编译原理第六章标准答案
(完整版)编译原理[张素琴]第2版-答案-清华大学出版社
![(完整版)编译原理[张素琴]第2版-答案-清华大学出版社](https://img.taocdn.com/s3/m/2b7b9004dd88d0d232d46a24.png)
《编译原理》课后习题第 1 章引论第1 题解释下列术语:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
编译原理第六章到第十一章课后习题答案
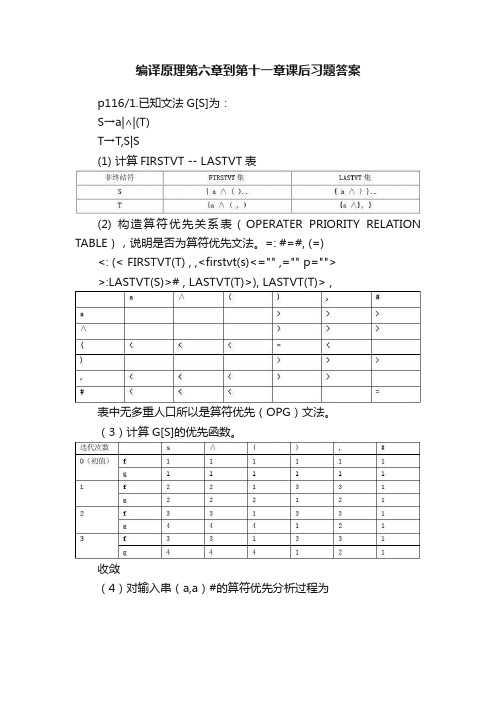
编译原理第六章到第十一章课后习题答案p116/1.已知文法G[S]为:S→a|∧|(T)T→T,S|S(1) 计算FIRSTVT -- LASTVT表(2) 构造算符优先关系表(OPERATER PRIORITY RELATION TABLE),说明是否为算符优先文法。
=: #=#, (=)<: (< FIRSTVT(T) , ,<firstvt(s)<="" ,="" p="">>:LASTVT(S)># , LASTVT(T)>), LASTVT(T)> ,表中无多重人口所以是算符优先(OPG)文法。
(3)计算G[S]的优先函数。
收敛(4)对输入串(a,a)#的算符优先分析过程为Success!3.有文法G(S):s->Vv->T/ViTT->F/T+FF->)V*|((1)(+(i(的规范推导S=>V=>ViT=>ViF=>Vi(=>Ti(=>T+Fi(=>T+(i(=>F+(i(=>(+(i((2)F+Fi(的短语、句柄、素短语。
短语S: F+Fi(T1:F+F (素短语)T2:F (句柄)F:( (素短语)(3) G(S)是否为OPG?若是,给出(1)中句子的分析过程!S’->#S# S->V V->T/ViT T->F/T+F F->)V*|(算符优先关系表(OPERATER PRIORITY RELATION TABLE)对输入串(+(I(的算符优先分析过程为:p152/2文法:S→L.L|LL→LB|BB→0|1拓广文法为G′,增加产生式S′→SI3若产生式排序为:0 S' →S1 S →L.L2 S →L3 L →LB4 L →B5 B →06 B →1由产生式知:First (S' ) = {0,1}First (S ) = {0,1}First (L ) = {0,1}First (B ) = {0,1}Follow(S' ) = {#}Follow(S ) = {#}Follow(L ) = {.,0,1,#}Follow(B ) = {.,0,1,#}G′的LR(0)项目集族及识别活前缀的DFA如下图所示:I5B →.0和B →.1为移进项目,S →L.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
编译原理第6章习题答案

1)抽象语法树:
2)四元式序列:
3)三元式序列:
4)间接三元式序列:
6.4.1 向图6-19的翻译方案中加入对应于下列产生式的规则: 1) E E1 * E2 2) E E1 (单目加)
E.addr = E1.addr E.code = E1.code
例如:+3
6.4.2 使用图6-20中的增量式翻译方案重复练习6.4.1
{E.addr = E1.addr}
在增量方式中,gen不仅要构造出一个新的三地址指令,还 要将它添加到至今为止已生成的指令序列之后。
6.4.3 使用使用图6-22所示的翻译方案来翻译下 列赋值语句: 2) x = a[i][j] + b[i][j] 假设w1为数组a的第一维的宽度,w2为数组b 的第一维的宽度,整数宽度为w。第6章习题答案
作业: 6.1.1 6.2.1 6.4.1 6.4.2 6.4.3 6.6.1
6.7.1 (1) 补充习题1
第6章 中间代码生成
6.1.1 为下面的表达式构造DAG ((x+y)-((x+y)*(x-y)))+((x+y)*(x-y))
6.2.1 将算术表达式 a+-(b+c) 翻译成
补充习题1:用本节所给的翻译模式(采用回填)翻译语句: if (a<b || c<d && e<f ) A1 else A2; while (a<b) A3 ; 假定语句序号从100起算,又假定A1、A2、A3语句各生成10条指令。
100 if a<b goto 106 101 goto 102 102 if c<d goto 104 103 goto 117 104 if e<f goto 106 105 goto 117 106 107 . A1 . 115 116 goto 127 117 118 A2 . . 126 127 if a<b goto 129 128 goto 140 129 130 A3 . . 138 139 goto 127 140 141 142 143 144 145
编译原理及其习题解答(武汉大学出版社)课件chap6

练习1题目 练习 题目
文法G[T]: T→ F | T*F F →F ↑ P | P P→ (T) | i 证明T*P ↑(T*F)是文法G的一个句型,并 指出这个句型的所有短语、直接短语、 句柄。
编译原理 Compiler Principles
练习1 练习1解答
证明:T T*F T*F↑P T*F↑(T) 语法树: T T * F P F ↑ ( P T )
编译原理 Compiler Principles
练习2题目
设有文法G[S]: 设有文法 S →V1 V1→ V2 | V1iV2 V2→ V3 | V2+V3 V3→ )V1* | ( (1)给出 (+(i( 的最右推导,并画出相应的语法树; 给出 的最右推导,并画出相应的语法树; (2)证明 2+V3i( 是文法的一个句型,并指出这个句型的短语、直接 证明V 是文法的一个句型,并指出这个句型的短语、 证明 短语、句柄。 短语、句柄。
编译原理 Compiler Principles
非确定的自下而上的分析器
非确定的自下而上的分析器,是一般移进 归约方法 非确定的自下而上的分析器,是一般移进-归约方法 的抽象模型,可识别任何上下文无关语言。 的抽象模型,可识别任何上下文无关语言。给定一个上下 文无关文法,可构造一个自下而上的分析器。 文无关文法,可构造一个自下而上的分析器。 非确定的自下而上的分析器与非确定的自上而下的分 析器的不同之处: 析器的不同之处: 课本P147 课本
编译原理 Compiler Principles
自下而上分析法存在的问题
可归约串的问题;(∵ 该分析的每一步就是从当前串中找一 ;(∵
个子串( 个子串(称“可归约串”),将它归约到某个非终结符号) 可归约串”),将它归约到某个非终结符号) 将它归约到某个非终结符号 自下而上分析法的关键就是找哪个子串是“可归约串” 自下而上分析法的关键就是找哪个子串是“可归约串”, 关键就是找哪个子串是 哪个不是“可归约串” 例如上例中的(3) 哪个不是“可归约串”。例如上例中的
编译原理(第2版)课后习题答案详解

第1 章引论第1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
编译原理作业题答案编译原理课后题答案

第二章高级语言的语法描述6、令文法G 6为:N →D|ND D → 0|1|2|3|4|5|6|7|8|9(1)G 6 的语言L (G 6)是什么?(2)给出句子01270127、、34和568的最左推导和最右推导。
解答:思路:由N N →→ D|ND 可得出如下推导N =>=>ND ND ND=>=>=>NDD NDD NDD=>…=>=>…=>=>…=>D D n(n >=1=1))可以看出,N 最终可以推导出1个或多个(也可以是无穷)D ,而D D →→ 0|1|2|3|4|5|6|7|8|9可知,每个D 为0~9中的任一个数字,所以,中的任一个数字,所以,N N N 最终推导出的就是由最终推导出的就是由0~9这10个数字组成的字符串。
(1)G 6 的语言L (G 6)是由0~9这10个数字组成的字符串个数字组成的字符串,,或{0{0,,1,1,……,9}+。
(2)(2)句子句子01270127、、34和568的最左推导分别为的最左推导分别为: : N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>NDDD NDDD NDDD=>=>=>DDDD DDDD DDDD=>=>=>0DDD 0DDD 0DDD=>=>=>01DD 01DD 01DD=>=>=>012D 012D 012D=>=>=>0127 0127 N =>=>ND ND ND=>=>=>DD DD DD=>=>=>3D 3D 3D=>=>=>34 34N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>DDD DDD DDD=>=>=>5DD 5DD 5DD=>=>=>56D 56D 56D=>=>=>568 568 句子01270127、、34和568的最右推导分别为的最右推导分别为: :N =>=>ND ND ND=>=>=>N7N7N7=>=>=>ND7ND7ND7=>=>=>N27N27N27=>=>=>ND27ND27ND27=>=>=>N127N127N127=>=>=>D127D127D127=>=>=>0127 0127 N =>=>ND ND ND=>=>=>N4N4N4=>=>=>D4D4D4=>=>=>34 34N =>=>ND ND ND=>=>=>N8N8N8=>=>=>ND8ND8ND8=>=>=>N68N68N68=>=>=>D68D68D68=>=>=>568 5687、写一个文法,使其语言是奇数集,且每个基数不以0开头。
编译原理与实践 第六 七章 答案

The Exercises of Chapter Six6.2应该在nu m→digit产生式中再加一条语义规则:numd.count=1用来进行初始化。
6.46.7 Consider the following grammar for simple Pascal-style declarations:delc →var-list : typevar-list →var-list, id | idtype →integer | realWrite an attribute grammar for the type of a variable.[Solution]Grammar Rule Semantic Rulesdelc →var-list : type var-list.type = type.typevar-list1 →var-list2, id val-list2.type=var-list1.typeid.type=var-list1.typevar-list →id id.type=var-list.typetype →integer type.type= INTERGERtype →real type.type=REAL6.10 a. Draw dependency graphs corresponding to each grammar rule of Example 6.14 (Page 283) , and for the expression 5/2/2.0.b. Describe the two passes required to compute the attributes on the syntax tree of 5/2/2.0, including a possible order in which the nodes could be visited and the attribute values computed at each point.c. Write pseudcode for procedures that would perform the computations described in part(b). [Solution]a. The grammar rules of Example 6.14S →expexp →exp/exp | num | num.numThe dependency graphs for each grammar rule:S →expval SisFloat etype val expexp →exp / expvalexp →numisFloat etype val expval numexp →num.numisFloat etype val expval num.numThe dependency graphs for the expression: 5/2/2.0val SexpisFloat val num.num(2.0)val num val num(5)(2)b. The first pass is to compute the etype from isFloat.The second pass is to compute the val from etype.The possible order is as follows:val S1221i expisFloat val num.num(2.0)(5)(2)c. The pseudcode procedure for the computation of the isFloat.Function EvalisFloat(T: treenode): BooleanVar temp1, temp2: BooleanBeginCase nodekind of T ofexp:temp1= EvalisFloat(left child of T);if right child of T is not nil thentemp2=EvalisFloat( right child of T)return temp1 or temp2elsereturn temp1;num:return false;num.num:return true;endFunction Evalval(T: treenode, etype:integer): V ALUEVar temp1, temp2: V ALUEBeginCase nodekind of T ofS:Return(Evalval(left child of T, etype));Exp:If etype=EMPTY thenIf EvalisFloat(T) then etype:=FLOAT;Else etype=INT;Temp1=Evalval(left child of T, etype)If right child of T is not nil thenTemp2=Evalval(right child of T, etype);If etype=FLOAT thenReturn temp1/temp2;ElseReturn temp1 div temp2;ElseReturn(temp1);Num:If etype=INTReturn(T.val);ElseReturn(T.val);Num.num:Return(T.val).6.11Dependency graphs corresponding to the numbered grammar rules in 6.4:Dependency graph for the string ‘3 *(4+5) *6:6.21 Consider the following extension of the grammar of Figure 6.22(page 329) to include function declarations and calls:program → var-decls;fun-decls;stmtsvar-decls → var-decls;var-decl|var-declvar-decl → id: type-exptype-exp → int|bool|array [num] of type-expfun-decls → fun id (var-decls):type-exp;bodybody → expstmts → stmts;stmt| stmtstmt → if exp then stmt | id:=expexp → exp + exp| exp or exp | exp[exp]|id(exps)|num|true|false|idexps→ exps,exp|expa.Devise a suitable tree structure for the new function type structure, and write a typeEqualfunction for two function types.b.Write semantic rules for the type checking of function declaration and functioncalls(represented by the rule exp →id(exps)),similar to rules of table 6.10(page 330).[Solution]a. One suitable tree structure for the new function type structure:The typeEqual function for two function type:Function typeEqual-Fun(t1,t2 : TypeFun): BooleanVar temp : Boolean;p1,p2:TypeExpbeginp1:=t1.lchild;p2:=t2.lchild;temp:=true;while temp and p1<>nil and p2<>nil dobegintemp=typeEqual-Exp(p1,p2);p1=p1.sibling;p2=p2.sibling;endif temp then return(typeEqual-Exp(t1.rchild,t2.rchild));return(temp);endb. The semantic rules for type checking of function declaration and function call:fun-decls → fun id (var-decls):type-exp; bodyid.type.lchild:=var-decls.type;id.type.rchild:=type-exp.type;insert(,id.typefun)exp → id(exps)if isFunctionType(id.type) andtypeEqual-Exp(id.type.lchild,exps.type) thenexp.type=id.type.rchild;else type-error(exp)The exercise of chapter seven7.2 Draw a possible organization for the runtime environment of the following C program, similar to that of Figure 7.4 (Page 354).a. After entry into block A in function f.[Solution]a. Global/static area Activation record of main Activation record of f after entering the Block Afpsp7.8 In languages that permit variable numbers of arguments in procedure calls, one way to find the first argument is to compute the arguments in reverse order, as described in section 7.3.1, page 361.a. One alternative to computing the arguments in reverse would be to reorganize the activation record to make the first argument available even in the presence of variable arguments. Describe such an activation record organization and the calling sequence it would need.b. Another alternative to computing the arguments in reverse is to use a third point(besides the sp and fp), which is usually called the ap (argument pointer). Describe an activation record structure that uses an ap to find the first argument and the calling sequence it would need.[Solution]a. The reorganized activation record.Global/static areaActivation record of mainActivation record of g after entering the Block BThe calling sequence will be:(1)store the fp as the control link in the new activation record;(2)change the fp to point to the beginning of the new activation record;(3)store the return address in the new activation record;(4)compute the arguments and store their in the new activation record in order;(5)perform a jump to the code of procedure to be called.The calling sequence will be:(1) set ap point to the position of the first argument.(2) compute the arguments and store their in the new activation record in order;(3)store the fp as the control link in the new activation record;(4)change the fp to point to the beginning of the new activation record;(5)store the return address in the new activation record;(6)perform a jump to the code of procedure to be called.7.15 Give the output of the following program(written in C syntax) using the four parameter methods discussed in section 7.5.#include <stdio.h>int i=0;void p(int x, int y){ x +=1;i +=1;y +=1;}main{ int a[2]={1,1};p(a[i], a[i]);printf(“%d %d\n”, a[0], a[1]);return 0;}[Solution]pass by value: 1, 1pass by reference: 3, 1pass by value-result: 2, 1pass by name: 2, 2。
《编译原理》(陈火旺版)课后作业参考答案ch6-10

第6章属性文法和语法制导翻译7. 下列文法由开始符号S产生一个二进制数,令综合属性val给出该数的值:试设计求的属性文法,其中,已知B的综合属性c, 给出由B产生的二进位的结果值。
例如,输入时,=,其中第一个二进位的值是4,最后一个二进位的值是。
【答案】11. 设下列文法生成变量的类型说明:(1)构造一下翻译模式,把每个标识符的类型存入符号表;参考例。
【答案】第7章语义分析和中间代码产生1. 给出下面表达式的逆波兰表示(后缀式):【答案】3. 请将表达式-(a+b)*(c+d)-(a+b+c)分别表示成三元式、间接三元式和四元式序列。
【答案】间接码表:(1)→(2)→(3)→(4)→(1)→(5)→(6)4. 按节所说的办法,写出下面赋值句A:=B*(-C+D) 的自下而上语法制导翻译过程。
给出所产生的三地址代码。
【答案】5. 按照7.3.2节所给的翻译模式,把下列赋值句翻译为三地址代码:A[i, j]:=B[i, j] + C[A [k, l]] + d[ i+j]【答案】6. 按7.4.1和节的翻译办法,分别写出布尔式A or ( B and not (C or D) )的四元式序列。
【答案】用作数值计算时产生的四元式:用作条件控制时产生的四元式:其中:右图中(1)和(8)为真出口,(4)(5)(7)为假出口。
7. 用7.5.1节的办法,把下面的语句翻译成四元式序列: While A<C and B<D do if A=1 then C:=C+1 else while A ≦D do A:=A+2; 【答案】第9章 运行时存储空间组织4. 下面是一个Pascal 程序:当第二次( 递归地) 进入F 后,DISPLAY 的内容是什么当时整个运行栈的内容是什么 【答案】第1次进入F 后,运行栈的内容: 第2次进入F 后,运行栈的内容: 109 87 6 5 4 3 2 1 017 1615 14 13 12 11 10 9 8 7 6 5第2次进入F 后,Display 内容为:5. 对如下的Pascal 程序,画出程序执行到(1)和(2)点时的运行栈。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第6 章自底向上优先分析
第1 题
已知文法G[S]为:
S→a|∧|(T)
T→T,S|S
(1) 计算G[S]的FIRSTVT 和LASTVT。
(2) 构造G[S]的算符优先关系表并说明G[S]是否为算符优先文法。
(3) 计算G[S]的优先函数。
(4) 给出输入串(a,a)#和(a,(a,a))#的算符优先分析过程。
答案:
文法展开为:
S→a
S→∧
S→(T)
T→T,S
T→S
(1) FIRSTVT - LASTVT 表:
表中无多重人口所以是算符优先(OPG)文法。
友情提示:记得增加拓广文法S`→#S#,所以# FIRSTVT(S),LASTVT(S) #。
(3)对应的算符优先函数为:
Success!
对输入串(a,(a,a))# 的算符优先分析过程为:
Success!
第2 题
已知文法G[S]为:
S→a|∧|(T)
T→T,S|S
(1) 给出(a,(a,a))和(a,a)的最右推导,和规范归约过程。
(2) 将(1)和题1 中的(4)进行比较给出算符优先归约和规范归约的区别。
答案:
(2)算符优先文法在归约过程中只考虑终结符之间的优先关系从而确定可归约串,而与
非终结符无关,只需知道把当前可归约串归约为某一个非终结符,不必知道该非终结符的名字是什么,因此去掉了单非终结符的归约。
规范归约的可归约串是句柄,并且必须准确写出可归约串归约为哪个非终结符。
第3题:
有文法G[S]:
S V
V T|ViT
T F|T+F
F )V*|(
(1) 给出(+(i(的规范推导。
(2) 指出句型F+Fi(的短语,句柄,素短语。
(3) G[S]是否为OPG?若是,给出(1)中句子的分析过程。
因为该文法是OP,同时任意两个终结符的优先关系唯一,所以该文法为OPG。
(+(i(的分析过程
第4题
文法G[S]为:
S→S;G|G
G→G(T)|H
H→a|(S)
T→T+S|S
(1)构造G[S]的算符优先关系表,并判断G[S]是否为算符优先文法。
(2)给出句型a(T+S);H;(S)的短语、句柄、素短语和最左素短语。
(3)给出a;(a+a)和(a+a)的分析过程,说明它们是否为G[S]的句子。
(4)给出(3)中输入串的最右推导,分别说明两输入串是否为G[S]的句子。
(5)由(3)和(4)说明了算符优先分析的哪些缺点。
(6)算符优先分析过程和规范归约过程都是最右推导的逆过程吗?
答案:
(1)构造文法G[S]的算符优先关系矩阵:。