eviews使用简单讲解
第1讲Eviews基本命令的掌握

第1讲Eviews基本命令的掌握Eviews基本命令的掌握要求:①掌握Eviews 基本操作:包括建⽴⼯作⽂件,录⼊数据,Eviews⼯作命令⽅式。
②了解并熟悉eviews基本函数的使⽤以及假设检验。
Eviews简介:见演⽰⽂档⼀、Eviews 基本操作1. 启动Eviews双击Eviews 图标,出现Eviews 窗⼝,它由以下部分组成:标题栏“Eviews ”、主菜单“⽂件,编辑,…,帮助”、命令窗⼝(空⽩处)和⼯作区域。
2.产⽣⽂件Eviews 的操作在⼯作⽂件中进⾏,故⾸先要有⼯作⽂件,然后进⾏数据输⼊、分析等等操作。
(1)读已存在⽂件:⽂件/打开/Workfile 。
(2)新建⽂件:⽂件/新建/Workfile ,出现对话框“⼯作⽂件范围”,选取或填上数据类型、起⽌时间。
填好后,得到⼀个⽆名字的⼯作⽂件,其中有:时间范围、当前⼯作⽂件样本范围、Filter、默认⽅程、系数向量C 、序列残差。
附:1Annual选项:可以⽤四位年份如Start date:1955 End date 1998,在1900年和2000年之间的年份只需要后两位即可。
Quarterly选项: 输⼊格式为: 1992:1, 65:4, 2002:3年后⾯只能跟1、2、3、4代表季度。
Monthly选项: 输⼊格式Examples: 1956:1, 1990:11年后⾯为⽉Weekly and daily选项: 在缺省状态下的格式如8:10:97即为October 8, 1997. Undated or irregular选项:为⾮⽇期数据如:Start date:1 End date 100,即为100个数的⼀个序列。
附:2保存Workfile可以⽤两种⽅法保存Workfile,第⼀种⽅法点击主窗⼝中File/SaveAs or File/Save;第⼆,Workfile窗⼝中的⼯具栏中的Save按钮即可以保存。
打开Workfile⽤File/Open/Workfile的⽅式可以打开以前保存的Workfile改变workfile的显⽰⽅式:选择View/Display Filter,或者双击workfile窗⼝中的Filter.*就会出现如下的对话框在*号后⾯填⼊你想要显⽰的变量(中间⽤空格阁开),点OK即可3.输⼊数据(1)从键盘输⼊:快速的quick/空组empty group (编辑系列) ,打开组窗⼝,产⽣⼀个⽆标题“组”;按列在表中输⼊序列名(在OBS )及其数据,每输⼊⼀个数据完,敲⼀次enter 。
eviews使用指南与案例

eviews使用指南与案例Eviews使用指南与案例。
Eviews是一款广泛用于经济学、金融学和统计学等领域的专业数据分析软件,其强大的数据处理和分析功能受到了广大用户的青睐。
本文将为大家介绍Eviews的基本使用方法,并结合实际案例进行详细说明,希望能够帮助大家更好地掌握这一工具。
首先,我们来看一下Eviews的基本操作流程。
在打开Eviews软件后,首先需要新建一个工作文件,选择“File”中的“New”选项,然后选择“Workfile”来创建一个新的数据工作文件。
在新建工作文件后,可以导入需要分析的数据,Eviews支持导入多种格式的数据文件,如Excel、CSV等,用户可以根据实际情况选择合适的数据导入方式。
在导入数据后,我们可以进行数据的预处理工作,包括数据的清洗、变量的转换、缺失值的处理等。
Eviews提供了丰富的数据处理工具,用户可以根据需要进行相应的操作。
接下来,我们可以进行数据的描述性统计分析,包括数据的均值、标准差、相关系数等指标的计算,以及绘制数据的直方图、散点图等图表来直观地展现数据的特征。
在数据的基本分析完成后,我们可以进行更深入的统计分析,如回归分析、时间序列分析等。
Eviews提供了丰富的统计分析工具,用户可以根据实际需求选择合适的方法进行分析。
在进行统计分析时,我们还可以进行模型的建立和检验,以及参数的估计和显著性检验等工作,从而得到对实际问题的有效解释和预测。
除了基本的数据分析功能外,Eviews还提供了强大的数据可视化工具,用户可以通过图表、表格等形式将分析结果直观地展现出来。
同时,Eviews还支持数据的导出和报告的生成,用户可以将分析结果导出到Word、Excel等格式的文件中,或者直接在Eviews中生成报告,方便进行结果的分享和展示。
在实际应用中,Eviews可以广泛用于经济预测、金融风险分析、市场调研等领域,其强大的数据分析功能可以帮助用户更好地理解和解决实际问题。
Eviews软件使用说明

Eviews软件使用说明Eviews软件使用说明1.引言1.1 背景信息Eviews是一种强大的计量经济学和时间序列分析软件,具有数据管理、统计分析、图形展示等功能。
本文档旨在提供Eviews软件的详细使用说明,帮助用户更好地掌握该软件的功能和操作方法。
2.安装和启动2.1 硬件和软件需求在使用Eviews之前,确认您的计算机符合软件的最低硬件和软件要求,并安装好所需的依赖库和驱动。
2.2 安装Eviews通过Eviews官方网站最新的安装程序,并按照安装向导的提示完成软件的安装。
2.3 启动Eviews双击桌面上的Eviews图标或通过开始菜单中的Eviews快捷方式启动软件。
3.数据导入与管理3.1 导入数据通过Eviews提供的数据导入功能,可以从多种文件格式(如Excel、CSV等)中导入数据。
3.2 数据浏览和编辑在Eviews中,可以方便地浏览和编辑已导入的数据,包括修改列名、调整数据格式等。
3.3 数据变换与处理Eviews提供了多种数据变换和处理的功能,如数据平滑、差分等,以满足用户对数据的需求。
4.统计分析4.1 描述性统计Eviews可以计算出数据集的各种描述性统计量,并相应的报告。
4.2 假设检验通过Eviews提供的假设检验功能,可以对单个变量或多个变量进行各种假设检验,如t检验、F检验等。
4.3 回归分析Eviews拥有强大的回归分析功能,可以进行简单回归、多元回归等各类回归分析,并提供了丰富的回归结果和诊断工具。
5.时间序列分析5.1 时间序列图Eviews可以绘制各种时间序列图形,包括线图、散点图、自相关图等,以帮助用户更好地理解时间序列数据的特征。
5.2 预测模型建立通过Eviews提供的时间序列建模功能,可以建立AR、MA、ARMA等各类时间序列模型,并进行模型的拟合和预测。
5.3 模型诊断与优化Eviews提供了一系列模型诊断与优化工具,如残差分析、模型优化、模型比较等,以帮助用户评估和改进建立的时间序列模型。
EViews基本操作与数据分析

EViews基本操作与数据分析EViews基本操作与数据分析一、EViews的基本操作与数据处理1、建立工作文件(File/New/Workfile)、数据库(Database)、程序(Program)或文本文件(Text File)。
(1)EViews的界面:菜单栏下面的白色空白区域为命令窗口。
(2)打开空表:Quick/Empty Group。
(3)Workfile的界面:c表示截距序列,resid表示残差序列。
2、输入数据(1)数据分为时间序列数据(Dated-regular Frequency,默认选项)、横界面数据(Unstructured/Undated)和面板数据(Balanced Panel),时间序列的日期间隔符号可以是“:”、“.”或“,”。
Q表示季度,M表示月份,W表示周。
(2)EViews也可以直接打开已有文件(Open/EViews Workfile)、外部数据(Foreign Data)、数据库(Database)、程序(Program)或文本文件(T ext File)。
EViews 5.0可以导入其他的外部数据:File/Open/Foreign Data as Workfile。
(3)调用外部数据:File/Import/……。
先建立工作文件,然后才能调用数据,EViews允许调用3种格式的数据:ASCII、Lotus和Excel工作表。
如果原文件已有序列名称,则只需输入序列个数即可。
3、对象(Object)的操作与处理(1)生成新对象(New Object):Equation、Graph、Group、Matrix、Series、Table、Text、V AR等。
(2)对象的编辑:剪切(Cut)、复制(Copy)、粘贴(Paste)、删除(Delete)、合并(Merge)和替代(Replace)等。
(3)对象的命名:对象必须以半角字符命名,不能用中文命名,命名不宜太长。
eviews使用技巧

eviews使用技巧1. 转换数据类型:Eviews可以读取多种不同的数据文件,如文本文件、Excel文件等。
在读取数据之后,你可以使用Eviews的内置函数将数据转换为不同的数据类型,例如将字符型数据转换为数值型数据或者将文本数据转换为日期型数据。
这样可以方便你在进行后续的数据分析和建模过程中使用。
2. 数据清理:在进行数据分析之前,通常需要对数据进行清理。
Eviews提供了很多数据清理的功能,包括删除重复观测值、处理缺失值、识别和处理异常值等。
通过使用这些功能,你可以有效地清理数据,减少错误和噪声对分析结果的影响。
3. 数据变换:Eviews提供了多种数据变换的函数,可以帮助你对数据进行处理,使其更符合分析和建模的要求。
例如,你可以使用对数变换将非线性数据转化为线性关系,或者使用差分运算获取数据的一阶差分,以便进行时间序列分析等。
4. 建模与预测:Eviews是一个强大的统计建模和预测软件。
你可以使用Eviews中的函数和工具进行各种建模和预测任务,如回归分析、时间序列分析、面板数据分析等。
通过Eviews的建模和预测功能,你可以得到准确的分析结果和可靠的预测结果。
5. 图表展示:Eviews提供了丰富的图表展示功能,可以帮助你更直观地理解和分析数据。
你可以使用Eviews绘制各种统计图表,如散点图、直方图、线图等。
此外,Eviews还支持可视化地展示模型的拟合情况和预测结果,使你能够更清晰地了解模型的性能和有效性。
6. 批处理:Eviews支持批处理功能,可以帮助你批量运行多个分析任务。
通过编写脚本,你可以一次性运行多个Eviews 命令,节省时间和劳动力成本。
批处理功能在需要运行多个相似的分析或模型时非常有用。
7. 自定义函数和程序:Eviews提供了自定义函数和程序的功能,使你能够根据自己的需求创建自己的函数和程序。
通过自定义函数和程序,你可以扩展Eviews的功能,实现更复杂和个性化的分析和模型。
eviews使用指南与案例

eviews使用指南与案例EViews是一款经济统计软件,广泛应用于经济学、金融学等领域的数据分析和建模工作。
本文将为大家介绍EViews的使用指南和一些实际案例,帮助读者更好地了解和应用EViews。
一、EViews的使用指南1. EViews的安装和启动:首先,用户需要下载并安装EViews软件。
安装完成后,双击桌面上的EViews图标即可启动软件。
2. 数据导入和处理:EViews支持导入多种数据格式,如Excel、CSV等。
用户可以使用“File”菜单中的“Import”选项将数据导入EViews中,并进行必要的数据清洗和处理。
3. 数据探索和描述统计分析:在导入数据后,用户可以使用EViews提供的数据探索功能进行数据分析,包括数据的描述统计分析、数据可视化等。
4. 模型建立和估计:EViews提供了多种经济学模型的建立和估计方法,如回归分析、时间序列分析等。
用户可以通过选择相应的命令和参数来进行模型建立和估计。
5. 模型诊断和检验:在模型建立和估计完成后,用户需要对模型进行诊断和检验。
EViews提供了多种模型诊断和检验的功能,如残差分析、异方差性检验等。
6. 模型预测和模拟:EViews可以基于已建立的模型进行预测和模拟。
用户可以输入新的自变量数据,通过模型预测因变量的值,或者进行模型的蒙特卡洛模拟分析。
7. 结果输出和报告生成:EViews可以将分析结果以表格、图形等形式输出,并支持生成报告和文档。
用户可以选择相应的输出选项和格式,方便结果的展示和分享。
二、EViews的应用案例1. 时间序列分析:使用EViews可以进行时间序列数据的建模和分析。
例如,可以通过ARIMA模型对股票价格进行预测,或者通过VAR模型分析宏观经济变量之间的关系。
2. 经济政策评估:EViews可以用于评估不同经济政策对经济变量的影响。
例如,可以建立一个VAR模型,通过冲击响应分析来评估货币政策对通胀和经济增长的影响。
eviews操作说明解析

删除( Delete ):在当前(激活)窗口中删除对象。若 当前(激活)窗口是工作文件窗口,则删除已选定的对 象。 复制对象(Copy Object):复制一个
• 打印(Print):打印当前(激活)窗口中的内容。
功能选择(View Options):改变当前对象的操作功能。 随着当前对象性质的不同,功能选择(View Options) 中的内容也不同。
•撤销(Undo):撤销最后一次操作,恢复到最后一次操
作以前的状态。
• 剪切(Cut):删除用拖动覆盖法选定的内容并放入剪切
板。
•复制(Copy):把所选定的内容存入剪切板。 •粘贴(Paste):把复制的内容粘贴到光标所在的位置。
•清除(Delete):清除所选定的内容。 •进行(Next):执行下一个预指定操作。 •合并(Merge):把一个文件合并到一个待修改
二、主菜单说明
(1) File键: 主菜单中File键的主要功能 :
•新建(New):创建新工作文件( New Workfile)。 •打开(Open):打开已有的工作文件。 •保存(Save):使用现存的文件名保存当前的工作文件,如
果文件尚未命名,则要求给出文件名,并指出保存路Байду номын сангаас。
•另存(Save as):用另一个文件名保存当前文件。 •关闭(Close):关闭当前的窗口。如尚未做最后保
存,将出现对话框提醒你保存。
•打印(Print):打印当前(激活)窗口的显示结果。
•打印设置(Print
Setup): 通过打印设置选择对话 框控制打印设置。
•运行(Run):运行EViews程序文件。 •退出(Exit):关闭所有窗口,并退出EViews。
第二章 EViews的基本操作
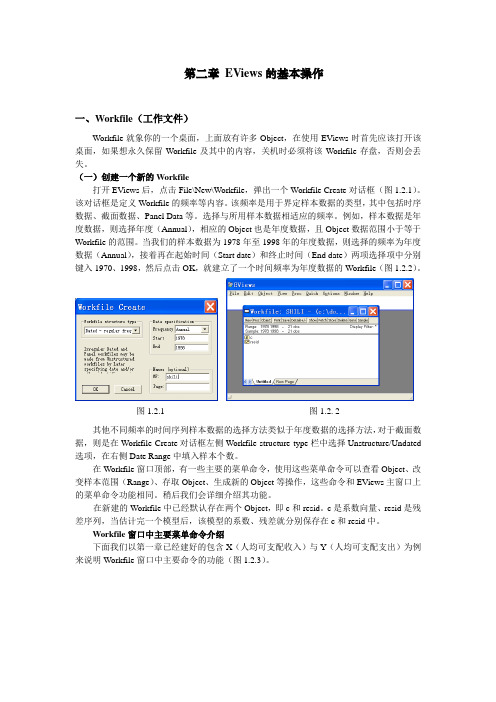
第二章EViews的基本操作一、Workfile(工作文件)Workfile就象你的一个桌面,上面放有许多Object,在使用EViews时首先应该打开该桌面,如果想永久保留Workfile及其中的内容,关机时必须将该Workfile存盘,否则会丢失。
(一)创建一个新的Workfile打开EViews后,点击File\New\Workfile,弹出一个Workfile Create对话框(图1.2.1)。
该对话框是定义Workfile的频率等内容。
该频率是用于界定样本数据的类型,其中包括时序数据、截面数据、Panel Data等。
选择与所用样本数据相适应的频率。
例如,样本数据是年度数据,则选择年度(Annual),相应的Object也是年度数据,且Object数据范围小于等于Workfile的范围。
当我们的样本数据为1978年至1998年的年度数据,则选择的频率为年度数据(Annual),接着再在起始时间(Start date)和终止时间(End date)两项选择项中分别键入1970、1998,然后点击OK,就建立了一个时间频率为年度数据的Workfile(图1.2.2)。
图1.2.1图1.2. 2其他不同频率的时间序列样本数据的选择方法类似于年度数据的选择方法,对于截面数据,则是在Workfile Create对话框左侧Workfile structure type栏中选择Unstructure/Undated 选项,在右侧Date Range中填入样本个数。
在Workfile窗口顶部,有一些主要的菜单命令,使用这些菜单命令可以查看Object、改变样本范围(Range)、存取Object、生成新的Object等操作,这些命令和EViews主窗口上的菜单命令功能相同。
稍后我们会详细介绍其功能。
在新建的Workfile中已经默认存在两个Object,即c和resid。
c是系数向量、resid是残差序列,当估计完一个模型后,该模型的系数、残差就分别保存在c和resid中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据导入File-foreign data as workfile --2种选项的不同 File-new-workfile新变量的输入Object-new object-series 如:x ,双击打开后,edit+/-编辑,通过excel 复制粘贴,再一下结束Quick-generate series 通过已知变量的运算一元线性回归模型 and 多元线性回归模型t t t u bX a Y ++=t nt n t t t u X b X b X b a Y +++++= 2211非线性回归模型 常见有4种 双对数线性模型εγβ1x y = )ln()ln()ln(ln 1εβγ++=x y半对数模型—原先x or y 在指数上u x y ++=)ln(10αα u x y ++=10)ln(αα双曲函数模型(倒数模型)t tt u X Y ++=)1(21ββ多项式回归模型u x x x y n n +++++=ββββ 2210非线性回归模型,先用变量替换成为线性(一元or 多元)回归模型,然后做法相同。
虚拟变量模型⎩⎨⎧=另一种状态一种状态10t D eg ⎩⎨⎧=,男性女性1,0t D 研究定性变量的时候引入,比如说性别、种族、宗教、民族、婚姻状况、教育程度等。
一般的,定性变量有m 类,引入m-1个虚拟变量。
分布滞后模型t n t n t t t u x x x y +++++=--ββββ 1210对于时间序列数据,由于经济系统中的经济政策的传导、经济行为的相互影响和渗透都是需要一定时间的。
他们的数值是由某些滞后量决定的。
Eg 消费不仅取决于当期的收入,还取决于以前的收入。
先做图观察一下大体趋势,是否要取对数等。
Quick-graph 建立模型Quick-estimation equation 选择LS 变量第一个是因变量,常数项输入c 注:log (x )表示对x 取自然对数x (-1) 表示滞后一阶 ;x (-1 to -4)表示x (-1)、x (-2)、x (-3)、x (-4)其实,更方便快捷的是用execl进行普通的回归模型工具-加载宏-分析数据库and 分析数据库-vba函数工具-数据分析获取新变量“=”虚拟变量,简单编程eg:=IF(E2>400000,1,0)时间序列分析在处理有关时间序列的数据的时候,首先画图,看看是否需要季节调整Eg 冰激凌销售的例子。
季节性变动掩盖了经济发展的客观规律。
A原序列b调整后的序列(趋势循环要素)c季节因素d不规则扰动项季节调整2种方法1、剔除季节影响因素双击需要处理的变量名(打开)-proc-seasonal adjustment2、引入虚拟变量季节调整后的序列趋势和循环要素不能分解,方法主要有hp滤波方法。
双击需要处理的变量名(打开)-proc-Hodrick Prescott filterSmoothing parameter 中lambda 表示平滑参数的值,年度数据取100,季度和月度数据分别取1600和14400。
有些数据(如股票数据)不具有明显的季节波动和趋势变动。
用指数平滑方法进行拟合和预测。
(如名称所示,数据更加平滑)双击需要处理的变量名(打开)-proc-exponential smoothing无论是单方程计量经济学模型还是联立方程计量经济学模型,这种分析背后有一个隐含的假设,即这些数据是平稳的,否则的话,通常的t 、F 等假设检验是不可信的。
涉及时间序列数据的另一问题,成为虚假回归或者伪回归,即如果有两列时间序列数据表现出一致的变化趋势(非平稳的),即使他们之间没有任何经济关系,若进行回归也可表现出较高的可绝系数。
平稳性检验(单位根检验)Quick-series statistics-unit root test 哪阶差分拒绝,那阶差分平稳 框中直接选or eg gdp ;d(gdp) ;d(gdp,2) …ARMA 模型 and ARIMA 模型向量自回归 AR(p) ),0.(..~22211σεεφφφD I I x x x x t tp t p t t t ++++=---移动平均模型MA (q ) ),0(..~,211σεεθεθεD I I x t q t q t t t --+++= ARMA (p ,q )模型q t q t t p t p t t t x x x x -----+++++++=εθεθεφφφ 112211注:t x 序列必须是平稳的,如果原序列不平稳,用差分序列做该模型。
如果是d 阶差分,则称为ARIMA (p ,d ,q )模型。
第一,识别。
Quick-series statistics-correlogram 。
其中,autocorrelation 指示的是q ,第二列只是的是p第二,方程。
Quick-estimation equation LS 输入 eg :gdp c ar(1) ar(2) ma(1) ma(2)自回归条件异方差模型(ARCH)一些时间序列特别是金融时间序列,常常会出现某一特征的值成群出现的情况。
如对股票收益率序列建模,其随机扰动项往往在较大幅度波动后面伴随着较大幅度的波动,在较小幅度波动之后面紧接着较小幅度的波动,这种性质成为波动的集群性。
在一般回归分析和时间序列分析中,要求随机扰动项是同方差,但这类序列随机扰动项的无条件方差是常量,条件方差是变化的量。
这种情况下,需要使用条件异方差模型(ARCH)。
在普通回归之后,设立新变量=resid,可以作图观察等上图是股票价格指数回归残差图。
观察该图我们可以注意到波动的“成群”现象:波动在一些较长的时间内非常小,在其他一些较长的时间内非常大,这说明残差序列存在高阶ARCH 效应。
在方程界面选择view-residual test-heteroskedasticity tests-ARCH协整分析假定一些经济指标被某经济系统联系在一起,那么从长远看这些变量应该具有均衡关系,这是建立和检验模型的基本出发点。
在短期内,因为季节影响或随机干扰,这些变量有可能偏离均值。
如果这种偏离是暂时的,那么随着时间的推移将会回到均衡状态;如果这种偏离是持久的,就不能说明这些变量之间存在均衡关系。
协整被看做这种均衡关系性质的统计表示。
注:参与协整的每个变量必须是都是d阶单整(平稳)的,然后对原序列做协整分析。
2变量的协整,可以用EG 两步法进行检验。
首先对2变量进行回归,然后生成新序列,e=resid ,检验它是否为白噪声序列(满足~N (0,1))。
多变量的协整,johansen 检验法。
Quick-group statistics-cointegration test Eg at most 1 拒绝,则至少一个。
离散因变量通常的经济计量模型都是假定因变量是连续的,但是在现实的经济决策中经常面临许多选择的问题。
人们需要在可供选择的有限多个方案中做出选择,与通常被解释变量是连续变量的假设相反,此时因变量只取有限多个离散的值。
例如,人们对交通工具的选择,地铁、公共汽车或出租车;投资决策中,是投资股票还是房地产。
以这样的决策结果作为被解释变量建立的计量经济模型,称为离散因变量模型。
以二元选择模型为例。
即y=0,1i ki k i i i u x x x y ++++=βββ 2211⎩⎨⎧=选择第二种选择第一种01i y要强调的是,建模时输入的是y 的观测值,但估计对象不是原始模型而是模型(10.1.2)。
根据F 的不同,二元选择模型可以有不同的类型如下表:其中logit模型最常用。
Quick-estimate equation-binary Eg y c gdp m1受限因变量模型现实的经济生活中,有时会遇到这样的问题,因变量是连续的,但是受到某种限制,也就是说所得到的因变量的观测值来源于总体的一个受限制的子集,并不能完全反应总体的实际特征,那么通过这样的观测值来推断总体的特征就需要建立受限因变量模型。
当出现因变量受限问题时,应分别引进删失回归模型和截尾回归模型。
Quick- estimate equation- censored联立方程模型前面介绍的单方程模型,用于揭示单个变量(被解释变量)受多个变量影响形成的关系。
而现实的社会经济现象往往错综复杂,描述这种复杂关系考一个方程通常不够,因此需要考虑用一组方程加以说明,即使用多方程模型。
在联立方程中,由模型确定的变量称为内生变量,如供给需求模型中的t Dt S t P Q Q 、、,对应的称为外生变量。
外生变量和滞后内生变量称为先决变量。
一般的联立方程模型可记为ε+=AX BY (7.1.4)下面用工具变量法对联立方程模型进行估计Quick- estimate equation-TSLS向量自回归模型(V AR )传统的经济计量方法(如联立方程模型等结构性方法)是以经济理论为基础来描述变量关系的模型。
然而,经济理论通常并不足以对变量之间的动态联系提供一个严密的说明,而且内生变量既可以出现在方程的左端又可以出现在方程的右端使得估计和推断变得更加复杂。
为了解决这些问题而出现了一种用非结构性方法来建立各个变量之间关系的模型,即向量自回归模型(V AR )。
向量表示法 t t p t p t t εHx y Φy Φy +++⋅⋅⋅+=--11⎪⎪⎪⎪⎪⎭⎫ ⎝⎛+⎪⎪⎪⎪⎪⎭⎫ ⎝⎛+⎪⎪⎪⎪⎪⎭⎫ ⎝⎛++⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=⎪⎪⎪⎪⎪⎭⎫ ⎝⎛------kt t t dt t t p t k p t p t p t k t t kt t t x x x y y y y y y y y y εεε 21212111211121H ΦΦ 展开即为k 个方程组成。
注:1、在进行模型建立时,要对变量之间进行格兰杰因果关系检验 Quick-group statistics-granger causality test2、多变量的协整检验(已讲)Quick-estimate VAR(1) 选择模型类型(V AR Type ):无约束向量自回归(Unrestricted V AR )或者向量误差修正(Vector Error Correction )。
无约束V AR 模型是指V AR 模型的简化式。
(2) 在Estimation Sample 编辑框中设置样本区间(3) 输入滞后信息:在Lag Intervals for Endogenous 编辑框中输入滞后信息,表明哪些滞后变量应该被包括在每个等式的右端。
这一信息应该成对输入:每一对数字描述一滞后区间。
(4) 在Endogenous V ariables 编辑栏中输入相应的内生变量 (5)在Exogenous Variables 编辑栏中输入相应的外生变量 注:滞后阶数的选择,AIS 和SC 准则,要求越小越好。