多元统计分析实验报告doc
【Selected】 多元统计分析-实验三.doc

实验三一、实验内容1、实验背景近几年,中国房地产业得到了长足的发展,但房地产价格的上涨一直饱受争议,甚至有逃离“北、上、广”的言论,这也从侧面反映了房地产价格的区域性特征。
2、实验目的根据20BB年中国31个省、市、自治区房地市场的房屋平均销售价格、住宅平均销售价格、别墅与高档公寓平均销售价格、经济适用房平均销售价格等九项指标的统计数据(见下表3),对各省市进行区域性分类。
3、实验要求试根据这些数据分别进行R型和Q型聚类分析。
二、实验报告1、实验数据选取全国31个省市地区的房屋平均销售价格、住宅平均销售价格、别墅与高档公寓平均销售价格、经济适用房平均销售价格、办公楼平均销售价格、商业营业用房平均销售价格、其他平均销售价格、商品房销售面积、住宅销售面积等9项指标作为观测量进行分析。
数据见下表3。
表3注:X1:房屋平均销售价格;X2:住宅平均销售价格;X3:别墅、高档公寓平均销售价格;X4:经济适用房平均销售价格;X5:办公楼平均销售价格;X6:商业营业用房平均销售价格;X7:其他平均销售价格;X8:商品房销售面积;X9:住宅销售面积。
2、数据处理数据中无异常值或缺失值,因此不需要进行处理。
3、数据分析1)、Q型聚类分析操作步骤如下:(1)打开SPSS统计软件,将数据输入数据文件中。
(2)在菜单的选项中选择Analyze→Classify命令,在Classify命令下选择Hierarchicalcluster(系统聚类法)。
(3)Cluster下选择Cases单选框。
将9个变量移入Variables框中,将省份变量移入LabelCasesby框中作为标识变量。
(4)选择Statistics选项,选中Agglomerationschedule复选框;ClusterMembership栏中选择Rangeofsolution并在其后两个小矩形框中分别填入2和8。
单击Continue继续。
(5)选择Plots选项,选中Dendrogram复选框,其他默认,单击Continue 继续。
多元统计分析实验报告
第二部分:实验过程记录(可加页) (包括实验原始数据记录,实验现象记录,实验过程发现的问题
等) 操作步骤: 1、 执行“分析”—“比较均值”—“单因素方差分析” ; 2、 在弹出的单因素方差分析对话框中,将时期选为因子,将 X1、X2、X3、X4 选为因变量; 3、 单击“对比” ,选择“多项式” ,在后面的下拉菜单中选择“线性” ,然后继续; 4、 单击“两两比较” ,选择“LSD”和“S-N-K” ,显著性水平默认为 0.05,然后继续; 5、 单击“选项” ,选择“方差同质性检验”和“均值图” ,然后继续,点击“确定”后即可输出结果。
12
题目:研究者提出,随着时间的推移头骨尺寸会发生变化,这是外来移民与原住民人口民族融合的证据。表 6.13 是古埃及三个时期的男性头骨的四个观测值得观测数据,这是个观测变量是: X1=头骨最大的最大宽度 X2=头骨高度 X3=头骨底穴至齿槽的长度 X4=头骨鼻梁高度 对古埃及头骨数据构造单因子 MANOVA 表, a=0.05.并构造 95%联合置信区间来判断在三个时期中哪个分 令 量的均值发生了改变。同常的 MANOVA 假设对这些数据是不是合理的?请解释。 部分数据如下:
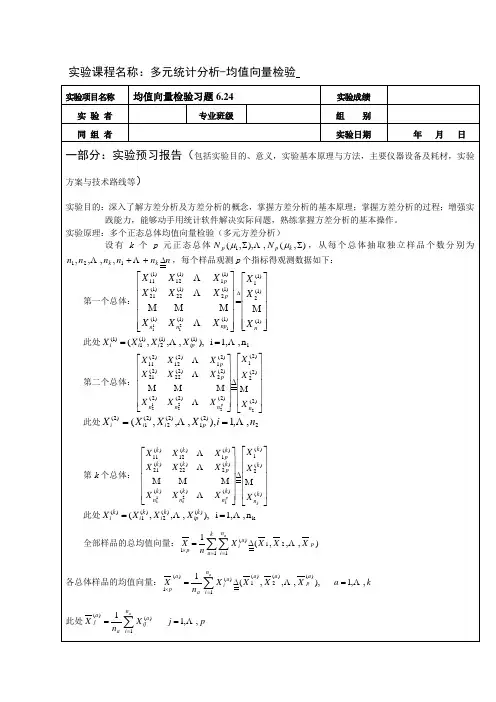
实验课程名称:多元统计分析-均值向量检验
实验项目名称 实 验 者 同 组 者
均值向量检验习题 均值向量检验习题 6.24
专业班级
实验成绩 实验成绩 组 别 年 月 日
实验日期
一部分:实验预习报告(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验
方案与技术路线等) 实验目的:深入了解方差分析及方差分析的概念,掌握方差分析的基本原理;掌握方差分析的过程;增强实 践能力,能够动手用统计软件解决实际问题,熟练掌握方差分析的基本操作。 实验原理:多个正态总体均值向量检验(多元方差分析) 设 有 k 个 p 元 正 态 总 体 N p ( µ1 , Σ), L , N p ( µ k , Σ) , 从 每 个 总 体 抽 取 独 立 样 品 个 数 分 别 为
多元统计实验报告

多元统计实验报告一、实验目的多元统计分析是统计学的一个重要分支,它能够处理多个变量之间的复杂关系。
本次实验的主要目的是通过实际操作和数据分析,深入理解多元统计分析的基本原理和方法,并掌握其在实际问题中的应用。
二、实验数据本次实验使用了一组来自某市场调研公司的数据集,包含了消费者的年龄、性别、收入、消费习惯等多个变量,共计_____个样本。
三、实验方法1、主成分分析(PCA)主成分分析是一种降维方法,它通过将多个相关变量转换为一组较少的不相关变量(即主成分),来简化数据结构并提取主要信息。
2、因子分析因子分析用于发现潜在的公共因子,这些因子能够解释多个观测变量之间的相关性。
3、聚类分析聚类分析将数据对象分组,使得同一组内的对象具有较高的相似性,而不同组之间的对象具有较大的差异性。
四、实验过程1、数据预处理首先,对原始数据进行了清洗和预处理,包括处理缺失值、异常值和数据标准化等操作,以确保数据的质量和可用性。
2、主成分分析使用统计软件进行主成分分析,计算出特征值、贡献率和累计贡献率。
根据特征值大于 1 的原则,确定了保留的主成分个数。
通过主成分载荷矩阵,解释了主成分的实际意义。
3、因子分析运用因子分析方法,提取公共因子,并通过旋转因子载荷矩阵,使得因子的解释更加清晰和具有实际意义。
计算因子得分,用于进一步的分析和应用。
4、聚类分析采用 KMeans 聚类算法,根据选定的变量对样本进行聚类。
通过不断调整聚类中心和重新分配样本,最终得到了较为合理的聚类结果。
五、实验结果与分析1、主成分分析结果提取了_____个主成分,它们累计解释了_____%的方差。
第一个主成分主要反映了_____,第二个主成分主要与_____相关,以此类推。
这为我们理解数据的主要结构提供了重要的线索。
2、因子分析结果成功提取了_____个公共因子,它们能够较好地解释原始变量之间的相关性。
每个因子所代表的潜在因素也得到了清晰的解释,有助于深入了解消费者的行为特征和市场结构。
应用多元统计分析实验报告

多元统计分析实验报告学院名称理学院专业班级应用统计学14-2学生姓名张艳雪学号201411081051工资、受教育年限、初始工资和工作经验资料如下表所示: 设职工总体的以上变量服从多元正态分布,根据样本资料利用 SPSS 软件求出均注 1:最大似然估计公式为: μˆ = X = ∑ ∑ (X i - X )(X i - X )' ; ˆ第一章 多元正态分布1.1 从某企业全部职工中随机抽取一容量为 6 的样本,该样本中个职工的目前值向量和协方差矩阵的最大似然估计。
1 n n i =1 X i , Σ = 1 nn i =1一.SPSS 操作步骤:第一步:利用 spss 建立数据集第二步:分析--描述统计--描述 计算样本均值向量 第三步:分析--相关--双变量计算样本协方差阵与样本相关系数二.输出结果:⎪ μ= 37125 ⎪ 152.50⎪ ⎛ 352068000 12500 -110677500 102000 ⎫= -110677500 - 86250 2192793750 691125 ⎪16695.1⎪⎭ ∑ X i,∑ (X i - X )(X i - X )'ˆ三.实验结果分析:样本均值为样本的协方差∑⎪⎪如此就可以按照极大似然估计方程:1 nΣ =n i =1得出均值向量与协方差向量的最大似然估计结果。
μ=X=1nn i=1ˆ第三章聚类分析3.1下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K-均值法利用SPSS软件分别对这些公司进行聚类,并对结果进行比较分析。
公司编号净资产收益率每股净利润总资产周转率资产负债率流动负债比率每股净资产净利润增长率总资产增长率111.090.210.0596.9870.53 1.86-44.0481.99211.960.590.7451.7890.73 4.957.0216.11300.030.03181.99100-2.98103.3321.18411.580.130.1746.0792.18 1.14 6.55-56.325-6.19-0.090.0343.382.24 1.52-1713.5-3.366100.470.4868.486 4.7-11.560.85710.490.110.3582.9899.87 1.02100.2330.32811.12-1.690.12132.14100-0.66-4454.39-62.759 3.410.040.267.8698.51 1.25-11.25-11.4310 1.160.010.5443.7100 1.03-87.18-7.411130.220.160.487.3694.880.53729.41-9.97128.190.220.3830.31100 2.73-12.31-2.771395.79-5.20.5252.3499.34-5.42-9816.52-46.821416.550.350.9372.3184.05 2.14115.95123.4115-24.18-1.160.7956.2697.8 4.81-533.89-27.74一、实验原理:1.系统聚类的基本思想是:首先,每个样品(或变量)先聚成一类,然后,选择距离公式计算类与类之间的距离,把距离相近的样品(或变量)先聚成类,距离相远的后聚成类,该过程一直进行下去,每个样品(或变量)总能聚到合适的类中,最后,所有的样品(或变量)聚成一类。
多元统计分析——典型相关分析实验报告
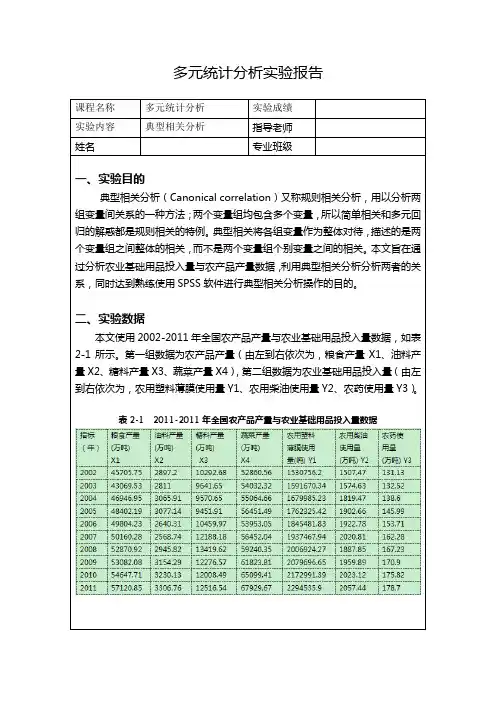
多元统计分析实验报告课程名称多元统计分析实验成绩实验内容典型相关分析指导老师姓名专业班级一、实验目的典型相关分析(Canonical correlation)又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。
典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。
本文旨在通过分析农业基础用品投入量与农产品产量数据,利用典型相关分析分析两者的关系,同时达到熟练使用SPSS软件进行典型相关分析操作的目的。
二、实验数据本文使用2002-2011年全国农产品产量与农业基础用品投入量数据,如表2-1所示。
第一组数据为农产品产量(由左到右依次为,粮食产量X1、油料产量X2、糖料产量X3、蔬菜产量X4),第二组数据为农业基础用品投入量(由左到右依次为,农用塑料薄膜使用量Y1、农用柴油使用量Y2、农药使用量Y3)。
表2-1 2011-2011年全国农产品产量与农业基础用品投入量数据由于cancorr不能读取中文名称,所以变量名均需为英文名。
将表2-1数据转换为能够进行典型相关分析形式的数据,如表2-2所示。
表2-2 典型相关分析数据(农产品产量与农业基础用品投入量数据)三、实验过程SPSS 16.0并未提供典型相关分析的交互窗口,只能直接在syntax editor 窗口呼叫SPSS的CANCORR程序来执行分析。
选择【File】—【New】—【Syntax】,弹出Syntax对话框,在对话框中写入调用Cancorr程序,如图3-1所示。
图3-1 Syntax窗口调用CONCORR函数四、实验结果表4-1为第一组数据,即农产品产量之间的相关关系表。
从表中可以看出,粮食产量(X1)与蔬菜产量(X4)有较高的相关关系,相关系数高达0.9035;粮食产量(X1)与糖料产量(X3)相关关系也较大,相关系数为0.8081;油料产量(X2)与蔬菜产量(X4)的相关关系较大,为0.7442。
多元统计分析报告整理版.doc

1、主成分分析的目的是什么?主成分分析是考虑各指标间的相互关系,利用降维的思想把多个指标转换成较少的几个相互独立的、能够解释原始变量绝大局部信息的综合指标,从而使进一步研究变得简单的一种统计方法。
它的目的是希望用较少的变量去解释原始资料的大局部变异,即数据压缩,数据的解释。
常被用来寻找判断事物或现象的综合指标,并对综合指标所包含的信息进展适当的解释。
2、主成分分析根本思想?主成分分析就是设法将原来指标重新组合成一组新的互相无关的几个综合指标来代替原来指标。
同时根据实际需要从中选取几个较少的综合指标尽可能多地反映原来的指标的信息。
● 设p 个原始变量为 ,新的变量(即主成分)为 , 主成分和原始变量之间的关系表示为?3、在进展主成分分析时是否要对原来的p 个指标进展标准化?SPSS 软件是否能对数据自动进展标准化?标准化的目的是什么?需要进展标准化,因为因素之间的数值或者数量级存在较大差距,导致较小的数被淹没,导致主成分偏差较大,所以要进展数据标准化; 进展主成分分析时SPSS 可以自动进展标准化;标准化的目的是消除变量在水平和量纲上的差异造成的影响。
求解步骤⏹ 对原来的p 个指标进展标准化,以消除变量在水平和量纲上的影响 ⏹ 根据标准化后的数据矩阵求出相关系数矩阵 ⏹ 求出协方差矩阵的特征根和特征向量⏹ 确定主成分,并对各主成分所包含的信息给予适当的解释版本二:根据我国31个省市自治区2006年的6项主要经济指标数据,表二至表五,是SPSS 的输出表,试解释从每X 表可以得出哪些结论,进展主成分分析,找出主成分并进展适当的解释:〔下面是SPSS 的输出结果,请根据结果写出结论〕 表一:数据输入界面p 21p x x x ,,, 2121p y y y ,,, 21表二:数据输出界面a〕此表为相关系数矩阵,表示的是各个变量之间的相关关系,说明变量之间存在较强的相关系数,适合做主成分分析。
观察各相关系数,假如相关矩阵中的大局部相关系数小于,如此不适合作因子分析。
《多元统计实验》因子分析实验报告一
《多元统计实验》因子分析实验报告newscore2 #显示以第二因子得分排序结果newscore3<-newscore[order(newscore[,4],decreasing=T),] #按第三因子得分排序newscore3 #显示以第三因子得分排序结果newscore4<-newscore[order(newscore[,5],decreasing=T),] #按因子综合得分排序newscore4 #显示以因子综合得分排序结果三、实验结果分析下图为数据标准化后相关系数矩阵图,可以看出x3、x8、x4之间的存在较大的相关性,这些消费指标之间存在较强的线性相关关系,适合用因子分析模型进行分析,下面用极大似然估计法进行因子分析。
将公共因子设置为3个,从下运行结果可以看出,累计方差贡献率达到了83.36%,说明选择3个是合适的,从初始载荷阵可以看出消费指标无法准确的解释因子的含义,故我们在进行基于极大似然法的正交旋转。
由下图旋转得到的因子载荷估计,居住(x3)、生活用品及服务(x4)、交通通信(x5)、教育文化娱乐(x6)、医疗保健(x7)和其他用品及服务(x8)在因子f1上的载荷分别为0.772、0.679、0.663、0.858、0.733、0.692,这六个消费指标反映了日常消费,因此f1命名为日常消费因子;x1在f2上反映了食品烟酒的消费,因此f2命名为食品烟酒因子;x2在f3上反映了衣着的消费,因此命名为衣着因子。
也由此可得到因子分析模型:x*1≈0.208f1+0.975f2+ε1x*2≈0.220f1+0.972f3+ε2x*3≈0.772f1+0.510f2+ε3x*4≈0.679 f1+0.361 f2+0.405f3+ε4x*5≈0.663 f1+0.440 f2+0.271 f3+ε5x*6≈0.858 f1+0.262 f2+ε6x*7≈0.733 f1+0.350 f3+ε7x*8≈0.692 f1+0.522 f2+0.391+ε8从下图的各因子得分结果,可以看出,在第一因子上得分多的为上海、北京、天津;第二因子上得分多的为北京、上海、云南;第三因子得分多的为海南、广东、上海;但是这样得到的结果,较难找,因此我们对得分分别按第一因子和第二因子以及第三因子进行排序可直观看出。
多元统计分析课程设报告计参考Word
XXXX课程设计任务书课程名称多元统计分析课题判别分析与因子分析专业班级学生姓名学号指导老师审批任务书下达日期任务完成日期目录课题一判别分析摘要 (1)一、指标和数据 (1)二、聚类分析的实施 (1)三、判别分析的实施 (2)四、结果分析 (5)课题二因子分析摘要 (6)一、数据 (6)二、因子分析的实施 (6)三、结果分析 (10)总结 (11)参考文献 (11)评分标准 (12)附表 (13)课题一判别分析摘要聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。
而判别分析是根据表明事物特点的变量值和它们所属的类,求出判别函数。
根据判别函数对未知所属类别的事物进行分类的一种分析方法。
核心是考察类别之间的差异。
本课题正是基于多元统计分析中聚类分析和判别分析的方法,以《各地区按行业分城镇单位就业人员平均工资》的调查数据为对象(预留出待判样本),借助Spss统计软件用聚类分析进行分类,并以分好的类别为依据对待判样本进行判别分类以及对已分类样本进行回判分析。
一、指标和数据按要求于国家统计局网站查找变量数大于等于10,样本数大于等于20的合适数据并整理。
得到整理后的《各地区按行业分城镇单位就业人员平均工资》(见附表一)。
其体系共有31个地区,19项指标。
具体指标x1:农、林、牧、渔业就业人员平均工资,简写“农、林、牧、渔业”(以下具以简写形式省略“就业人员平均工资”);x2:采矿业;x3:制造业;x4:电力、燃气及水的生产和供应;x5:建筑业;x6:交通运输、仓储和邮政业;x7:信息传输、计算机服务和软件业;x8:批发和零售业;x9:住宿和餐饮业;x10:金融业;x11:房地产业;x12:租赁和商务服务业;x13:科学研究、技术服务和地质勘查业;x14:水利、环境和公共设施管理业;x15:居民服务和其他服务业;x16:教育;x17:卫生、社会保障和社会福利业;x18:文化、体育和娱乐业;x19:公共管理和社会组织。
实验报告-因子分析(多元统计)精选全文
精选全文完整版可编辑修改实验报告主成分分析(综合性实验)(Principal component analysis)实验原理:主成分分析利用指标之间的相关性,将多个指标转化为少数几个综合指标,从而达到降维和数据结构简化的目的。
这些综合指标反映了原始指标的绝大部分信息,通常表示为原始指标的某种线性组合,且综合指标间不相关。
利用矩阵代数的知识可求解主成分。
实验题目一:将彩色胶卷在显影液下处理后在不同情形下曝光,然后通过红、绿、蓝三种滤色片并在高、中、低三种密度下进行测量,每个胶卷有高红、高绿、高蓝、中红、…、低蓝等九个指标(分别记为X1-X9九个变量)。
试验了108个胶卷,由数据已算得如下协差阵:(S2a1)177 179 95 96 53 32 -7 -4 -3419 245 131 181 127 -2 1 4302 60 109 142 4 4 11158 102 42 4 3 2137 96 4 5 6128 2 2 834 31 3339 3948实验要求:(1)试从协差阵出发进行主成分分析;(2)计算方差累积贡献率;(3)作Scree图,并结合(2)的结果确定主成分的个数;(4)试对结果进行解释。
实验题目二:下表中给出了不同国家及地区的男子径赛记录:(t8a6)Country 100m(s) 200m(s)400m(s)800m(min)1500m(min)5000m(min)10,000m(min)Marathon(mins)Argentina 10.39 20.81 46.84 1.81 3.7 14.04 29.36 137.72 Australia 10.31 20.06 44.84 1.74 3.57 13.28 27.66 128.3 Austria 10.44 20.81 46.82 1.79 3.6 13.26 27.72 135.9 Belgium 10.34 20.68 45.04 1.73 3.6 13.22 27.45 129.95 Bermuda 10.28 20.58 45.91 1.8 3.75 14.68 30.55 146.62 Brazil 10.22 20.43 45.21 1.73 3.66 13.62 28.62 133.13 Burma 10.64 21.52 48.3 1.8 3.85 14.45 30.28 139.95 Canada 10.17 20.22 45.68 1.76 3.63 13.55 28.09 130.15 Chile 10.34 20.8 46.2 1.79 3.71 13.61 29.3 134.03 China 10.51 21.04 47.3 1.81 3.73 13.9 29.13 133.53 Columbia 10.43 21.05 46.1 1.82 3.74 13.49 27.88 131.35 Cook Islands 12.18 23.2 52.94 2.02 4.24 16.7 35.38 164.7 Costa Rica 10.94 21.9 48.66 1.87 3.84 14.03 28.81 136.58 Czechoslovakia 10.35 20.65 45.64 1.76 3.58 13.42 28.19 134.32 Denmark 10.56 20.52 45.89 1.78 3.61 13.5 28.11 130.78 Dominican Republic 10.14 20.65 46.8 1.82 3.82 14.91 31.45 154.12 Finland 10.43 20.69 45.49 1.74 3.61 13.27 27.52 130.87 France 10.11 20.38 45.28 1.73 3.57 13.34 27.97 132.3 German (D.R.) 10.12 20.33 44.87 1.73 3.56 13.17 27.42 129.92 German (F.R.) 10.16 20.37 44.5 1.73 3.53 13.21 27.61 132.23 Great Brit.& N. Ireland 10.11 20.21 44.93 1.7 3.51 13.01 27.51 129.13 Greece 10.22 20.71 46.56 1.78 3.64 14.59 28.45 134.6 Guatemala 10.98 21.82 48.4 1.89 3.8 14.16 30.11 139.33 Hungary 10.26 20.62 46.02 1.77 3.62 13.49 28.44 132.58 India 10.6 21.42 45.73 1.76 3.73 13.77 28.81 131.98Indonesia 10.59 21.49 47.8 1.84 3.92 14.73 30.79 148.83 Ireland 10.61 20.96 46.3 1.79 3.56 13.32 27.81 132.35 Israel 10.71 21 47.8 1.77 3.72 13.66 28.93 137.55 Italy 10.01 19.72 45.26 1.73 3.6 13.23 27.52 131.08 Japan 10.34 20.81 45.86 1.79 3.64 13.41 27.72 128.63 Kenya 10.46 20.66 44.92 1.73 3.55 13.1 27.38 129.75 Korea 10.34 20.89 46.9 1.79 3.77 13.96 29.23 136.25 D.P.R Korea 10.91 21.94 47.3 1.85 3.77 14.13 29.67 130.87 Luxembourg 10.35 20.77 47.4 1.82 3.67 13.64 29.08 141.27 Malaysia 10.4 20.92 46.3 1.82 3.8 14.64 31.01 154.1 Mauritius 11.19 22.45 47.7 1.88 3.83 15.06 31.77 152.23 Mexico 10.42 21.3 46.1 1.8 3.65 13.46 27.95 129.2 Netherlands 10.52 20.95 45.1 1.74 3.62 13.36 27.61 129.02 New Zealand 10.51 20.88 46.1 1.74 3.54 13.21 27.7 128.98 Norway 10.55 21.16 46.71 1.76 3.62 13.34 27.69 131.48 Papua New Guinea 10.96 21.78 47.9 1.9 4.01 14.72 31.36 148.22 Philippines 10.78 21.64 46.24 1.81 3.83 14.74 30.64 145.27 Poland 10.16 20.24 45.36 1.76 3.6 13.29 27.89 131.58 Portugal 10.53 21.17 46.7 1.79 3.62 13.13 27.38 128.65 Rumania 10.41 20.98 45.87 1.76 3.64 13.25 27.67 132.5 Singapore 10.38 21.28 47.4 1.88 3.89 15.11 31.32 157.77 Spain 10.42 20.77 45.98 1.76 3.55 13.31 27.73 131.57 Sweden 10.25 20.61 45.63 1.77 3.61 13.29 27.94 130.63 Switzerland 10.37 20.46 45.78 1.78 3.55 13.22 27.91 131.2 Taipei 10.59 21.29 46.8 1.79 3.77 14.07 30.07 139.27 Thailand 10.39 21.09 47.91 1.83 3.84 15.23 32.56 149.9 Turkey 10.71 21.43 47.6 1.79 3.67 13.56 28.58 131.5 USA 9.93 19.75 43.86 1.73 3.53 13.2 27.43 128.22 USSR 10.07 20 44.6 1.75 3.59 13.2 27.53 130.55Western Samoa 10.82 21.86 49 2.02 4.24 16.28 34.71 161.83 (数据来源:1984年洛杉机奥运会IAAF/AFT径赛与田赛统计手册)实验要求:(1)试求主成分,并对结果进行解释;(2)试用方差累积贡献率和Scree图确定主成分的个数;(3)计算各国第一主成分的得分并排名。
多元统计分析实验报告(精选多篇)
多元统计分析实验报告(精选多篇)第一篇:多元统计分析实验报告多元统计分析得实验报告院系:数学系班级:13级 B 班姓名:陈翔学号:20131611233 实验目得:比较三大行业得优劣性实验过程有如下得内容:(1)正态性检验;(2)主体间因子,多变量检验a;(3)主体间效应得检验;(4)对比结果(K 矩阵);(5)多变量检验结果;(6)单变量检验结果;(7)协方差矩阵等同性得Box 检验a,误差方差等同性得Levene 检验 a;(8)估计;(9)成对比较,多变量检验;(10)单变量检验。
实验结果:综上所述,我们对三个行业得运营能力进行了具体得比较分析,所得数据表明,从总体来瞧,信息技术业要稍好于电力、煤气及水得生产与供应业以及房地产业。
1。
正态性检验Kolmogorov-SmirnovaShapir o—Wilk 统计量 df Sig.统计量df Sig、净资产收益率。
113 35、200*。
978 35。
677 总资产报酬率。
121 35、200*。
964 35、298 资产负债率。
086 35。
200*.962 35、265 总资产周转率.180 35、006。
864 35。
000流动资产周转率、164 35、018.88535、002 已获利息倍数、28135.000。
55135、000 销售增长率.103 35、200*。
949 35、104 资本积累率。
251 35。
000、655 35。
000 *。
这就是真实显著水平得下限。
a。
Lilliefors显著水平修正此表给出了对每一个变量进行正态性检验得结果,因为该例中样本中n=35<2000,所以此处选用 Shapiro—W ilk 统计量。
由 Sig。
值可以瞧到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面得分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成得向量遵从正态分布(尽管事实上并非如此)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元统计与程序设计》课程实验报告
项目名称:
学生姓名:
学生学号:
指导教师:
完成日期:
1 实验内容
2 模型建立与求解 2.1聚类分析的形成思路
2.2.1类平均法
2.2.2谱系图的形成
2.3.快速聚类法 (以上内容见课本) 3 实验数据与实验结果
3.1实验数据
设有20个土壤样品分别对5个变量的观测数据如表5.16所示,试利用 聚类法对其进行样品聚类分析
样品号 含沙量1X 淤泥含量2X 粘土含量3X 有机物4X PH 值5X 1 77.3 13.0 9.7 1.5 6.4 2 82.5 10.0 7.5 1.5 6.5 3 66.9 20.0 12.5 2.3 7.0 4 47.2 33.3 19.0 2.8 5.8 5 65.3 20.5 14.2 1.9 6.9 6 83.3 10.0 6.7 2.2 7.0 7 81.6 12.7 5.7 2.9 6.7 8 47.8 36.5 15.7 2.3 7.2 9 48.6 37.1 14.3 2.1 7.2 10 61.6 25.5 12.6 1.9 7.3 11 58.6 26.5 14.9 2.4 6.7 12 69.3 22.3 8.4 4.0 7.0 13 61.8 30.8 7.4 2.7 6.4 14 67.7 25.3 7.0 4.8 7.3 15 57.2 31.2 11.6 2.4 6.3 16 67.2 22.7 10.1 33.3 6.2 17 59.2 31.2 9.6 2.4 6.0 18
80.2
13.2
6.6
2.0
5.8
19 82.2 11.1 6.7 2.2 7.2 20
69.7
20.7
9.6
3.1
5.9
3.2实验过程及结果 Case Processing Summary(a)
Cases
Valid Missing Total N Percent N Percent N Percent 20 100.0% 0 .0% 20 100.0%
a Squared Euclidean Distance used
上表是接近度矩阵,计算距离使用的是平方欧氏距离,所以样品间距离越大,样品越相异,由表中矩阵可以看出样品8号和样品9号的距离是最小的,因此它们最先聚为一类。
Average Linkage (Between Groups)
Agglomeration Schedule
Stage Cluster Combined
Coefficient
s Stage Cluster First
Appears
Next Stage
Cluster 1 Cluster 2
Cluster 1 Cluster 2 1
8
9
.153
16
2 6 19 .17
3 0 0 8 3 3 5 .273 0 0 7
4 2 7 .524 0 0 8
5 12 14 .624 0 0 13
6 15 1
7 .656 0 0 9 7 3 10 1.061 3 0 10
8 2 6 1.120 4 2 11
9 13 15 1.240 0 6 15 10 3 11 1.522 7 0 13 11 1 2 2.008 0 8 14 12 18 20 2.223 0 0 14 13 3 12 3.519 10 5 15 14 1 18 4.926 11 12 17 15 3 13 5.014 13 9 16 16 3 8 6.646 15 1 17 17 1 3 10.557 14 16 18 18 1 4 17.079 17 0 19 19 1
16
24.533
18
上表是反应每一阶段聚类的结果,可见第一阶段时第8个样品和第9个样品聚为一类。
聚合系数随分类数变化曲线
0510152025
300
5
1015
20
分类数
聚合系数
系列1
从上曲线可以看出当分类数为4或5时,曲线变得平缓。
Dendrogram
{16},第二类{4},第三类{1,2,6,7,18,19,20},剩下的为第四类。
上图是冰柱图,我们把它分成四类,每个样品后边有一列X,如果个数少于4,那么它与前面多于4个X的样品聚为一类,由上图很容易看出分类结果。
Quick Cluster
Initial Cluster Centers
Cluster
1 2 3 4
含沙量69.3 83.3 67.2 47.8 淤泥含
量
22 10 23 37 粘土含
量
8.4 6.7 10.1 15.7 有机物 4.0 2.2 33.3 2.3 PH值7.0 7.0 6.2 7.2
Iteration History(a)
Iterat ion
Change in Cluster Centers 1 2 3 4
1 6.015 2.765 .000 3.210
2 .000 .000 .000 .000
a Convergence achieved due to no or small change in cluster centers. The maximum absolute coordinate change for any center is .000. The current iteration is 2. The minimum distance between initial centers is 18.799.
Cluster Membership
Case
Number 样品号Cluster Distanc
e
1 1
2 4.869
2 2 2 2.224
3 3 1 5.677
4 4 4 5.115
5 5 1 5.662
6 6 2 2.765
7 7 2 2.019
8 8 4 3.210
9 9 4 3.215
10 10 1 3.683
11 11 1 7.433
12 12 1 6.015
13 13 1 7.384
14 14 1 5.351
15 15 4 8.530
16 16 3 .000
17 17 1 8.429
18 18 2 2.065 19 19 2 1.393 20 20 1 6.774
上表是样品的分类情况,快速聚类法将样品分为这样四类:第一类{3,5,10,11,12,13,14,17,20},第二类{1,2,6,7,18,19},第三类{16},第四类{4,8,9,15}。
Final Cluster Centers
Cluster
1 2 3 4 含沙量 64.5 81.2 67.2 50.2 淤泥含
量
25 12 23 35
粘土含
量
10.7 7.2 10.1 15.2
有机物 2.8 2.1 33.3 2.4 PH 值 6.7 6.6 6.2 6.6
Distances between Final Cluster Centers
Clust er 1 2 3 4 1 21.547 30.669 17.854 2 21.547 36.093 39.327 3 30.669 36.093 37.541 4 17.854 39.327 37.541 ANOVA
Cluster Error F Sig. Mean Square df Mean
Square df 含沙量 797.706 3 14.693 16 54.291 .000 淤泥含
量
442.583 3 11.208 16 39.489 .000
粘土含
量
51.435 3 6.682 16 7.697 .002
有机物 301.257 3 .585 16 515.244 .000 PH 值 .088 3 .301 16 .293 .830 The F tests should be used only for descriptive purposes because the clusters have been chosen to maximize the differences among cases in
different clusters. The observed significance levels are not corrected for this and thus cannot be interpreted as tests of the hypothesis that the cluster means are equal.
上表是方差分析表,从中可以看出,有4个变量对分类贡献显著。
Number of Cases in each Cluster
Clust er 1 9.000
2 6.000
3 1.000
4 4.000
Valid 20.000
Missing .000
用系统聚类法,分为4类,结果如下:
第一类{16},
第二类{4},
第三类{1,2,6,7,18,19,20},
剩下的为第四类。
用快速聚类法将样品分为这样四类:
第一类{3,5,10,11,12,13,14,17,20},
第二类{1,2,6,7,18,19},
第三类{16},
第四类{4,8,9,15}。
用两种方法得出的分类结果稍有不同,这时需要综合考虑分类问题本身的知识来决定归为哪一类会好些。