时间序列实验报告-R
用R语言做时间序列分析

用R语言做时间序列分析时间序列(time series )是一系列有序的数据。
通常是等时间间隔的采样数据。
如果不是等间隔,则一般会标注每个数据点的时间刻度。
下面以time series 普遍使用的数据airline passenger 为例。
这是^一年的每月乘客数量,单位是千人次。
Time如果想尝试其他的数据集,可以访问这里:https:///data/list/?q=provider:tsdl可以很明显的看出,airli ne passe nger 的数据是很有规律的。
time series data mining 主要包括decompose (分析数据的各个成分,例如趋势,周期性),prediction (预测未来的值),classificatio n (对有序数据序列的feature 提取与分类),clusteri ng (相似数列聚类)等。
这篇文章主要讨论prediction (forecast,预测)问题。
即已知历史的数据,如何准确预测未来的数据。
先从简单的方法说起。
给定一个时间序列,要预测下一个的值是多少,最简单的思路是什么呢?(1)m ean (平均值):未来值是历史值的平均。
(2)exponential smoothing (指数衰减):当去平均值得时候,每个历史点的权值可以不一样。
最自然的就是越近的点赋予越大的权重。
= aX± + ct^X2 + a3X3+ …或者,更方便的写法,用变量头上加个尖角表示估计值X t+1 = aX t+ (1 - a)X t(3) sn aive :假设已知数据的周期,那么就用前一个周期对应的时刻作为下一个周期对应时刻的预测值(4)d rift :飘移,即用最后一个点的值加上数据的平均趋势tX t+h|t =禺+占2心-斗-丄= x t +占(罠-如Tt = •介绍完最简单的算法,下面开始介绍两个time series 里面最火的两个强大的算法:Holt-Winters 和ARIMA 。
时间序列分析R语言程序

#例2.1 绘制1964——1999年中国年纱产量序列时序图(数据见附录1.2)Data1.2=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.2.csv",header=T)#如果有标题,用T;没有标题用Fplot(Data1.2,type='o')#例2.1续tdat1.2=Data1.2[,2]a1.2=acf(tdat1.2)#例2.2绘制1962年1月至1975年12月平均每头奶牛产奶量序列时序图(数据见附录1.3)Data1.3=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.3.csv",header=F)tdat1.3=as.vector(t(as.matrix(Data1.3)))[1:168 ]#矩阵转置转向量plot(tdat1.3,type='l')#例2.2续acf(tdat1.3) #把字去掉pacf(tdat1.3)#例2.3绘制1949——1998年北京市每年最高气温序列时序图Data1.4=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.4.csv",header=T)plot(Data1.4,type='o')##不会定义坐标轴#例2.3续tdat1.4=Data1.4[,2]a1.4=acf(tdat1.4)#例2.3续Box.test(tdat1.4,type="Ljung-Box",lag=6) Box.test(tdat1.4,type="Ljung-Box",lag=12)#例2.4随机产生1000个服从标准正态分布的白噪声序列观察值,并绘制时序图Data2.4=rnorm(1000,0,1)Data2.4plot(Data2.4,type='l')#例2.4续a2.4=acf(Data2.4)#例2.4续Box.test(Data2.4,type="Ljung-Box",lag=6) Box.test(Data2.4,type="Ljung-Box",lag=12) #例2.5对1950——1998年北京市城乡居民定期储蓄所占比例序列的平稳性与纯随机性进行检验Data1.5=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.5.csv",header=T)plot(Data1.5,type='o',xlim=c(1950,2010),ylim=c (60,100))tdat1.5=Data1.5[,2]a1.5=acf(tdat1.5)#白噪声检验Box.test(tdat1.5,type="Ljung-Box",lag=6) Box.test(tdat1.5,type="Ljung-Box",lag=12)#例2.5续选择合适的ARMA模型拟合序列acf(tdat1.5)pacf(tdat1.5)#根据自相关系数图和偏自相关系数图可以判断为AR (1)模型#例2.5续 P81 口径的求法在文档上#P83arima(tdat1.5,order=c(1,0,0),method="ML")#极大似然估计ar1=arima(tdat1.5,order=c(1,0,0),method="ML") summary(ar1)ev=ar1$residualsacf(ev)pacf(ev)#参数的显著性检验t1=0.6914/0.0989p1=pt(t1,df=48,lower.tail=F)*2#ar1的显著性检验t2=81.5509/ 1.7453p2=pt(t2,df=48,lower.tail=F)*2#残差白噪声检验Box.test(ev,type="Ljung-Box",lag=6,fitdf=1) Box.test(ev,type="Ljung-Box",lag=12,fitdf=1) #例2.5续P94预测及置信区间predict(arima(tdat1.5,order=c(1,0,0)),n.ahead= 5)tdat1.5.fore=predict(arima(tdat1.5,order=c(1,0 ,0)),n.ahead=5)U=tdat1.5.fore$pred+1.96*tdat1.5.fore$seL=tdat1.5.fore$pred-1.96*tdat1.5.fore$seplot(c(tdat1.5,tdat1.5.fore$pred),type="l",col =1:2)lines(U,col="blue",lty="dashed")lines(L,col="blue",lty="dashed")#例3.1.1 例3.5 例3.5续#方法一plot.ts(arima.sim(n=100,list(ar=0.8))) #方法二x0=runif(1)x=rep(0,1500)x[1]=0.8*x0+rnorm(1)for(i in 2:length(x)){x[i]=0.8*x[i-1]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)##拟合图没有画出来#例3.1.2x0=runif(1)x=rep(0,1500)x[1]=-1.1*x0+rnorm(1)for(i in 2:length(x)){x[i]=-1.1*x[i-1]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)#例3.1.3方法一plot.ts(arima.sim(n=100,list(ar=c(1,-0.5)))) #方法二x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]-0.5*x[i-2]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)#例3.1.4x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1 x[2]=x1+0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]+0.5*x[i-2]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)又一个式子x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=-x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=-x[i-1]-0.5*x[i-2]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)#均值和方差smu=mean(x)svar=var(x)#例3.2求平稳AR(1)模型的方差例3.3mu=0mvar=1/(1-0.8^2) #书上51页#总体均值方差cat("population mean and var are",c(mu,mvar),"\n")#样本均值方差cat("sample mean and var are",c(mu,mvar),"\n")#例题3.4svar=(1+0.5)/((1-0.5)*(1-1-0.5)*(1+1-0.5))#例题3.6 MA模型自相关系数图截尾和偏自相关系数图拖尾#3.6.1法一:x=arima.sim(n=1000,list(ma=-2))plot.ts(x,type='l')acf(x)pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-2*rnorm[i-1]}plot(x,type='l')acf(x)pacf(x)#3.6.2法一:x=arima.sim(n=1000,list(ma=-0.5))plot.ts(x,type='l')acf(x)pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-0.5*rnorm[i-1]}plot(x,type='l')acf(x)pacf(x)##错误于rnorm[i] : 类别为'closure'的对象不可以取子集#3.6.3法一:x=arima.sim(n=1000,list(ma=c(-4/5,16/25))) plot.ts(x,type='l')acf(x)pacf(x)法二:x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-4/5*rnorm[i-1]+16/25*rnorm[i-2] }plot(x,type='l')acf(x)pacf(x)##错误于x[i] = rnorm[i] - 4/5 * rnorm[i - 1] + 16/25 * rnorm[i - 2] :##更换参数长度为零#例3.6续根据书上64页来判断#例 3.7拟合ARMA(1,1)模型,x(t)-0.5x(t-1)=u(t)-0.8*(u-1),并直观观察该模型自相关系数和偏自相关系数的拖尾性。
R语言综合实验报告

学号:2013310200629姓名:王丹学院:理学院专业:信息与计算科学成绩:日期:年月日基于工业机器人能否准确完成操作的时间序列分析摘要:时间序列分析是预测领域研究的重要工具之一,它描述历史数据随时间变化的规律,并用于预测数据。
本文首先介绍了一些常用的时间序列模型,包括建模前对数据的预处理、模型的识别以及模型的预测等。
通过多种方法分析所得到的数据,实现准确建模,可以得出正确的结论。
关键词:自回归(AR)模型,滑动平均(MA)模型,自回归滑动平均(ARMA)模型,ARMA最优子集一、问题提出,问题分析随着社会日新月异的发展,不断创新的科技为我们的生活带来了越来越多的便利。
机器人也逐渐走向了我们的生活,工厂里使用机器人去工作也可以大大减少生产成本,但为了保证产品质量,工厂使用的机器人应该多次测试,确保动作准确无误。
现有一批数据,包含了来自工业机器人的时间序列(机器人需要完成一系列的动作,与目标终点的距离以英寸为单位被记录下来,重复324次得到该时间序列),对于这些离散的数据,我们期望从中发掘一些信息,以便对机器人做更好的改进或者确定机器人是否可以投入使用。
但我们从中并不能看出什么,需要借助工具做一些处理,对数据进行分析。
时间序列分析是通过直观的数据比较或作图观测,去寻找序列中包含的变化规律,这种分析方法称为描述性时序分析。
在物理、天文、海洋学等科学领域,这种描述性时序分析方法经常能够使人们发现一些意想不到的规律,操作起来十分简单而且直观有效,因此从史前到现在一直被人们广泛使用,它也是我们进行统计时序分析的第一步。
我们将利用自回归(AR)模型、滑动平均(MA)模型以及自回归滑动平均(ARMA)模型去解决遇到的问题。
二、数据描述和初步分析下面是我们接收到的数据,数据来源:/~kchan/TSA.htm0.0011 0.0011 0.0024 0.0000 -0.0018 0.0055 0.0055 -0.00150.0047 -0.0001 0.0031 0.0031 0.0052 0.0034 0.0027 0.00410.0041 0.0034 0.0067 0.0028 0.0083 0.0083 0.0030 0.00320.0035 0.0041 0.0041 0.0053 0.0026 0.0074 0.0011 0.0011-0.0001 0.0008 0.0004 0.0000 0.0000 -0.0009 0.0038 0.00540.0002 0.0002 0.0036 -0.0004 0.0017 0.0000 0.0000 0.00470.0021 0.0080 0.0029 0.0029 0.0042 0.0052 0.0056 0.00550.0055 0.0010 0.0043 0.0006 0.0013 0.0013 0.0008 0.00230.0043 0.0013 0.0013 0.0045 0.0037 0.0015 0.0013 0.00130.0029 0.0039 -0.0018 0.0016 0.0016 -0.0003 0.0000 0.00090.0017 0.0017 0.0030 -0.0001 0.0070 -0.0008 -0.0008 0.00090.0025 0.0031 0.0002 0.0002 0.0022 0.0020 0.0003 0.00330.0033 0.0044 -0.0010 0.0048 0.0019 0.0019 0.0031 0.00200.0017 0.0014 0.0014 0.0039 0.0052 0.0020 0.0012 0.00120.0031 0.0022 0.0040 0.0038 0.0038 0.0007 0.0016 0.00240.0003 0.0003 0.0057 0.0006 0.0009 0.0040 0.0040 0.00350.0032 0.0068 0.0028 0.0028 0.0048 0.0035 0.0042 -0.0020-0.0020 0.0023 -0.0011 0.0062 -0.0021 -0.0021 0.0000 -0.0019-0.0005 0.0048 0.0048 0.0027 0.0009 -0.0002 0.0079 0.00790.0017 0.0034 0.0030 0.0025 0.0025 0.0004 0.0031 0.0057-0.0003 -0.0003 0.0006 0.0018 0.0022 0.0042 0.0042 0.0055-0.0005 -0.0053 0.0028 0.0028 0.0005 0.0036 0.0017 -0.0043-0.0043 0.0066 -0.0016 0.0055 -0.0011 -0.0011 -0.0049 0.00470.0056 0.0057 0.0057 -0.0002 0.0056 0.0037 0.0012 0.00120.0018 -0.0025 -0.0011 0.0027 0.0027 0.0039 0.0058 0.00030.0040 0.0040 0.0042 0.0000 0.0056 -0.0029 -0.0029 -0.00260.0016 0.0019 0.0015 0.0015 0.0007 0.0007 -0.0044 -0.0030-0.0030 0.0013 0.0029 -0.0010 0.0009 0.0009 -0.0016 0.00000.0000 0.0014 0.0014 -0.0003 0.0009 -0.0068 0.0003 0.0003-0.0012 0.0037 -0.0019 0.0023 0.0023 -0.0033 -0.0002 -0.00100.0021 0.0021 0.0026 -0.0002 0.0011 0.0028 0.0028 -0.00040.0026 -0.0015 0.0002 0.0002 0.0018 -0.0005 0.0004 -0.0008-0.0008 0.0018 0.0019 0.0029 -0.0022 -0.0022 0.0010 -0.00330.0020 0.0000 0.0000 0.0003 0.0007 -0.0009 -0.0035 -0.00350.0010 0.0007 0.0028 -0.0008 -0.0008 -0.0034 -0.0010 -0.0018-0.0021 -0.0021 -0.0006 -0.0018 -0.0046 -0.0017 -0.0017 -0.0001-0.0029 0.0020 -0.0049 -0.0049 -0.0021 -0.0027 -0.0018 -0.0015-0.0015 0.0051 -0.0002 0.0000 -0.0006 -0.0006 -0.0012 0.00120.0000 0.0021 0.0021 -0.0001 0.0022 0.0055 -0.0010 -0.00100.0048 0.0006 0.0026 0.0004 0.0004 0.0000 0.0000 0.00080.0044 0.0044 0.0002 0.0036这一群数目庞大的数据,以我们直观的判断,它们错综复杂,且毫无规律可言,根本不能从中得到有用的消息。
时间序列分析试验报告

时间序列分析试验报告
一、试验简介
本次试验旨在探索时间序列分析,以分析日期变化的影响与规律。
时
间序列分析是数据分析的一种,目的是预测未来正确的趋势,并且分析既
有趋势的影响及其变化。
二、试验材料
本次试验使用的资料为最近12个月(即2024年1月到2024年12月)的电子商务网站销售数据。
该电子商务网站以每月总销售量、每月总销售
额及每月交易次数三个变量作为试验数据。
三、试验方法
1.首先,收集2024年1月到2024年12月的电子商务销售数据,记
录每月总销售量、总销售额及交易次数。
2.然后,编制时间序列分析图表,反映每月总销售量、总销售额及
交易次数的变化情况。
3.最后,分析每月的变化趋势,比较每月的销售数据,并进行相关
分析推断。
四、实验结果
1.通过时间序列分析图表可以看出,每月总销售量、总销售额及交
易次数均呈现出稳定上升趋势。
2.从图表中可以推断,在2024年底到2024年底,当月的总销售量、总销售额及交易次数均较上月有所增加。
3.从表中可以推断,每月的总销售量、总销售额及交易次数都在逐渐增加,最终在2024年末达到高峰。
五、结论
通过本次实验可以得出结论。
时间序列实验报告

重庆交通大学学生实验报告实验课程名称时间序列分析开课实验中心数统学院实验教学中心开课学院数学与统计学院专业年级应用统计学2015级1班姓名XXXX学号6315XXXXXXXX任课老师XXXXX开课时间2017—2018学年第1学期此页空页!实验一R语言简介: 基本操作一实验目的1、了解软件R:安装、启动、退出、帮助等。
2、熟悉R的操作界面。
二、实验内容及要求:1、实验内容:(1)R的安装;(2)启动与退出;(3)包的安装及R的更新;(4)帮助及移除多个对象等;(5)常见命令2、实验要求:(1)熟悉R的操作环境;(2)熟悉包的安装与帮助;(3)学习常见命令,熟悉 R 的操作界面。
三、实验过程及结果1、(1)R的安装(2)启动与退出;(3)包的安装及R的更新;A、包的安装> chooseCRANmirror()> install.packages()B、R的更新> install.packages("installr") > library(installr)> updateR()(4)帮助及移除多个对象等;> ?关键字> ??关键字> help.start()#帮助> rm()> rm(list=ls())#移除多个对象(5)常见命令四、实验心得了解了R的一些基本使用及其常见的命令,为自己深入学习r的使用打下了基础。
实验二R语言简介: 数据集创建与处理一实验目的1、掌握R数据集的不同创建形式。
2、熟悉并掌握利用R对时间序列数据集进行变换与处理。
二、实验内容及要求1、实验内容:(1)利用data.frame函数创建数据集;(2)读取 d.txt 型数据框;(3)读取 excel 数据及对某变量数据进行某些处理(4)导出 R 中数据集(5)时间序列数据输入(6)对已有数据集中数据的处理2、实验要求:熟悉R数据集的不同创建方法,掌握利用R对时序数据集进行变换与处理三、实验过程及结果1、实验内容:(1)利用data.frame函数创建数据集;(2)读取 d.txt 型数据框;m(3)读取 excel 数据及对某变量数据进行某些处理(4)导出 R 中数据集(5)时间序列数据输入(6)对已有数据集中数据的处理(5)(6)合> library(readxl)> X2_7<- read_excel("C:/Users/Administrator/Desktop/2.7.x lsx")> summary(X2_7)330.45 330.97 331.64 332.87 333.61Min. :331.6 Min. :330.1 Min. :328.6 Min. :328.3 Min. :329.41st Qu.:332.9 1st Qu.:332.4 1st Qu.:331.9 1st Qu.:33 1.5 1st Qu.:332.8Median :334.7 Median :334.4 Median :333.7 Median :33 4.4 Median :335.1Mean :335.0 Mean :334.2 Mean :333.9 Mean :334.3 Mean :335.23rd Qu.:336.8 3rd Qu.:336.1 3rd Qu.:335.9 3rd Qu.:33 7.0 3rd Qu.:337.7Max. :339.2 Max. :338.2 Max. :339.9 Max. :340.6 Max. :341.2333.55Min. :330.61st Qu.:333.9Median :336.0Mean :335.73rd Qu.:338.0Max. :340.9四、实验心得通过本次实验,首先,我知道了文件其他格式的文件如何导入R,知晓乐数据集的创建,使用及一些简单的处理。
统计学实验报告--时间序列分析
实验目的:
1.综合运用统计学时间序列相关知识,并结合经济学等方面的知识进
行回归分析,预测2012年社会投资额。
2.根据时间序列预测结果,建立回归方程,预测该地2012年GDP。
实验步骤:
1.对所搜集的数据资料进行分类整理。
2.绘制表格及频数分布直方图。
3.运用时间数列,进行回归分析,预测2012年社会投资额。
4.运用时间数列预测结果,建立回归方程,预测2012年GDP。
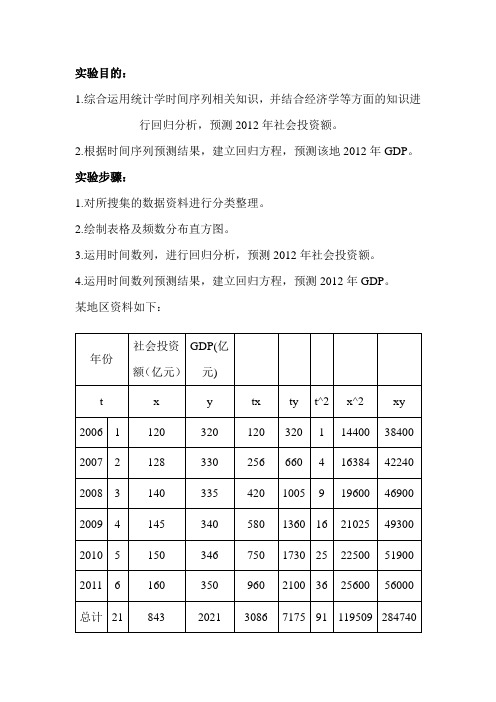
某地区资料如下:
分析: (1)设X=a+bt b=(∑xt -n
/1∑∑t x )/[∑2^t -2)^(/1∑t n ]
=(3086-1/6*384*21)/(91-1/6*21^2) =7.7429 x =140.5 t =3.5 a=x -b t
=140.5-7.7429*3.5 =113.3999+7.7429t
故,2012年,即t=7时,社会投资额为167.6002亿元。
(2)设ŷ=c+dx
d=(∑xy-1/n∑∑y
/1
n
x]
2^x
x)/[∑∑
-2
)^
(
=(284740-1/6*2021*843)/(179509-1/6*843^2)
=0.74
c=y-d x=232.86
故,2012年该地GDP为356.88亿元。
实验结论:运用时间序列进行回归分析,可以根据以往的经济数据进行预测分析,提高经济活动的目的性与计划性。
时间序列分析R语言程序

#例2.1绘制196 ------- 1999年中国年纱产量序列时序图(数据见附录1.2)Data1.2=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录1.2.csv",header=T)#如果有标题,用T;没有标题用Fplot(Data1.2,type='o')#例2.1续tdat1.2=Data1.2[,2]a1.2=acf(tdat1.2)#例2.2绘制1962年1月至1975年12月平均每头奶牛产奶量序列时序图(数据见附录1.3)Data1.3=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录 1.3.csv”,header=F)tdat1.3=as.vector(t(as.matrix(Data1.3)))[1:168]# 矩阵转置转向量plot(tdat1.3,type=T)#例2.2续acf(tdat1.3) #把字去掉pacf(tdat1.3)#例2.3绘制1949——1998年北京市每年最高气温序列时序图Data1.4=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录 1.4.csv”,header=T)plot(Data1.4,type='o')##不会定义坐标轴#例2.3续tdat1.4=Data1.4[,2]a1.4=acf(tdat1.4)#例2.3续Box.test(tdat1.4,type="Ljung-Box”,lag=6)Box.test(tdat1.4,type="Ljung-Box”,lag=12)#例2.4随机产生1000个服从标准正态分布的白噪声序列观察值,并绘制时序图Data2.4=rnorm(1000,0,1)Data2.4plot(Data2.4,type=T)#例2.4续a2.4=acf(Data2.4)#例2.4续Box.test(Data2.4,type="Ljung-Box”,lag=6)Box.test(Data2.4,type="Ljung-Box”,lag=12)#例2.5对195 ——1998年北京市城乡居民定期储蓄所占比例序列的平稳性与纯随机性进行检验Data1.5=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录 1.5.csv”,header=T)plot(Data1.5,type='o',xlim=c(1950,2010),ylim=c(60,100) )tdat1.5=Data1.5[,2]a1.5=acf(tdat1.5)#白噪声检验Box.test(tdat1.5,type="Ljung-Box”,lag=6)Box.test(tdat1.5,type="Ljung-Box”,lag=12)#例2.5续选择合适的ARMA模型拟合序列acf(tdat1.5)pacf(tdat1.5)#根据自相关系数图和偏自相关系数图可以判断为AR(1)模型#例2.5续P81 口径的求法在文档上#P83arima(tdat1.5,order=c(1,0,0),method="ML")# 极大似然估计ar1=arima(tdat1.5,order=c(1,0,0),method="ML") summary(ar1)ev=ar1$residualsacf(ev)pacf(ev)#参数的显著性检验t1=0.6914/0.0989p1=pt(t1,df=48,lower.tail=F)*2#ar1的显著性检验t2=81.5509/ 1.7453p2=pt(t2,df=48,lower.tail=F)*2#残差白噪声检验Box.test(ev,type="Ljung-Box”,lag=6,fitdf=1)Box.test(ev,type="Ljung-Box”,lag=12,fitdf=1)#例2.5续P94预测及置信区间predict(arima(tdat1.5,order=c(1,0,0)),n.ahead=5)tdat1.5.fore=predict(arima(tdat1.5,order=c(1,0,0)),n.ahea d=5)U=tdat1.5.fore$pred+1.96*tdat1.5.fore$seL=tdat1.5.fore$pred-1.96*tdat1.5.fore$seplot(c(tdat1.5,tdat1.5.fore$pred),type="l”,col=1:2)lines(U,co l=”blue”,lty=”dashed”)lines(L,col=”blue”,lty=”dashed”)#例3.1.1例3.5 例3.5续#方法一plot.ts(arima.sim(n=100,list(ar=0.8)))#方法二x0=runif(1)x=rep(0,1500)x[1]=0.8*x0+rnorm(1) for(i in 2:length(x)) {x[i]=0.8*x[i-1]+rnorm(1)} plot(x[1:100],type=T) acf(x)pacf(x)##拟合图没有画出来x[1]=x1x[2 ]=-x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=-x[i-1]-0.5*x[i-2]+rnorm(1)} plot(x[1:100],type=T)acf(x)pacf(x)#例3.1.2x0=runif(1)x=rep(0,1500)x[1]=-1.1*x0+rnorm(1) for(i in 2:length(x)) #均值和方差smu=mean(x) svar=var(x){x[i]=-1.1*x[i-1]+rnorm(1)} plot(x[1:100],type=T) acf(x) pacf(x) #例3.2求平稳AR (1)模型的方差例3.3 mu=0 mvar=1/(1-0.8A2) #书上51 页#总体均值方差#例3.1.3方法一plot.ts(arima.sim(n=100,list(ar=c(1,-0.5)))) #方法二x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]-0.5*x[i-2]+rnorm(1)}plot(x[1:100],type=T)acf(x)pacf(x) cat("population mean and var are”,c(mu,mvar),"\n")#样本均值方差cat("sample mean and var are”,c(mu,mvar),"\n")#例题3.4svar=(1+0.5)/((1-0.5)*(1-1-0.5)*(1+1-0.5))#例题3.6 MA模型自相关系数图截尾和偏自相关系数图拖尾#3.6.1法:x=arima.sim(n=1000,list(ma=-2))plot.ts(x,type='l')acf(x)#例3.1.4x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=x1+0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]+0.5*x[i-2]+rnorm(1)} plot(x[1:100],type=T)acf(x)pacf(x) pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-2*rnorm[i-1]} plot(x,type=T)acf(x)pacf(x)#3.6.2法一:又一个式子x0=runif(1)x1=runif(1)x=rep(0,1500) x=arima.sim(n=1000,list(ma=-0.5)) plot.ts(x,type='l')acf(x)pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-0.5*rnorm[i-1]}plot(x,type='l')acf(x)pacf(x)##错误于rnorm[i]:类别为'closure'的对象不可以取子集#3.6.3法^:x=arima.sim(n=1000,list(ma=c(-4/5,16/25)))plot.ts(x,type=T)acf(x)pacf(x)法二:x=rep(0:1000)for(i in 1:1000) {x[i]=rnorm[i]-4/5*rnorm[i-1]+16/25*rnorm[i-2]} plot(x,type='l')acf(x)pacf(x)##错误于x[i] = rnorm[i] - 4/5 * rnorm[i - 1] + 16/25 * rnorm[i - 2] :##更换参数长度为零#例3.6续根据书上64页来判断#例3.7拟合ARMA ( 1,1)模型,x(t)-0.5x(t-1)=u(t)-0.8*(u-1),并直观观察该模型自相关系数和偏自相关系数的拖尾性。
时间序列分析实验报告

引言概述:
时间序列分析是一种用于研究时间数据的统计方法,主要关注数据随时间的变化趋势、季节性和周期性等特征。
时间序列分析应用广泛,可以用于金融预测、经济分析、气象预测等领域。
本实验报告旨在介绍时间序列分析的基本概念和方法,并通过实例分析来展示其应用。
正文内容:
1.时间序列分析基本概念
1.1时间序列的定义
1.2时间序列的模式
1.3时间序列分析的目的
2.时间序列分析方法
2.1随机游走模型
2.2移动平均模型
2.3自回归移动平均模型
2.4季节性模型
2.5ARCH和GARCH模型
3.时间序列数据预处理
3.1数据平稳性检验
3.2数据平滑
3.3缺失值填补
3.4离群值检测
3.5数据变换
4.时间序列模型建立与评估
4.1模型的选择
4.2参数估计
4.3拟合优度检验
4.4模型诊断
4.5预测准确性评估
5.实例分析:某公司销售数据时间序列分析
5.1数据收集与预处理
5.2模型建立与评估
5.3预测分析与结果解释
5.4预测精度评估
5.5结果讨论与进一步改进方向
总结:
时间序列分析是一种重要的统计方法,可用于预测和分析时间相关的数据。
本报告介绍了时间序列分析的基本概念和方法,并通
过实例分析展示了其应用过程。
通过时间序列分析,可以更好地理解数据的趋势和周期性,并进行准确的预测。
时间序列分析也面临着多样的挑战,如数据质量问题和模型选择困难等。
因此,在实际应用中,需要综合考虑多种因素,灵活运用合适的方法和技巧,以提高预测准确性和分析可靠性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告
课程名称时间序列分析
实验项目名称ARCH建模
班级与班级代码1125040
实验室名称(或课室)北4-602 专业统计学
任课教师陈根
学号:***********
*名:**
实验日期:2014年6月08日
广东财经大学教务处制
姓名实验报告成绩
评语:
指导教师(签名)
年月日说明:指导教师评分后,实验报告交院(系)办公室保存。
一.实验目的:
将Merck股票从1946年6月到2008年12月的月简单收益变换成对数收益率,并解决下列问题:
(a)对数收益率中有没有明显的相关性?用自相关系数和5%的显著性水平来
回答该问题。
如果有,则移除序列相关性。
(b)此对数收益率存在ARCH效应么?如果(a)部分中有序列相关性,则该部分
用其残差序列。
用Ljung-Box统计量,对收益率平方(或残差的平方)的6个间隔和12个间隔的自相关系数,在5%的显著性水平下回答该问题。
(c)对数据识别一个ARCH模型,然后给数据拟合被识别的模型,写出所拟合
的模型。
二.实验设备:
计算机、R-3.0.3
三.实验过程及得出的结论:
1.加载安装包并引入实验数据
2.按实验目的输入实验代码,从运行结果得出结论
(a)①对数收益率中有显著的序列相关性。
通过自相关系数和5%的显著性水平解答:
02040
6080100
0.00.20.40.60.8
1.0Lag
A C F
Series lmrk
图1 Merck 股票对数收益率的自相关系数
样本ACF 的值并没有在两个标准差之内,说明5%水平下它们与0有显著差别,对于对数收益率,Ljung-Box 统计量为Q(12)= 27.2364,对应的p 值为0.007144,p<a=0.05,拒绝原假设,即证实了Merck 股票对数收益率有显著的序列相关性。
②移除序列相关性
I.使用ar()函数对对数收益率序列识别得一个阶数为8的AR 模型:
II.月对数收益率拟合AR (8)模型得出残差序列:
算得Q (12)=8.2078,并且基于自由度为4的Χ2分布的p 值为0.084. 然而,延迟为2、3、5、6的AR 系数在5%水平下是不显著的,所以改进模型见第三步。
III .改进模型如下所示:
模型改进为:
a r
r
t
t
++++=8
-t 7
-t 4
-t 1
-t 0.1082
0.0474
0.0699
0.0826
-0.0107r
r
r
,
0698
.0^=σ
a
其中所有的估计在5%水平下都是显著的。
残差序列给出Q (12)=8.779,其p
值为0.361(基于28χ分布)。
该模型对数据的动态线性依赖性的建模是充分的。
(b )此对数收益率存在ARCH 效应。
由于(a)部分中存在序列相关性,因此需要用残差的平方做关于对数收益率的ARCH 效应检验。
使用Box-Ljung 检验的6个间隔与12个间隔的自相关系数在5%的显著性水平下对残差的平方进行检验,结果如下:
a t 序列的Ljung-Box 统计量Q (6)=22.5444,Q (12)= 33.0125,p 值都接近于0,这表明存在很强的ARCH 效应。
(c )建立ARCH 模型
用残差的平方做关于对数收益率的ARCH 效应检验图。
结果如图2所示:
图2 残差平方的PACF
由图2中的样本PACF 表明ARCH (3)模型可能是合适的,因此下面将对Merck 股票的月对数收益率具体建立一个如下形式的模型:
a r t
+=μt
,εσt
t t a =,a a a t t t t
2
3
322221102---∂∂∂∂+++=σ
5
10
15
20253035
-0.050.000.05
0.10Lag
P a r t i a l A C F
Series at^2
假定εt 是独立同分布的标准正态序列,我们得到的拟合模型为:
a r t
+=0.0120t
,a a a t t t t
2
3
222120.084140.069510.029670.00406---+++=σ
各个参数估计值的标准误差分别是0.0026,0.0003,0.0392,0.0372,0.0391,参见下面输出结果。
尽管估计值满足ARCH (3)模型的一般条件,然而∂1和∂2的估计值在5%的水平下不是统计显著的,模型需要进一步优化。
四.实验程序:
da=read.table("C:/m-mrk.txt",header=T)
da[1,]
mrk=da[,2]
lmrk=log(mrk+1)
acf(lmrk,lag=100)
Box.test(lmrk,lag=12,type='Ljung')
m1=ar(lmrk,method='mle')
m1$order
m2=arima(lmrk,order=c(8,0,0))
m2
(1+.0811-.0220+.0077-.0688-.0047-.0115-.0486-.1077)*mean(lmrk) sqrt(m2$sigma2)
Box.test(m2$residuals,lag=12,type='Ljung')
pv=1-pchisq(8.2078,4)
pv
m3=arima(lmrk,order=c(8,0,0),fixed=c(NA,0,0,NA,0,0,NA,NA,NA)) m3
(1+.0826-.0699-.0474-.1082)*mean(lmrk)
sqrt(m3$sigma2)
Box.test(m3$residuals,lag=12,type='Ljung')
pv=1-pchisq(8.779,8)
pv
at=lmrk-mean(lmrk)
Box.test(at^2,lag=6,type='Ljung')
Box.test(at^2,lag=12,type='Ljung')
pacf(at^2,lag.max=36)
library(fGarch)
arch1=garchFit(lmrk~garch(3,0),data=lmrk,trace=F) summary(arch1)。