数据挖掘导论课程复习
数据挖掘复习提纲

《数据挖掘》复习提纲第一章数据挖掘概述1、什么是数据挖掘从大量数据中挖掘有用的知识2、数据挖掘的动机数据丰富,信息贫乏3、数据挖掘的同义词从数据中挖掘知识,知识提炼,数据/模式分析,数据考古,数据捕捞、信息收获、资料勘探等等4、知识发现的过程1.数据清理2.数据集成3.数据选择4.数据变换5.数据挖掘6.模式评估7.知识表示5、数据挖掘和知识发现是一回事吗?数据挖掘是知识发现过程的一个步骤6、数据挖掘可以挖掘的两类模式?描述性的数据挖掘,预测性的数据挖掘7、常用的数据挖掘技术?概念/类描述: 特性化和区分,挖掘频繁模式、关联和相关,分类和预,聚类分析,离群点(孤立点)分析,趋势和演变分析8、什么是离群点?离群点总是被抛弃的吗?离群点:一些与数据的一般行为或模型不一致的孤立数据。
通常孤立点被作为“噪音”或异常被丢弃,但在欺骗检测中却可以通过对罕见事件进行孤立点分析而得到结论9、挖掘的所有模式都是有趣的吗?什么样的模式是有趣的?如何度量模式的有趣度?一个数据挖掘系统/查询可以挖掘出数以千计的模式, 并非所有的模式都是有趣的易于理解,在某种必然程度上,对于新的或检验数据是有效的,是潜在有用的,是新颖的,符合用户确信的某种假设客观: 基于模式的统计和结构, 例如, 支持度, 置信度, 等.主观: 基于用户对数据的确信, 例如, 出乎意料, 新颖性, 可行动性等.10、数据挖掘原语类型?任务相关的数据,挖掘的知识类型,背景知识,模式相关度度量,发现模式的可视化第二章数据预处理1、现实世界中的数据是“脏”的,主要体现在哪几个方面?数据为什么脏?不完整、含噪声和不一致不完全数据源于:数据收集时未包含,数据收集和数据分析时的不同考虑.,人/硬件/软件问题噪音数据源于:收集数据的设备可能出现故障,数据输入时人为录入错误,数据传输错误不一致数据源于:不同的数据源,数据代码不一致(日期格式)2、为什么要进行数据预处理?现实世界的数据一般是脏的、不完整的和不一致的。
机器学习及数据挖掘复习

机器学习与数据挖掘复习第一章:Introduction1. 什么是数据挖掘:数据挖掘时从大量的数据中取出令人感兴趣的知识〔令人感兴趣的知识:有效地、新颖的、潜在有用的和最终可以理解的〕。
2. 数据挖掘的分类〔从一般功能上的分类〕:a)描述型数据挖掘〔模式〕:聚类,summarization,关联规那么,序列发现。
b)预测型数据挖掘〔值〕:分类,回归,时间序列分析,预测。
3. KDD〔数据库中的知识发现〕的概念:KDD是一个选择和提取数据的过程,它能自动地发现新的、准确的、有用的模式以及现实世界现象的模型。
数据挖掘是KDD过程的一个主要的组成局部。
4. 用数据挖掘解决实际问题的大概步骤:a)对数据进展KDD过程的处理来获取知识。
b)用知识指导行动。
c)评估得到的结果:好的话就循环使用,不好的话分析、得到问题然后改良。
5. KDD过程中的角色问题:6. 整个KDD过程:a)合并多个数据源的数据。
b)对数据进展选择和预处理。
c)进展数据挖掘过程得到模式或者模型。
d)对模型进展解释和评价得到知识。
第二章数据和数据预处理1. 什么是数据:数据是数据对象和它的属性的集合。
一个属性是一个对象的性质或特性。
属性的集合描述了一个对象。
2. 属性的类型:a)标称〔nominal〕:它的值仅仅是不同的名字,只是提供足够的信息来区分对象。
例如邮政编码、ID、性别。
b)序数:序数属性的值提供足够的信息确定对象的序。
例如硬度、成绩、街道。
c)区间:对于区间属性,值之间的差是有意义的,即存在测量单位。
例如日历日期、温度。
d)比率:对于比率变量,差和比率都是有意义的。
例如绝对温度、年龄、质量、长度。
3. 用值的个数描述属性:a)离散的:离散属性具有有限惑无限可数个值,这样的属性可以是分类的。
b)连续的:连续属性是取实数值的属性。
4. 非对称属性:对于非对称属性,出现非零属性值才是最重要的。
5. 数据集的类型:a)记录型数据:每一个数据对象都是有固定数目的属性组成的。
数据挖掘复习题.doc
1.数据挖掘的定义?从人量的、不完全的、有噪卢的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但乂是潜在有用的信息和知识的过程。
2.数据挖掘的源是否必须是数据仓库的数据?可以宥哪些来源?关系数裾库数据仓库事务数据库高级数据3.数据挖掘的常用方法?聚类分析决策树人工神经网络粗糙集关联规则挖掘统汁分析5.数据挖掘与数据仓库的关系?(联系和区别)联系:数据仓库为数据挖掘提供了更好的、更广泛的数据源; 数裾仓库为数裾挖掘提供了新的支持平台;数据仓库为更好地使川数据挖掘工具提供广A便:数据挖掘为数据仓库提供了更好的决策支持;数据挖掘对数据仓库的数据组织提出了更高的要求;数据挖掘为数裾仓库提供了广泛的技术支持。
区别:数据仓库处存数据,数据挖掘足用数据。
第二章1.数据仓库的定义数据仓库是一个面句主题的、集成的、随吋间而变化的、不容易丢失的数据集合,支持筲理部门的决策制定过程2.数据仓库数据的四大基木特征:面向主题的集成的不可更新的随吋间变化的3.数据仓库体系结构奋3个独立的数据层次:信息获取层、信息存储层、信息传递层4.粒度的定义?它对数据仓库冇什么影响?(1)是指数据仓库的数据单位中保存数据细化或綜合程度的级别。
粒度越小,细节程度越髙,综合程度越低,回答查询的种类就越多;(2)影响存放在数据仓库屮的数据呈大小;影响数裾仓库所能回答查询问题的细节程度。
5.在数据仓庳中,数据按照粒度从小到大可分为死哥级别:早期细节级、当前细节级、轻度细节级和高度细节级。
6.数据分割的标准:可按日期、地域、业务领域、或按多个分割秘准的组合,但一般包栝日期项。
7.数据仓库设计屮,一般存在着三级数据模型:概念数据模型、逻辑数据模型、物理数据模型8.数据仓库涉及步骤概念模型设计、技术准备工作、逻辑模型设计、物理模型设计、数据仓庳的生成、数据仓库的使川和维护9.数据装入吋,并不是•-次就将准备装入的数据全部装入数据仓库,而是按照逻辑模型设计中所确定和分析的主题域,先装入并生成某一主题域。
数据挖掘考试复习资料

数据挖掘考试复习资料一、名词解释1、数据仓库:面向主题的、集成的、非易失的、是随时间变化的数据集合,用来支持管理决策.2、聚类:将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类3、数据挖掘:从大量的数据中挖掘那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识4、人工神经网络:人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
在工程与学术界也常直接简称为神经网络或类神经网络.5、文本挖掘:文本数据挖掘(Text Mining)是指从文本数据中抽取有价值的信息和知识的计算机处理技术6、OLAP:又称联机分析处理,是使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业为特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
定义1:OLAP是针对特定问题的联机数据访问和分析。
通过对信息(维数据)的多种可能的观察形式进行快速、稳定一致和交互性的存取,允许管理决策人员对数据进行深入地观察。
定义2:OLAP是使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业“维”特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
)7、概念描述:就是对目标类对象的内涵进行描述,并概括这类对象的有关特征.特征化:提供给定数据汇集的简洁汇总比较:提供两个或多个数据汇集的比较描述8、信息熵:在信息论中,熵被用来衡量一个随机变量出现的期望值.它代表了在被接收之前,信号传输过程中损失的信息量,又被称为信息熵。
信息熵也称信源熵、平均自信息量。
二、简答题1、数据仓库和传统数据库的区别和联系是什么?(1)区别:数据仓库和数据库是不同的概念数据仓库是一个综合的解决方案,而数据库只是一个现成的产品。
数据仓库需要一个功能十分强大的数据库引擎来驱动,它更偏向于工程。
数据挖掘复习

数据挖掘复习第五章⼤型数据库中的关联规则挖掘1.什么是关联规则挖掘?从事物数据库,关系数据库和其他信息存储中的⼤量数据的项集之间发现有趣的、频繁出现的模式、关联和相关性。
2.为什么要进⾏关联规则挖掘?(动机)发现数据中的规律性。
3.为什么频繁模式挖掘是数据挖掘的基本任务?频繁模式挖掘是许多基本的数据挖掘任务的基础,应⽤⼴泛。
4.⼤型数据库中的关联规则挖掘的过程?①找出所有频繁项集(⼤部分计算集中在这⼀步)②由频繁项集产⽣强关联规则(即满⾜最⼩⽀持度和最⼩置信度的规则) 5.关联规则的分类?①根据规则中所处理的值类型布尔关联规则,量化关联规则②根据规则中设计的数据维单维关联规则,多维关联规则③根据规则集所涉及的抽象层单层关联规则,多层关联规则④根据关联挖掘的各种扩充挖掘最⼤的频繁模式,挖掘频繁闭项集 6.关联规则如何产⽣?(基于Apriori 算法)①对于每个频繁项集l ,产⽣I 的所有⾮空⼦集②对于每个⾮空⼦集s ,如果confs count port l count m in_)(_sup )(_support≥,则输出规则)(s l s -?7.如何提⾼Apriori 算法的有效性?①基于hash 表的项集计数②事务压缩③划分④选样⑤动态项集计数8.Apriori-候选产⽣-检查⽅法优缺点?优:⼤幅度压缩了候选项集的⼤⼩,导致好的性能缺:可能产⽣⼤量的候选项集,可能需要重复扫描数据库,通过模式匹配检查⼀个很⼤的候选集合,对候选项集的⽀持度计算⼗分繁琐 9.FP-树挖掘过程?①为FP 树的每⼀个节点构建条件模式基②从每⼀个条件模式基中构建条件FP 树③递归挖掘条件FP 树,增加频繁模式使其包含两个路径 10.FP 树结构的优点?①完备性:保留了频繁模式挖掘的完整信息;从不打扰任何事务中的⼀个长模式②紧凑性:减少⽆关信息-不频繁项去除;频率的降序排列:更多的频繁项更易被共享;绝不⽐源数据库规模⼤(③分治:根据已经得到的频繁模式划分任务和数据库;导致较⼩的数据库的聚焦的搜索④其他:没有候选产⽣,没有候选测试;压缩数据库;不重复的扫描整个数据库;基本操作-局部频繁项计数和建⽴⼦fp 树结构,没有模式搜索和匹配)填空:1.频繁模式:在数据库中频繁出现的模式(项集,序列等)。
数据挖掘课程复习提纲(4 0)资料

数据挖掘课程复习提纲(4+0)有关考试题型:一、选择题(每题2 分,共16 分)二、判断题(每题1 分,共10 分)三、填空题(每空1 分,共19 分)四、简答题(每题5 分,共15 分)五、计算题(每题10 分,共40 分)基本要求:掌握数据预处理、分类、聚类、关联分析、离群点检测的基本方法,及每类方法的应用场景(每类方法理解、熟悉一个例子)。
算法重点掌握k-means、一趟聚类、Appriori 及基于密度的离群点检测方法;掌握决策树分类(C4.5、CART)、KNN分类的基本思想,基于聚类的离群点检测方法的思想。
第一章绪论1 数据挖掘的定义技术层面:数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中、人们事先不知道的、但又潜在有用的信息和知识的过程。
商业层面:数据挖掘是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助商业决策的关键性数据。
2 数据挖掘的任务预测任务:根据其它属性的值预测特定(目标)属性的值,如回归、分类、异常检测。
描述任务:寻找概括数据中潜在联系的模式,如关联分析、聚类分析、序列模式挖掘。
●聚类(Clustering)分析“物以类聚,人以群分”。
聚类分析技术试图找出数据集中数据的共性和差异,并将具有共性的对象聚合在相应的簇中。
聚类分析可以帮助判断哪些组合更有意义,聚类分析已广泛应用于客户细分、定向营销、信息检索等领域。
●分类(Classification)分析分类分析就是通过分析示例数据库中的数据,为每个类别做出准确的描述,或建立分析模型,或挖掘出分类规则,然后用这个分类模型或规则对数据库中的其它记录进行分类。
分类分析已广泛应用于用户行为分析(受众分析)、风险分析、生物科学等领域。
聚类与分类的区别聚类问题是无指导的:没有预先定义的类。
分类问题是有指导的:预先定义有类。
●关联(Association)分析关联分析是发现特征之间的相互依赖关系,通常是在给定的数据集中发现频繁出现的模式知识(又称为关联规则)。
数据挖掘概论(复习大纲)
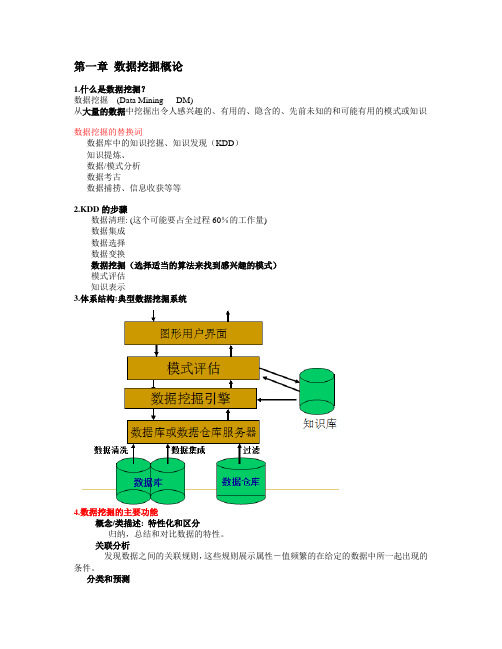
第一章数据挖掘概论1.什么是数据挖掘?数据挖掘(Data Mining DM)从大量的数据中挖掘出令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识数据挖掘的替换词数据库中的知识挖掘、知识发现(KDD)知识提炼、数据/模式分析数据考古数据捕捞、信息收获等等2.KDD的步骤数据清理: (这个可能要占全过程60%的工作量)数据集成数据选择数据变换数据挖掘(选择适当的算法来找到感兴趣的模式)模式评估知识表示3.体系结构:典型数据挖掘系统4.数据挖掘的主要功能概念/类描述: 特性化和区分归纳,总结和对比数据的特性。
关联分析发现数据之间的关联规则,这些规则展示属性-值频繁的在给定的数据中所一起出现的条件。
分类和预测通过构造模型(或函数)用来描述和区别类或概念,用来预测类型标志未知的对象类。
聚类分析将类似的数据归类到一起,形成一个新的类别进行分析。
孤立点分析通常孤立点被作为“噪音”或异常被丢弃,但在欺骗检测中却可以通过对罕见事件进行孤立点分析而得到结论。
趋势和演变分析描述行为随时间变化的对象的发展规律或趋势5.数据挖掘系统与DB或DW系统的集成方式不耦合松散耦合半紧密耦合紧密耦合概念P23第三章数据仓库和OLAP技术1.什么是数据仓库?数据仓库的定义很多,但却很难有一种严格的定义.“数据仓库是一个面向主题的、集成的、随时间而变化的、不容易丢失的数据集合,支持管理部门的决策过程.”—W. H. Inmon(数据仓库构造方面的领头设计师)2.数据仓库关键特征数据仓库关键特征一——面向主题数据仓库关键特征二——数据集成数据仓库关键特征三——随时间而变化数据仓库关键特征四——数据不易丢失3.数据仓库与异种数据库集成传统的异种数据库集成:在多个异种数据库上建立包装程序和中介程序采用查询驱动方法——当从客户端传过来一个查询时,首先使用元数据字典将查询转换成相应异种数据库上的查询;然后,将这些查询映射和发送到局部查询处理器缺点:复杂的信息过虑和集成处理,竞争资源数据仓库: 采用更新驱动将来自多个异种源的信息预先集成,并存储在数据仓库中,供直接查询和分析高性能.4.从关系表和电子表格到数据立方体数据仓库和数据仓库技术基于多维数据模型。
数据挖掘复习知识点整理
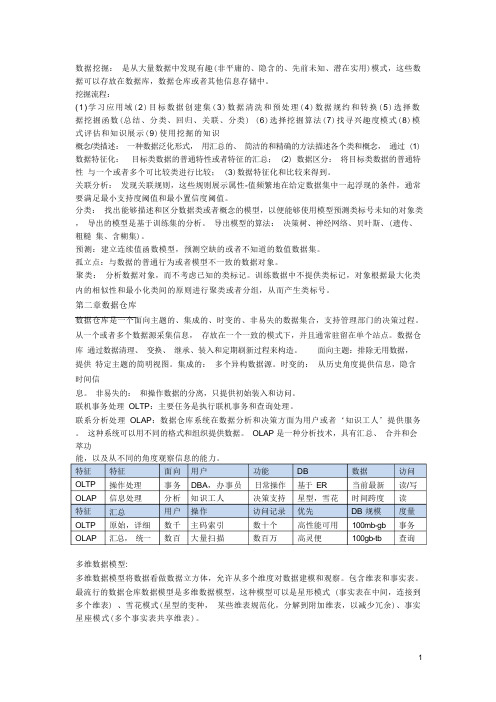
数据挖掘:是从大量数据中发现有趣(非平庸的、隐含的、先前未知、潜在实用)模式,这些数据可以存放在数据库,数据仓库或者其他信息存储中。
挖掘流程:(1)学习应用域(2)目标数据创建集(3)数据清洗和预处理(4)数据规约和转换(5)选择数据挖掘函数(总结、分类、回归、关联、分类) (6)选择挖掘算法(7)找寻兴趣度模式(8)模式评估和知识展示(9)使用挖掘的知识概念/类描述:一种数据泛化形式,用汇总的、简洁的和精确的方法描述各个类和概念,通过 (1) 数据特征化:目标类数据的普通特性或者特征的汇总; (2) 数据区分:将目标类数据的普通特性与一个或者多个可比较类进行比较; (3)数据特征化和比较来得到。
关联分析:发现关联规则,这些规则展示属性-值频繁地在给定数据集中一起浮现的条件,通常要满足最小支持度阈值和最小置信度阈值。
分类:找出能够描述和区分数据类或者概念的模型,以便能够使用模型预测类标号未知的对象类,导出的模型是基于训练集的分析。
导出模型的算法:决策树、神经网络、贝叶斯、(遗传、粗糙集、含糊集)。
预测:建立连续值函数模型,预测空缺的或者不知道的数值数据集。
孤立点:与数据的普通行为或者模型不一致的数据对象。
聚类:分析数据对象,而不考虑已知的类标记。
训练数据中不提供类标记,对象根据最大化类内的相似性和最小化类间的原则进行聚类或者分组,从而产生类标号。
第二章数据仓库数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理部门的决策过程。
从一个或者多个数据源采集信息,存放在一个一致的模式下,并且通常驻留在单个站点。
数据仓库通过数据清理、变换、继承、装入和定期刷新过程来构造。
面向主题:排除无用数据,提供特定主题的简明视图。
集成的:多个异构数据源。
时变的:从历史角度提供信息,隐含时间信息。
非易失的:和操作数据的分离,只提供初始装入和访问。
联机事务处理OLTP:主要任务是执行联机事务和查询处理。
联系分析处理OLAP:数据仓库系统在数据分析和决策方面为用户或者‘知识工人’提供服务。