SPSS第三章参数估计
参数估计与假设检验SPSS

3
区别
参数估计更侧重于总体参数的估计和推断,而假 设检验更侧重于对总体参数的假设进行验证和决 策。
02
SPSS软件介绍
SPSS软件的特点与优势
强大的统计分析功能
SPSS提供了广泛的统计分析方法,包括描述性统计、推论性统计、 多元统计分析等,能够满足各种数据分析和科学研究的需求。
易用性
SPSS的用户界面友好,操作简单,使得用户可以快速上手,减少了 学习成本。
参数估计与假设检验的应用场景与注 意事项
参数估计与假设检验的应用场景
社会科学研究 在社会科学研究中,参数估计与 假设检验是常用的统计方法,用 于检验理论模型和假设,评估变 量之间的关系。
心理学研究 在心理学研究中,参数估计与假 设检验用于研究人类行为、认知 和情感等方面的规律和特点。
医学研究 在医学研究中,参数估计与假设 检验常用于临床试验和流行病学 研究中,以评估治疗效果、疾病 发病率和风险因素等。
04
05
根据输出结果判断假设是否 成立。
假设检验的实例分析
以一个实际研究问题为例,如比较两组人群的平均身高是否存在显著差异。
在SPSS中实现该实例分析,包括数据导入、选择统计方法、设置参数、运 行统计方法和结果解读等步骤。
根据SPSS的输出结果,判断提出的假设是否成立,并解释结果的实际意义。
05
数据处理技术,提高分析效率和准确性。
多变量分析方法
03
多变量分析方法的发展将促进参数估计与假设检验的进一步应
用,能够更全面地揭示变量之间的关系。
THANKS
感谢观看
使用SPSS进行参数估计,例如使用逻辑回归分 析来估计吸烟与肺癌之间的关系。
04
假设检验在SPSS中的实现
参数估计的一般步骤

参数估计的一般步骤引言:参数估计是统计学中一项重要的任务,它用于根据样本数据来推断总体参数的值。
参数估计的一般步骤包括确定估计方法、选择样本、计算估计值和进行推断。
本文将详细介绍参数估计的一般步骤,并以人类的视角进行描述,使读者更好地理解和应用这些步骤。
一、确定估计方法在参数估计中,首先需要确定合适的估计方法。
估计方法可以分为点估计和区间估计两种。
点估计方法通过单个数值来估计参数的值,例如最大似然估计和矩估计。
区间估计方法则通过一个区间来估计参数的范围,例如置信区间估计。
选择合适的估计方法是参数估计的第一步。
二、选择样本在确定了估计方法后,接下来需要选择合适的样本进行参数估计。
样本应当具有代表性,能够反映总体的特征。
为了保证样本的代表性,可以使用随机抽样方法来选择样本。
通过合理选择样本,可以减小估计误差,提高参数估计的准确性。
三、计算估计值在选择好样本后,需要计算参数的估计值。
对于点估计方法,可以使用最大似然估计或矩估计等方法来计算参数的估计值。
对于区间估计方法,可以使用置信区间估计来计算参数的范围。
计算估计值时,需要根据样本数据和估计方法进行相应的计算,确保估计结果的准确性。
四、进行推断在计算得到估计值后,需要进行推断,即根据估计值对总体参数进行推断。
对于点估计方法,可以直接使用估计值作为总体参数的估计值。
对于区间估计方法,可以使用置信区间来表示总体参数的范围。
通过推断可以了解总体参数的可能取值范围,帮助做出正确的决策和预测。
总结:参数估计的一般步骤包括确定估计方法、选择样本、计算估计值和进行推断。
在进行参数估计时,需要选择合适的估计方法和样本,计算出估计值,并进行相应的推断。
参数估计在统计学中扮演着重要的角色,它帮助我们根据样本数据来推断总体参数的值,从而更好地了解和应用统计学。
通过本文的介绍,希望读者能够更好地理解和应用参数估计的一般步骤。
SPSS第三章参数估计

利利利利
t 21.192
Mean df Sig. (2-tailed) Difference 32 .000 8.86364
结论: 结论
1:33家平均受益量为 8.8636万元 万元, 表1:33家平均受益量为 8.8636万元,标准 差为2.4027万元. 2.4027万元 差为2.4027万元.
新电池 ):18.2\10.4\12.6\18.0\11.7\15.0\24.0\17.6\ (日):18.2\10.4\12.6\18.0\11.7\15.0\24.0\17.6\23 .6\24.8\19.3\20.5\19.8\17.1\ .6\24.8\19.3\20.5\19.8\17.1\16.3 旧电池 ):12.1\17.5\8.6\13.9\7.8\15.1\17.9\10.6\ (日):12.1\17.5\8.6\13.9\7.8\15.1\17.9\10.6\13.8 14.2\15.3\ \14.2\15.3\11.6
挂牌上课态度反映得分(X) 挂牌上课态度反映得分( 10—20 10 20 20—30 20 30 30—40 30 40 40—50 40 50 50—60 50 60 60—70 60 70 合计 人数(f ) 人数( 2 6 10 12 20 10 60
案例1 案例1
(1分表示"很不同意" (1分表示"很不同意",7分表示"很同 分表示 分表示" 10项态度分累加后得一总态度分 项态度分累加后得一总态度分, 意",将10项态度分累加后得一总态度分,这种 量叫7级李克累加量表): 量叫7级李克累加量表): 试计算: 试计算: 学生态度得分的平均值和标准差; (1)学生态度得分的平均值和标准差; 构造学生态度得分平均值的98%置信区间. 98%置信区间 (2)构造学生态度得分平均值的98%置信区间.
17SPSS综合应用参数估计和假设检验

钮“”,将变量选入到相应的行变量“[Row(s)]”和列变量 “[Column(s)]”列表中。 点击“Statistics”,选择“McNemar(M)”, 点击 “Continue”。 单击“OK”完成。
在弹出的对话框左侧的变量列表中单击选择成对分 析变量“手术前”和“手术后”,单击按钮,将变 量选入到“Paired Variable(s)”变量列表中。 单击“Options…”,设置“Confidence Interval” 为95%,然后“Continue”。
2.两独立样本均数的比较(p90)
内容回顾
Statistical Inference
Parameter Estimation
Hypothesis Test
point Estimation
Interval Estimation
parametric Test
Nonparame -tric T参数检验
2.两相关样本率的卡方检验
操作过程
SPSS进行两相关样本率的检验的操作为:“Data”→“Weight Cases…”。
在弹出的对话框中选择“Weight cases by”,在左侧的变量列 表中单击选择分析变量,单击按钮“”,将变量“对子数”选 入到“Frequency Variable”,点击“OK”。
在“Test Value”中输入要比较的总体均数,本例为 140 g/L。
单击“Options…”,设置“Confidence Interval”为 95%,然后单击“Continue”。
单击“OK”完成。
SPSS参数的区间估计
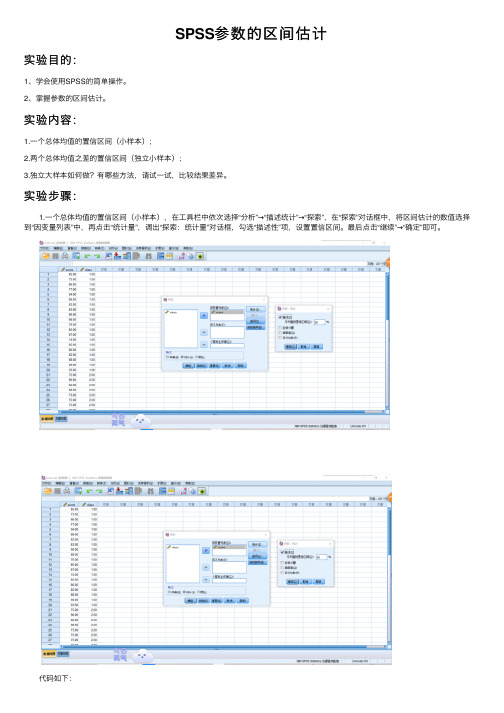
SPSS参数的区间估计实验⽬的:1、学会使⽤SPSS的简单操作。
2、掌握参数的区间估计。
实验内容:1.⼀个总体均值的置信区间(⼩样本);2.两个总体均值之差的置信区间(独⽴⼩样本);3.独⽴⼤样本如何做?有哪些⽅法,请试⼀试,⽐较结果差异。
实验步骤: 1.⼀个总体均值的置信区间(⼩样本),在⼯具栏中依次选择“分析”→“描述统计”→“探索”,在“探索”对话框中,将区间估计的数值选择到“因变量列表”中,再点击“统计量”,调出“探索:统计量”对话框,勾选“描述性”项,设置置信区间。
最后点击“继续”→“确定”即可。
代码如下:1 EXAMINE VARIABLES=score2 /PLOT NONE3 /STATISTICS DESCRIPTIVES4 /CINTERVAL 955 /MISSING LISTWISE6 /NOTOTAL.⼀个总体均值的置信区间 2.两个总体均值之差的置信区间(独⽴⼩样本),利⽤F检验判断两总体的⽅差是否相等;利⽤t检验判断两总体均值是否存在显著差异。
两独⽴样本t检验之前,对于数据的正确处理是⼀个⾮常关键的任务,spss要求两组数据在⼀个变量中,即在⼀个列中,同时要定义⼀个存放总体标志的标识变量。
选择“分析”→“⽐较均值”→“独⽴样本T检验”,在弹出的对话框中选择“检验变量”和“分组变量”,在“定义组”时,此处使⽤指定值,因为原始数据已经定义相关组。
置信区间通常默认95%。
代码如下:1 T-TEST GROUPS=class(12)2 /MISSING=ANALYSIS3 /VARIABLES=score4 /CRITERIA=CI(.95).两个总体均值之差的置信区间 3.独⽴⼤样本的⼀个总体的均值的置信区间和两个总体均值之差的置信区间的做法与上述做法⼀致,但是,结果是不⼀样的。
⼤样本总体均值置信区间上限:81.8543,下限:76.2410; ⼩样本总体均值置信区间上限:82.2371,下限:76.5129; 此处差异看图。
参数估计的一般步骤

参数估计的一般步骤
参数估计是统计学中的一种方法,用于根据样本数据估计总体参数的值。
它是一个重要的统计推断技术,可以帮助我们了解和描述总体的特征。
参数估计的一般步骤如下:
1. 确定研究对象和目标参数:首先,我们需要明确研究对象是什么,需要估计的是哪个参数。
例如,我们可能希望估计某个产品的平均寿命,那么研究对象是产品,目标参数是平均寿命。
2. 收集样本数据:为了进行参数估计,我们需要收集一定数量的样本数据。
样本应该能够代表总体,并且必须是随机选择的,以避免抽样偏差。
3. 选择合适的估计方法:根据研究对象和目标参数的不同,我们可以选择不同的估计方法。
常见的估计方法包括点估计和区间估计。
点估计给出一个单一的数值作为参数的估计值,而区间估计给出一个范围,以表明参数估计值的不确定性。
4. 计算估计值:根据选择的估计方法,我们可以使用样本数据计算出参数的估计值。
例如,对于平均寿命的估计,我们可以计算样本的平均值作为总体平均寿命的估计值。
5. 评估估计的准确性:估计值的准确性可以通过计算估计的标准误
差或置信区间来评估。
标准误差反映了估计值与真实参数值之间的差异,而置信区间提供了参数估计值的不确定性范围。
6. 解释和应用估计结果:最后,我们需要解释估计结果并应用于实际问题中。
根据估计结果,我们可以得出结论,做出决策或提出建议。
参数估计是一种重要的统计推断方法,可以帮助我们了解总体特征并做出准确的推断。
通过正确的步骤和方法,我们可以获得可靠的参数估计结果,并将其应用于实际问题中。
第三章 参数估计 《统计学》PPT课件
注意到这里的样本均值 x 就是样本比例,而 p 是总体比例, 所以总体比例的矩估计是样本比例。
几个例子
【例 3.3】设总体服从参数为 的指数分布 E() ,
即 X p(x;) ex, x 0 ; (x1, , xn ) 是来自总体的样本,
解: 因为 X 的概率密度为
f (x; ) 1 , 0 x 0, x [0, ]
所以,样本 (x1, , xn ) 的联合概率密度为
n
f
(xi ;
)
1
n
,
i 1
0 ,
0 x1, ,xn x j [0, ] , 1 j n
于是 的似然函数为
L(
)
1
n
,
0 ,
mx1a x (xn , , ) max(x1, ,xn )
x 2 sn2 可得 (, 2) 的矩估计为 ˆ x ,ˆ 2 sn2 。
注意
矩估计法可能不惟一,比如例3.3中参数λ 的矩估计;
矩估计法得到的估计在有些情况下可能不 符合逻辑,比如例3.1中当样本的最大值大 于两倍样本均值,那么采用两倍样本均值 作为区间上限的估计显然不是一个合理的 估计,因为区间上限θ至少与x(n)一样大。
3.2 点估计的评价标准
对于总体参数,采用不同的估计方法可能 得到不同的估计量,一个自然而然的问题 就是:
同一个参数的多个不同估计量哪一个最好? 三种常用的评价标准:无偏性,一致性和
有效性。
3.2.1 无偏性
定义 3.1 设ˆ 是 的一个估计量, 的参数空间为 , 如果对任意 , 有
E(ˆ)
Var(*) Var(ˆ) 则称ˆ 是 的一致最小方差无偏估计量(uniformly minimum
参数估计的一般步骤
参数估计的一般步骤参数估计是统计学中的一种方法,用于根据样本数据估计总体参数的取值。
它在各个领域都有广泛的应用,例如经济学、医学、社会学等。
本文将介绍参数估计的一般步骤,帮助读者了解如何进行参数估计。
一、确定参数类型在进行参数估计之前,首先需要确定要估计的参数类型。
参数可以是总体均值、总体比例、总体方差等,根据具体问题来确定。
二、选择抽样方法接下来,需要选择合适的抽样方法来获取样本数据。
常用的抽样方法有简单随机抽样、系统抽样、分层抽样等。
选择合适的抽样方法可以保证样本的代表性,从而提高参数估计的准确性。
三、收集样本数据在进行参数估计之前,需要收集样本数据。
收集样本数据时要注意数据的准确性和完整性,避免数据采集过程中的偏差。
四、计算点估计量得到样本数据后,可以计算点估计量来估计总体参数的取值。
点估计量是根据样本数据计算得出的一个具体数值,用来估计总体参数的未知值。
常见的点估计量有样本均值、样本比例等。
五、构建置信区间除了点估计量,还可以构建置信区间来估计总体参数的取值范围。
置信区间是一个区间估计,表示总体参数的真值有一定的概率落在该区间内。
置信区间的计算方法与具体的参数类型有关,可以利用统计学中的分布理论或抽样分布来计算。
六、进行假设检验除了估计总体参数的取值,参数估计还可以用于假设检验。
假设检验是根据样本数据来判断总体参数是否符合某个特定的假设。
在假设检验中,需要先提出原假设和备择假设,然后计算检验统计量,最后根据统计显著性水平来判断是否拒绝原假设。
七、解释结果需要对参数估计的结果进行解释和说明。
解释结果时要清楚、简洁,避免使用过于专业的术语,以便读者能够理解和接受。
参数估计是统计学中重要的内容之一,它可以帮助我们从有限的样本数据中推断总体的特征。
通过合理选择抽样方法、收集准确的样本数据,并运用适当的统计方法,我们可以得到准确可靠的参数估计结果,为实际问题的决策提供科学依据。
SPSS17.0在生物统计学中的应用实验指导-实验三、参数估计 实验四、t检验
SPSS在生物统计学中的应用——实验指导手册实验三:参数估计一、实验目的与要求1.理解参数估计的概念2.熟悉区间估计的概念与操作方法二、实验原理1. 参数估计的定义●参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中的未知参数的方法。
它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。
●点估计(point estimation):又称定值估计,就是用实际样本指标数值作为总体参数的估计值。
当总体的性质不清楚时,我们须利用某一量数(样本统计量)作为估计数,以帮助了解总体的性质,如:样本平均数乃是总体平均数μ的估计数,当我们只用一个特定的值,亦即数线上的一个点,作为估计值以估计总体参数时,就叫做点估计。
✧点估计的数学方法很多,常见的有“矩估计法”、“最大似然估计法”、“最小二乘估计法”、“顺序统计量法”等。
✧点估计的精确程度用置信区间表示。
●区间估计(interval estimation)是从点估计值和抽样标准误出发,按给定的概率值建立包含待估计参数的区间。
其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起来的包含待估计函数的区间称为置信区间,指总体参数值落在样本统计值某一区内的概率●置信区间(confidence interval)是指在某一置信水平下,样本统计值与总体参数值间误差范围。
置信区间越大,置信水平越高。
划定置信区间的两个数值分别称为置信下限(lower confidence limit,lcl)和置信上限(upper confidence limit,ucl)2. 参数估计的基本原理统计分析的目的就是由样本推断总体,参数估计即是实现这一目的的方法之一。
3. 参数估计的方法参数估计的结果,常用点估计值(样本均值)+置信区间(置信下限、置信上限)来表示。
三、实验内容与步骤1. 单个总体均值的区间估计打开数据文件“描述性统计(100名女大学生的血清蛋白含量).sav”选择菜单【分析】—>【描述统计】—>【探索】”,打开图3.1探索(Explore)对话框。
spss实验报告
实验报告实验目的:1.了解连续变量的统计描述指标体系和参数估计指标体系。
2.掌握具体案例的统计描述和分析。
3.学会bootstrap等方法。
实验原理:1、spss的许多模块均可完成统计描述的任务。
2、spss有专门用于连续变量统计描述的过程。
3、spss可以进行频率等数据分析。
实验内容:1根据CCSS数据,分析受访者的年龄分布情况,分城市/合并描述,并给出简要结果分析。
2 对CCSS中的总指数、现状指数和预期指数进行标准正态变换,对变换后的变量进行统计描述,并给出简要说明。
3根据CCSS 数据,分城市对现状指数的均数和标准差进行Bootstrap方法的参数点估计和区间估计,并同时与传统方法计算出的均值95%置信区间进行比较,给出简要结果分析。
4 根据CCSS项目数据,对职业和婚姻状况进行统计描述,并进行简要说明。
5 根据CCSS项目数据,对职业和家庭月收入情况的关系进行统计描述,并进行行列百分比的汇总,对结果进行简要说明。
6根据CCSS项目数据,给出变量A3a各选项的频数分布情况,并分析每个选项的应答人次和应答人数百分比。
7根据CCSS项目数据,分城市考察A3a各选项的频数分布情况,并给出简要分析。
实验步骤:(1)在分析菜单中点击描述统计,打开对话框“探索”。
把“S3年龄”添加到“因变量列表”,把“S0城市”添加到“因子列表”,把“ID”添加到“标注个案”,点击“确定”。
(2)在分析菜单中点击描述统计,打开对话框“描述性”。
把总指数[index1]、现状指数[index1a]和预期指数[index1b]添加到“变量”框中,选中下方的“将标准化得分另存为变量(Z)”,点击“确定”。
(3)同(2),打开对话框“描述性”,把“现状指数[index1a]”添加到“变量”框中,打开对话框“Bootstrap”,选择“执行”“水平”框中填95,选择“分层”,把“S0城市”添加到“分层变量”中,点击“继续”,点击“确定”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
操作步骤: (1)定义变量X输入数据资料; (2)选择Analyze Compare means one-sample T Test (3)将变量X放入Test栏中 (4)激活 Options … 子对话框,置信度改 为90%,单击 Continue 按钮,返回onesample T Test主对话框; (5)单击OK 按钮执行
反 得 组 值 映 分 中
t 26.711
df 59
Sig . (2-tailed) .000
Mean Difference 47.00000
结论:
表1:学生态度得分的平均值为47分,标准差 为13.6295分. 表2:以98%的置信区间估计学生总体态度得 分平均值的置信区间为 (42.7925,51.2075) 从中可以反映出学生对挂牌上课这一教改 措施普遍赞成,但并不十分拥护,可见还 需进一步改进和完善.
利润增 7.3 量(万 元)
10.2 5.4
企业 序号
12
13
13
14
15
161718192021
利润增 9.7 量(万 元)
6.9
4.3
11. 2
8.2
8.7
7.6
9.1
6.6
8.5
8.9
企业 序号
23
24
25
26
27
28
29
30
31
32
33
利润增 10.4 12. 量(万 8 元)
14. 6
7.5
案例1
(1分表示“很不同意”,7分表示“很同 意”,将10项态度分累加后得一总态度分,这种 量叫7级李克累加量表): 试计算: (1)学生态度得分的平均值和标准差; (2)构造学生态度得分平均值的98%置信区间。
操作步骤:
(1)定义变量X和f ,X 为组中值,输入数据资 料; (2)选择Data Weight Cases ,对f 进行加权。 (3)选择Analyze Compare means onesample T Test (4)将变量X放入Test栏中 (5)激活 子对话框,置信度为98%, Options … 单击 按钮,返回one-sample T Continue Test主对话框; (6)单击 按钮执行。
OK
T - Test
One-Sample Statistics N 反 得 组 值 映 分 中 60 Mean 47.0000 Std. Deviation 13.62948 Std. Error Mean 1.75956
One-Sample Test Test Value = 0 98% Confidence Interv of the al Difference Lower Upper 42.7925 51.2075
11.7 6.0
13.2 13.6 9.0
5.9
9.6
单侧和双侧区间估计公式及图形
n
X Z
X Z
n
X Z
2
n
X Z
n
不重复抽样公式
2
X Z
n
N n n X 1 N 1 N n ( N 1 N )
解: 该电视台宣布的平均受益量应该是最小受益 量,故构造置信下限.设X为企业利润增量.
结论:
表1:得出两个独立样本各自的均值,标准 差以及平均标准误差.新电池的平均使用 寿命明显长于旧电池。 表2:可以看出新旧电池平均使用寿命之差 的95%的置信区间为:若两个样本方差相 等则为(2.4454,8.6746);若两个样 本方差不等则为(2.5437,8.5763)
2、Paired-Samples 选择Analyze Compare Means
利 增 润量
t 21.192
df 32
Sig . (2-tailed) .000
Mean Difference 8.86364
结论:
表1:33家平均受益量为 8.8636万元,标准 差为2.4027万元.
表2:该项电视台可以95%的置信度宣布在该 电台黄金时间做广告给企业带来的平均 受益量至少在8.1552万元以上.
打开Independent-Samples T Test对话框, (3)将变量X放入Test栏中 (4)激活Define Groups 按钮,打开该对话框Groups1中输入1 Groups2中输入2,单击Continue返回主对话框;
(5)单击OK 按钮执行
T - Test
Group Statistics g 1 2 N 15 12 Mean 17.927 12.367 Std. Deviation 4.3442 3.2609 Std. Error Mean 1.1217 .9413
F x Equal variances assumed Equal variances not assumed .514
Sig. .480
t 3.677 3.797
df 25 24.928
Sig. (2-tailed) .001 .001
Mean Difference 5.5600 5.5600
Std. Error Difference 1.5123 1.4643
实例分析3___新旧电池使用寿命比较 (Independent )
某一个新的制造过程可以增加电池的使用 寿命,假设电池使用寿命服从正态分布.在新电 池中随机抽取15个,而在旧电中随机抽取12个同 时测试其使用寿命,资料如下:新旧两种电池平 均使用寿命之差95%的置信区间.
新电池 (日):18.2\10.4\12.6\18.0\11.7\15.0\24.0\17.6\23 .6\24.8\19.3\20.5\19.8\17.1\16.3 旧电池 (日):12.1\17.5\8.6\13.9\7.8\15.1\17.9\10.6\13.8 \14.2\15.3\11.6
x
Independent Samples Test Levene's Test for Equality of Variances t-test for Equality of Means 95% Confidence Interval of the Difference Lower Upper 2.4454 2.5437 8.6746 8.5763
one-
检验变量栏
选择置信度和控 制缺失值处理 检验值栏
Options子对话框 ------ 选择置信度和控制缺失值处理
1 (或1 2 )
只删除与分析有关的 带有缺失值的观测量
删除所有带缺失值的观测量
§3.2 区间估计公式(2) (三)两个总体均值之差的区间估计
待估计参数
已知条件 两个正态总体
置信区间
X Z
2
n
总体均值 (μ)
s X t ( n 1) n 2 s X Z n 2
N n X Z n N 1 2
(二)一个总体比率的区间估计
待估计参数 已知条件 无限总体, np和nq都大于5 总体比率 (p) 有限总体, np和nq都大于5 置信区间
置信度与精确度关系:一般情况下,置信度越高, 允许 误差越大,精确度越低.
在样本容量一定时,通常是在确保一定置信度的前提下 提高精确度.
掌握的样本不同所用区间估计的公式不同.
§3.2 区间估计公式(1)
(一)一个总体均值的区间估计
待估计参数
已知条件
正态总体,σ2已知 正态总体,σ2未知n<30 非正态总体,n≥30 σ未知时,用S 有限总体,n≥30 (不重复) σ未知时,用S
( X1 X 2 ) Z
2
12
n1
2 2
n2
(四)两个总体比率(成数)之差的区间估计
待估计参数 两个总体 成数之差 (P1-P2) 已知条件 置信区间
△
ˆ
无限总体, p1q 2 p 2q 2 N1P1>5, n1q1>5 (p1 p 2 ) Z α n1 n2 2 N2P2>5, n2q2>5
P(1 P) p Z n 2
P(1 P) N n p Z ( ) n N 1 2
§3.3已知原始数据资料的参数估计 —Analyze Compare means
§3.3.1单个总体均值的区间估计步骤: 1、选择Analyze
sample T
Compare means Test 对话框
置信区间
△
12
n1
2 2
ˆ
两个总体 均值之差 μ1-μ2
,
2 1
2 2
已知
( X1 X 2 ) Z
2
n2
两个正态总体 2 12 , 2 未知但相等 两个非正态总体
n1,n2≥30
( X1 X 2 ) t
2
( n1 n2 2 )
Sp
1 1 n1 n2
T - Test
One-Sample Statistics N 利 增 润 量 33 Mean 8.8636 Std. Deviation 2.40271 Std. Error Mean .41826
One-Sample Test Test Value = 0 90% Confidence Interval of the Difference Lower Upper 8.1552 9.5721
1、Independent-Sample T Test过程 选择Analyze Compare Means
Independent-Samples T Test,
打开Independent-Samples T Test对话 框,
打开Independent-Samples