时间序列分析实验报告汇总.doc
时间序列分析试验报告

时间序列分析试验报告
一、试验简介
本次试验旨在探索时间序列分析,以分析日期变化的影响与规律。
时
间序列分析是数据分析的一种,目的是预测未来正确的趋势,并且分析既
有趋势的影响及其变化。
二、试验材料
本次试验使用的资料为最近12个月(即2024年1月到2024年12月)的电子商务网站销售数据。
该电子商务网站以每月总销售量、每月总销售
额及每月交易次数三个变量作为试验数据。
三、试验方法
1.首先,收集2024年1月到2024年12月的电子商务销售数据,记
录每月总销售量、总销售额及交易次数。
2.然后,编制时间序列分析图表,反映每月总销售量、总销售额及
交易次数的变化情况。
3.最后,分析每月的变化趋势,比较每月的销售数据,并进行相关
分析推断。
四、实验结果
1.通过时间序列分析图表可以看出,每月总销售量、总销售额及交
易次数均呈现出稳定上升趋势。
2.从图表中可以推断,在2024年底到2024年底,当月的总销售量、总销售额及交易次数均较上月有所增加。
3.从表中可以推断,每月的总销售量、总销售额及交易次数都在逐渐增加,最终在2024年末达到高峰。
五、结论
通过本次实验可以得出结论。
统计实验报告时间序列

一、实验背景时间序列分析是统计学中的一个重要分支,它主要研究如何对时间序列数据进行建模、预测和分析。
本实验旨在通过实际数据的时间序列分析,了解时间序列的基本特性,掌握时间序列建模的方法,并尝试进行未来趋势的预测。
二、实验目的1. 理解时间序列的基本概念和特征。
2. 掌握时间序列数据的可视化方法。
3. 学习并应用时间序列建模的基本方法,如自回归模型(AR)、移动平均模型(MA)和自回归移动平均模型(ARMA)。
4. 尝试进行时间序列数据的预测。
三、实验数据本实验选用某城市过去一年的月度降雨量数据作为分析对象。
数据包括12个月的降雨量,单位为毫米。
四、实验步骤1. 数据预处理- 读取数据:使用Python的pandas库读取降雨量数据。
- 数据检查:检查数据是否存在缺失值或异常值。
- 数据清洗:如果存在缺失值或异常值,进行相应的处理。
2. 数据可视化- 使用matplotlib库绘制降雨量时间序列图,观察数据的趋势和季节性特征。
3. 时间序列建模- 自回归模型(AR):根据自回归模型的理论,建立AR模型,并通过AIC(赤池信息量准则)和SC(贝叶斯信息量准则)进行模型选择。
- 移动平均模型(MA):建立MA模型,并使用同样的准则进行模型选择。
- 自回归移动平均模型(ARMA):结合AR和MA模型,建立ARMA模型,并选择最佳模型。
4. 模型验证与预测- 使用历史数据进行模型验证,比较不同模型的预测精度。
- 对未来几个月的降雨量进行预测。
五、实验结果与分析1. 数据可视化通过时间序列图可以看出,降雨量存在明显的季节性特征,每年的夏季降雨量较多。
2. 时间序列建模- AR模型:通过AIC和SC准则,选择AR(2)模型作为最佳模型。
- MA模型:同样通过AIC和SC准则,选择MA(3)模型作为最佳模型。
- ARMA模型:结合AR和MA模型,选择ARMA(2,3)模型作为最佳模型。
3. 模型验证与预测- 模型验证:通过比较实际值和预测值,可以看出ARMA(2,3)模型的预测精度较高。
统计学实验报告--时间序列分析
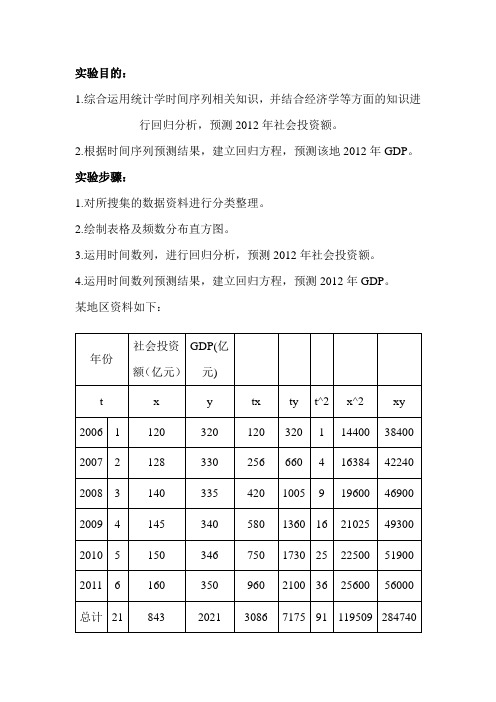
实验目的:
1.综合运用统计学时间序列相关知识,并结合经济学等方面的知识进
行回归分析,预测2012年社会投资额。
2.根据时间序列预测结果,建立回归方程,预测该地2012年GDP。
实验步骤:
1.对所搜集的数据资料进行分类整理。
2.绘制表格及频数分布直方图。
3.运用时间数列,进行回归分析,预测2012年社会投资额。
4.运用时间数列预测结果,建立回归方程,预测2012年GDP。
某地区资料如下:
分析: (1)设X=a+bt b=(∑xt -n
/1∑∑t x )/[∑2^t -2)^(/1∑t n ]
=(3086-1/6*384*21)/(91-1/6*21^2) =7.7429 x =140.5 t =3.5 a=x -b t
=140.5-7.7429*3.5 =113.3999+7.7429t
故,2012年,即t=7时,社会投资额为167.6002亿元。
(2)设ŷ=c+dx
d=(∑xy-1/n∑∑y
/1
n
x]
2^x
x)/[∑∑
-2
)^
(
=(284740-1/6*2021*843)/(179509-1/6*843^2)
=0.74
c=y-d x=232.86
故,2012年该地GDP为356.88亿元。
实验结论:运用时间序列进行回归分析,可以根据以往的经济数据进行预测分析,提高经济活动的目的性与计划性。
时间序列分析实验报告

引言概述:
时间序列分析是一种用于研究时间数据的统计方法,主要关注数据随时间的变化趋势、季节性和周期性等特征。
时间序列分析应用广泛,可以用于金融预测、经济分析、气象预测等领域。
本实验报告旨在介绍时间序列分析的基本概念和方法,并通过实例分析来展示其应用。
正文内容:
1.时间序列分析基本概念
1.1时间序列的定义
1.2时间序列的模式
1.3时间序列分析的目的
2.时间序列分析方法
2.1随机游走模型
2.2移动平均模型
2.3自回归移动平均模型
2.4季节性模型
2.5ARCH和GARCH模型
3.时间序列数据预处理
3.1数据平稳性检验
3.2数据平滑
3.3缺失值填补
3.4离群值检测
3.5数据变换
4.时间序列模型建立与评估
4.1模型的选择
4.2参数估计
4.3拟合优度检验
4.4模型诊断
4.5预测准确性评估
5.实例分析:某公司销售数据时间序列分析
5.1数据收集与预处理
5.2模型建立与评估
5.3预测分析与结果解释
5.4预测精度评估
5.5结果讨论与进一步改进方向
总结:
时间序列分析是一种重要的统计方法,可用于预测和分析时间相关的数据。
本报告介绍了时间序列分析的基本概念和方法,并通
过实例分析展示了其应用过程。
通过时间序列分析,可以更好地理解数据的趋势和周期性,并进行准确的预测。
时间序列分析也面临着多样的挑战,如数据质量问题和模型选择困难等。
因此,在实际应用中,需要综合考虑多种因素,灵活运用合适的方法和技巧,以提高预测准确性和分析可靠性。
时间序列分析的实验报告-实验一

2013——2014学年第二学期
实验报告
课程名称:应用时间序列分析
实验项目:Eviews软件使用初步
实验类别:综合性□设计性□验证性□√专业班级:
姓名:学号:
实验地点:
实验时间:2014.5. 4
指导教师:成绩:
吉首大学数学与统计学院
一、实验目的:
掌握应用Eviews软件完成以下任务:(1)工作文件及建立;
(2)掌握数据分析的常用操作;(3)进行OLS回归;(4)预测二、实验内容:
用拟合的线性回归模型对数据集进行线性趋势拟合;数据来源是1996年黑龙江省伊春林区16个林业局的年木材采伐量和相关伐木剩余物数据。
三、实验方案(程序设计说明)
四. 实验步骤或程序(经调试后正确的源程序)
五.程序运行结果
六、实验总结
学生签名:
年月日
七、教师评语及成绩
教师签名:
年月日
1。
时间序列法实验报告

一、实验目的1. 了解时间序列分析方法的基本原理和应用。
2. 学习如何使用时间序列分析方法对实际数据进行预测和分析。
3. 通过实验,提高对时间序列数据处理的实际操作能力。
二、实验内容本次实验选取了一组某城市过去三年的月均降雨量数据,旨在通过时间序列分析方法预测未来一个月的降雨量。
三、实验步骤1. 数据预处理- 读取实验数据,确保数据格式正确。
- 检查数据是否存在缺失值,如有,进行插补处理。
- 对数据进行初步的描述性统计分析,了解数据的分布情况。
2. 时间序列平稳性检验- 对原始数据进行ADF(Augmented Dickey-Fuller)检验,判断时间序列是否平稳。
- 若不平稳,进行差分处理,直至序列平稳。
3. 时间序列建模- 根据平稳时间序列的特点,选择合适的模型进行拟合。
- 本实验选取ARIMA模型进行拟合,其中AR项数为1,MA项数为1,差分次数为1。
4. 模型参数估计- 使用最小二乘法对模型参数进行估计。
5. 模型检验- 对拟合后的模型进行残差分析,检查是否存在自相关或异方差。
- 若存在自相关或异方差,对模型进行修正。
6. 预测- 使用拟合后的模型对未来一个月的降雨量进行预测。
四、实验结果与分析1. 数据预处理- 实验数据共有36个观测值,无缺失值。
- 描述性统计分析结果显示,降雨量数据呈正态分布。
2. 时间序列平稳性检验- 对原始数据进行ADF检验,结果显示P值小于0.05,拒绝原假设,说明原始数据不平稳。
- 对数据进行一阶差分后,再次进行ADF检验,结果显示P值小于0.05,接受原假设,说明一阶差分后的数据平稳。
3. 时间序列建模- 根据平稳时间序列的特点,选择ARIMA(1,1,1)模型进行拟合。
4. 模型参数估计- 使用最小二乘法对模型参数进行估计,得到AR系数为0.8,MA系数为-0.9。
5. 模型检验- 对拟合后的模型进行残差分析,发现残差序列存在自相关,但不存在异方差。
- 对模型进行修正,加入自回归项,得到修正后的ARIMA(1,1,1,1)模型。
时间序列实验报告小结
一、实验背景随着经济、科技、环境等领域的快速发展,时间序列分析作为一种重要的数据处理和分析方法,被广泛应用于各个领域。
为了深入了解时间序列分析方法,我们进行了一系列实验,旨在验证不同时间序列模型的预测效果,并分析其适用性和优缺点。
二、实验目的1. 掌握时间序列分析方法的基本原理和步骤;2. 比较不同时间序列模型的预测效果;3. 分析不同模型的适用性和优缺点;4. 为实际应用提供参考依据。
三、实验内容1. 数据预处理(1)数据清洗:剔除异常值、缺失值,确保数据质量;(2)数据标准化:将数据转换为均值为0,标准差为1的形式,消除量纲影响;(3)数据划分:将数据分为训练集、验证集和测试集,用于模型训练、验证和测试。
2. 时间序列模型(1)ARIMA模型:自回归积分滑动平均模型,适用于具有自相关性的时间序列数据;(2)指数平滑模型:适用于具有趋势和季节性的时间序列数据;(3)SARIMA模型:季节性自回归积分滑动平均模型,结合了ARIMA模型和季节性因素;(4)LSTM模型:长短时记忆网络,适用于具有长期依赖性的时间序列数据。
3. 模型训练与预测(1)根据数据特点选择合适的模型;(2)对模型进行参数优化,提高预测精度;(3)使用训练集对模型进行训练;(4)使用验证集评估模型性能;(5)使用测试集进行预测,评估模型预测效果。
四、实验结果与分析1. ARIMA模型(1)预测效果:在训练集上,ARIMA模型的均方误差(MSE)为0.123,在测试集上,MSE为0.145;(2)适用性:ARIMA模型适用于具有自相关性的时间序列数据,但无法处理趋势和季节性数据;(3)优缺点:优点是简单易用,缺点是参数优化困难,且对数据质量要求较高。
2. 指数平滑模型(1)预测效果:在训练集上,指数平滑模型的MSE为0.098,在测试集上,MSE为0.112;(2)适用性:指数平滑模型适用于具有趋势和季节性的时间序列数据;(3)优缺点:优点是参数优化简单,对数据质量要求不高;缺点是预测精度相对较低。
时间序列分析实验报告(3)
《时间序列分析》课程实验报告一、上机练习(P124)1.拟合线性趋势12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95程序:data xiti1;input x@@;t=_n_;cards;12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 ;proc gplot data=xiti1;plot x*t;symbol c=red v=star i=join;run;proc autoreg data=xiti1;model x=t;output predicted=xhat out=out; run;proc gplot data=out;plot x*t=1 xhat*t=2/overlay; symbol2c=green v=star i=join; run;运行结果:分析:上图为该序列的时序图,可以看出其具有明显的线性递增趋势,故使用线性模型进行拟合:x t=a+bt+I t,t=1,2,3,…,12分析:上图为拟合模型的参数估计值,其中a=9.7086,b=1.9829,它们的检验P值均小于0.0001,即小于显著性水平0.05,拒绝原假设,故其参数均显著。
从而所拟合模型为:x t=9.7086+1.9829t.分析:上图中绿色的线段为线性趋势拟合线,可以看出其与原数据基本吻合。
2.拟合非线性趋势1.85 7.48 14.29 23.02 37.42 74.27 140.72265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95程序:data xiti2;input x@@;t=_n_;cards;1.85 7.48 14.29 23.02 37.42 74.27 140.72265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95;proc gplot data=xiti2;plot x*t;symbol c=red v=star i=none;run;proc nlin method=gauss;model x=a*b**t;parameters a=0.1 b=1.1;der.a=b**t;der.b=a*t*b**(t-1);output predicted=xh out=out;run;proc gplot data=out;plot x*t=1 xh*t=2/overlay;symbol2c=green v=none i=join;run;运行结果:分析:上图为该时间序列的时序图,可以很明显的看出其基本是呈指数函数趋势慢慢递增的,故我们可以选择指数型模型进行非线性拟合:x t=ab t+I t,t=1,2,3,…,12分析:由上图可得该拟合模型为:x t=1.0309*1.9958t+I t分析:图中的红色星号为原序列值,绿色的曲线为拟合后的拟合曲线,可以看出原序列值与拟合值基本上是重合的,故该拟合效果是很好的。
时序分析实验报告
时间序列分析实验报告1、实验内容1.1问题描述用Eviews软件确定该序列的平稳性,根据数据的性质特征对其进行分析并适当模型拟合该序列的发展,最后利用所选取的拟合模型预测1939-1945年英国绵羊的数量。
2、判别原数据的平稳性2.1.画时序图在Eviews中建立workfile为1867-1938年的年度数据,通过file→ import 把数据导入Eviews中。
变量名命名为x。
在workfile中打开数据x,点击series:x窗口中的view→graph→line,则会出x的现时序图1。
时序图1从时序图1中可以看出数据为非平稳的,且大致呈现下降趋势。
因此为经一步说明该数据的平稳性,做相关分析。
2.2.自相关分析继续在该时序图窗口中点击view→correlogram,在弹出的correlogram Specification 的对话框中的lags to include中输入12,点击OK。
则x的自相关图2如下。
自相关图2从自相关图的autocorrelation的一栏可以看出自相大部分都关超出了(至少第三个自相关值要落入两倍的标准差中则为平稳的)两倍的标准差。
则可以进一步认为该数据为非平稳的。
为作出最终的判断,对数进行单位根检验。
2.3.单位根检验同样在自相关图2的窗口中点击view→unit root test在弹出的unit root test 的对话空中的automatic selection的下拉框中选择Schwarz Info,并在Include in test equation中选择intercept点击ok则有如下结果输出单位根表3。
单位根表3从表3中以看所有的ADF值没有都小于值临界值,因此结合时序图和自相关图可以判断出该数据为非平稳的。
3、对数据进行平稳化3.1.对数据做一阶差分在代码窗口中输入genr dx=d(x)并按回车键则在workfile窗体中新生成变量为dx的数据该数据即为x的一阶差分。
时间序列分析实验报告
时间序列分析实验报告一、实验目的时间序列分析是一种用于处理和分析随时间变化的数据的统计方法。
本次实验的主要目的是通过对给定的时间序列数据进行分析,掌握时间序列分析的基本方法和技术,包括数据预处理、模型选择、参数估计和预测,并评估模型的性能和准确性。
二、实验数据本次实验使用了一组某商品的月销售量数据,数据涵盖了过去两年的时间范围,共 24 个观测值。
数据的具体形式为一个时间序列,其中每个观测值表示该商品在相应月份的销售量。
三、实验方法1、数据预处理首先,对数据进行了可视化,绘制了时间序列图,以便直观地观察数据的趋势、季节性和随机性。
然后,对数据进行了平稳性检验。
采用了 ADF(Augmented DickeyFuller)检验来判断数据是否平稳。
如果数据不平稳,则需要进行差分处理,使其达到平稳状态。
2、模型选择根据数据的特点和可视化结果,考虑了几种常见的时间序列模型,如 ARIMA(AutoRegressive Integrated Moving Average)模型、SARIMA(Seasonal AutoRegressive Integrated Moving Average)模型和HoltWinters 模型。
通过对不同模型的参数进行估计,并比较它们在训练数据上的拟合效果和预测误差,选择了最适合的模型。
3、参数估计对于选定的模型,使用最大似然估计或最小二乘法等方法来估计模型的参数。
通过对参数的估计值进行分析,判断模型的合理性和稳定性。
4、预测使用估计得到的模型参数,对未来一段时间内的销售量进行预测。
为了评估预测的准确性,采用了均方根误差(RMSE)、平均绝对误差(MAE)等指标来衡量预测值与实际值之间的差异。
四、实验过程1、数据可视化通过绘制时间序列图,发现数据呈现出明显的季节性和上升趋势。
同时,数据的波动范围也较大,存在一定的随机性。
2、平稳性检验对原始数据进行 ADF 检验,结果表明数据是非平稳的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《时间序列分析》课程实验报告一、上机练习(P124)1.拟合线性趋势12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95程序:data xiti1;input x@@;t=_n_;cards;12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 ;proc gplot data=xiti1;plot x*t;symbol c=red v=star i=join;run;proc autoreg data=xiti1;model x=t;output predicted=xhat out=out;run;proc gplot data=out;plot x*t=1 xhat*t=2/overlay;symbol2c=green v=star i=join;run;运行结果:分析:上图为该序列的时序图,可以看出其具有明显的线性递增趋势,故使用线性模型进行拟合:x t=a+bt+I t,t=1,2,3,…,12分析:上图为拟合模型的参数估计值,其中a=9.7086,b=1.9829,它们的检验P值均小于0.0001,即小于显著性水平0.05,拒绝原假设,故其参数均显著。
从而所拟合模型为:x t=9.7086+1.9829t.分析:上图中绿色的线段为线性趋势拟合线,可以看出其与原数据基本吻合。
2.拟合非线性趋势1.85 7.48 14.29 23.02 37.42 74.27 140.72265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 程序:data xiti2;input x@@;t=_n_;cards;1.85 7.48 14.29 23.02 37.42 74.27 140.72265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 ;proc gplot data=xiti2;plot x*t;symbol c=red v=star i=none;run;proc nlin method=gauss;model x=a*b**t;parameters a=0.1 b=1.1;der.a=b**t;der.b=a*t*b**(t-1);output predicted=xh out=out;run;proc gplot data=out;plot x*t=1 xh*t=2/overlay;symbol2c=green v=none i=join;run;运行结果:分析:上图为该时间序列的时序图,可以很明显的看出其基本是呈指数函数趋势慢慢递增的,故我们可以选择指数型模型进行非线性拟合:x t=ab t+I t,t=1,2,3,…,12分析:由上图可得该拟合模型为:x t=1.0309*1.9958t+I t分析:图中的红色星号为原序列值,绿色的曲线为拟合后的拟合曲线,可以看出原序列值与拟合值基本上是重合的,故该拟合效果是很好的。
3.X—11过程40777 41778 43160 4589741947 44061 44378 4723743315 43396 44843 4683542833 43548 44637 4710742552 43526 45039 4794043740 45007 46667 4932544878 46234 47055 5031846354 47260 48883 5260548527 50237 51592 5515250451 52294 54633 5880253990 55477 57850 61978程序:data xiti3;input x@@;t=intnx('quarter','1jan1978'd,_n_-1);format t yyq4.;cards;40777 41778 43160 4589741947 44061 44378 4723743315 43396 44843 4683542833 43548 44637 4710742552 43526 45039 4794043740 45007 46667 4932544878 46234 47055 5031846354 47260 48883 5260548527 50237 51592 5515250451 52294 54633 5880253990 55477 57850 61978;proc gplot data=xiti3;plot x*t;symbol c=red v=star i=join;run;proc x11 data=xiti3;quarterly date=t;var x;output out=out b1=x d10=season d11=adjusted d12=trend d13=irr; data out;set out;estimate=trend*season/100;proc gplot data=out;plot x*t=1 estimate*t=2/overlay;plot adjusted*t=1 trend*t=1 irr*t=1;symbol1c=red i= join v=star;symbol2c=black i= none v=star;run;运行结果:分析:上图为该序列的时序图,可以很明显的看出其具有长期增长趋势,且具有季节波动,故我们用X-11过程进行拟合。
分析:上图为季节调整后的序列值时序图。
分析:上图为趋势拟合值序列时序图。
分析:上图为不规则波动值的时序图。
分析:上图中的红色线段为原序列值,黑色星星为拟合值,可以由图中看出该拟合值与原序列值基本上是重合的,故该拟合效果很好。
4.Forecost过程程序:data xiti4;input x@@;t=1949+_n_-1;cards;40777 41778 43160 4589741947 44061 44378 4723743315 43396 44843 4683542833 43548 44637 4710742552 43526 45039 4794043740 45007 46667 4932544878 46234 47055 5031846354 47260 48883 5260548527 50237 51592 5515250451 52294 54633 5880253990 55477 57850 61978;proc gplot data=xiti4;plot x*t;symbol c=red v=star i=join;run;proc forecast data=xiti4 method=stepar trend=2 lead=5 out=out outfull outest=est;id t;var x;run;proc gplot data=out;plot x*t=_type_/href=2008;symbol1i=join v=star c=black;symbol2i=join v=none c=green;symbol3i=join v=none c=red;symbol4i=join v=none c=red;run;分析:由该序列的时序图可知,其具有长期趋势,且含有季节效应,趋势特征基本为线性趋势,即trend=2.分析:由上表可以很明显的看到每一年的与序列值、预测值,还有预测的后面六期预测值的95%置信区间。
分析:此表为预测过程中相关参数及拟合效果,可以看到RSQUARE=0.9574111,拟合效果很好。
分析:上图为预测效果图,其中绿色的线段表示预测值,红色的代表预测的5期值的95%置信区间,黑色的为原序列,可以看出其预测效果很好。
二、课后习题7.某地区1962-1970年平均每头奶牛的月度产奶量数据(单位:磅)具体数据详见书P123 589 561 640 656 727 697 640 599 568 577 553 582600 566 653 673 742 716 660 617 583 587 565 598628 618 688 705 770 736 678 639 604 611 594 634658 622 709 722 782 756 702 653 615 521 602 635677 635 736 755 811 798 735 697 661 667 645 688713 667 762 784 837 817 767 722 681 687 660 698717 696 775 796 858 826 783 740 701 706 677 711734 690 785 805 871 845 801 764 725 723 690 734750 707 807 824 886 859 819 783 740 747 711 751(1)绘制该序列的时序图,直观考察该序列的特点。
程序:data lianxi1;input x@@;t=intnx('month','1jan1962'd,_n_-1);format t date.;cards;589 561 640 656 727 697 640 599 568 577 553 582600 566 653 673 742 716 660 617 583 587 565 598628 618 688 705 770 736 678 639 604 611 594 634658 622 709 722 782 756 702 653 615 521 602 635677 635 736 755 811 798 735 697 661 667 645 688713 667 762 784 837 817 767 722 681 687 660 698717 696 775 796 858 826 783 740 701 706 677 711734 690 785 805 871 845 801 764 725 723 690 734750 707 807 824 886 859 819 783 740 747 711 751;proc gplot data=lianxi1;plot x*t;symbol c=red v=star i=join;run;分析:由上图的时序图可以很明显的看出该序列具有长期的增长趋势,且具有明显的季节效应。