MATLAB回归预测模型
matlab回归建模过程

matlab回归建模过程摘要:一、回归建模概述- 回归分析的定义- 回归建模的目的和意义二、MATLAB 回归建模过程- 一元线性回归- 数学模型定义- 模型参数估计- 检验、预测及控制- 多元线性回归- 数学模型定义- 模型参数估计- 多元线性回归中检验与预测- 逐步回归分析三、MATLAB 回归建模应用案例- 案例一:一元线性回归分析- 案例二:多元线性回归分析- 案例三:逐步回归分析正文:一、回归建模概述回归分析是一种研究变量之间关系的统计方法,通过建立一个数学模型,描述自变量与因变量之间的线性关系。
回归建模在实际应用中有着广泛的应用,如经济学、生物学、社会学等学科的研究中,可以帮助我们更好地理解变量之间的关系,并对未来趋势进行预测和控制。
MATLAB 是一种广泛应用于科学计算和数据分析的编程语言,提供了丰富的回归建模工具箱,可以帮助我们快速、高效地进行回归建模分析。
二、MATLAB 回归建模过程1.一元线性回归一元线性回归是最简单的回归分析方法,适用于只有一个自变量和一个因变量的情况。
在MATLAB 中,我们可以使用回归分析工具箱中的`regress`函数进行一元线性回归建模。
(1)数学模型定义一元线性回归的数学模型可以表示为:y = a + bx其中,y 表示因变量,x 表示自变量,a 和b 分别表示回归系数。
(2)模型参数估计在MATLAB 中,我们可以使用`regress`函数对模型参数进行估计。
函数的原型为:b = regress(y, x)其中,y 表示因变量向量,x 表示自变量向量,b 表示回归系数向量。
(3)检验、预测及控制在得到回归系数向量b 后,我们可以进行回归检验、预测以及控制。
2.多元线性回归多元线性回归适用于有多个自变量和因变量的情况。
在MATLAB 中,我们可以使用回归分析工具箱中的`polyfit`函数进行多元线性回归建模。
(1)数学模型定义多元线性回归的数学模型可以表示为:y = a0 + a1x1 + a2x2 + ...+ anxn其中,y 表示因变量,x1、x2、...、xn 表示自变量,a0、a1、a2、...、an 分别表示回归系数。
matlab随机森林回归预测算法

随机森林是一种常用的机器学习算法,它在回归和分类问题中都有很好的表现。
而在Matlab中,也提供了随机森林回归预测算法,能够帮助用户解决实际问题中的预测和建模需求。
下面我们将就Matlab中的随机森林回归预测算法展开详细的介绍。
一、随机森林的原理随机森林是一种集成学习算法,它由多棵决策树组成。
在构建每棵决策树时,会随机选择样本和特征进行训练,最后将多棵决策树的结果综合起来,形成最终的预测结果。
这样的做法可以有效地减少过拟合的风险,同时具有很高的预测准确性。
随机森林的优点主要包括:具有很好的鲁棒性,对于数据中的噪声和缺失值有很强的适应能力;能够处理高维数据和大规模数据,不需要对数据进行特征选择和降维;具有很好的泛化能力,不易发生过拟合。
二、Matlab中的随机森林回归预测算法Matlab提供了一个强大的集成学习工具箱,其中包括了随机森林回归预测算法。
用户可以很方便地使用这个工具箱进行数据建模和预测。
1. 数据准备在使用Matlab进行随机森林回归预测之前,首先需要准备好数据。
数据应该包括自变量和因变量,可以使用Matlab的数据导入工具将数据导入到工作空间中。
2. 构建随机森林模型在数据准备好之后,可以使用Matlab的fitrensemble函数来构建随机森林模型。
该函数可以指定树的数量、最大深度、最小叶子大小等参数,也可以使用交叉验证来优化模型的参数。
3. 模型预测一旦模型构建完成,就可以使用predict函数对新的数据进行预测了。
通过输入自变量的数值,就可以得到相应的因变量的预测值。
4. 模型评估在得到预测结果之后,通常需要对模型进行评估,以了解模型的预测能力。
可以使用Matlab提供的各种评估指标函数,如均方误差(MSE)、决定系数(R-squared)、平均绝对误差(MAE)等来评估模型的表现。
5. 参数调优如果模型的表现不佳,可以尝试使用交叉验证、网格搜索等方法对模型的参数进行调优,以提高模型的预测准确性。
matlab建立多元线性回归模型并进行显著性检验及预测问题

matlab建立多元线性回归模型并进行显着性检验及预测问题例子;x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';X=[ones(16,1) x]; 增加一个常数项Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]'; [b,bint,r,rint,stats]=regress(Y,X) 得结果:b = bint = stats = 即对应于b的置信区间分别为[,]、[,]; r2=, F=, p= p<, 可知回归模型y=+ 成立. 这个是一元的,如果是多元就增加X的行数!function [beta_hat,Y_hat,stats]=regress(X,Y,alpha)% 多元线性回归(Y=Xβ+ε)MATLAB代码%?% 参数说明% X:自变量矩阵,列为自变量,行为观测值% Y:应变量矩阵,同X% alpha:置信度,[0 1]之间的任意数据% beta_hat:回归系数% Y_beata:回归目标值,使用Y-Y_hat来观测回归效果% stats:结构体,具有如下字段% =[fV,fH],F检验相关参数,检验线性回归方程是否显着% fV:F分布值,越大越好,线性回归方程越显着% fH:0或1,0不显着;1显着(好)% =[tH,tV,tW],T检验相关参数和区间估计,检验回归系数β是否与Y有显着线性关系% tV:T分布值,beta_hat(i)绝对值越大,表示Xi对Y显着的线性作用% tH:0或1,0不显着;1显着% tW:区间估计拒绝域,如果beta(i)在对应拒绝区间内,那么否认Xi对Y显着的线性作用% =[T,U,Q,R],回归中使用的重要参数% T:总离差平方和,且满足T=Q+U% U:回归离差平方和% Q:残差平方和% R∈[0 1]:复相关系数,表征回归离差占总离差的百分比,越大越好% 举例说明% 比如要拟合y=a+b*log(x1)+c*exp(x2)+d*x1*x2,注意一定要将原来方程线化% x1=rand(10,1)*10;% x2=rand(10,1)*10;% Y=5+8*log(x1)+*exp(x2)+*x1.*x2+rand(10,1); % 以上随即生成一组测试数据% X=[ones(10,1) log(x1) exp(x2) x1.*x2]; % 将原来的方表达式化成Y=Xβ,注意最前面的1不要丢了% [beta_hat,Y_hat,stats]=mulregress(X,Y,%% 注意事项% 有可能会出现这样的情况,总的线性回归方程式显着的=1),% 但是所有的回归系数却对Y的线性作用却不显着=0),产生这种现象的原意是% 回归变量之间具有较强的线性相关,但这种线性相关不能采用刚才使用的模型描述,% 所以需要重新选择模型%C=inv(X'*X);Y_mean=mean(Y);% 最小二乘回归分析beta_hat=C*X'*Y; % 回归系数βY_hat=X*beta_hat; % 回归预测% 离差和参数计算Q=(Y-Y_hat)'*(Y-Y_hat); % 残差平方和U=(Y_hat-Y_mean)'*(Y_hat-Y_mean); % 回归离差平方和T=(Y-Y_mean)'*(Y-Y_mean); % 总离差平方和,且满足T=Q+UR=sqrt(U/T); % 复相关系数,表征回归离差占总离差的百分比,越大越好[n,p]=size(X); % p变量个数,n样本个数% 回归显着性检验fV=(U/(p-1))/(Q/(n-p)); % 服从F分布,F的值越大越好fH=fV>finv(alpha,p-1,n-p); % H=1,线性回归方程显着(好);H=0,回归不显着% 回归系数的显着性检验chi2=sqrt(diag(C)*Q/(n-p)); % 服从χ2(n-p)分布tV=beta_hat./chi2; % 服从T分布,绝对值越大线性关系显着tInv=tinv+alpha/2,n-p);tH=abs(tV)>tInv; % H(i)=1,表示Xi对Y显着的线性作用;H(i)=0,Xi对Y的线性作用不明显% 回归系数区间估计tW=[-chi2,chi2]*tInv; % 接受H0,也就是说如果在beta_hat(i)对应区间中,那么Xi与Y线性作用不明显stats=struct('fTest',[fH,fV],'tTest',[tH,tV,tW],'TUQR',[T,U,Q,R]);。
matlab建立多元线性回归模型并进行显著性检验及预测问题

matlab建立多元线性回归模型并进行显著性检验及预测问题例子;x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';X=[ones(16,1) x]; 增加一个常数项 Y=[88 85 88 91 92 93 93 95 96 98 97 9698 99 100 102]'; [b,bint,r,rint,stats]=regress(Y,X) 得结果:b = bint = stats = 即对应于b的置信区间分别为[,]、[,]; r2=, F=, p= p<, 可知回归模型 y=+ 成立. 这个是一元的,如果是多元就增加X的行数!function [beta_hat,Y_hat,stats]=regress(X,Y,alpha)% 多元线性回归(Y=Xβ+ε)MATLAB代码%% 参数说明% X:自变量矩阵,列为自变量,行为观测值% Y:应变量矩阵,同X% alpha:置信度,[0 1]之间的任意数据% beta_hat:回归系数% Y_beata:回归目标值,使用Y-Y_hat来观测回归效果% stats:结构体,具有如下字段% =[fV,fH],F检验相关参数,检验线性回归方程是否显著% fV:F分布值,越大越好,线性回归方程越显著% fH:0或1,0不显著;1显著(好)% =[tH,tV,tW],T检验相关参数和区间估计,检验回归系数β是否与Y有显著线性关系% tV:T分布值,beta_hat(i)绝对值越大,表示Xi对Y显著的线性作用% tH:0或1,0不显著;1显著% tW:区间估计拒绝域,如果beta(i)在对应拒绝区间内,那么否认Xi对Y显著的线性作用% =[T,U,Q,R],回归中使用的重要参数% T:总离差平方和,且满足T=Q+U% U:回归离差平方和% Q:残差平方和% R∈[0 1]:复相关系数,表征回归离差占总离差的百分比,越大越好% 举例说明% 比如要拟合 y=a+b*log(x1)+c*exp(x2)+d*x1*x2,注意一定要将原来方程线化% x1=rand(10,1)*10;% x2=rand(10,1)*10;% Y=5+8*log(x1)+*exp(x2)+*x1.*x2+rand(10,1); % 以上随即生成一组测试数据% X=[ones(10,1) log(x1) exp(x2) x1.*x2]; % 将原来的方表达式化成Y=Xβ,注意最前面的1不要丢了% [beta_hat,Y_hat,stats]=mulregress(X,Y,%% 注意事项% 有可能会出现这样的情况,总的线性回归方程式显著的=1),% 但是所有的回归系数却对Y的线性作用却不显著=0),产生这种现象的原意是% 回归变量之间具有较强的线性相关,但这种线性相关不能采用刚才使用的模型描述,% 所以需要重新选择模型%C=inv(X'*X);Y_mean=mean(Y);% 最小二乘回归分析beta_hat=C*X'*Y; % 回归系数βY_hat=X*beta_hat; % 回归预测% 离差和参数计算Q=(Y-Y_hat)'*(Y-Y_hat); % 残差平方和U=(Y_hat-Y_mean)'*(Y_hat-Y_mean); % 回归离差平方和T=(Y-Y_mean)'*(Y-Y_mean); % 总离差平方和,且满足T=Q+UR=sqrt(U/T); % 复相关系数,表征回归离差占总离差的百分比,越大越好[n,p]=size(X); % p变量个数,n样本个数% 回归显著性检验fV=(U/(p-1))/(Q/(n-p)); % 服从F分布,F的值越大越好fH=fV>finv(alpha,p-1,n-p); % H=1,线性回归方程显著(好);H=0,回归不显著% 回归系数的显著性检验chi2=sqrt(diag(C)*Q/(n-p)); % 服从χ2(n-p)分布tV=beta_hat./chi2; % 服从T分布,绝对值越大线性关系显著tInv=tinv+alpha/2,n-p);tH=abs(tV)>tInv; % H(i)=1,表示Xi对Y显著的线性作用;H(i)=0,Xi 对Y的线性作用不明显% 回归系数区间估计tW=[-chi2,chi2]*tInv; % 接受H0,也就是说如果在beta_hat(i)对应区间中,那么Xi与Y线性作用不明显stats=struct('fTest',[fH,fV],'tTest',[tH,tV,tW],'TUQR',[T,U,Q,R]) ;。
matlab中的偏最小二乘法(pls)回归模型,离群点检测和变量选择

matlab中的偏最小二乘法(pls)回归模型,离群点检测和变
量选择
在MATLAB中,可以使用以下函数实现偏最小二乘法回归模型、离群点检测和变量选择:
1. 偏最小二乘法(PLS)回归模型:
- `plsregress`:该函数用于计算偏最小二乘法(PLS)回归模型。
它可以输出回归系数、预测结果以及其他性能指标。
2. 离群点检测:
- `mahal`:该函数用于计算多元正态分布下的马氏距离,可以作为离群点的度量。
- `outlier`:该函数用于检测一维数据的离群点。
3. 变量选择:
- `plsregress`的输出结果中可以通过使用交叉验证和预测误差来选择最优的变量数量。
- `plsregress`的输出结果中的回归系数中可以通过设置阈值来选择较大的变量。
具体用法可以参考MATLAB的文档和示例代码。
均值回归模型参数估计 matlab代码

均值回归模型是一种常见的统计建模方法,它通过对自变量和因变量之间的平均关系进行建模来进行参数估计。
在实际的数据分析和建模过程中,我们经常需要使用MATLAB来进行均值回归模型的参数估计和分析。
本文将针对均值回归模型参数估计的MATLAB代码进行详细的介绍和解释。
1. 均值回归模型简介均值回归模型是一种简单但常用的统计建模方法,它假设自变量与因变量之间的关系是通过均值来进行描述的。
均值回归模型的基本形式可以表示为:Y = β0 + β1*X + ε其中,Y表示因变量,X表示自变量,β0和β1分别表示回归方程的截距和斜率参数,ε表示误差项。
均值回归模型的目标就是通过对数据进行拟合来估计出最优的β0和β1参数,从而描述自变量和因变量之间的关系。
2. MATLAB代码实现在MATLAB中,我们可以使用regress函数来进行均值回归模型参数的估计。
regress函数的基本语法如下:[b,bint,r,rint,stats] = regress(y,X)其中,y表示因变量的数据向量,X表示自变量的数据矩阵,b表示回归系数的估计值,bint表示回归系数的置信区间,r表示残差向量,rint表示残差的置信区间,stats是一个包含了回归统计信息的向量。
3. 代码示例下面是一个使用MATLAB进行均值回归模型参数估计的简单示例:```MATLAB生成随机数据X = randn(100,1);Y = 2*X + randn(100,1);均值回归模型参数估计[b,bint,r,rint,stats] = regress(Y,X);打印回归系数估计值fprintf('回归系数估计值:\n');disp(b);打印回归统计信息fprintf('回归统计信息:\n');disp(stats);```在这个示例中,我们首先生成了一个随机的自变量X和一个根据线性关系生成的因变量Y。
然后使用regress函数对这些数据进行了均值回归模型参数的估计,并打印出了回归系数的估计值和一些回归统计信息。
遗传算法回归预测matlab程序

遗传算法回归预测matlab程序1. 简介遗传算法是一种基于生物遗传机制的优化算法,它模拟了自然界中的遗传、变异、适应与选择机制。
在数据预测领域,遗传算法被广泛应用于回归分析,它能够通过不断迭代优化模型参数,找到最优的拟合曲线,从而实现对未知数据的准确预测。
而在matlab程序中,遗传算法回归预测模型的实现也成为了一种常见的工具,深受数据分析和预测领域的从业者所青睐。
2. 遗传算法回归预测原理遗传算法回归预测模型基于遗传算法的优化能力,通过不断迭代调整模型参数,使其与真实数据的差距最小化。
其基本原理包括以下几个步骤:2.1. 个体编码:将回归模型的参数进行二进制编码,构成种裙的个体。
2.2. 适应度评估:采用回归模型拟合真实数据,计算个体的适应度,即拟合度。
2.3. 选择操作:根据个体的适应度进行选择,将适应度高的个体保留下来,作为父代参与繁殖。
2.4. 交叉操作:对选择出来的父代进行交叉操作,产生新的个体,并保留一定概率的变异操作。
2.5. 新一代个体重复步骤2.2~2.4,直至达到预设的迭代次数或收敛条件。
3. 遗传算法回归预测matlab程序实现步骤在matlab中实现遗传算法回归预测模型,通常可以按以下步骤进行操作:3.1. 导入数据:首先需要导入需要进行回归预测的数据,并进行数据预处理,包括归一化、标准化等操作。
3.2. 初始化种裙:根据回归模型的参数范围,随机初始化种裙的个体,并进行个体编码。
3.3. 适应度评估:利用回归模型对种裙中的个体进行拟合,计算其适应度。
3.4. 选择、交叉、变异操作:根据个体的适应度进行选择、交叉、变异操作,产生新一代的个体。
3.5. 迭代操作:重复进行选择、交叉、变异操作,直至达到预设的迭代次数或收敛条件。
3.6. 获取最优解:得到迭代过程中适应度最高的个体,即为最优解,用于构建回归模型进行预测。
4. 遗传算法回归预测matlab程序示例代码下面是一个简单的遗传算法回归预测matlab程序示例代码:```matlab导入数据data = load('data.txt');X = data(:, 1);y = data(:, 2);m = length(y);初始化种裙populationSize = 100;numParams = 2;population = zeros(populationSize, numParams);for i = 1:populationSizepopulation(i, :) = rand(1, numParams);end迭代参数优化numIterations = 100;for iter = 1:numIterations适应度评估fitness = zeros(populationSize, 1);for i = 1:populationSizeparams = population(i, :);yPredicted = params(1) * X + params(2);fitness(i) = 1 / (m * 2) * sum((yPredicted - y).^2); end选择、交叉、变异操作[fitness, indices] = sort(fitness);population = population(indices, :);newPopulation = zeros(populationSize, numParams);for i = 1:populationSizeparent1 = population(mod(i, populationSize) + 1, :);parent2 = population(mod(i + 1, populationSize) + 1, :); crossoverPoint = randi([1, numParams - 1]);child = [parent1(1:crossoverPoint),parent2(crossoverPoint+1:end)];mutationPoint = randi([1, numParams]);child(mutationPoint) = rand(1);newPopulation(i, :) = child;endpopulation = newPopulation;end获取最优解bestParams = population(1, :);yPredicted = bestParams(1) * X + bestParams(2);plot(X, y, 'ro', X, yPredicted, 'b-');```5. 总结遗传算法回归预测matlab程序的实现,基于遗传算法的优化能力,可以有效地对回归模型进行参数优化,从而实现对未知数据的准确预测。
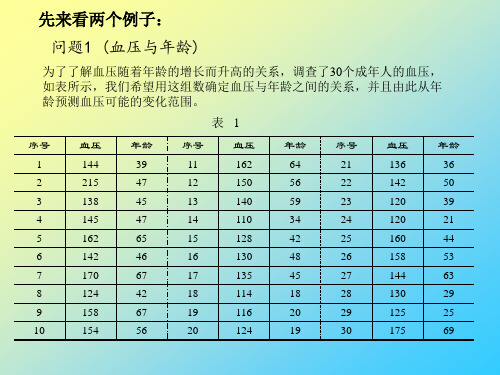
第三讲 MATLAB预测(1)回归分析
ˆ 489.2946 s t 2 65.8896 t 9.1329
方法二
化为多元线性回归:
t=1/30:1/30:14/30;
s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];
3
1
模型:记血压为 y ,年龄为 x1 ,体重指数为 x2 ,吸烟习惯为 x3 , 用Matlab将 y 与 x2 的数据做散点图,看出大致也呈线性关系,建立 模型: y 0 1 x1 2 x2 3 x3 由数据估计系数 0,2,3,4 ,也可看做曲面拟合(其实为 超平面)
T=[ones(14,1) t‘ (t.^2)'];
[b,bint,r,rint,stats]=regress(s',T); b,stats
得回归模型为 :
ˆ 9.1329 65.8896 s t 489.2946 t2
预测及作图
Y=polyconf(p,t,S) plot(t,s,'k+',t,Y,'r')
(二)多元二项式回归
命令:rstool(x,y,’model’, alpha)
nm矩阵
n维列向量
显著性水平
(缺省时为0.05)
由下列 4 个模型中选择 1 个(用字符串输入,缺省时为线性模型): linear(线性): y 0 1 x1 m xm purequadratic(纯二次): interaction(交叉): y
其中 x=(x1,x2,„,xn) ,y=(y1,y2 ,„,yn) ; m m-1 p=(a1,a2,„,am+1)是多项式 y=a1x +a2x +„+amx+am+1 的系数;S 是一个矩阵,用来估计预测误差.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MATLAB---回归预测模型
Matlab统计工具箱用命令regress实现多元线性回归,用的方法是最小二乘法,用法是:b=regress(Y,X)
[b,bint,r,rint,stats]=regress(Y,X,alpha)
Y,X为提供的X和Y数组,alpha为显着性水平(缺省时设定为0.05),b,bint为回归系数估计值和它们的置信区间,r,rint为残差(向量)及其置信区间,stats是用于检验回归模型的统计量,有四个数值,第一个是R2,第二个是F,第三个是与F对应的概率 p ,p <α拒绝 H0,回归模型成立,第四个是残差的方差 s2 。
残差及其置信区间可以用 rcoplot(r,rint)画图。
例1合金的强度y与其中的碳含量x有比较密切的关系,今从生产中收集了一批数据如下表 1。
先画出散点图如下:
x=0.1:0.01:0.18;
y=[42,41.5,45.0,45.5,45.0,47.5,49.0,55.0,50.0];
plot(x,y,'+')
可知 y 与 x 大致上为线性关系。
设回归模型为y =β
0+β
1
x
用regress 和rcoplot 编程如下:
clc,clear
x1=[0.1:0.01:0.18]';
y=[42,41.5,45.0,45.5,45.0,47.5,49.0,55.0,50.0]'; x=[ones(9,1),x1];
[b,bint,r,rint,stats]=regress(y,x);
b,bint,stats,rcoplot(r,rint)
得到 b =27.4722 137.5000
bint =18.6851 36.2594
75.7755 199.2245
stats =0.7985 27.7469 0.0012 4.0883
即β
0=27.4722 β
1
=137.5000
β
的置信区间是[18.6851,36.2594],
β
1
的置信区间是[75.7755,199.2245];
R2= 0.7985 , F = 27.7469 , p = 0.0012 , s2 =4.0883 。
可知模型(41)成立。
观察命令 rcoplot(r,rint)所画的残差分布,除第 8 个数据外其余残差的置信区间均包含零点第8个点应视为异常点,
将其剔除后重新计算,
可得 b =30.7820 109.3985
bint =26.2805 35.2834
76.9014 141.8955
stats =0.9188 67.8534 0.0002 0.8797
应该用修改后的这个结果。