 创建⼀个账号索引,字段如下:PUT /accounts{"mappings": {"properties": {"userid": {"type": "long"},"username": {"type": "keyword"},"fullname": {"type": "text"},"sex": {"type": "double"},"birth": {"type": "date"}}}}2. 创建⼀个订单索引PUT /orders{"mappings": {"properties": {"orderid": {"type": "long"},"ordernum": {"type": "keyword"},"username": {"type": "keyword"},"type": "text"},"createTime": {"type": "date"},"amount": {"type": "double"}}}}2. 查看索引字段liqiang@root MINGW64 ~/Desktop$ curl -X GET http://localhost:9200/accounts/_mapping?pretty=true% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 10037510037500120960 --:--:-- --:--:-- --:--:-- 366k{ "accounts" : {"mappings" : {"properties" : {"birth" : {"type" : "date"},"fullname" : {"type" : "text"},"sex" : {"type" : "double"},"userid" : {"type" : "long"},"username" : {"type" : "keyword"}}}}}liqiang@root MINGW64 ~/Desktop$ curl -X GET http://localhost:9200/orders/_mapping?pretty=true% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 10044810044800144510 --:--:-- --:--:-- --:--:-- 437k{ "orders" : {"mappings" : {"properties" : {"amount" : {"type" : "double"},"createTime" : {"type" : "date"},"description" : {"type" : "text"},"orderid" : {"type" : "long"},"ordernum" : {},"username" : {"type" : "keyword"}}}}}3. 创建⼗条数据1.创建⽤户数据private static void createDocument() throws UnknownHostException, IOException, InterruptedException { // on startupSettings settings = Settings.builder().put("", "my-application").build();TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));for (int i = 0; i < 10; i++) {XContentBuilder builder = XContentFactory.jsonBuilder().startObject().field("username", "zhangsan" + i) .field("fullname", "张三" + i).field("sex", i % 2 == 0 ? 1 : 2).field("userid", (i + 1)).field("birth", new Date()).endObject();// 存到users索引中的user类型中IndexResponse response = client.prepareIndex("accounts", "_doc").setSource(builder).get();// 打印保存信息String _id = response.getId();System.out.println("_id " + _id);Thread.sleep(1 * 1000);}// on shutdownclient.close();}结果:_id BpeN0nMBntNcepW152XL_id B5eN0nMBntNcepW17WVO_id CJeN0nMBntNcepW18mWF_id CZeN0nMBntNcepW192XD_id CpeN0nMBntNcepW1_GXZ_id C5eO0nMBntNcepW1AWWe_id DJeO0nMBntNcepW1BmUf_id DZeO0nMBntNcepW1CmXE_id DpeO0nMBntNcepW1D2Xh_id D5eO0nMBntNcepW1FGVL在kibana中使⽤Discover搜索数据如下:2.创建订单数据private static void createDocument() throws UnknownHostException, IOException, InterruptedException { // on startupSettings settings = Settings.builder().put("", "my-application").build();TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));for (int i = 0; i < 10; i++) {XContentBuilder builder = XContentFactory.jsonBuilder().startObject().field("amount", i).field("ordernum", "order" + i).field("username", "zhangsan" + (i % 5)).endObject();// 存到users索引中的user类型中IndexResponse response = client.prepareIndex("orders", "_doc").setSource(builder).get();// 打印保存信息String _id = response.getId();System.out.println("_id " + _id);Thread.sleep(1 * 1000);}// on shutdownclient.close();}结果:_id EJfo0nMBntNcepW15mUP_id EZfo0nMBntNcepW16mW3_id Epfo0nMBntNcepW172VR_id E5fo0nMBntNcepW182Xr_id FJfo0nMBntNcepW1-WXO_id FZfo0nMBntNcepW1_mU5_id Fpfp0nMBntNcepW1AmV2_id F5fp0nMBntNcepW1BmXi_id GJfp0nMBntNcepW1C2VR_id GZfp0nMBntNcepW1D2WOkibana查看数据:(1)kibana的Management-》Index patterns-》Create index pattern(2)Discover 查看数据4. 创建9条news数据(1)字段映射如下 =content字段采⽤ik分词器进⾏分词{properties={creator={type=text, fields={keyword={ignore_above=256, type=keyword}}}, createTime={type=date}, description= {type=double}, id={type=long}, title={search_analyzer=ik_smart, analyzer=ik_max_word, type=text}, type={type=text, fields= {keyword={ignore_above=256, type=keyword}}}, content={search_analyzer=ik_smart, analyzer=ik_max_word, type=text}}}(2) 数据如下:{"creator":"creator1","createTime":"2020-08-27T02:52:24.491Z","type":"java","title":"java记录","content":"这⾥是java记录"} {"creator":"creator2","createTime":"2020-08-27T02:52:31.677Z","type":"vue","title":"vue记录","content":"这⾥是vue记录"} {"creator":"creator3","createTime":"2020-08-27T02:52:31.915Z","type":"js","title":"js记录","content":"这⾥是js记录"} {"creator":"creator4","createTime":"2020-08-27T02:52:32.067Z","type":"es","title":"js记录","content":"这⾥是js记录"} {"creator":"creator7","createTime":"2020-08-27T02:52:33.733Z","type":"vue","title":"vue记录","content":"这⾥是vue记录"} {"creator":"creator6","createTime":"2020-08-27T02:52:32.395Z","type":"java","title":"java记录","content":"这⾥是java记录"} {"creator":"creator0","createTime":"2020-08-27T02:52:14.353Z","type":"杂⽂","title":"杂⽂记录","content":"这⾥是杂⽂记录"} {"creator":"creator5","createTime":"2020-08-27T02:52:32.202Z","type":"杂⽂","title":"杂⽂记录","content":"这⾥是杂⽂记录"} {"creator":"creator8","createTime":"2020-08-27T02:52:34.030Z","type":"js","title":"js记录","content":"JS是真的强"}3. kibana中使⽤DSL查询1.query and filterThe fullname field contains the word 张三The username field contains the word "张三2"GET /_search{"query": {"bool": {"must": [{ "match": { "fullname": "张三" }},{ "match": { "username": "zhangsan2" }}],"filter": [{ "term": { "sex": 1 }},{ "range": { "birth": { "gte": "2015-01-01" }}}]}}}结果:{"took" : 20,"timed_out" : false,"_shards" : {"total" : 6,"successful" : 6,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 2.0854702,"hits" : [{"_index" : "accounts","_type" : "_doc","_id" : "CJeN0nMBntNcepW18mWF","_score" : 2.0854702,"_source" : {"username" : "zhangsan2","fullname" : "张三2","sex" : 1,"userid" : 3,"birth" : "2020-08-09T09:29:44.832Z"}}]}}。
kibana 索引结构导出

kibana 索引结构导出标题:Kibana索引结构导出的全面指南在大数据分析和可视化领域,Elasticsearch和Kibana是两个不可或缺的工具。
Elasticsearch是一个强大的开源搜索引擎,而Kibana则是一个基于Elasticsearch的数据可视化平台。
在使用Kibana进行数据分析时,我们可能会需要将Kibana的索引结构导出。
本文将详细解析这一过程,一步一步解答如何导出Kibana的索引结构。
第一步:理解Kibana索引结构在开始导出之前,我们需要理解Kibana的索引结构。
在Elasticsearch 中,数据被存储在索引中,每个索引由一个或多个类型组成,每个类型包含多个文档。
每个文档都有一个唯一的_id和一个_version,以及一系列的字段和值。
Kibana则是通过这些索引来获取和展示数据。
第二步:访问Kibana控制台首先,我们需要登录到Kibana的控制台。
在浏览器中输入Kibana的地址(通常是第三步:选择目标索引在Kibana的主界面,点击左侧菜单栏的“Management”(管理)选项,然后在下拉菜单中选择“Index Patterns”(索引模式)。
在这里,你可以看到所有在Elasticsearch中创建的索引。
选择你想要导出的索引。
第四步:查看索引结构在选定的索引模式页面,你可以看到该索引的基本信息,包括索引名称、字段列表等。
这些信息构成了索引的结构。
你可以通过点击“Edit index pattern”(编辑索引模式)来查看和修改索引的详细结构。
第五步:使用Elasticsearch API导出索引结构虽然Kibana本身并没有直接提供导出索引结构的功能,但我们可以通过Elasticsearch的API来实现这个目标。
在浏览器的地址栏中输入以下URL:将<index_name>替换为你想要导出的索引名称。
然后按下Enter键,浏览器将会显示该索引的完整结构,以JSON格式返回。
elasticsearchmapping问题解决

elasticsearchmapping问题解决1.报错信息如下:[2018-07-16T00:10:17,743][WARN ][logstash.outputs.elasticsearch] Could not index event to Elasticsearch. {:status=>400, :action=>["index", {:_id=>nil, :_index=>"filebeat-api-2018.07.15", :_type=>"doc", :_routing=>nil}, #<LogStash::Event:⽇期格式不对报错,解决办法如下,建⽴⼀个map,关掉⽇期格式检测,对需要⽇期格式的字段加上date类型字段。
这⾥也实现了field限制,将默认的1000加到了3000.报错:"reason"=>"object mapping for [moditys] tried to parse field [commoditys] as object, but found a concrete value"}}}}这个ignore_malformed设置为true解决curl -XPUT "10.66.178.20:9200/_template/template_api" -H 'Content-Type: application/json' -d'{"index_patterns":["filebeat-api-*"],"order":0,"settings":{"number_of_replicas":0,"index":{"mapping":{"ignore_malformed": true,"total_fields": {"limit": "3000"}}}},"mappings": {"doc": {"date_detection": false,"properties": {"@timestamp": {"type": "date"}}}}}'。
filebeat+logstash+elasticsearch+granfa

filebeat+logstash+elasticsearch+granfafilebeat + logstash + elasticsearch + granfa⼀。
背景前端web服务器为nginx,采⽤filebeat + logstash + elasticsearch + granfa 进⾏数据采集与展⽰,对客户端ip进⾏地域统计,监控服务器响应时间等。
⼆。
业务整体架构:nginx⽇志落地——》filebear——》logstash——》elasticsearch——》grafna(展⽰)三。
先上个效果图,慢慢去⼀步步实现四,准备条件需要具备如下条件:1.nginx⽇志落地,需要主要落地格式,以及各个字段对应的含义。
2.安装filebeat。
filebeat轻量,功能相⽐较logstash⽽⾔⽐较单⼀。
3.安装logstash 作为中继服务器。
这⾥需要说明⼀下的是,起初设计阶段并没有计划使⽤filebeat,⽽是直接使⽤logstash发往elasticsearch,但是当前端机数量增加之后logstash 数量也随之增加,同时发往elasticsearch的数量增⼤,logstash则会抛出由于elasticsearch 限制导致的错误,⼤家遇到后搜索相应错误的代码即可。
为此只采⽤logstash作为中继。
4.elasticsearch 集群。
坑点是index templates的创建会影响新⼿操作 geoip模块。
后⽂会有。
5.grafana安装,取代传统的kibana,grafana有更友好、美观的展⽰界⾯。
五。
实现过程1.nginx⽇志落地配置nginx⽇志格式、字段的内容和顺序都是⾼度可定制化的,将需要收集的字段内容排列好。
定义⼀个log_format定义的形势实际上直接决定了logstash配置中对于字段抽取的模式,这⾥有两种可⽤,⼀种是直接在nginx⽇志中拼接成json的格式,在logstash中⽤codec => "json"来转换,⼀种是常规的甚⾄是默认的分隔符的格式,在logstash中需要⽤到grok来进⾏匹配,这个会是相对⿇烦些。
elasticsearch_cat命令详解(秒懂+史上最全)

elasticsearch_cat命令详解(秒懂+史上最全)⽂章很长,⽽且持续更新,建议收藏起来,慢慢读! 奉上以下珍贵的学习资源:免费赠送经典图书:⾯试必备 + ⼤⼚必备 + 涨薪必备免费赠送经典图书:⾯试必备 + ⼤⼚必备 +涨薪必备(加尼恩领取)免费赠送经典图书:⾯试必备 + ⼤⼚必备 + 涨薪必备(加尼恩领取)免费赠送资源宝库: Java 必备百度⽹盘资源⼤合集价值>10000元(加尼恩领取)推荐:⼊⼤⼚、做架构、⼤⼒提升Java 内功的精彩博⽂⼊⼤⼚、做架构、⼤⼒提升Java 内功必备的精彩博⽂2021 秋招涨薪1W + 必备的精彩博⽂1:2:3: (⾯试必备)4: (史上最全)5:6:7:8:9:10:11:12:13:14:Java ⾯试题 30个专题 , 史上最全 , ⾯试必刷阿⾥、京东、美团... 随意挑、横着⾛1:17、29、30、9.更多专题,请参见【】SpringCloud 精彩博⽂更多专题,请参见【】背景:下⼀个视频版本,从架构师视⾓,尼恩为⼤家打造⾼可⽤、⾼并发中间件的原理与实操。
⽬标:通过视频和博客的⽅式,为各位潜⼒架构师,彻底介绍清楚架构师必须掌握的⾼可⽤、⾼并发环境,包括但不限于:⾼可⽤、⾼并发nginx架构的原理与实操⾼可⽤、⾼并发mysql架构的原理与实操⾼可⽤、⾼并发nacos架构的原理与实操⾼可⽤、⾼并发rocketmq架构的原理与实操⾼可⽤、⾼并发es架构的原理与实操⾼可⽤、⾼并发minio架构的原理与实操why ⾼可⽤、⾼并发中间件的原理与实操:实际的开发过程中,很多⼩伙伴聚焦crud开发,环境出了问题,都不能启动。
作为架构师,或者未来想⾛向⾼端开发,或者做架构,必须掌握⾼可⽤、⾼并发中间件的原理,掌握其实操。
本系列博客的具体内容,请参见ES-cat相关命令汇总_cat/allocation #查看单节点的shard分配整体情况_cat/shards #查看各shard的详细情况_cat/shards/{index} #查看指定分⽚的详细情况_cat/master #查看master节点信息_cat/nodes #查看所有节点信息_cat/indices #查看集群中所有index的详细信息_cat/indices/{index} #查看集群中指定index的详细信息_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占⽤⼤⼩, 是否刷盘_cat/segments/{index}#查看指定index的segment详细信息_cat/count #查看当前集群的doc数量_cat/count/{index} #查看指定索引的doc数量_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
ElasticSearch模板文件配置

ElasticSearch模板文件配置Elasticsearch模板文件是一种用于定义Elasticsearch索引的配置文件,它包含了索引的映射和设置信息。
通过模板文件,可以在创建索引时自动应用这些配置信息,从而简化索引的管理和维护工作。
模板文件通常使用JSON格式来表示,它包含一个或多个定义索引的对象。
每个对象定义了一个或多个字段的映射和设置信息。
以下是一个示例模板文件的简单结构:```json"index_patterns": ["index-name-*"],"order": 1,"settings":"number_of_shards": 1,"number_of_replicas": 0},"mappings":"_doc":"properties":"field1": { "type": "text" },"field2": { "type": "keyword" }}}}```模板文件的主要配置项包括以下几个部分:1. `index_patterns`:指定适用于该模板的索引名称模式,可以使用通配符来匹配多个索引名称。
这是模板文件与索引关联的重要参数。
2. `order`:指定模板的优先级,如果有多个模板适用于同一个索引,那么根据优先级决定哪个模板会被应用。
模板的优先级从小到大,数值越大优先级越高。
默认为0。
3. `settings`:指定索引的设置信息,例如分片数量、副本数量等。
可以根据需求自定义这些设置。
4. `mappings`:指定索引的字段映射信息,定义字段的数据类型、分词器和其他属性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
elasticsearch index_patterns格式-回复elasticsearch index_patterns格式:详解和用法
Elasticsearch是一个开源的分布式全文搜索和分析引擎,旨在处理大量的数据并提供快速的搜索和分析功能。
在Elasticsearch中,索引是存储和组织数据的基本单位。
而index_patterns是一种用于指定多个索引的模式,它可以帮助我们更灵活、高效地搜索和分析数据。
本文将详细介绍elasticsearch index_patterns格式的用法和具体操作步骤。
1. 什么是index_patterns?
在Elasticsearch中,index_patterns是一个模式匹配字符串,通常用于选择需要搜索或分析的索引。
它可以是一个简单的索引名称,也可以是一个包含通配符的模式。
通配符有两种形式:*和?。
其中,*用于匹配零或多个字符,而?用于匹配一个字符。
例如,可以使用"my_index_*"来匹配以"my_index_"开头的所有索引。
使用index_patterns的好处是可以根据具体需求选择性搜索或分析数据。
比如,我们可以通过"logstash-*"来搜索所有由logstash生成的索引,或者使用"2021-*"来搜索所有以2021年为前缀的索引。
这种方式不仅可以提高查询效率,还可以减少不必要的资源消耗。
2. index_patterns 的语法和用法
index_patterns的语法非常简单,只需要将需要匹配的索引模式放置在中括号中即可。
例如,"[my_index_*]"表示匹配所有以"my_index_"开头的索引。
可以通过以下几种方式使用index_patterns:
- 单个索引:可以直接指定一个索引名称,例如"[my_index]"。
- 多个索引:可以通过逗号分隔指定多个索引名称,例如
"[index1,index2,index3]"。
- 通配符:可以通过使用通配符模式匹配多个索引,例如"[logstash-*]"。
- 排除索引:可以使用"-"字符排除某些不需要的索引,例如
"[my_index_*, -my_index_2021]",表示匹配所有以"my_index_"开头的索引,但排除以"my_index_2021"开头的索引。
另外,index_patterns还支持嵌套的模式。
可以使用圆括号来分组模式。
例如,"[((2021 2022)-*)]"表示匹配以"2021-"或"2022-"开头的索引。
3. 使用index_patterns进行搜索和分析
在Elasticsearch中,可以使用index_patterns来指定需要搜索或分析的
索引。
下面是使用index_patterns进行搜索和分析的具体步骤:
- 搜索数据:
要搜索数据,我们可以使用Elasticsearch提供的REST API或客户端库。
在搜索请求中,可以在"index"字段中指定index_patterns。
例如,在使用REST API进行搜索时,可以将请求body中的"index"字段设置为"[my_index_*]",以只搜索所有以"my_index_"开头的索引。
- 分析数据:
分析数据可以帮助我们了解数据的趋势和模式,以便做出更明智的决策。
在Elasticsearch中,我们可以使用聚合(aggregation)来实现数据分析。
在聚合请求中,可以在"index"字段中指定index_patterns。
例如,在使用REST API进行聚合时,可以将请求body中的"index"字段设置为"[logstash-*]",以聚合所有由logstash生成的索引的数据。
需要注意的是,当使用index_patterns进行搜索或分析时,应尽量使用具体的模式,避免使用过于宽泛的通配符。
过于宽泛的模式可能会导致搜索或分析的性能下降。
总结:
本文介绍了elasticsearch index_patterns格式的用法和具体操作步骤。
index_patterns为我们提供了更灵活、高效的搜索和分析数据的方式。
我们可以使用单个索引、多个索引、通配符模式、排除索引等方式来指定需要匹配的索引。
在实际应用中,我们可以根据具体需求选择合适的index_patterns,以提高查询效率并减少资源消耗。
无论是搜索数据还是分析数据,都可以通过指定index_patterns来实现。
在使用
index_patterns时,应注意使用具体的模式,避免使用过于宽泛的通配符。
希望本文能帮助大家更好地理解和使用elasticsearch index_patterns格式。