残差分析(课堂PPT)
合集下载
3.2 残差分析

-10
450 400 350 300 250 200 150 100 50 0 -5 -50 0
产卵数
产卵数
气 温
5 10 15 20 25 30 35 40
线性模型
二次函数模型
指数函数模型
最好的模型是哪个?
函数模型 线性回归模型
相关指数R2 0.7464
比 一 比
二次函数模型
指数函数模型
0.802
将t=x2代入线性回归方程得: y=0.367x2 -202.54 当x=28时,y=0.367×282202.54≈85,且R2=0.802, 所以,二次函数模型中温度解 释了80.2%的产卵数变化。
产卵数y/个 350 300 250 200 150 100 50 0 0 150 300 450 600 750 900 1050 1200 1350
求根据一名女大学生的身高预报她的体重的回归方程,并预报一名身高为 172cm的女大学生的体重。
3、从散点图还看到,样本点散布在某一条直线的附近,而不是 在一条直线上,所以不能用一次函数y=bx+a描述它们关系。
我们可以用下面的线性回归模型来表示:
y=bx+a+e,其中a和b为模型的未知参数,
e称为随机误差。
i 1 i i 1 n i i
n
2
2
第一个好
一般地,建立回归模型的基本步骤为:
(1)确定研究对象,明确哪个变量是解析变量,哪个变量是预 报变量。 (2)画出确定好的解析变量和预报变量的散点图,观察它们之 间的关系(如是否存在线性关系等)。
(3)由经验确定回归方程的类型(如我们观察到数据呈线性关系, 则选用线性回归方程y=bx+a). (4)按一定规则估计回归方程中的参数(如最小二乘法)。 (5)得出结果后分析残差图是否有异常(个别数据对应残差 过大,或残差呈现不随机的规律性,等等),过存在异常, 则检查数据是否有误,或模型是 否合适等。
450 400 350 300 250 200 150 100 50 0 -5 -50 0
产卵数
产卵数
气 温
5 10 15 20 25 30 35 40
线性模型
二次函数模型
指数函数模型
最好的模型是哪个?
函数模型 线性回归模型
相关指数R2 0.7464
比 一 比
二次函数模型
指数函数模型
0.802
将t=x2代入线性回归方程得: y=0.367x2 -202.54 当x=28时,y=0.367×282202.54≈85,且R2=0.802, 所以,二次函数模型中温度解 释了80.2%的产卵数变化。
产卵数y/个 350 300 250 200 150 100 50 0 0 150 300 450 600 750 900 1050 1200 1350
求根据一名女大学生的身高预报她的体重的回归方程,并预报一名身高为 172cm的女大学生的体重。
3、从散点图还看到,样本点散布在某一条直线的附近,而不是 在一条直线上,所以不能用一次函数y=bx+a描述它们关系。
我们可以用下面的线性回归模型来表示:
y=bx+a+e,其中a和b为模型的未知参数,
e称为随机误差。
i 1 i i 1 n i i
n
2
2
第一个好
一般地,建立回归模型的基本步骤为:
(1)确定研究对象,明确哪个变量是解析变量,哪个变量是预 报变量。 (2)画出确定好的解析变量和预报变量的散点图,观察它们之 间的关系(如是否存在线性关系等)。
(3)由经验确定回归方程的类型(如我们观察到数据呈线性关系, 则选用线性回归方程y=bx+a). (4)按一定规则估计回归方程中的参数(如最小二乘法)。 (5)得出结果后分析残差图是否有异常(个别数据对应残差 过大,或残差呈现不随机的规律性,等等),过存在异常, 则检查数据是否有误,或模型是 否合适等。
残差分析

5
0
0
20
40
存在高杠杆率观测值的散点图
x 60
19
13
异常值 (OUTLIER)
1. 如果某一个点与其他点所呈现的趋势不相吻合, 这个点就有可能是异常点,或称为野点
■ 如果异常值是一个错误的数据,比如记录错误造成的, 应该修正该数据,以便改善回归的效果
■ 如果是由于模型的假定不合理,使得标准化残差偏大, 应该考虑采用其他形式的模型,比如非线性模型
不良贷款对贷款余额回归的残差图
7
残差
X Variable 1 Residual Plot
5
0
0
2
4
6
8
-5
X Variable 1
火灾损失数据的残差图
8
标准化残差(standardized residual)
ZREi
ei
ˆ
标准化残差使残差具有可比性,ZREi 3 的相应观测值即判定为异常值,但没有解
计算公式为
1
hii n
(xi x )2 (xi x )2
表h示ii ,其
3. 如果一个观测值的杠杆率 识别为有高杠杆率的点
hii就可6以n将该观测值
4. 一个有高杠杆率的观测值未必是一个有影响的观测 值,它可能对回归直线的斜率没有什么影响
18
高杠杆率点 (图示)
y
25
20
高杠杆率点
15
10
■ 如果完全是由于随机因素而造成的异常值,则应该保 留该数据
2. 在处理异常值时,若一个异常值是一个有效的观 测值,不应轻易地将其从数据集中予以剔除
14
异常值 (识别)
1. 异常值也可以通过标准化残差来识别 2. 如果某一个观测值所对应的标准化残差较
第十六讲 残差分析

变量变换
• 线性模型假设 E(y|x)的线性性, 和误差方差齐性: E(y|x)=a+b’x var(y|x)=常数 • 我们知道(y,x)联合正态分布时,该假设是正确的。 • 实际问题中,若x,y都是连续变量,通常对x或y或两者做 变换,使得变换之后(x,y)近似服从正态分布。 • 若某些自变量是因子(x1),其它自变量(x2)是连续型,那 么, 变换,使得(y,x2)|x1~正态。
变换的一般原则
• 总的原则是变换后每个变量都比较对称、均衡,换言之联合分布接近 正态。变换包括
– – – – Log变换 或 Box-Cox变换, 连续变量离散化, 有次序的因子变量的连续化, 无次序因子变量的合并
•
log 原则 如果一个非负变量的取值不在一个尺度或量级(magnitude)上,则取对数 后分析可能是有益的. 如果一个变量的取值在一个尺度或量级内,任何变换都可能无益. 不容易确定何种变换时,采用Box-Cox变换。
(b) 若x, z不独立 ⇒ var( y | x)一般依赖于x,除非 var( z | x)不依赖于x ⇒ var( y | x) = 常数 若( z , x) ~ 正态, 则
(3) δ = y-{α + β ' x} = a + b' x + c' z − {α + β ' x} = a − α + (b − β )' x + c' z
δ与x是否相关可通过 (1), (2)部分地检查,但一般无 法完全验证。
注:通常我们只有“工作模型”而不知道完全模型,只能通过 工作模型的残差探讨其拟合好坏。
残差分析
• 残差分析:拟合线性回归模型之后,通过 分析残差特征,检查拟合的好坏,即检查 数据是否满足模型假设
(教学课件)残差分析

2.8 2.4
2 1.6 1.2 0.8 0.4
0 0
z
36
x
9 12 15 18 21 24 27 30 33 36 39
变化
最好的模型是哪个?
产卵数
400 300 200 100
0 0
-100
5
10 15 20 25 30
35
40
线性模型
产卵数
400
300
200
100
气
0
温
-40 -30 -20 -10 0 10 20 30 40
在例1中,残差平方和约为128.361。
残差分析与残差图的定义:
在研究两个变量间的关系时,首先要根据散点图来粗略判断它们是否线 性相关,是否可以用回归模型来拟合数据。
然后,我们可以通过残差 e1, e2, , en 来判断模型拟合的效果,判断原始
数据中是否存在可疑数据,这方面的分析工作称为残差分析。
i1
^
a y bx,......(1)
(4)写出直线方程为y^=bx+a,即为所求的回归直线方程。
例1 从某大学中随机选取8名女大学生,其身高和体重数据如表1-1所示。
编号 1 2 3 4 5 6 7 8 身高/cm 165 165 157 170 175 165 155 170 体重/kg 48 57 50 54 64 61 43 59
案例2 一只红铃虫的产卵数y和温度x有关。现
收集了7组观测数据列于表中:
温度xoC 21 23 25 27 29 32 35 产卵数y/个 7 11 21 24 66 115 325
(1)试建立产卵数y与温度x之间的回归方程;并 预测温度为28oC时产卵数目。 (2)你所建立的模型中温度在多大程度上解释了 产卵数的变化?
2025年高考数学一轮复习 第十章 -第二节 -第3课时 残差分析与决定系数【课件】

第二节 数据分析——回归模型及其应用
第3课时 残差分析与决定系数
题型一 残差分析
典例1 树木根部半径与树木的高度呈正相关,即树木根部越粗,树木的高度也就越高.某
块山地上种植了树木,某农科所为了研究树木的根部半径与树木的高度之间的关系,
从这些地块中用简单随机抽样的方法抽取6棵树木,调查得到树木根部半径
15
20
25
30
7.25
8ห้องสมุดไป่ตู้12
8.95
9.90
10.9
11.8
(1)作出散点图并求回归直线方程;
解 画出散点图,如图所示.
样本点分布在一条直线附近,与具有线性相
关关系.
1
6
由表中数据,得 = × (5 + 10 + 15 + 20
+ 25 + 30) = 17.5,
1
6
= × (7.25 + 8.12 + 8.95 + 9.90 + 10.9
∑ −ෝ
题型二 决定系数 = − =
∑ −
=
典例2 已知某种商品的价格(单位:元/件)与需求量(单位:件)之间的关系有如下
五组数据:
14
16
18
20
22
12
10
7
5
3
求关于的回归直线方程,并说明回归模型拟合效果的好坏.
1
5
1
5
解 = × 14 + 16 + 18 + 20 + 22 = 18, = × 12 + 10 + 7 + 5 + 3 = 7.4,
第3课时 残差分析与决定系数
题型一 残差分析
典例1 树木根部半径与树木的高度呈正相关,即树木根部越粗,树木的高度也就越高.某
块山地上种植了树木,某农科所为了研究树木的根部半径与树木的高度之间的关系,
从这些地块中用简单随机抽样的方法抽取6棵树木,调查得到树木根部半径
15
20
25
30
7.25
8ห้องสมุดไป่ตู้12
8.95
9.90
10.9
11.8
(1)作出散点图并求回归直线方程;
解 画出散点图,如图所示.
样本点分布在一条直线附近,与具有线性相
关关系.
1
6
由表中数据,得 = × (5 + 10 + 15 + 20
+ 25 + 30) = 17.5,
1
6
= × (7.25 + 8.12 + 8.95 + 9.90 + 10.9
∑ −ෝ
题型二 决定系数 = − =
∑ −
=
典例2 已知某种商品的价格(单位:元/件)与需求量(单位:件)之间的关系有如下
五组数据:
14
16
18
20
22
12
10
7
5
3
求关于的回归直线方程,并说明回归模型拟合效果的好坏.
1
5
1
5
解 = × 14 + 16 + 18 + 20 + 22 = 18, = × 12 + 10 + 7 + 5 + 3 = 7.4,
第5章 残差分析
第 15 个数据 hii=0.339>2 h ,因而从杠杆值看第 15 个数据是 自变量的异常值,同时库克距离 D15=1.555>1,这样第 15 个数据为
异常值的原因是由自变量异常与因变量异常两个原因共同引起的。
异常值与强影响值
异常值原因
异常值消除方法
1.数据登记误差,存在抄写或录入 重新核实数据 的错误
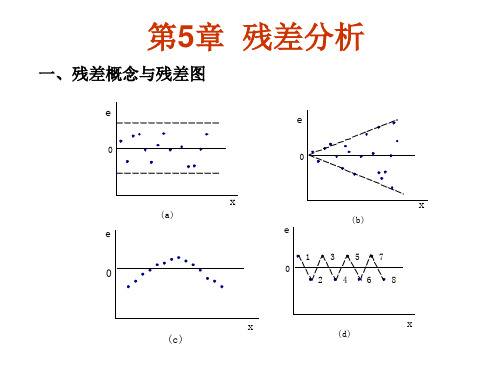
第5章 残差分析
一、残差概念与残差图
e
e
0
0
(a)
e
0
x
e
x
(b)
1 3 57
0 2 46 8
x (c)
x
(d)
残差分析
一、残差概念与残差图
4
3
2
1
0
-1
-2
-3
-4
0
1
2
3
4
5
6
7
X
火灾损失数据残差图
残差分析
二、残差的性质
性质1 E (ei)=0
证明: E(ei ) E( yi ) E( yˆi )
chii=杆值 chii的平均值是
i 1
ch
1 n
n
chii
i 1
p n
异常值与强影响值
二、关于自变量x的异常值
虽然强影响点并不总是y的异常值点,不能单纯根据 杠杆值hii的大小判断强影响点是否异常,但是我们对强影 响点应该有足够的重视。为此引入库克距离,用来判断强 影响点是否为y的异常值点。库克距离的计算公式为:
i 1
残差分析
三、改进的残差
标准化残差
ZREi
ei
ˆ
学生化残差
SREi ˆ
异常值的原因是由自变量异常与因变量异常两个原因共同引起的。
异常值与强影响值
异常值原因
异常值消除方法
1.数据登记误差,存在抄写或录入 重新核实数据 的错误
第5章 残差分析
一、残差概念与残差图
e
e
0
0
(a)
e
0
x
e
x
(b)
1 3 57
0 2 46 8
x (c)
x
(d)
残差分析
一、残差概念与残差图
4
3
2
1
0
-1
-2
-3
-4
0
1
2
3
4
5
6
7
X
火灾损失数据残差图
残差分析
二、残差的性质
性质1 E (ei)=0
证明: E(ei ) E( yi ) E( yˆi )
chii=杆值 chii的平均值是
i 1
ch
1 n
n
chii
i 1
p n
异常值与强影响值
二、关于自变量x的异常值
虽然强影响点并不总是y的异常值点,不能单纯根据 杠杆值hii的大小判断强影响点是否异常,但是我们对强影 响点应该有足够的重视。为此引入库克距离,用来判断强 影响点是否为y的异常值点。库克距离的计算公式为:
i 1
残差分析
三、改进的残差
标准化残差
ZREi
ei
ˆ
学生化残差
SREi ˆ
残差分析
第5章 残差分析
一、残差概念与残差图
e
e
0
0
x
(a)
(b)
x
e
1 3 2 4 5 6 7 8
e
0
0
x
(c)
x
(d)
残差分析
一、残差概念与残差图
4 3 2 1 0 -1 -2 -3 -4 0 1 2 3 4 5 6 7
X
火灾损失数据残差图
残差分析
二、残差的性质
性质1 E (ei)=0
ˆ 证明: E ( e i ) E ( y i ) E ( y i ) ( 0 1 x i ) E ( ˆ 0 ˆ1 x i ) 0
异常值与强影响值
采用加权最小二乘回归后,删除学生化残差SRE(i)的绝 对值最大者为|SRE(13)|=1.7424,库克距离都在0.5至1.0之 间,说明数据没有异常值。
ei 0 xiei 0
i 1
残差分析
三、改进的残差 标准化残差
ZRE
i
ei
ˆ
ei
学生化残差
SRE
i
ˆ
1 h ii
异常值与强影响值
二、关于自变量x的异常值
在 D(ei)=(1-hii)σ 2 中,hii 是帽子矩阵中主对角线的第 i 个元素,它是调节 ei 方差 大小的杠杆,因而称 hii 为第 i 个观察值的杠杆值。类似于一元线性回归,多元线性 回归的杠杆值 hii 也是表示自变量的第 i 次观测值与自变量平均值之间距离的远近。 较大的杠杆值的残差偏小,这是因为大杠杆值的观测点远离样本中心,能够把回归 方程拉向自己,因而把杠杆值大的样本点称为强影响点。
一、残差概念与残差图
e
e
0
0
x
(a)
(b)
x
e
1 3 2 4 5 6 7 8
e
0
0
x
(c)
x
(d)
残差分析
一、残差概念与残差图
4 3 2 1 0 -1 -2 -3 -4 0 1 2 3 4 5 6 7
X
火灾损失数据残差图
残差分析
二、残差的性质
性质1 E (ei)=0
ˆ 证明: E ( e i ) E ( y i ) E ( y i ) ( 0 1 x i ) E ( ˆ 0 ˆ1 x i ) 0
异常值与强影响值
采用加权最小二乘回归后,删除学生化残差SRE(i)的绝 对值最大者为|SRE(13)|=1.7424,库克距离都在0.5至1.0之 间,说明数据没有异常值。
ei 0 xiei 0
i 1
残差分析
三、改进的残差 标准化残差
ZRE
i
ei
ˆ
ei
学生化残差
SRE
i
ˆ
1 h ii
异常值与强影响值
二、关于自变量x的异常值
在 D(ei)=(1-hii)σ 2 中,hii 是帽子矩阵中主对角线的第 i 个元素,它是调节 ei 方差 大小的杠杆,因而称 hii 为第 i 个观察值的杠杆值。类似于一元线性回归,多元线性 回归的杠杆值 hii 也是表示自变量的第 i 次观测值与自变量平均值之间距离的远近。 较大的杠杆值的残差偏小,这是因为大杠杆值的观测点远离样本中心,能够把回归 方程拉向自己,因而把杠杆值大的样本点称为强影响点。
实用回归分析课件 (残差与残差图)
5.3 异常值与强影响值
一、关于因变量y的异常值
在残差分析中,认为超过 3ˆ 的残差为异常值。
标准化残差
ZREi
ei
ˆ
学生化残差
SREi ˆ
ei 1 hii
ZREi / SREi 3 观测数据判定为异常值
存在y的异常观测值,普通/标准化/学生化残差都不适用
5.3 异常值与强影响值
当数据中存在关于 y 的异常观察值时,异常值把回归线拉向 自己,使异常值本身的残差减少,而其余观察值的残差增大,这时 回归标准差ˆ 也会增大,因而用“3σ”准则不能正确分辨出异常值。 解决这个问题的方法是改用删除残差。
其中, hii
1 n
(xi x)2 Lxx
称为杠杆值
靠近x附近的点相应的残差方 差较大,
远离x附近的点相应的残差方 差较小.
5.2 残差的性质
一、残差的性质
性质3. 残差满足约束条件:
n
ei 0
i 1 n
xiei 0
i 1
5.2 残差的性质
二、改进的残差
5.3 异常值与强影响值
异常值分为两种情况: 一种是关于因变量y异常; 另一种是关于自变量x异常。
第三步,做等级相关系数的显著性检验。在n>8的情况下, 用下式对样本等级相关系数rs进行t检验。检验统计量为:
t n 2 rs 1 rs2
如果t≤tα/2(n-2)可认为异方差性问题不存在, 如果t>tα/2(n-2),说明xi与|ei|之间存在系统关系,异方差性 问题存在。
违背基本假设的情况
第六章 关于异方差性问题 第七章 关于自相关性问题 第八章 关于多重共相关问题
第六章 关于异方差性问题
var(i ) var( j ), i j
简单线性回归模型与分析残差图(ppt 35页)
销 售 额 / 千 元 5 81 0 58 81 1 8 1 1 7 1 3 7 1 5 7 1 6 9 1 4 9 2 0 2
根据以上数据,你能否判断学生人数(x)如何影 响到销售收入(y)?根据一家连锁店附近大学的人数, 你能够预测该家连锁店的季度销售收入吗?
3
描述学生人数和销售收入之间的关系
第i个标准化残差
其中
Std_ˆi ˆi / sˆi
sˆi s
1 hi ,
1
h i n
(xi x)2 (xi x)2
26
如何分析残差图
如果模型是符合的,那么残差图上的散 点应该落在一条水平带中间,除此之外, 残差图上的点不应呈现出什么规律性。
使用EXCEL对阿姆德连锁店的数据产生残 差图。你能得到什么结论?
协方差(315.56)和相关系数(0.95),散点图;
250
季 度 销 售 收 入 /千 美 圆
200
150
100
50
0
0
5
10
15
20
25
30
学生人数/千人
根据这些你可以得到什么结论?
4
Types of Regression Models
Positive Linear Relationship
散点图; 利用学生化标准残差基本服从标 准正态分布来检测(落在2个标准差之外 时)。
32
带有异常值的散点图示例
80
70
60
50
40
30
20
10
0
0
1
2
3
4
5
6
7
33
检测有影响的观测值
什么是有影响的观测? 观测的杠杆率:
根据以上数据,你能否判断学生人数(x)如何影 响到销售收入(y)?根据一家连锁店附近大学的人数, 你能够预测该家连锁店的季度销售收入吗?
3
描述学生人数和销售收入之间的关系
第i个标准化残差
其中
Std_ˆi ˆi / sˆi
sˆi s
1 hi ,
1
h i n
(xi x)2 (xi x)2
26
如何分析残差图
如果模型是符合的,那么残差图上的散 点应该落在一条水平带中间,除此之外, 残差图上的点不应呈现出什么规律性。
使用EXCEL对阿姆德连锁店的数据产生残 差图。你能得到什么结论?
协方差(315.56)和相关系数(0.95),散点图;
250
季 度 销 售 收 入 /千 美 圆
200
150
100
50
0
0
5
10
15
20
25
30
学生人数/千人
根据这些你可以得到什么结论?
4
Types of Regression Models
Positive Linear Relationship
散点图; 利用学生化标准残差基本服从标 准正态分布来检测(落在2个标准差之外 时)。
32
带有异常值的散点图示例
80
70
60
50
40
30
20
10
0
0
1
2
3
4
5
6
7
33
检测有影响的观测值
什么是有影响的观测? 观测的杠杆率:
实用回归分析课件(残差与及残差图)
残差的基本概念
定义
残差是指观测值与通过回归模型预测的值之间的 差异。
计算方法
残差 = 观测值 - 预测值。
重要性
残差用于评估回归模型的拟合效果,可以帮助我 们发现异常值、模型的不确定性和误差来源。
02
残差的性质与计算
残差的定义与计算方法
残差
观测值与回归方程预测值之差。
计算方法
实际观测值 - 预测值。
如果残差分布符合正态分布,那 么残差图上的点应该大致呈钟形 分布。通过观察残差图的分布形
状,可以检验残差的正态性。
残差图的用途与限制
01
辅助模型诊断
通过观察残差图,可以对模型的假设条件进行检验,如线性关系、误差
项的正态性等。
02
改进模型
根据残差图的观察结果,可以对模型进行调整和改进,如添加或删除解
详细描述
在案例一中,我们将使用一组线性回归模型的数据,通过计算残差、绘制残差图等方法,分析模型的 拟合效果。我们将重点关注残差的分布、正态性、独立性和同方差性等方面,以评估模型的可靠性。
案例二:时间序列数据的残差分析
总结词
时间序列数据具有时序依赖性和波动性,因此在进行回归分析时需要特别注意残差的分 析。
自相关性诊断方法
通过计算自相关图、使用自相关 系数、偏自相关系数等方法,可 以诊断出自相关性。
自相关性处理方法
处理自相关性可以采用差分、季 节性差分、指数平滑等方法,消 除自相关性对回归分析的影响。
异方差性诊断与处理
异方差性定义
异方差性是指回归模型的残差项的方差不恒 定,即随着预测变量的变化,残差的方差也 会发生变化。
指残差之间存在相关性,通常表现为 时间序列数据的滞后相关性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
性回归解释的部分
^_
(y y)2
11
剩余平方和(residual sum of squares):即残差平方 和,不能用线性回归解释的部分
^
( y y)2
以上三部分的自由度分别为n-1,m和n-m-1。其 中,n为样本数,m为自变量数。 方差分析的假设为
一元线性回归:H0: =0 多元线性回归:
17
(3)残差的方差齐性检验 以上都是对残差的分析,称为残差分析。
残差分析还可以1)检出奇异点 2)评判预测效果。
(4)共线性诊断 •共线性(collinearity) •共线性的危害 •共线性的鉴别 容差(tolerance) 方差膨胀因子(variance inflation factor)
18
一元线性回归:
Q (yi yi )2 [ yi (a b xi )]2
多元线性回归:
Q (yi yi )2 [ yi (b0 b1 x1 b2 x2 bn xn )]2
9
一元线性回归时,计算比较简单:
b (x x) (y y) x y x y / n lxy
• 决定系数(determination coefficient)( R square)
^
R2
( y y)2
( y y)2
• 调整(校正)决定系数(adjusted R square)
R2
1
n 1
(1 R2 )
• 复相关系数R (multniplemcorrelation coefficient)
斜率) 回归系数的统计学意义是:自变量每变化一个单位,
应变量平均变化的单位数.
(3)ei是残差
3
因此直线回归方程的一般形式是:
^
yi a bxi
•
其中
^
yi
是应变量y的预测值或称估计值。
4
4、多元线性回归 多元线性回归方程模型为: yi=b0+b1x1i+b2x2i+…+bnxni+ei
其中 (1) b有0是时常,数人项们,称是它各为自本变底量值都。等于0时,应变量的估计值。 (2) bco1,effbic2i,en…t ),,b其n是统偏计回学归意系义数是(在pe其rt它ial所re有gr自es变sio量n 不变
5
多元线性回归方程的一般形式是:
^
yi b0 b1x1i b2 x2i bn xni
其中的符号含义同前。
6
三、理论假设
• 自变量x与应变量y之间存在线性关系; • 正态性:随机误差(即残差)e服从均值为 0,
方差为2的正态分布; • 等方差:对于所有的自变量x,残差e的条件方
差为2 ,且为常数; • 独立性:在给定21
九、线性回归分析的注意事项
• 应用条件 • 样本量 • 自变量的观察范围 • 分类/等级变量
22
谢谢!
23
线性回归分析
公共卫生学院
1
一. 前言
回归分析的目的:
设法找出变量间的依存(数量)关系, 用函数关系 式表达出来
2
二、基本概念
1、应变量(dependent variable) 2、自变量(independent variable)
3、一元线性回归 直线回归方程的模型是:yi=a+bxi+ei
其中 (1)a是截距 (2)b是回归系数(regression coefficient)(回归直线的
(x x)2
x2 ( x)2 / n lxx
a ybx y bx
n
n
多元线性回归时,比较复杂,一般需要用计算机 处理。
10
五、线性回归的检验
1、回归方程的检验 方差分析法:
应变量的总变异
_
( y y)2
可分解为 回归平方和(regression sum of squares):可用线
16
5、线性回归适用性检验 (1)回归模型残差的正态性检验 •残差的直方图 •残差的累积概率图(P-P图)
(2)回归模型残差的独立性检验 用Durbin--Watson检验,其参数称为Dw或D。 D的取值范围是0<D<4。其统计学意义为: D≈2,残差与自变量相互独立; D<2,残差与自变量正相关; D>2,残差与自变量负相关。
H1: 0
H0: 1= 2=…= m=0 H1: 1, 2,…, m中至少有一个不等于零 因此方差分析的结论是线性回归方程是否显著, 是否有意义。
12
2、回归/偏回归系数的检验 检验回归系数是否为零,每一个偏回归系数是
否为零。用t检验方法。 统计量
t bi sbi
自由度
v nm1
结论:回归/偏回归系数是否有意义,是否为零; 对应的自变量是否有意义。
件期望值为0(本假设又称零均值假设); • 无自相关性:各随机误差项e互不相关;
7
• 残差e与自变量x不相关:随机误差项e与相 应的自变量x不相关;
• 无共线性:自变量x之间相互独立.
8
四、回归方程的建立
• 散点图 • 奇异点(ouliers) • 最小二乘法(least square, LS) • 残差平方和(sum of squares for residuals)
六、自变量的选择
• 强迫引入法(Enter) • 强迫剔除法(Remove) • 前进法(Forward) • 后退法(Backward) • 逐步向前法(Forward stepwise) • 逐步向后法(Backward stepwise)
19
七、线性回归的应用
• 预测 • 控制 • 鉴别影响因素
的情况下,某一自变量每变化一个单位,应变量平均 变化的单位数。 如就数果等,所于用有符0,参号b加b11,‘分,b析b2,2的’,…变…,量,b都nbn就是‘表变标示成准。了化标的准变化量偏,回这归时系b0 bi’= bi*sxi/sy 由量于的b相i’没对有作量用纲大,小因。此可以相互比较大小,反映自变 (3) ei是残差
13
3、常数项(截距)的检验
检验常数项(截距)是否为零。
用t检验方法。 一元线性回归:
H0: =0
H1: 0
a t
sa v n2
14
多元线性回归: H0: 0=0
H1: 00
t b0 sb0
v n m 1
15
4、模型的预测效果检验
亦称回归模型的拟合优度检验。检验回归模型 对样本数据的拟合程度。
^_
(y y)2
11
剩余平方和(residual sum of squares):即残差平方 和,不能用线性回归解释的部分
^
( y y)2
以上三部分的自由度分别为n-1,m和n-m-1。其 中,n为样本数,m为自变量数。 方差分析的假设为
一元线性回归:H0: =0 多元线性回归:
17
(3)残差的方差齐性检验 以上都是对残差的分析,称为残差分析。
残差分析还可以1)检出奇异点 2)评判预测效果。
(4)共线性诊断 •共线性(collinearity) •共线性的危害 •共线性的鉴别 容差(tolerance) 方差膨胀因子(variance inflation factor)
18
一元线性回归:
Q (yi yi )2 [ yi (a b xi )]2
多元线性回归:
Q (yi yi )2 [ yi (b0 b1 x1 b2 x2 bn xn )]2
9
一元线性回归时,计算比较简单:
b (x x) (y y) x y x y / n lxy
• 决定系数(determination coefficient)( R square)
^
R2
( y y)2
( y y)2
• 调整(校正)决定系数(adjusted R square)
R2
1
n 1
(1 R2 )
• 复相关系数R (multniplemcorrelation coefficient)
斜率) 回归系数的统计学意义是:自变量每变化一个单位,
应变量平均变化的单位数.
(3)ei是残差
3
因此直线回归方程的一般形式是:
^
yi a bxi
•
其中
^
yi
是应变量y的预测值或称估计值。
4
4、多元线性回归 多元线性回归方程模型为: yi=b0+b1x1i+b2x2i+…+bnxni+ei
其中 (1) b有0是时常,数人项们,称是它各为自本变底量值都。等于0时,应变量的估计值。 (2) bco1,effbic2i,en…t ),,b其n是统偏计回学归意系义数是(在pe其rt它ial所re有gr自es变sio量n 不变
5
多元线性回归方程的一般形式是:
^
yi b0 b1x1i b2 x2i bn xni
其中的符号含义同前。
6
三、理论假设
• 自变量x与应变量y之间存在线性关系; • 正态性:随机误差(即残差)e服从均值为 0,
方差为2的正态分布; • 等方差:对于所有的自变量x,残差e的条件方
差为2 ,且为常数; • 独立性:在给定21
九、线性回归分析的注意事项
• 应用条件 • 样本量 • 自变量的观察范围 • 分类/等级变量
22
谢谢!
23
线性回归分析
公共卫生学院
1
一. 前言
回归分析的目的:
设法找出变量间的依存(数量)关系, 用函数关系 式表达出来
2
二、基本概念
1、应变量(dependent variable) 2、自变量(independent variable)
3、一元线性回归 直线回归方程的模型是:yi=a+bxi+ei
其中 (1)a是截距 (2)b是回归系数(regression coefficient)(回归直线的
(x x)2
x2 ( x)2 / n lxx
a ybx y bx
n
n
多元线性回归时,比较复杂,一般需要用计算机 处理。
10
五、线性回归的检验
1、回归方程的检验 方差分析法:
应变量的总变异
_
( y y)2
可分解为 回归平方和(regression sum of squares):可用线
16
5、线性回归适用性检验 (1)回归模型残差的正态性检验 •残差的直方图 •残差的累积概率图(P-P图)
(2)回归模型残差的独立性检验 用Durbin--Watson检验,其参数称为Dw或D。 D的取值范围是0<D<4。其统计学意义为: D≈2,残差与自变量相互独立; D<2,残差与自变量正相关; D>2,残差与自变量负相关。
H1: 0
H0: 1= 2=…= m=0 H1: 1, 2,…, m中至少有一个不等于零 因此方差分析的结论是线性回归方程是否显著, 是否有意义。
12
2、回归/偏回归系数的检验 检验回归系数是否为零,每一个偏回归系数是
否为零。用t检验方法。 统计量
t bi sbi
自由度
v nm1
结论:回归/偏回归系数是否有意义,是否为零; 对应的自变量是否有意义。
件期望值为0(本假设又称零均值假设); • 无自相关性:各随机误差项e互不相关;
7
• 残差e与自变量x不相关:随机误差项e与相 应的自变量x不相关;
• 无共线性:自变量x之间相互独立.
8
四、回归方程的建立
• 散点图 • 奇异点(ouliers) • 最小二乘法(least square, LS) • 残差平方和(sum of squares for residuals)
六、自变量的选择
• 强迫引入法(Enter) • 强迫剔除法(Remove) • 前进法(Forward) • 后退法(Backward) • 逐步向前法(Forward stepwise) • 逐步向后法(Backward stepwise)
19
七、线性回归的应用
• 预测 • 控制 • 鉴别影响因素
的情况下,某一自变量每变化一个单位,应变量平均 变化的单位数。 如就数果等,所于用有符0,参号b加b11,‘分,b析b2,2的’,…变…,量,b都nbn就是‘表变标示成准。了化标的准变化量偏,回这归时系b0 bi’= bi*sxi/sy 由量于的b相i’没对有作量用纲大,小因。此可以相互比较大小,反映自变 (3) ei是残差
13
3、常数项(截距)的检验
检验常数项(截距)是否为零。
用t检验方法。 一元线性回归:
H0: =0
H1: 0
a t
sa v n2
14
多元线性回归: H0: 0=0
H1: 00
t b0 sb0
v n m 1
15
4、模型的预测效果检验
亦称回归模型的拟合优度检验。检验回归模型 对样本数据的拟合程度。