一个新的多分类器组合模型_蒋林波
基于Boosting的多分类器融合算法

1 H (x ) = ∑ log β t t
ht ( x, y )
图 1 Adaboost 算法(可信度版本)
3 手写体汉字识别系统
本文研究内容的测试平台为手写体汉字识别系统,该系统采用传统的统计模式识别与结 构模式识别相结合的方法, 建立了识别系统的信息传递模型。 同时该系统采用了多分支多级 分类技术, 解决了多级分类过程中误差累积的问题, 整个识别过程分为笔段识别-字根识别字根识别三个层次,其基本原理图如图 2。 本系统在笔段排序和部件分析识别中采用的知识是一种专家知识,表示形式是一条条的 规则。在整字识别中采用的模板也是基于专家知识确定的,因而具有知识表达精炼、内存开 销少、识别效果好、识别速度快等优点。 此外,本系统中采用了三个不同的分类器:基于结构的分类器( e1 ), 动态规划分类器 ( e 2 )和高斯分类器( e3 )。 最终输出的分类器(E1)为这些单个分类器经 Adaboost 算法融合而 得到。
Z t = ∑ Dt (i )(β t y i ht ( xi ))
i
(2)
从(1)和(2)中可以看出,在每一次循环中,通过选择 log 1 / β t 和 ht 可以减小 Z t ,
2
从而使训练错误快速地降低,同时训练错误是呈指数下降。
给定: ( x1 , y1 ), K , ( x m , y m ) 其中, xi ∈ X , y i ∈ Y = { 1, K , k } 初始化: Dt (i ) = 1 / m For t = 1, K , T : 1. 利用权值 Dt (i ) 训练弱学习算法。 2. 得到弱假设 ht : X × Y → [0,1] 3. 计算 ht 的误差:
ht : X × Y → [0,1] ,然后,尽量减小其错误率( et ): et = Pi ~ Dt [ht ( xi ) ≠ y i ] 。一旦确定了
2023年人工智能现代科技知识考试题与答案

2023年《人工智能》现代科技知识考试题与答案目录简介一、单选题:共40题二、多选题:共20题三、判断题:共26题一、单选题1、下列哪部分不是专家系统的组成部分?A .用户B.综合数据库C.推理机D.知识库正确答案:A解析:《人工智能导论》(第4版)作者:王万良出版社: 高等教育出版社2、下列哪个神经网络结构会发生权重共享?A.卷积神经网络B.循环神经网络C.全连接神经网络D. A 和B正确答案:D解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社3、下列哪个不属于常用的文本分类的特征选择算法?A.卡方检验值B.互信息C .信息增益D.主成分分析正确答案:D解析:《自然语言处理》作者:刘挺出版社:高等教育出版社4、下列哪个不是人工智能的技术应用领域?A.搜索技术B.数据挖掘C.智能控制D .编译原理解析:《走进人工智能》作者:周旺出版社:高等教育出版社5、Q(s,a)是指在给定状态s的情况下,采取行动a之后,后续的各个状态所能得到的回报()。
A.总和B.最大值C.最小值D.期望值正确答案:D解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社6、数据科学家可能会同时使用多个算法(模型)进行预测,并且最后把这些算法的结果集成起来进行最后的预测(集成学习),以下对集成学习说法正确的是()。
A.单个模型之间有高相关性B.单个模型之间有低相关性C,在集成学习中使用“平均权重”而不是“投票”会比较好D.单个模型都是用的一个算法解析:《机器学习方法》作者:李航出版社:清华大学出版社7、以下哪种技术对于减少数据集的维度会更好?A.删除缺少值太多的列B.删除数据差异较大的列C.删除不同数据趋势的列D.都不是正确答案:A解析:《机器学习》作者:周志华出版社:清华大学出版社8、在强化学习过程中,学习率越大,表示采用新的尝试得到的结果比例越(),保持旧的结果的比例越()。
A .大,小B.大,大C.小,大D.小,小正确答案:A解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社9、以下哪种方法不属于特征选择的标准方法?A.嵌入B.过滤C ,包装D.抽样正确答案:D解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社10、要想让机器具有智能,必须让机器具有知识。
人工智能导论第二章答案

人工智能导论第二章答案1、单选题:下列关于智能说法错误的是()选项:A:细菌不具有智能B:任何生命都拥有智能C:从生命的角度看,智能是生命适应自然界的基本能力D:目前,人类智能是自然只能的最高层次答案: 【细菌不具有智能】2、判断题:目前,智能的定义已经明确,其定义为:智能是个体能够主动适应环境或针对问题,获取信息并提炼和运用知识,理解和认识世界事物,采取合理可行的(意向性)策略和行动,解决问题并达到目标的综合能力。
()选项:A:错B:对答案: 【错】3、判断题:传统人工智能领域将人工智能划分为强人工智能与弱人工智能两大类。
所谓强人工智能指的就是达到人类智能水平的技术或机器,否则都属于弱人工智能技术。
()选项:A:错B:对答案: 【对】4、判断题:人类历史上第一个人工神经元模型为MP模型,由赫布提出。
()选项:A:对B:错答案: 【错】5、单选题:下列关于数据说法错误的是()选项:A:数据可以分为模拟数据和数字数据两类B:数据就是描述事物的符号记录,是可定义为有意义的实体C:我们通常所说的数据即能够直接作为计算机输入的数据是模拟数据D:在当今社会,数据的本质是生产资料和资产答案: 【我们通常所说的数据即能够直接作为计算机输入的数据是模拟数据】6、多选题:下列关于大数据的说法中正确的有()选项:A:大数据具有多样、高速的特征B:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产C:大数据带来的思维变革中,更多是指更多的随机样本D:“大数据时代”已经来临答案: 【大数据具有多样、高速的特征;“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产;“大数据时代”已经来临】7、判断题:大数据在政府公共服务、医疗服务、零售业、制造业、以及涉及个人位置服务等领域都将带来可观的价值。
()选项:A:对B:错答案: 【对】8、多选题:人工智能在各个方面都有广泛应用,其研究方向也众多,下面属于人工智能研究方向的有()选项:A:知识图谱B:模式识别C:语音识别D:机器学习答案: 【知识图谱;模式识别;语音识别;机器学习】9、判断题:机器人发展经历了程序控制机器人(第一代)、自适应机器人(第二代)、智能机器人(现代)三代发展历程。
基于遗传算法和模糊积分的多分类器集成

基于遗传算法和模糊积分的多分类器集成
姚明海;李澎林
【期刊名称】《计算机应用与软件》
【年(卷),期】2003(020)008
【摘要】多分类器联合是解决复杂模式识别问题的有效办法.模糊积分是其中一种多分类器联合方法.但是对于模糊积分,如何计算模糊积分密度是一个尚未解决的问题.本文提出了一种基于模糊积分和遗传算法的分类器集成方法,该方法利用遗传算法计算模糊积分密度函数,再利用模糊积分把分类器输出信息联合起来.实验结果表明,该方法比其他方法能够得到更好的识别性能.
【总页数】3页(P66-68)
【作者】姚明海;李澎林
【作者单位】浙江工业大学信息工程学院,杭州,310032;浙江工业大学信息工程学院,杭州,310032
【正文语种】中文
【中图分类】TP31
【相关文献】
1.基于模糊积分多分类器融合的JPEG图像隐写算法识别 [J], 李开达;张涛;李星
2.基于Sugeno模糊积分的多分类器融合方法在多属性决策中的应用 [J], 侯帅;韩中庚;黄洁;于俊杰
3.基于模糊积分的多分类器融合文本分类研究 [J], 邹晴;钮焱;李军
4.基于模糊积分和粒子群算法的多分类器融合 [J], 陈曦;赵志伟
5.基于多分类器多模糊积分的信息融合方法 [J], 段宝彬;孙梅兰
因版权原因,仅展示原文概要,查看原文内容请购买。
2014年宁波大学考博试题 3809智能系统 B
考试科目: 适用专业: 智能系统 移动计算与人机交互 科目代码: 3809
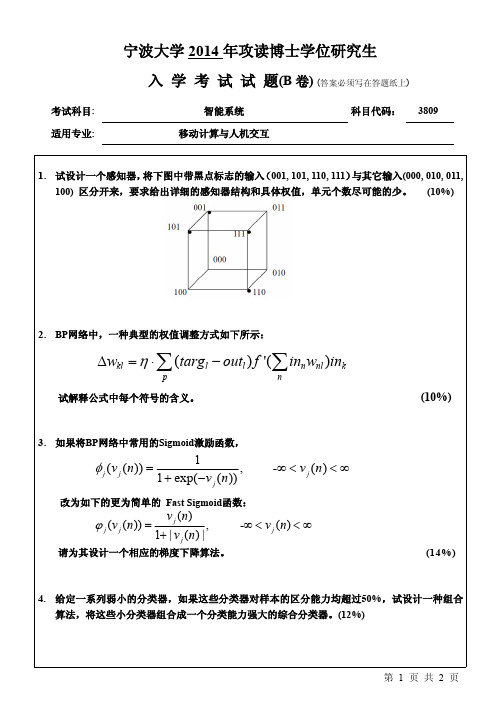
1. 试设计一个感知器, 将下图中带黑点标志的输入 (001, 101, 110, 111) 与其它输入(000, 010, 011, 100) 区分开来,要求给出详细的感知器结构和具体权值,单元个数尽可能的少。 (10%)
第 2 页 共 2 页
6. 当RBF网络的学习样本数较小,即学习样本数 N 小于 RBF单元个数 M 时,学习过程就转化 为精确的插值过程,请给出具体的权值确定方法;反之,当 N M 时,该方法将失效,为什 么?请给出新的权值学习方案。 (14%)
7.
对于 M 类(ω1,......,ωM )的分类问题,给定每一类的先验概率 P(ωi) 和类条件概率密度 p(x|ωi),如果先验概率和类条件概率均服从正态分布。 (14%) (1) 请给出基于最小错误率的Bayes分类决策。 (2) 假设将第j类样本分到第i类的损失为λij, 请用公式叙述基于最小风险点贝叶斯决策过程 ,说明在什么情况下最小风险决策等价于最小错误率决策。
第 1 页 共 2 页
宁波大学 2014 年攻读博士学位研究生 入 学 考 试 试 题(B 卷) (答案必须写在答题纸上)
考试科目: 适用专业: 智能系统 移动计算与人机交互 科目代码: 3809
5. 索引和散列函数在数据处理中的用途非常大。索引指单独的、物理的数据结构,一般就是指 向集合中不同值的逻辑指针,而散列函数可以把数据压缩成摘要,使得数据量变小。请设计 高效的方法判断某些词语是否在一数据量很大的词典中出现,假设绝大多数情况这些词语并 不出现在词典中。写出方法(可画图表示)并给出分析。可综合索引或散列函数的方法,也可用 其他方法。 (12%)
人工智能导论测试题库及答案精选全文

精选全文完整版(可编辑修改)人工智能导论测试题库及答案1、在关联规则分析过程中,对原始数据集进行事务型数据处理的主要原因是。
A、提高数据处理速度B、节省存储空间C、方便算法计算D、形成商品交易矩阵答案:C2、计算机视觉可应用于下列哪些领域()。
A、安防及监控领域B、金融领域的人脸识别身份验证C、医疗领域的智能影像诊断D、机器人/无人车上作为视觉输入系统E、以上全是答案:E3、1943年,神经网络的开山之作《A logical calculus of ideas immanent in nervous activity》,由()和沃尔特.皮茨完成。
A、沃伦.麦卡洛克B、明斯基C、唐纳德.赫布D、罗素答案:A4、对于自然语言处理问题,哪种神经网络模型结构更适合?()。
A、多层感知器B、卷积神经网络C、循环神经网络D、感知器答案:C5、图像的空间离散化叫做:A、灰度化B、二值化C、采样D、量化答案:C6、()越多,所得图像层次越丰富,灰度分辨率高,图像质量好。
A、分辨率B、像素数量C、量化等级D、存储的数据量答案:C7、一个完整的人脸识别系统主要包含人脸图像采集和检测、人脸图像特征提取和人脸识别四个部分。
A、人脸分类器B、人脸图像预处理C、人脸数据获取D、人脸模型训练答案:B8、下列不属于人工智能学派的是()。
A、符号主义B、连接主义C、行为主义D、机会主义答案:D9、关于正负样本的说法正确是。
A、样本数量多的那一类是正样本B、样本数量少的那一类是负样本C、正负样本没有明确的定义D、想要正确识别的那一类为正样本答案:D10、以下不属于完全信息博弈的游戏有()。
A、井字棋B、黑白棋C、围棋D、桥牌答案:D11、下列关于人工智能的说法中,哪一项是错误的。
A、人工智能是一门使机器做那些人需要通过智能来做的事情的学科B、人工智能主要研究知识的表示、知识的获取和知识的运用C、人工智能是研究机器如何像人一样合理思考、像人一样合理行动的学科D、人工智能是研究机器如何思维的一门学科答案:D12、认为智能不需要知识、不需要表示、不需要推理;人工智能可以像人类智能一样逐步进化;智能行为只能在现实世界中与周围环境交互作用而表现出来。
东北大学本科毕业设计论文《基于支持向量机算法的电网故障诊断方法研究》

ABSTRACT
With electricity demand growth and technology progress, power grid has become larger and more complex. Due to the formation of large power grids, the quality of electricity supply and electric security improves, also, resources complementary has been strengthened. Once fault occurs, however, it will spread to a wider area with a faster speed. For these merits, this study focuses on the fault diagnosis for power network based on support vector machine. By analyzing relative literatures and building a simulation model, this thesis finishes the analyzing of fault waveforms and harmonic distribution, and studies fault characteristics from the perspective of signal synthesis. To extract fault features submerged in original fault data, this thesis deeply studies the fuzzy processing method, the value detection of instantaneous current and the common fault feature extraction method based on wavelet singular entropy. For the error-prone of instantaneous current detection, fuzzing set ideas is drew to optimize the training samples and by modifying diagnostic strategies, the shortcoming is overcame. To reduce the elapsed time of the common fault feature extraction method based on wavelet singular entropy, a new fault feature combination is proposed by comparing the method with instantaneous current detection. This new combination can inspect faults rapidly when current has a sharp rise such as no- load line closing serious short circuit and improve the diagnostic accuracy when fault current rise is more gentle by taking advantage of wavelet transform which has a wealth of information. Under the condition that the fault features are extracted entirely, artifirt vector machine are used to diagnose power network faults. On one hand, a comparison of the two methods and a study on kernels, multi-class classification methods and SVM training algorithms are carried out. On the other hand, for a figurative expression of the diagnostic results, two dimensions are constructed from the training samples and a twodimensional optimal hyperplane is established by analyzing simulation system structure and data characteristics. Finally, by analyzing the spatial distribution of sample points, the three-dimensional optimal hyperplane is explored. -III-
一个新的多分类器组合模型

Ab t a t sr c :Cls i c t n i a v r mp r n p r i h o i o a a a s a i s e y i o a t a t n t e d ma n f d t mi i g h we e , ig e ls i e s h v n ee t , u h i f o t n n , o v r sn l ca sf r a e ma y d fc s s c i a v r f i a p ia i t a d o a c r c . o ii g s ey i t p l b l y n lw c u a yC mb n n mut l c a sf r a o e c me h d f csT e xse t o ia in ne c i l p e l si es i i c n v r o t e ee t. h e itn c mb n t o r l , h c i h p v t l o c p in u i g t e r c s f c mb n t n ic u ig r d c r l , u r l me in u l , o i g u l u e w ih s e i oa c n e t d r h p o e s o o i ai ,n l d n p o u t u e s m e, d a r e v t r e t o n o u n
E m i jf— 0 @13 o - al x t0 5 6 . m g. e JAN Ln— o C L -u , Y qn . e mo e f o iig I G i b , AI i j n YI e— igN w d l cmbnn mut l lsies mp tr n ier g n o lpe as r. i c f Co ue E gnei中扮 演着很重要的 角色, 然而单 个分 类器有很 多缺点 , 包括适 用范围十分有限和分类准确度 不高等。 多 把
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3 度量级信息计算方法
分类器输出度量级信息对融合多分类器最有利, 但并不是 所有的分类器都像贝叶斯那样能直接输出度量级信息的, 因 此, 有必要寻找其他的计算和表示方法。本文使用相似度和混 淆距阵的概念, 以便把不能直接输出度量级信息的分类器所产 生 分 类 结 果 度 量 级 化 。相 似 度 和 后 验 概 率 都 给 出 了 在 给 定 单 分 类器条件下样本属于某类别的相对概率。
组合多分类器就是通过某种组合技术, 将多个分类器的预 测结果进行融合, 从而产生一个新的分类器, 并用新分类器对 样本进行分类。如果融合得当, 组合分类器的性能比任何单个 分类器都优越[1]。最近 10 年, 组合多分类器在现实研究各领域 中 取 得 了 重 大 成 果 , 比 如 字 迹 和 文 本 识 别 [2], 银 行 借 贷 风 险 预 测[4], 生物种群分类[5]等等。分类器融合方法一般分为并联 和 串 联 两 种 方 式 , 这 篇 文 章 中 , 将 提 出 一 种 新 的 基 于 BP 神 经 网 络 的并联融合算法, 这个算法利用各分类器的度量级输出信息和 模型的决策误差自动调整各单分类器与类别间的权值。
Abstr act: Classification is a very important part in the domain of data mining, however, single classifiers have many defects, such as very finite applicability and low accuracy.Combining multiple classifiers can overcome the defects.The existent combination rule, which is the pivotal conception during the process of combination, including product rule, sum rule, median rule, voting rule and so on, but these are not steady enough.In this paper, the authors develop a new model of combining multiple classifiers based on nerve net, and it is proved that it can improve not only the accuracy of classification but also its applicability. Key wor ds: data mining; classification; nerve net; combining multiple classifiers
J IANG Lin - bo, CAI Li - jun, YI Ye - qing.New model of combining multiple classifier s.Computer Engineer ing and Applications, 2008, 44( 17) : 131- 134.
$
$$d( X, i0)·Ki
d( $$
%
X, i)·K
d( X, i0) =0 且 d( X, i) =0
d(
X, i0)
=0
且
d(
X,
i)
≠0,
或者
Ki
=0 (
2)
d( X, i0) ≠0 且 Ki ≠0
3.2 混淆距阵及后验概率
E( X) =j 表示分类器 E 将来自 X 的模式分到类 Cj 中 , 为 了
Computer Engineering and Applications 计算机工程与应用
2008, 44( 17) 131
一个新的多分类器组合模型
蒋林波 1, 蔡立军 1, 2, 易叶青 2 JIANG Lin- bo1, CAI Li- jun1, 2, YI Ye- qing2
1.湖南大学 计算机与通信学院, 长沙 410082 2.湖南大学 软件学院, 长沙 410082 1.College of Computer and Communication, Hunan University, Changsha 410082, China 2.Software School, Hunan University, Changsha 410082, China E- mail: jxfgt_005@163.com
度 s( X, i) 定义如下:
1"
$ $
d( X, i0) =0 且 d( X, i) =0
$
s(
X,
i)
=
0$$
#
d( X, i0) =0 且 d( X, i) ≠0
( 1)
$
$$d( X, i0)
d( $$
%
X, i)
d( X, i0) ≠0
其中 d( X, i0) 是所有 d( X, i) 的最小值。相似度 s( X, i) 反映了未
许多分类方法和技术可以用于构造分类模型, 例如决策 树、决策表、神经网络、k- 最近邻、遗传算法、贝叶斯方法以及支 持向量机等。然而, 这些单一的分类技术在应用中常常会受到 一定条件的限制, 因此寻求能广义上提高分类性能的方法成为 分类算法的一个研究方向, 构造一个好的组合分类器已成为当 前分类数据挖掘的研究热点和难点之一。
& 即 d( X, i) = d( X, Xj) /K(i j=1, 2, …, Ki ; Xj 是属于类别 Ci 的 X Ki
的 近 邻 ; Ki 是 这 些 近 邻 的 个 数) , d( X, i0) 同 样 表 示 所 有 d( X, i)
的最小值, 那么有:
1"
$
$
$
(s
X,
i)
=
0$$
’
摘 要: 分类在数据挖掘中扮演着很重要的角色, 然而单个分类器有很多缺点, 包括适用范围十分有限和分类准确度不高等。把多 个单分类器的分类结果融合起来是克服这些缺点的有效途径, 因此存在很高的研究价值。组合多分类器的一个核心内容是融合规 则, 现存的融合规则有积规则、和规则、中值规则与投票规则等, 但这些规则性能还不够稳定。提出了一个新的基于神经网络的融 合规则, 并依此建立一个新的多分类器组合模型, 实验表明它能提高分类准确度和稳定性。 关键词: 数据挖掘; 分类; 神经网络; 组合多分类器 DOI: 10.3778/j.issn.1002- 8331.2008.17.039 文章编号: 1002- 8331( 2008) 17- 0131- 04 文献标识码: A 中图分类号: TP311
知样本 X 在 K- Means 算法基础上属于 Ci 类的可能性, 此值越
大, X 属于 Ci 的概率也就越大[6]。
对于 K- NN 分类器, 本文对 以 上 定 义 稍 作 修 改 , 令 d( X, i)
表 示 X 与 它 K 个 近 邻 中 属 于 类 别 Ci 的 所 有 样 本 的 平 均 距 离 ,
3.1 相似度
相 似 度 是 针 对 基 于 距 离 的 分 类 器 的 , 即 根 据 某 种 距 离( 如
欧氏距离, 见式( 3) 对未知样本 X 进行分类的算法。设 f 表示距
离分类器 K- Means, d( X, i) 表示由模式的特征确定的 X 与类别
Ci 的 中 心 的 距 离( i=1, 2, … , M) , 那 么 X 与 类 别 Ci 之 间 的 相 似
机 网 络 、基 因 分 类 等 。 收稿日期: 2007- 09- 14 修回日期: 2007- 12- 03
132 2008, 44( 17)
Computer Engineering and Applications 计算机工程与应用
一般把分类器 E 的输出信息分为三个等级[6]: ( 1) 抽 象 级 : E 仅 输 出 类 标 签 j, 或 可 能 的 类 标 签 子 集 J( 类 别集的真子集) ; ( 2) 排 列 级 : E 把 类 别 集 或 J 中 的 类 标 签 根 据 一 个 内 部 规 则排列起来, 排在第一位的即为 X 所属样本类别的首选; ( 3) 度量级: E 输出在给定样本 X 各属性值时, X 属于每一 类别的概率 P( i/X)( i=1, 2, …, M) 或与概率相对应的某些值。 很显然, 分类器所输出的信息级别越高, 它所包含的信息 越全面。如果能充分利用这些被遗弃的信息, 无疑会使分类准 确度大大提高。然而, 单个分类器由于缺少信息融合机制, 无法 把这些信息综合起来对样本进行类别预测, 它们只能在这些信 息里做出简单的选择。因此, 组合多分类器的概念应运而生, 有 关它的研究和发展也得到许多学者的重视。 多分类器组合方式最突出的优点是模型可以综合不同分 类器所得到的分类信息, 避免单一分类器可能存在的片面性, 以达到更好的分类效果。一般化的组合多分类器模型如图 1 所示。
基金项目: 湖南省自然科学基金( the Natural Science Foundation of Hunan Province of China under Grant No.06JJ20049, No.07JJ5085) 。 作者简介: 蒋林波( 1985- ) , 男, 硕士研究生, 主要研究方向: 机器学习与数据挖掘; 蔡立军( 1964- ) , 男, 博士, 教授, 主要研究方向: 机器学 习 、计 算
2 组合多分类器概述
尽管一个实际的单分类器的最终输出是一个单值 j( 第 j 个类别) , 但实质上很多分类器可以提供更多信息, 只是这些信 息被遗弃罢了。比如贝叶斯算法能提供每个样本 X 属于某类 别的概率, 而在新样本上利用它所取得的结果, 其实就是它计 算出来的具有最大概率值相对应的那个类标签。