Greenplum数据仓库技术架构介绍
Greenplum构建实时数据仓库实践

读书笔记模板
01 思维导图
03 目录分析 05 读书笔记
目录
02 内容摘要 04 作者介绍 06 精彩摘录
思维导图
本书关键字分析思维导图
数据库
维度
技术
装载
实时
小结
模型
数据仓 库
数据
数据仓库
第章
监控
实时
数据
配置
数据仓库
系统
功能
安装
内容摘要
内容摘要
Greenplum分布式数据库具有可选存储模式、事务支持、并行查询与数据装载、容错与故障转移、数据库统 计、过程化语言扩展等方面的功能特性,因此Greenplum成为一款理想的分析型数据库产品。本书详解 Greenplum数据仓库构建与数据分析技术,配套示例源码。本书共分10章。内容包括数据仓库简介、数据仓库设 计基础、Greenplum与数据仓库、Greenplum安装部署、实时数据同步、实时数据装载、维度表技术、事实表技 术、Greenplum运维与监控、集成机器学习库MADlib。
2.6小结
3.1
1
Greenplum简
介
3.2
2
Greenplum系
统架构
3 3.3
Greenplum功 能特性
4
3.4为什么选 择Greenplum
5
3.5小结
1
4.1平台需求
2
4.2容量评估
3
4.3操作系统 配置
4 4.4安装
Greenplum软 件
5 4.5初始化
Greenplum数 据库系统
目录分析
本书内容 读者对象
源码下载 致谢
几款分布式数据库的对比

⼏款分布式数据库的对⽐1 概述随着海量数据问题的出现,海量管理能⼒,多类型,变化快,⾼可⽤性,低成本,⾼端可扩展性等需求给企业数据战略带来了巨⼤的挑战。
企业数据仓库、数据中⼼的技术选型变得尤其重要!所以在选型之前,有必要对⽬前市场上各种⼤数据量的解决⽅案进⾏分析。
2 主流分布式并⾏处理数据库产品介绍2.1 Greenplum 2.1.1 基础架构Greenplum 是基于Hadoop 的⼀款分布式数据库产品,在处理海量数据⽅⾯相⽐传统数据库有着较⼤的优势。
Greenplum 整体架构如下图:数据库由Master Severs 和Segment Severs 通过Interconnect 互联组成。
Master 主机负责:建⽴与客户端的连接和管理;SQL 的解析并形成执⾏计划;执⾏计划向Segment 的分发收集Segment 的执⾏结果;Master 不存储业务数据,只存储数据字典。
Segment 主机负责:业务数据的存储和存取;⽤户查询SQL 的执⾏。
2.1.2 主要特性Greenplum 整体有如下技术特点: Shared-nothing 架构Network Interconnect...Master Severs 查询解析、优化、分发Segment Severs 查询处理、数据存储ExternalSources 数据加载海量数据库采⽤最易于扩展的Shared-nothing架构,每个节点都有⾃⼰的操作系统、数据库、硬件资源,节点之间通过⽹络来通信。
◆基于gNet Software Interconnect数据库的内部通信通过基于超级计算的―软件Switch‖内部连接层,基于通⽤的gNet (GigE,10GigE) NICs/switches在节点间传递消息和数据,采⽤⾼扩展协议,⽀持扩展到1000个以上节点。
◆并⾏加载技术利⽤并⾏数据流引擎,数据加载完全并⾏,加载数据可达到4。
5T/⼩时(理想配置)。
gpdb原理

gpdb原理GPDB(Greenplum Database)是一个基于PostgreSQL 开发,面向大型数据仓库和分析的高度并行化数据库管理系统。
GPDB的核心特性是可伸缩性、高性能和可靠性,适用于OLAP场景下的海量数据处理。
从技术架构来看,GPDB的设计思路是将一个大数据仓库拆分成多个子数据集,并将每个数据集分配到不同的计算节点上进行处理。
这种方式可以有效地提高数据的并行处理能力和整体性能,同时也可以更好地支持更高的数据容量和更广泛的计算任务。
在GPDB中,每个数据集都被称为“分布式表”,它们由一组相互协作的计算节点组成,每个节点负责处理其中的一部分数据。
同时,GPDB还支持数据分区(Partitioning),它可以将每个表的数据按照特定的规则划分到不同的节点上,以进一步提高计算效率。
GPDB的核心是“分布式查询处理器”(QP,Query Processor),它负责接收用户的SQL查询请求,将其转换为分布式任务并提交到相应的计算节点上进行处理。
QP基于PostgreSQL的执行引擎进行扩展,支持分布式查询规划和优化、数据划分和转移等功能。
在执行查询时,QP会将查询计划分配给不同的节点,每个节点处理自己分配到的数据,之后将结果返回给QP进行汇总。
GPDB还支持一种称为“MPP”(Massively Parallel Processing)的并行计算模式,它可以将一个查询拆分成多个子查询,并将每个子查询并发执行于不同的计算节点上。
每个节点都可以自主选择并行执行的任务,以提高整个查询的性能和可伸缩性。
MPP可以直接对接Hadoop生态,收集Hadoop集群中的数据进行复杂查询。
在GPDB中,数据的安全性和可靠性也得到了高度重视。
系统支持数据备份和恢复、事务处理、用户权限管理等功能,以确保数据的完整性和安全性。
分布式查询执行引擎还支持许多优化策略,如查询优化、并行查询优化和索引优化等,以进一步提高查询性能和响应速度。
EMC Greenplum电信--Mobile

•建立统一的地市数据集市系统。避免了各个地市单独建立自己的集市系统,完美的实 现数据管理统一化,业务应用个性化两大需求。 •在可控成本内,提供清单级别的数据海量存储及数据快速访问。
© Copyright 2011 EMC Corporation. All rights reserved.
11
SQL
结果
Oracle
测试耗时 47.7s 44.1s
结果
GP测
试耗时
GP提升
倍数 39.7x 15.7x
37528247 11508156713 081.13 306653.19
1.2s 2.8s
FISPA 段 D
2.7s
16.7x
select min(zfje) from stage.fs_zh_cdfispad;
16
Greenplum计算能力测试结果
Query:合并字段测试、代码转换测试。GP系统计算耗时与Oracle系统比较如下:
table typ
e 合 FS_Z H_CD 并 字 select avg(zfje) from stage.fs_zh_cdfispad; 测 试 select max(zfje) from stage.fs_zh_cdfispad; select count(*) from stage.fs_zh_cdfispad; select sum(zfje) from stage.fs_zh_cdfispad; 36396887 110873414383 10.2 304623.344252 221 6480500000 43.3s 6480500000. 00 2.1s 20.6x 45.0s
9
9
四川及安徽电信项目架构及效益
Greenplum介绍

因为GP的算法优化有关,行迁移操作将导致混乱
每个操作都是独立的。
GP Query Plans查询计划
查询计划是从下向上的。
如果操作设计table scans、joins等操作,要涉及到多个Segment合力完成,这时多个节点之间将会有数据的移动-----motion/这样是非常消耗性能的。(多个节点在数据交互是产生的)
每个子节点必须是在不同的网段。
详细将Greenplum Interconnect
GP内部连接实际上是网络基础(实际上是指Internet,多节点并行计算,多个节点之间是有数据交互的,这个交互就是通过Interconnect来进行)。
GP将内部连接(Interconnnent)称之为Inter-process communication---IPC内部进行通信。
Segment Failover and Recovery机制
当挂掉其中的一个子节点时,整个系统仍然可以运行(有Mirror Segment),如果是read-only模式,对于客户端来说只有查询功能,没有写功能。
好处为:当子节点恢复时是恢复到Mirror Segment之前点的数据,这样Primary Segment和Mirror Segment之间不会出现数据差异。
缺点:造成节点上的数据量不同。
优点:在做joins时可以避免节点与节点中的数据交互,节省大量资源
在查询是SQL语句通过Master进行解析、优化并将查询转为并行的查询计划,实现并行查询。
如表扫描table scans 连接joins统计aggregations排序sorts都是并行进行的,而不是串行的。
每一个slice都至少有一个worker process assigned(工作处理被指派)是独立与执行计划的,这时也是并行的。
gp物理架构配置
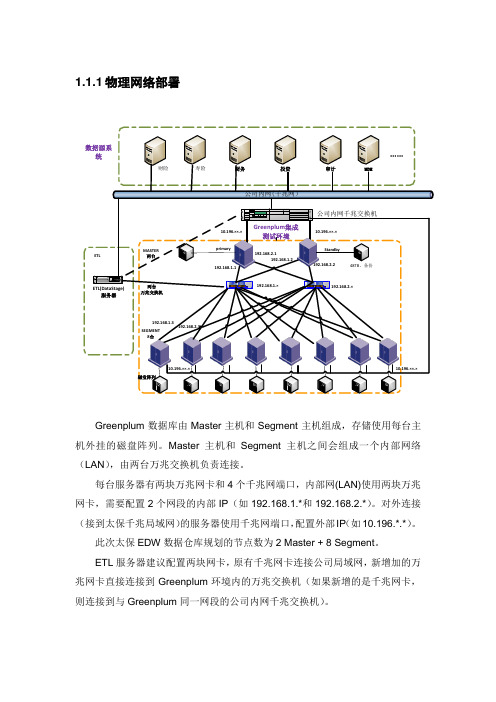
1.1.1 物理网络部署8台primary192.168.1.1192.168.2.1192.168.2.2磁盘阵列10.196.××.×10.196.××.×Greenplum数据库由Master主机和Segment主机组成,存储使用每台主机外挂的磁盘阵列。
Master主机和Segment主机之间会组成一个内部网络(LAN),由两台万兆交换机负责连接。
每台服务器有两块万兆网卡和4个千兆网端口,内部网(LAN)使用两块万兆网卡,需要配置2个网段的内部IP(如192.168.1.*和192.168.2.*)。
对外连接(接到太保千兆局域网)的服务器使用千兆网端口,配置外部IP(如10.196.*.*)。
此次太保EDW数据仓库规划的节点数为2 Master + 8 Segment。
ETL服务器建议配置两块网卡,原有千兆网卡连接公司局域网,新增加的万兆网卡直接连接到Greenplum环境内的万兆交换机(如果新增的是千兆网卡,则连接到与Greenplum同一网段的公司内网千兆交换机)。
1.1.2 存储配置EDW数据存储在每台Segment服务器的外挂磁盘阵列上,各服务器内置硬盘只存储系统文件、程序文件以及临时文件。
外置和内置磁盘都做RAID5保护。
根据容量的需求,我们建议对磁盘阵列(在做RAID5之后)进行如下划分:1)9台7.2TB(600GB*12)裸容量的HP磁盘阵列:a. 与Primary Master主机连接的1台:划分1个逻辑卷(磁盘分区),使用全部可用容量。
b. 与Segment 主机连接的8台:划分2个逻辑卷(磁盘分区),分别使用可用容量的一半。
2)1台48TB(2TB*24)的HP磁盘阵列:按照系统能够支持的最大容量来划分逻辑卷。
注意:请在上述分区安装XFS文件系统。
1.1.3 数据库实例配置每个Segment服务器上建立4个主数据库实例和4个镜像数据库实例(instance)。
greenplum集群原理
greenplum集群原理
Greenplum是一种基于PostgreSQL的开源数据仓库系统,设计用于处理大规模数据集。
它使用MPP(大规模并行处理)架构,将数据分散到多个节点上,并使用这些节点进行并行查询处理,以提高查询性能。
Greenplum集群的基本原理是将数据分散到多个节点上,每个节点都有自己的存储和计算资源。
这种分布式架构允许多个节点同时处理查询,从而显著提高了大规模数据的查询性能。
在Greenplum集群中,有一个主节点(Master)和多个工作节点(Segment)。
主节点负责管理集群中的所有节点,协调查询请求并分发数据。
工作节点负责存储数据和执行查询操作。
当客户端发送查询请求时,主节点首先将查询计划分发给工作节点。
每个工作节点执行查询计划并返回结果给主节点。
主节点再将这些结果合并并返回给客户端。
Greenplum集群还具有强大的数据并行处理能力。
它将查询分成多个子任务,并将这些子任务分发给多个工作节点。
这些工作节点可以并行处理子任务,并在执行过程中自动进行数据分片和负载均衡。
这使得Greenplum集群能够高效地处理大规模数据集,提高查询性能。
基于Greenplum的金融数据仓库模型设计与实现
B06. 票据业务 承兑业务 贴现业务
转贴现
再贴现
预算管控 零余额管理 投标保证金
聚合支付
B07. 资金业务 内部拆借 内部清算
信贷资产转让 财务顾问 委托理财
B08. 国际业务 外汇买卖业务 外汇资金管理业务
质押式回购 发行债券 票据回购 票据质押
资金划转
外币存款 外币贷款
债券现券 公募基金
票据池
第 21 期
综合金融服务系统 结算服务 票据服务 ……
客户服务能力层 聚合支付系统
快捷支付 商户管理 ……
员工工作台系统 代办管理 消息管理 ……
渠道整合平台
企业服务总线(ESB)
业务运营能力层
信贷管理系统
资金结算系统
票据系统
投资管理系统
外汇业务系统
贷前管理
一户通总户
票据承兑
同业存款
外汇买卖
合同管理
数据管控
元 数 据 管 理
智能搜索查询 业务应用
一户式分析
自定义查询 自定义分析
工作桌面 大屏展示
经营管理 数据化运营
数据应用服务平台
风险管理 精准画像
关系图谱 ……
调度平台
数
据
数
标
据
实
准
中
时
心
明细层 汇总层
数
校验层
据
质
量
实时抽取
数据缓冲处理
应用集市层
共性加工层
离 线
统 一
基础数据层
调
度
技术缓冲层
平
显得至关重要,数据仓库在面对海量的业务数据时,有着安全化、实时化、规范化、智能分析以及预测等诸多优势。而数据模型
GreenPlum安装笔记_计算机软件及应用_IT计算机_专业资料
2015/6/13 22:51 GP架构_1与GreenPlum类似的产品:IBM NITIZA(国内没人用)Terndata2007年被EMC收购GreenPlum国外市场:纳斯达克,skypeGreenPlum国内市场:阿里,民生银行,深发展银行,电信业(MPP架构)MPP架构:海量并行处理Massively Parallel Processingshare nothing 模式,每一个节点不进行资源共享,集群中每个节点有独立的CPU、内存、存储、总线等。
SMP架构:symmetric mass processing 对称多处理系统:耦合的多处理系统,共享总线、内存、IO资源,传统的ORCKLE,DB2是非常典型的产品ORACLE_RAC 处于半共享状态,各节点连接共享存储,所以不能算MPPGreenPlum 基于PostGreSQL8.2 之前在国内使用比较少,在国外使用广泛。
Mysql与PostGreSQL地位同等,但mysql被Oracle收购之后没落。
GreenPlum 在函数、dataloading、存储过程等继承了PostGreSQLGP增加BI和数据仓库的支持:A、外部表、并行加载(优势明显)B、资源队列管理的优化,对角色、用户、组进行资源优化分配,管理。
C、GP在查询优化器的增强、分布支持、分区表、执行计划的优化、空间回收、数据分析,简化调优,架构时对称、数据分布均匀的话,可以免去调优Master Host:访问系统的入口,所有请求都需要从Master Host访问,正常来讲,管理员也不可以直接访问SegmentHost ,系统中只允许直接访问MasterHost ,单独操作SegmentHost 影响一致性和完整性。
数据监听进程(PostGres):监听用户请求。
处理所有用户连接。
建立执行计划,通过网络层分发给SegmentHost。
协调整个处理过程,保证SegmentHost处理结果侧一致和同步。
Greenplum中文介绍解析
Greenplum现有国内客户案例分析
• 巨人网络(征途游戏):财务分析、游戏在线分析 • 阿里巴巴:B2B、B2C、点击、在线分析 • 上海航空:航线结算分析 • 东方航空:航线结算分析 • 民族证券:数据中心,证券投资分析 • 北京第二外语大学:图书分析 • 中信银行:信用卡分析 • 深发展银行:数据中心兼ODS • 李宁公司:销售和库存分析 • 公安部:图像分析 • 国家海洋局:海洋数据采集与分析 • 上海安吉物流:收入&市场分析、客户经理跟踪分析 • 中远集团:收入、发展、销售分析
前提条件 – 硬件:基于开放式标准硬件 – 软件:Postgres和Greenplum – 体系架构:海量并行处理体系,针对商务智能/数据仓库 进行了优化,解决了所有数据流瓶颈问题
Greenplum数据引擎
全球最强大的分析数据仓库
通过经济的方案扩展 到千万亿字节规模
• 不用担心数据增长或 者开始的规模太小
官方网站:
2022/3/22
Greenplum:简介
推动数据依赖型企业的发展 Greenplum数据引擎软件为新一代数 据仓库所需的大规模数据和复杂查询功 能所设计
3
全球各地的一些Greenplum客户
亚太地区
欧洲、中东、非洲
• 高度灵活性
• 逐步扩展计算能力 • 动态措施
• 数据访问:
• 在一个系统中协调所有企业数据的位置 • 可以通过任何语言(SQL、M/R等)进行分析
14
强大并且不断扩展的合作伙伴网络
硬件供应商 商务智能工具
服务供应商
15
业内支持和认可
行业奖励
Magic Quadrant 2007 (”远见者象限”)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
- 数据认识 - 业务认识 - 业务需求 - 整体框架 - 数据流转 - 实现方式
3
数据仓库体系架构
数据生命周期与业务归类 时间维度:过去 - 现在 - 未来 (数据的生命周期)
• “现在”的数据 —— OLTP • “过去”的数据 —— OLAP • “未来”的数据 —— 趋势分析
4
数据仓库体系架构
5
数据仓库体系架构
OLAP场景举例
• 业务相关场景
Ø 用户状态 (注册数,活跃数,并发量,峰值) Ø 金币状态 Ø 道具/物品状态 Ø 对账状态 Ø 活动反馈
• 架构相关场景
Ø 不同数据量,不同事务特点,不同查询需求 Ø 历史数据归档与冷热分离 Ø 实时与延时需求的权衡
6
数据仓库体系架构
数据架构示意图
Greenplum数据仓库技术架构介绍
OLAP 在互联网公司的实践与思考
1
一
数据仓库体系架构
二
Greenplum体系架构
三
Greenplum状态描述
四
Greenplum运维体系
五
Greenplum开发规范
2
数据仓库体系架构
数据仓库架构要点
Hale Waihona Puke • 数据生命周期 • 业务数据特点 • OLAP场景举例 • OLAP架构示意 • 数据流转过程 • 具体技术实现
业务数据特点
• 现在的数据 —— OLTP
Ø 实时,在线系统,客户使用 Ø 事务小,频率高,并发高
• 过去的数据 —— OLAP
Ø 非实时(T+1,或小时级),离线系统,分析决策 Ø 事务大,频率相对小,并发低
• 未来的数据 —— 趋势分析
Ø 非实时,离线+在线流系统,趋势分析 Ø 算法分析,持续计算
11
greenplum体系架构
postgresql体系结构
12
greenplum体系架构
postgresql体系结构
• pg结构组成
➢ 连接关系系统 ➢ 编译执行系统 ➢ 存储执行系统 ➢ 事务系统 ➢ 系统表
• pg逻辑和物理结构
➢ instance实例 - user - tablesapce ➢ database - schema - table,view,function - data row ➢ 物理文件 - oid - 表空间 - 数据文件命名
7
数据仓库体系架构
数据流转过程
• 1 业务数据的产生 —— OLTP • 2 业务数据的中转 —— ETL服务器 • 3 数据的存储和计算 —— OLAP集群 • 4 结果数据的展现 —— 数据集市 • 5 访问接口的封装 —— API接口服务器 • 6 最终数据的显示 —— 前端界面
• 7 结果数据的交互 —— OLTP,趋势分析 • 8 OLAP数据流转 —— dbsync平台
• greenplum的核心功能
➢ 无共享MPP ➢ 多态存储 ➢ 高效数据加载 (gpfdist+外部表,每小时4TB+) ➢ 分布分区 ➢ 数据压缩 ➢ 外部访问
16
一
数据仓库体系架构
二
Greenplum体系架构
三
Greenplum状态描述
四
Greenplum运维体系
五
Greenplum开发规范
• 公司IDC_01机房Greenplum体系
➢ 公司第一套Greenplum集群,网络环境为千兆网 ➢ 数据来源为OLTP库,针对小数据量传输和计算,部分实时交互操作 ➢ 以对账业务为主,统计计算为辅
• 公司IDC_02机房Greenplum体系
➢ 针对数据来源主要是kfk产生csv文件的业务,不直接从数据库传数 ➢ 以重点业务线、活动数据、非OLTP业务数据的任务计算为主
13
greenplum体系架构
greenplum的体系结构
14
greenplum体系架构
greenplum的体系结构
15
greenplum体系架构
greenplum的体系结构
• greenplum的架构特点
➢ MPP ShareNothing 海量并行处理+完全无共享 ➢ cpu计算能力 ➢ 数据从Disk上的I/O吞吐性能 ➢ master管理节点 ➢ segment数据节点
• 公司IDC_03机房Greenplum体系
➢ 数据来源来源为OTLP库库,针对大数据量传输和计算,采用T+1方式 ➢ 以核心业务的数据计算、统计为主
19
Greenplum现状说明
数据架构示意图
20
Greenplum现状说明
三大Greenplum集群关系
• 数据来源不同 • 数据处理不同 • 时效速度不同
8
数据仓库体系架构
架构的具体技术实现
• 轻量级数据仓库 —— Inforbright
– 与MySQL数据库结合,易使用,冷热分离 – 数据库归档,只能load,不支持DML – 对特定OLAP类查询有很好的支持作用
• 通用性数据仓库 —— Greenplum
– 独立的数据库仓库解决方案 – 可以很好支持各种方式的数据加载和DML操作 – 具备海量的数据存储和计算性能
17
Greenplum现状说明
Greenplum集群现状概述
• 三大Greenplum集群体系
➢ 公司IDC_01机房Greenplum体系 ➢ 公司IDC_02机房Greenplum体系 ➢ 公司IDC_03机房Greenplum体系
18
Greenplum现状说明
三大Greenplum集群定位分类
运维要点
• 环境规划与部署 • 系统状态监控 • 数据库备份 • 数据传输与同步 • 任务调度
- 构建系统 - 监控系统 - 保障系统 - 流转系统 - 计算系统
24
• 体系架构相同 • 年表划分相同 • 平台整体定位
• 定位不同,多集群配合形成逻辑大集群
21
Greenplum现状说明
Greenplum多层业务规划图
22
一
数据仓库体系架构
二
Greenplum体系架构
三
Greenplum状态描述
四
Greenplum运维体系
五
Greenplum开发规范
23
Greenplum运维体系
9
一
数据仓库体系架构
二
Greenplum体系架构
三
Greenplum状态描述
四
Greenplum运维体系
五
Greenplum开发规范
10
greenplum体系架构
体系结构要点
• postgresql体系结构 • pg逻辑和物理结构 • Greenplum体系结构 • GP架构特点与功能
- 单元结构 - 单元分解 - 集群结构 - 集群特点