郭秀花--医学大数据分析策略与数据挖掘
医学数据分析与挖掘技术的应用

医学数据分析与挖掘技术的应用在当今信息化的时代,医学数据的获取和管理变得越来越容易,但是对这些数据进行分析和挖掘,却需要更为专业的技术。
医学数据分析和挖掘技术是当前医学领域中的热门技术之一,它可以帮助医学工作者更好地了解疾病的发展规律、优化诊疗方案和预测疾病趋势,具有重要的现实意义。
一、医学数据分析技术医学数据分析技术是指通过计算机技术对大量病例数据进行改变分析、统计和建模,以发现疾病的发展规律和预测疾病的发展趋势。
其中,数据处理技术和数据挖掘技术是最为核心和关键的技术。
1. 数据处理技术数据处理技术是指将海量、复杂、多样的医学数据进行收集、整理、清洗、存储和管理,以便进行后续的数据分析和挖掘。
医学数据一般包含临床和非临床数据,临床数据包括病史、检查、诊断、治疗和随访记录等,而非临床数据则包括生化、遗传、影像、药物等多个方面。
数据处理技术需要使用到数据库技术、数据仓库技术和大数据技术等。
2. 数据挖掘技术数据挖掘技术是指运用计算机技术来发现数据中包含的隐藏关系和规律,以及对未来的趋势进行预测和分析。
常用的数据挖掘算法包括分类算法、聚类算法、关联算法和预测算法等。
数据挖掘技术可以为医学工作者提供较为全面的疾病信息,例如疾病的多发人群、治疗效果、不良反应等方面的信息。
二、医学数据挖掘技术医学数据挖掘技术是指通过计算机技术,从大量海量的医学数据中发现隐藏的关系和规律,可以帮助医学工作者深入了解疾病的发展规律和预测疾病的发展趋势。
医学数据挖掘技术包括以下几个方面。
1. 临床决策支持系统临床决策支持系统是一种基于计算机技术的智能化医疗决策辅助工具,它可以对患者的个性化特征和治疗方案进行自动化评估和分析,为医生提供可靠性、准确性和效益性的治疗决策。
临床决策支持系统使用数据挖掘技术和人工智能技术,可以分析医生的临床行为和病例记录,提高医生的决策效率和可靠性,引导医生进行更为恰当和科学的治疗决策。
2. 疾病预测和诊断模型通过对大量疾病数据进行分析和挖掘,可以建立可靠、准确的疾病预测和诊断模型,这些模型可以快速、准确地对患者的病情进行评估和预测,帮助医生更好地做出治疗方案和预防措施。
生物医学大数据分析与挖掘ppt课件

报告内容
一、生物医学大数据分析挖掘的几个方向 二、基于流感大数据发展流感预测预警新方法
21
临床大数据分析与挖掘-流感危害性预测
y = 31.31 x - 8.85 R2=0.83
通过分析流感监测产生的大数据,社会经济大数据以及大 量基因序列,以及大量的相关性分析,发现了快速预测流 感病毒危害性的新方法
1,目前该方法已经申请了专利。 2,在使用我们的方法向WHO推荐疫苗参考株。 3,Nature Communcations, 2012.
28
X X
X
XX XX
XX
X
29
新华社发布的新闻:我国科学家发明流感 疫苗株快速选择新技术
30
我国2013年华东地区H7N9溯源
进化分析
大规模病毒采样 与基因测序
Based on 7 seasons during 2002-2009.
Du et al. Nature Communications析与挖掘-流感疫苗推荐
大规模病毒采样 与基因测序
流感病毒关联 网络
疫苗推荐
该工作发表在《Nature Communications》上, 被选为亮点文章,并且同期《Nature》杂志也对 该工作进行了报道
商业大数据 生物医学大数据
智能交通
天气预报
股票
? 智慧医疗和
个性化医疗
3
医院信息化产生海量临床数据
临床大数据
4
美国卫生信息化发展计划
2011年,美国卫生信息技术协调官办公室发布全国卫生信息化发展计划,计 划时限2011-2015
5
我国卫生信息化发展计划
35212工程
6
美国VS中国
美国 系统逐步成型、理念推广、政策制定、科 学研究
数据挖掘技术在医疗大数据中的应用研究
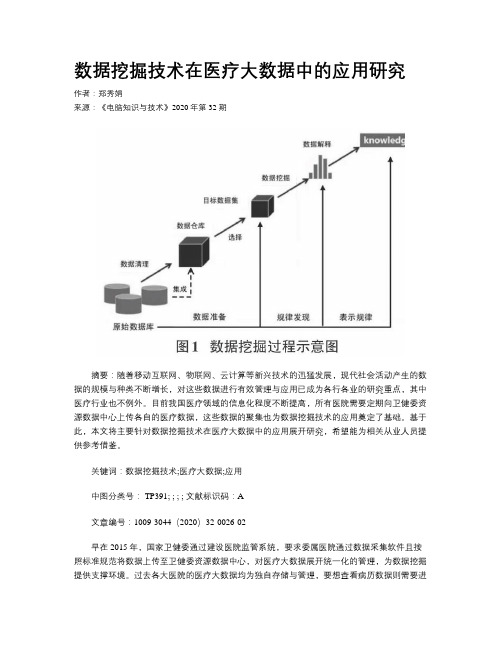
数据挖掘技术在医疗大数据中的应用研究作者:郑秀娟来源:《电脑知识与技术》2020年第32期摘要:随着移动互联网、物联网、云计算等新兴技术的迅猛发展,现代社会活动产生的数据的规模与种类不断增长,对这些数据进行有效管理与应用已成为各行各业的研究重点,其中医疗行业也不例外。
目前我国医疗领域的信息化程度不断提高,所有医院需要定期向卫健委资源数据中心上传各自的医疗数据,这些数据的聚集也为数据挖掘技术的应用奠定了基础。
基于此,本文将主要针对数据挖掘技术在医疗大数据中的应用展开研究,希望能为相关从业人员提供参考借鉴。
关键词:数据挖掘技术;医疗大数据;应用中图分类号: TP391; ; ; ; 文献标识码:A文章编号:1009-3044(2020)32-0026-02早在2015年,国家卫健委通过建设医院监管系统,要求委属医院通过数据采集软件且按照标准规范将数据上传至卫健委资源数据中心,对医疗大数据展开统一化的管理,为数据挖掘提供支撑环境。
过去各大医院的医疗大数据均为独自存储与管理,要想查看病历数据则需要进入到各个医院的系统,再加上各医院使用的系统可能不一样,也导致医疗数据收集难度增加[1]。
从这一点来看,医疗领域的信息化程度相较于如今日新月异的互联网生活来讲,显得较为落后,所以整个医疗行业急需抓紧信息化建设步伐。
而在医疗行业,每天都会产生大量的数据信息,所以在数据挖掘技术应用上该技术必然会在医疗行业中得到应用。
医疗大数据主要在医疗服务中所产生,其来源范围较为广泛,例如有些数据来自制药企业、有些数据信息则来自临床方面的数据,还有的数据信息来自医院与医保费用管理方面。
相关数据表明,通常医疗机构每年产生数据存储量为1TB~20TB,在这些海量数据中蕴含着丰富知识与规律,倘若能够从中获取价值性知识,对于推动现代医学研究而言意义重大[2]。
随着数据挖掘技術逐渐发展成熟,在医疗大数据中也得到了充分应用,本文便针对此展开深入研究。
临床医学大数据分析与挖掘—基于Python机器学习与临床决策-第11章-数据挖掘建模平台实现全

大数据挖掘专家
7
பைடு நூலகம்
数据源
➢ 【数据源】模块主要用于数据分析工程的数据导入与管理,根据情况用户可选择【CSV文件】或者【SQL 数据库】。【CSV文件】支持从本地导入CSV类型的数据,如图所示。
大数据挖掘专家
8
数据源
➢ 【SQL数据库】支持从DB2、SQL Server、MySQL、Oracle、PostgreSQL等关系型数据库导入数据,如 图所示。
大数据挖掘专家
15
TipDM数据挖掘建模平台的本地化部署
➢ 通过开源TipDM数据挖掘建模平台官网(),如图所示。
大数据挖掘专家
16
TipDM数据挖掘建模平台的本地化部署
➢ 进入Github或码云开源网站,如图所示,同步平台程序代码到本地,按照说明文档进行配置部署。
➢ 在TipDM数据挖掘建模平台上配置医疗保险的欺诈发现案例的总体流程如图所示。
数据来源
数据获取
数据准备
特征工程
模型训练
数
数据源
据 获
取
描述性统计
修改列名
绘制保险条 款类别饼图
新增列 分组聚合
表堆叠 表连接 缺失值处理 数据编码化 数据标准化
基于K-Means 的投保人聚类
大数据挖掘专家
22
总体流程
大数据挖掘专家
6
首页
➢ 登录平台后,用户即可看到【首页】模块系统提供的示例工程(模板),如图所示。
【模板】模块主要用于常用数据分析与建模案例的快速创建和展示。通过【模板】模块,用户可以创建一个 无须导入数据及配置参数就能够快速运行的工程。同时,用户可以将自己搭建的数据分析工程生成为模板, 显示在【首页】模块,供其他用户一键创建。
数据挖掘在医学大数据研究中的应用

数据挖掘在医学大数据研究中的应用作者:孙雪松王晓丽来源:《中国信息化周报》2018年第21期医院信息化的发展及云计算、大数据、物联网、人工智能等在医疗领域的应用,为医学数据的获取、存储及处理提供了极大便利。
数据挖掘也随着计算机技术得到了广泛应用,从而提高了数据利用效率,拓展了知识发现的广度与深度。
目前,医院已积累了大量医疗相关数据。
医学大数据与数据挖掘的结合,能够帮助人们从存储的大体量、高复杂的医学数据中提取有价值信息,加速医学成果转化,为医疗行业开拓新的时代。
数据挖掘是指从数据库中,提取隐含在其中的人们事先未知、潜在的有用的信息和知识的过程。
数据挖掘已有较多成熟方法,并在医学大数据挖掘中取得了一定成果。
数据挖掘分类及常用算法预测型数据挖掘是从历史数据中发现的已知结果,推断或预测未知数据的可能值,有预测和回归两种类型。
常用算法有线性回归、Logistic回归、K-NN算法、决策树(DT)、人工神经网络(ANN)、支持向量机(SVM)及各种集成算法等。
回归是指确定响应变量和一个或多个自变量之间依赖关系以构建预测模型。
Kirkland等利用Logistic回归建立模型,对采集的病人临床指标等数据建立了疾病恶化预警模型,可对病人未来2-12小时可能出现的疾病恶化风险进行预测。
分类是指基于已知所属类别的历史数据的特征描述预先定义好的类别,构建预测类别的模型,再根据待查数据的相关特征与这些类别相应特征之间的相似程度,确定待查数据应划归的类别,可用于预测性研究。
描述型数据挖掘是识别数据中的模式或关系,旨在探索被分析数据的内在性质,常用方法有关联规则、序列规则和聚类。
关联规则通过从大量数据中,发现数据之间某些未知的、潜在的且有实际意义的关联或联系,并以关联规则的形式表现出来。
关联规则应用于医学研究,可以从医疗信息中揭示疾病发生、发展规律以及医学诊断、医学图像、症状与用药等某些内在联系,为疾病诊断和健康管理提供参考。
大数据分析技术在医学数据挖掘中的应用研究

大数据分析技术在医学数据挖掘中的应用研究随着科技的不断发展和医学数据的迅猛增长,如何高效地挖掘医学数据并提取有价值的信息成为了一个重要的课题。
在这个过程中,大数据分析技术的应用变得愈发重要。
本文将探讨大数据分析技术在医学数据挖掘中的应用研究,并总结其在医学领域中的潜力和挑战。
首先,大数据分析技术在医学数据挖掘中的应用可以帮助医学界更好地理解和解决疾病问题。
医学数据中包含了丰富的信息,如患者的个人信息、医学影像、实验室检测结果等。
通过大数据分析技术,可以将这些数据进行整合、分析和挖掘,从而找出潜在的规律和趋势,为医学研究和临床实践提供有力的支持。
例如,通过对大量患者数据的分析,可以发现某个特定人群中某种疾病的高发原因,从而制定相应的预防措施和治疗策略。
其次,大数据分析技术可以在医院管理中发挥重要作用。
医院作为一个大型组织,拥有大量的病历、药品、设备等信息。
如何将这些信息进行整合和分析,对于提高医院的管理效率和优化资源配置非常关键。
通过大数据分析技术,可以对医院的运营情况进行综合评估,发现问题并快速采取相应措施。
例如,通过对医院的病历数据进行分析,可以发现患者的就诊习惯和疾病流行趋势,进而调整医院的服务策略和资源配置。
另外,大数据分析技术还可以用于辅助医学研究和新药开发。
医学研究通常需要收集和处理大量的数据,并进行统计分析和建模。
大数据分析技术可以在这个过程中发挥重要作用,帮助研究人员提取有效信息、建立预测模型和评估药物的疗效。
例如,通过对大量患者的基因数据和临床数据进行分析,可以发现潜在的基因与疾病之间的关联,为研究人员提供新的研究思路和治疗靶点。
然而,大数据分析技术在医学数据挖掘中也面临一些挑战。
首先,医学数据的质量和隐私问题是一个重要的挑战。
医学数据涉及患者的敏感信息,如个人信息和病历记录,如何保护数据的隐私成为一个亟待解决的问题。
同时,由于医学数据的多样性和复杂性,数据质量的问题也需要引起重视。
数据挖掘方法综述
收稿日期:2003-09-281 作者简介:郭秀娟(1961~),女,吉林省德惠市人,副教授,在读博士研究生.文章编号:100920185(2004)0120049205数据挖掘方法综述郭 秀 娟(吉林建筑工程学院计算机科学与工程系,长春 130021)摘要:数据挖掘方法结合了数据库技术、机器学习、统计学等领域的知识,从深层次挖掘有效的模式.数据挖掘技术的常见方法,关联规则、决策树、神经网络、粗糙集法、聚类方法、遗传算法和统计分析方法被应用到各个领域,数据挖掘技术具有广泛的应用前景.关键词:数据挖掘;挖掘工具;挖掘方法;挖掘理论中图分类号:N 37 文献标识码:A 数据挖掘(Data Mining )是从大量的、不完全的、有噪声的、模糊的和随机的数据中,提取隐含在其中的、人们事先不知道的,但又是潜在有用的信息和知识的过程[1-2].人们把原始数据看作是形成知识的源泉,就像从矿石中采矿一样,原始数据可以是结构化的,如关系数据库中的数据,也可以是半结构化的,如文本、图形、图像数据,甚至是分布在网络上的异构型数据.发现知识的方法可以是数学的,可以是非数学的,也可以是演绎的或是归纳的.发现了的知识可以被用于信息管理、查询优化、决策支持、过程控制等,还可以用于数据自身的维护.可以说数据挖掘是一门很广义的交叉学科,它汇聚了不同领域的研究者,尤其是数据库、人工智能、数理统计、可视化、并行计算等方面的学者和工程技术人员[2].数据挖掘技术从一开始就是面向应用领域,它不仅是面向特定数据库的简单检索查询调用,而且,要对数据进行微观、中观乃至宏观的统计、分析、综合和推理,以指定实际问题的求解,企图发现事件间的相互关联,甚至利用已有的数据对未来的活动进行预测.1 数据挖掘的方法 研究的对象是大量的隐藏在数据内部的有用信息,如何获取信息是我们所要解决的问题.数据挖掘从一个新的角度把数据库技术、人工智能、统计学等领域结合起来,从更深层次发掘存在于数据内部新颖、有效、具有潜在效用的乃至最终可理解的模式.在数据挖掘中,数据分为训练数据、测试数据和应用数据3部分.数据挖掘的关键是在训练数据中发现事实,以测试数据作为检验和修正理论的依据,把知识应用到数据中.数据挖掘利用了分类、关联规则、序列分析、群体分析、机器学习、知识发现及其他统计方法,能够通过数据的分析,预测未来.数据挖掘有以下几种常用方法:111 关联规则挖掘 1993年,R 1Agrawal 等人首先提出了关联规则挖掘问题,他描述的是数据库中一组数据项之间某种潜在关联关系的规则.一个典型的例子是:在超市中,90%的顾客在购买面包和黄油的同时,也会购买牛奶.直观的意义是:顾客在购买某种商品时有多大的倾向会购买另外一些商品.找出所有类似的关联规则,对于企业确定生产销售、产品分类设计、市场分析等多方面是有价值的.关联规则是数据挖掘研究的主要模式之一,侧重于确定数据中不同领域之间的关系,找出满足给定条件下的多个域间的依赖关系.关联规则挖掘对象一般是大型数据库(Transactional Database ),该规则一般表示式为:A 1∧A 2∧…A m =>B 1∧B 2∧…B m ,其中,A k (k =1,2,…,m ),B j (j =1,2,…,n )是数据库中的数据项.有Support (A =>B )=P (A ∪B ),Confidence (A =>B )=P (A|B )1数据项之间的 第21卷 第1期2004年3月吉 林 建 筑 工 程 学 院 学 报Journal of Jilin Architectural and Civil Engineering Institute Vol.21 No.1Mar 12004 05吉 林 建 筑 工 程 学 院 学 报第21卷关联,即根据一个事务中某些数据项的出现可以导出另一些数据项在同一事务中的出现[3-4].在关联规则挖掘法的研究中,算法的效率是核心问题,如何提高算法的效率是所要解决的关键.最有影响的是Apriori算法,它探查逐级挖掘,Apriori的性质是频繁项集的所有非空子集都必须是频繁的.112 决策树方法 决策树(decision tree)根据不同的特征,以树型结构表示分类或决策集合,产生规则和发现规律.利用信息论中的互信息(信息增益)寻找数据库中具有最大信息量的字段,建立决策树的一个结点,再根据字段的不同取值建立树的分枝.在每个分枝子集中,重复建立树的下层结点和分枝的过程,即可建立决策树.决策树起源于概念学习系统CL S(Concept Learning System)[5],其思路是找出最有分辨能力的属性,把数据库划分为多个子集(对应树的一个分枝),构成一个分枝过程,然后对每一个子集递归调用分枝过程,直到所有子集包含同一类型的数据.最后得到的决策树能对新的例子进行分类.CL S的不足是它处理的学习问题不能太大.为此,Quinlan提出了著名的ID3学习算法[6],通过选择窗口来形成决策树.从示例学习最优化的角度分析,理想的决策树分为3种:①叶子数最少;②叶子结点深度最小;③叶结点数最少且叶子结点深度最小.寻优最优决策树已被证明是N P困难问题.ID3算法借用信息论中的互信息(信息增益),从单一属性分辨能力的度量,试图减少树的平均深度,却忽略了叶子数目的研究.其启发式函数并不是最优的,存在的主要问题有:(1)互信息的计算依赖于属性取值的数目多少,而属性取值较多的属性并不一定最优.(2)ID3是非递增学习算法.(3)ID3决策树是单变量决策树(在分枝结点上只考虑单个属性),许多复杂概念表达困难,属性间的相互关系强调不够,容易导致决策树中子树的重复或有些属性在决策树的某一路径上被检验多次.(4)抗噪声性差,训练例子中,正例和反例的比例较难控制.针对上述问题,出现许多较好的改进算法,刘晓虎等在选择一个新属性时,并不仅仅计算该属性引起的信息增益,而是同时考虑树的两层结点,即选择该属性后继续选择属性带来的信息增益.Schlimmer和Fisher设计了ID4递增式算法,通过修改ID3算法,在每个可能的决策树结点创建一系列表,每个表由未检测属性值及其示例组成,当处理新例时,每个属性值的正例和反例递增计量.在ID4的基础上,Utgoff 提出了ID5算法,它抛弃了旧的检测属性下面的子树,从下面选择属性构造树.此外,还有许多算法使用了多变量决策树的形式,著名的C415系统也是基于决策树的.113 神经网络方法 模拟人脑神经元方法,以MP模型和HEBB学习规则为基础,建立了3大类多种神经网络模型,即前馈式网络、反馈式网络、自组织网络.它是一种通过训练来学习的非线性预测模型,可以完成分类、聚类等多种数据挖掘任务.神经网络(neural network)是由大量的简单神经元,通过极其丰富和完善的连接而构成的自适应非线性动态系统,并具有分布存储、联想记忆、大规模并行处理、自组织、自学习、自适应等功能[7].网络能够模拟人类大脑的结构和功能,采用某种学习算法从训练样本中学习,并将获取的知识存储于网络各单元之间的连接权中,神经网络和基于符号的传统A I技术相比,具有直观性、并行性和抗噪声性.目前,已出现了许多网络模型和学习算法,主要用于分类、优化、模式识别、预测和控制等领域.在数据挖掘领域,主要采用前向神经网络提取分类规则.神经网络模拟人的形象直觉思维,其中,最大的缺点是“黑箱”性,人们难以理解网络的学习和决策过程.因此,有必要建立“白化”机制,用规则解释网络的权值矩阵,为决策支持和数据挖掘提供说明,使从网络中提取知识成为自动获取的手段.通常有两种解决方案:①建立一个基于规则的系统辅助.神经网络运行的同时,将其输入和输出模式给基于规则的系统,然后用反向关联规则完成网络的推理过程.这种方法把网络的运行过程和解释过程用两套系统实现,开销大,不够灵活;②直接从训练好的网络中提取(分类)规则.这是当前数据挖掘使用得比较多的方法.从网络中采掘规则,主要有以下倾向:(1)网络结构分解的规则提取.它以神经网络的隐层结点和输出层结点为研究对象,把整个网络分解为许多单层子网的组合.这样研究较简单的子网,便于从中挖掘知识.Fu 的KT 算法和Towell 的MofM 算法是有代表性的方法.KT 方法的缺点是通用性差,且当网络比较复杂时,要对网络进行结构的剪枝和删除冗余结点等预处理工作.(2)神经网络的非线性映射关系提取规则.这种方法直接从网络输入和输出层数据入手,不考虑网络的隐层结构,避免了基于结构分解的规则提取算法的不足.Sestito 等人的相似权值法,以及CSW 算法(将网络输入扩展到连续取值),是其中的两种典型算法.当然,在数据挖掘领域,神经网络的规则提取还存在许多问题,即如何进一步降低算法的复杂度,提高所提取规则的可理解性及算法的适用性,研究提取规则集的评估标准和在训练中从神经网络动态提取规则,以及及时修正神经网络并提高神经网络性能等,都是进一步研究的方向.114 粗集方法粗集(rough set )理论的特点是不需要预先给定某些特征或属性的数量描述[4,8],如统计学中的概率分布,模糊集理论中的隶属度或隶属函数等,而是直接从给定问题出发,通过不可分辨关系和不可分辨类确定问题的近似域,从而找出该问题中的内在规律.粗集理论同模糊集、神经网络、证据理论等其它理论均成为不确定性计算的一个重要分支.粗集理论是根据目前已有的给定问题的知识,将问题的论域进行划分,然后对划分后的每一个组成部分确定其对某一概念的支持度,即肯定支持此概念或不支持此概念.在粗集理论中,上述情况分别用3个近似集合来表示正域、负域和边界.在数据挖掘中,从实际系统采集到的数据可能包含各种噪声,存在许多不确定的因素和不完全信息有待处理.传统的不确定信息处理方法,如模糊集理论、证据理论和概率统计理论等,因需要数据的附加信息或先验知识(难以得到),有时在处理大量数据的数据库方面无能为力.粗集作为一种软计算方法,可以克服传统不确定处理方法的不足,并且和它们有机结合,可望进一步增强对不确定、不完全信息的处理能力.粗集理论中,知识被定义为对事物的分类能力.这种能力由上近似集、下近似集、等价关系等概念体现.因为粗集处理的对象是类似二维关系表的信息表(决策表).目前,成熟的关系数据库管理系统和新发展起来的数据仓库管理系统,为粗集的数据挖掘奠定了坚实的基础.粗集从决策表挖掘规则,辅助决策,其关键步骤是求值约简或数据浓缩,包括属性约简Wong SK 和Ziarko W 已经证明求最小约简是一个N P hard 问题[9].最小约简的求解需要属性约简和值约简两个过程,决策表约简涉及到核和差别矩阵两个重要概念.一般来讲,决策表的相对约简有许多,最小约简(含有最小属性)是人们期望的.另一方面,决策表的核是唯一的,它定义为所有约简的交集,所以,核可以作为求解最小约简的起点.差别矩阵突出属性的分辨能力,从中可以求出决策表的核,以及约简规则.借助启发式搜索解决,苗夺谦等人从信息论的角度对属性的重要性作了定义,并在此基础上提出了一种新的知识约简算法M IBAR K ,但其对最小约简都是不完备的.此外,上述方法还只局限于完全决策表.Marzena K 应用差别矩阵,推广了等价关系(相似关系)、集合近似等概念,研究了不完全决策表(属性的取值含有空值的情况)的规则的发展问题,从而为粗集的实用化迈出了可喜的一步.Marzena K 还比较了几种不完全系统的分析方法,得出如下结论:①一个规则是确定的,如果此规则在原不完全系统的每个完全拓展中是确定的;②删除从不完全决策表包含空值的对象后,采掘的知识可能成为伪规则.粗集的数学基础是集合论,难以直接处理连续的属性.而现实决策表中连续属性是普遍存在的,因此,连续属性的离散化是制约粗集理论实用化的难点之一,这个问题一直是人工智能界关注的焦点.连续属性的离散化的根本出发点,是在尽量减少决策表信息损失的前提下(保持决策表不同类对象的可分辨关系),得到简化和浓缩的决策表,以便用粗集理论分析,获得决策所需要的知识.最优离散化问题(离散的切点数最少)已被证明是N P -hard 问题,利用一些启发式算法可以得到满意的结果.总体上讲,现有15 第1期郭秀娟:数据挖掘方法综述25吉 林 建 筑 工 程 学 院 学 报第21卷离散化方法主要分为非监督离散化和监督离散化.前者包括等宽度(将连续值属性的值域等份)和等频率离散化(每个离散化区间所含的对象相同).非监督离散化方法简单,它忽略了对象的类别信息,只能用在属性具有特殊分布的情况.针对上述问题,监督离散化方法考虑了分类信息,提高了离散效果.目前,比较有代表性的监督离散化方法有以下几种:①Holte提出了一种贪婪的单规则离散器(one rule dis2 cretizer)方法;②统计检验方法;③信息熵方法等.这些方法各有特点,但都存在一个不足,即每个属性的离散化过程是相互独立的,忽略了属性之间的关联,从而使得离散结果中含有冗余或不合理的分割点.针对这个问题,有人给出了一种连续属性的整体离散化方法,实验表明,不仅能显著减少离散化划分点和归纳规则数,而且提高了分类精度.连续属性离散化目前还存在的问题是缺乏递增的离散化方法,即当新的对象加入决策表时,原有的分割点可能不是最优或最满意的.粗集理论和其它软计算方法的结合,能够提高数据挖掘能力.Mohua Banerjee等利用集理论获得初始规则集,然后,构造对应的模糊多层神经网络(规则的置信度对应网络的连接权)[10],训练后可得到精化的知识.粗集与其它软计算方法的集成是数据挖掘的一种趋势.目前,基于粗集的数据挖掘在以下方面有待深化.(1)粗集和其它软计算方法的进一步结合问题;(2)粗集知识采掘的递增算法;(3)粗集基本运算的并行算法及硬件实现,将大幅度改善数据挖掘的效率.已有的粗集软件适用范围还很有限.决策表中的实例数量和属性数量受限制.面对大量的数据,有必要设计高效的启发式简化算法或研究实时性较好的并行算法;(4)扩大处理属性的类型范围,实际数据库的属性类型是多样的,既有离散属性,也有连续属性;既有字符属性,也有数值属性.粗集理论只能处理离散属性,因此,需要设计连续值的离散算法.115 遗传算法遗传算法(G A:genetic algorithms)是模拟生物进化过程,利用复制(选择)、交叉(重组)和变异(突变)3个基本算子优化求解的技术.遗传算法类似统计学,模型的形式必须预先确定,在算法实施的过程中,首先对求解的问题进行编码,产生初始群体,然后计算个体的适应度,再进行染色体的复制、交换、突变等操作,优胜劣汰,适者生存,直到最佳方案出现为止.遗传算法在执行过程中,每一代都有许多不同的种群个体同时存在,这些染色体中个体的保留与否取决于它们对环境的适应能力,适应性强的有更多的机会保留下来,适应性强弱是由计算适应性函数f (x)的值决定的,这个值称为适应值(fitness).适应函数f(x)的构成与目标函数有密切的关系,这个函数基本上是目标函数的变种.应用遗传算法解决实际问题,存在以下几方面的问题:(1)编码.把问题参数按某种形式进行编码形成个体,一组个体构成一个种群,编码是一项有创造性的工作,也是遗传算法应用的关键.(2)适应值函数.适应值是对种群中每个个体的评价.它涉及到的问题包括:问题的目标函数的确定、目标函数到适应值函数的映射、适应值函数调整等.(3)交叉.以一定概率P c,对两个个体进行交叉.好的交叉策略能够使种群迅速收敛到最优解.(4)变异.以一定概率P c,对个体上的某种基因(对应于位串上的某位)进行改变.变异是使当前种群进化的必不可少的条件.遗传算法的研究方向遗传算法是多学科结合与渗透的产物,它已发展成为一种自组织、自适应的综合技术,广泛应用在计算机科学、工程技术和社会科学等领域[11].它的研究工作主要集中在以下几个方面:(1)基础理论.包括进一步发展遗传算法理论的数学基础,从理论和试验方面研究它们的计算复杂性.怎样阻止过早收敛也是人们正在研究的问题之一.(2)分布并行遗传算法.遗传算法在操作上具有高度的并行性,许多研究人员都在探索在并行机和分布式系统上高效执行遗传算法的策略.(3)分类系统.分类系统是基于遗传算法的机器学习中的一类,它包括一个简单的基于串规则的并行生成子系统、规则评价子系统和遗传算法子系统.分类系统正在被人们越来越多地应用于科学、工程和经济领域中,是目前遗传算法研究领域中一个非常活跃的领域[12].(4)遗传神经网络.它包括联接权、网络结构和学习规则的进化.遗传算法与神经网络相结合,成功地从时间序列分析来进行财政预算.Muhienbein 分析了多层感知机网络的局限性,并预测下一代神经网络将会是遗传神经网络.(5)进化算法.模拟自然进化过程可以产生鲁棒的计算机算法———进化算法.除上述方法外,还有把数据与结果转化和表达成可视化形式的可视化技术、统计分析方法、云模型方法和归纳逻辑程序等方法[13].2 结语 数据挖掘算法是对上述挖掘方法的具体体现.数据挖掘研究具有广泛的应用前景,它既可应用于决策支持,也可应用于数据库管理系统(DBMS )中.数据挖掘作为决策支持和分析的工具,可以用于构造知识库,在DBMS 中,数据挖掘可以用于语义查询优化、完整性约束和不一致检验.参 考 文 献 [1]Han J ,K ambr M.Data Mining :Concepts and Techniques 〔M 〕.Beijing Higher Education Press ,2001. [2] 张 伟,廖晓峰,吴中福1一种基于遗传算法的聚类新方法〔J 〕1计算机科学,2002,29(6):114-1161 [3]Agrawal R ,Mannila H ,Srikant R ,et al.Fast discovery of association rules :Advances in knowledge discovery and data mining 〔M 〕.California :MIT Press ,1996:307-328. [4]Sanjay Soni Unisys ,Zhaohui Tang Microsoft Corporation ,Jim Y ang Microsoft Corporation Performance Study of Microsoft Data Mining Algorithms August ,2001. [5] 唐华松,姚耀文1数据挖掘中决策树算法的探讨〔J 〕1计算机应用研究,2001,(8):18-221 [6] 李德仁,王树良,李德毅,王新洲1论空间数据挖掘和知识发现的理论与方法〔J 〕1武汉大学学报・信息科学版,2002(6):221-2331 [7] 周志华,陈世福1神经网络集成〔J 〕1计算机学报,2002(6):587-5901 [8] 李永敏,朱善君等1基于粗糙理论的数据挖掘模型〔J 〕1清华大学学报(自然科学版),1999,39(1):110-1131 [9]Pawlak Z.Rough Set Theory and its Applications to Data Analysi 〔J 〕.Cybernetics and syst ,1998,29(7):661-688. [10]Tsumoto S.Automated discovery of positive and negative knowledge in clinical database based on rough set model 〔J 〕.IEEE EMB Mag 2azine ,2000,19(4):415-422. [11] 糜元根1数据挖掘方法的评述〔J 〕1南京化工大学学报,2001(9):105-1091 [12] 吉根林,帅 克,孙志辉1数据挖掘技术及其应用〔J 〕1南京师大学报(自然科学版),2000,23(2):25-271 [13] 李德毅,史雪梅,孟海军1隶属云和隶属云发生器〔J 〕1计算机研究与发展,1995,42(8):32-411Summary of Data Mining MethodsGUO Xiu 2juan(Depart ment of Com puter Engineering ,Jilin A rchitectural and Civil Engineering Institute ,Changchun 130021)Abstract :The good methods and technologies of data mining may get excellent knowledge.This paper presents an overview on data mining methods.First ,the concept of data mining is discussed.Then ,this paper de 2scribes the theories and technologies on data mining ,such as relational rules ,decision tree ,neural network ,rough sets ,clustering analysis ,genetic algorithms ,and statistics analysis.Finally ,how to study data mining is forecasted.K eyw ords :data mining ;mining tools ;mining methods ;data mining theories 35 第1期郭秀娟:数据挖掘方法综述。
医学大数据挖掘与分析技术研究
医学大数据挖掘与分析技术研究一、引言随着医学信息的数字化进程迅速发展,医学大数据成为了医学研究中的宝贵资源。
然而,医学大数据面临着海量、复杂、多源等挑战,如何快速、准确地从中发现有价值的信息成为了亟待解决的问题。
医学大数据挖掘与分析技术应运而生,成为解决这一问题的有效手段。
本文将从医学大数据挖掘与分析技术的主要内容、应用领域等方面进行介绍和探讨。
二、医学大数据挖掘技术1. 数据预处理医学大数据往往存在着缺失值、异常值以及噪声等问题,数据预处理是挖掘和分析的前提。
常见的数据预处理方法包括数据清洗、数据集成、数据变换和数据规约等。
2. 数据挖掘算法医学数据中蕴含着大量的潜在知识,通过数据挖掘算法可以将这些知识挖掘出来。
常见的数据挖掘算法包括分类、聚类、关联规则挖掘等。
3. 特征提取与选择医学数据通常具有高维度的特点,特征提取与选择的目标是降低数据维度并减少冗余信息。
主成分分析、奇异值分解等方法可以帮助提取有效特征。
三、医学大数据分析技术1. 数据可视化数据可视化是将医学大数据转化为可视化的图表、图像等形式展示,有助于医务人员直观理解数据。
常见的数据可视化工具包括数据图表、热力图、散点图等。
2. 数据挖掘建模通过构建合适的模型可以对医学大数据进行预测和分析。
常用的建模方法包括逻辑回归、支持向量机、神经网络等。
3. 生物信息学分析生物信息学是医学大数据分析的重要组成部分,主要应用于研究基因、蛋白质、代谢物等分子水平的信息。
通过生物信息学分析,可以揭示疾病的发生机制、寻找治疗靶点等。
四、医学大数据挖掘与分析技术的应用领域1. 疾病诊断与预测医学大数据挖掘与分析技术可以挖掘患者病历、医学影像等数据,辅助医生进行疾病诊断和预测。
通过分析大量病例数据,可以发现潜在的疾病规律和特点,提高诊断的准确性。
2. 药物研发与个体化治疗医学大数据挖掘与分析技术可以帮助科学家分析大量的临床试验数据、基因组数据等,加速药物研发过程,同时为个体化治疗提供依据。
医学大数据的挖掘和应用
医学大数据的挖掘和应用近年来,医学界出现了一股“数据革命”。
随着医疗健康信息化建设的不断推进,数据已经成为医学研究与临床实践的重要支撑。
医学大数据量大、种类繁多,包括基因组数据、影像学数据、临床数据以及社会经济数据等多维度信息,有效挖掘和应用这些数据,对提升疾病预防、诊断、治疗等方面具有重要意义。
一、医学大数据的挖掘1.数据获取医学大数据的挖掘首先需要获取有效数据。
医学数据的来源包括基因组数据库、病例数据库、影像数据库和生命体征数据库等。
常见的基因组数据库包括NCBI、ENSEMBL、UCSC Genome Browser等;病例数据库常见的有MIMIC、COPDGene、TCGA等;影像数据库包括ImageNet、LIDC-IDRI、ADNI等;生命体征数据库包括国内的虚拟生命体征数据库以及国外的PhysioNet、NHANES等。
2.数据清洗数据清洗是医学大数据挖掘的第一步,它涉及到诸如数据预处理、数据去噪、数据标准化等数据清理工作。
在数据清理的过程中,需要使用各种数据分析、挖掘、可视化工具来辅助分析。
3.数据建模数据建模不仅是医学生物信息学研究的关键步骤,也是数据挖掘的重要环节之一。
数据建模的主要目的是为了使数据模型更加完整、准确,从而达到更好的数据挖掘效果。
4.知识挖掘知识挖掘是利用数据挖掘技术去挖掘隐含于数据背后的知识。
利用数据挖掘技术,我们可以从大数据中提取出某些特定的模式、规律等,这些模式、规律和知识可以帮助我们对医学数据进行分析和推断。
二、医学大数据的应用1.疾病预测与分析医学大数据能够从多方面帮助医生和研究者进行疾病预测和分析。
利用机器学习等技术,我们可以通过大数据拟合出疾病预测模型,不仅可以预测疾病发生的可能性,还可以预测疾病萎缩的趋势。
此外,针对某些难以诊断的疾病,我们也可以通过大数据对其进行分析,提供有力的参考依据。
2.精准医疗精准医疗是医学领域的一个新兴概念,它旨在根据个体的基因信息、环境信息、生活方式等因素,量身定制个性化的医学方案,改进传统的临床诊疗模式。
数据挖掘技术在医学大数据中的使用方法
数据挖掘技术在医学大数据中的使用方法随着医疗技术的进步和电子记录系统的普及,医学界积累了大量的医学数据。
这些数据可以是来自医院记录的电子病历、医疗保险数据、医学图像、基因组数据等,这些数据都被称为医学大数据。
然而,由于数据量庞大、复杂性高和数据之间的关联性,如何从这些海量的医学大数据中提取有用的信息,对于医学研究和临床实践来说是一个巨大的挑战。
数据挖掘技术则是一种常用的方法,用于从医学大数据中发掘知识和信息。
数据挖掘技术是一种利用计算机算法来发现大规模数据集中存在的隐藏模式和关联关系的过程。
在医学大数据中,数据挖掘技术可以被广泛应用于多个领域,包括疾病预测、错诊检测、治疗方案优化等。
下面将介绍一些常见的数据挖掘技术在医学大数据中的使用方法。
首先,决策树是一种常用的数据挖掘技术。
它通过构建一棵树来表示不同特征之间的关联关系,并根据这些关系来进行分类或预测。
在医学大数据中,决策树可以被用于诊断疾病。
通过分析病人的病历数据和症状信息,决策树可以帮助医生快速判断病人所患疾病的可能性,从而提供更准确的诊断。
其次,聚类分析是另一种常见的数据挖掘技术。
聚类分析通过将相似的数据点分为一组来发现数据中的相似性和不相似性。
在医学大数据中,聚类分析可以用于发现疾病之间的关联性。
例如,通过对基因组数据进行聚类分析,可以发现一些疾病之间共享的基因变异,从而为疾病的病因研究提供线索。
另外,关联规则挖掘是以寻找项集之间的关联为目标的数据挖掘技术。
在医学大数据中,关联规则挖掘可以用于发现疾病之间的相关因素。
例如,通过分析大量的医学数据,可以发现某些疾病与特定基因变异之间存在相关性,或者某些疾病与特定环境因素之间存在相关性。
这些关联规则的发现可以为医学研究和临床实践提供重要的参考依据。
此外,序列模式挖掘是一种用于医学大数据中的时间序列数据的数据挖掘技术。
在医学领域,许多数据都具有时间顺序性,如病人的体温数据、心电图数据等。
通过序列模式挖掘,可以发现这些时间序列数据中的模式和规律。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
37
STATA该软件是美国Computer Resource Center 研 制的统计软件,目前的12、13版本就可以实现数据 挖掘。 SAS for windows:国际权威的统计软件,有专门 的数据挖掘模块。 SPSS for Windows :该软件是一个统计专用软件 ,界面很友好。在19.0之前的版本需要加专门的 Clementine模块;19.0之后版本因有modeler,可 直接做。
模拟式存量
2000年
数字式存量
Source: Researchers at the University of Southern California took four years -- 1986, 1993, 2000 and 2007 -- and extrapolated numbers from roughly 1,100 sources of information. Credit: Todd Lindeman and Brian Vastag/ The Washington Post
x x 1 x ,2 x ,...,l x
T
代替输入向量x,
则可以得到最优分类函数为: l f x sgn w x b sgn ai yi xi x b i 1
20
20
Monte Carlo模拟分析结果
纹理相关系数为0.1时,840个纹理值各 预测模型拟合结果
21
纹理相关系数为0.2时, 840个纹理值 各预测模型拟合结果
21
支持向量机
支持向量机(Support Vector Machine, SVM)是美国Vapnik 教授 于1963年提出的。
在解决小样本、非线性和高维 模式识别问题中表现出许多优势, 并在一定程度上克服了“维数灾难” 和“过学习”等问题。在模式识别、 回归分析、函数估计、时间序列预 测等领域,都得到了长足的发展。
4. 综合法:合并轴状位、冠状位、矢状位数据集,建立一个 预测模型,其结果作为最终结果。
27
病例基本信息分析结果
良恶性病例人口学特征分析
良性 性别 N(Missing) 女性 n(%) 男性 n(%) 年龄 N(Missing) Mean(Std) 84(0) 50(59.52) 34(40.48) 84(0) 54.10(13.57) 恶性 252(0) 150(59.52) 102(40.48) 252(0) 59.90(12.68) 61(53~69.5) 25~83 3.45(秩和检验) 0.0006 统计值 0(卡方检验) P值 1.0000
3
在R的官方网址上,选择网站镜像 /mirrors.html
33
R软件
R Console: 运行过程 提示错误等
R编辑器: 编辑程序 选择运行
/
34
支持向量机R语言实现
library(kernlab) /加载支持向量机程序包/ setwd(“D:\\ku”) /设置当前数据库路径/ datayuce=read.csv(“a.csv”,header=T)/导入预测集数据/ dataxunlian=read.csv(“b.csv”,header=T) )/导入训练集数据/ svmModel <- ksvm(as.matrix(dataxunlian[1:5]), as.factor(dataxunlian$x), type=“C-svc”,kernel=“rbfdot”,C=10,cross=4) )/核函数选择/ pre=predict(svmModel,datayuce[1:5]) write.csv(data.frame(pre,class=datayuce$x, zu=datayuce$no),file="result.csv") )/输出结果到result.csv / table(pre,class=datayuce$x) /结果整理/
数据量规模巨大到无法通过人工,在合理时间
内达到截取、管理、处理、并整理成为人类所能解读
的信息。
Velocity 出现和更新速度快 时效性高
Value
潜在价值大 密度低 提纯难度大
Volume
数据容量巨大: TB到PB级别 Variety 数据类型繁多: 图片、视频等
4
大数据时代的来临
•2000年以前大部分数据是analog data (模拟式数据) 以书、报纸、录像带等存储。特点:数据量较小。 •2000年以后digital data (数字式数据)大大增加 以CD、DVD、硬盘等存储。特点:数据量巨大。
定义研究问题 数据准备
大数据源 模型应用
提取数据
建立模型
模型评估 14
14
数据挖掘方法概述
分类回归树
朴素贝叶斯
神经网络分类 支持向量机 回归组合模型 支持向量机回归
分类预测
决策树 随机森林
回归预测
神经网络回归 广义线性回归 K均值聚类 期望最大化EM 属性关联分析 LASSO 高维数据降维
数据挖掘
01基本信息
年龄、性别等
02 既往史
肿瘤病史 粉尘接触史 遗传病史 吸烟史等
04 CT图像 纹理
高维大数据库 (变量约1000, 样本336例) 轴位纹理 冠状位纹理 矢状位纹理
03 影像学 检查
淋巴结是否肿大 边缘是否光滑 是否分叶 结节位置 有无空泡征等
18
数据挖掘主要分类预测方法
医学大数据分析策略与数据挖掘
讲座人:郭秀花 博士生导师 guoxiuh@ 单 位:首都医科大学 日 期:2014年11月22日
1
提纲
1 2 3 中心概况 医学大数据及其分析策略
数据挖掘方法简介及其应用 中心概况 数据挖掘软件及其实现方法
2
医学大数据及其分析策略
3
大数据(Big Data)
38
基于大数据进行数据挖掘,采用 大型服务器可以提高运行速度。
39
40
41
9
在生物医学研究领域,大数据:
环境气象学数据 医学影像数据 基因、蛋白等组学数据 大型临床资料 复杂的生物和环境因素研究
生物医学大数据的只要特点:高维
10
科学问题处理方式
11
常用的医学多元统计学应用受到制约
多元线性回归分析 Logistic回归分析 Cox回归分析 聚类分析 判别分析 主成分分析 因子分析 广义线性模型 ......
基于肺结节纹理 鉴别诊断肺癌
支持向量机 决策树
随机森林 最近邻分类 神经网络 Gradient Lasso回归 boosting
19
19
Monte Carlo模拟分析结果
各纹理产生30,40,50,60个子代(即纹理分别 为420,560,700,840个)。每个纹理子代分布 为正态分布,均值和标准差与轴位CT图像均值相 近; 设定每个纹理内部子代之间的相关系数为r=0.1, 0.2,0.3,0.4; 分别产生2组数据,设定两组各个变量均值之间 的差值为d(0.01-0.1)。
Median(Q1~Q3) 57(46.5~63) Min~Max 21~80
不同评价方法支持向量机预测模型结果
29
利用病例人口学特征、环境遗传信息和结节形态
学信息等综合性信息,建立支持向量机预测模型。
基于人口学、环境遗传和结节形态学信息建立预测模型结果
结论:
基于三正交位CT图像,结合多方面信息,采用大数据支
方 法
正态性 线性、齐性 独立性 足够大的样本量 变量的20倍 ......
条 件
传统的多元统计方法难以处理和分析医学大数据
高维、非线性、非高斯等数据,采用数据挖掘方法,可以
提供更高的预测精度。
12
数据挖掘方法简介及其应用
13
数据挖掘概念
数据挖掘:是在从大量的数据中提取隐含的、 事先未知的,但又是潜在有用的信息和知识的过程。
持向量机分类分类预测方法,可以有效提高肺癌诊断正确率,
辅助放射科医生进行辅助诊断肺癌。
数据挖掘软件及其实现方法
32
R软件
1
R是统计领域广泛使用的诞生于1980年 左右的S语言的一个分支。
Your text
2
R是一个有着统计分析功能及强大作图功能的 软件系统,是由奥克兰大学统计学系的Ross Ihaka和Robert Gentleman共同创立。
Vapnik
22
最优分类(超平)面
SVM的机理是寻找一个满足分类要求的最优分类 超平面 w x b 0 ,使得该超平面在保证分类精 度的同时,能够使超平面两侧的空白区域最大化。
23
广义最优分类面
-
24
当线性不可分时,SVM的主要思想是将输人向量映 射到一个高维的特征向量空间,并在该特征空间中 构造最优分类面。
35
支持向量机
36
• WEKA(Waikato Environment for Knowledge Analysis)
WEKA作为一个公开的数 据挖掘工作平台,用于非商 业目的的研究行为,集合了 大量能承担数据挖掘任务的 机器学习算法,包括对数据 进行预处理,分类、回归、 聚类、关联规则以及在新的 交互式界面上的可视化。
Laplacian 核函数
Bessel核函数
26
预测模型不同判别方法结果
1. 投票法:选取多数类结果(例如:2个或者2个以上预测模 型结果为恶性)作为最后病例的预测结果; 2. 并联法:只要有一个预测模型结果判断为恶性,此病人最 终判断为恶性结果,否则为良性;
3. 串联法:只有3个预测模型同时判断为恶性,此病人最终判 断为恶性结果,否则为良性;