并行计算课程报告
并行计算课程报告

并行计算课程报告1.学习总结1.1并行计算简介并行计算是相对于串行计算来说的。
它是一种一次可执行多个指令的算法,目的是提高计算速度,及通过扩大问题求解规模,解决大型而复杂的计算问题。
所谓并行计算可分为时间上的并行和空间上的并行。
时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计算。
1.2并行计算机分类和并行机体系结构的特征按内存访问模型、微处理器和互联网络的不同,当前流行的并行机可分为对称多处理共享存储并行机(SMP:Symmetric Multi-Processing)、分布共享存储并行机(DSM:Distributed Shared Memory)、机群(cluster)、星群(constellation)和大规模并行机(MPP:Massively Parallel Processing)等五类。
SMP并行机有如下主要特征:对称共享存储、单一的操作系统映像、局部高速缓存cache 及其数据一致性、低通信延迟、共享总线带宽、支持消息传递、共享存储并行程序设计。
SMP 并行机具有如下缺点:欠可靠、可扩展性(scalability)较差。
DSM 并行机具有如下主要特征:并行机以结点为单位,每个结点包含一个或多个CPU,每个CPU 拥有自己的局部cache,并共享局部存储器和I/O设备,所有结点通过高性能互联网络相互连接;物理上分布存储;单一的内存地址空间;非一致内存访问(NUMA)模式;单一的操作系统映像;基于cache 的数据一致性;低通信延迟与高通信带宽;DSM 并行机可扩展到数百个结点,能提供每秒数千亿次的浮点运算性能;支持消息传递、共享存储并行程序设计。
机群(cluster)有三个明显的特征:①系统由商用结点构成,每个结点包含2-4 个商用微处理器,结点内部共享存储。
②采用商用机群交换机连接结点,结点间分布存储。
③在各个结点上,采用机群Linux 操作系统、GNU 编译系统和作业管理系统。
并行计算课程设计报告

并行计算与多核多线程技术课程报告专业班级学号XX成绩___________________年月日课程报告要求手写内容:设计目的、意义,设计分析,方案分析,功能模块实现,最终结果分析,设计体会等。
允许打印内容:设计原理图等图形、图片,电路图,源程序。
硬件类的设计,要有最终设计的照片图;软件类设计,要有各个功能模块实现的界面图、输入输出界面图等。
评价理论根底实践效果〔正确度/加速比〕难度工作量独立性目录1. 设计目的、意义〔功能描述〕12. 方案分析〔解决方案〕13. 设计分析13.1 串行算法设计13.2 并行算法设计13.3 理论加速比分析24. 功能模块实现与最终结果分析24.1 基于OpenMP的并行算法实现24.1.1 主要功能模块与实现方法24.1.2 实验加速比分析34.2 基于MPI的并行算法实现34.2.1 主要功能模块与实现方法34.2.2 实验加速比分析44.3 基于Java的并行算法实现44.3.1 主要功能模块与实现方法44.3.2 实验加速比分析54.4 基于Windows API的并行算法实现54.4.1 主要功能模块与实现方法54.4.2 实验加速比分析64.5 基于.net的并行算法实现64.5.1 主要功能模块与实现方法64.5.2 实验加速比分析64.6并行计算技术在实际系统中的应用64.6.1 主要功能模块与实现方法64.6.2 实验加速比分析75. 设计体会76. 附录96.1 基于OpenMP的并行程序设计96.1.1 代码及注释96.1.2 执行结果截图116.1.3 遇到的问题及解决方案126.2 基于MPI的并行程序设计126.1.1 代码及注释126.2.2 执行结果截图126.2.3 遇到的问题及解决方案166.3 基于Java的并行程序设计196.3.1 代码及注释196.3.2 执行结果截图226.3.3 遇到的问题及解决方案236.4 基于Windows API的并行程序设计256.4.1 代码及注释256.4.2 执行结果截图256.4.3 遇到的问题及解决方案306.5 基于.net的并行程序设计306.5.1 代码及注释306.5.2 执行结果截图346.5.3 遇到的问题及解决方案356.6并行计算技术在实际应用系统的应用366.6.1 代码及注释366.6.2 执行结果截图366.6.3 遇到的问题及解决方案421. 设计目的、意义〔功能描述〕设计一个计算向量夹角的WinForm窗体应用,用户只需要在窗体上输入向量的维度,系统随机产生两个向量并将计算结果显示在窗体上。
omp并行计算课程报告

并行计算与多核多线程技术课程报告专业班级学号姓名成绩2015 年9月21日4.1 基于OpenMP的并行算法实现4.1.1 主要功能模块与实现方法#pragma omp parallel num_threads(2){for (xxj_g = 0; xxj_g <xxj_M/2; xxj_g++){for (xxj_d = 0; xxj_d< xxj_P; xxj_d++){xxj_C[xxj_g][xxj_d] = 0;for (xxj_k = 0; xxj_k < xxj_N; ++xxj_k){xxj_C[xxj_g][xxj_d] += xxj_A[xxj_g][xxj_k] *xxj_B[xxj_k][xxj_d];}}}for (xxj_g = xxj_M/2; xxj_g <xxj_M; xxj_g++){for (xxj_d = 0; xxj_d < xxj_P; xxj_d++){xxj_C[xxj_g][xxj_d] = 0;for (xxj_k = 0; xxj_k < xxj_N; ++xxj_k){ // cout << "2num=" << omp_get_thread_num() << endl;xxj_C[xxj_g][xxj_d] += xxj_A[xxj_g][xxj_k] * xxj_B[xxj_k][xxj_d];}}}}(1)将两个矩阵的乘法进行并行运算打开2个进程#pragma omp parallel num_threads(4)注意输出和输入部分的for循环不能用并行,否则会出现输入输出的个数出错的问题。
(2)将得到最终结果的xxj_C[i][j]分成两个子矩阵进行运算第一个子矩阵为xxj_A[i][j]的M/2行乘以xxj_B[i][j]的P列的结果,第二个子矩阵为xxj_A[i][j]的M-M/2行乘以xxj_B[i][j]的P列的结果。
《并行计算导论》课程报告
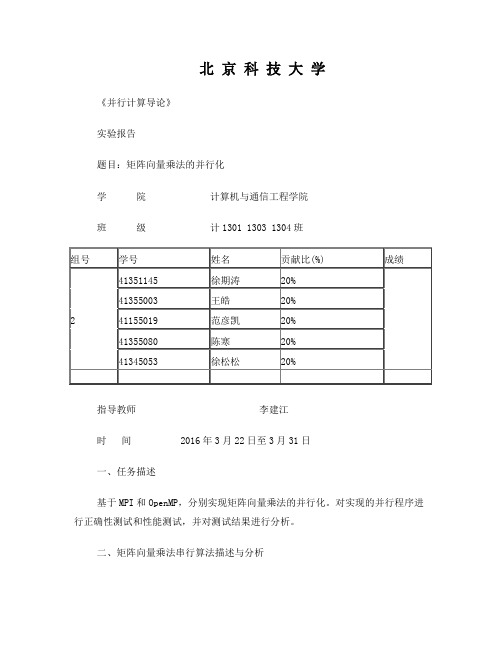
北京科技大学《并行计算导论》实验报告题目:矩阵向量乘法的并行化学院计算机与通信工程学院班级计1301 1303 1304班指导教师李建江时间 2016年3月22日至3月31日一、任务描述基于MPI和OpenMP,分别实现矩阵向量乘法的并行化。
对实现的并行程序进行正确性测试和性能测试,并对测试结果进行分析。
二、矩阵向量乘法串行算法描述与分析1. 串行算法描述在线性代数中,矩阵和向量的乘法是将每行矩阵的每个元素乘以向量中的每个元素,得到一个新的向量,要求矩阵是N*N阶,向量是N阶,这样相乘后,得到一个新的N阶向量。
利用串行算法,设置循环,让矩阵中的每一行的元素乘以完向量的每个元素后得到一个数值再进行下一行的乘法,一直到最后一行的乘法结束,得到新的向量。
2. 空间复杂度分析对于N阶的矩阵向量乘法,A*b=x,定义数据类型为long,则需要的存储空间为(N^2+2*N)*4 Byte 。
(矩阵数:N^2+向量数N+结果N)3. 时间复杂度分析对于N阶的矩阵向量乘法,A*b=x,需要串行算法执行的次数为:N^2*(N-1)三、矩阵向量乘法的并行化(一)基于MPI的矩阵向量的并行化1. 并行策略(含图示)因为矩阵乘以向量,每行的乘法是相互独立的,所以可以把N阶矩阵按行平均分配给各个进程,让每个进程分别处理分配给它的数据块。
2. 并行算法描述先为程序指定阶数,然后用随机数生成N阶方阵和向量,采用静态均匀负载,为每个处理器分配相同数量的数组元素,做到负载相对比较均衡(由于可能存在0元素,使得负载相对有些偏差)。
然后把N阶方阵和向量显示出来,做MPI静态并行计算,然后将得出的结果显示出来3. 空间复杂度分析设进程数为n,数据类型为long,则N阶矩阵向量乘法的所需的空间为:N^2+n*N+N,(矩阵空间N^2+n倍的b向量空间n*N+结果N)4. 时间复杂度分析假设负载均衡,假设最小的划分块大于等于矩阵的一行,由于将行分块划分给各个进程,所以整体的时间是1/n倍的串行算法的时间复杂度,即1/n*N^2*(N-1)(二)基于OpenMP的矩阵向量的并行化1. 并行策略(含图示)与MPI并行策略类似,把矩阵按行分块,与向量相乘,但是可以采用更为灵活的池技术动态调用,更加充分利用了计算资源。
并行计算实验报告一

并行计算实验报告一江苏科技大学计算机科学与工程学院实验报告评定成绩指导教师实验课程:并行计算宋英磊实验名称:Java多线程编程学号: 姓名: 班级: 完成日期:2014年04月22日1.1 实验目的(1) 掌握多线程编程的特点;(2) 了解线程的调度和执行过程;(3) 掌握资源共享访问的实现方法。
1.2 知识要点1.2.1线程的概念(1) 线程是程序中的一个执行流,多线程则指多个执行流;(2) 线程是比进程更小的执行单位,一个进程包括多个线程;(3) Java语言中线程包括3部分:虚拟CPU、该CPU执行的代码及代码所操作的数据。
(4) Java代码可以为不同线程共享,数据也可以为不同线程共享; 1.2.2 线程的创建(1) 方式1:实现Runnable接口Thread类使用一个实现Runnable接口的实例对象作为其构造方法的参数,该对象提供了run方法,启动Thread将执行该run方法;(2) 方式2:继承Thread类重写Thread类的run方法;1.2.3 线程的调度(1) 线程的优先级, 取值范围1,10,在Thread类提供了3个常量,MIN_PRIORITY=1、MAX_ PRIORITY=10、NORM_PRIORITY=5;, 用setPriority()设置线程优先级,用getPriority()获取线程优先级; , 子线程继承父线程的优先级,主线程具有正常优先级。
(2) 线程的调度:采用抢占式调度策略,高优先级的线程优先执行,在Java 中,系统按照优先级的级别设置不同的等待队列。
1.2.4 线程的状态与生命周期说明:新创建的线程处于“新建状态”,必须通过执行start()方法,让其进入到“就绪状态”,处于就绪状态的线程才有机会得到调度执行。
线程在运行时也可能因资源等待或主动睡眠而放弃运行,进入“阻塞状态”,线程执行完毕,或主动执行stop方法将进入“终止状态”。
1.2.5 线程的同步--解决资源访问冲突问题(1) 对象的加锁所有被共享访问的数据及访问代码必须作为临界区,用synchronized加锁。
并行计算与分布式系统实验报告

并行计算与分布式系统实验报告1. 引言“彼岸花,开过就只剩残香。
”这是一句来自中国古代文学名篇《红楼梦》的名言。
它告诉我们,珍贵的事物往往难以长久保持,只有通过合理的分工与协作,才能实现最大的效益。
在计算机科学领域,这句话同样适用。
并行计算和分布式系统正是通过有效地利用计算资源,实现高效的数据处理与任务分工,从而提高计算效率和系统性能。
2. 并行计算介绍并行计算是一种利用多个处理器或计算节点同时执行计算任务的方法。
它通过将大型计算问题划分为多个小的子问题,并同时解决这些子问题,大幅提高计算速度。
并行计算有两种主要的形式:数据并行和任务并行。
数据并行将大型数据集分割成多个小块,分别交给不同的处理器进行处理;任务并行将不同的任务分配到不同的处理器上同时执行。
3. 分布式系统介绍分布式系统是一组互连的计算机节点,通过网络相互协作以实现共同的目标。
分布式系统可以分布在不同地理位置的计算机上,通过消息传递和远程过程调用等通信机制实现节点间的协作。
分布式系统具有高可靠性、可扩展性和容错性的特点,并广泛应用于云计算、大数据处理和分布式存储等领域。
4. 并行计算和分布式系统的关系并行计算和分布式系统之间存在密切的关系。
分布式系统提供了并行计算所需的底层基础设施和通信机制,而并行计算则借助分布式系统的支持,实现任务的并行处理和数据的高效交换。
通过充分利用分布式系统中的计算资源,可以实现更高效的并行计算,并加速大规模数据处理和科学计算。
5. 并行计算与分布式系统实验在完成本次实验中,我们使用了一台集群式分布式系统,包括8台计算节点和1台主控节点。
我们利用MPI(Message Passing Interface)实现了一个并行计算的案例,该案例通过并行处理大规模图像数据,实现图像的快速处理和分析。
实验中,我们首先将图像数据划分成多个小块,并分发给不同的计算节点进行处理。
每个计算节点利用并行算法对图像进行滤波和边缘检测,然后将处理结果返回给主控节点。
并行计算实训课程学习总结并行程序设计与性能优化

并行计算实训课程学习总结并行程序设计与性能优化并行计算实训课程学习总结:并行程序设计与性能优化在本学期的并行计算实训课程中,我学习了并行程序设计与性能优化的基本概念和技巧。
通过课程的学习,我对并行计算的原理和应用有了更深入的了解,并且掌握了一些重要的并行编程工具和技术。
本文将对我在课程学习中所获得的收获和体会进行总结。
一、并行计算基础知识的学习在课程的初期,我们首先系统地学习了并行计算的基础知识。
我们了解了并行计算的定义和特点,并且学习了一些常用的并行计算模型和编程范式,如共享内存和分布式内存,并行编程的基本概念等。
通过这些学习,我对并行计算的概念和原理有了更加清晰的认识,并且了解到了并行计算在大规模数据处理和科学计算领域的重要性。
二、并行程序设计的实践在掌握了并行计算的基础知识后,我们进行了一系列的并行程序设计实践。
我们采用了不同的并行编程模型和工具,如OpenMP和MPI,并编写了一些简单的并行程序。
通过实践,我学会了如何在程序中进行任务划分和数据划分,并且掌握了一些常用的并行编程技巧,如粒度调整、负载平衡等。
这些实践帮助我更好地理解了并行程序设计的思想和方法,并且提高了我的编程能力。
三、性能优化的策略与技术在实践的基础上,我们进一步学习了性能优化的策略与技术。
我们了解了一些常见的性能瓶颈,如数据传输、负载不平衡等,并学习了一些性能优化的方法和工具,如并行算法设计、并行调试和性能分析工具等。
通过对这些策略和技术的学习,我学会了如何在编程过程中尽可能地提高程序的并行性和性能,并且提高了我的问题分析和解决能力。
综上所述,通过本学期的并行计算实训课程,我不仅学会了并行程序设计与性能优化的基本理论和技术,还提高了我的实践能力和问题解决能力。
这门课程对我今后的学习和研究具有重要的指导意义。
我将继续努力学习,并将所学知识应用到实际项目中,为实现高效的并行计算做出贡献。
注:本文仅为参考范文,具体内容需要根据实际情况和要求进行修改和补充。
湖南大学并行计算课程报告

并行系统的调度设计问题我们组选取了五篇关于并行系统调度的相关论文,并进行了总结,完成了ppt 的讲解和报告的制作。
五篇论文的题目如下:solving the parallel task scheduling problem by means of a genetic approach通过遗传手段方法解决并行任务调度问题scheduling parallel tasks approximation algorithms调度并行任务的近似算法scheduling algorithms and support tools for parallel systems调度算法和支持工具并行系统practical multiprocessor scheduling algorithms for efficient parallel processing 实用的多处理机调度算法高效的并行处理A new DAG based Dynamic Task Scheduling Algorithm (DYTAS) for Multiprocessor Systems 一种新的基于DAG的动态任务调度算法(DYTAS)的多处理器系统本次报告主要包括以下四个部分:1.分布式并行操作系统概述2.分布式并行操作系统调度的算法设计3.系统性能分析4.报告总结1.分布式并行操作系统概述1.1 分布式操作系统的定义分布式软件系统(Distributed Software Systems)是支持分布式处理的软件系统,是在由通信网络互联的多处理机体系结构上执行任务的系统。
它包括分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等。
其中分布式操作系统负责管理分布式处理系统资源和控制分布式程序运行。
它和集中式操作系统的区别在于资源管理、进程通信和系统结构等方面。
一个分布式计算机系统是一些独立的计算机的集合,但是对这个系统的用户来说,系统就象一台计算机一样。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
成绩:并行计算导论课程报告专业:软件工程班级:软件二班学号:140120010057姓名:蒋琳珂2017年6月1日1、并行计算的实际意义并行计算或称平行计算是相对于串行计算来说的。
它是一种一次可执行多个指令的算法,目的是提高计算速度,及通过扩大问题求解规模,解决大型而复杂的计算问题。
所谓并行计算可分为时间上的并行和空间上的并行。
时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计算。
在应用需求方面,人类对计算机性能的需求总是永无止境的,在诸如预测模型的构造和模拟、工程设计和自动化、能源勘探、医学、军事以及基础理论研究等领域中都对计算提出了极高的具有挑战性的要求。
例如,在作数值气象预报时,要提高全球气象预报的准确性,据估计在经度、纬度和大气层方向上至少要取200*100*20=40万各网格点。
并行计算机产生和发展的目的就是为了满足日益增长的大规模科学和工程计算、事务处理和商业计算的需求。
问题求解最大规模是并行计算机的最重要的指标之一,也是一个国家高新技术发展的重要标志。
2、拟优化的应用介绍应用jacobi迭代近似求解二维泊松方程。
二维泊松方程:Ω∂∈=Ω∈=∆-),(),,(),(u ),(),,(),(u y x y x g y x y x y x f y x其中),0(*),0(H W =Ω,),(),(),(2222y x u y y x u x y x u ∂+∂=∆),(y x f 和),(y x g 为已知函数,分别定义在Ω的内部和边界上。
对于任意正整数xM 和yN ,将网格剖分成yx N M *个相同的方格。
在网格节点上,用二阶中心差分来近似二阶偏导数。
21,,1,2,1,,12),(222),(22y j i j i j i y x x j i j i j i y x h u u u jh ih u yh u u u jh ih u x+-+-+-≈∂∂+-≈∂∂将差分近似代入泊松方程,便得到了五点差分离散格式,泊松方程的求xx ji y x j i j i x j i j i y j i y x N j M i f h h u u h u u h u h h ≤≤-≤≤=+-+-++-+-1,11)()()(2,221,1,2,1,12,22之后用经典的jacobi 算法来求解此方程组。
从任意一初始近似解yx j i N j M i u ,3,2,1.3,2,1,0,⋯=⋯=,出发,迭代计算:yx y x j i j i x j i j i y j i y x k j i N j M i h h u u h u u h f h h u ,3,2,1.3,2,1)(2)()(221,1,2,1,12,22,⋯=⋯=+++++=+-+-,迭代序号k=1,2,3…直至近似解满足误差要求。
若4),(-=y x f ,且在边界Ω∂上22),(y x y x g +=那么泊松方程的解析解为22),(u y x y x +=,若0),(=y x g ,且)y 2sin()2sin(4),(2πππx y x f =,那么泊松方程的一个解析解是)y 2sin()2sin(),(u ππx y x =。
3、串行算法设计(或介绍)最耗时的是主循环,是一个三重循环嵌套,时间复杂度为3^N 。
4、并行算法设计对主循环进行OpenMP 并行优化,采用#pragma omp parallel for reduction(+:uerr) default(none) \shared(c1,c2,fij,hy2,hx2,Nyp1)shared(u1,u0)private(ix,jy,tmp)时间复杂度无太大变化。
但是多个线程运算也的确加速了其运算速度。
5、采用的并行计算机结构介绍采用个人笔记本进行最终测试,其配置如下:6、基于OpenMP的并行程序实现#include<stdio.h>#include<stdlib.h>#include<math.h>#include<omp.h>#if defined(_WIN32)||defined(_WIN64)#include<sys/timeb.h>#define gettime(a) _ftime(a)#define usec(t1,t2) ((((t2).time-(t1).time)*1000+ \((t2).millitm-(t1).millitm))*100) typedef struct _timeb timestruct;#else#include<sys/time.h>#define gettime(a) gettimeofday(a,NULL)#define usec(t1,t2) (((t2).tv_sec-(t1).tv_sec*1000000+ \((t2).tv_usec-(t1).tv_usec)) typedef struct timeval timestruct;#endif // defined(_WIN32)||defined(_WIN64)#define Mx 8191#define Ny 1023精选文库float uval(float x, float y){return (x*x + y*y);}int main(){float Widthy = 2.0, Heightx = 1.0;float *u0, *u1;float hx, hy, hx2, hy2, fij, c1, c2;float uerr, errtol, tmp, *tprt;int ix, jy, maxIter, iter;int Nyp1 = Ny + 1;timestruct t1, t2;long long telapsed;u0 = (float*)malloc(sizeof(float)*(Mx + 1)*(Ny + 1));u1 = (float*)malloc(sizeof(float)*(Mx + 1)*(Ny + 1));maxIter = 100;errtol = 0.00f;hx = Heightx / Mx;hy = Widthy / Ny;//初始化u0/u1的左右边界for (ix = 0; ix <= Mx; ix++){u0[ix*Nyp1 + 0] = u1[ix*Nyp1 + 0] = uval(ix*hx, 0.0f);u0[ix*Nyp1 + Ny] = u1[ix*Nyp1 + Ny] = uval(ix*hx, Ny*hy);}//初始化u0/u1的上下边界for (jy = 0; jy <= Ny; jy++){u0[jy] = u1[jy] = uval(0.0f, jy*hy);u0[Mx*Nyp1 + jy] = u1[Mx*Nyp1 + jy] = uval(Mx*hx, jy*hy);}//初始化u0的内部点for (ix = 1; ix < Mx; ix++){for (jy = 1; jy < Ny; jy++){u0[ix*Nyp1 + jy] = 0.0f;}}fij = -4.0f;c1 = hx*hx*hy*hy;c2 = 1.0f / (2.0*(hx*hx + hy*hy));hx2 = hx*hx;hy2 = hy*hy;gettime(&t1);//主要迭代for (iter = 1; iter <= maxIter; iter++){uerr = 0.0f;#pragma omp parallel for reduction(+:uerr) default(none) \shared (c1,c2,fij,hy2,hx2,Nyp1) shared(u1,u0) private (ix,jy,tmp)for (ix = 1; ix < Mx; ix++){for (jy = 1; jy < Ny; jy++){u1[ix*Nyp1 + jy] = (c1*fij + hy2*(u0[(ix - 1)*Nyp1 + jy] + u0[(ix + 1)*Nyp1 + jy]) +hx2*(u0[ix*Nyp1 + jy - 1] + u0[ix*Nyp1 + jy + 1]))*c2;tmp = fabs(u0[ix*Nyp1 + jy] - u1[ix*Nyp1 + jy]);uerr = tmp > uerr ? tmp : uerr;}}printf("iter = %d uerr =%e\n", iter, uerr);if (uerr<errtol){break;}tprt = u0;u0 = u1;u1 = tprt;}gettime(&t2);telapsed = usec(t1, t2);printf("历时= %13ld 微秒\n", telapsed);free(u0);free(u1);return 0;}7、并行优化结果分析编译平台:VS2017并行编程平台:OpenMP测试数据集合:100次jacobi迭代求二维泊松方程的近似解。
集群测试:串行算法结果:iter为迭代次数,uerr为误差。
时间单位为微秒。
精选文库并行算法结果:加速比:15241150/2552944=5.97 本机测试:串行算法:并行算法:加速比:13000617/6000371=2.17结论:每次测试中,误差单调减少,且趋于平稳。
代码中设定误差阈值为0,保证每次迭代相同次数。
在集群和本机上,串行算法精确度一样,本机速度较快。
采用cpu并行,集群的并行程度更高,所以速度有明显优势。
本机速度相对较慢。
主要原因是本机核数不如集群多。
但由于reduction(+:uerr)字句,归约了误差,所以并行程度越高,误差越大,导致集群误差较大,而本机相对误差较小。
8、并行计算导论学习体会并行计算导论这门课,概述介绍了并行计算的内容、特点和发展方向,并介绍了并行计算机的体系结构和一些著名的超级计算机。
又深入介绍了几门并行编程方法,如MPI、OpenMP、CUDA等,让我们对并行编程有一个初步的认识。
概述部分可以引发学生的学习兴趣,编程实战正好也满足了学生的学习欲望。
老师提供了先进的计算平台也使学生们更好的了解、认识、学习并行计算。
并行计算是一个热门而且很有作用的方向,这门课给学生打开了一扇求知的窗户,开阔了眼界,学习了知识。
非常感谢老师给我们上了这么有意义的课程。