回归中缺失值处理方法
如何处理逻辑回归模型中的缺失值(七)

在数据分析和建模中,缺失值是一个常见的问题。
在逻辑回归模型中,缺失值的处理尤为重要,因为缺失值可能会导致模型的偏差和不准确性。
因此,正确处理逻辑回归模型中的缺失值是非常关键的。
### 理解缺失值首先,我们需要理解什么是缺失值。
缺失值指的是在数据集中某一列中部分观测值缺失的情况。
缺失值可能由于多种原因产生,例如数据采集过程中的错误、调查对象的拒绝回答或者设备故障等。
在实际应用中,缺失值是一个不可避免的问题,因此我们需要学会如何处理它。
### 删除缺失值最简单的处理缺失值的方法是直接删除包含缺失值的观测。
这种方法的优点是简单直接,不需要进行额外的处理。
但是,缺失值的删除会导致数据的丢失,从而可能影响模型的准确性。
因此,这种方法并不是最好的选择。
### 填充缺失值另一种常见的处理方法是填充缺失值。
填充缺失值的方法有很多种,比如用平均值、中位数或者众数来填充;用相邻观测值的值进行填充;或者用机器学习算法来预测缺失值等。
这些方法都有各自的优缺点,在选择填充方法时需要根据具体情况来决定。
### 使用缺失值指示变量另一种处理缺失值的方法是使用缺失值指示变量。
这种方法的思想是将缺失值单独作为一个类别,为其创建一个新的变量。
这样做的好处是能够保留原始数据的信息,同时也能够避免对数据进行填充或删除。
但是,这种方法会增加数据的维度,可能会导致模型的复杂性增加。
### 组合多种方法实际应用中,常常会采用多种方法来处理缺失值。
比如,可以先尝试填充缺失值,然后再用缺失值指示变量来处理剩余的缺失值。
或者可以先删除缺失值较多的观测,再对剩余的缺失值进行填充。
在选择组合方法时,需要综合考虑数据的特点和建模的要求。
### 交叉验证处理缺失值之后,我们需要对模型进行评估。
在逻辑回归模型中,常用的评估方法是交叉验证。
交叉验证能够更客观地评估模型的性能,避免过拟合和欠拟合的问题。
通过交叉验证,我们可以确定模型的准确性和稳定性,从而选择最优的处理缺失值的方法。
如何处理逻辑回归模型中的缺失值(九)

逻辑回归模型是一种用于预测二元变量的统计模型,它在实际应用中通常会遇到数据缺失的情况。
在处理逻辑回归模型中的缺失值时,我们需要采取一些有效的方法来应对。
本文将从几个方面来探讨如何处理逻辑回归模型中的缺失值。
首先,我们需要了解导致数据缺失的原因。
数据缺失可能是由于调查设计上的缺陷、受访者拒绝回答某些问题或者数据录入时的错误等多种原因导致的。
在处理逻辑回归模型中的缺失值时,我们需要分析数据缺失的原因,并根据实际情况采取相应的处理方法。
其次,对于缺失值的处理方法,常见的有三种:删除法、替补法和模型法。
删除法是指直接删除数据中含有缺失值的样本,这种方法简单粗暴,但可能会造成数据量的减少和信息的丢失。
替补法是指用均值、中位数、众数或者其他预测模型的预测值来替换缺失值,这种方法可以保留数据的完整性,但可能会引入预测误差。
模型法是指利用其他变量的信息来预测缺失变量的值,这种方法可以更好地利用数据的信息,但需要建立相应的模型来进行预测。
对于逻辑回归模型来说,缺失值的处理方法需要根据实际情况来确定。
在实际应用中,我们通常会结合不同的方法来处理缺失值,以达到最佳的效果。
例如,对于缺失值较少的变量,可以使用替补法来处理;对于缺失值较多的变量,可以考虑使用模型法来处理。
除了处理缺失值的方法外,我们还需要注意一些细节问题。
例如,在使用替补法处理缺失值时,需要分析替补值的分布是否与原始数据的分布相似;在使用模型法处理缺失值时,需要评估所建立模型的拟合效果和预测准确性。
此外,还需要注意处理后的数据是否符合逻辑回归模型的假设,如变量之间是否存在多重共线性等。
在实际应用中,处理逻辑回归模型中的缺失值是一个复杂而又重要的问题。
我们需要根据实际情况灵活运用不同的处理方法,结合数据的特点和逻辑回归模型的要求,来选择最合适的处理方式。
同时,还需要对处理后的数据进行严格的检验和评估,以确保模型的准确性和稳定性。
总的来说,处理逻辑回归模型中的缺失值是一个需要综合考虑多方面因素的问题。
回归中缺失值处理方法
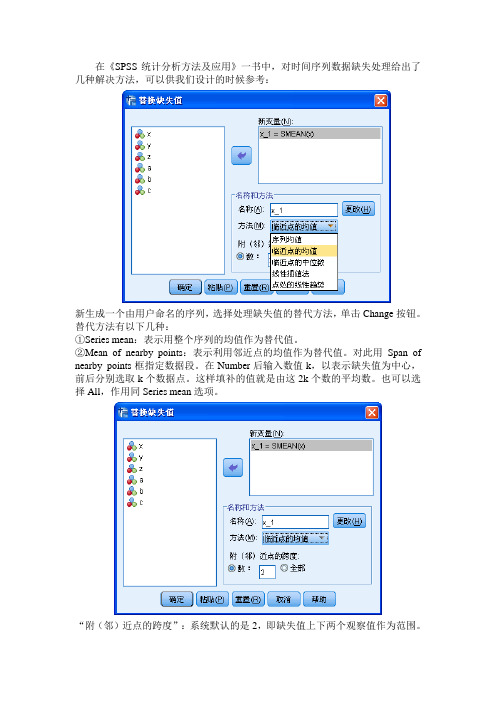
在《SPSS统计分析方法及应用》一书中,对时间序列数据缺失处理给出了几种解决方法,可以供我们设计的时候参考:新生成一个由用户命名的序列,选择处理缺失值的替代方法,单击Change按钮。
替代方法有以下几种:①Series mean:表示用整个序列的均值作为替代值。
②Mean of nearby points:表示利用邻近点的均值作为替代值。
对此用Span of nearby points框指定数据段。
在Number后输入数值k,以表示缺失值为中心,前后分别选取k个数据点。
这样填补的值就是由这2k个数的平均数。
也可以选择All,作用同Series mean选项。
“附(邻)近点的跨度”:系统默认的是2,即缺失值上下两个观察值作为范围。
若选择“全部”,即将所有的观察值作为临近点。
③Median of nearby points:表示利用邻近点的中位数作为替代值。
数据指定方法同上。
④Linear interpolation:为线性插值法,表示利用缺失值前后两时点数据的某种线性组合进行填补,是一种加权平均。
线性插值法应用线性插值法填补缺失值。
用该列数据缺失值前一个数据和后一个数据建立插值直线,然后用缺失点在线性插值函数的函数值填充该缺失值。
如果前后值有一个缺失,则得不到缺失值的替换值。
⑤Linear trend at point:为线性趋势值法,表示利用回归拟合线的拟合值作为替代值。
缺失点处的线性趋势法应用缺失值所在的整个序列建立线性回归方程,然后用该回归方程在缺失点的预测值填充缺失值。
*注意:如果序列的第一个和最后一个数据为缺失值,只能利用序列均值和线性趋势值法处理,其他方法不适用。
缺失值和异常值的处理方法 回归方程

缺失值和异常值的处理方法回归方程导语缺失值和异常值是数据处理过程中常见的问题,对于回归方程的建模和预测结果会产生不良影响,因此如何正确处理缺失值和异常值成为了数据分析领域中的重要课题。
本文将从缺失值和异常值的定义、影响、处理方法和回归方程的应用等方面展开讨论,旨在帮助读者全面理解和掌握相关知识。
一、缺失值和异常值的定义及影响1. 缺失值的定义及影响缺失值是指数据集中的部分观测值因某种原因而缺失的情况,通常用NaN(Not a Number)或空值来表示。
缺失值的存在会导致数据样本减少、统计分析结果不准确以及建模过程失败等问题,严重影响了数据分析的结果和结论的可信度。
2. 异常值的定义及影响异常值(Outlier)是指在数据集中与其他观测值存在显著偏离或差异的数值,通常称之为离群点。
异常值的存在会扭曲数据的分布、影响统计量的计算以及损害模型的准确性,导致建模结果不可靠而无法有效预测。
二、缺失值和异常值的处理方法1. 缺失值的处理方法(1)删除缺失值:当缺失值的比例较低且对整体数据影响不大时,可以选择将含有缺失值的观测样本删除,以保证数据集的完整性和准确性。
(2)填补缺失值:采用均值、中位数、众数等统计量填补缺失值,或者使用插值法、回归模型等进行缺失值的估计。
2. 异常值的处理方法(1)删除异常值:当异常值对数据分析和建模产生严重影响时,可以选择将异常值排除在外,以确保模型的准确性和稳定性。
(2)平滑处理:采用分箱、截尾、转换等方法对异常值进行平滑处理,使得异常值不再对模型产生显著的影响。
三、回归方程在缺失值和异常值处理中的应用1. 缺失值的处理在回归方程中的应用在回归分析中,缺失值的存在会导致数据样本减少,从而影响了回归模型的构建和预测能力。
正确处理缺失值对于回归方程的准确性至关重要。
可以利用各种填补方法进行缺失值的处理,如均值填补、插值法填补等,以确保回归方程基于完整的数据集进行建模。
2. 异常值的处理在回归方程中的应用异常值对回归方程的影响往往较大,会扭曲自变量与因变量之间的关系,导致回归模型的参数估计不准确。
如何处理逻辑回归模型中的缺失值(五)

逻辑回归模型在数据分析和预测中被广泛应用。
然而,在实际应用过程中,我们常常会遇到数据中的缺失值,这些缺失值会对模型的准确性和可靠性造成影响。
因此,如何处理逻辑回归模型中的缺失值成为了一个重要的问题。
本文将从不同的角度探讨如何处理逻辑回归模型中的缺失值,以期为数据分析和模型建立提供一些有益的思路。
首先,我们需要认识到缺失值的存在对逻辑回归模型的影响。
缺失值会造成样本量的减少,从而降低模型的稳定性和可靠性。
此外,如果缺失值的存在与其他变量之间存在相关性,那么忽略缺失值可能会导致模型的偏误。
因此,我们需要在处理逻辑回归模型中的缺失值时,采取一些有效的方法来保证模型的准确性和可靠性。
一种常用的处理缺失值的方法是删除缺失值所在的样本。
这种方法简单直接,但是会造成样本量的减少,从而降低模型的稳定性。
此外,如果缺失值的存在与其他变量之间存在相关性,那么采用删除缺失值的方法可能会导致模型的偏误。
因此,在实际应用中,我们需要谨慎采用删除缺失值的方法,避免对模型造成不利的影响。
另一种处理缺失值的方法是利用均值或中位数来填补缺失值。
这种方法可以保持样本量不变,但是会造成数据的扭曲。
如果数据中存在较多的缺失值,那么利用均值或中位数填补缺失值可能会对模型的准确性造成较大的影响。
因此,在应用中,我们需要根据数据的特点和缺失值的分布情况,来决定是否采用均值或中位数填补缺失值的方法。
还有一种处理缺失值的方法是利用插值法来填补缺失值。
插值法可以利用数据中的相关信息来估计缺失值,从而保持数据的完整性和准确性。
常用的插值方法包括线性插值、多项式插值和样条插值等。
这些方法可以有效地填补缺失值,但是需要根据数据的特点和缺失值的分布情况选择合适的方法。
此外,我们还可以考虑利用机器学习算法来处理逻辑回归模型中的缺失值。
机器学习算法可以利用数据中的相关信息来建立模型,从而预测缺失值。
常用的机器学习算法包括随机森林、支持向量机和神经网络等。
这些算法可以有效地处理逻辑回归模型中的缺失值,但是需要充分考虑模型的准确性和可靠性。
缺失值及其处理方法

缺失值及其处理方法缺失值是指在数据集中出现的空值或不完整的数据。
缺失值具有重要的信息,因此在数据分析和建模过程中需要正确处理。
对于缺失值的处理方法也有很多种,下面将详细介绍。
1.明确缺失值的原因:首先,需要了解缺失值产生的原因,这有助于选择合适的处理方法。
缺失值的原因可能包括数据采集错误、数据传输错误、调查对象拒绝回答等。
2.删除含有缺失值的样本:当数据集中一些变量的缺失值比较少且对整体分析结果影响不大时,可以考虑直接删除含有缺失值的样本。
但需要注意,删除样本可能会引起数据集的偏差,因此在进行删除操作之前,应该评估删除对数据分析结果的影响。
3.删除含有过多缺失值的变量:如果一些变量的缺失值占比较大,超过了一定阈值(例如20%),则可以考虑删除该变量。
删除操作需要谨慎,应该先分析该变量是否对问题的解释有重要作用,再决定是否删除。
4.插值填充缺失值:当数据集中的变量缺失值较多时,可以选择插值方法进行填充。
常用的插值方法包括均值插值、中位数插值、众数插值和回归插值等。
-均值插值:将缺失值用变量的均值填充。
-中位数插值:将缺失值用变量的中位数填充。
-众数插值:将缺失值用变量的众数填充。
-回归插值:通过已有数据拟合回归模型,然后用回归模型预测缺失值。
5.分类变量的处理方法:对于分类变量,可以将缺失值单独作为一类,或者根据其他变量的取值特征进行填充。
-将缺失值单独作为一类:如果缺失值对问题的解释具有特殊意义,可以将缺失值单独作为一类。
-根据其他变量的取值特征进行填充:可以根据其他变量的取值特征进行填充,例如使用频率最高的取值填充缺失值。
6.时间序列数据的处理方法:对于时间序列数据,可以根据已有数据的趋势和周期性进行填充。
-线性插值:通过已有数据拟合线性回归模型,然后使用模型预测缺失值。
-滑动窗口方法:根据一定的窗口大小,对于缺失位置的每一侧,根据已有数据的均值或中位数进行填充。
-季节分解方法:将时间序列数据进行季节分解,然后根据季节分解的结果进行填充。
如何处理逻辑回归模型中的缺失值(四)

在数据分析和建模过程中,缺失值是一个常见的问题,处理好缺失值对模型的准确性和可靠性至关重要。
逻辑回归模型作为一种常用的分类模型,同样需要处理缺失值。
本文将围绕如何处理逻辑回归模型中的缺失值展开讨论。
首先,我们需要了解缺失值在逻辑回归模型中的影响。
逻辑回归模型本质上是一个用于解决二分类问题的模型,它通过对输入特征进行加权求和,并经过一个逻辑函数(如sigmoid函数)得到分类结果。
缺失值会对模型的参数估计和预测产生影响,因此需要进行合理的处理。
一种常见的处理缺失值的方法是删除含有缺失值的样本。
这种方法简单直接,但是会造成样本量的减少,可能会损失一些重要信息。
在逻辑回归模型中,样本量的减少会影响模型参数的稳定性和准确性,因此并不是一个理想的处理方式。
另一种常见的处理方法是使用均值、中位数或众数来填补缺失值。
这种方法适用于数值型特征,可以减少数据的信息损失。
但是需要注意的是,填补缺失值会对数据的分布产生影响,可能会导致模型的偏差增加。
因此在使用这种方法时需要谨慎选择填补值,并进行适当的模型评估。
对于分类型特征,常见的处理方法是使用众数来填补缺失值。
这种方法适用于分类型特征的情况,可以保持数据的离散性。
但是需要注意的是,填补缺失值可能会引入偏差,因此需要谨慎选择填补值。
除了以上介绍的常见方法外,还有一些其他处理缺失值的方法。
例如可以使用回归、随机森林等模型来预测缺失值,或者使用插值法来估计缺失值。
这些方法在一定情况下可以取得较好的效果,但是需要根据具体问题具体分析,选择合适的方法。
在处理缺失值时,需要注意的是不同的处理方法可能会对模型产生不同的影响。
因此在选择处理方法时需要综合考虑数据的特点、模型的需求以及具体的问题背景。
另外,需要注意的是在处理缺失值时需要避免数据泄露的问题,即在填补缺失值时不能使用未来信息。
综上所述,处理逻辑回归模型中的缺失值是一个重要的问题。
合理的处理缺失值能够提高模型的准确性和可靠性,为数据分析和建模提供有力支持。
回归分析中的缺失数据处理方法有哪些?

回归分析中的缺失数据处理方法有哪些?回归分析是一种用于研究变量之间关系的统计分析方法,然而在实际应用中,由于各种原因,我们经常会遇到数据缺失的情况。
当数据中含有缺失值时,会影响回归分析的结果和准确度。
在本文中,我们将介绍几种常用的回归分析中的缺失数据处理方法。
一、删除含有缺失值的样本这是一种简单直接的方法,即将含有缺失值的样本直接删除,只保留完整数据的样本进行分析。
这种方法的优点是简单易行,但缺点也很明显,随着样本数量的减少,分析结果的可靠性也会相应降低。
二、使用均值或中位数填充缺失值这是一种常见的缺失数据处理方法,即用样本的均值或中位数来填充缺失值。
这种方法的优点是简单快捷,可以避免删除样本带来的信息损失,但也存在一定的局限性,特别是当缺失值较多时,用均值或中位数填充可能会引入较大的误差。
三、使用插值法填充缺失值插值法是一种通过已知数据预测未知数据的方法。
在回归分析中,我们可以利用样本中其他变量之间的关系,通过插值法来填充缺失值。
常用的插值方法有线性插值、多项式插值、样条插值等。
这种方法的优点是利用了其他变量之间的相关性,能够更准确地预测缺失值,但也需要注意插值方法的选择和合理性。
四、使用回归模型预测缺失值在回归分析中,我们可以利用已有数据建立回归模型,然后利用该模型来预测缺失值。
这种方法的优点是可以利用其他变量之间的关系,建立更为准确的预测模型,但也需要注意模型自身的准确度和合理性,以及是否存在过拟合等问题。
五、使用专门的缺失数据处理方法除了上述常用的方法外,还有一些专门用于处理缺失数据的方法,如概率校正方法、多重插补方法等。
这些方法在处理缺失数据时能够更为准确地捕捉到缺失值的特点和规律,提高回归分析的结果准确性。
综上所述,回归分析中的缺失数据处理方法有删除含有缺失值的样本、使用均值或中位数填充缺失值、使用插值法填充缺失值、使用回归模型预测缺失值以及使用专门的缺失数据处理方法。
在实际应用中,我们根据数据的具体情况和要求选择合适的方法来处理缺失数据,以提高回归分析的准确度和可靠性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
回归中缺失值处理方法文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
在《SPSS统计分析方法及应用》一书中,对时间序列数据缺失处理给出了几种解决方法,可以供我们设计的时候参考:
新生成一个由用户命名的序列,选择处理缺失值的替代方法,单击Change按钮。
替代方法有以下几种:
①Series mean:表示用整个序列的均值作为替代值。
②Mean of nearby points:表示利用邻近点的均值作为替代值。
对此用Span of nearby points框指定数据段。
在Number后输入数值k,以表示缺失值为中心,前后分别选取k个数据点。
这样填补的值就是由这2k 个数的平均数。
也可以选择All,作用同Series mean选项。
“附(邻)近点的跨度”:系统默认的是2,即缺失值上下两个观察值作为范围。
若选择“全部”,即将所有的观察值作为临近点。
③Median of nearby points:表示利用邻近点的中位数作为替代值。
数据指定方法同上。
④Linear interpolation:为线性插值法,表示利用缺失值前后两时点数据的某种线性组合进行填补,是一种加权平均。
线性插值法应用线性插值法填补缺失值。
用该列数据缺失值前一个数据和后一个数据建立插值直线,然后用缺失点在线性插值函数的函数值填充该缺失值。
如果前后值有一个缺失,则得不到缺失值的替换值。
⑤Linear trend at point:为线性趋势值法,表示利用回归拟合线的拟合值作为替代值。
缺失点处的线性趋势法应用缺失值所在的整个序列建立线性回归方程,然后用该回归方程在缺失点的预测值填充缺失值。
*注意:如果序列的第一个和最后一个数据为缺失值,只能利用序列均值和线性趋势值法处理,其他方法不适用。