常用回归模型
常用回归模型
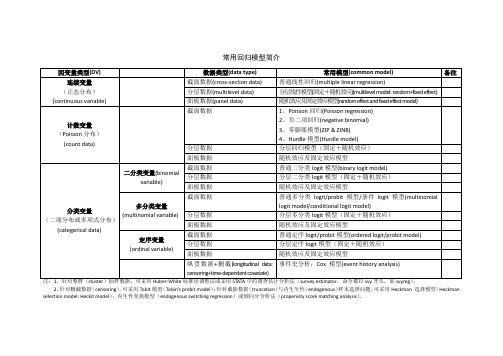
分层数据
2、负二项回归(negative binomial) 3、零膨胀模型(ZIP & ZINB) 4、Hurdle 模型(Hurdle model) 分层回归模型(固定+随机效应)
面板数据
随机效应及固定效应模型
二分类变量(binomial variable)
截面数据 分层数据 面板数据
普通二分类 logit 模型(binary logit model) 分层二分类 logit 模型(固定+随机效应) 随机效应及固定效应模型
截面数据
普通多分类 logit/probit 模型/条件 logit 模型(multinomial
多分类变量 分类变量 (二项分布或多项式分布) (multinomial variable) (categorical data)
定序变量 (ordinal variable)
分层数据 面板数据+删截(longitudinal data: 事件史分析:Cox 模型(event history analysis)
censoring+time-dependent covariate)
注:1、针对整群(cluster)抽样数据,可采用 Huber-White 标准误调整法或采用 STATA 中的调查估计分析法(survey estimator,命令都以 svy 开头,如 svyreg)。 2、针对删截数据(censoring),可采用 Tobit 模型(Tobin’s probit model);针对截除数据(truncation)与内生生性(endogenous)样本选择问题,可采用 Heckman 选择模型(Heckman
计量经济学--几种常用的回归模型课件

计量经济学--几种常用的回归模型
18
• 半对数模型的斜率系数度量了解释变量一个单位 的绝对变化,对应的因变量的相对变化量。
• P166例6.4
计量经济学--几种常用的回归模型
19
对数到线性模型(解释变量对数形式)
计量经济学--几种常用的回归模型
20
Yi 1 2 ln X i i
计量经济学--几种常用的回归模型
9
半对数模型
• 只有一个变量以对数形式出现
计量经济学--几种常用的回归模型
10
2. 半对数模型
• 线性到对数模型(因变量对数形式) • 对数到线性模型(解释变量对数形式)
计量经济学--几种常用的回归模型
11
• 线性到对数模型(因变量对数形式)
计量经济学--几种常用的回归模型
12
Yt Y0(1 r )t
ln Yi 2 ln X i i
计量经济学--几种常用的回归模型
4
2的含义?
• 其测度了Y对X的弹性,即X变动百分之一引起Y变 动的百分数。
• 例如,Y为某一商品的需求量,X为该商品的价格, 那么斜率系数为需求的价格弹性。
计量经济学--几种常用的回归模型
5
证明:
d(ln Y ) dY Y 2 d(ln X ) dX X
计量经济学--几种常用的回归模型
8
ห้องสมุดไป่ตู้意
• 是产出对资本投入的(偏)弹性,度量
在保持劳动力投入不变的情况下资本投入 变化1%时的产出变动百分比;
• 是产出对劳动投入的(偏)弹性,度量
在保持资本投入不变的情况下劳动力投入 变化1%时的产出变动百分比;
• 给出了规模报酬信息
十大数据分析模型详解

十大数据分析模型详解数据分析模型是指用于处理和分析数据的一种工具或方法。
下面将详细介绍十大数据分析模型:1.线性回归模型:线性回归模型是一种用于预测数值型数据的常见模型。
它基于变量之间的线性关系建立模型,然后通过拟合这个模型来进行预测。
2.逻辑回归模型:逻辑回归模型与线性回归模型类似,但应用于分类问题。
它通过将线性模型映射到一个S形曲线来进行分类预测。
3.决策树模型:决策树模型是一种基于树结构的分类与回归方法。
它将数据集划分为一系列的决策节点,每个节点代表一个特征变量,根据特征变量的取值选择下一个节点。
4.随机森林模型:随机森林模型是一种集成学习的方法,通过建立多个决策树模型来进行分类与回归分析。
它通过特征的随机选择和取样来增加模型的多样性和准确性。
5.支持向量机模型:支持向量机模型是一种用于分类和回归分析的模型。
其核心思想是通过找到一个最优的分割超平面,使不同类别的数据点之间的间隔最大化。
6.主成分分析:主成分分析是一种常用的数据降维方法,用于减少特征维度和提取最重要的信息。
它通过找到一组新的变量,称为主成分,这些主成分是原始数据中变量的线性组合。
7.聚类分析:聚类分析是一种无监督学习方法,用于对数据进行分类和分组。
它通过度量样本之间的相似性,将相似的样本归到同一类别或簇中。
8.关联规则挖掘:关联规则挖掘是一种挖掘数据集中的频繁项集和关联规则的方法。
它用于发现数据集中的频繁项集,并根据频繁项集生成关联规则。
9.神经网络模型:神经网络模型是一种模拟人脑神经网络结构和功能的机器学习模型。
它通过建立多层的神经元网络来进行预测和分类。
10.贝叶斯网络模型:贝叶斯网络模型是一种基于概率模型的图论模型,用于表示变量之间的条件依赖关系。
它通过计算变量之间的概率关系来进行推理和预测。
以上是十大数据分析模型的详细介绍。
这些模型在实际应用中具有不同的优势和适用范围,可以根据具体的问题和数据情况选择合适的模型进行分析和预测。
非线性回归分析常见模型

非线性回归常见模型一.基本内容模型一xc e c y 21=,其中21,c c 为常数.将xc ec y 21=两边取对数,得x c c e c y xc 211ln )ln(ln 2+==,令21,ln ,ln c b c a y z ===,从而得到z 与x 的线性经验回归方程a bx z +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型二221c x c y +=,其中21,c c 为常数.令a c b c x t ===212,,,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型三21c x c y +=,其中21,c c 为常数.a cbc x t ===21,,,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型四反比例函数模型:1y a b x=+令xt 1=,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型五三角函数模型:sin y a b x=+令x t sin =,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.二.例题分析例1.用模型e kx y a =拟合一组数据组()(),1,2,,7i i x y i =⋅⋅⋅,其中1277x x x ++⋅⋅⋅+=;设ln z y =,得变换后的线性回归方程为ˆ4zx =+,则127y y y ⋅⋅⋅=()A.70e B.70C.35e D.35【解析】因为1277x x x ++⋅⋅⋅+=,所以1x =,45z x =+=,即()127127ln ...ln ln ...ln 577y y y y y y +++==,所以35127e y y y ⋅⋅⋅=.故选:C例2.一只红铃虫产卵数y 和温度x 有关,现测得一组数据()(),1,2,,10i i x y i =⋅⋅⋅,可用模型21e c x y c =拟合,设ln z y =,其变换后的线性回归方程为4zbx =- ,若1210300x x x ++⋅⋅⋅+=,501210e y y y ⋅⋅⋅=,e 为自然常数,则12c c =________.【解析】21e c x y c =经过ln z y =变换后,得到21ln ln z y c x c ==+,根据题意1ln 4c =-,故41e c -=,又1210300x x x ++⋅⋅⋅+=,故30x =,5012101210e ln ln ln 50y y y y y y ⋅⋅⋅=⇒++⋅⋅⋅+=,故5z =,于是回归方程为4zbx =- 一定经过(30,5),故ˆ3045b -=,解得ˆ0.3b =,即20.3c =,于是12c c =40.3e -.故答案为:40.3e -.该景点为了预测2023年的旅游人数,建立了模型①:由最小二乘法公式求得的数据如下表所示,并根据数据绘制了如图所示的散点图.。
各种线性回归模型原理

各种线性回归模型原理线性回归是一种广泛应用于统计学和机器学习领域的方法,用于建立自变量和因变量之间线性关系的模型。
在这里,我将介绍一些常见的线性回归模型及其原理。
1. 简单线性回归模型(Simple Linear Regression)简单线性回归模型是最简单的线性回归模型,用来描述一个自变量和一个因变量之间的线性关系。
模型方程为:Y=α+βX+ε其中,Y是因变量,X是自变量,α是截距,β是斜率,ε是误差。
模型的目标是找到最优的α和β,使得模型的残差平方和最小。
这可以通过最小二乘法来实现,即求解最小化残差平方和的估计值。
2. 多元线性回归模型(Multiple Linear Regression)多元线性回归模型是简单线性回归模型的扩展,用来描述多个自变量和一个因变量之间的线性关系。
模型方程为:Y=α+β1X1+β2X2+...+βnXn+ε其中,Y是因变量,X1,X2,...,Xn是自变量,α是截距,β1,β2,...,βn是自变量的系数,ε是误差。
多元线性回归模型的参数估计同样可以通过最小二乘法来实现,找到使残差平方和最小的系数估计值。
3. 岭回归(Ridge Regression)岭回归是一种用于处理多重共线性问题的线性回归方法。
在多元线性回归中,如果自变量之间存在高度相关性,会导致参数估计不稳定性。
岭回归加入一个正则化项,通过调节正则化参数λ来调整模型的复杂度,从而降低模型的过拟合风险。
模型方程为:Y=α+β1X1+β2X2+...+βnXn+ε+λ∑βi^2其中,λ是正则化参数,∑βi^2是所有参数的平方和。
岭回归通过最小化残差平方和和正则化项之和来估计参数。
当λ=0时,岭回归变为多元线性回归,当λ→∞时,参数估计值将趋近于0。
4. Lasso回归(Lasso Regression)Lasso回归是另一种用于处理多重共线性问题的线性回归方法,与岭回归不同的是,Lasso回归使用L1正则化,可以使得一些参数估计为0,从而实现特征选择。
统计学多模型

在统计学中,有多种模型可以用于分析和处理数据。
以下是一些常见的统计学模型:
1. 线性回归模型:用于研究自变量与因变量之间的线性关系。
2. 逻辑回归模型:常用于分类问题,预测二分类或多分类的结果。
3. 方差分析(ANOVA):用于比较多个组之间的差异。
4. 聚类分析:将数据对象分组或聚类,使相似的对象归为一组。
5. 时间序列模型:用于分析随时间变化的数据趋势和周期性。
6. 面板数据模型:适用于处理具有多个时间点和多个个体的数据。
7. 主成分分析(PCA):用于降低数据维度和提取主要特征。
8. 因子分析:探索变量之间的潜在结构和因子。
9. 生存分析:用于研究事件发生时间的数据,如病人的生存时间。
10. 混合效应模型:考虑到数据中的层次结构或随机效应。
11. 贝叶斯模型:基于贝叶斯定理进行概率推断和预测。
12. 机器学习模型:如决策树、随机森林、支持向量机等,用于分类、回归和预测。
这只是一小部分常见的统计学模型,实际应用中根据问题的性质和数据的特点,可以选择合适的模型进行分析。
不同的模型有其适用的场景和限制,模型的选择和应用需要结合具体问题和数据进行判断。
同时,在使用模型时,还需要进行模型评估和验证,以确保模型的准确性和可靠性。
回归模型介绍

回归模型介绍回归模型是统计学和机器学习中常用的一种建模方法,用于研究自变量(或特征)与因变量之间的关系。
回归分析旨在预测或解释因变量的值,以及评估自变量与因变量之间的相关性。
以下是回归模型的介绍:•线性回归(Linear Regression): 线性回归是最简单的回归模型之一,用于建立自变量和因变量之间的线性关系。
简单线性回归涉及到一个自变量和一个因变量,而多元线性回归包含多个自变量。
线性回归模型的目标是找到一条最佳拟合直线或超平面,使得预测值与实际观测值的误差最小。
模型的形式可以表示为:Y=b0+b1X1+b2X2+⋯+b p X p+ε其中,Y是因变量, X1,X2,…X p 是自变量,b0,b1,…,b p 是回归系数,ε是误差项。
•逻辑回归(Logistic Regression): 逻辑回归是用于处理分类问题的回归模型,它基于逻辑函数(也称为S形函数)将线性组合的值映射到概率范围内。
逻辑回归常用于二元分类问题,例如预测是否发生某个事件(0或1)。
模型的输出是一个概率值,通常用于判断一个样本属于某一类的概率。
逻辑回归的模型形式为:P(Y=1)=11+e b0+b1X1+b2X2+⋯+b p X p其中P(Y=1)是事件发生的概率,b0,b1,…,b p是回归系数,X1,X2,…X p是自变量。
•多项式回归(Polynomial Regression): 多项式回归是线性回归的扩展,允许模型包括自变量的高次项,以适应非线性关系。
通过引入多项式特征,可以更灵活地拟合数据,但也可能导致过拟合问题。
模型形式可以表示为:Y=b0+b1X+b2X2+⋯+b p X p+ε其中,X是自变量,X2,X3,…,X p是其高次项。
•岭回归(Ridge Regression)和Lasso回归(Lasso Regression): 岭回归和Lasso 回归是用于解决多重共线性问题的回归技术。
这些方法引入了正则化项,以减小回归系数的大小,防止模型过度拟合。
机器学习中的五种回归模型及其优缺点

机器学习中的五种回归模型及其优缺点1.线性回归模型:线性回归模型是最简单和最常用的回归模型之一、它通过利用已知的自变量和因变量之间的线性关系来预测未知数据的值。
线性回归模型旨在找到自变量与因变量之间的最佳拟合直线。
优点是简单易于实现和理解,计算效率高。
缺点是假设自变量和因变量之间为线性关系,对于非线性关系拟合效果较差。
2.多项式回归模型:多项式回归模型通过添加自变量的多项式项来拟合非线性关系。
这意味着模型不再只考虑自变量和因变量之间的线性关系。
优点是可以更好地拟合非线性数据,适用于复杂问题。
缺点是容易过度拟合,需要选择合适的多项式次数。
3.支持向量回归模型:支持向量回归模型是一种非常强大的回归模型,它通过在数据空间中构造一个最优曲线来拟合数据。
支持向量回归模型着眼于找到一条曲线,使得在该曲线上离数据点最远的距离最小。
优点是可以很好地处理高维数据和非线性关系,对离群值不敏感。
缺点是模型复杂度高,计算成本也较高。
4.决策树回归模型:决策树回归模型将数据集划分为多个小的决策单元,并在每个决策单元中给出对应的回归值。
决策树由一系列节点和边组成,每个节点表示一个特征和一个分割点,边表示根据特征和分割点将数据集分配到下一个节点的规则。
优点是容易理解和解释,可处理离散和连续特征。
缺点是容易过度拟合,对噪声和离群值敏感。
5.随机森林回归模型:随机森林回归模型是一种集成学习模型,它基于多个决策树模型的预测结果进行回归。
随机森林通过对训练数据进行有放回的随机抽样来构建多个决策树,并利用每个决策树的预测结果进行最终的回归预测。
优点是可以处理高维数据和非线性关系,对噪声和离群值不敏感。
缺点是模型较为复杂,训练时间较长。
总之,每种回归模型都有其独特的优点和缺点。
选择适当的模型取决于数据的特点、问题的要求和计算资源的可用性。
在实际应用中,研究人员需要根据具体情况进行选择,并对模型进行评估和调整,以获得最佳的回归结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。