基于k_means聚类算法的研究
基于改进K—Means算法的教学反思文本聚类研究

( 1 . S c h o o l o f C o mp u t e r S c i e n c e , S h a a n x i No r ma l U n i v e r s i t y , X i ’ a l l 7 1 0 0 6 2 , C h i n a ;
e n h a n c e t h e i r p r o f e s s i o n a l c a p a b i l i i t e s . Cl us t e i r ng t h e s a me t h e me o f t h e t e a c h i n g ef r l e c io t n t e x t b a s e d o n a l l i mp r o v e d K -Me ns a a l g o —
第2 3卷
第 l l 期
计 算 机 技 术 与 发 展
COMP UT ER r E CHNOL OGY AND DEVEL OP MENT
2 0 1 3年 1 1月
Vo 1 . 2 3 N o . 1 1 NO V. 2 01 3
基 于 改进 K— Me a n s 算 法 的教 学 反 思 文本 聚 类研 究
c l u s t e in r g p r o c e s s, s i mi l a r i  ̄ t h r e s h o l d i s i n t r o d u c d e t o l i mi t he t r e l f e c io t n t e x t s’ s i i l m a r i t y r ng a e s , ea r l i z i n g he t t e a c in h g ef r le ct i o n t e x t
基于k-means聚类算法的研究

第 7期
计 算 机 技Biblioteka 术 与 发 展 C0MP ER ECHNOL UT T OGY AND DEVE LOP MEN1 ’
V0. 1 No 7 12 .
2 1 年 7月 01
J l 2 1 uy 0 1
基 于 k me n — a s聚 类算 法 的研 究
黄 韬, 刘胜 辉 , 艳 娜 谭
HUANG o, U h n Ta LI S e g-h i TAN n-n u, Ya a
( c . f o u c.n eh - ri U i.fSiadT c . H bn108 。 hn ) Sh o mp ̄r iadT c .Ha n nv o c. eh , a i 5 0 0 C ia C S b n r
( 尔滨理 工大 学 计 算机 科 学与技 术 学院 , 哈 黑龙 江 哈 尔滨 10 8 ) 5 00
摘 要 : 析研 究聚 类分 析方法 , 多种 聚类分 析算 法进 行 分析 比较 , 分 对 讨论 各 自的优 点 和 不 足 , 同时 针 对原 k m as 法 - en 算
的 聚类结 果受 随机选 取初 始聚 类 中心的影 响较 大 的缺 点 , 出一 种 改进 算 法 。通过 将 对 数据 集 的 多次 采 样 , 提 选取 最 终较
中图分 类号 :P0 . T 316 文献 标识 码 : A 文章 编号 : 7 —2 X(0 10 — 04 0 1 3 69 2 1 )7 05 — 4 6
Re e r h o u trn g rt m s d o - a s s a c f Cl se i g Al o i h Ba e n K me n
Ab t a t An l z n e e r h t e me o fcu t ra a y i - a y e a d c mp r n i d fa g rt ms o l se n y i 。 i u s s r c : ay e a d r s a c h t d o l se l ss a l z n o a e ma y k n so o i h n n l h fcu t ra a ss d s s l c merr s e t e s e g s a d we k e s s Att e s me t i e p c v t n t n a n s . a i i r h e h me。 c o d n o t e we kn s s o e c u tr r s l fo g n a c r i g t a e s f t l se e u to r i a k-me s ag - h e h i l n a lo r h a i ini c ti fu n e b lc i g t e i i a l t r c n e s r d ml a mo i e g rt m s p o o e T o g k n a p e i r s sg f a n e c y s e t n t cus e t r a o y。 d f d a o i t in l e n h i l e n i l h i r p s d. hr u h t i g s a m l ma y t st aa s t c o s n u e o l se e t r br g d wn t e i a t fi i a l se e t r o i r e g rt m r a l . n me d t e , h o e f a s p r rcu t rc n e - i o mp c tl cu trc n e st mp ov d a o h g e t i o il i n h o ni l i y S mu tn o sy-t e ii a t ssa d d z d o e t ei i a l se e tr i s lc e i l e u l h n t da i tn a ie nc t cu t r n e s ee t d,ma e l se fe t mp o e t e mo . t — a i l a h ni l c k scu t re c r v d f h r r Dee i ur e c i w o t m r g ue a g r h Hk- a s t r u h t e d t f UCId t t t e r s l s o a n l i me h o g h a e o n aa s 。 u t h wst tHk- a s ag rt m s mo r mi e ti r v e h e h me o i n l h i r p o n n mp e o o d h n n tl k t a i i a —me sa g rt m i l se fe t a d i S u f l o o f r n e t e a v ie d i n a l o h i n cu t re f , c n t s u f rc n e c o r lt ef l . e e i Ke r s d t n n cus r g a g rt m ; me s ag r h y wo d : aa m i g; l t i o i i en l h k— a o i m n l t
基于K-means聚类算法的数据分析模型应用研究

关键词 : 回归模 型; K — me a n s聚类算法 ; 分析模 型; 预估 ; 显著性
D OI : 1 0 . 1 1 9 0 7 / r j d k . 1 6 2 5 3 4
中图 分 类 号 : TP 3 1 9
文献标识码 : A
文章编号 : 1 6 7 2 — 7 8 0 0 ( 2 0 1 7 ) 0 0 3 — 0 1 0 3 — 0 5 析的技术 , 以期 为 电 网管 理 优 化 提 供 参 考 。
同的 类 群 ; ② 将 每 一 类 典 型 台 区 的基 础 数 据 与 预 测 值 相 关 联, 通 过 线 性 回归 的方 式 建 立 数 学 预 测 模 型 ; ③ 将 需 要 预
测的数据输入模型 , 得 到输 出, 从 而 得 出每 一 类 台 区 的 合
理 预 测 值 。整 个模 型 建 立 的 流 程 如 图 1所 示 。 数据分析过 程 的主 要活 动 由识 别信 息 需求 、 收 集 数 据、 分 析处理数据 、 数据分析模型的建立组成 。
基 于 K— me a n s算 法 的 数 据 预 估 模 型 的 建 立 包 含 K—
me a n s聚类 与线 性 回归 两 部 分 。首 先 通 过 K— me a n s聚类
电 网数 据 , 能 够 带 来 可观 的经 济 与社 会 效 益 。以 分 析 预 测
线损为例 , 台 区线 损 管 理 通 过 比较 理 论 线 损 与 实 际线 损 的
范 围 内 台 区数 量 巨 大 , 彼 此 之 间差 别 较 大 , 无 法 采 用 统 一
模 式 进 行 管 理 。因 此 , 如 何 进 一 步 提 高 台区 线 损 管 理 的精 益化水平 , 给 出每 个 台 区 可 参 照 的 合 理 线 损 范 围 , 并 科 学 合 理 地 对 台 区线 损 进 行 监 视 , 及 时发现 异常 台 区, 分 析 原
基于K-means聚类算法的网络个性化学习行为研究

再变化 时终止 】 代使 得选 取 的聚类 中心越来越 接近 真 实 的簇 中心 , 。迭 聚类效 果将越 来越 好 , 最后 把 所有对 象划分 为 k个簇 。 K— a¥ me/ 聚类 算 法 的具 体步 骤 : l
输入 : 聚类 的数 目 k和包 含 n个数据 对象 的数据集 X:{ X , , ; X , … x f 输 出 : 个 簇 { S , , , 目标 函数 最小 。 k S ,: … S } 使 1 选 取聚类个 数 k ) 。 2 从数据集 中随机选 取 k 对 象作为初 始 的聚类 中心 c , … , ) 个 C , c。
表现出不同的学习行为和个性特征 , 远程教育工作者应根据学生 的个性化学习行 为, 当地将学生分 适 类, 从而有针对性地采取个性化教学策略, 提高教学效果。本文研究聚类分析的经典算法 K— e l算 m a¥ l 法- , 2 将其应 用于学 生 的网络学 习行 为 , 】 建立 了数据 挖掘模 型 , 合理 将学 生分类 , 进而提 出相 应 的教 学
尹 帮 治
( 河源市广播 电视 大学 工程技术教学部 , 广东 河源 [ 摘 5 70 ) 100
要] 聚类是 指按 照事物 问的相似性对事物进行 区分和 分类 的过 程。对 网络个性化 学习行为 中的
大量数据 , 首先对样本数据进行 了预处理 , 然后运用数据挖掘算 法 中的 K—m a8 法进行 分类, c. 算 n 获取各 类与
第2 5卷 第 9期
V0 . 5 No 9 12 .
荆 楚理 工 学 院 学报
J u n lo i g h n v ri f e h oo y o r a fJn c u U i est o c n l g y T
基于K-means算法的亚洲足球聚类研究
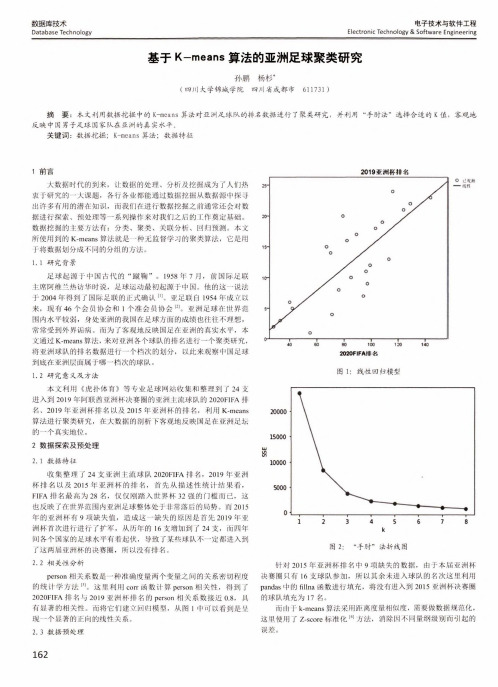
电子技术与软件工程Electronic Technology & Software Engineering数据库技术Database Technology 基于K-means 算法的亚洲足球聚类研究孙鹏杨杉*(四川大学锦城学院 四川省成都市 611731 )摘 要:本文利用数据挖掘中的K-means 算法对亚洲足球队的排名数据进行了聚类研究,并利用“手肘法”选择合适的K 值,客观地 反映中国男子足球国家队在亚洲的真实水平。
关键词:数据挖掘;K-means 算法;数据特征1前言大数据时代的到来,让数据的处理、分析及挖掘成为了人们热 衷于研究的一大课题,各行各业都能通过数据挖掘从数据源中探寻 出许多有用的潜在知识,而我们在进行数据挖掘之前通常还会对数 据进行探索、预处理等一系列操作来对我们之后的工作奠定基础。
数据挖掘的主要方法有:分类、聚类、关联分析、回归预测。
本文 所使用到的K-means 算法就是一种无监督学习的聚类算法,它是用 于将数据划分成不同的分组的方法。
1. 1研究背景足球起源于中国古代的“蹴鞠”。
1958年7月,前国际足联 主席阿维兰热访华时说,足球运动最初起源于中国。
他的这一说法 于2004年得到了国际足联的正式确认⑴。
亚足联自1954年成立以 来,现有46个会员协会和1个准会员协会⑵。
亚洲足球在世界范 围内水平较弱,身处亚洲的我国在足球方面的成绩也往往不理想, 常常受到外界诟病。
而为了客观地反映国足在亚洲的真实水平,本 文通过K-means 算法,来对亚洲各个球队的排名进行一个聚类研究, 将亚洲球队的排名数据进行一个档次的划分,以此来观察中国足球 到底在亚洲层面属于哪一档次的球队。
1. 2研究意义及方法本文利用《虎扑体育》等专业足球网站收集和整理到了 24支 进入到2019年阿联酋亚洲杯决赛圈的亚洲主流球队的2020FIFA 排 名、2019年亚洲杯排名以及2015年亚洲杯的排名,利用K-means 算法进行聚类研究,在大数据的剖析下客观地反映国足在亚洲足坛 的一个真实地位。
K-Means聚类算法的研究

Ab t a t Th l o t m fK- s r c : e a g r h o me n so e k n f ca sc l se n l o t m ,i c u i g b t n o n s a d as h r g s F r i a s i n i d o l s ia c u tr g ag r h l i i n ld n o h ma y p i t n lo s o t e . o a
Th s a c bo us e i g rt m f K -M e ns e Re e r h a ut Cl t rng Al o ih o a
ZHOU —wu.YU —f i Ai Ya e
( ol eo o ue cec n eh ooy A hi nvr t, ee 2 03 ,hn ) C lg f mp t S i eadTcn lg , n u U i sy H fi 30 9 C ia e C r n ei
第2 卷 1
第 2期
计 算 机 技 术 与 发 展
COMP UTER T : ECHNOLOGY AND DEVE LOP MENT
21 0 1年 2月
V0 . No. 1 2l 2 Fe . 2 b 011
K Me n — a s聚 类 算 法 的 研 究
周 爱武 , 于亚 飞
降低 , 而且 聚类结果 更接近 实际数 据分 布。
关键词 : — e n 算法 ; K M as 初始 聚类 中心 ; 孤立 点
中图 分类号 : P 0 . T 3 16 文献标 识码 : A 文章编 号 :6 3 6 9 2 1 ) 2 0 6 - 4 1 7 — 2 X( 0 1 0 — 0 2 0
K-means聚类算法研究

个数据对象作为初始的聚类中心 , 初 始的代表一个 聚类 。对于剩下的其他数据集 。 则分别计算它们 到 这些聚类中心的相似度 ( 以欧 氏距离作 为相似度 测 量准则) ,并根据最短距离将每个数据对象赋给 各 个聚类中心 。然后再计算新获得 的每一个聚类的距 离平均值得 到新 的聚类 中心 , 如果连续两次计算 出
进 行 了详 细 的分析 。
关键词 : 聚类分析 ; K — m e a n s 算法 中图分类号 : T P 3 1 1 文献标识码 : A 文章编号 : 1 6 7 2 - 4 4 7 X ( 2 0 1 3 ) 0 5 - 0 0 1 7 - 0 3 文 采 用 Ma l t a b 7 . 0实 现 了 K- me a n s 聚 类 算
法, 下面这个例子 , 显示 K - me a d s 聚类算法对于一 组二维数据集合 的聚类效果。
输入 : 包含 n 个数据对象的集合置,
x ={ X l , x 2 , … , X n }
b e i g n f o r j = 1 t o k d o
c o m p u t e D ( , z j ) = x i 一 l; / / 计算剩下的数
据对象到各聚类中心的距离 i f D ( , z ) = m i n { D ( X i Z ) } t h e n ∈ C j ; / / 根 据最 短距离将数据对象分类
J 已经收敛 , 聚类算法结束。通常采用平方误差准则
函数 作为 聚类目 标准则, 即 . , = ∑ : 。 ∑ 鹇I P 一 『,
∑g z 。 是分类 的中心 , 即 = 。 的数据 , 可以降低数据量及计算量 , 并可 以避免 杂 p是一个数据 对象 , ¨ 一,目 质的不 良影响。 上述算法的特 点是首先必须指定 k个初 始聚类 中 本 文简要介绍了 K - me a n s 聚类算法 的算法流 心, 然后借着 反复迭代运算 , 逐次降低 目标准则函 程, 复杂度 , 并用 Ma d a b实现 , 根据实验结果分析 了
K-means聚类算法的研究的开题报告

K-means聚类算法的研究的开题报告一、选题背景K-means聚类算法是一种常用的聚类算法,它可以把数据分成K个簇,每个簇代表一个聚类中心。
该算法适用于大数据分析、图像分析等领域。
由于其具有简单、快速、效果明显等特点,因此备受研究者的关注。
二、研究意义K-means聚类算法在大数据分析、图像分析等领域的应用广泛,研究该算法有着十分重要的意义。
本次研究将对该算法进行探究,通过改进和优化算法,提高其聚类效果和运行效率,为实际应用提供更加可靠、有效的解决方案。
三、研究内容与方法本研究将围绕K-means聚类算法展开,重点探讨以下内容:1. K-means聚类算法原理及优缺点分析2. 基于距离的K-means聚类算法优化3. 基于密度的K-means聚类算法研究4. 算法的实现与效果评估在研究方法上,将采用文献调研、数学统计方法、算法实现和效果评估等多种方法对K-means聚类算法进行研究。
四、计划进度安排本研究总计时长为12周,具体进度安排如下:第1-2周:文献调研,研究K-means聚类算法的原理和优缺点分析第3-4周:基于距离的K-means聚类算法优化第5-6周:基于密度的K-means聚类算法研究第7-8周:算法实现第9-10周:效果评估第11-12周:论文撰写和答辩准备五、预期研究结果本研究将针对K-means聚类算法进行深入探究,并尝试改进和优化算法,提高其聚类效果和运行效率。
预期研究结果将包括以下几个方面:1.对该算法的优缺点进行全面分析,揭示其内在机制和局限性。
2.基于距离和密度两种方法对算法进行优化,提高其聚类效果和运行效率。
3.通过实验评估算法效果,得出具体的结论。
4.输出论文成果,向相关领域进行贡献。
六、研究的难点1.算法优化的设计,需要具备一定的数学和计算机知识。
2.实验的设计需要满足实际应用场景,需要有较强的应用能力。
3.研究过程中可能遇到一些技术难点,需要耐心解决。
七、可行性分析K-means聚类算法是广泛使用的算法之一,其研究具有实际意义和可行性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0引言
数据挖掘( Data Mining) [1]是一种数据分析处理技 术,一般采取排出专 家 因 素 而 通 过 自 动 的 方 式 来 发 现 数据仓库、大型数据库或其他大量信息中新的、不可预 见的或隐藏的有价值的知识。数据挖掘方法既可以是 数学的,又可以是非数学的; 既可以是归纳的,又可以 是演绎的。发现的知识能被用于信息管理,查询优化, 决策支持以及过程控制等,用在数据自身的维护,所以 数据挖掘技术是当前多个领域研究的热点。
1 相关工作
聚类算法是一种非监督机器学习算法,其实质就 是对人们事先不了 解 的 数 据 集 进 行 分 组 ,使 得 同 一 组 内的数据尽可能相似而不同组内的数据尽可能不同, 其目的是揭示数据分布的真实情况。聚类分析在统计
第7 期
黄 韬等: 基于 k - means 聚类算法的研究
·55·
数据分析、模式识别、图 像 处 理、生 物 学 以 及 市 场 营 销 等领域也有着广泛的应用前景。目前的聚类算法大致 上主要被分为五类[3]: 划分方法,层次方法,基于密度 的方法,基于网格的方法和基于模型的方法。 1. 1 划分聚类算法
第 21 卷 第 7 期 2011 年 7 月
计算机技术与发展
COMPUTER TECHNOLOGY AND DEVELOPMENT
Vol. 21 No. 7 July 2011
基于 k - means 聚类算法的研究
黄 韬,刘胜辉,谭艳娜
( 哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080)
Abstract:Analyze and research the method of cluster analysis,analyze and compare many kinds of algorithms of cluster analysis,discuss their respective strengths and weaknesses. At the same time,according to the weaknesses of the cluster result of original k - means algorithm is significant influence by selecting the initial cluster centers randomly,a modified algorithm is proposed. Through taking sample many times to data set,choose final superior cluster center,bring down the impact of initial cluster centers to improved algorithm greatly. Simultaneously, the initial data is standadized once the initial cluster center is selected,makes cluster effect improved furthermore. Detecting new algorithm Hk - means through the date of UCI data set,the result shows that Hk - means algorithm is more prominent improved than initial k - means algorithm in cluster effect,and it's useful for conference to relative field. Key words:data mining;clustering algorithm;k - means algorithm
基于模型的聚类算法为每个簇假定一个模型,寻 找数据对象与给定模型之间的最佳拟合。基于模型的 算法可能通过构建反映数据的对象空间分布的密度函 数来定位聚类,或者基于标准的统计数字来自动决定 聚类的数目,从而 产 生 健 壮 的 聚 类 方 法 。 典 型 的 代 表 有 EM 算法,概念聚类以及神经网络。EM 算法比较 易于实现并且算法简单,但是不能达到全局最优; 概念 聚类在机器学习中 有 着 广 泛 的 应 用 ,但 是 对 于 大 型 数 据集聚类没有良好的伸缩性。
摘 要:分析研究聚类分析方法,对多种聚类分析算法进行分析比较,讨论各自的优点和不足,同时针对原 k - means 算法
的聚类结果受随机选取初始聚类中心的影响较大的缺点,提出一种改进算法。通过将对数据集的多次采样,选取最终较
优的初始聚类中心,使得改进后的算法受初始聚类中心选择的影响度大大降低; 同时,在选取初始聚类中心后,对初值进
行数据标准化处理,使聚类效果进一步提高。通过 UCI 数据集上的数据对新算法 Hk - means 进行检测,结果显示 Hk -
means 算法比原始的 k - means 算法在聚类效果上有显著的提高,并对相关领域有借鉴意义。
关键词:数据挖掘; 聚类算法; k - means 算法
中图分类号:TP301. 6
k - means 算法是划分聚类算法的典型代表,实质 上该算法基于簇中对象的平均值。为了能达到全局最 优,基于划分的聚类要求穷举所有可能的划分。算法 的处理过程如下:
算法的输入: 数据库中的对象与簇的数目 k。 算法的输出: 使得平方误差准则最小的 k 个簇。 方法如下: ( 1) 从整个样本 n 中,任意选择 k 个对象作为初始 的簇的中心 mi ( i = 1,2,…,k) 。 ( 2) 利用公式 1,计算数据集中的每个 p 到 k 个簇 中心的距离 d ( p ,mi ) 。 ( 3) 找到每个对象 p 的最小的 d ( p,mi) ,将 p 归入 到与 mi 相同的簇中。 ( 4) 遍历完所有对象之后,利用公式 2 重新计算 mi 的值,作为新的簇中心。
层次方法对给出 的 数 据 集 合 而 进 行 层 次 分 级 ,叫 做树聚类算法。它使 用 数 据 的 联 接 规 则,透 过 一 种 层 次架构方式,反复将数据进行分裂或聚合,以形成一个 层次序列的聚类的问题解。根据分解而形成的过程, 层次聚类则可以分为凝聚的 和 分 裂 的[7]。凝 聚 的 方 法,也叫做自底向上方法,首先将每一个对象作为单独 的一个组,接着相继地合并相近的对象和组,直到所有 的组合都合并为 一 个,或 者 达 到 了 一 个 中 止 条 件 。 分 裂的方法,也叫做自顶向下的方法,首先将所有的对象 都置于一个簇中。在 迭 代 的 每 一 个 步 骤 中 ,一 个 簇 则 被分裂为更小的簇,一 直 到 最 终 每 一 个 对 象 在 单 独 的 一个簇中,或达到 了 一 个 终 止 条 件。 一 种 纯 粹 的 层 次 聚类方法的缺点主要在于一旦合并或者是分裂执行, 则将不能修正,也就是说,如果某个合并或是分裂效果 在后来证明是不好的选择,该方法无法退回或是更正。 层次聚合算法的计算复杂性为 O( n2 ) ,适合于小型数 据集的分类。 1. 3 基于密度的聚类算法
聚类分析[2]是数 据 挖 掘 领 域 中 的 一 个 重 要 分 支 , 它既可以作为数据挖掘中其他分析算法的一个预处理 步骤,也可以作为一 个 单 独 的 工 具 发 现 数 据 库 中 数 据 分布的一些深入的信息。聚类算法大致分为划分方
法,层次方法,基于密度方法,基于网格方法和基于模 型方法。一般情况下,为了使聚类效果更佳,经常将划 分方法作为其他聚 类 方 法 的 预 处 理 步 骤 ,所 以 划 分 方 法的好坏直接影响结合聚类算法的效果。k - means 算法是划分方法中 应 用 最 广 泛 的 一 种 方 案 ,所 以 改 进 k - means 算法,不但改善了划分方法本身的性能,还 对结合的聚类方法提供了良好的接口。
由于 k - means 算法选取初始聚类质心是随机的, 导致聚类结果不稳定。为了提高聚类结果的稳定性, 在传统的聚类方法 上 结 合 聚 类 融 合 思 想 ,提 出 一 种 新 的 Hk - means 聚类方法,进行多次采样,选取最终较 优的选择的影响度大大降低,提高聚类结果的稳定性。
2 Hk - means 聚类算法
k - means 算法是划分聚类算法的典型代表之一, 它具有算法简单,速度快等优点,经常作为其他算法的 预处理步骤,所以它的精度直接或间接地影响着聚类 结果的质量。由于原始的 k - means 算法对初始质心 的选取敏感,导致结果质量不稳定。下文将针对这个 问题提出解决办法。 2. 1 k - means 算法
收稿日期:2010 - 12 - 01;修回日期:2011 - 03 - 02 基金项目:哈尔滨市后备带头人基金项目( 2004AFXXJ039) 作者简介:黄 韬( 1982 - ) ,男,黑龙江人,硕士研究生,研究方向为 企业智能计算; 刘胜辉,教授,硕士研究生导师,研究方向为计算机 集成制造系统,企业智能计算。
基于网格的聚类算法使用了一种多分辨率的网格 的数据结构,把对象的空间量化为有限数目的单元,进 而形成了一个网格结构。这种方法的优点是处理速度 很快。但是在构建父亲单元的时候则往往没有考虑到 子女单元及其相邻 的 单 元 之 间 的 关 系 ,从 而 降 低 了 聚 类结果的质量及其精确性。 1. 5 基于模型的聚类算法
文献标识码:A
文章编号:1673 - 629X(2011)07 - 0054 - 04
Research of Clustering Algorithm Based on K - means
HUANG Tao,LIU Sheng - hui,TAN Yan - na
( Sch. of Computer Sci. and Tech. ,Harbin Univ. of Sci. and Tech. ,Harbin 150080,China)
划分聚类的算法过程[4]如下: 给出一个 n 个对象 或元组的数据库,一个划分方法构建数据的 k 个划分, 每个划分即表示一个聚簇,并且 k < n 。也就是说,它 将数据划分为 k 个组,同时满足以下的要求: ( 1) 每个 组至少包括一个对象; ( 2) 每一个对象必须属于且仅 属于一个组。其思想是给定一个 n 个对象的数据库,通 过迭代重定位策略优化特定的目标函数,尝试确定数 据集的 k 个划分,每个划分表示一个聚簇 ( k ≤ n) 。 要求簇间的对象尽 可 能 相 近 或 相 关,不 同 的 簇 间 的 对 象尽可能不同。划分聚类算法实质上通过迭代重定位 策略优化特定的目 标 函 数,尝 试 确 定 数 据 集 的 一 个 划 分[5,6]。它具有挖掘算 法 简 单 、速 度 快 等 优 点,适 用 于 中小规模的数据集 中 发 现 球 状 簇,但 不 能 发 现 形 状 任 意和大小差别很大的类簇,只能保证收敛到局部最优, 聚类结果 受 初 始 聚 类 质 心 的 影 响,且 对 噪 音 点 敏 感。 典型的代表算法是 k - means 算法。 1. 2 层次聚类算法