实验二分治法归并排序
分治算法及其典型应用

分治算法及其典型应用
分治算法是一种重要的算法设计策略,它将一个大问题分解成若干个规模较小的子问题,然后递归地解决这些子问题,最后将它们的解合并起来,得到原问题的解。
分治算法在计算机科学和算法设计中有着广泛的应用,可以解决许多实际问题,下面将介绍一些典型的应用。
1. 排序算法。
分治算法在排序算法中有着重要的应用。
其中最著名的就是归并排序和快速排序。
在归并排序中,算法将数组分成两个子数组,分别进行排序,然后合并这两个有序的子数组。
而在快速排序中,算法选择一个基准值,将数组分成两个子数组,分别小于和大于基准值,然后递归地对这两个子数组进行排序。
2. 搜索算法。
分治算法也可以用于搜索问题,例如二分搜索算法。
在这种算法中,将搜索区间分成两个子区间,然后递归地在其中一个子区间中进行搜索,直到找到目标元素或者子区间为空。
3. 求解最大子数组问题。
最大子数组问题是一个经典的动态规划问题,也可以用分治算法来解决。
算法将数组分成两个子数组,分别求解左右子数组的最大子数组,然后再考虑跨越中点的最大子数组,最后将这三种情况的最大值作为整个数组的最大子数组。
4. 矩阵乘法。
分治算法也可以用于矩阵乘法。
在矩阵乘法中,算法将两个矩阵分成四个子矩阵,然后递归地进行矩阵乘法,最后将四个子矩阵的结果合并成一个矩阵。
总的来说,分治算法是一种非常重要的算法设计策略,它在许多实际问题中有着广泛的应用。
通过将一个大问题分解成若干个规模较小的子问题,然后递归地解决这些子问题,最后将它们的解合并起来,我们可以高效地解决许多复杂的问题。
分治法解决问题的步骤

分治法解决问题的步骤一、基础概念类题目(1 - 5题)题目1:简述分治法解决问题的基本步骤。
解析:分治法解决问题主要有三个步骤:1. 分解(Divide):将原问题分解为若干个规模较小、相互独立且与原问题形式相同的子问题。
例如,对于排序问题,可将一个大的数组分成两个较小的子数组。
2. 求解(Conquer):递归地求解这些子问题。
如果子问题规模足够小,则直接求解(通常是一些简单的基础情况)。
对于小到只有一个元素的子数组,它本身就是有序的。
3. 合并(Combine):将各个子问题的解合并为原问题的解。
在排序中,将两个已排序的子数组合并成一个大的有序数组。
题目2:在分治法中,分解原问题时需要遵循哪些原则?解析:1. 子问题规模更小:分解后的子问题规模要比原问题小,这样才能逐步简化问题。
例如在归并排序中,不断将数组对半分,子数组的长度不断减小。
2. 子问题相互独立:子问题之间应该尽量没有相互依赖关系。
以矩阵乘法的分治算法为例,划分后的子矩阵乘法之间相互独立进行计算。
3. 子问题与原问题形式相同:方便递归求解。
如二分查找中,每次查找的子区间仍然是一个有序区间,和原始的有序区间查找问题形式相同。
题目3:分治法中的“求解”步骤,如果子问题规模小到什么程度可以直接求解?解析:当子问题规模小到可以用简单的、直接的方法(如常量时间或线性时间复杂度的方法)解决时,就可以直接求解。
例如,在求数组中的最大最小值问题中,当子数组只有一个元素时,这个元素既是最大值也是最小值,可以直接得出结果。
题目4:分治法的“合并”步骤有什么重要性?解析:1. 构建完整解:它将各个子问题的解组合起来形成原问题的解。
例如在归并排序中,单独的两个子数组排序好后,只有通过合并操作才能得到整个数组的有序排列。
2. 保证算法正确性:如果合并步骤不正确,即使子问题求解正确,也无法得到原问题的正确答案。
例如在分治算法计算斐波那契数列时,合并不同子问题的结果来得到正确的斐波那契数是很关键的。
二路归并算法步骤

二路归并算法步骤在计算机科学中,归并排序是一种常用的排序算法,它的核心思想是将一个大问题分解为多个小问题,然后逐步解决这些小问题,最终得到整体的解决方案。
二路归并算法是归并排序的一种特殊实现方式,它通过将两个有序序列合并为一个有序序列来完成排序操作。
下面我们来详细介绍二路归并算法的步骤。
步骤一:将序列划分为若干子序列首先,我们将待排序的序列划分为若干个长度为1的子序列。
每个子序列都可以看作是一个已排序的序列。
步骤二:两两合并子序列接下来,我们将这些长度为1的子序列两两合并为长度为2的子序列。
在合并的过程中,我们需要比较两个子序列的元素大小,并按照从小到大的顺序将它们合并为一个新的有序子序列。
步骤三:再次两两合并子序列继续进行上述的合并操作,将长度为2的子序列两两合并为长度为4的子序列。
在每次合并的过程中,我们始终保持将两个子序列合并为一个有序子序列的原则。
步骤四:重复合并操作重复进行上述的合并操作,直到所有的子序列都合并为一个完整的有序序列为止。
这个过程可以看作是一个二叉树的构建过程,每次合并操作都会生成一个新的子节点,直到根节点为止。
步骤五:完成排序最终,我们得到的根节点就是一个已排序的序列,这个序列就是我们要求解的排序结果。
总结:二路归并算法通过将序列划分为若干个子序列,并逐步合并这些子序列来完成排序操作。
它的核心思想是利用已排序的子序列,通过比较和合并操作来生成一个更大的有序序列。
这个过程可以看作是一个逐层合并的过程,直到最终得到完整的有序序列。
二路归并算法的时间复杂度为O(nlogn),其中n表示待排序序列的长度。
这是因为在每次合并操作中,我们需要比较和移动每个元素一次,而合并的次数为logn。
因此,总的时间复杂度为O(nlogn)。
与其他排序算法相比,二路归并算法具有较好的稳定性和可扩展性,适用于各种规模的数据集。
总之,二路归并算法是一种高效的排序算法,它通过将待排序序列划分为若干个子序列,并逐步合并这些子序列来完成排序操作。
分治法-合并排序和快速排序
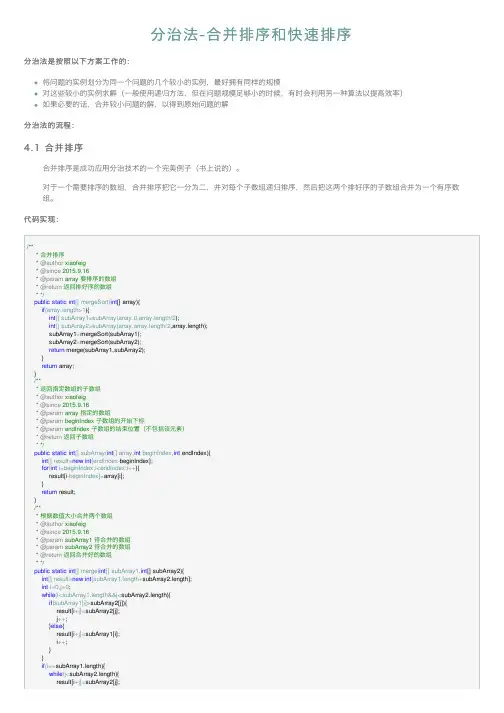
分治法-合并排序和快速排序分治法是按照以下⽅案⼯作的:将问题的实例划分为同⼀个问题的⼏个较⼩的实例,最好拥有同样的规模对这些较⼩的实例求解(⼀般使⽤递归⽅法,但在问题规模⾜够⼩的时候,有时会利⽤另⼀种算法以提⾼效率)如果必要的话,合并较⼩问题的解,以得到原始问题的解分治法的流程:4.1 合并排序合并排序是成功应⽤分治技术的⼀个完美例⼦(书上说的)。
对于⼀个需要排序的数组,合并排序把它⼀分为⼆,并对每个⼦数组递归排序,然后把这两个排好序的⼦数组合并为⼀个有序数组。
代码实现:/*** 合并排序* @author xiaofeig* @since 2015.9.16* @param array 要排序的数组* @return返回排好序的数组* */public static int[] mergeSort(int[] array){if(array.length>1){int[] subArray1=subArray(array,0,array.length/2);int[] subArray2=subArray(array,array.length/2,array.length);subArray1=mergeSort(subArray1);subArray2=mergeSort(subArray2);return merge(subArray1,subArray2);}return array;}/*** 返回指定数组的⼦数组* @author xiaofeig* @since 2015.9.16* @param array 指定的数组* @param beginIndex ⼦数组的开始下标* @param endIndex ⼦数组的结束位置(不包括该元素)* @return返回⼦数组* */public static int[] subArray(int[] array,int beginIndex,int endIndex){int[] result=new int[endIndex-beginIndex];for(int i=beginIndex;i<endIndex;i++){result[i-beginIndex]=array[i];}return result;}/*** 根据数值⼤⼩合并两个数组* @author xiaofeig* @since 2015.9.16* @param subArray1 待合并的数组* @param subArray2 待合并的数组* @return返回合并好的数组* */public static int[] merge(int[] subArray1,int[] subArray2){int[] result=new int[subArray1.length+subArray2.length];int i=0,j=0;while(i<subArray1.length&&j<subArray2.length){if(subArray1[i]>subArray2[j]){result[i+j]=subArray2[j];j++;}else{result[i+j]=subArray1[i];i++;}}if(i==subArray1.length){while(j<subArray2.length){result[i+j]=subArray2[j];}}else{while(i<subArray1.length){result[i+j]=subArray1[i];i++;}}return result;}算法分析:当n>1时,C(n)=2C(n-2)+C merge(n),C(1)=0C merge(n)表⽰合并阶段进⾏键值⽐较的次数。
分治法

顾铁成
1
引例:称硬币
如果给你一个装有16枚硬币的袋子,其中有一
枚是假的,并且其重与真硬币不同。你能不能 用最少的比较次数,找出这个假币?
为了帮助你完成这个任务,将提供一台可用来 比较两组硬币重量的仪器,利用这台仪器,可
以知道两组硬币的重量是否相同。
2
引例:称硬币
常规的解决方法是先将这些硬币分成两
15
当 k = 1 时,各种可能的残缺棋盘
16
三格板的四个不同方向
17
【输入】
第一行输入棋盘 的总行数,第二 行输入残缺棋盘 的格子坐标。
【样例输入】 4
4 1
【样例输出】 2 2 3 3 2 1 1 3 4 4 1 5
【输出】
覆盖的矩阵图。
0 4 5 5
18
问题分析
很明显,当K=0时,是不需要三格板的,而当
24
【样例输入】 5 3 23 8 91 56 4 【样例输出】 1
25
问题分析
对于一组混乱无序的数来说,要找到第k
小的元素,通常要经过两个步骤才能实 现:
第一步:将所有的数进行排序; 第二步:确定第k个位置上的数。
26
问题分析
传统的排序算法(插入排序、选择排序
、冒泡排序等)大家都已经很熟悉了, 但已学过的排序方法无论从速度上பைடு நூலகம்还 是从稳定性方面,都不是最佳的。
将7作为一个参照数;
将这个数组中比7大的数放在7的左边; 比7大的数放在7的右边;
这样,我们就可以得到第一次数组的调整:
[ 4 2 6 6 1 ] 7 [ 10 22 9 8 ]
29
c语言分治法实现合并排序算法

c语言分治法实现合并排序算法在计算机科学中,分治算法是一种将问题划分为较小子问题,然后将结果合并以解决原始问题的算法。
其中,合并排序算法就是一种常见的分治算法。
C语言可以使用分治法实现合并排序算法。
该算法的基本思想是将原始数组递归地分成两半,直到每个部分只有一个元素,然后将这些部分合并起来,直到形成一个完整的已排序的数组。
具体实现过程如下:1.首先,定义一个函数merge,该函数将两个已排序的数组合并成一个已排序的数组。
2.然后,定义一个函数merge_sort,该函数使用递归的方式将原始数组分成两个部分,并对每个部分调用merge_sort函数以进行排序。
3.最后,将已排序的两个数组合并到一起,使用merge函数。
以下是C语言代码:void merge(int arr[], int left[], int left_count, int right[], int right_count) {int i = 0, j = 0, k = 0;while (i < left_count && j < right_count) {if (left[i] < right[j]) {arr[k++] = left[i++];} else {arr[k++] = right[j++];}}while (i < left_count) {arr[k++] = left[i++];}while (j < right_count) {arr[k++] = right[j++];}}void merge_sort(int arr[], int size) { if (size < 2) {return;}int mid = size / 2;int left[mid];int right[size - mid];for (int i = 0; i < mid; i++) {left[i] = arr[i];}for (int i = mid; i < size; i++) {right[i - mid] = arr[i];}merge_sort(left, mid);merge_sort(right, size - mid);merge(arr, left, mid, right, size - mid);}int main() {int arr[] = {3, 8, 1, 6, 9, 4, 5, 7, 2};int size = sizeof(arr) / sizeof(arr[0]);merge_sort(arr, size);for (int i = 0; i < size; i++) {printf('%d ', arr[i]);}return 0;}以上代码可以将数组{3, 8, 1, 6, 9, 4, 5, 7, 2}排序成{1, 2, 3, 4, 5, 6, 7, 8, 9}。
常见算法设计实验报告(3篇)
第1篇一、实验目的通过本次实验,掌握常见算法的设计原理、实现方法以及性能分析。
通过实际编程,加深对算法的理解,提高编程能力,并学会运用算法解决实际问题。
二、实验内容本次实验选择了以下常见算法进行设计和实现:1. 排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序。
2. 查找算法:顺序查找、二分查找。
3. 图算法:深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)。
4. 动态规划算法:0-1背包问题。
三、实验原理1. 排序算法:排序算法的主要目的是将一组数据按照一定的顺序排列。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序等。
2. 查找算法:查找算法用于在数据集中查找特定的元素。
常见的查找算法包括顺序查找和二分查找。
3. 图算法:图算法用于处理图结构的数据。
常见的图算法包括深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)等。
4. 动态规划算法:动态规划算法是一种将复杂问题分解为子问题,通过求解子问题来求解原问题的算法。
常见的动态规划算法包括0-1背包问题。
四、实验过程1. 排序算法(1)冒泡排序:通过比较相邻元素,如果顺序错误则交换,重复此过程,直到没有需要交换的元素。
(2)选择排序:每次从剩余元素中选取最小(或最大)的元素,放到已排序序列的末尾。
(3)插入排序:将未排序的数据插入到已排序序列中适当的位置。
(4)快速排序:选择一个枢纽元素,将序列分为两部分,使左侧不大于枢纽,右侧不小于枢纽,然后递归地对两部分进行快速排序。
(5)归并排序:将序列分为两半,分别对两半进行归并排序,然后将排序好的两半合并。
(6)堆排序:将序列构建成最大堆,然后重复取出堆顶元素,并调整剩余元素,使剩余元素仍满足最大堆的性质。
2. 查找算法(1)顺序查找:从序列的第一个元素开始,依次比较,直到找到目标元素或遍历完整个序列。
二分归并排序的时间复杂度以及递推式
一、简介二分归并排序是一种常见的排序算法,它通过将问题分解为子问题,并将子问题的解合并来解决原始问题。
该算法的时间复杂度非常重要,因为它直接影响算法的效率和性能。
在本文中,我们将深入探讨二分归并排序的时间复杂度,并通过递推式来进一步分析算法的性能。
二、二分归并排序的时间复杂度1. 分析在二分归并排序中,时间复杂度可以通过以下三个步骤来分析:- 分解:将原始数组分解为较小的子数组。
- 解决:通过递归调用来对子数组进行排序。
- 合并:将排好序的子数组合并为一个整体有序的数组。
2. 时间复杂度在最坏情况下,二分归并排序的时间复杂度为O(nlogn)。
这是因为在每一层递归中,都需要将数组分解为两个规模近似相等的子数组,并且在每一层递归的最后都需要将这两个子数组合并起来。
可以通过递推式来进一步证明算法的时间复杂度。
3. 递推式分析我们可以通过递推式来分析二分归并排序的时间复杂度。
假设对规模为n的数组进行排序所需的时间为T(n),则可以得到以下递推式:T(n) = 2T(n/2) +其中,T(n/2)表示对规模为n/2的子数组进行排序所需的时间表示将两个子数组合并所需的时间。
根据递推式的定义,我们可以得到二分归并排序的时间复杂度为O(nlogn)。
三、结论与个人观点通过以上分析,我们可以得出二分归并排序的时间复杂度为O(nlogn)。
这意味着该算法在最坏情况下也能保持较好的性能,适用于大规模数据的排序。
我个人认为,二分归并排序作为一种经典的排序算法,其时间复杂度的分析对于理解算法的工作原理和性能至关重要。
通过深入研究递推式,可以更加直观地理解算法的性能表现,为进一步优化算法提供了重要的参考依据。
四、总结在本文中,我们探讨了二分归并排序的时间复杂度,通过分析和递推式的方式深入理解了该算法的性能表现。
通过对时间复杂度的分析,我们对算法的性能有了更深入的认识,并且能够更好地理解算法在实际应用中的表现。
相信通过本文的阅读,读者能够对二分归并排序有更全面、深刻和灵活的理解。
归并排序的优化方法及效率测试
归并排序的优化方法及效率测试归并排序是一种常见的排序算法,它通过将待排序元素分成两个子序列,分别对子序列进行排序,然后将两个有序子序列合并成一个有序序列。
这种算法的时间复杂度为O(nlogn),效率相对较高。
然而,在实际应用中,我们可以进一步优化归并排序的性能,以提升排序的效率。
本文将介绍归并排序的三种常见优化方法,并对它们进行效率测试。
一、优化方法一:插入排序优化在归并排序中,当待排序序列的元素数量减少到一定程度时,可以使用插入排序来代替归并排序,以提高效率。
插入排序是一种简单但效率较高的排序算法,适用于小规模或基本有序的序列。
具体实现方法是,在归并过程中判断子序列的长度,当子序列的长度小于等于某个阈值时,使用插入排序算法进行排序。
该优化方法的关键是选择合适的阈值。
当阈值过大时,插入排序无法体现出优势;当阈值过小时,频繁的切换排序算法反而会增加额外的开销。
因此,我们需要通过实验找到最优的阈值,以达到最佳的性能。
二、优化方法二:自底向上的归并排序传统的归并排序采用递归的方式进行,即不断地将待排序序列划分为两个子序列并进行合并。
然而,递归调用会增加额外的开销,并占用大量的栈空间。
为了优化此问题,可以使用自底向上的归并排序。
自底向上的归并排序不再依赖递归,而是通过迭代来实现。
具体实现方法是,先将待排序序列中的每个元素看作一个独立的有序子序列,然后两两合并相邻的子序列,直至得到一个完全有序的序列。
相比传统的递归归并排序,自底向上的归并排序无需额外的栈空间,并且可以减少递归调用的开销,因此在实际应用中效率更高。
三、优化方法三:优化合并操作归并排序的核心操作是合并两个有序子序列,该操作通常使用一个辅助数组来存储合并结果。
然而,每次进行合并操作时都需要申请和释放额外的内存空间,可能存在性能损耗。
为了优化这一问题,可以在排序过程中创建一个与待排序序列等长的辅助数组,并在合并过程中循环利用该辅助数组。
具体实现方法是,在每次合并操作之前,将待排序序列的元素复制到辅助数组中,然后利用辅助数组进行合并操作。
二叉树的快速排序、归并排序方法
二叉树的快速排序、归并排序方法一、快速排序快速排序采用的是分治法策略,其基本思路是先选定一个基准数(一般取第一个元素),将待排序序列抽象成两个子序列:小于基准数的子序列和大于等于基准数的子序列,然后递归地对这两个子序列排序。
1. 递归实现(1)选定基准数题目要求采用第一个元素作为基准数,因此可以直接将其取出。
(2)划分序列接下来需要将待排序序列划分成两个子序列。
我们定义两个指针 i 和 j,从待排序序列的第二个元素和最后一个元素位置开始,分别向左和向右扫描,直到 i 和 j 相遇为止。
在扫描过程中,将小于等于基准数的元素移到左边(即与左侧序列交换),将大于基准数的元素移到右边(即与右侧序列交换)。
当 i=j 时,扫描结束。
(3)递归排序子序列完成划分后,左右两个子序列就确定了下来。
接下来分别对左右两个子序列递归调用快速排序算法即可。
2. 非递归实现上述方法是快速排序的递归实现。
对于大量数据或深度递归的情况,可能会出现栈溢出等问题,因此还可以使用非递归实现。
非递归实现采用的是栈结构,将待排序序列分成若干子序列后,依次将其入栈并标注其位置信息,然后将栈中元素依次出栈并分割、排序,直至栈为空。
二、归并排序归并排序同样采用的是分治思想。
其基本思路是将待排序序列拆分成若干个子序列,直至每个子序列只有一个元素,然后将相邻的子序列两两合并,直至合并成一个有序序列。
1. 递归实现(1)拆分子序列归并排序先将待排序序列进行拆分,具体方法是将序列平分成两个子序列,然后递归地对子序列进行拆分直至每个子序列只剩下一个元素。
(2)合并有序子序列在完成子序列的拆分后,接下来需要将相邻的子序列两两合并为一个有序序列。
我们先定义三个指针 i、j 和 k,分别指向待合并的左侧子序列、右侧子序列和合并后的序列。
在进行合并时,从两个子序列的起始位置开始比较,将两个子序列中较小的元素移动到合并后的序列中。
具体操作如下:- 当左侧子序列的第一个元素小于等于右侧子序列的第一个元素时,将左侧子序列的第一个元素移动到合并后的序列中,并将指针 i 和 k 分别加 1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告专用纸
实验报告专用纸
成绩: 实验报告专用纸
课程
学院
专业
(班级)
姓名 学号 日期 年 月 日 2、算法分析: 设待排序记录个数为n ,
该算法的基本语句是 归并算法的 循环体的 比较语句 “if (b[i]<=b[j]) temp[k++]=b[i++]; else temp[k++]=b[j++]; ”,
其执行次数为: ,即执行一趟 归并算法 的时间复杂度为 。
则 归并排序算法存在以下推式:
所以,归并排序算法 的时间复杂度为 。
另外,归并排序算法递归调用次数为 。
3、结果如下:
n=5
n=8
成绩:
实验报告专用纸
课程学院
专业
(班级)
姓名学号日期年月日
由n = 5,6,…,10等数据的运行结果可知,
随着问题规模n的增加,其时间复杂度(比较次数的执行)也增加,
所以,该算法分析的判断正确。
4、与选择排序的对比(时间复杂度)
平均情况最好情况最坏情况选择排序
归并排序
从时间复杂度上看,归并排序的要小于选择排序,
并且实际上,
在问题规模相同而待排序记录顺序的整齐程度有所差异的情况下,
选择排序是不论待排序记录顺序的整齐程度如何,其时间复杂度都是固定的;
n=10
成绩:。