RAID6三块硬盘离线数据恢复案例
raid恢复

raid恢复RAID恢复:保护你的数据完整性摘要:RAID(独立磁盘冗余阵列)是一种用于保护数据完整性的技术。
当RAID系统遭遇故障时,恢复数据成为至关重要的任务。
本文将介绍RAID恢复的概念、原因和常见的恢复方法,以及一些建议来预防和处理RAID故障。
引言:在现代计算机系统中,存储数据是至关重要的任务。
RAID是一种主流的数据存储技术,通过将数据分散存储在多个独立的磁盘上,提供了数据冗余和容错能力。
然而,RAID系统仍然可能遭遇故障,例如硬盘故障、控制器损坏或不完全的数据写入。
当这些故障发生时,RAID恢复就成为了重要的任务。
一、RAID恢复的概念RAID恢复是指在RAID系统遭遇故障或数据丢失后,通过使用冗余的数据副本或数据重建过程,将数据还原到正常状态的过程。
恢复过程的目标是尽可能地恢复所有数据,并尽快将RAID系统恢复到正常工作状态。
二、常见的RAID故障原因1. 硬盘故障:当RAID系统中的硬盘发生故障时,RAID的冗余机制可以帮助保护数据。
然而,如果多个硬盘同时发生故障,RAID系统可能无法正常工作。
2. 控制器故障:RAID控制器是管理整个RAID系统的关键组件。
如果控制器发生故障,可能导致RAID系统无法读取或写入数据。
3. 错误操作:错误的操作或配置可能导致RAID系统数据损坏或丢失。
4. 电源故障:电源故障可能导致RAID系统无法正常工作,进而导致数据丢失。
三、常见的RAID恢复方法1. 热备份恢复:RAID系统中的热备份是指在RAID故障发生时,系统自动从冗余的备份中恢复数据。
这是最常见和最简单的RAID 恢复方法之一。
2. 数据重建:如果RAID系统中的硬盘发生故障,数据重建是一种常见的恢复方法。
数据重建通过使用其他剩余的硬盘上的数据,将数据从故障硬盘中还原。
3. 数据恢复软件/工具:有一些专门的数据恢复软件和工具可以用于恢复损坏或丢失的RAID数据。
这些工具可以尝试从故障的RAID 系统中恢复数据。
RAID 磁盘阵列数据恢复

我们也可以混合选择物理硬盘和镜像文件.
单击 "Open drives" 选择的每个硬盘或镜像的容量会显示在右边,同时RAID 的总容量将显示在下面:
注意: 我们输入的硬盘个数可以小于阵列的长度. 在这个例子中 #drives 仍然是 3 ,但可以保留一个空的驱动器分析 RAID 结构,确定正确的磁盘次序、块大小和旋转方向.
单击 拷贝 "Copy". 现在开始重构RAID:
下一步是什么?
如果我们运气好的话,把这个RAID镜像拷贝到另一个硬盘或阵列上,就能直接通过操作系统存取这个设备上的文件,这样数据恢复就成功了。否则, 你还要用 Runtime 的GetDataBack 或其它数据恢复工具试试,能否成功就要取决于数据的损坏程度了。
选择上面描述的项(最有可能的是第一项)并单击 完成“Finish”. 这样就把我们选择的参数拷贝到主屏幕。拷贝 RAID现在我们就准备把RAID 拷贝到另一个镜像文件或另一个驱动器上,当然目标设备必须有足够的空间来容纳这个RAID。
在目的 "Target" 框中输入要拷贝得文件名和路径. 它可以是物理驱动器名(如"HD132:"), 也可以是镜像文件名(如E:\raid.img").
因为 RAID 5 冗余性, 如果原阵列里的磁盘数为N ,RAID Reconstructor 通过N-1 个磁盘也能重新计算出原来的数据。
使用Raid Reconstructor的三个简单的步骤:规定 RAID 阵列的组合
输入原始 RAID 5 阵列的硬盘数.然后我们输入RAID的每个物理硬盘或硬盘镜像文件。如果你使用物理硬盘名,这些硬盘必须是可以访问的。我们可以使用镜像文件代替物理硬盘(这个镜像文件可以用Runtime的 GetDataBack 或DiskExplorer建立。
硬盘低格时断电损坏修复方法

硬盘低格时断电损坏修复方法全文共四篇示例,供读者参考第一篇示例:硬盘是计算机中非常重要的组成部分,其中存储着大量的数据和文件。
在日常使用中,有时候会遇到硬盘低格的情况,即在对硬盘进行格式化的过程中突然断电导致硬盘损坏。
这个问题对于很多用户来说都是比较头疼的,因为里面存储的数据可能非常重要,一旦损坏就可能无法恢复。
那么如何修复这种情况下的硬盘损坏呢?接下来我们就来详细介绍一下。
一、硬盘低格时断电损坏的原因及表现硬盘低格时断电损坏通常是由于处理过程中突然断电造成的。
当硬盘在进行低格操作时,会删除硬盘上的所有数据并重新分区格式化。
如果在这个过程中突然断电,就可能导致硬盘损坏。
这时,硬盘可能无法被识别,或者不能正常读取数据。
1. 使用数据恢复工具如果硬盘低格时断电造成的损坏比较严重,无法被识别或者读取数据,可以尝试使用一些专业的数据恢复工具来修复。
这些工具可以深入硬盘内部进行扫描和恢复数据,可能会花费一定的时间和精力,但是在大多数情况下可以成功恢复数据。
2. 使用硬盘修复工具除了数据恢复工具之外,还有一些专门用于修复硬盘的工具,比如硬盘修复工具。
这些工具可以诊断硬盘的问题并修复损坏的部分,恢复硬盘的正常运行状态。
使用这些工具需要有一定的专业知识和经验,否则可能会导致数据丢失或者硬盘进一步损坏。
3. 寻求专业帮助如果以上方法都无法修复硬盘低格时断电造成的损坏,建议及时寻求专业帮助。
有些硬盘损坏比较严重,需要专业的硬盘修复公司进行修复。
他们有专门的设备和技术,可以对硬盘进行深度修复,帮助恢复丢失的数据。
1. 在进行低格操作时,最好在电脑充电或者连接UPS电源的情况下进行,避免因为突然断电造成硬盘损坏。
2. 定期备份数据,避免因为硬盘损坏导致数据丢失。
可以将重要数据备份到外部硬盘或者云端存储,确保安全。
3. 定期检查硬盘的状态,如果发现硬盘有问题及时修复,避免硬盘损坏加重。
硬盘低格时断电造成的损坏是比较麻烦的问题,但是通过一些专业的方法和工具是可以修复的。
关于raid磁盘阵列数据恢复的技巧攻略PPT文档共24页

2、要冒一次险!整个生命就是一场冒险。走得最远的人,常是愿意 去做,并愿意去冒险的人。“稳妥”之船,从未能从岸边走远。-戴尔.卡耐基。
梦 境
3、人生就像一杯没有加糖的咖啡,喝起来是苦涩的,回味起来却有 久久不会退去的余香。
关于raid磁盘阵列数据恢复的技巧攻略 4、守业的最好办法就是不断的发展。 5、当爱不能完美,我宁愿选择无悔,不管来生多么美丽,我不愿失 去今生对你的记忆,我不求天长地久的美景,我只要生生世世的轮 回里有你。
21、要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。——培根 22、业精于勤,荒于嬉;行成于思,毁于随。——韩愈
23、一切节省,归根到底都归结为时间的节省。——马克思 24、意志命运往往背道而驰,决心到最后会全部推倒。——莎士比亚
25、学习是劳动,是充满思想的劳动。——乌申斯基
RAID恢复
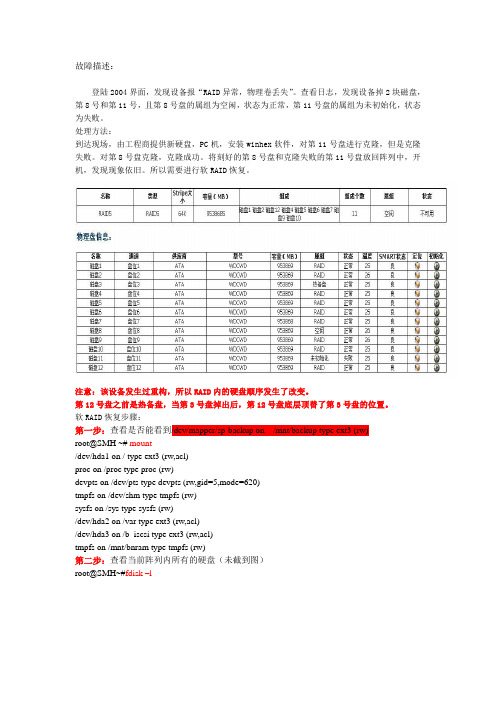
故障描述:登陆2004界面,发现设备报“RAID异常,物理卷丢失”。
查看日志,发现设备掉2块磁盘,第8号和第11号,且第8号盘的属组为空闲,状态为正常,第11号盘的属组为未初始化,状态为失败。
处理方法:到达现场,由工程商提供新硬盘,PC机,安装winhex软件,对第11号盘进行克隆,但是克隆失败。
对第8号盘克隆,克隆成功。
将刻好的第8号盘和克隆失败的第11号盘放回阵列中,开机,发现现象依旧。
所以需要进行软RAID恢复。
注意:该设备发生过重构,所以RAID内的硬盘顺序发生了改变。
第12号盘之前是热备盘,当第3号盘掉出后,第12号盘底层顶替了第3号盘的位置。
软RAID恢复步骤:第一步:查看是否能看到/dev/mapper/sp-backup on /mnt/backup type ext3 (rw)root@SMH ~# mount/dev/hda1 on / type ext3 (rw,acl)proc on /proc type proc (rw)devpts on /dev/pts type devpts (rw,gid=5,mode=620)tmpfs on /dev/shm type tmpfs (rw)sysfs on /sys type sysfs (rw)/dev/hda2 on /var type ext3 (rw,acl)/dev/hda3 on /b_iscsi type ext3 (rw,acl)tmpfs on /mnt/bnram type tmpfs (rw)第二步:查看当前阵列内所有的硬盘(未截到图)root@SMH~#fdisk –lroot@SMH ~#cd /proc/sys/dev/raidroot@SMH /proc/sys/dev/raid# lsspeed_limit_max speed_limit_min 第三步:确认有这两条命令root@SMH /proc/sys/dev/raid# echo 0 >speed_limit_maxroot@SMH /proc/sys/dev/raid# echo 0 >speed_limit_min 第四步:将重构速度降为0,保证阵列不再读写,防止自动重构。
RAID磁盘阵列数据恢复方法-天盾数据恢复中心

RAID磁盘阵列数据恢复方法
对于服务器物理层故障,主要是指服务器阵列SAS、SCSI 硬盘由于硬盘内部磁头或者电机原因引起的故障。主要表现 是硬盘通电敲盘, 硬盘通电不转, 硬盘通电不识别。 这种 情况,一般公司技术人员没办法恢复, 需要专业数据恢复 人员进行恢复。 可能还涉及到硬盘开盘恢复, 建议不要自 行操作, 可以联系数据恢复中心, 由工程师诊断故障原因 在制定恢复方案。
(2)奇偶校验 奇偶校验通过对所有数据进行冗余校验实现确保数据的有效性。利用奇偶校 验,当RAID系统的一个磁盘发生故障时,其它磁盘能够重建该故障磁盘。 (3)磁盘镜像 镜像是将数据同时写入两个驱动器的技术,如果一个磁盘发生故障,镜像磁 盘将接替它进行运行。 (4)奇偶校验 异或(XOR)是进行奇偶校验的一种方法,从每个磁盘中取出一位(0和1) 并相加。如果和为偶数,则奇偶为被置为0;如果和为奇数,则奇偶位被置为1。根 据RAID等级,奇偶校验即可保存到一个磁盘上,也可分配到所有磁盘上。
RAID磁盘阵列数据恢复方法-天盾数据恢复中心
前言
服务器数据安全有着至关重要的意义, 目前大多数服务器都采用了RAID磁盘阵列技术。受服务器自身硬件局限和技术人员的操作因素,服务器无阵列无法做到100% 的无故障发生。 那么RAID磁盘阵列故障有哪些? RAID磁盘阵列如何进行数据恢复?
RAID0
RAID磁盘阵列数据恢复方法
对于RAID坏道层故障 服务器坏道层故障,主要是指, 磁盘阵列中SCSI、SAS硬盘由于一块或者多块有坏道引起操 作系统产生如无法启动, 启动操作系统蓝屏, 启动操作 系统死机等故障。坏道里的数据无法读取,有坏道的硬盘需 要做全盘镜像,只有镜像完成之后,才能着手去重组硬盘阵 列,然后导出数据。
服务器阵列硬盘顺序出错导致数据丢失怎么办?
服务器阵列硬盘顺序出错导致数据丢失怎么恢复?
服务器磁盘阵列内的硬盘是否有顺序要求?相信很多用户对这方面都没有过多的认识,以至于在整理服务器设备时,经常没有考虑到阵列硬盘的顺序,从而导致阵列中的磁盘顺序错乱,致使磁盘数据无法读取文件丢失,或是造成阵列丢失无法引导,在这种情况下,大家该怎么办呢?如何解决因服务器阵列硬盘顺序出错导致的数据丢失问题呢?
当出现服务器阵列硬盘顺序出错问题后,用户应该立即咨询专业数据恢复机构进行服务器数据找回。
无论你的RAID组合级别是RAID1,RAID0、RAID5、RAID6、RAID10、RAID50还是软RAID、跨区卷、动态磁盘.......也不论您的服务器是用何种操作系统,只要阵列出现问题,不要轻易做Rebuild,数据恢复中心均可恢复数据。
还拥有跨平台数据读取能力,即使用户使用的不是WINDOWS操作系统,亦可轻易恢复。
这个数据恢复中心采取磁盘镜像技术和只读不写的操作,彻底杜绝二次破坏,保证了服务器的安全,另外用户可全程关注数据恢复过程,涉密数据不离开用户的视线,这比任何保密协议都要有效。
奇校验下的三磁盘崩溃数据恢复策略①
奇校验下的三磁盘崩溃数据恢复策略①张华;冯凯平【摘要】Some disaster may result in the simultaneous collapse of multiple data disks on the data center storage system. If a mirror backup was used, it would be highly likely that the data cannot be recovered. But if the redundancy technology, based on the odd parity, is used, and it has been ensured that all disks have equal probability of operation, then not only can the technology recover the data of one or two collapsed data disks, but it can also recover the data of three or more simultaneously collapsed data disks.% 灾难发生的后果可能导致数据中心存储系统中的多个数据盘同时崩溃,如果采用镜像式备份,极有可能导致数据无法恢复。
而采用基于奇校验的冗余技术,在确保所有磁盘被操作概率相同的情况下,既可以对一个或者两个崩溃的数据盘进行数据恢复,也可以对三个或三个以上同时崩溃的数据盘进行数据恢复。
【期刊名称】《计算机系统应用》【年(卷),期】2013(000)008【总页数】4页(P151-154)【关键词】奇校验;数据盘;冗余技术;崩溃;数据恢复【作者】张华;冯凯平【作者单位】四川烹饪高等专科学校信息技术系,成都 610072;四川烹饪高等专科学校信息技术系,成都 610072【正文语种】中文如今, 大型数据中心的存储基础设施通常部署上万块硬盘, 随着存储阵列中硬盘数量的增多, 该阵列发生故障的概率在随之增加, 比如, 一个由 100块硬盘构成的阵列中, 每块硬盘的 MTBF大约为 750,000小时, 则整个阵列每隔7500小时就可能会发生硬盘崩溃. 另外, 磁盘数量的增大还使得多个磁盘同时发生故障的可能性加大, 特别当某种灾难发生时这种可能性就更大. 因此, 数据恢复技术就成为当今数据管理技术中的一大热点话题[1].在数据中心, 对数据盘的备份可以采用镜像备份技术, 一旦数据盘或备份盘发生故障, 均可以采用镜像盘对数据进行恢复. 在此情形下, 只要损坏的磁盘数量只有一个均可以对数据进行恢复. 如果出现两个磁盘同时崩溃的现象, 只要不出现数据盘与对应的备份盘同时崩溃, 也可以恢复数据. 但在镜像备份中,当数据盘与其镜像盘同时崩溃时其数据可能将无法恢复, 同样, 三个磁盘同时出现故障时也有类似的情形.另外, 采用镜像备份时, 数据盘的数量和备份盘的数量应相等.但是, 如果我们采用基于奇偶校验的冗余码技术,在两个磁盘或者三个磁盘同时崩溃的情况下, 任何两个盘或者三个盘同时崩溃, 均可以对数据进行恢复.而且, 通常冗余盘的数量低于数据盘数量.1 基于奇偶校验的单盘崩溃数据恢复策略以下分析中均以八位二进制代码表示磁盘中完整的数据块.假设有两个任意八位二进制代码: 10110010、11010101, 对每个位进行异或操作进行奇偶校验, 将得到异或码 01100111[2]. 事实上, 这三个码字互为异或, 第三个码字一定会在其它两个码字的基础上通过异或操作而得到, 或者说, 偶数个1校验值为0, 奇数个1校验值为1.如果这三个码字代表三个不同的磁盘, 其中两个为数据盘, 一个为冗余盘, 当其中的任意一个磁盘发生故障, 通过对其余两个磁盘的异或操作进行奇偶位校验, 就能够恢复被损坏盘的数据.在此, 数据盘数量为2, 冗余盘数量为1.2 两个磁盘同时崩溃后的数据恢复策略当两个以上磁盘同时发生崩溃时, 不能简单地用异或操作对其进行数据恢复. 采用基于RAID6的冗余技术[3], 首先建立一张冗余表, 如表 1. 根据冗余表反馈的0和1的分布规律来确定如何用未损盘数据对已损盘数据进行恢复.表1 修复双磁盘冗余码?对于由 7个磁盘组成的数据存储系统, 首先制作一张长度为7的冗余码表[2], 此表有以下特征:1)每列均有1;2)冗余盘部分每列一个1;3)数据盘部分每列两个以上的1;4)每行1的个数为偶数;5)7列冗余码均不相同.按偶数个1为0校验、奇数个1为1校验进行校验. 假设1、2、3、4号数据盘已分别写入以下数据:1号: 10110011、2号: 01010101、3号: 00100011、4号: 11011011按表1进行奇偶校验得到5、6、7号盘的数据为:5号: 01001011、6号: 00111101、7号: 11000101其中, 5号盘与1、3、4号盘进行异或操作; 6号盘与1、2、4号盘进行异或操作; 7号盘与1、2、3号盘进行异或操作. 每行均为四个1, 形成偶校验.如果2、4号盘同时崩溃, 可用冗余码第一行进行数据判断, 用1、3、7号盘的数据对2号盘进行数据恢复, 2号盘的数据被恢复之后, 可用冗余码表第二行或第三行对4号盘进行数据恢复.在此方案中, 数据盘数量为4, 冗余盘数量为3.3 基于奇校验的三磁盘崩溃数据恢复策略3.1 建立冗余表假设系统包含 13个磁盘, 其中数据盘数量为 8,编号为 1、2、…8. 冗余盘数量为 5, 编号 9、10、…13. 建立如表2的冗余表, 它有如下特征:1)每一列均有1;2)冗余盘的每一列仅有一个1;3)数据盘的每一列至少两个1;4)数据盘中的每一行均为偶数个1;5)13个磁盘冗余码每行每列各不相同.3.2 冗余盘数据规则数据盘上的数据是随机而任意的, 而冗余盘上的数据必须根据数据盘的内容进行设置.八个数据盘的数据可以任意写入:1号: 10110010、2号: 11001100、3号: 00110101、4号: 01010010、5号: 11001100、6号: 10101010、7号: 11100010、8号: 10011100以表2为参考, 冗余盘中的数据按以下规则设置:1)9号盘由1、5、7、8号数据盘进行奇校验, 每个盘对应位如果1的个数为偶数, 则9号盘的对应位为0, 反之, 如果1、5、7、8号盘的对应位为奇数个1时, 9号盘的对应位则为1;2)10号盘由2、3、4、8号数据盘进行奇校验;3)11号盘由1、3、6、8号数据盘进行奇校验;4)12号盘由2、4、5、7号数据盘进行奇校验;5)13号盘由2、3、5、6号数据盘进行奇校验;如此, 冗余表中的每一行有奇数个1, 形成奇校验.最终各冗余盘校验码为:9号: 00000000、10号: 00110111、11号: 10110001、12号: 10110000、13号: 100111113.3 写数据当对数据盘重新写数据后, 相对应的冗余盘代码必须随之改变. 设1号数据盘变为00101101, 如此, 9号冗余盘和11号冗余盘的冗余码应分别变为10011111和00101110, 其余冗余盘不变.冗余盘代码修正的过程实际上是一个 CPU查询冗余码表并进行相对简单的异或操作的过程, 由于不涉及其他的算术运算, 因此, CPU消耗的时间资源较少, 冗余效率较高.表2 修复三磁盘崩溃冗余码?同理, 如果对5号数据盘重新写数据后, 则9、12、13号冗余盘也将随之做相应改变.3.4 三个磁盘同时崩溃后的数据恢复任何三个磁盘损坏后, 均可通过表 2进行数据恢复, 前提是表2中三个盘的冗余码中仅有一个1, 且每一列代码均不相同, 否则可能出现三个坏盘只能够恢复其中一个的现象.假如2、3、7号盘同时损坏, 由表2查询可知, 在冗余码中的第三行, 2号盘的冗余码为0, 3号盘的冗余码为1, 7号的冗余码为0, 符合“三个盘的冗余码中仅有一个1”的要求.首先用1、6、8、11号盘的八位代码对3号数据盘相应位进行奇校验, 以第三位为例, 由于1、6、8、11号4个盘的第三位有3个1和1个0, 所以3号盘的第三位确认为1, 等等. 最后3号盘该数据块的第三位被恢复为: 00110101. 3号盘数据被恢复之后, 后续两个盘的数据恢复变得简单, 用表2冗余码的第2行或者第5行对2号盘进行数据恢复, 因为这两行的2号和7号盘的冗余码分别为1和0. 但第4行却由于2号盘和7号盘冗余码同时为1而不能使用.此例列举的实例中, 三个盘均为数据盘. 如果损坏盘中包含冗余盘, 或者损坏的三个盘均为冗余盘,其数据恢复方法相同, 只要能保证冗余表中三个损坏盘的冗余码仅有一个为1而其余两个为0即可.表2拥有8个数据盘, 而其中三个数据盘同时损坏的情况共有56种组合情形. 表2所列0、1序列可以做为公式使用, 它可以对56种所有可能损坏的盘序进行数据恢复. 以下VB代码证明了在表2中的任何一种情况均能保证三个损坏盘的冗余码中仅有一个 1,即所有组合均成立.Dim p(8) (定义8个磁盘的冗余码)p(1)= "10100": p(2)= "01011"p(3)= "01101": p(4)= "01010"p(5)= "10011": p(6)= "00101"p(7)= "10010": p(8)= "11100"ki = 0For i = 1 To 6 (损坏的某一个盘可能是1-6号盘)For j = i + 1 To 7 (损坏的另一个盘可能是2-7号盘)For k = j + 1 To 8 (损坏的第三个盘可能是3-8号盘)For h = 1 To 5 (从第1位到第5位冗余码, 判断三个冗余码中是否仅有一个1) x=Mid(p(i),h, 1) (取第1个损坏盘第h位冗余码)y=Mid(p(j),h, 1) (取第2个损坏盘第h位冗余码)z=Mid(p(k),h,1) (取第3个损坏盘第h位冗余码)If Val(x) + Val(y) + Val(z) = 1 Then (三个损坏盘的冗余码是否仅有一个1)ki = ki + 1 (56种组合序号)Print ki; ":"; i; ","; j; ","; k; ":"; x; ","; y; ","; z (该种组合能够恢复所有损毁盘的数据) Exit ForEnd IfNextIf h = 6 Thenki = ki + 1Print ki; ":"; i; ","; j; ","; k (该种组合不成立, 不能够完全进行数据恢复)End IfNext: Next: Next以上代码并没有考虑冗余盘的存在, 但由于冗余盘的每一行仅有一个1, 而且每一列均不相同, 它对组合可行性判断没有影响. 因此, 表2这种0、1序列具备完全可行性, 适合于每一种组合.3.5 均衡性配置以上操作中, 任何一个数据盘数据的改变均要涉及冗余盘的读写, 因此, 冗余盘的工作负荷要远远大于数据盘. 事实上, 无论是数据盘还是冗余盘, 它们之间都是互为异或(互为奇偶对应)的[2,4], 因此, 为了保持所有磁盘工作强度的均衡性, 可将冗余盘所有存储空间按一定规则均匀分布到全部13个磁盘中[5].将13个磁盘分别命名为n=0、1、2、…12号, 设F为某一个磁盘的冗余柱面, F除以13取余数C, 即F mod 13=C, C则表示某一数据盘的盘号.当 F分别取 0、13、26、39、…等数字作为磁盘柱面编号时, 余数C=0, 因此, 0、13、26、39等柱面将作为 0号盘的基础柱面. 然后在基础柱面之上加 9并上推四个柱面即n+9、n+10、n+11、n+12, 这样, 对于n=0的基柱面, 与9、10、11、12共5个柱面作为0号磁盘的第一组冗余块; 同理, 对于0号磁盘的n=13的基柱面, 向上则与22、23、24、25形成另一组冗余块. 对0号盘的基柱面26、39…等情况类推.同理, 当F分别取1、14、27、40、…等作为基柱面时, C=F mod 13=1. 将这些柱面作为1号盘的起始冗余块, 然后再将另外四个柱面: n+9、n+10、n+11、n+12, 即10、11、12、13共5个柱面作为1号盘的第一组冗余块; 第二组冗余块组合为 14、23、24、25、26五个柱面. 等等.图1 13粒磁盘均衡性配置2号到12号盘的情况依此类推.如此, 13个盘被读和写的负荷概率均为 1/13. 具体应用时, 仍然采用表 2作为冗余码表进行数据恢复操作.由于每个盘除了被写正常数据外还要写冗余数据,因此, 每个磁盘的写概率将大于1/13.仅对 8个数据盘而言, 每个盘的被写概率是 1/8.观察表2可知, 1、4、6、7号盘的写操作将涉及两个冗余盘的写操作, 比如1号盘的写涉及9、11号冗余盘的写; 2、3、5、8号盘的写将涉及三个冗余盘的写, 其中2号盘的写涉及10、11、13号冗余盘的写. 因此, 13个盘总的写概率为(1/8)×3×4+(1/8)×4×4=7/2, 平均每个盘的写概率为(7/2)/13=7/26.4 扩展修复4个同时崩溃的磁盘利用表2可以对某些情况下发生四个盘同时损坏的情况进行数据恢复, 前提是四个盘的冗余码表中仅有一个1, 如2、4、8、9号盘同时崩溃, 利用表2中的第三行冗余码, 首先对8号盘利用1、3、6、11号盘的数据进行奇偶校验后进行数据恢复;8号盘被恢复之后, 再利用第一行冗余码对 9号盘进行数据恢复;最后再恢复2、4号盘.对四个盘同时损坏的情况, 仅利用表2并不能对所有组合都能进行数据恢复, 如2、4、5、7号盘同时损坏则无法恢复, 它在表 2中无法找到这四个盘有且仅有一个1的情形.5 结语目前, 单个磁盘的MTBF大约为750000小时, 则三个盘同时崩溃的概率大约为63万年, 13个磁盘同时出现三个盘同时崩溃的概率为630000/56, 约为11000年, 对于1个1500个磁盘的系统, 其概率大约为100年. 另据研究表明, 当一个磁盘损坏后, 其他磁盘损坏的概率将会上升[1]. 这种概率对于一个大型数据存储机构而言是很高的. 特别当发生某种自然灾难如数据库节点的爆炸、火灾及恶意破坏的计算机病毒等,此概率大增. 本文针对三个磁盘损毁设计的冗余码表,可以以较少的 CPU代价实现三个或更多磁盘同时崩溃后的数据恢复.对于数据中心, 在实际应用过程中将每13个磁盘划分为一组, 就可以对存储系统中所有磁盘进行三磁盘损坏的恢复数据操作.参考文献【相关文献】1 董欢庆,李战怀,林伟.raid_vcr:一种能够承受三个磁盘故障的raid结构.计算机学报,2006,29(5):792-800.2 Garcia-Molina H, Ullman JD, Widom J. Database System Implementation. Palo Alto, California: Stanford University,2010,1:584-587.3 汪中夏,张京生,刘伟.RAID 数据恢复技术揭秘.北京:清华大学出版社,2010.35-45.4 刘伟.数据恢复技术深度揭秘.北京:电子工业出版社,2010.51-54.5 张京生,汪中夏,刘伟.数据恢复方法及案例分析.北京:电子工业出版社,2008.474-478.6 戴士剑.数据恢复与硬盘修理.北京:电子工业出版社,2012.4-7.7 佚名.解析 RAID6:最新的冗余技术.2006-10-07. .。
一种面向RAID6固态阵列的数据盘失效快速修复方法
一种面向RAID6固态阵列的数据盘失效快速修复方法万洪浩;邓明翥;肖侬;刘芳【期刊名称】《计算机研究与发展》【年(卷),期】2015(0)S2【摘要】近年来,闪存正被越来越广泛地应用到各种各样的存储系统当中.同时,闪存技术的革新促使单个设备存储容量剧增,这导致了基于固态硬盘的阵列(RAIS)系统中单设备失效的修复时间急剧增加,在其恢复过程中将有更高的概率影响到其他设备的可靠性,从而降低整个系统的可靠性.针对实际RAID6系统应用中较为广泛的RDP编码进行分析和问题抽象化,提出了一种基于固态硬盘阵列的编码算法RAIS+方法,并证明了其优越性.RAIS+方法通过添加一个冗余盘来减少大容量单盘失效的修复时间.RAIS+方法权衡了系统的可靠性、性能、写更新、负载情况以及可行性.例如,RAIS+方法在原8个设备的RAID6系统上,任意单个数据盘失效的修复时间能够减少约为18.5%.【总页数】6页(P62-67)【关键词】RAID6编码;额外冗余;快速修复;RDP编码;修复时间;单盘失效【作者】万洪浩;邓明翥;肖侬;刘芳【作者单位】国防科学技术大学计算机学院【正文语种】中文【中图分类】TP333【相关文献】1.基于RAID6的冗长度修复数据的设计方法 [J], 梁志恒;2.面向纠删码的低成本多节点失效修复方法 [J], 郑力明;李晓冬3.面向自动修复并融合失效场景的缺陷定位方法 [J], 李昂;毛晓光;雷晏4.一种容三盘失效纠删码的单数据盘失效快速重建方法 [J], 邱丽娜;王芳;李楚5.阵列失效单元非凸压缩感知平面近场快速诊断方法 [J], 李玮;邓维波;杨强;MARCO Donald Migliore因版权原因,仅展示原文概要,查看原文内容请购买。
如果NAS坏了,如何恢复(拯救)数据(学习资料)?
如果NAS坏了,如何恢复(拯救)数据(学习资料)?开篇碎碎念大家好,之前搞了一台蜗牛星际,整机到手即用,给它安装了某晖的NAS系统,花了半天时间,将我之前放在硬盘中的所有学习资料(正常资料)全部转移到了这台NAS中。
之前一直用外接硬盘方式保存资料,苦了这些跟随我多年的学习资料,之前TA们连个草屋都没有,现在终于有个大房子了,怎么样,蜗牛颜值还是在线吧,感觉依旧是性价比很高的NAS神器~ 入的最喜欢的B款有预算的就上白的吧,支持正版,都说要有忧患意识,我也不例外,我突然想到如果这台NAS崩了或者坏了,里面的学习资料如何恢复呢?下面就来看看恢复NAS硬盘数据的几种常见方法,主要是结合官方资料总结了一些恢复方法,给有需要的朋友参考下~当然,主要是以群晖NAS示范,因为手上只有这台,其他NAS也有官方方法,换汤不换药。
温馨提示:本篇只是简单演示常见NAS数据的『非专业』恢复方法,仅适用于恢复可再生的学习资料,重要资料请求助专业数据恢复机构!老样子,依旧有视频版的,不想看视频版的小伙伴就看下面的文字版吧~NAS坏了,如何恢复数据!拯救方法一最简单的方法当然是新买一台,在群晖官网已经有说明,如何在两台群晖机器间迁移数据?此页面直达链接:如何在两台 Synology NAS(DSM 6.0 及更高版本)之间迁移数据?当然,也有DSM5.0的官方迁移方法,链接在此:如何在两台Synology NAS (DSM 5.x) 之间迁移数据?提供了两台不同型号机器之间的数据迁移和相同型号机器之间的数据迁移,这里也列出了哪些型号机器是可以进行数据迁移的,并且包含了许多注意事项这种方法比较适用于白群,有些组了raid的硬盘迁移到新机器时硬盘位置要相同,黑群的话盘符或位置基本都是乱序的,有点难搞~ 当然,本篇假想是NAS坏了的情况下而又没新NAS可以迁移数据的情况下,如何进行数据恢复,前面也简单提一下做为参考~拯救方法二第2种方法就是没有新机器的情况下如何进行数据恢复,首先来模拟NAS损坏的场景,以最常见的Basic硬盘模式和Raid 1硬盘模式进行测试数据恢复的操作。