audition人声处理技巧
用Adobe Audition消除人声的技巧

用Adobe Audition消除人声的技巧用Adobe Audition消除人声的技巧在自制卡拉OKMV时,如果找不到伴奏,可以用Adobe Audition消除原唱人声。
方法如下:傻瓜式:方法一:效果- 立体声声像- 声道重混缩- 选择Vocal Cut 新建左声道(左100;右-100) 新建右声道(左-100;右100;反相)方法二:效果- 立体声声像- 析取中置通道- Karaoke(效果预置) - 男声.(测试后,在傻瓜式中这种方法效果最好)方法三:编辑- 转换采样类型,在弹出的对话框中选中"通道"选项中的"单声道".再将左声道混合比和右声道混合比分别设置为100%和-100%.优化式,以小齐的对面的女孩看过来.mp3为例步骤一(同傻瓜式方法二一样):初步消除人声。
在多轨视图下将歌曲导入到Adobe Audition 3.0音轨1,双击音块进入编辑模式,如歌曲对面的女孩看过来,在单轨编辑视图模式下,效果- 立体声声像- 析取中置通道- Karaoke(效果预置) - 男声.另存为对面的女孩看过来(伴凑).mp3这里也可以用同傻瓜式方法一一样,完成初频消除人声,不同的歌二种方式都有不同的效果。
步骤二:进一步消除噪音效果- 滤波和均衡–参量均衡器,进行调整,确定并保存。
步骤三:低频补尝消声后,它的音频被衰减了很多。
要对低频进行补尝。
打开原对面的女孩看过来.mp3文件,导入到音轨2中。
同上进入间轨2编辑模式,并打开效果- 滤波和均衡–参量均衡器。
进行如下调节并另存为对面的女孩看过来(BASS).mp3步骤四:多轨合成对音轨1音轨2进行合并,选中音轨1音轨2,在音轨3中右击–合并到新音轨–所选音频剪辑(立体声)把合成的音频另存为就OK了。
顺便说一下,wav格式音质会好一些。
如何利用PR和AU软件进行人声降噪

如何利用PR/AU软件人声降噪大家都知道手机、相机、摄像机等设备录制出来的人声是有很多杂音的,无法直接用于视频制作中的,可以利用2018以上版本的PR直接在软件里进行处理,仅需十步:第一步:选中需要处理的音频,鼠标左键按照下图操作就可以自动打开Audition(专业的音频处理软件);
第二步:Au打开以后是下图出现的炫酷界面,如果你的跟我不一样也不用紧张,都可以处理的,在软件里调整
就行了;
第三步:鼠标滚轮可以放大音频时间线,跟pr的时间线是一样的,下图红线圈起的那一段平的波形就是杂音,没有人声(处理杂音的时候要选择没人说话的那一小段声音哦,不然人声会有损失。
PS:怎么选中?就是鼠标左键按住不放拖动你觉得合适的);
第四步:自己选好合适的一段噪音后,按照下图“捕捉噪声样本”快捷键:Shift+P(大家学会使用快捷键,能提高效率);
第五步:完成上一步操作之后就会提示你,在你确定要用这段噪音过后,点击确定即可,如果觉得自己选择的噪声样本不合适,可以从图三重新开始选;
第八步:可以多试试框起来的降噪和降噪幅度的参数,会有不同程度的降噪,一般可以参考红色框里的参数,但是要根据音频的实际情况进行调整,调好过后点击应用;
第九步:处理好过后会看到原来有噪声的那些地方变平了有没有,这就证明你的噪声处理成功啦(这里图片上忘记说了,如果你的声音太小了,可以在像手机信号的那个地方加音量就可以;
第十步:处理完后回到pr,看到处理过的音频会变成另一个颜色。
完成以上降噪处理,音频就可以直接融入到视频中去了,是不是很简单呢!。
AdobeAudition 3.0 人声处理的四个步骤
简明后期人声处理的四个步骤
本文参考国际在线论坛
对于歌曲制作后期说起来麻烦,但总体归纳只需三大步:处理人声、调整人声和伴奏的比例、音轨缩混。
先说明第一大步里的四个步骤:
1、降噪。
2、激励。
3、压限。
4、混响。
1)降噪
四个步骤之中,只有这步是对声音音质起破坏作用的!只是处理的好,影响的小一些。
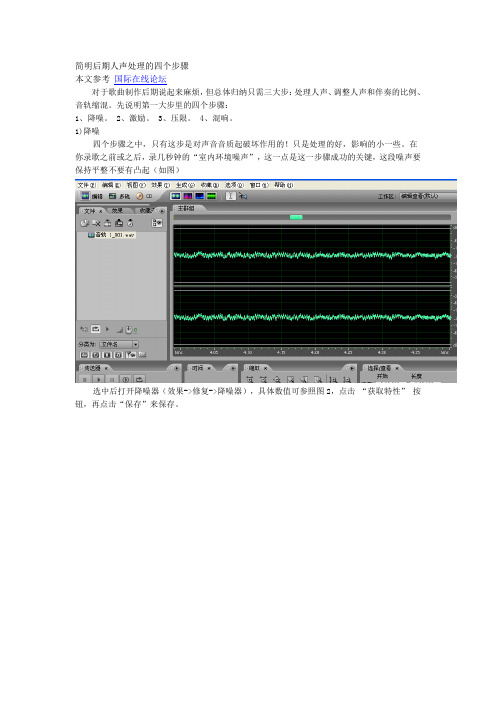
在你录歌之前或之后,录几秒钟的“室内环境噪声”,这一点是这一步骤成功的关键,这段噪声要保持平整不要有凸起(如图)
选中后打开降噪器(效果->修复->降噪器),具体数值可参照图2,点击“获取特性”按钮,再点击“保存”来保存。
干声录制好后,全部选中,打开降噪器,点击“加载”,打开你刚才保存过的文件,单击OK,第一步结束。
2)激励
这步是这四步中最简单的一步,也是必须用插件的一步。
打开BBE ( 效果 -> DirectX插件 -> BBE Sonic Maximizer)
将1、2钮调置“12点”位置(数值为5),3钮调到“3点”位置(数值为4),正确定。
此调法适合大多数需要。
如下图
3)压限
打开“动态处理”(效果–> 振幅和压限 -> 动太处理),预设效果中的Compander 很适合处理人声,可以直接用。
如下图
4)混响
最后一步加混响,用Adobe Audition 3.0的完美混响就可以了,效果 -> 混响–> 完美混响。
使用预设效果中的“Lecture Hall”就可以了. 混响有控制人声远近的作用,一定不要加的过大!“干声”这项就可以控制了,想再小点,就放到100%处。
详解AdobeAudition音频编辑技巧

详解AdobeAudition音频编辑技巧Adobe Audition是一款专业的音频编辑软件,被广泛应用于音频制作和后期处理领域。
它提供了丰富的工具和功能,能够帮助用户对音频进行各种编辑和优化。
本文将详细介绍Adobe Audition 的一些音频编辑技巧,内容包括基本编辑、音频效果、音频标准化以及混音技巧等。
第一章:基本编辑技巧Adobe Audition提供了强大的基本编辑功能,可以对音频进行剪切、复制、粘贴、删除等操作。
在编辑过程中,可以通过快捷键或者菜单栏进行操作。
1.1 剪切和复制在编辑音频时,剪切和复制是最常用的操作之一。
可以使用鼠标选中需要编辑的部分,然后按下Ctrl+X进行剪切,按下Ctrl+C 进行复制。
剪切或复制后,可以在所选地方用Ctrl+V进行粘贴。
1.2 删除和还原如果需要删除音频的某个部分,可以选中该部分并按下Delete 键进行删除。
如果误删了某个部分,可以按下Ctrl+Z进行还原。
1.3 清除音频噪音如果音频中有噪音,可以使用Audition的噪音减少功能来清除。
在Effects菜单下选择Noise Reduction/Restoration,然后选择Noise Reduction或者Click/Pop Eliminator,调整参数直到获得清晰的音频。
第二章:音频效果技巧除了基本编辑之外,Adobe Audition还提供了丰富的音频效果,可以对音频进行音频特效、均衡器、混响等处理。
2.1 音频特效在Effects菜单下的Amplitude and Compression选项中,可以找到一系列音频特效,如压缩、放大、减小峰值等。
通过调整参数可以改变音频的音色、音量等特性。
2.2 均衡器均衡器可以用来调整音频的频谱平衡,增强或减弱特定频率的音量。
在Effects菜单下的Filter and EQ选项中,可以选择Graphic Equalizer来进行频谱调整。
2.3 混响混响可以为音频增加空间感,使其听起来更加自然。
(完整版)audition人声处理技巧

audition人声处理技巧人声音源的频谱分布比较特殊,就其发音方式而言,他有三个部分:一个是由声带震动所产生的乐音,此部分的发音最为灵活,不同音高、不同发音方式所产生的频谱变化也很大;二是鼻腔的形状较为稳定,因而其共鸣所产生的谐音频谱分布变化不大;三是口腔气流在齿缝间的摩擦声,这种齿音与声带震动所产生的乐音基本无关。
频率均衡可以大致的将这三部分频谱分离出来。
用于调节鼻音的频率段在500Hz,以下均衡的中点频率一般在80~150Hz,均衡带宽为4个倍频程。
例如,可以将100Hz定为频率均衡的中点,均衡曲线应从100~400Hz平缓的过渡,均衡增益的调节范围可以为+10Db~ -6dB。
这里应提醒大家的是:进行此项调整的监听音箱不得使用低频发音很弱的小箱子,以避免鼻音被无意过分加重。
人声乐音的频谱随音调的变化也很大,所以调节乐音的均衡曲线应非常平缓,均衡的中点频率可在1000~3400Hz,均衡带宽为六个倍频程。
此一频段控制着歌唱发音的明亮感,向上调节可温和地提升人声的亮度。
然而如需降低人声的明亮度,情况就会更复杂一些。
一般音感过分明亮的人声大多都是2500Hz附近的频谱较强,这里我们可用均衡带宽为1/2倍频程,均衡增益为-4dB左右的均衡处理,在2500Hz附近寻找一个效果最好的频点即可。
人声齿音的频谱分布在4kHz以上。
由于此频段亦包含部分乐音频谱,所以建议调节齿音的频段应为6~16KHz,均衡带宽为3个倍频程,均衡中点频率一般在10~12KHz,均衡增益最大向上可调至+10Db;如需向下降低人声齿音的响度,则应使用均衡带宽为1/2倍频程,均衡中点频率为6800Hz的均衡处理,其均衡增益最低可向下降至-10Db。
由以上分析可以看出,对人声进行频率均衡处理时,为突出某一音感而进行的频段提升,都尽量使用曲线平缓的宽频带均衡。
这是为了使人声鼻音、乐音、齿音三部分的频谱分布均匀连贯,以使其发音自然、顺畅。
audacity人声消除参数

audacity人声消除参数使用Audacity进行人声消除是一种常见的音频处理方法。
通过调整Audacity的参数,可以有效地去除背景噪音,使人声更加清晰。
本文将介绍一些常用的Audacity人声消除参数,帮助读者在处理音频时获得更好的效果。
我们需要了解Audacity的一些基本操作。
打开音频文件后,我们可以看到波形图和控制面板。
在控制面板中,有一些参数可以调整,以达到人声消除的效果。
1. 静音区域分析(Silence Finder)在Audacity中,可以使用静音区域分析工具来自动检测音频中的静音区域。
静音区域通常是指没有人声的部分,通过分析这些区域,我们可以更好地了解背景噪音的特点。
在Audacity中,选择“效果”-“静音区域分析”可以进行静音区域分析。
2. 消除噪音(Noise Reduction)消除噪音是人声消除的核心步骤之一。
在Audacity中,可以使用噪音消除效果来处理音频文件。
选择要处理的音频段落,然后选择“效果”-“噪音消除”,在对话框中点击“获取噪音样本”,然后点击“OK”进行处理。
3. 声音增强(Amplify)在消除噪音后,有时人声可能会变得过于柔弱,这时可以使用声音增强工具来提高人声的音量。
在Audacity中,选择要处理的音频段落,然后选择“效果”-“放大”,在对话框中可以调整增益的大小。
4. 频谱编辑器(Spectral Editing)频谱编辑器是Audacity中一个非常强大的工具,它可以直接编辑音频的频谱图。
通过调整频谱图中的参数,可以对音频进行更精细的处理。
在Audacity中,选择“效果”-“频谱编辑器”,然后调整参数进行编辑。
5. 去除杂音(De-essing)有时,音频中可能存在过多的“s”音(也称为“嘶音”),这会影响人声的清晰度。
在Audacity中,可以使用去除杂音工具来处理这个问题。
选择要处理的音频段落,然后选择“效果”-“去除杂音”,在对话框中可以调整去除杂音的强度。
如何用Audition消人声
如何用Audition 消人声由于消除人声是使用声道重混缩效果器,会同时把中置声道的一些鼓节奏同时消除掉。
: b8 A$ l6 A0m3 Z4 v5 \, u 所以呢,咱拖两次。
也就是说分别将防盗锁这首歌放在音轨一和音轨二。
还有一点就是,若歌曲中人声的混响比较大的话,人声是无法消除的十分干净的。
; h6 y) A# A5 B6 u6 s所以。
咱将就一下就好。
' |+ J- |2 s4 Q; C3 n选中音轨一,选择FX。
选择立体声声像缩。
声道重混选择预置的vocal cut 选项然后,将新建左声道中的左声道调成100,右声道调成-100.将新建右声道中的左声道调成-100,右声道调成100 " r5 G+ I1 L* e- G( Z: J6 t6 m 记得新建右声道下方的反相勾选!接着回答音轨一。
) C6 b4 r7 y* i1 V" z4 ~加载滤波与均衡- 参量均衡器。
$ \8 ?3 {4 J% X/ p 进一步消除噪音。
如右图:. N对其进行低音补偿。
2 N1 f# h+ ^& V3 E/ Y( C, o F具体参数,如右图:接着,我们在音轨二加载滤波与均衡 - 参量均衡接下来我们需要对其进行多轨合成。
/ N& |2 U; X) m8 F$ K3 q3 t) [9 l: U7 i: c6 O! s# i- h在空白轨道里,右键- 合并到新音轨所选范围的音频剪辑(立体声)接着就会发现合成的一轨回到了咱的编辑界面l2f! ]6 A% x7 {# Z+ l5 d 将它SOLO。
(点亮S)+导出!" G&选择好保存路径。
改好名字。
8 t9 \) r! e6 o8 {) J;q选择好参数。
6 J6 g6 _) Y6 R- ~" z' r( p' D [保存!N$ x(如何使用CUBASE 消音在导入音频时,选择split channels 将该音频拆分为左右声道。
au中实现人声分离的方法
au中实现人声分离的方法
在AU(Adobe Audition)中实现人声分离,通常需要使用到一些复杂的音频处理技术,如独立提取人声、背景音乐和其他声音元素。
以下是一种可能的方法:
1. 采集音频:首先,你需要有包含人声和背景音乐的音频文件。
这个音频文件可以是一首歌曲,一个对话,或者其他任何有多个声音元素同时存在的音频。
2. 音频导入AU:将音频文件导入AU。
AU是一款强大的音频编辑软件,可以处理各种复杂的音频任务。
3. 预处理:在开始分离人声之前,你可能需要对音频进行一些预处理,比如降噪、均衡化等,以提高人声和背景音乐的分离度。
4. 使用“中置声道提取器”:在AU中,你可以使用“中置声道提取器”来分离人声。
这个工具可以通过分析音频的频率和声场分布,将人声从背景音乐和其他声音元素中提取出来。
在AU的菜单栏上,选择“效果”>“立体声声像”>“中置声道提取器”。
在弹出的窗口中,你可以调整各种参数来控制人声的提取程度。
5. 调整和优化:分离出人声后,你可能还需要进行一些调整和优化,比如对人声进行均衡化、降噪等处理,以得到更好的音质。
6. 导出结果:最后,你可以将处理后的音频导出为一个新的文件。
你可以选择不同的格式和质量设置,以满足你的需求。
需要注意的是,人声分离是一项复杂的技术,受到许多因素的影响,包括音频质量、人声和背景音乐的混合程度等。
尽管AU提供了许多工具来帮助你进行人声分离,但有时结果可能并不完美。
此外,这种处理过程可能需要一些时间来完成,具体取决于你的电脑性能和音频文件的大小。
第7周:Audition效果器插件及人声润色综合技术
v 为了达到人声的字与字之间的完美统一,消除忽高忽低的 现象,很有必要对录制的音频文件进行压限。压限有三种 方法,一种是AA3.0自自带的,其他两种是第三方插件中 的,一是WAVES C4,一种是UITRAFUNK----COMPRESSOR
v 法1:效果——振幅与压限度——动态处理 v 法2:效果---DERECTX----WAVES----C4,在对话框中,找
v 注: v 1)对非常顽固的电流声用WAVES---X-HOM插件即可消除。
点击效果----WAVES----X-HOM,打开对话框就行 v 2)有很大的噪音,全选音频,先用AA3.0的效果--修复—
消除嘶声,再用效果----WAVES----X-HOM,过一遍,往往 会完全消除噪声,效果很好。
v 法1:运用BBT高声激励器,D82 Sonic Maximizer不过一 般地可设为7、 6 、 -10、为宜。
v 法2:效果----滤波和均衡----图示均衡,就是EQ噻,里 面有很多预置的效果。10段均衡参数,对于男声31,63, 是要拉到底的。250会使人声厚实。8K,16K,进行提升就 是噪音了。
v 用效果—WAVES---METAFLANGER 人声的立体声就出来了。
v 效果—WAVES—L2:参数如下,THRESHOID(阀值)向下就 提升音量。OUT CEILING(输出限制)向下就变小音量, ARC一般设为0.3。右边的IDR下面的三个框框分别为24、 TYPE1、NORMAI。人声就明亮了。
v 法1:效果----修复----降噪器进程----出现对话框。进行 必要的参数设置。右边上角的获取特性为6000,左下角的 FFT为8192,:中间的降噪级别一般定在85-90之间,调到100 会使人声变得很别扭和失声。进行反复试听和微调,自己满 意为止。然后点击“波形全选”,让机器自动进行降噪。
去除人声
4) 如果希望得到伪立体声文件,不要激活New Right
Channel Invert(新的右通道转换)选项;如果希望得到伪单声道文件,不需要作其他设置。与前面所讲的相同,伪单声道的最后结果声音会好一些。
5) 点击OK。
DeComposer 3种消人声的方法
6) 点击OK。
Cool Edit Pro
1) 打开音频文件
2) 选择Edit>Select Entire Wave,选取文件的全部数据。
3) 选择Transform>Amplitude>Channel Mixer在通道混合器的对话框中选择Vocal Cut preset(歌声消除预置)
完成这些设置之后,按OK键回到主界面,在上方的快捷工具栏中将Note Filter按钮激活,表示将以音符方式进行消音处理,然后按下后面的感叹号图标(Apply Filter),稍等片刻后,便能在目录区看到新生成的文件,用Play播放听听效果,如觉得满意就在开始设置的目录里面把它保存下来。
3) 选择Process>Channel Converter
4) 在通道转换对话框中选择Stereo to Stereo - Vocal Cut preset(立体声到立体声-歌声消除预置)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
audition人声处理技巧人声音源的频谱分布比较特殊,就其发音方式而言,他有三个部分:一个是由声带震动所产生的乐音,此部分的发音最为灵活,不同音高、不同发音方式所产生的频谱变化也很大;二是鼻腔的形状较为稳定,因而其共鸣所产生的谐音频谱分布变化不大;三是口腔气流在齿缝间的摩擦声,这种齿音与声带震动所产生的乐音基本无关。
频率均衡可以大致的将这三部分频谱分离出来。
用于调节鼻音的频率段在500Hz,以下均衡的中点频率一般在80~150Hz,均衡带宽为4个倍频程。
例如,可以将100Hz定为频率均衡的中点,均衡曲线应从100~400Hz平缓的过渡,均衡增益的调节范围可以为+10Db~ -6dB。
这里应提醒大家的是:进行此项调整的监听音箱不得使用低频发音很弱的小箱子,以避免鼻音被无意过分加重。
人声乐音的频谱随音调的变化也很大,所以调节乐音的均衡曲线应非常平缓,均衡的中点频率可在1000~3400Hz,均衡带宽为六个倍频程。
此一频段控制着歌唱发音的明亮感,向上调节可温和地提升人声的亮度。
然而如需降低人声的明亮度,情况就会更复杂一些。
一般音感过分明亮的人声大多都是2500Hz附近的频谱较强,这里我们可用均衡带宽为1/2倍频程,均衡增益为-4dB左右的均衡处理,在2500Hz附近寻找一个效果最好的频点即可。
人声齿音的频谱分布在4kHz以上。
由于此频段亦包含部分乐音频谱,所以建议调节齿音的频段应为6~16KHz,均衡带宽为3个倍频程,均衡中点频率一般在10~12KHz,均衡增益最大向上可调至+10Db;如需向下降低人声齿音的响度,则应使用均衡带宽为1/2倍频程,均衡中点频率为6800Hz的均衡处理,其均衡增益最低可向下降至-10Db。
由以上分析可以看出,对人声进行频率均衡处理时,为突出某一音感而进行的频段提升,都尽量使用曲线平缓的宽频带均衡。
这是为了使人声鼻音、乐音、齿音三部分的频谱分布均匀连贯,以使其发音自然、顺畅。
从理论上讲,应使人声在发任何音时,其响度都保持恒定。
为了在不破坏人生自然感的基础上对其进行特定效果的处理可以使用1/5倍频程的均衡处理,具体有以下几种情形:(1)音感狭窄,缺乏厚度,可在800Hz处使用1/5倍频程的衰减处理,衰减的最大值可以在-3dB。
(2)卷舌齿音的音感尖啸,"嘘"音缺乏清澈感,可在2500Hz处使用1/5倍频程的衰减处理,衰减的最大值可以在-6Db。
对音源的均衡处理,最好是使用能显示均衡曲线的均衡器。
一般数字调音台均衡器上的均衡增益调节钮用"G"来标识,均衡频率调节钮用"F"来标识,均衡带宽调节钮用"F"或"Q"来标识。
延时反馈延时反馈是效果处理当中应用最为广泛,但也是最为复杂的方式。
其中,混响、合唱、镶边、回声等效果,其基本处理方式都是延时反馈。
1、混响混响效果主要是用于增加音源的融合感。
自然音源的延时声阵列非常密集、复杂,所以模拟混响效果的程序也复杂多变。
常见参数有以下几种:混响时间:能逼真的模拟自然混响的数码混响器上都有一套复杂的程序,其上虽然有很多技术参数可调,然而对这些技术参数的调整都不会比原有的效果更为自然,尤其是混响时间。
高频滚降:此项参数用于模拟自然混响当中,空气对高频的吸收效应,以产生较为自然的混响效果。
一般高频混降的可调范围为0.1~1.0。
此值较高时,混响效果也较接近自然混响;此值较低时,混响效果则较清澈。
扩散度:此项参数可调整混响声阵密度的增长速度,其可调范围为0~10,其值较高时,混响效果比较丰厚、温暖;其值较低时,混响效果则较空旷、冷僻。
预延时:自然混响声阵的建立都会延迟一段时间,预延时即为模拟次效应而设置。
声阵密度:此项参数可调整声阵的密度,其值较高时,混响效果较为温暖,但有明显的声染色;其值较低时,混响效果较深邃,切声染色也较弱。
频率调制:这是一项技术性的参数,因为电子混响的声阵密度比自然混响稀疏,为了使混响的声音比较平滑、连贯,需要对混响声阵列的延时时间进行调制。
此项技术可以有效的消除延时声阵列的段裂声,可以增加混响声的柔和感。
调治深度:指上述调频电路的调治深度。
混响类型:不同房间的自然混响声阵列差别也较大,而这种差别也不是一两项参数就能表现的。
在数码混响器当中,不同的自然混响需要不同的程序。
其可选项一般有小厅(S-Hall)、大厅(L-Hall)、房间(Room)、随机(Random)、反混响(Reverse)、钢板(Plate)、弹簧(Sprirg)等。
其中小厅、大厅房间混响属自然混响效果;钢板、弹簧混响则可以模拟早期机械式混响的处理效果。
房间尺寸:这是为了配合自然混响效果而设置的,很容易理解。
房间活跃度:活跃度,就是一个房间的混响强度,他与房间墙面吸声特性有关,此项参数即用于调节此特性。
早期反射声与混响声的平衡:混响的早期反射声与其处理效果特性关系密切,而混响声阵的音感则不那么变化多端,所以数码混响器的这两部分的生成是分开的,本参数就是用于调整早期反射声与混响声阵之间响度平衡。
早期反射声与混响声的延时时间:即早期反射声与混响声阵之间的延时时间控制。
此时间较长,混响效果的前段就较清澈;此时间较短,早期反射声与混响声就会重叠在一起,混响效果的前段就较浑浊。
除以上可调参数之外,混响效果还有一些其他附属参数,例如低通滤波、高通滤波、直达/混响声的响度平衡控制等。
2、延时延时就是将音源延迟一段时间后,再欲播放的效果处理。
依其延迟时间的不同,可分别产生合唱、镶边、回音等效果。
当延迟时间在3~35ms之间时人耳感觉不到滞后音的存在,并且他与原音源叠加后,会因其相位干涉而产生"梳状滤波"效应,这就是镶边效果。
如果延迟时间在50ms以上时,其延迟音就清晰可辨,此时的处理效果才是回音。
回音处理一般都是用于产生简单的混响效果。
延时、合唱、镶边、回音等效果的可调参数都差不多.具体有以下几项:*延时时间(Dly),即主延时电路的延时时间调整。
*反馈增益(FB Gain),即延时反馈的增益控制。
*反馈高频比(Hi Ratio),即反馈回路上的高频衰减控制。
*调制频率(Freq),指主延时的调频周期。
*调制深度(Depth),指上述调频电路的调制深度。
*高频增益(HF),指高频均衡控制。
*预延时(Ini Dly),指主延时电路预延时时间调整。
*均衡频率(EQ F),这里的频率均衡用于音色调整,此为均衡的中点频率选择。
由于延时产生的效果都比较复杂多变,如果不是效果处理专家,建议使用设备提供的预置参数,因为这些预置参数给出的处理效果一般都比较好。
3、声激励对音源信号进行浅度的限幅处理,音响便会产生一种类似"饱和"的音感效果从而使其发音在不提高其实际响度的基础上有响度增大的效果。
一些数码效果器上也配有非线性饱和效果,他就是对信号的振幅处理,模拟大电瓶信号在三极管上的饱和所引起的非线性,从而产生出"发硬"的音感效果。
由于限幅失真所引起的主要是产生额外的高次谐波成分,因而新设计的激励器,为了使其处理效果柔和一些,都是通过在音源中家置高次载波成分来模拟限幅失真,营造不那么"嘶哑"的声激励效果。
另外,通过一个用于加强高次谐波的高通滤波器对原信号进行处理,然后再叠加在经延时的原信号上,可以营造出音头清澈的声效果。
显然、这种处理方式可以产生出不那么嘈杂的激励处理。
激励处理类似于音响设备的过载失真,因而对音源的过量激励,会产生令人不悦的嘈杂感。
由于早期音响设备的保真度都不高,人们已经习惯了那种稍显嘈杂的音响,而对于音感清洁的高保真度音响,反而不太习惯,感觉其发音过分柔弱。
在人声音源当中,除了一少部分经过专门训练的人之外,大部分的发言都缺乏劲度,因而这里的激励处理是十分必要的。
对人声的激励处理有下面几种情形:(1)对人声乐音的激励处理,其频谱分布以2500Hz为中点。
此种激励的效果比较自然舒适、对增加音源突出感的作用也比较明显。
(2)对人声鼻音的激励处理,其频谱分布以500Hz为中点。
此种激励可以有效地增大人声的劲度感。
(3)对人声800Hz附近进行激励,可以增加音源的喧嚣感,当然此处理方式的使用应十分谨慎,最好是只用于摇滚乐的演唱。
(4)对人声3500-6800Hz范围内的频谱,不宜使用激励处理,因为它容易使音源产生令人不悦的嘈杂声响。
(5)对人声的齿音一般应避免使用激励处理,因为此频段的失真很容易被人察觉。
当然如果是使用激励效果比较柔和的数字式激励器,也可以对齿音做轻微的激励处理,以用于加重齿音的清析感。
其处理的频谱应在7200Hz以上。
歌唱发音的激励处理通常要保守一些。
在实际的调音当中,激励处理的音感效果有可能随长时间的听音而逐渐弱化,所以在调节激励效果时,时间不要超过10分钟。
对人声音源的激励处理,最好是使用数码效果处理器。
它通常有以下几项调整参量:1.输入增益(Gmn),用于调节输入电平,注意此处切勿使设备产生过载。
2.调谐频率(Tuning),根据需要处理的频段,选择一个合适的频率。
3.驱动电平(Drive),用于调整激励的深度。
驱动电平较大时,效果比较嘈杂;驱动电平较小时,效果则比较温和。
4.混合比率(Mix),即原信号与效果信号的响度比。
效果处理的整体规划对人声音源的精细处理,需要使用1台全数字式调音台,至少3台数字式效果器和一台数字式激励器,其连接方式如附图所示。
首先在调音台上,使用通道均衡控制单元对人声进行音色调整,以使其音感得以改善,这里给出几个常用的例子。
(1)8OOHz附近的频段可使人产生某种厌烦感,因而是可在此频段予以最大为15dB的衰减,频带宽度为1/5倍频程,用于改善人声发音的总印象;(2)68O0Hz附近的频段可使人声产生尖啸、刺耳的感觉,可在此频段予以最大为10dB 的衰减,频带宽度为l/5倍频程,用以减弱齿音的尖啸感;(3)对于发音过亮、有炸耳棍子的感觉者,可在3400Hz处予以最大为8dB的衰减,频带宽度为1/3倍频程;(4)对于鼻音过重者,可在500Hz以下频段适当衰减,衰减带宽为3倍频程;(5)齿音的超高频段由于受人耳灵敏度的影响,需对12KHz处提升6dB(频带宽度为2倍频程),其响度才能与人声的乐音平衡。
以上均衡处理较适用于现场扩音,如果是多轨录音或节目转发,则应将增益的调节量减半。
均衡调好之后,再调节激励器。
先将激励器的驱动电平和混频电平调至最大状态,频率调谐放在2500Hz,此时如果其发音已显嘈杂,或音色过硬,可将驱动电平调低,应注意这种调整有变化的是音源的硬度。
如果驱动电平调在较高的位置,而只将混频电平调低,则高硬度声响的音响保持不变,但它会被未经激励处理的原声略微掩盖。