数据挖掘复习题和答案
数据挖掘-题库带答案

数据挖掘-题库带答案1、最早提出“大数据”时代到来的是全球知名咨询公司麦肯锡()答案:正确2、决策将日益基于数据和分析而作出,而并非基于经验和直觉()答案:错误解析:决策将日益基于数据和分析而作出,而并非基于经验和直觉3、2011年被许多国外媒体和专家称为“大数据元年”()答案:错误解析:2013年被许多国外媒体和专家称为“大数据元年”4、我国网民数量居世界之首,每天产生的数据量也位于世界前列()答案:正确5、商务智能的联机分析处理工具依赖于数据库和数据挖掘。
()答案:错误解析:商务智能的联机分析处理工具依赖于数据仓库和多维数据挖掘。
6、数据整合、处理、校验在目前已经统称为 EL()答案:错误解析:数据整合、处理、校验在目前已经统称为 ETL7、大数据时代的主要特征()A、数据量大B、类型繁多C、价值密度低D、速度快时效高答案: ABCD8、下列哪项不是大数据时代的热门技术()A、数据整合B、数据预处理C、数据可视化D、 SQL答案: D9、()是一种统计或数据挖掘解决方案,包含可在结构化和非结构化数据中使用以确定未来结果的算法和技术。
A、预测B、分析C、预测分析D、分析预测答案: C10、大数据发展的前提?答案:解析:硬件成本的降低,网络带宽的提升,云计算的兴起,网络技术的发展,智能终端的普及,电子商务、社交网络、电子地图等的全面应用,物联网的兴起11、调研、分析大数据发展的现状与应用领域。
?答案:解析:略12、大数据时代的主要特征?答案:解析:数据量大(Volume)第一个特征是数据量大。
大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。
类型繁多(Variety)第二个特征是数据类型繁多。
包括网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
价值密度低(Value)第三个特征是数据价值密度相对较低。
如随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值“提纯”,是大数据时代亟待解决的难题。
历年数据挖掘期末考试试题及答案

历年数据挖掘期末考试试题及答案2019年春选择题1. 关于数据挖掘下列叙述中,正确的是:- A. 数据挖掘只是寻找数据中的有用信息- B. 数据挖掘就是将数据放置于数据仓库中,方便查询- C. 数据挖掘是指从大量有噪音数据中提取未知、隐含、先前未知的、重要的、可理解的模式或知识- D. 数据挖掘就是从数据中提取出数值型变量2. 下列关于聚类分析的说法中,正确的是:- A. 聚类分析是无监督研究- B. 聚类分析的目的是找到一组最优特征- C. 聚类分析只能用于数值型变量- D. 聚类分析是一种监督研究方法3. 一般的数据挖掘流程包括以下哪些步骤:- A. 数据采集- B. 数据清洗- C. 数据转换- D. 模型构建- E. 模型评价- F. 模型应用- G. A、B、C、D、E- H. A、B、C、D、E、F- I. B、C、D、E、F- J. C、D、E、F简答题1. 什么是数据挖掘?介绍一下数据挖掘的流程。
数据挖掘是从庞大、复杂的数据集中提取有价值的、对决策有帮助的信息。
包括数据采集、数据清洗、数据转换、模型构建、模型评价和模型应用等步骤。
2. 聚类分析和分类分析有什么不同?聚类分析和分类分析都是数据挖掘的方法,不同的是聚类分析是无监督研究,通过相似度,将数据集分为不同的组;分类分析是监督研究,通过已知的训练集数据来预测新的数据分类。
也就是说在分类中有“标签”这个中间过程。
3. 请介绍一个你知道的数据挖掘算法,并简单阐述它的流程。
Apriori算法:是一种用于关联规则挖掘的算法。
主要流程包括生成项集、计算支持度、生成候选规则以及计算可信度四步。
首先生成单个项集,计算各项集在数据集中的支持度;然后根据单个项集生成项集对,计算各项集对在数据集中的支持度;接着从项集对中找出支持度大于某个阈值的,生成候选规则;最后计算规则的置信度,保留置信度大于某个阈值的规则作为关联规则。
数据挖掘考试题库及答案

数据挖掘考试题库及答案一、选择题1. 数据挖掘是从大量数据中提取有价值信息的过程,以下哪项不是数据挖掘的主要任务?A. 预测B. 分类C. 聚类D. 数据可视化答案:D2. 以下哪种技术不属于数据挖掘的常用方法?A. 决策树B. 支持向量机C. 关联规则D. 数据仓库答案:D3. 数据挖掘中,以下哪项技术常用于分类和预测?A. 神经网络B. K-均值聚类C. 主成分分析D. 决策树答案:D4. 在数据挖掘中,以下哪个概念表示数据集中的属性?A. 数据项B. 数据记录C. 数据属性D. 数据集答案:C5. 数据挖掘中,以下哪个算法用于求解关联规则?A. Apriori算法B. ID3算法C. K-Means算法D. C4.5算法答案:A二、填空题6. 数据挖掘的目的是从大量数据中提取______信息。
答案:有价值7. 在数据挖掘中,分类任务分为有监督学习和______学习。
答案:无监督8. 决策树是一种用于分类和预测的树形结构,其核心思想是______。
答案:递归划分9. 关联规则挖掘中,支持度表示某个项集在数据集中的出现频率,置信度表示______。
答案:包含项集的记录中同时包含结论的记录的比例10. 数据挖掘中,聚类分析是将数据集划分为若干个______的子集。
答案:相似三、判断题11. 数据挖掘只关注大量数据中的异常值。
()答案:错误12. 数据挖掘是数据仓库的一部分。
()答案:正确13. 决策树算法适用于处理连续属性的分类问题。
()答案:错误14. 数据挖掘中的聚类分析是无监督学习任务。
()答案:正确15. 关联规则挖掘中,支持度越高,关联规则越可靠。
()答案:错误四、简答题16. 简述数据挖掘的主要任务。
答案:数据挖掘的主要任务包括预测、分类、聚类、关联规则挖掘、异常检测等。
17. 简述决策树算法的基本原理。
答案:决策树算法是一种自顶向下的递归划分方法。
它通过选择具有最高信息增益的属性进行划分,将数据集划分为若干个子集,直到满足停止条件。
(完整word版)数据挖掘题目及答案

(完整word版)数据挖掘题⽬及答案⼀、何为数据仓库?其主要特点是什么?数据仓库与KDD的联系是什么?数据仓库是⼀个⾯向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,⽤于⽀持管理决策。
特点:1、⾯向主题操作型数据库的数据组织⾯向事务处理任务,各个业务系统之间各⾃分离,⽽数据仓库中的数据是按照⼀定的主题域进⾏组织的。
2、集成的数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加⼯、汇总和整理得到的,必须消除源数据中的不⼀致性,以保证数据仓库内的信息是关于整个企业的⼀致的全局信息。
3、相对稳定的数据仓库的数据主要供企业决策分析之⽤,⼀旦某个数据进⼊数据仓库以后,⼀般情况下将被长期保留,也就是数据仓库中⼀般有⼤量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
4、反映历史变化数据仓库中的数据通常包含历史信息,系统记录了企业从过去某⼀时点(如开始应⽤数据仓库的时点)到⽬前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
所谓基于数据库的知识发现(KDD)是指从⼤量数据中提取有效的、新颖的、潜在有⽤的、最终可被理解的模式的⾮平凡过程。
数据仓库为KDD提供了数据环境,KDD从数据仓库中提取有效的,可⽤的信息⼆、数据库有4笔交易。
设minsup=60%,minconf=80%。
TID DATE ITEMS_BOUGHTT100 3/5/2009 {A, C, S, L}T200 3/5/2009 {D, A, C, E, B}T300 4/5/2010 {A, B, C}T400 4/5/2010 {C, A, B, E}使⽤Apriori算法找出频繁项集,列出所有关联规则。
解:已知最⼩⽀持度为60%,最⼩置信度为80%1)第⼀步,对事务数据库进⾏⼀次扫描,计算出D中所包含的每个项⽬出现的次数,⽣成候选1-项集的集合C1。
数据挖掘 习题及参考答案

①电信行业中利用数据挖掘技术进行客户行为分析,包含客户通话记录、通话时间、所 开通的服务等,据此进行客户群体划分以及客户流失性分析。
②天文领域中利用决策树等数据挖掘方法对上百万天体数据进行分类与分析,帮助天文 学家发现其他未知星体。
③制造业中应用数据挖掘技术进行零部件故障诊断、资源优化、生产过程分析等。
第 4 页 共 27 页
(b)对于数据平滑,其它方法有: (1)回归:可以用一个函数(如回归函数)拟合数据来光滑数据; (2)聚类:可以通过聚类检测离群点,将类似的值组织成群或簇。直观地,落在簇集合 之外的值视为离群点。
2.6 使用习题 2.5 给出的 age 数据,回答以下问题: (a) 使用 min-max 规范化,将 age 值 35 转换到[0.0,1.0]区间。 (b) 使用 z-score 规范化转换 age 值 35,其中,age 的标准偏差为 12.94 年。 (c) 使用小数定标规范化转换 age 值 35。 (d) 指出对于给定的数据,你愿意使用哪种方法。陈述你的理由。
回归来建模,或使用时间序列分析。 (7) 是,需要建立正常心率行为模型,并预警非正常心率行为。这属于数据挖掘领域
的异常检测。若有正常和非正常心率行为样本,则可以看作一个分类问题。 (8) 是,需要建立与地震活动相关的不同波形的模型,并预警波形活动。属于数据挖
掘领域的分类。 (9) 不是,属于信号处理。
1.6 根据你的观察,描述一个可能的知识类型,它需要由数据挖掘方法发现,但本章未列出。 它需要一种不同于本章列举的数据挖掘技术吗?
答:建立一个局部的周期性作为一种新的知识类型,只要经过一段时间的偏移量在时间序列 中重复发生,那么在这个知识类型中的模式是局部周期性的。需要一种新的数据挖掘技 术解决这类问题。
数据挖掘习题及解答-完美版
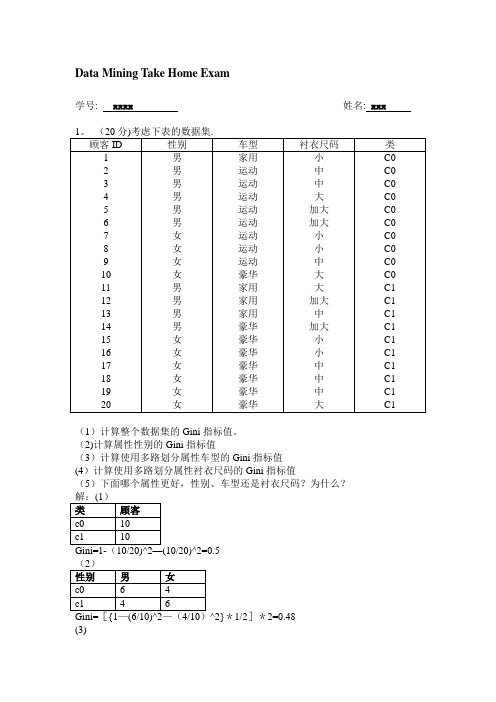
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?^2}*1/2]*2=0.48(3)—(8/8)^2-(0/8)^2}*8/20+{1—(1/8)^2—(7/8)^2}*8/20=26/160=0。
16254/7)^2}*7/20+[{1—(2/4)^2—(2/4)^2}*4/20]*2=8/25+6/35=0。
4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0。
1625最小,即使用车型属性更好。
2。
((1)将每个事务ID视为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度.(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0). (4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0。
8;{b,d}的支持度为2/10=0。
2;{b,d,e}的支持度为2/10=0。
2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0。
8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)〉anova(ls1)Df Sum Sq Mean Sq F value Pr(〉F)x1 1 10021.2 10021.2 62。
数据挖掘测试题及答案
数据挖掘测试题及答案一、选择题1. 数据挖掘的目的是:A. 数据清洗B. 数据转换C. 模式发现D. 数据存储答案:C2. 以下哪项不是数据挖掘的常用算法?A. 决策树B. 聚类分析C. 线性回归D. 关联规则答案:C二、填空题1. 数据挖掘中的_________是指在大量数据中发现的有意义的模式。
答案:知识2. 一种常用的数据挖掘技术是_________,它用于发现数据中隐藏的分组。
答案:聚类三、简答题1. 简述数据挖掘与数据分析的区别。
答案:数据挖掘是一种自动或半自动的过程,旨在从大量数据中发现模式和知识。
数据分析通常涉及更具体的查询和问题,使用统计方法来理解数据。
2. 描述什么是关联规则挖掘,并给出一个例子。
答案:关联规则挖掘是一种用于发现变量之间有趣关系的技术,特别是变量之间的频繁模式、关联或相关性。
例如,在市场篮子分析中,关联规则挖掘可以用来发现顾客购买行为中的模式,如“购买面包的顾客中有80%也购买了牛奶”。
四、计算题1. 给定以下数据集,计算支持度和置信度:| 事务ID | 购买的商品 |||-|| 1 | A, B || 2 | A, C || 3 | B, C || 4 | A, B, C || 5 | B, D |(1) 计算项集{A}的支持度。
(2) 计算规则A => B的置信度。
答案:(1) 项集{A}的支持度为4/5,因为A出现在4个事务中。
(2) 规则A => B的置信度为3/4,因为A和B同时出现在3个事务中,而A出现在4个事务中。
五、论述题1. 论述数据挖掘在电子商务中的应用,并给出至少两个具体的例子。
答案:数据挖掘在电子商务中的应用非常广泛,包括:- 客户细分:通过数据挖掘技术,商家可以识别不同的客户群体,为每个群体提供定制化的服务或产品。
- 推荐系统:利用关联规则挖掘,电商平台可以推荐用户可能感兴趣的商品,提高用户满意度和购买率。
- 欺诈检测:通过分析交易模式,数据挖掘可以帮助识别异常行为,预防信用卡欺诈等风险。
数据挖掘试题
数据挖掘试题及答案
1.数据挖掘的定义是什么?
数据挖掘是指从大量数据中通过算法自动发现和提取有用的信息,并对其进行分析和解释,以帮助企业做出决策的过程。
1.数据挖掘的主要任务是什么?
数据挖掘的主要任务包括关联分析、聚类分析、分类和预测、偏差检测等。
1.什么是关联分析?
关联分析是指通过发现大量数据中项集之间的关联性或相关性来进行分析的一种方法。
常见的关联分析算法有Apriori算法和FP-Growth算法。
1.什么是聚类分析?
聚类分析是指将物理或抽象对象组成的多个组或类按照它们的相似性进行分类。
聚类分析的目标是将相似的对象归为一类,同时将不相似或不同的对象分离出来。
1.什么是分类和预测?
分类是指根据历史数据和经验建立模型,然后使用该模型对新的未知数据进行预测或分类。
预测则是利用已知的变量和参数来预测未来的结果或趋势。
1.什么是偏差检测?
偏差检测是指通过检测数据中的异常值、离群点或不寻常的模式来发现异常情况或错误的过程。
偏差检测可以帮助企业发现数据中的问题和不一致性,及时纠正错误或采取相应措施。
数据挖掘习题及解答-完美版
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
数据挖掘期末考试试题及答案详解
数据挖掘期末考试试题及答案详解一、选择题(每题2分,共20分)1. 数据挖掘中,关联规则分析主要用于发现数据中的哪种关系?A. 因果关系B. 相关性C. 聚类关系D. 顺序关系答案:B2. 在决策树算法中,哪个指标用于评估特征的重要性?A. 信息增益B. 支持度C. 置信度D. 覆盖度答案:A3. 以下哪个是数据挖掘的常用方法?A. 线性回归B. 逻辑回归C. 神经网络D. 所有选项答案:D4. K-means聚类算法中,K值的选择是基于什么?A. 数据的维度B. 聚类中心的数量C. 数据的分布情况D. 数据的规模答案:B5. 以下哪个是数据挖掘中常用的数据预处理技术?A. 数据清洗B. 数据转换C. 数据归一化D. 所有选项答案:D...(此处省略其他选择题)二、简答题(每题10分,共30分)1. 简述什么是数据挖掘,并列举其主要的应用领域。
答案:数据挖掘是从大量数据中自动或半自动地发现有趣模式的过程。
它主要应用于市场分析、风险管理、欺诈检测、客户关系管理等领域。
2. 解释什么是朴素贝叶斯分类器,并说明其在数据挖掘中的应用。
答案:朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。
在数据挖掘中,朴素贝叶斯分类器常用于文本分类、垃圾邮件检测等任务。
3. 描述K-means聚类算法的基本原理,并举例说明其在实际问题中的应用。
答案:K-means聚类算法是一种基于距离的聚类方法,其目标是将数据点划分到K个簇中,使得每个数据点与其所属簇的中心点的距离之和最小。
例如,在市场细分中,K-means聚类可以用来将客户根据购买行为划分为不同的群体。
三、计算题(每题25分,共50分)1. 给定一组数据点:{(1,2), (2,3), (3,4), (4,5)},请使用K-means算法将这些点分为两个簇,并计算簇的中心点。
答案:首先随机选择两个点作为初始中心点,然后迭代地将每个点分配到最近的中心点,接着更新中心点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(
一、考虑表中二元分类问题的训练样本集
1.整个训练样本集关于类属性的熵是多少
2.关于这些训练集中a1,a2的信息增益是多少
3.对于连续属性a3,计算所有可能的划分的信息增益。
4.根据信息增益,a1,a2,a3哪个是最佳划分
5.~
6.根据分类错误率,a1,a2哪具最佳
7.根据gini指标,a1,a2哪个最佳
答1.
P(+) = 4/9 and P(−) = 5/9
−4/9 log(4/9) −5/9 log(5/9) = .
<
答2:
(估计不考)
答3:
} '
答4: According to information gain, a produces the best split.
答5:
<
For attribute a: error rate = 2/9.
For attribute a: error rate = 4/9.
Therefore, according to error rate, a produces the best split.
答6:
'
二、考虑如下二元分类问题的数据集
1.计算信息增益,决策树归纳算法会选用哪个属性
《
2.计算 gini指标,决策树归纳会用哪个属性
这个答案没问题
3.从图4-13可以看出熵和gini指标在[0,]都是单调递增,而[,1]之间单调递减。
有没有可能信息增益和gini
指标增益支持不同的属性解释你的理由
Yes, even though these measures have similar range and monotonous
%
behavior, their respective gains, Δ, which are scaled differences of the
measures, do not necessarily behave in the same way, as illustrated by
the results in parts (a) and (b).
贝叶斯分类
1.P(A = 1|−) = 2/5 = , P(B = 1|−) = 2/5 = ,
,
P(C = 1|−) = 1, P(A = 0|−) = 3/5 = ,
P(B = 0|−) = 3/5 = , P(C = 0|−) = 0; P(A = 1|+) = 3/5 = , P(B = 1|+) = 1/5 = , P(C = 1|+) = 2/5 = ,
P(A = 0|+) = 2/5 = , P(B = 0|+) = 4/5 = ,
P(C = 0|+) = 3/5 = .
2.
3.P(A = 0|+) = (2 + 2)/(5 + 4) = 4/9,
P(A = 0|−) = (3+2)/(5 + 4) = 5/9,
#
P(B = 1|+) = (1 + 2)/(5 + 4) = 3/9,
P(B = 1|−) = (2+2)/(5 + 4) = 4/9,
P(C = 0|+) = (3 + 2)/(5 + 4) = 5/9,
P(C = 0|−) = (0+2)/(5 + 4) = 2/9.
4.Let P(A = 0,B = 1, C = 0) = K
5.当的条件概率之一是零,则估计为使用m-估计概率的方法的条件概率是更好的,因为我们不希望整个表达
式变为零。
》
1.P(A = 1|+) = , P(B = 1|+) = , P(C = 1|+) = , P(A =
1|−) = , P(B = 1|−) = , and P(C = 1|−) =
2.
Let R : (A = 1,B = 1, C = 1) be the test record. To determine its
class, we need to compute P(+|R) and P(−|R). Using Bayes theorem, P(+|R) = P(R|+)P(+)/P(R) and P(−|R) = P(R|−)P(−)/P(R).
Since P(+) = P(−) = and P(R) is constant, R can be classified by
、
comparing P(+|R) and P(−|R).
For this question,
P(R|+) = P(A = 1|+) × P(B = 1|+) × P(C = 1|+) =
P(R|−) = P(A = 1|−) × P(B = 1|−) × P(C = 1|−) =
Since P(R|+) is larger, the record is assigned to (+) class.
3.
P(A = 1) = , P(B = 1) = and P(A = 1,B = 1) = P(A) ×
P(B) = . Therefore, A and B are independent.
\
4.
P(A = 1) = , P(B = 0) = , and P(A = 1,B = 0) = P(A =1)× P(B = 0) = . A and B are still independent.
5.
Compare P(A = 1,B = 1|+) = against P(A = 1|+) = and
P(B = 1|Class = +) = . Since the product between P(A = 1|+)
and P(A = 1|−) are not the same as P(A = 1,B = 1|+), A and B are
not conditionally independent given the class.
·
三、使用下表中的相似度矩阵进行单链和全链层次聚类。
绘制树状况显示结果,树状图应该清楚地显示合并的次序。
【
There are no apparent relationships between s, s, c, and c.
A2: Percentage of frequent itemsets = 16/32 = % (including the null set).
A4: False alarm rate is the ratio of I to the total number of itemsets. Since the count of I = 5, therefore the false alarm rate is 5/32 = %.。