定性数据分析第五章课后答案.doc
《统计分析和SPSS的应用(第五版)》课后练习答案(第5章)

《统计分析和SPSS的应用(第五版)》课后练习答案(第5章)《统计分析和SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值 = 75t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
运筹学基础课后习题答案

运筹学基础课后习题答案[2002年版新教材]第一章导论P51.、区别决策中的定性分析和定量分析,试举例。
定性——经验或单凭个人的判断就可解决时,定性方法定量——对需要解决的问题没有经验时;或者是如此重要而复杂,以致需要全面分析(如果涉及到大量的金钱或复杂的变量组)时,或者发生的问题可能是重复的和简单的,用计量过程可以节约企业的领导时间时,对这类情况就要使用这种方法。
举例:免了吧。
2、.构成运筹学的科学方法论的六个步骤是哪些?.观察待决策问题所处的环境;.分析和定义待决策的问题;.拟定模型;.选择输入资料;.提出解并验证它的合理性(注意敏感度试验);.实施最优解;3、.运筹学定义:利用计划方法和有关许多学科的要求,把复杂功能关系表示成数学模型,其目的是通过定量分析为决策和揭露新问题提供数量根据第二章作业预测P251、.为了对商品的价格作出较正确的预测,为什么必须做到定量与定性预测的结合?即使在定量预测法诸如加权移动平均数法、指数平滑预测法中,关于权数以及平滑系数的确定,是否也带有定性的成分?答:(1)定量预测常常为决策提供了坚实的基础,使决策者能够做到心中有数。
但单靠定量预测有时会导致偏差,因为市场千变万化,影响价格的因素很多,有些因素难以预料。
调查研究也会有相对局限性,原始数据不一定充分,所用的模型也往往过于简化,所以还需要定性预测,在缺少数据或社会经济环境发生剧烈变化时,就只能用定性预测了。
(2)加权移动平均数法中权数的确定有定性的成分;指数平滑预测中的平滑系数的确定有定性的成分。
2.、某地区积累了5个年度的大米销售量的实际值(见下表),试用指数平滑法,取平滑系数α=0.9,预测第6年度的大米销售量(第一个年度的预测值,根据专家估计为4181.9千公斤)年度12345大米销售量实际值(千公斤)52025079393744533979。
答:F6=a*x5+a(1-a)*x4+a(1-a)~2*x3+a(1-a)~3*x2+a(1-a)~4*F16=0.9*3979+0.9*0.1*4453+0.9*0.01*3937+0.9*0.001*5079+0.9*0.0001*4181.9F6=3581.1+400.77+35.433+4.5711+0.3764F6=4022.33、某地区积累了11个年度纺织品销售额与职工工资总额的数据,列入下列表中(表略),计算:(1)回归参数a,b(2)写出一元线性回归方程。
定性数据分析第五章课后答案

定性数据分析第五章课后作业1、为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问题,你有什么看法?为什么?解:(1)数据压缩分析首先将上表中不同年龄段的数据合并在一起压缩成二维2X 2列联表1.1 ,合起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异?二维22列联表独立检验的似然比检验统计量2ln的值为0.7032,p值为p P( 2(1) 0.7032) 0.4017 0.05,不应拒绝原假设,即认为“偏好类型”与“性别”无关。
(2)数据分层分析其次,按年龄段分层,得到如下三维2X 2X 2列联表1.2,分开来看,男性和女性对这两种类型的饮料的偏好有没有差异?在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调 查,在“年青人”年龄段,男性中偏好饮料A 占58. 73%偏好饮料B 占41.27%; 女性中偏好饮料A 占58. 73%偏好饮料B 占41.27%,我们可以得出在这个年 龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。
同理,在“老年人”年龄段,也有一定的差异。
(3) 条件独立性检验为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令C 表示年龄段,0表示年青人,C 2表示老年人;D 表示性别,D ! 表示男性,D 2表示女性;E 表示偏好饮料的类型,E !表示偏好饮料A, E 2表示 偏好饮料B 。
欲检验的原假设为:C 给定后D 和E 条件独立 按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量 2ln 的值如下:条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,2ln 6.248 11.822 18.07由于ret 2,所以条件独立性检验的似然比检验统计量的渐近 2分布的自由度为r(e 1)(t 1) 2,也就是上面这2个四格表的渐近 2分布的自由度的和 由于p 值P( 2(2)18.07) 0.000119165很小,所以认为条件独立性不成立,即在年龄段给定的条件下,男性和女性对两种类型的饮料的偏好是有差异的。
第四版统计学课后习题答案

第四版统计学课后习题答案《统计学》第四版统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
王静龙定性数据分析 习题五

王静龙定性数据分析习题五1. 问题描述在定性数据分析中,王静龙遇到了一个问题,他想要了解一份调查问卷中的开放性问题的回答情况。
具体而言,他想要回答以下几个问题:1.开放性问题的回答内容的总体情况如何?2.开放性问题的回答内容中是否存在一些常见的关键词或主题?3.开放性问题的回答内容中是否存在一些特定的意见或情感?为了解决这个问题,王静龙希望能够进行数据分析,并得出一些有用的结论。
2. 数据准备首先,王静龙需要准备调查问卷中开放性问题的回答数据。
这些数据可以以文本文件的形式存储,每一行代表一个回答。
例如,以下是一些示例数据:1. 我觉得工作环境很好,同事们相互合作,给了我很多帮助。
2. 公司的培训计划很好,能够提高员工的技能和知识。
3. 我对公司的管理方式有一些不满意,希望能够改进。
4. 薪资待遇不够优厚,希望能够有所提升。
5. 我觉得公司的发展前景很不错,希望能够有更好的发展空间。
3. 数据分析3.1 总体情况分析为了了解开放性问题的回答内容的总体情况,王静龙可以进行以下分析:•回答的总数•回答的平均长度•回答的最长长度•回答的最短长度为了实现这些分析,可以使用Python编程语言中的文本处理库进行操作。
下面是一个示例代码,可以帮助完成上述分析:```python # 导入所需的库 import pandas as pd 读取文本文件data = pd.read_csv(’responses.txt’, header=None)计算回答的总数total_responses = len(data)计算回答的平均长度average_length = data[0].apply(len).mean()计算回答的最长长度max_length = data[0].apply(len).max()计算回答的最短长度min_length = data[0].apply(len).min()输出结果print(。
定性数据分析课后答案0001
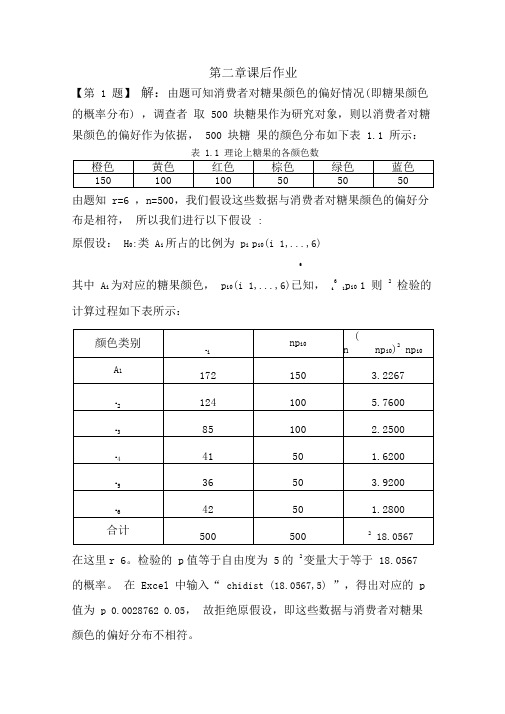
第二章课后作业【第 1 题】解:由题可知消费者对糖果颜色的偏好情况(即糖果颜色的概率分布) ,调查者取500 块糖果作为研究对象,则以消费者对糖果颜色的偏好作为依据,500 块糖果的颜色分布如下表 1.1 所示:表 1.1 理论上糖果的各颜色数由题知r=6 ,n=500,我们假设这些数据与消费者对糖果颜色的偏好分布是相符,所以我们进行以下假设:原假设:H0:类A i所占的比例为p i p i0(i 1, (6)6其中A i为对应的糖果颜色,p i0(i 1,...,6)已知,i61p i0 1 则2检验的计算过程如下表所示:在这里r 6。
检验的p值等于自由度为5的2变量大于等于18.0567 的概率。
在Excel 中输入“ chidist (18.0567,5) ”,得出对应的p 值为p 0.0028762 0.05,故拒绝原假设,即这些数据与消费者对糖果颜色的偏好分布不相符。
【第 2 题】解:由题可知,r=3 ,n=200,假设顾客对这三种肉食的喜好程度相同,即顾客选择这三种肉食的概率是相同的。
所以我们可以进行以下假设:原假设H 0 : p i1(i 1,2,3)0i3则2检验的计算过程如下表所示:在这里r 3。
检验的p值等于自由度为2的2变量大于等于15.72921 的概率。
在Excel 中输入“ chidist (15.72921,2) ”,得出对应的p 值为p 0.0003841 0.05 ,故拒绝原假设,即认为顾客对这三种肉食的喜好程度是不相同的。
【第 3 题】解:由题可知,r=10,n=800,假设学生对这些课程的选择没有倾向性,即选各门课的人数的比例相同, 则十门课程每门课程被选择的概率都相等。
所以我们可以进行以下假设:原假设H 0 : p i 0.1(i 1,2, (10)则2检验的计算过程如下表所示:在这里r 10 。
检验的p值等于自由度为9的2变量大于等于 5.125 的概率。
报告中定性数据的有效分析方法
报告中定性数据的有效分析方法一、什么是定性数据定性数据是指用文字、描述或标签等形式来表示的数据,与定量数据相对。
它主要关注事物的属性、特征或品质,并不能直接用数字进行度量。
在报告中,定性数据的分析常常涉及到对调查问卷、访谈记录或文本材料等进行细致观察和深入理解。
二、定性数据的整理与分类1. 数据整理定性数据的第一步是进行数据整理。
这一步通常包括:将数据输入电子表格中,对材料进行注释,检查和纠正可能出现的错误,并将数据按照一定的方式排序,以便更好地进行分析。
2. 数据分类定性数据的下一步是进行数据分类。
分类可以根据不同的属性、特征或品质进行,以帮助我们更好地理解数据的结构和特点。
可以采用基于主题的分类、基于情感的分类或者基于目标的分类等。
三、定性数据的内容分析方法1. 文本内容分析文本内容分析是一种针对定性数据的常用方法。
它基于对文本材料的深入理解和解释,通过对语言的分析来揭示隐藏在文字背后的信息。
在报告中,可以使用文本内容分析方法来提取和总结调查问卷或访谈记录的主题、观点或趋势,并加以解释和讨论。
2. 语义网络分析语义网络分析是一种将文本数据转化为图形结构的分析方法。
它通过构建和分析词语之间的关系网络来揭示数据之间的联系。
在报告中,可以使用语义网络分析方法来探索和呈现调查问卷或访谈记录中的潜在关系和相互影响。
四、定性数据的模式识别方法1. 主题模式识别主题模式识别是一种通过对定性数据进行归类和总结,识别出数据中的主题和模式的方法。
它通过对数据的频次、相对比例和相关关系进行统计分析,从而揭示数据中隐藏的结构。
2. 情感模式识别情感模式识别是一种通过对定性数据中的情感内容进行识别和分析,揭示数据中蕴含的情感态度和情绪的方法。
它可以通过对文本表达的情感词汇、语气和语境等进行分析,得出调查对象的情感倾向或态度。
五、定性数据的质性验证方法1. 基于质性的逻辑验证基于质性的逻辑验证是一种通过对定性数据进行逻辑推理和验证的方法。
应用回归分析,第5章课后习题参考答案
第5章自变量选择与逐步回归思考与练习参考答案自变量选择对回归参数的估计有何影响答:回归自变量的选择是建立回归模型得一个极为重要的问题。
如果模型中丢掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。
自变量选择对回归预测有何影响答:当全模型(m元)正确采用选模型(p元)时,我们舍弃了m-p个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差,所以全模型正确而误用选模型有利有弊。
当选模型(p元)正确采用全模型(m 元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选模型的大,所以回归自变量的选择应少而精。
如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣C统计量达到最小的准则来衡量回答:如果所建模型主要用于预测,则应使用p归方程的优劣。
试述前进法的思想方法。
答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm建立m 个一元线性回归方程, 并计算F检验值,选择偏回归平方和显着的变量(F值最大且大于临界值)进入回归方程。
每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的F检验值,选择偏回归平方和显着的两变量变量(F 值最大且大于临界值)进入回归方程。
在确定引入的两个自变量以后,再引入一个变量,建立m-2个三元线性回归方程,计算它们的F检验值,选择偏回归平方和显着的三个变量(F值最大)进入回归方程。
不断重复这一过程,直到无法再引入新的自变量时,即所有未被引入的自变量的F检验值均小于F检验临界值Fα(1,n-p-1),回归过程结束。
统计学课后简答题答案
第一章思考题什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论.解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法.推断统计;它是研究如何利用样本数据来推断总体特征的统计方法.统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的.(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值.统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的.实验数据:在实验中控制实验对象而收集到的数据.统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据.时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据.第二章思考题什么是二手资料使用二手资料应注意什么问题与研究内容有关,由别人调查和试验而来已经存在,并会被我们利用的资料为“二手资料”.使用时要进行评估,要考虑到资料的原始收集人,收集目的,收集途径,收集时间使用时要注明数据来源.比较概率抽样和非概率抽样的特点,指出各自适用情况概率抽样:抽样时按一定的概率以随机原则抽取样本.每个单位别抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽到的概率.技术含量和成本都比较高.如果调查目的在于掌握和研究对象总体的数量特征,得到总体参数的置信区间,就使用概率抽样.非概率抽样:操作简单,时效快,成本低,而且对于抽样中的统计学专业技术要求不是很高.它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备.它同样使用市场调查中的概念测试(不需要调查结果投影到总体的情况).除了自填式,面访式和式还有什么搜集数据的办法试验式和观察式等第三章思考题数据预处理内容数据审核(完整性和准确性;适用性和实效性),数据筛选和数据排序.分类数据和顺序数据的整理和图示方法各有哪些分类数据:制作频数分布表,用比例,百分比,比率等进行描述性分析.可用条形图,帕累托图和饼图进行图示分析.顺序数据:制作频数分布表,用比例,百分比,比率.累计频数和累计频率等进行描述性分析.可用条形图,帕累托图和饼图,累计频数分布图和环形图进行图示分析.数据型数据的分组方法和步骤分组方法:单变量值分组和组距分组,组距分组又分为等距分组和异距分组.分组步骤:1确定组数2确定各组组距3根据分组整理成频数分布表第4章数据的概括性度量一组数据的分布特征可以从哪几个方面进行测度数据分布特征可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或集中的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态.怎样理解平均数在统计学中的地位平均数在统计学中具有重要的地位,是集中趋势的最主要的测度,主要适用于数值型数据,而不适用于分类数据和顺序数据.简述四分位数的计算方法.四分位数是一组数据排序后处于25%和75%位置上的值.根据未分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数值就是四分位数.第七章思考题估计量:用于估计总体参数的随机变量估计值:估计参数时计算出来的统计量的具体值评价估计量的标准:无偏性:估计量抽样分布的数学期望等于被估计的总体参数有效性:对同一总体参数的两个无偏点估计量,有更小标准差的估计量更有效一致性:随着样本容量的增大,估计量的值越来越接近被估计的总体参数置信区间:由样本统计量所构造的总体参数的估计区间第8章思考题假设检验和参数估计有什么相同点和不同点答:参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,然而推断的角度不同.参数估计讨论的是用样本统计量估计总体参数的方法,总体参数μ在估计前是未知的.而在参数假设检验中,则是先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立.什么是假设检验中的显着性水平统计显着是什么意思答:显着性水平是一个统计专有名词,在假设检验中,它的含义是当原假设正确时却被拒绝的概率和风险.统计显着等价拒绝H0,指求出的值落在小概率的区间上,一般是落在或比更小的显着水平上.什么是假设检验中的两类错误答:假设检验的结果可能是错误的,所犯的错误有两种类型,一类错误是原假设H0为真却被我们拒绝了,犯这种错误的概率用α表示,所以也称α错误或弃真错误;另一类错误是原假设为伪我们却没有拒绝,犯这种错误的概论用β表示,所以也称β错误或取伪错误.第10章思考题什么是方差分析它研究的是什么答:方差分析就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显着影响.它所研究的是非类型自变量对数值型因变量的影响.要检验多个总体均值是否相等时,为什么不作两两比较,而用方差分析方法答:作两两比较十分繁琐,进行检验的次数较多,随着增加个体显着性检验的次数,偶然因素导致差别的可能性也会增加.而方差分析方法则是同时考虑所有的样本,因此排除了错误累积的概率,从而避免拒绝一个真实的原假设.方差分析包括哪些类型它们有何区别答:方差分析可分为单因素方差分析和双因素方差分析.区别:单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响,而双因素涉及两个分类型自变量.第13章思考题简述时间序列的构成要素.时间序列的构成要素:趋势,季节性,周期性,随机性利用增长率分析时间序列时应注意哪些问题.(1)当时间序列中的观察值出现0或负数时,不宜计算增长率;(2)不能单纯就增长率论增长率,要注意增长率与绝对水平的综合分析;大的增长率背后,其隐含的绝对值可能很小,小的增长率背后其隐含的绝对值可能很大.简述平稳序列和非平稳序列的含义.1.平稳序列(stationary series)基本上不存在趋势的序列,各观察值基本上在某个固定的水平上波动或虽有波动,但并不存在某种规律,而其波动可以看成是随机的2.非平稳序列 (non-stationary series)是包含趋势、季节性或周期性的序列,它可能只含有其中的一种成分,也可能是几种成分的组合.因此,非平稳序列又可以分为有趋势的序列、有趋势和季节性的序列、几种成分混合而成的复合型序列.第14章思考题解释指数的含义.答:指数最早起源于测量物价的变动.广义上,是指任何两个数值对比形成的相对数;狭义上,是指用于测定多个项目在不同场合下综合变动的一种特殊相对数.实际应用中使用的主要是狭义的指数.加权综合指数和加权平均指数有何区别与联系加权综合指数:通过加权来测定一组项目的综合变动,有加权数量指数和加权质量指数.使用条件:必须掌握全面数据(数量指数,测定一组项目的数量变动,如产品产量指数,商品销售量指数等)(质量指数,测定一组项目的质量变动,如价格指数、产品成本指数等)拉式公式:将权数的各变量值固定在基期.帕式公式:把作为权数的变量值固定在报告期.加权平均指数:以某一时期的总量为权数对个体指数加权平均.使用条件:可以是全面数据、不完全数据.因权数所属时期的不同,有不同的计算形式.有:算术平均形式、调和平均形解释零售价格指数、消费价格指数、生产价格指数、股票价格指数.答:零售价格指数:反映城乡商品零售价格变动趋势的一种经济指数.消费价格指数:反映一定时期内消费者所购买的生活消费品价格和服务项目价格的变动趋势和程度的一种相对数.生产价格指数: 测量在初级市场上出售的货物(即在非零售市场上首次购买某种商品时) 的价格变动的一种价格指数.股票价格指数:反映某一股票市场上多种股票价格变动趋势的一种相对数,简称股价指数.其单位一般用“点”(point)表示,即将基期指数作为100,每上升或下降一个单位称为“1点”.。
人卫第七版医学统计学课后答案及解析-李康、贺佳主编
人卫第七版医学统计学课后答案李康、贺佳主编第一章绪论一、单项选择题答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A 8. C 9. E 10. D11、E 12、C 13、E 14、A 15、C二、简答题1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。
2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。
统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。
统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。
3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。
4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。
5答系统误差、随机测量误差、抽样误差。
系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。
第二章定量数据的统计描述一、单项选择题答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E 8. D 9. B 10. E 11、D 12、E 13、E 14、C 15、E二、计算与分析第三章正态分布与医学参考值范围一、单项选择题答案 1. A 2. B 3. B 4. C 5. D 6. D 7. C 8. E 9. B 10. A11、E 12、C 13、C 14、B 15、A二、计算与分析2[参考答案] 题中所给资料属于正偏态分布资料,所以宜用百分位数法计算其参考值范围。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
定性数据分析第五章课后答案
定性数据分析第五章课后作业
1、为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老年人中作调查。
调查数据如下:
试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问题,你有什么看法?为什么?解:(1)数据压缩分析首先将上表中不同年龄段的数据合并在一起压缩成二维2X2列联表1.1,合起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异?
表1.1 “性别X偏好饮料”列联表
二维2X2列联表独立检验的似然比检验统计量-2ln A的值为0.7032, P值为p=P(x2⑴m0.7032)=0.4017>0.05,不应拒绝原假设,即认为“偏好类型”与“性别”无关。
(2)数据分层分析
其次,按年龄段分层,得到如下三维2X2X2列联表1.2,分开来看,男性和女性对这两种类型的饮料的偏好有没有差异?
表1.2三维2X2X2列联表
在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调查,在“年青人”年龄段,男性中偏好饮料A占58. 73%,偏好饮料B占41.27%;女性中偏好饮料A占58. 73%,偏好饮料B占41.27%, 我们可以得出在这个年龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。
同理,在“老年人”年龄段,也有一定的差异。
(3)条件独立性检验
为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令C表示年龄段,C1表示年青人,C2表示老年人;D表示性别,D1表示男性,D2表示女性;E表示偏好饮料的类型,E1表示偏好饮料A,E2表示偏好饮料B。
欲检验的原假设为:C给定后D和E条件独立。
按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量-2ln A的值如下:
C1层
C2层
-2ln A=6.248 -2ln A =11.822 条件独立性
检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为-2lnA=6.248+11.822=18.07
由于r=c=t=2,所以条件独立性检验的似然比检验统计量的渐近x 2分布的自由度为r(c-l)(t-l)=2,也就是上面这2个四格表的渐近x 2分布的自由度的和。
由于p值P(x 2(2)318.07)=0.000119165很小,所以认为条件独立性不成立,即在年龄段给定的条件下,男性和女性对两种类型的饮料的偏好是有差异的。
(4)产生偏差的原因
a、在(1)中,将不同年龄段的数据压缩在一起合起来后分析发现男性和女性在对两种类型的饮料的偏好上是没有差异的。
但将数据以不同的年龄段
分层后并分别分析发现男性和女性在对两种类型的饮料的偏好上是有一定差异的。
合起来看和分开来看的结果不同。
b、由此看来,年龄段在此次调查中属于混杂因素。
由于不同年龄段的
人对饮料的选择也会有差异,例如现在的年青人偏好喝一些像可口可乐, 美年达等这样的碳酸饮料,而老年人则偏好喝一些红茶,绿茶等这样的非碳酸饮料,在调查中,“老年人”年龄段共有115 A,所占比例大,从而使整个结果就倾向于老年人的观点,即使得混杂因素“年龄段”起到一定的干扰作用,从而导致整个调查结果产生了偏差。
2、某工厂有三个车间。
车间主任分别为王、张和李。
过去的一年里,
该工厂产品的质量情况总结如下:
王主任将内销和外销产品合并在一起,然后计算各个车间的不合格率。
计算结果如下:
王主任说,我负责的车间生产情况最好,其次是李主任负责的车间,最差的是张主任负责的车间。
这样的比较是不是有偏比较?为什么?
解:不是,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题只是将数据压缩起来后相互间比较,因此这样的比较不是有偏比较。
具体分析如下:
由题知,分析车间主任与产品的质量情况之间的关系,则本题是以产品类别为层,以车间主任为行,产品的质量情况为列进行相关分析。
(1)数据压缩分析
首先将上表中不同产品类别的数据合并在一起压缩成二维3X2列联表2.1,合起来看,分析车间主任与产品的质量情况两者之间的关系?
表2.1 “车间主任X产品质量”列联表
可计算出该表独立性检验的似然比检验统计量-2ln A的值为48.612, p
值为p=P(x 2(2)348.612)^0。
应该拒绝原假设,即认为车间主任与产品的质量情况两者是有一定相关性的。
(2)数据分层分析
其次,按产品类别分层,得到如下三维2X3X2列联表2.2,分开来看,分析车间主任与产品的质量情况两者之间的关系?
表1.2三维2X2X2列联表
在上述数据中,分别对两个产品类别(即内销和外销)进行分析,在“内销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓主任车间的不合格率最低,即车间生产情况最好;在“外销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓和李姓主任车间生产情况差不多。
(3)条件独立性检验
为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令A表示产品类别,A1表示内销,A2表示外销;B表示车间主任,B1表示王姓主任,B2表示张姓主任,B3表示李姓主任;C表示产品的质量情况,
欲检验的原假设为:A给定后B和CC1表示合格产品数,C2表示不合格产品数。
条件独立。
按产品类别分层后得到的两张表格,以及它们的似然比检验统计量
A1层
A2层-2lnA=15.289 -2lnA=51.684
条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为
-2lnA=15.289+51.684=66.973
由于c=t=2,r=3,所以条件独立性检验的似然比检验统计量的渐近x 2 分布的
自由度为r(c-l)(t-l)=3,也就是上面这2个表格的渐近x 2分布的自由度的和。
由于p值P(x 2(3)>66.973)R0很小,所以认为条件独立性不成立,即在产品类别给定的条件下,车间主任与产品的质量情况两者是有一定相关性的。
(4)结论
在(1)中,将不同产品类别的数据压缩在一起合起来后分析发现车间主任与产品的质量情况两者是有一定相关性的;在(2)中,将数据以不同的产品类别分层后分析发现车间主任与产品的质量情况两者也是有一定相关性的。
即合起来看和分开来看的结果相同。
据我们所知,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题合起来看和分开来看的结果都是相同的。
因此此题若是分析车间主任与产品的质量情况两者之间的相关关系的话,则该题是无偏的,即不均有有偏性,无法进行有偏比较。